
對實時數據湖的解讀 數據湖的概念是比較寬泛的,不同的人可能有著不同的解讀。這個名詞誕生以來,在不同的階段被賦予了不同的含義。 數據湖的概念最早是在 Hadoop World 大會上提出的。當時的提出者給數據湖賦予了一個非常抽象的含義,他認為它能解決數據集市面臨的一些重要問題。 其中最主要的兩個問題是 ...
對實時數據湖的解讀
數據湖的概念是比較寬泛的,不同的人可能有著不同的解讀。這個名詞誕生以來,在不同的階段被賦予了不同的含義。

數據湖的概念最早是在 Hadoop World 大會上提出的。當時的提出者給數據湖賦予了一個非常抽象的含義,他認為它能解決數據集市面臨的一些重要問題。
其中最主要的兩個問題是:首先,數據集市只保留了部分屬性,只能解決預先定義好的問題;另外,數據集市中反映細節的原始數據丟失了,限制了通過數據解決問題。從解決問題的角度出發,希望有一個合適的存儲來保存這些明細的、未加工的數據。因此在這個階段,人們對數據湖的解讀更多的是聚焦在中心化的存儲之上。
不同的雲廠商也把自己的對象產存儲產品稱為數據湖。比如 AWS 在那個階段就強調數據湖的存儲屬性,對應的就是自家的對象存儲 S3。在 Wiki 的定義中也是強調數據湖是一個中心化存儲,可以存海量的不同種類的數據。但是當對象存儲滿足了大家對存儲海量數據的訴求之後,人們對數據湖的解讀又發生了變化。
第二階段,對數據湖的解讀更多的是從開源社區和背後的商業公司發起的。比如 Databricks 作為一個雲中立的產品,它將雲廠商的這個對象存儲稱為 data lakes storage,然後把自己的重心聚焦在如何基於一個中心化的存儲構建一個數據分析、數據科學和機器學習的數據湖解決方案,並且把這個方案稱之為 lake。他們認為在這個中心化的存儲之上構建事務層、索引層,元數據層,可以去解決數據湖上的可靠性、性能和安全的問題。
與此同時,Uber 最初也將 Hudi 對外稱為一個事務型的數據湖,名字實際上也是由 Hadoop Updates and Incrementals 縮寫而來,最早也是被用於解決 Uber 內部離線數據的合規問題。現在他們更傾向的定義是一個流式數據湖平臺,Iceberg 也常常被人們納入數據湖的討論。儘管 Ryan Blue 一直宣稱 Iceberg 是一個 Open Table Format。這三者有一些共同點,一個是對 ACID 的支持,引入了一個事務層,第二是對 streaming 和 batch 的同等支持,第三就是聚焦在如何能更快的查詢數據。國內也有人將 Hudi、Iceberg、Delta Lake 稱為數據湖的三劍客。
講完了業界的解讀,來看一下位元組跳動對數據湖的解讀。我們是結合位元組的業務場景來解讀的。通過實踐總結,我們發現數據湖需要具備六大能力:
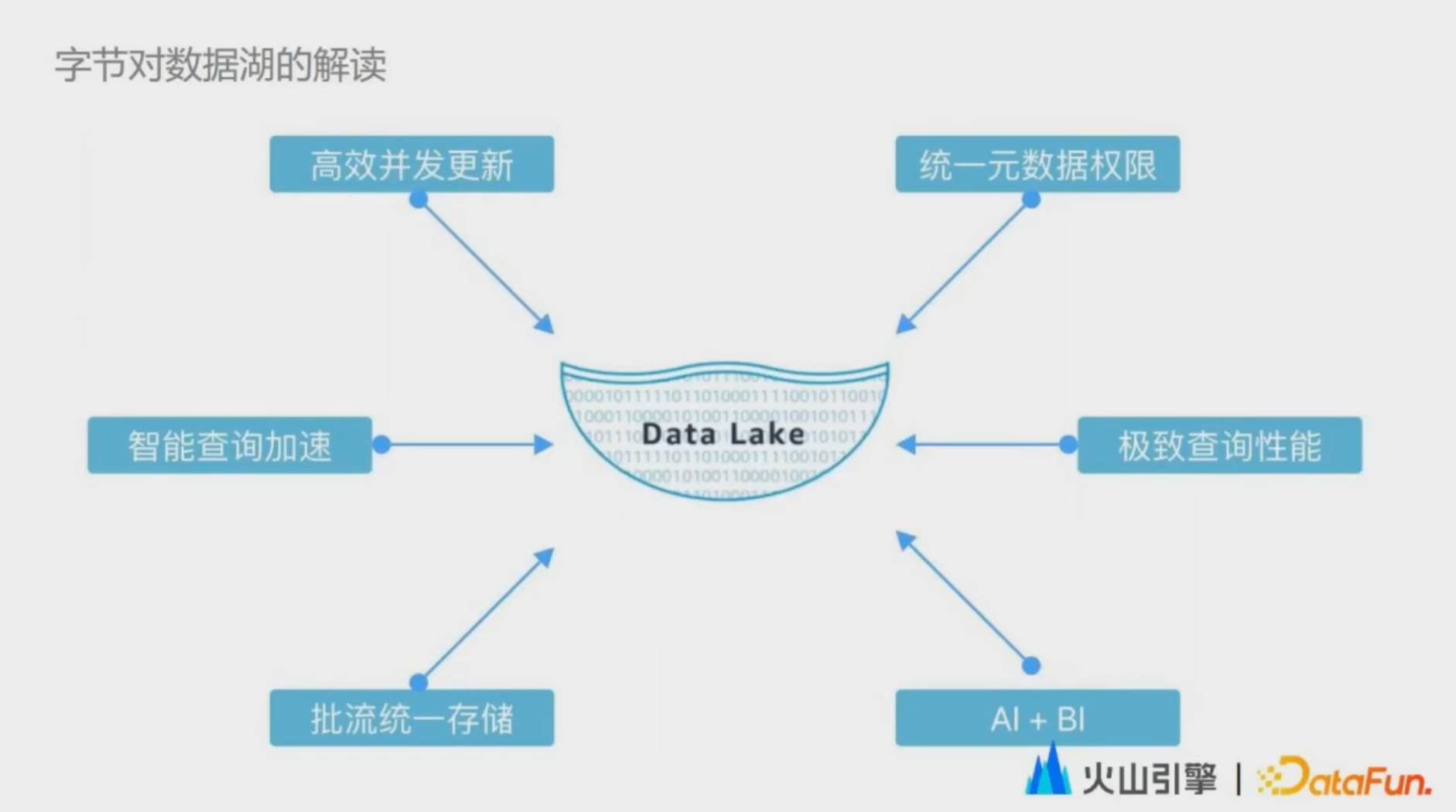
第一是高效的併發更新能力。 因為它能夠改變我們在 Hive 數倉中遇到的數據更新成本高的問題,支持對海量的離線數據做更新刪除。
第二是智能的查詢加速。 用戶使用數據湖的時候,不希望感知到數據湖的底層實現細節,數據湖的解決方案應該能夠自動地優化數據分佈,提供穩定的產品性能。
第三是批流一體的存儲。 數據湖這個技術出現以來,被數倉行業給予了厚望,他們認為數據湖可以最終去解決一份存儲流批兩種使用方式的問題,從而從根本上提升開發效率和數據質量。
第四是統一的元數據和許可權。 在一個企業級的數據湖當中,元數據和許可權肯定是不能少的。同時在湖倉共存的情況下,用戶不希望元數據和許可權在湖倉兩種情況下是割裂的。
第五是極致的查詢性能。 用戶對於數據湖的期望就是能夠在數據實時入湖的同時還能做到數據的秒級可視化。
第六是 AI + BI。 數據湖數據的對外輸出,不只局限於 BI,同時 AI 也是數據湖的一等公民,數據湖也被應用在了位元組的整個推薦體系,尤其是特征工程當中。實時數據湖其實是數據湖之上,更加註重數據的實時屬性或者說流屬性的一個數據湖發展方向。當然,正如業界對於數據湖的解讀一直在演變,我們對數據湖的解讀也不會局限於以上場景和功能。
落地實時數據湖過程中的挑戰和應對方式
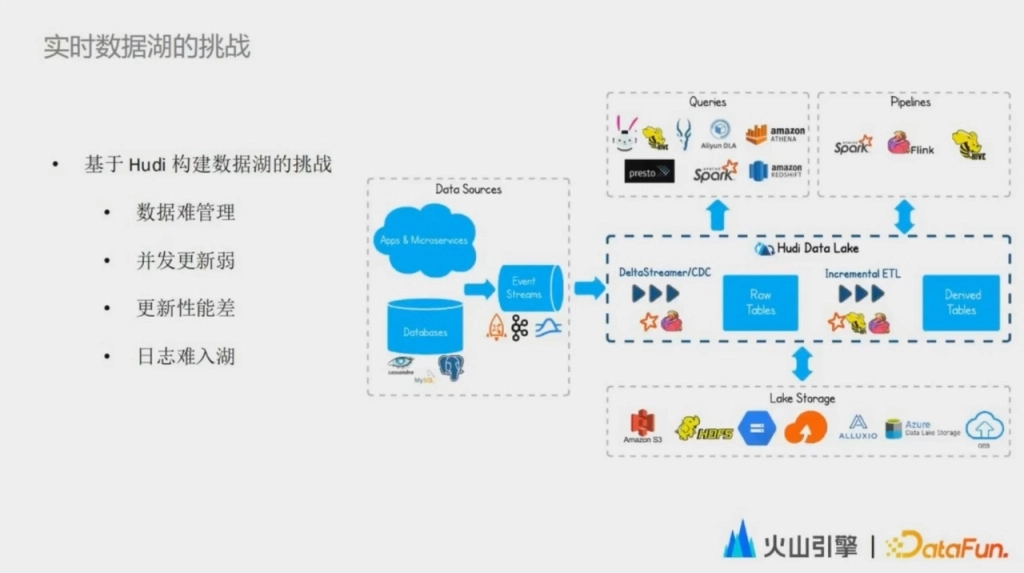
接下來介紹數據湖落地的挑戰和應對。位元組內部的數據湖最初是基於開源的數據湖框架 Hudi 構建的,選擇 Hudi,最簡單的一個原因就是因為相比於 Iceberg 和 Delta Lake,Hudi 原生支持可擴展的索引系統,能夠幫助數據快速定位到所在的位置,達到高效更新的效果。
在嘗試規模化落地的過程中,我們主要遇到了四個挑戰:數據難管理,併發更新弱,更新性能差,以及日誌難入湖。
接下來會一一介紹這些挑戰背後出現的原因以及我們應對的策略。
- 數據難管理
下圖是一個典型的基於中心化存儲構建數倉機器學習和數據科學的架構。這裡將加工過後的數據保存在數倉中,通過數倉的元數據進行組織。數據科學家和機器學習框架都會直接去這個中心化的存儲中獲取原始數據。因此在這個中心化存儲之上的數據對用戶來說是完全分散的,沒有一個全局的視圖。
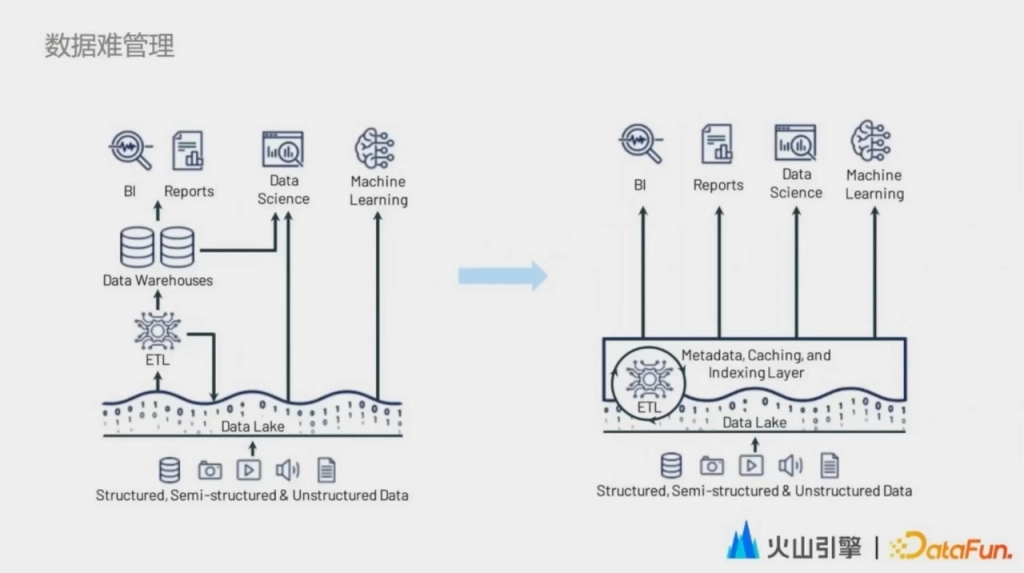
為瞭解決這個數據難管理的問題,Databricks 提出了一個 Lakehouse 的架構,就是在存儲層之上去構建統一的元數據緩存和索引層,所有對數據湖之上數據的使用都會經過這個統一的一層。在這一點上和我們的目標是很相似的,但是現實是比較殘酷的,我們面臨的是海量存量數據,這些存量數據不管是數據格式的遷移,還是使用方式的遷移,亦或是元數據的遷移,都意味著巨大的投入。因此在很長一段時間里,我們都會面臨數倉和數據湖共存這樣一個階段。在這一階段,兩者的連通性是用戶最為關心的。
我們在數據湖和數倉之上,構建了一層統一的元數據層,這層元數據層屏蔽了下層各個系統的元數據的異構性,由統一的元數據層去對接 BI 工具,對接計算引擎,以及數據開發、治理和許可權管控的一系列數據工具。而這一層對外暴露的 API 是與 Hive 相容的。儘管 Hive 這個引擎已經逐漸被其他的更新的計算引擎代替了,比如 Spark、Presto、Flink,但是它的源數據管理依舊是業界的事實標準。另外一些雲廠商即使選擇構建了自己的元數據服務,也都同時提供了和 HMS 相容的元數據查詢介面,各個計算引擎也都內置了 Hive Catalog 這一層。

解決了上層的訪問統一的問題,但依舊沒有解決數據湖和數倉元數據本身的異構問題。這個異構問題是如何導致的呢?為什麼 Hive Matestore 沒有辦法去滿足元數據管理的這個訴求?
這就涉及到數據湖管理元數據的特殊性。以 Hudi 為例,作為一個典型的事務型數據湖,Hudi 使用時間線 Timeline 來追蹤針對錶的各種操作。比如 commit compaction clean, Timeline 類似於數據湖裡的事務管理器,記錄對錶的更改情況。而這些更改或事務記錄了每次更新的操作是發生在哪些文件當中,哪些文件為新增,哪些文件失效,哪些數據新增,哪些數據更新。
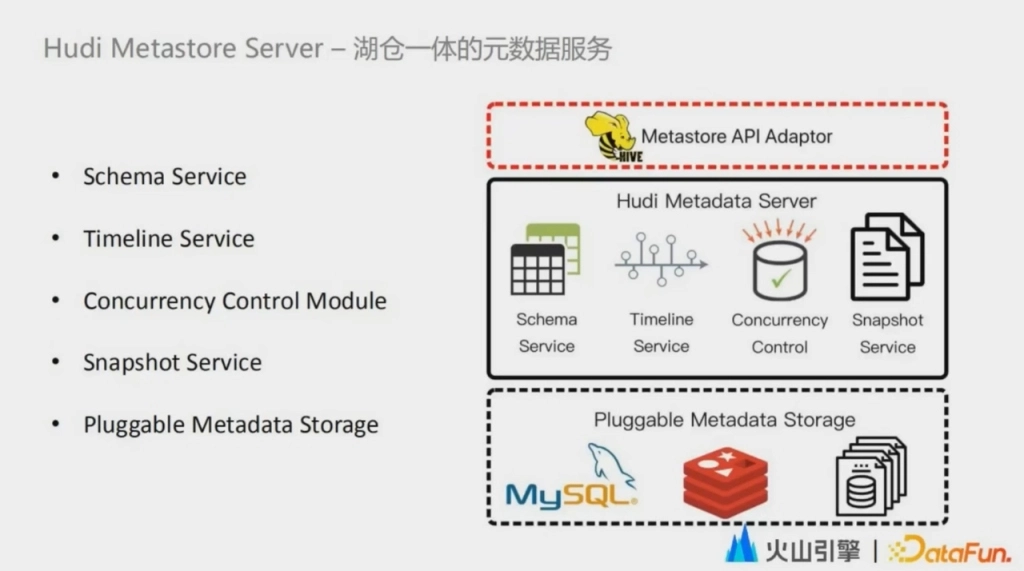
總結下來,數據湖是通過追蹤文件來管理元數據。管理的力度更細了,自然也就避免了無效的讀寫放大,從而提供了高效的更新刪除、增量消費、時間旅行等一系列的能力。但這其實也就意味著另外一個問題,就是一個目錄中可以包含多個版本的文件,這與 Hive 管理元數據的方式就產生了分歧,因為 Hive Metastore 是通過目錄的形式來管理元數據的,數據更新也是通過覆蓋目錄來保證事務。由於對元信息的管理力度不同,基於 Hive Metastore 的元數據管理其實是沒有辦法實現數據湖剛剛提到的一系列能力的。針對這個問題,Hudi 社區的解決方案是使用一個分散式存儲來管理這個 Timeline 。Timeline 裡面記錄了每次操作的元數據,也記錄了一些表的 schema 和分區的信息,通過同步到 Hive Metastore 來做元數據的展示。這個過程中我們發現了三個問題。
第一個問題就是分區的元數據是分散在兩個系統當中的,缺乏 single source of true。第二個是分區的元數據的獲取需要從 HDFS 拉取多個文件,沒有辦法給出類似於 HMS 這樣的秒級訪問響應。服務線上的數據應用和開發工具時,這個延遲是沒有辦法滿足需求的。第三個是讀表的時候需要拉取大量的目錄和 Timeline 上記錄的表操作對應的元數據進行比對,找出最新的這個版本包含的文件。元數據讀取本身就很重,並且缺乏裁剪能力,這在近實時的場景下帶來了比較大的 overhead。
Hudi Metastore Server 融合了 Hive Metastore 和 Hudi MetaData 管理的優勢。首先,Hudi Metastore Server 提供了多租戶的、中心化的元數據管理服務,將文件一級的元數據保存在適合隨機讀寫的存儲中,讓數據湖的元數據不再分散在多個文件當中,滿足了 single source of true。其次,Hudi Metastore Server 針對元數據的查詢,尤其是一些變更操作。比如 Job position 提供了與 Hive Metastore 完全相容的介面,用戶在使用一張數據湖上的表的時候,享受到這些增加的高效更新、刪除、增量消費等能力的同時,也能享受到一張 Hive 表所具備的功能,例如通過 Spark、Flink、Presto 查詢,以及在一些數據開發工具上線上的去獲取到元數據以及一些分區 TTL 清理的能力。此外,Hudi Metastore Server 還解決了一個關鍵性的問題,就是多任務併發更新弱的問題。
- 併發更新弱
我們最早是基於 Hudi 社區的 0.7 版本的內核進行研發的,當時 Hudi 的 Timeline 中的操作必須是完全順序的,每一個新的事務都會去回滾之前未完成的事務,因此無法支持併發寫入。後續社區也實現了一個併發寫入的方案,整體是基於分散式鎖實現的,並且只支持了 Spark COW 表的併發寫,並不適用於 Flink 或者實時的 MOR 表。但是多任務的併發寫入是我們內部實踐當中一個非常通用的訴求。因此我們在 Hudi Metastore Server 的 Timeline 之上,使用樂觀鎖去重新實現了這個併發的更新能力。同時我們這個併發控制模塊還能支持更靈活的行列級別併發寫策略,為後續要介紹到的實時數據關聯的場景的落地提供了一個可能。
除了多任務的併發寫入之外,我們在單個 Flink 任務的併發寫入也遇到了瓶頸。由於 Hudi 設計之初嚴重依賴 Spark。0.7.0 的版本才剛剛支持 Flink。不管是在穩定性還是在功能上都和 Spark On Hudi 有非常大的差距。因此在進行高 QPS 入湖的情況下,我們就遇到了單個 Flink 任務的擴展性問題。
我們通過在 Flink 的 embedding term server 上支持對當前進行中的事務元信息進行一下緩存,大幅提升了單個任務能夠併發寫入的文件量級,基本上是在 80 倍的量級。結合分區級別的併發寫入,我們整體支撐了近千萬 QPS 的數據量的增量入湖。
下一步的併發問題是批流併發衝突的問題。批流併發衝突問題類似於一個我們在傳統數據湖中遇到的場景,就是有一連串的小事務和一個周期比較長的長事務,如果這兩者發生衝突,應該如何處理。
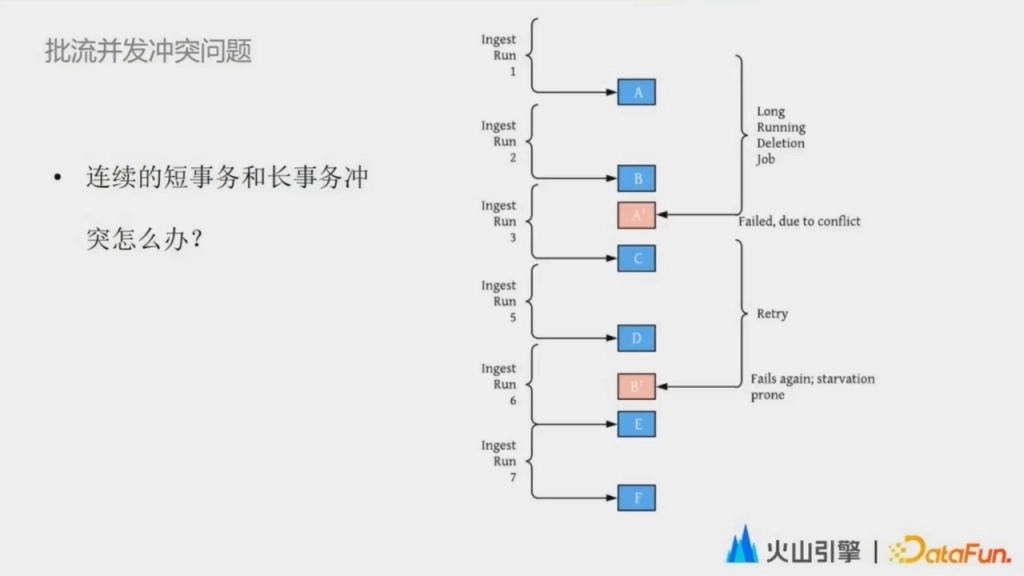
如果讓短事務等長事務完成之後再進行,那對一個實時的鏈路來說,就意味著數據的可見性變低了。同時如果在等待過程中失敗了,還會有非常高的 fail over 成本。但是如果我們讓這個長事務失敗了,成本又會很高,因為這個長事務往往需要耗費更多的資源和時間。而在批流併發衝突的這個場景下,最好是兩都不失敗,但這從語義上來講又不符合我們認知中的隔離級別。
為瞭解決批流衝突的問題,我們的思路是提供更靈活的衝突檢查和數據合併策略。最基礎的就是行級併發,首先兩個獨立的 writer 寫入的數據在物理上就是隔離的,藉助文件系統的租約機制也能夠保證對於一個文件同時只有一個 writer。所以這個衝突實際上不是發生在數據層面的,而是發生在元數據層面。那數據的衝突與否,就可以交由用戶來定義。很多時候入湖的數據實際上並不是一個現實中正在發生的事情,而是一個現實操作的回放。比如圖中的這個場景,我們假設刪除的作業是針對一個特定的 Snapshot。即使有衝突,我們可以認為整個刪除的過程是瞬時完成的,後續的新事物可以追加的發生在這次刪除作業之後。
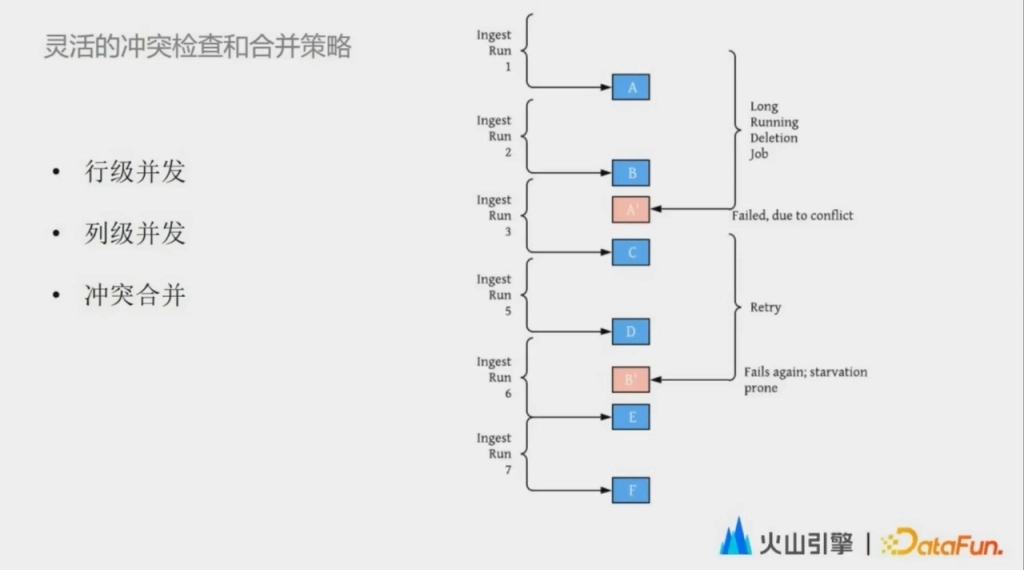
第二就是列級併發。比如接下來在實踐實際案例中,我們要介紹的這個實時數據關聯場景,每個 writer 實際上只是根據主鍵去更新部分的列。因此這些數據其實在行級別看起來是衝突的,但是從列的角度來看是完全不衝突的。配合我們的一些確定性索引,數據能被寫入到同一個文件組中,這樣就不會出現一致性的問題。
最後就是衝突合併。假如兩個數據真的是在行級別和列級別都發生了衝突,那真的只能通過 fail 掉一個事務才能完成嗎?我覺得是不一定的,這裡我們受到了 git 的啟發。假如兩次 commit 衝突了,我們是不是可以提供 merge 值的策略,比如數據中帶有時間戳,在合併時就可以按照時間戳的先後順序來做合併。
- 更新性能差
我們最早選擇基於 Hudi 也是因為可擴展的索引系統,通過這個索引系統可以快速地定位到需要跟新的文件。這帶來了三點好處,一個是避免讀取不需要的文件;二是避免更新不必要的文件;三是避免將更新的數據和歷史的數據做分散式關聯,而是通過提前將文件分好組的方式直接在文件組內進行合併。
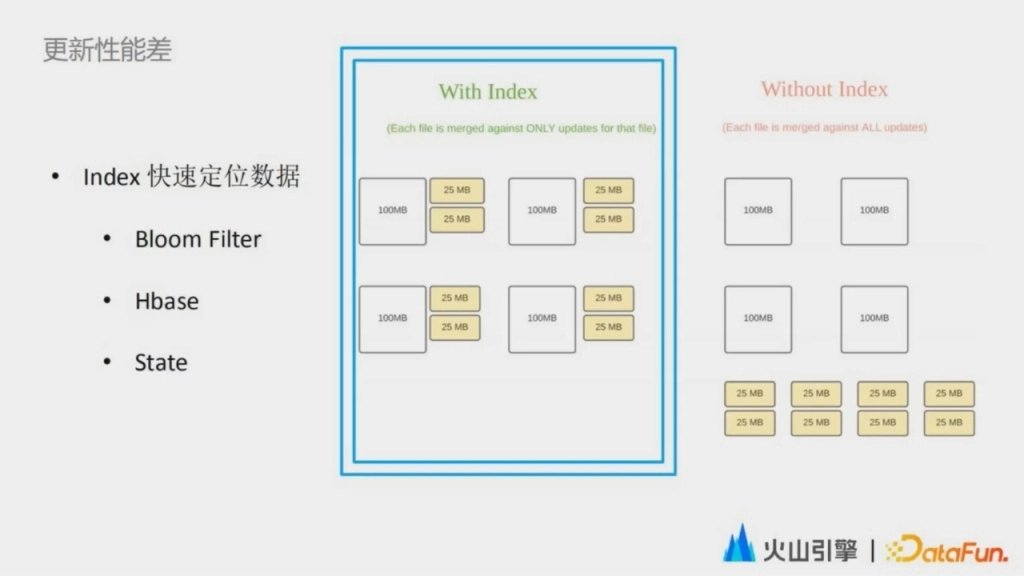
在早期的落地過程當中,我們嘗試儘可能去復用 Hudi 的一些原生能力,比如 Boom Filter index。但是隨著數據規模的不停增長,當達到了千億的量級之後,upsert 的數據隨著數據量的增長逐漸放緩,到了數千億的量級後,消費的速度甚至趕不上生產者的速度。即使我們去為它擴充了資源,而這時的數據總量其實也只是在 TB 級別。我們分析了每個文件組的大小,發現其實文件組的大小也是一個比較合理的值,基本上是在 0.5g 到 1g 之間。進一步分析,我們發現隨著數據量的增長,新的導入在通過索引定位數據的這一步花費的時間越來越長。
根本原因是 Bloom Filter 存在假陽性,一旦命中假陽性的 case,我們就需要把整個文件組中的主鍵鏈讀取上來,再進一步地去判斷這個數據是否已經存在。通過這種方式來區分這個到底是 update 還是 insert。upsert 本身就是 update 和 insert 兩個操作的結合,如果發現相同組件數據不存在,就進行 insert。如果存在,我們就進行 update。而 Bloom Filter 由於假陽性的存在,只能加速數據的 insert 而沒有辦法去加速 update。這就和我們觀察到的現象很一致。因為這個 pipeline 在運行初期,大部分數據都是第一次入湖,是 insert 操作,因此可以被索引加速。但是規模達到一定量級之後,大部分數據都是更新操作,沒有辦法再被索引加速。為瞭解決這個問題,我們急需一個更穩定更高效的索引。
Bloom Filter 索引的問題,根因是讀取歷史數據進行定位,導致定位的時間越來越長。那有沒有什麼辦法是無需讀歷史數據,也可以快速定位到數據所在位置呢?很自然的,我們就想到了類似於 Hive 的 bucket,也就是哈希的方法來解決這個問題。

Bucket Index 原理比較簡單,整個表或者分區就相當於是一張哈希表,文件名中記錄的這個哈希值,就相當於哈希表中這個數組的值。可以根據這個數據中的主鍵哈希值快速地定位到文件組。一個文件組就類似於哈希表中的一個鏈表,可以將數據追加到這個文件組當中。Bucket Index 成功地解決了流式更新性能的問題。由於極低的定位數據的成本,只要設置了一個合適的 bucket 桶大小,就能解決導入性能的問題。將流式更新能覆蓋的場景從 TB 級別擴展到了百 TB 級別。除了導入的性能,Bucket Index 還加速了數據的查詢,其中比較有代表性的就是 bucket Pruning 和 bucket join。
當然這種索引方式我們也遇到了一些擴展性的問題,用戶需要提前一步做桶數的容量規劃,給一個比較安全的值,避免單個桶擴大,以便應對接下來的數據增長。在數據傾斜的場景下,為了讓傾斜值儘可能分散在不同的 bucket,會將 bucket 的數量調到很大。而每個 bucket 平均大小很小,會帶來大量的小文件,給文件系統帶來衝擊的同時也會帶來查詢側性能下滑和寫入側的資源浪費。同時在一線快速增長的業務,很難對容量有一個精準的預估。如果估算少了,數據量飛速增長,單個的 bucket 的平均大小就會很大,這就會導致寫入和查詢的併發度不足,影響性能。如果估算多了,就會和傾斜的場景一樣出現大量的小文件。整體的 rehash 又是一個很重的運維操作,會直接影響業務側對數據的生產和使用。因此不管從業務的易用性出發,還是考慮到資源的使用率和查詢的效率,我們認為兼具高效導入和查詢性能,也能支持彈性擴展的索引系統是一個重要的方向。
這時我們就想到了可擴展 hash 這個數據結構。利用這個結構,我們可以很自然地去做桶的分裂和合併,讓整個 bucket 的索引從手動駕駛進化到自動駕駛。 在數據寫入的時候,我們也可以快速地根據現有的總數,推斷出最深的有效哈希值的長度,通過不斷地對 2 的桶深度次方進行取餘的方式,匹配到最接近的分桶寫入。我們將 Bucket Index 這個索引貢獻到了社區,已在 Hudi 的 0.11 版本對外發佈。
- 日誌難入湖
本質原因也是因為 Hudi 的索引系統。因為這個索引系統要求數據按照組件聚集,一個最簡單的方式就是把這個組件設成 UUID。但這樣就會帶來性能上的問題以及資源上的浪費。因此我們在 Hudi 之內實現了一套新的機制,我們認為是無索引。就是繞過 Hudi 的索引機制,去做到數據的實時入湖。同時因為沒有主鍵, Upsert 的能力也失效了。我們提供了用更通用的 update 能力,通過 shuffle hash join 和 broadcast join 去完數據實時更新。
實時數據湖在位元組內部的一些實踐案例
接下來詳細介紹實時數據湖在位元組的實踐場景。電商是位元組發展非常快速的業務之一,數據增長非常快,這也對數倉的建設提出了較高的要求。目前電商業務數據還是典型的 lambda 架構,分為是離線數倉和實時數倉建設。在實際場景中, lambda 架構的問題相信大家都已經比較瞭解了,我就不多做贅述了。這次的場景介紹是圍繞一個主題,通過數據湖來構建實時數倉,使實時數據湖切入到實時數倉的建設當中。這不是一蹴而就的,是分階段一步一步滲透到實時數倉的建設當中。而實時數據湖的終極目標也是在存儲側形成一個真正意義上的批流一體的架構。
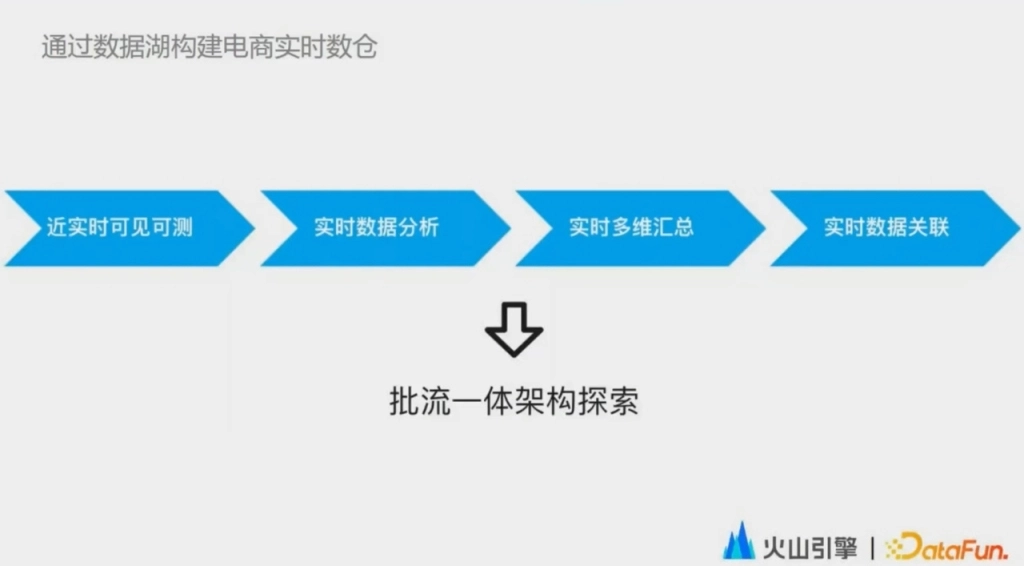
我們切入的第一個階段是實時數據的近實時可見可測。坦白說,在實時數據湖的落地初期,對於數據湖是否能在實時數倉中真正勝任,大家都是存疑的。因此最早的切入點也比較保守,用在數據的驗證環節。在電商的實時數倉中,由於業務發展快,上游系統變更,以及數據產品需求都非常多。導致實時數倉開發周期短,上線變更頻繁。當前這個實時的數據的新增欄位和指標邏輯變更,或者在任務重構優化時,都要對新版本的作業生成的指標進行驗證。驗證的目標主要有兩點,一是原有指標,數據是否一致,二是新增指標的數據是否合理。
在採用數據湖的方案之前,數據湖的驗證環節需要將結果導入到 Kafka 然後再 dump 到 Hive。進行全量數據校驗。這裡存在的一個問題就是數據無法實時或者近實時可見可檢的,基本上都是一個小時級的延遲。在很多緊急上線的場景下,因為延時的問題,只能去抽測數據進行測試驗證,就會影響數據質量。實時數據湖的方案,是通過將實時數據低成本的增量導入到數據湖中,然後通過 Presto 進行查詢,然後進行實時計算彙總,計算的結果做到近實時的全面的可見可測。
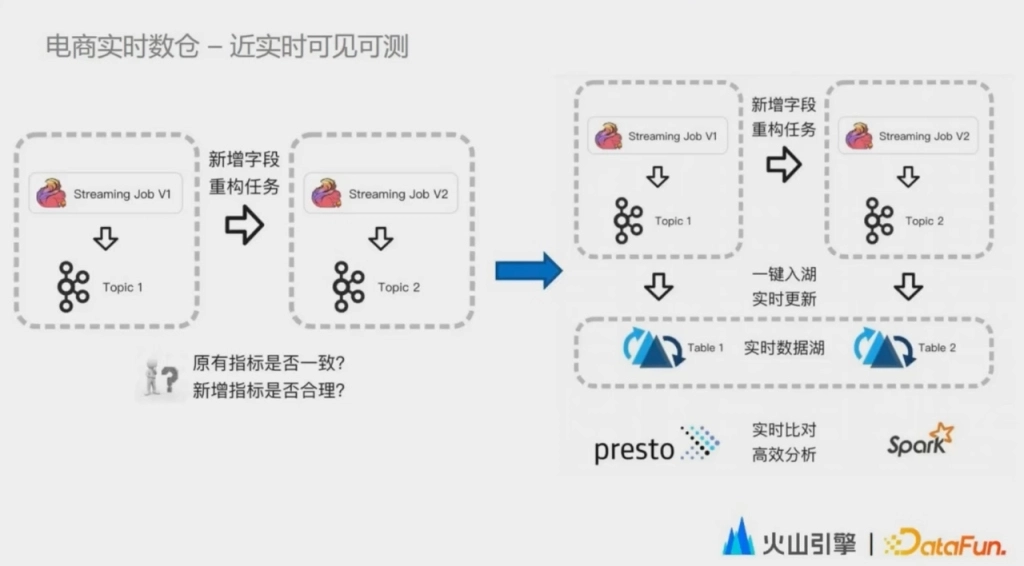
當然在這個階段中,我們也暴露出了很多數據湖上易用性的問題。業務側的同學反饋最多的問題就是數據湖的配置過於複雜。比如要寫一個數據湖的任務,Hudi 自身就存在十多個參數需要在寫入任務中配置。這增加了業務側同學的學習成本和引擎側同學的解釋成本。同時還需要在 Flink SQL 里定義一個 sync table 的 DDL,寫一個完整的 schema。很容易會因為頁的順序或者拼寫錯誤導致任務失敗。
我們藉助了 Hudi Metastore Server 的能力,封裝了大量的參數。同時使用 Flink Catalog 的能力,對 Meta Server 進一步封裝,讓用戶在配置一個 Fink SQL 任務的時候,從最初的寫 DDL 配置十多個參數,到現在只要寫一條 create table like 的語句,配置一張臨時表,用戶對這種方式的接受度普遍是比較高的。
第二個階段,也就是第二個應用場景是數據的實時入湖和實時分析。數據湖可以同時滿足高效的實時數據增量導入和互動式分析的需求,讓數據分析師可以自助地去搭建看板,同時也可以進行低成本的數據回刷,真正做到一份數據批流兩種使用方式。在這個階段,由於數據實際上已經開始生產了,用戶對於數據入湖的穩定性和查詢性能都有很高的要求。我們通過將 Compaction 任務與實時導入任務拆分,首先解決了資源搶占導致的入湖時效性比較低的問題,同時設計了 compaction service,負責 compaction 任務的調度,整個過程對業務側同學完全屏蔽。我們在服務層面也對報警和監控進行了加強,能夠做到先於業務去發現問題,處理問題,進一步提升了任務的穩定性,也讓我們的使用方能夠更有信心地去使用實時數據湖。
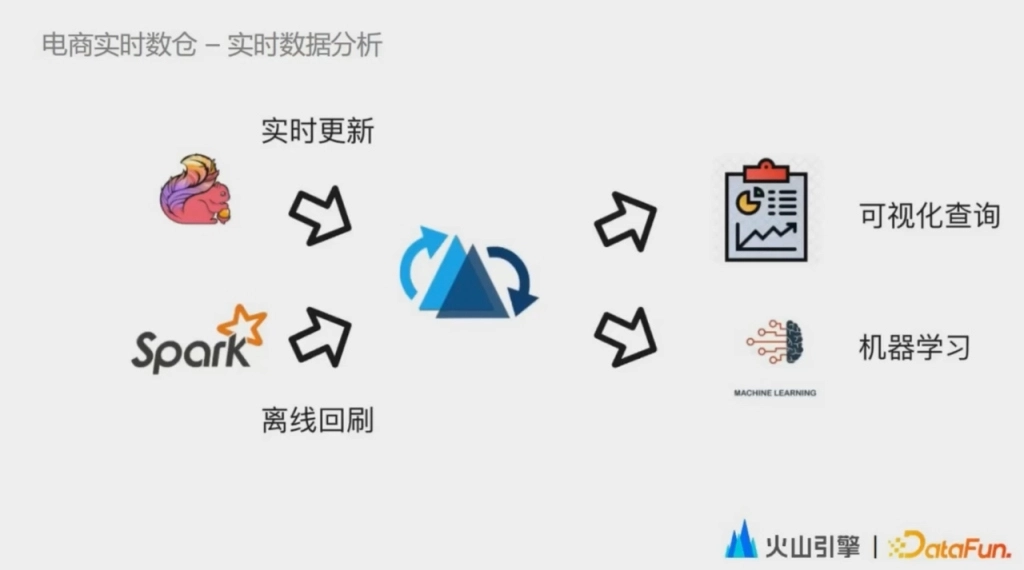
在查詢的優化上面,我們優化了讀文件系統的長尾問題,支持了實時表的列裁剪。同時我們對 Avro 日誌進行了短序列化和序列化的 case by case 的優化,還引入了列存的 log 進一步提升查詢性能。除了實時數據分析之外,這種能力還可以用於機器學習。在特征過程當中,有些 label 是可以快速地從日誌中實時獲取到的。比如對一個視頻點了個贊,和特征是可以關聯上的。而有些 label 的生成則是長周期的。比如在抖音上買了一個東西,或者把一個東西加入購物車,到最後的購買,這整個鏈路是很長的,可能涉及到天級別或者周級別的一個不定周期。但是在這兩種情況下,它的特征數據基本上都是相同的,這也使底層的存儲有了批流兩種使用方式的訴求,以往都是通過冗餘的存儲和計算來解決的。通過數據湖可以將短周期的特征和標簽實時地入湖,長周期的每天做一次調度,做一個批式入湖,真正能做到一份數據去適用多個模型。
第三個階段的應用場景是數據的實時多維彙總。在這個階短最重要的目標是實時數據的普惠。因為很多的實時數據使用方都是通過可視化查詢或者是數據服務去消費一個特定的彙總數據。而這些重度彙總過後的實時數據使用率相對來說是比較低的。因此我們和數倉的同學共同推進了一個實時多維彙總的方案落地。數倉的同學通過實時計算引擎完成數據的多維度的輕度彙總,並且實時地更新入湖。下游可以靈活地按需獲取重度彙總的數據,這種方式可以縮短數據鏈路,提升研發效能。
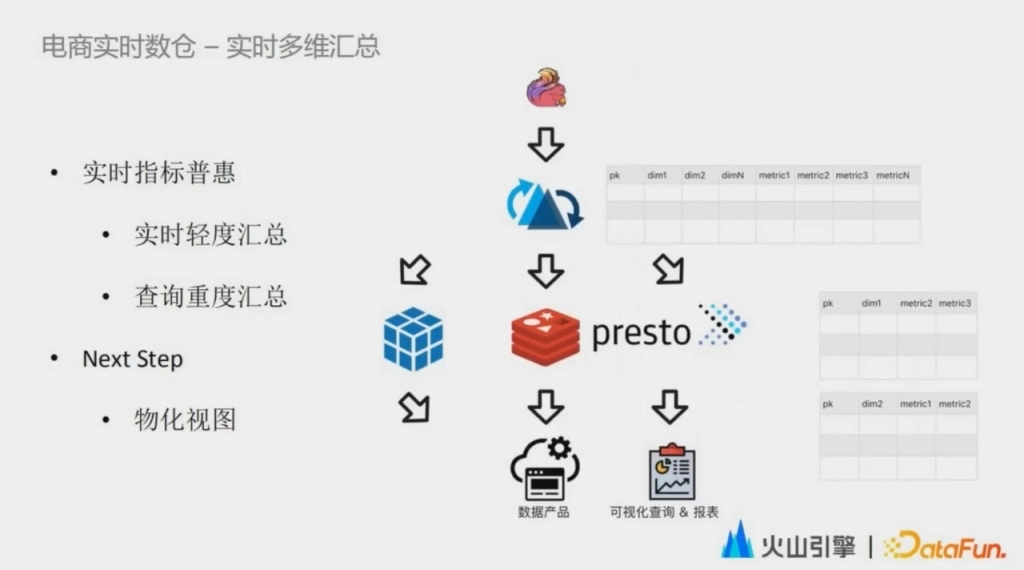
在實際的業務場景中,對於不同的業務訴求,又可以細分成三個不同的子場景。第一個場景是內部用戶的可視化查詢和報表這一類場景。它的特點就是查詢頻率不高,但是維度和指標的組合靈活,同時用戶也能容忍數秒的延遲。在這種場景下,上層的數據應用直接調用底層的 Presto 引擎行為實時入庫的數據進行多維度的重度聚合之後,再做展現。另外一個主要的場景就是面向線上的數據產品,這種場景對高查詢頻率、低查詢延遲的訴求比較高,但是對數據可見性的要求反而不那麼高。而且經過重度彙總的數據量也比較小,這就對數據分析工具提出了比較大的挑戰。因此在當前階段,我們通過增加了一個預計算鏈路來解決。
下麵一個問題,多維重度彙總的多維計算結果是從我們湖裡批量讀出來,然後定時地去寫入 KV 存儲,由存儲去直接對接數據產品。從長期來看,我們下一步計劃就是對實時數據湖之上的表去進行自動地構建物化視圖,並且載入進緩存,以此來兼顧靈活性和查詢性能,讓用戶在享受這種低運維成本的同時,又能滿足低延低查詢延遲、高查詢頻率和靈活使用的訴求。
第四個典型的場景是實時數據關聯,數據的關聯在數倉中是一個非常基礎的訴求。數倉的同學需要將多個流的指標和維度列進行關聯,形成一張寬表。但是使用維表 join,尤其是通過緩存加速的方式,數據準確性往往很難保障。而使用多流 join 的方式又需要維持一個大狀態,尤其是對於一些關聯周期不太確定的場景,穩定性和準確性之間往往很難取捨。
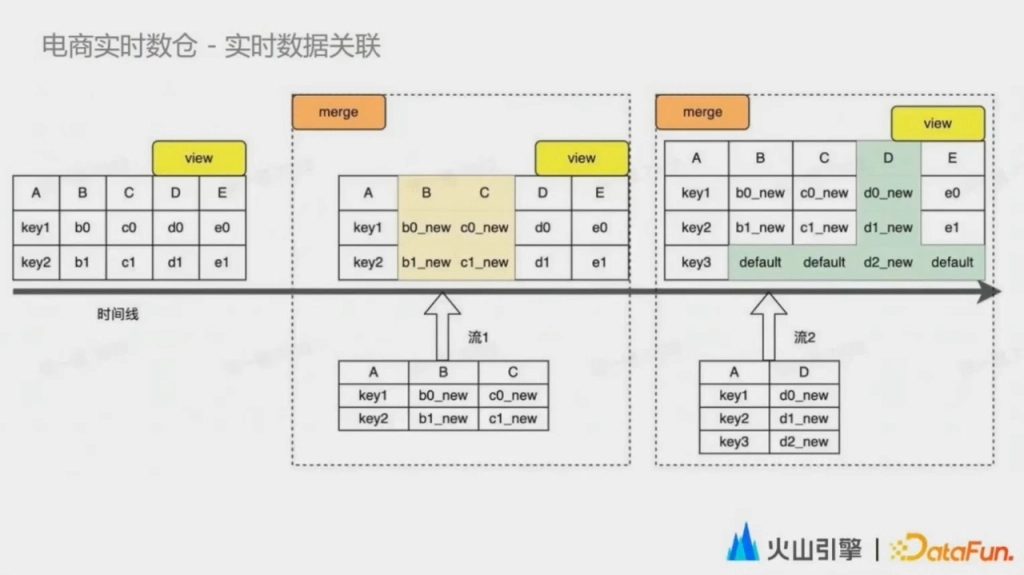
基於以上背景,我們的實時數據湖方案通過了這個列級的併發寫入和確定性的索引。我們支持多個流式任務併發地去寫入同一張表中,每個任務只寫表中的部分列。數據寫入的 log 件在物理上其實是隔離的,每個 log 文件當中也只包含了寬表中的部分列,實際上不會產生互相影響。再非同步地通過 compaction 任務定期的對之前對 log 數據進行合併,在這個階段對數據進行真正的實際的關聯操作。通過這種方式,提供一個比較穩定的性能。使用這一套方案,實時關聯用戶也不用再關註狀態大小和 TTL 該如何設置這個問題了,寬表的數據也可以做到實時可查。
最後一個階段。我們認為是實時數據湖的終極階段,目前仍在探索中。我們只在部分場景開啟了驗證。在這個架構裡面,數據可以從外部的不同數據源中實時或者批量的入湖和出湖,而流批作業完成湖內的數據實時流轉,形成真正意義上的存儲層批流一體。
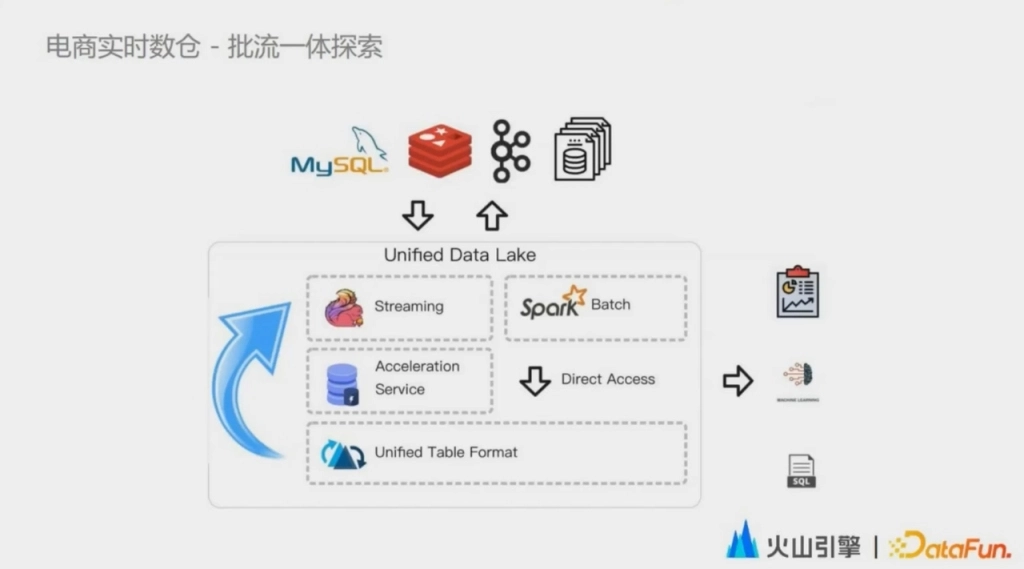
同時在這套架構中,為瞭解決實時數據湖從分鐘級到秒級的最後一公裡,我們在實時引擎與數據湖的表之間增加了一層數據加速服務。在這層數據加速服務之上,多個實時作業可以做到秒級的數據流轉。而這個服務也會解決頻繁流式寫入頻繁提交導致的小文件問題,為實時數據的交互查詢進一步提速。除此之外,由於流批作業的特性不同,批計算往往會需要更高的瞬時吞吐。因此這些批計算任務也可以直接地去讀寫底層的池化文件系統,來做到極強的擴展性,真正意義上做到批流寫入的隔離,批作業的寫入不會受限於加速服務的帶寬。在這個批流一體的架構中,數據湖之上的用戶,不管是 SQL 查詢,還是 BI 、AI ,都可以通過一個統一的 table format 享受到數據湖之上數據的開放性。
數據湖發展的一些規劃
最後來看一下未來規劃。主要聚焦於三個維度:功能層面的規劃,開源層面的規劃,以及商業化輸出相關的一些規劃。
- 功能層面
首先是功能維度,我們認為一個更智能的實時數據湖的加速系統是我們最重要的目標之一。

首先是元數據層面的加速,數據湖托管了文件級別的元數據,元數據的數據量,相比數倉有了幾個量級的增長,但同時也給我們帶來了一些優化的機會。比如我們未來計劃將查詢的謂詞直接下推到元數據系統當中,讓這個引擎在 scan 階段無需訪問系統,直接去跳過無效文件來提升查詢的性能。
其次就是數據的加速。當前的實時數據湖由於其 serverless 架構對文件系統的重度依賴,在生產實踐中還是處於分鐘級,秒級依舊處於驗證階段。那我們接下來計劃將這個數據湖加速服務不斷地去打磨成熟,用來做實時數據的交換和熱數據的存儲,以解決分鐘級到秒級的最後一公裡問題。智能加速層面臨的最大的挑戰是批流數據寫入的一致性問題,這也是我們接下來重點要解決的問題。例如在這種端到端的實時生產鏈路中,如何在提供秒級延時的前提下解決類似於跨表事務的問題。
第三是索引加速。通過 bucket, zorder 等一系列的主鍵索引,來進一步地提升數據湖之上的數據的查詢性能,過濾掉大量的原始數據,避免無效的數據交換。同時我們接下來也會非常註重二級索引的支持,因為二級索引的支持可以延伸湖上數據的更新能力,從而去加速非主線更新的效率。
第四是智能優化。我們接下來會通過一套表優化服務來實現智能優化,因為對於兩個類似的查詢能否去提供一個穩定的查詢性能,表的數據分佈是一個關鍵因素。而從用戶的角度來看,用戶只要查詢快、寫入快,像類似於 compaction 或 clustering、索引構建等一系列的表優化的方式,只會提升用戶的使用門檻。而我們的計劃是通過一個智能的表優化服務分析用戶的查詢特征,去同時監聽這個數據湖上數據的變化,自適應的去觸發這個表的一系列的優化操作,可以做到在用戶不需要瞭解過多細節的情況下,做到智能的互加速。
2. 開源層面
第二個維度是開源貢獻。我們現在一直在積極地投入到 Hudi 的社區貢獻當中。參與了多個 Hudi 的核心 feature 的開發和設計。其中 Bucket index 是我們合入到社區的第一個核心功能,而當下我們也在同時貢獻著多個重要的功能,比如最早提到的解決數據難管理的 Hudi MetaStore Server,我們已經貢獻到社區了,去普惠到開源社區。因為我們發現 Hudi MetaStore Server 不止解決我們在生產實踐中遇到的問題,也是業界普遍遇到的一個問題。現在也在跟 Hudi 社區的 PMC 共同探討數據湖的元數據管理系統制定標準。
其它一些功能我們也計劃分兩個階段貢獻到社區。比如 RPC 42,將我們的湖表管理服務與大家共用,長期來看能夠做到數據湖上的表的自動優化。還有 Trino 和 Presto DB 的 Hudi Connector,目前也是在和 Hudi 背後的生態公司共同推進投入到開源社區當中。
(3)商業化輸出
當前在火山引擎之上,我們將內部的數據湖技術實踐同時通過LAS和EMR這兩個產品向外部企業輸出。其中 LAS 湖倉一體分析服務是一個整體面向湖倉一體架構的 Serverless 數據處理分析服務,提供一站式的海量數據存儲計算和交互分析能力,完全地去相容 Spark、Presto 和 Flink 生態。同時這個產品具備了完整的位元組內部的實時數據湖的成熟能力,能夠幫助企業輕鬆完成湖倉的構建和數據價值的洞察。
另外一個產品 EMR 是一個 Stateless 的雲原生數倉,100%開源相容,在這個產品當中也會包含位元組數據湖實踐中一些開源相容的優化,以及一些引擎的企業級增強,以及雲上便捷的運維能力。
最後,歡迎大家關註位元組跳動數據平臺公眾號,在這裡有非常多的技術乾貨、產品動態和招聘信息。
立即跳轉瞭解:火山引擎LAS或 火山引擎EMR 產品

