
場景說明 現有一個 10G 文件的數據,裡面包含了 18-70 之間的整數,分別表示 18-70 歲的人群數量統計,假設年齡範圍分佈均勻,分別表示系統中所有用戶的年齡數,找出重覆次數最多的那個數,現有一臺記憶體為 4G、2 核 CPU 的電腦,請寫一個演算法實現。 23,31,42,19,60,30,3 ...
場景說明
現有一個 10G 文件的數據,裡面包含了 18-70 之間的整數,分別表示 18-70 歲的人群數量統計,假設年齡範圍分佈均勻,分別表示系統中所有用戶的年齡數,找出重覆次數最多的那個數,現有一臺記憶體為 4G、2 核 CPU 的電腦,請寫一個演算法實現。
23,31,42,19,60,30,36,........
模擬數據
Java 中一個整數占 4 個位元組,模擬 10G 為 30 億左右個數據, 採用追加模式寫入 10G 數據到硬碟里。每 100 萬個記錄寫一行,大概 4M 一行,10G 大概 2500 行數據。
package bigdata;
import java.io.*;
import java.util.Random;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:05
*/
public class GenerateData {
private static Random random = new Random();
public static int generateRandomData(int start, int end) {
return random.nextInt(end - start + 1) + start;
}
/**
* 產生10G的 1-1000的數據在D盤
*/
public void generateData() throws IOException {
File file = new File("D:\ User.dat");
if (!file.exists()) {
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
int start = 18;
int end = 70;
long startTime = System.currentTimeMillis();
BufferedWriter bos = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file, true)));
for (long i = 1; i < Integer.MAX_VALUE * 1.7; i++) {
String data = generateRandomData(start, end) + ",";
bos.write(data);
// 每100萬條記錄成一行,100萬條數據大概4M
if (i % 1000000 == 0) {
bos.write("\n");
}
}
System.out.println("寫入完成! 共花費時間:" + (System.currentTimeMillis() - startTime) / 1000 + " s");
bos.close();
}
public static void main(String[] args) {
GenerateData generateData = new GenerateData();
try {
generateData.generateData();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代碼調整參數執行 2 次,湊 10 個 G 的數據在 D 盤的 User.dat 文件里。
準備好 10G 數據後,接著寫如何處理這些數據。
場景分析
10G 的數據比當前擁有的運行記憶體大的多,不能全量載入到記憶體中讀取,如果採用全量載入,那麼記憶體會直接爆掉,只能按行讀取,Java 中的 bufferedReader 的 readLine() 按行讀取文件里的內容。
讀取數據
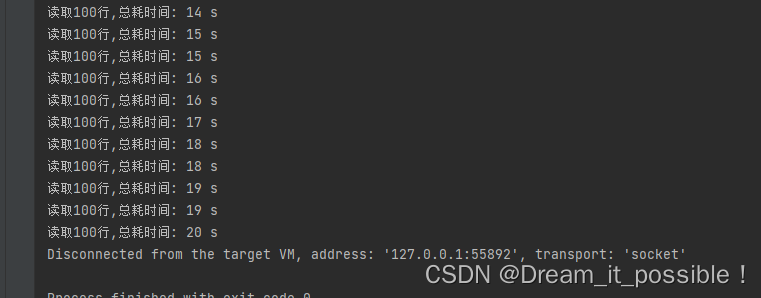
首先我們寫一個方法單線程讀完這 30E 數據需要多少時間,每讀 100 行列印一次:
private static void readData() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null) {
// 按行讀取
// SplitData.splitLine(line);
if (count % 100 == 0) {
System.out.println("讀取100行,總耗時間: " + (System.currentTimeMillis() - start) / 1000 + " s");
System.gc();
}
count++;
}
running = false;
br.close();
}
按行讀完 10G 的數據大概 20 秒,基本每 100 行,1E 多數據花 1S,速度還挺快:
處理數據
| 思路一:通過單線程處理
通過單線程處理,初始化一個 countMap,key 為年齡,value 為出現的次數,將每行讀取到的數據按照 "," 進行分割,然後獲取到的每一項進行保存到 countMap 里,如果存在,那麼值 key 的 value+1。
for (int i = start; i <= end; i++) {
try {
File subFile = new File(dir + "\" + i + ".dat");
if (!file.exists()) {
subFile.createNewFile();
}
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
單線程讀取並統計 countMap:
public static void splitLine(String lineData) {
String[] arr = lineData.split(",");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
countMap.computeIfAbsent(str, s -> new AtomicInteger(0)).getAndIncrement();
}
}
通過比較找出年齡數最多的年齡並列印出來:
private static void findMostAge() {
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext()) {
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue) {
targetValue = value;
targetKey = key;
}
}
System.out.println("數量最多的年齡為:" + targetKey + "數量為:" + targetValue);
}
完整代碼:
package bigdata;
import org.apache.commons.lang3.StringUtils;
import java.io.*;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:19
* 單線程處理
*/
public class HandleMaxRepeatProblem_v0 {
public static final int start = 18;
public static final int end = 70;
public static final String dir = "D:\dataDir";
public static final String FILE_NAME = "D:\ User.dat";
/**
* 統計數量
*/
private static Map<String, AtomicInteger> countMap = new ConcurrentHashMap<>();
/**
* 開啟消費的標誌
*/
private static volatile boolean startConsumer = false;
/**
* 消費者運行保證
*/
private static volatile boolean consumerRunning = true;
/**
* 按照 "," 分割數據,並寫入到countMap里
*/
static class SplitData {
public static void splitLine(String lineData) {
String[] arr = lineData.split(",");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
countMap.computeIfAbsent(str, s -> new AtomicInteger(0)).getAndIncrement();
}
}
}
/**
* init map
*/
static {
File file = new File(dir);
if (!file.exists()) {
file.mkdir();
}
for (int i = start; i <= end; i++) {
try {
File subFile = new File(dir + "\" + i + ".dat");
if (!file.exists()) {
subFile.createNewFile();
}
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new Thread(() -> {
try {
readData();
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
private static void readData() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null) {
// 按行讀取,並向map里寫入數據
SplitData.splitLine(line);
if (count % 100 == 0) {
System.out.println("讀取100行,總耗時間: " + (System.currentTimeMillis() - start) / 1000 + " s");
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
count++;
}
findMostAge();
br.close();
}
private static void findMostAge() {
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext()) {
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue) {
targetValue = value;
targetKey = key;
}
}
System.out.println("數量最多的年齡為:" + targetKey + "數量為:" + targetValue);
}
private static void clearTask() {
// 清理,同時找出出現字元最大的數
findMostAge();
System.exit(-1);
}
}
測試結果:總共花了 3 分鐘讀取完並統計完所有數據。
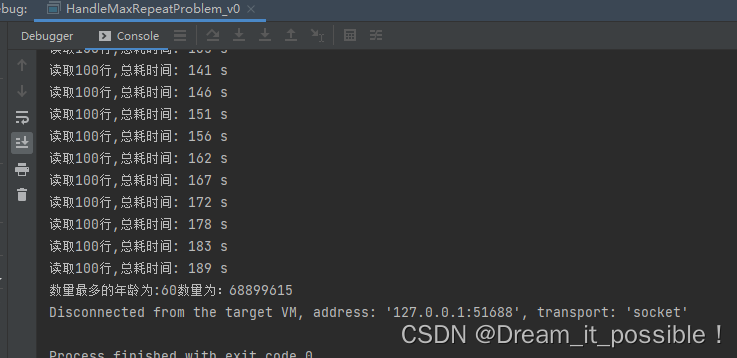
記憶體消耗為 2G-2.5G,CPU 利用率太低,只向上浮動了 20%-25% 之間:
要想提高 CPU 的利用率,那麼可以使用多線程去處理。下麵我們使用多線程去解決這個 CPU 利用率低的問題。
| 思路二:分治法
使用多線程去消費讀取到的數據。採用生產者、消費者模式去消費數據,因為在讀取的時候是比較快的,單線程的數據處理能力比較差,因此思路一的性能阻塞在取數據方,又是同步的,所以導致整個鏈路的性能會變的很差。
所謂分治法就是分而治之,也就是說將海量數據分割處理。根據 CPU 的能力初始化 n 個線程,每一個線程去消費一個隊列,這樣線程在消費的時候不會出現搶占隊列的問題。
同時為了保證線程安全和生產者消費者模式的完整,採用阻塞隊列,Java 中提供了 LinkedBlockingQueue 就是一個阻塞隊列。
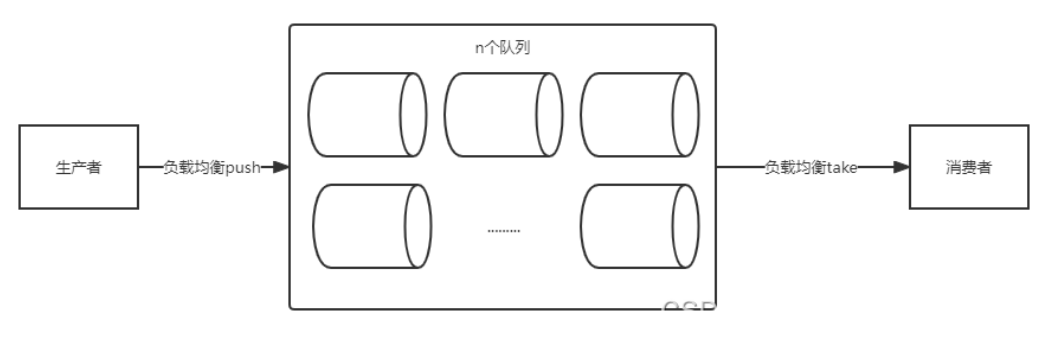
①初始化阻塞隊列
使用 linkedList 創建一個阻塞隊列列表:
private static List<LinkedBlockingQueue<String>> blockQueueLists = new LinkedList<>();
在 static 塊里初始化阻塞隊列的數量和單個阻塞隊列的容量為 256,上面講到了 30E 數據大概 2500 行,按行塞到隊列里,20 個隊列,那麼每個隊列 125 個,因此可以容量可以設計為 256 即可:
//每個隊列容量為256
for (int i = 0; i < threadNums; i++) {
blockQueueLists.add(new LinkedBlockingQueue<>(256));
}
②生產者
為了實現負載的功能, 首先定義一個 count 計數器,用來記錄行數:
private static AtomicLong count = new AtomicLong(0);
按照行數來計算隊列的下標:long index=count.get()%threadNums。
下麵演算法就實現了對隊列列表中的隊列進行輪詢的投放:
static class SplitData {
public static void splitLine(String lineData) {
// System.out.println(lineData.length());
String[] arr = lineData.split("\n");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
long index = count.get() % threadNums;
try {
// 如果滿了就阻塞
blockQueueLists.get((int) index).put(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
count.getAndIncrement();
}
}
③消費者
隊列線程私有化:消費方在啟動線程的時候根據 index 去獲取到指定的隊列,這樣就實現了隊列的線程私有化。
private static void startConsumer() throws FileNotFoundException, UnsupportedEncodingException {
//如果共用一個隊列,那麼線程不宜過多,容易出現搶占現象
System.out.println("開始消費...");
for (int i = 0; i < threadNums; i++) {
final int index = i;
// 每一個線程負責一個queue,這樣不會出現線程搶占隊列的情況。
new Thread(() -> {
while (consumerRunning) {
startConsumer = true;
try {
String str = blockQueueLists.get(index).take();
countNum(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
多子線程分割字元串:由於從隊列中多到的字元串非常的龐大,如果又是用單線程調用 split(",") 去分割,那麼性能同樣會阻塞在這個地方。
// 按照arr的大小,運用多線程分割字元串
private static void countNum(String str) {
int[] arr = new int[2];
arr[1] = str.length() / 3;
// System.out.println("分割的字元串為start位置為:" + arr[0] + ",end位置為:" + arr[1]);
for (int i = 0; i < 3; i++) {
final String innerStr = SplitData.splitStr(str, arr);
// System.out.println("分割的字元串為start位置為:" + arr[0] + ",end位置為:" + arr[1]);
new Thread(() -> {
String[] strArray = innerStr.split(",");
for (String s : strArray) {
countMap.computeIfAbsent(s, s1 -> new AtomicInteger(0)).getAndIncrement();
}
}).start();
}
}
分割字元串演算法:分割時從 0 開始,按照等分的原則,將字元串 n 等份,每一個線程分到一份。
用一個 arr 數組的 arr[0] 記錄每次的分割開始位置,arr[1] 記錄每次分割的結束位置,如果遇到的開始的字元不為 ",",那麼就 startIndex-1,如果結束的位置不為 ",",那麼將 endIndex 向後移一位。
如果 endIndex 超過了字元串的最大長度,那麼就把最後一個字元賦值給 arr[1]。
/**
* 按照 x坐標 來分割 字元串,如果切到的字元不為“,”, 那麼把坐標向前或者向後移動一位。
*
* @param line
* @param arr 存放x1,x2坐標
* @return
*/
public static String splitStr(String line, int[] arr) {
int startIndex = arr[0];
int endIndex = arr[1];
char start = line.charAt(startIndex);
char end = line.charAt(endIndex);
if ((startIndex == 0 || start == ',') && end == ',') {
arr[0] = endIndex + 1;
arr[1] = arr[0] + line.length() / 3;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return line.substring(startIndex, endIndex);
}
if (startIndex != 0 && start != ',') {
startIndex = startIndex - 1;
}
if (end != ',') {
endIndex = endIndex + 1;
}
arr[0] = startIndex;
arr[1] = endIndex;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return splitStr(line, arr);
}
完整代碼:
package bigdata;
import cn.hutool.core.collection.CollectionUtil;
import org.apache.commons.lang3.StringUtils;
import java.io.*;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.ReentrantLock;
/**
* @Desc:
* @Author: bingbing
* @Date: 2022/5/4 0004 19:19
* 多線程處理
*/
public class HandleMaxRepeatProblem {
public static final int start = 18;
public static final int end = 70;
public static final String dir = "D:\dataDir";
public static final String FILE_NAME = "D:\ User.dat";
private static final int threadNums = 20;
/**
* key 為年齡, value為所有的行列表,使用隊列
*/
private static Map<Integer, Vector<String>> valueMap = new ConcurrentHashMap<>();
/**
* 存放數據的隊列
*/
private static List<LinkedBlockingQueue<String>> blockQueueLists = new LinkedList<>();
/**
* 統計數量
*/
private static Map<String, AtomicInteger> countMap = new ConcurrentHashMap<>();
private static Map<Integer, ReentrantLock> lockMap = new ConcurrentHashMap<>();
// 隊列負載均衡
private static AtomicLong count = new AtomicLong(0);
/**
* 開啟消費的標誌
*/
private static volatile boolean startConsumer = false;
/**
* 消費者運行保證
*/
private static volatile boolean consumerRunning = true;
/**
* 按照 "," 分割數據,並寫入到文件里
*/
static class SplitData {
public static void splitLine(String lineData) {
// System.out.println(lineData.length());
String[] arr = lineData.split("\n");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
long index = count.get() % threadNums;
try {
// 如果滿了就阻塞
blockQueueLists.get((int) index).put(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
count.getAndIncrement();
}
}
/**
* 按照 x坐標 來分割 字元串,如果切到的字元不為“,”, 那麼把坐標向前或者向後移動一位。
*
* @param line
* @param arr 存放x1,x2坐標
* @return
*/
public static String splitStr(String line, int[] arr) {
int startIndex = arr[0];
int endIndex = arr[1];
char start = line.charAt(startIndex);
char end = line.charAt(endIndex);
if ((startIndex == 0 || start == ',') && end == ',') {
arr[0] = endIndex + 1;
arr[1] = arr[0] + line.length() / 3;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return line.substring(startIndex, endIndex);
}
if (startIndex != 0 && start != ',') {
startIndex = startIndex - 1;
}
if (end != ',') {
endIndex = endIndex + 1;
}
arr[0] = startIndex;
arr[1] = endIndex;
if (arr[1] >= line.length()) {
arr[1] = line.length() - 1;
}
return splitStr(line, arr);
}
public static void splitLine0(String lineData) {
String[] arr = lineData.split(",");
for (String str : arr) {
if (StringUtils.isEmpty(str)) {
continue;
}
int keyIndex = Integer.parseInt(str);
ReentrantLock lock = lockMap.computeIfAbsent(keyIndex, lockMap -> new ReentrantLock());
lock.lock();
try {
valueMap.get(keyIndex).add(str);
} finally {
lock.unlock();
}
// boolean wait = true;
// for (; ; ) {
// if (!lockMap.get(Integer.parseInt(str)).isLocked()) {
// wait = false;
// valueMap.computeIfAbsent(Integer.parseInt(str), integer -> new Vector<>()).add(str);
// }
// // 當前阻塞,直到釋放鎖
// if (!wait) {
// break;
// }
// }
}
}
}
/**
* init map
*/
static {
File file = new File(dir);
if (!file.exists()) {
file.mkdir();
}
//每個隊列容量為256
for (int i = 0; i < threadNums; i++) {
blockQueueLists.add(new LinkedBlockingQueue<>(256));
}
for (int i = start; i <= end; i++) {
try {
File subFile = new File(dir + "\" + i + ".dat");
if (!file.exists()) {
subFile.createNewFile();
}
countMap.computeIfAbsent(i + "", integer -> new AtomicInteger(0));
// lockMap.computeIfAbsent(i, lock -> new ReentrantLock());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new Thread(() -> {
try {
// 讀取數據
readData();
} catch (IOException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
// 開始消費
startConsumer();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
// 監控
monitor();
}).start();
}
/**
* 每隔60s去檢查棧是否為空
*/
private static void monitor() {
AtomicInteger emptyNum = new AtomicInteger(0);
while (consumerRunning) {
try {
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (startConsumer) {
// 如果所有棧的大小都為0,那麼終止進程
AtomicInteger emptyCount = new AtomicInteger(0);
for (int i = 0; i < threadNums; i++) {
if (blockQueueLists.get(i).size() == 0) {
emptyCount.getAndIncrement();
}
}
if (emptyCount.get() == threadNums) {
emptyNum.getAndIncrement();
// 如果連續檢查指定次數都為空,那麼就停止消費
if (emptyNum.get() > 12) {
consumerRunning = false;
System.out.println("消費結束...");
try {
clearTask();
} catch (Exception e) {
System.out.println(e.getCause());
} finally {
System.exit(-1);
}
}
}
}
}
}
private static void readData() throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE_NAME), "utf-8"));
String line;
long start = System.currentTimeMillis();
int count = 1;
while ((line = br.readLine()) != null) {
// 按行讀取,並向隊列寫入數據
SplitData.splitLine(line);
if (count % 100 == 0) {
System.out.println("讀取100行,總耗時間: " + (System.currentTimeMillis() - start) / 1000 + " s");
try {
Thread.sleep(1000L);
System.gc();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
count++;
}
br.close();
}
private static void clearTask() {
// 清理,同時找出出現字元最大的數
Integer targetValue = 0;
String targetKey = null;
Iterator<Map.Entry<String, AtomicInteger>> entrySetIterator = countMap.entrySet().iterator();
while (entrySetIterator.hasNext()) {
Map.Entry<String, AtomicInteger> entry = entrySetIterator.next();
Integer value = entry.getValue().get();
String key = entry.getKey();
if (value > targetValue) {
targetValue = value;
targetKey = key;
}
}
System.out.println("數量最多的年齡為:" + targetKey + "數量為:" + targetValue);
System.exit(-1);
}
/**
* 使用linkedBlockQueue
*
* @throws FileNotFoundException
* @throws UnsupportedEncodingException
*/
private static void startConsumer() throws FileNotFoundException, UnsupportedEncodingException {
//如果共用一個隊列,那麼線程不宜過多,容易出現搶占現象
System.out.println("開始消費...");
for (int i = 0; i < threadNums; i++) {
final int index = i;
// 每一個線程負責一個queue,這樣不會出現線程搶占隊列的情況。
new Thread(() -> {
while (consumerRunning) {
startConsumer = true;
try {
String str = blockQueueLists.get(index).take();
countNum(str);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
// 按照arr的大小,運用多線程分割字元串
private static void countNum(String str) {
int[] arr = new int[2];
arr[1] = str.length() / 3;
// System.out.println("分割的字元串為start位置為:" + arr[0] + ",end位置為:" + arr[1]);
for (int i = 0; i < 3; i++) {
final String innerStr = SplitData.splitStr(str, arr);
// System.out.println("分割的字元串為start位置為:" + arr[0] + ",end位置為:" + arr[1]);
new Thread(() -> {
String[] strArray = innerStr.split(",");
for (String s : strArray) {
countMap.computeIfAbsent(s, s1 -> new AtomicInteger(0)).getAndIncrement();
}
}).start();
}
}
/**
* 後臺線程去消費map里數據寫入到各個文件里, 如果不消費,那麼會將記憶體程爆
*/
private static void startConsumer0() throws FileNotFoundException, UnsupportedEncodingException {
for (int i = start; i <= end; i++) {
final int index = i;
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(dir + "\" + i + ".dat", false), "utf-8"));
new Thread(() -> {
int miss = 0;
int countIndex = 0;
while (true) {
// 每隔100萬列印一次
int count = countMap.get(index).get();
if (count > 1000000 * countIndex) {
System.out.println(index + "歲年齡的個數為:" + countMap.get(index).get());
countIndex += 1;
}
if (miss > 1000) {
// 終止線程
try {
Thread.currentThread().interrupt();
bw.close();
} catch (IOException e) {
}
}
if (Thread.currentThread().isInterrupted()) {
break;
}
Vector<String> lines = valueMap.computeIfAbsent(index, vector -> new Vector<>());
// 寫入到文件里
try {
if (CollectionUtil.isEmpty(lines)) {
miss++;
Thread.sleep(1000);
} else {
// 100個一批
if (lines.size() < 1000) {
Thread.sleep(1000);
continue;
}
// 1000個的時候開始處理
ReentrantLock lock = lockMap.computeIfAbsent(index, lockIndex -> new ReentrantLock());
lock.lock();
try {
Iterator<String> iterator = lines.iterator();
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
sb.append(iterator.next());
countMap.get(index).addAndGet(1);
}
try {
bw.write(sb.toString());
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
// 清除掉vector
valueMap.put(index, new Vector<>());
} finally {
lock.unlock();
}
}
} catch (InterruptedException e) {
}
}
}).start();
}
}
}
測試結果:
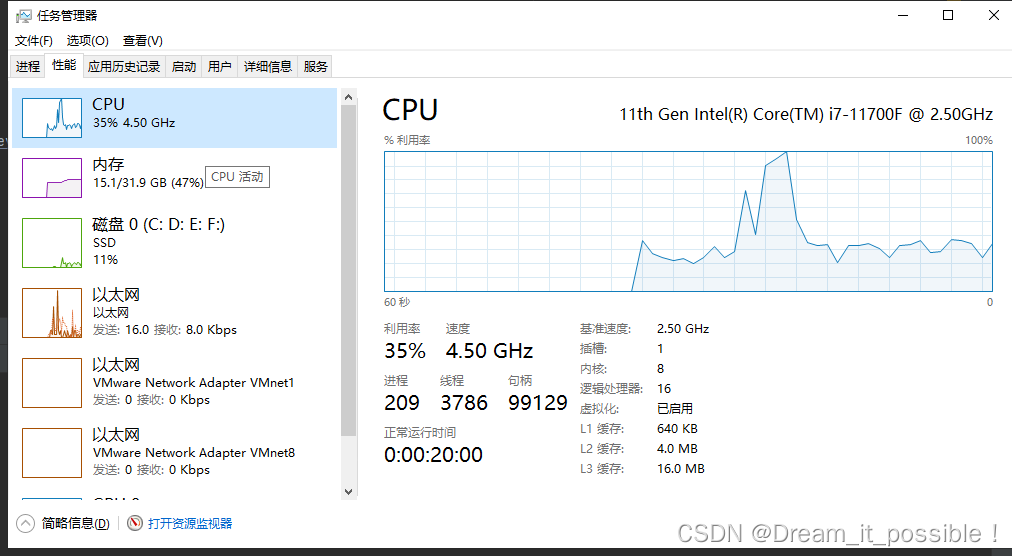
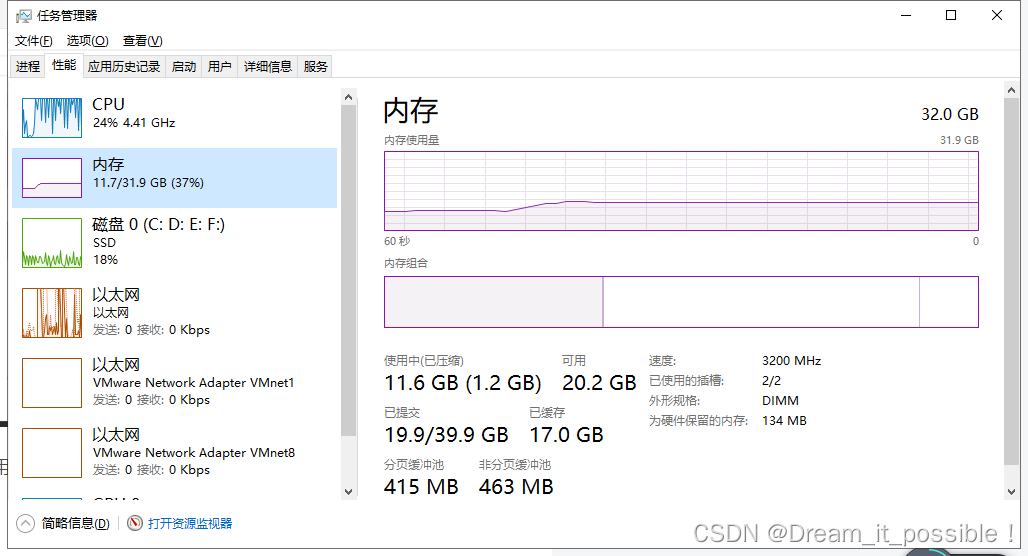
記憶體和 CPU 初始占用大小:

啟動後,運行時穩定在 11.7,CPU 穩定利用在 90% 以上。
總耗時由 180S 縮減到 103S,效率提升 75%,得到的結果也與單線程處理的一致!
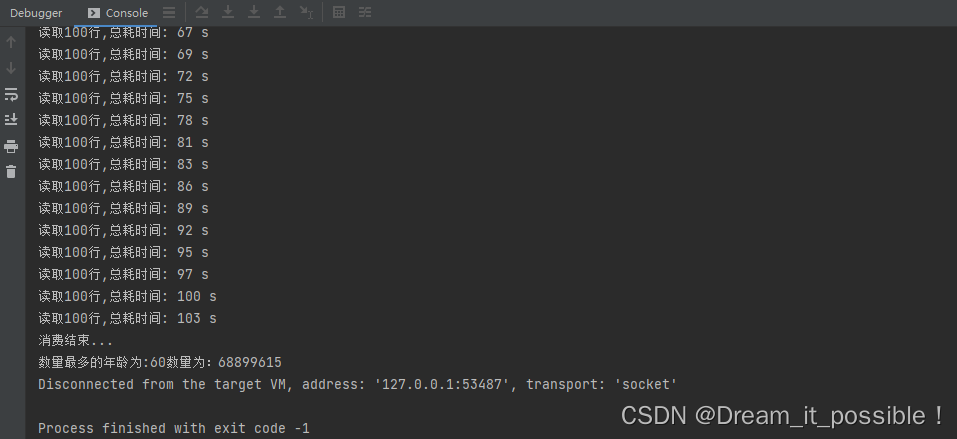
遇到的問題
如果在運行了的時候,發現 GC 突然罷工了,開始不工作了,有可能是 JVM 的堆中存在的垃圾太多,沒回收導致記憶體的突增。
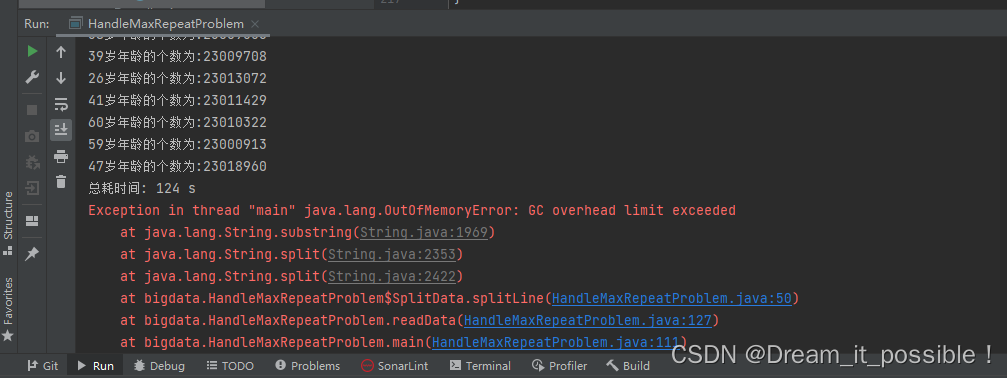
解決方法:在讀取一定數量後,可以讓主線程暫停幾秒,手動調用 GC。
提示:本 demo 的線程創建都是手動創建的,實際開發中使用的是線程池!
原文鏈接:https://blog.csdn.net/qq_33036061/article/details/124568689
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!

