
寫在前面 某音作為風靡中外的一款音樂創意短視頻社交軟體,其成功性不言而喻,一直聽說其強大的“威力”,但卻從沒深入研究過,作為人民的先鋒隊,這怎麼行,毅然決然的我,在上周五註冊了一個賬號,但沒想到的是等待我的確是一條不歸路~(以下內容純屬個人經歷與個人看法,沒有任何代表性,圖一樂呵兒) 一個視頻在發出 ...
寫在前面
某音作為風靡中外的一款音樂創意短視頻社交軟體,其成功性不言而喻,一直聽說其強大的“威力”,但卻從沒深入研究過,作為人民的先鋒隊,這怎麼行,毅然決然的我,在上周五註冊了一個賬號,但沒想到的是等待我的確是一條不歸路~(以下內容純屬個人經歷與個人看法,沒有任何代表性,圖一樂呵兒)
一個視頻在發出後要面臨什麼?
初入抖音的我很快就被它背後神奇的推薦演算法,引流手段,DOU+上熱門計劃深深的吸引住了。
抱著試試看的態度,我嘗試發了我第一個視頻。在發之前我也是四處取經,怎麼寫文案,怎麼配背景音樂,怎麼找和文案有呼應的視頻和照片。
最後在我高超的視頻剪輯技術之下(也就廢了刷五六道演算法題的時間),終於把它發出去了。
瞭解到,抖音平臺對每一個視頻是有系統推薦的基礎流量的(這裡考慮到新用戶首個視頻的特殊性,這裡從第二個視頻開始分析)。

短視頻發佈後抖音一般會進行的一系列推薦流程。
如果從技術層面去分析的話,那是相當複雜的,涉及很多數學層面的知識,但我始終相信,一切知識都是簡潔的。
所以我們何不以問題為導向,如果說你是某一鳴,可能的未來首富,你會如何去留住某音平臺的創作者與用戶們?
打分演算法
在我把我的這個視頻發出去之後,就開始了焦急的等待,人嘛,嘴上說著我不在乎,其實心裡都希望獲得一種認同感的。
看到有人觀看點贊自己的作品,心裡不開心是假的,真正做到寵辱不驚,不以物喜不以己悲,那也是看得多了,習慣了而已。
很快,距離我發佈這個作品馬上到一個小時了,但觀看數據仍然是沒有什麼變化的,大約在1~2個小時之後,數據出現斷崖式的增長,這說明平臺開始給你引流了。

而這一套引流的機制,要看四個標準:點贊量、評論量、轉發量、完播率。
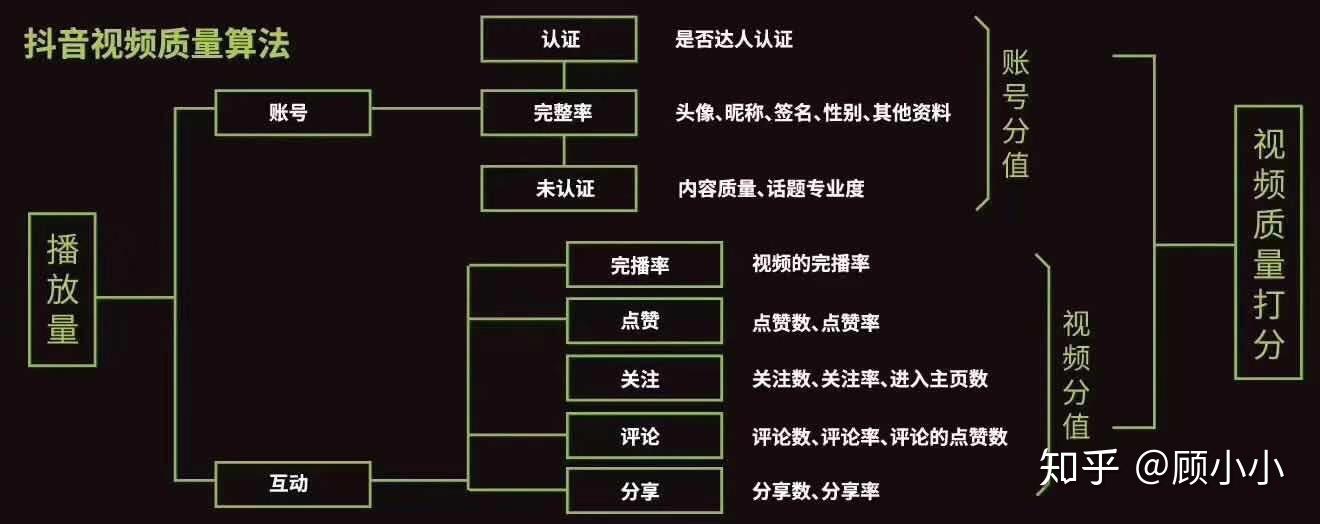
也就是在這個階段你作品的質量就會打上一個又一個的標簽,最後得到一個綜合得分,來決定該作品的曝光率,而且這種曝光是層層遞進的,上個階段的總分決定你下個階段的曝光率,當然如果你在第一個階段的效果就不行,那也就不需要第二階段了。
即播放量=A×完播率+B×點贊率+C×評論率+D×轉發率
看了我視頻的播放量,原來我連第一階段都算不上,這可太慘了。
這一兩百的播放,還是我冒著被圍觀社死的風險,分享到了我那些相親相愛的一家人的群里,結果,果然被圍觀了。(不過,也讓我明白一個道理,這世界上能永遠無私對你好的只有你的父母,他們會在你的每一個作品下點贊,贊美天下父母)。

DOU+上播放量
如果說,要我說誰是這個世界上最大的大怨種,那這個人就是我(我自以為)。
來到這世上二十幾載歲月,從沒有讓任何一個平臺從我身上割下一把韭菜的我,被割了一把。

看到這個作品鶴立雞群的播放量沒,這是我花了30大洋送上去的。

結果投放質量不好,還被嘲諷了一波,也是屬實扎心了。
推薦系統
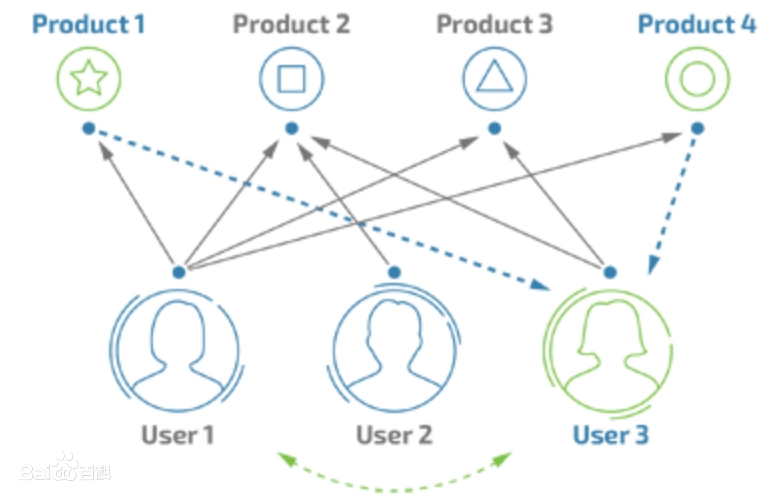
系統先識別出你想看的內容,讀懂我們的需求,然後在內容池裡匹配你想看的內容,最後展示出來,也就是千人千面,目前很多軟體都能做到千人千面。接下來進入正題,瞭解抖音的推薦系統,主要包括三部分:用戶畫像、內容畫像、用戶和內容之間的匹配。
1)用戶畫像,系統根據用戶基本屬性(比如:性別、年齡、學歷等)、興趣愛好(比如:科技、娛樂、體育、金融等)等數據集,然後給肪定義相關的標簽。
2)內容畫像,系統根據內容的層級分類、關鍵詞、實體詞等分析出特點,給各類內容打上相關的標簽。
3)用戶與內容匹配,有了用戶標簽和內容標簽之後,系統根據用戶畫像、內容畫像,在內容池裡面匹配出用戶喜歡的內容然後展示出來。
4)排序,系統要面對數億級的用戶和內容,同時還要考慮用戶的喜歡會不斷的發生改變,為了讓挑選的內容更加的貼近用戶想要的、更加符合用戶喜歡,系統需要對內容進行排序。
推薦演算法
我們的日常生活現在已經被各種推薦演算法包圍了,不只是某音,還有某條,某團,某了麽,甚至我們學校的一些APP都可以根據你常用的功能,推薦相應的信息。
但是對於我們這些非專業人士,能從這些推薦演算法中得到什麼呢?
百度百科:推薦演算法是電腦專業中的一種演算法,通過一些數學演算法,推測出用戶可能喜歡的東西,應用推薦演算法比較好的地方主要是網路。所謂推薦演算法就是利用用戶的一些行為,通過一些數學演算法,推測出用戶可能喜歡的東西
起源
如果說非要給推薦演算法找一個老祖宗,那就不得不提上世紀九十年代,一群美國明尼蘇達大學的大學生,他們本意是想製作一個名為Movielens的電影推薦系統,從而實現對用戶進行電影的個性化推薦。
但令他們沒想到的是,這一舉動,讓這個網站的銷售額提高了35%。
有利益的地方就會有資本的進入,在資本的驅動下,這項還很年輕的技術開始了快速的發展,個性化推薦的應用也越來越廣泛。
五種常見推薦演算法
基於內容的推薦、協同過濾推薦、基於關聯規則的推薦、基於知識的推薦、混合推薦。
1.基於內容的推薦
基於內容的推薦(Content-based Recommendation)是信息過濾技術的延續與發展,它是建立在項目的內容信息上做出推薦的,而不需要依據用戶對項目的評價意見,更多地需要用機器學習的方法從關於內容的特征描述的事例中得到用戶的興趣資料。
也就是說這種演算法是從供給側上分析,只管視頻內容,不管你用戶怎麼看怎麼評價。
2.協同過濾演算法
基於協同過濾的推薦演算法(Collaborative Filtering Recommendation)技術是推薦系統中應用最早和最為成功的技術之一。它一般採用最近鄰技術,利用用戶的歷史喜好信息計算用戶之間的距離,然後利用目標用戶的最近鄰居用戶對商品評價的加權評價值來預測目標用戶對特定商品的喜好程度,從而根據這一喜好程度來對目標用戶進行推薦。

該演算法是誕生最早,並且較為著名的推薦演算法,主要的功能是預測和推薦。
說白了,就是把人分成不同的興趣小組,把作品貼上相應的興趣標簽,在推給對應的小組。
3.基於關聯規則的推薦
基於關聯規則的推薦(Association Rule-based Recommendation)是以關聯規則為基礎,把已購商品作為規則頭,規則體為推薦對象。關聯規則挖掘可以發現不同商品在銷售過程中的相關性,在零售業中已經得到了成功的應用。
關聯規則就是在一個交易資料庫中統計購買了商品集X的交易中有多大比例的交易同時購買了商品集y。
其直觀的意義就是用戶在購買某些商品的時候有多大傾向去購買另外一些商品。比如購買牛奶的同時很多人會購買麵包。
4.基於知識的推薦
基於知識的推薦(Knowledge-based Recommendation)在某種程度是可以看成是一種推理(Inference)技術,它不是建立在用戶需要和偏好基礎上推薦的。
比如說,你在平臺上的用戶資料就可以是任何能支持推理的知識結構,它可以是用戶已經規範化的查詢,也可以是一個更詳細的用戶需要的表示
5.混合推薦
混合推薦即將上面的4種演算法組合應用,充分利用各個演算法的優點解決現實的問題。
一個簡單的推薦演算法實例
網上這種例子很多,這裡給大家找了一個。
python實現協同過濾推薦演算法完整代碼示例: https://www.jb51.net/article/130674.htm
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from numpy import *
import time
from texttable import Texttable
class CF:
def __init__(self, movies, ratings, k=5, n=10):
self.movies = movies
self.ratings = ratings
# 鄰居個數
self.k = k
# 推薦個數
self.n = n
# 用戶對電影的評分
# 數據格式{'UserID:用戶ID':[(MovieID:電影ID,Rating:用戶對電影的評星)]}
self.userDict = {}
# 對某電影評分的用戶
# 數據格式:{'MovieID:電影ID',[UserID:用戶ID]}
# {'1',[1,2,3..],...}
self.ItemUser = {}
# 鄰居的信息
self.neighbors = []
# 推薦列表
self.recommandList = []
self.cost = 0.0
# 基於用戶的推薦
# 根據對電影的評分計算用戶之間的相似度
def recommendByUser(self, userId):
self.formatRate()
# 推薦個數 等於 本身評分電影個數,用戶計算準確率
self.n = len(self.userDict[userId])
self.getNearestNeighbor(userId)
self.getrecommandList(userId)
self.getPrecision(userId)
# 獲取推薦列表
def getrecommandList(self, userId):
self.recommandList = []
# 建立推薦字典
recommandDict = {}
for neighbor in self.neighbors:
movies = self.userDict[neighbor[1]]
for movie in movies:
if(movie[0] in recommandDict):
recommandDict[movie[0]] += neighbor[0]
else:
recommandDict[movie[0]] = neighbor[0]
# 建立推薦列表
for key in recommandDict:
self.recommandList.append([recommandDict[key], key])
self.recommandList.sort(reverse=True)
self.recommandList = self.recommandList[:self.n]
# 將ratings轉換為userDict和ItemUser
def formatRate(self):
self.userDict = {}
self.ItemUser = {}
for i in self.ratings:
# 評分最高為5 除以5 進行數據歸一化
temp = (i[1], float(i[2]) / 5)
# 計算userDict {'1':[(1,5),(2,5)...],'2':[...]...}
if(i[0] in self.userDict):
self.userDict[i[0]].append(temp)
else:
self.userDict[i[0]] = [temp]
# 計算ItemUser {'1',[1,2,3..],...}
if(i[1] in self.ItemUser):
self.ItemUser[i[1]].append(i[0])
else:
self.ItemUser[i[1]] = [i[0]]
# 找到某用戶的相鄰用戶
def getNearestNeighbor(self, userId):
neighbors = []
self.neighbors = []
# 獲取userId評分的電影都有那些用戶也評過分
for i in self.userDict[userId]:
for j in self.ItemUser[i[0]]:
if(j != userId and j not in neighbors):
neighbors.append(j)
# 計算這些用戶與userId的相似度併排序
for i in neighbors:
dist = self.getCost(userId, i)
self.neighbors.append([dist, i])
# 排序預設是升序,reverse=True表示降序
self.neighbors.sort(reverse=True)
self.neighbors = self.neighbors[:self.k]
# 格式化userDict數據
def formatuserDict(self, userId, l):
user = {}
for i in self.userDict[userId]:
user[i[0]] = [i[1], 0]
for j in self.userDict[l]:
if(j[0] not in user):
user[j[0]] = [0, j[1]]
else:
user[j[0]][1] = j[1]
return user
# 計算餘弦距離
def getCost(self, userId, l):
# 獲取用戶userId和l評分電影的並集
# {'電影ID':[userId的評分,l的評分]} 沒有評分為0
user = self.formatuserDict(userId, l)
x = 0.0
y = 0.0
z = 0.0
for k, v in user.items():
x += float(v[0]) * float(v[0])
y += float(v[1]) * float(v[1])
z += float(v[0]) * float(v[1])
if(z == 0.0):
return 0
return z / sqrt(x * y)
# 推薦的準確率
def getPrecision(self, userId):
user = [i[0] for i in self.userDict[userId]]
recommand = [i[1] for i in self.recommandList]
count = 0.0
if(len(user) >= len(recommand)):
for i in recommand:
if(i in user):
count += 1.0
self.cost = count / len(recommand)
else:
for i in user:
if(i in recommand):
count += 1.0
self.cost = count / len(user)
# 顯示推薦列表
def showTable(self):
neighbors_id = [i[1] for i in self.neighbors]
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(["t", "t", "t", "t"])
table.set_cols_align(["l", "l", "l", "l"])
rows = []
rows.append([u"movie ID", u"Name", u"release", u"from userID"])
for item in self.recommandList:
fromID = []
for i in self.movies:
if i[0] == item[1]:
movie = i
break
for i in self.ItemUser[item[1]]:
if i in neighbors_id:
fromID.append(i)
movie.append(fromID)
rows.append(movie)
table.add_rows(rows)
print(table.draw())
# 獲取數據
def readFile(filename):
files = open(filename, "r", encoding="utf-8")
# 如果讀取不成功試一下
# files = open(filename, "r", encoding="iso-8859-15")
data = []
for line in files.readlines():
item = line.strip().split("::")
data.append(item)
return data
# -------------------------開始-------------------------------
start = time.clock()
movies = readFile("/home/hadoop/Python/CF/movies.dat")
ratings = readFile("/home/hadoop/Python/CF/ratings.dat")
demo = CF(movies, ratings, k=20)
demo.recommendByUser("100")
print("推薦列表為:")
demo.showTable()
print("處理的數據為%d條" % (len(demo.ratings)))
print("準確率: %.2f %%" % (demo.cost * 100))
end = time.clock()
print("耗費時間: %f s" % (end - start))
主要任務
1、初始化數據
獲取movies和ratings,轉換成數據userDict表示某個用戶的所有電影的評分集合,並對評分除以5進行歸一化,轉換成數據ItemUser表示某部電影參與評分的所有用戶集合
2、計算所有用戶與userId的相似度
找出所有觀看電影與userId有交集的用戶,對這些用戶迴圈計算與userId的相似度,獲取A用戶與userId的並集。格式為:{'電影ID',[A用戶的評分,userId的評分]},沒有評分記為0,計算A用戶與userId的餘弦距離,越大越相似
3、根據相似度生成推薦電影列表
4、輸出推薦列表和準確率
寫在最後
記得前段時間社會上曾出現過關於推薦系統究竟是服務了我們生活,還是限制了我們的生活的大討論。
2021年8月27日,國家互聯網信息辦公室發佈了關於《互聯網信息服務演算法推薦管理規定(征求意見稿)》公開征求意見的通知。其中第十五條規定:
演算法推薦服務提供者應當向用戶提供不針對其個人特征的選項,或者向用戶提供便捷的關閉演算法推薦服務的選項。用戶選擇關閉演算法推薦服務的,演算法推薦服務提供者應當立即停止提供相關服務。 演算法推薦服務提供者應當向用戶提供選擇、修改或者刪除用於演算法推薦服務的用戶標簽的功能。
更是引發了人們對推薦演算法這一技術的關註。
就像哈佛大學教授桑斯坦(Cass R. Sunstein)在2006年出版的《信息烏托邦》(Infotopia)一書中提出的信息繭房(Information Cocoon)這一概念:
當個體只關註自我選擇的或能夠愉悅自身的內容,而減少對其他信息的接觸,久而久之,便會像蠶一樣逐漸禁錮於自我編織的“繭房”之中。

我們知道這是陷阱,這是牢籠,但仍會跨入其中。很難去講這些對對錯錯,我們確實在享受它帶來的便利,又被它深深套牢。
但有一點是無可厚非的:技術本身是沒有對錯而言的,關鍵在用這項技術的人或團體,有力量的武器應該在更嚴格的監督制度中。
好了,以上便是這次的所有內容了。
遲來的端午祝福送給大家:

(不說了,剪視頻去了,趁著周六周日,把下周的要發的內容全剪完)
參考文獻:
漫畫來源 小林漫畫
http://t.csdn.cn/xxe7C
http://t.csdn.cn/XEG1j
http://t.csdn.cn/J4VR7
https://juejin.cn/post/7020246064955392013
https://www.zhihu.com/question/270224768/answer/1542280267
https://zhan-bin.github.io/2018/10/14/5種常用的推薦系統演算法/
https://baike.baidu.com/item/推薦演算法/6560536


