
一、概述 EFAK(Eagle For Apache Kafka,以前稱為 Kafka Eagle)是一款由國內公司開源的Kafka集群監控系統,可以用來監視kafka集群的broker狀態、Topic信息、IO、記憶體、consumer線程、偏移量等信息,併進行可視化圖表展示。獨特的KQL還可以通過 ...
目錄
一、概述
EFAK(Eagle For Apache Kafka,以前稱為 Kafka Eagle)是一款由國內公司開源的Kafka集群監控系統,可以用來監視kafka集群的broker狀態、Topic信息、IO、記憶體、consumer線程、偏移量等信息,併進行可視化圖表展示。獨特的KQL還可以通過SQL線上查詢kafka中的數據。
源碼: https://github.com/smartloli/kafka-eagle/
下載: http://download.kafka-eagle.org/
官方文檔:https://www.kafka-eagle.org/articles/docs/documentation.html
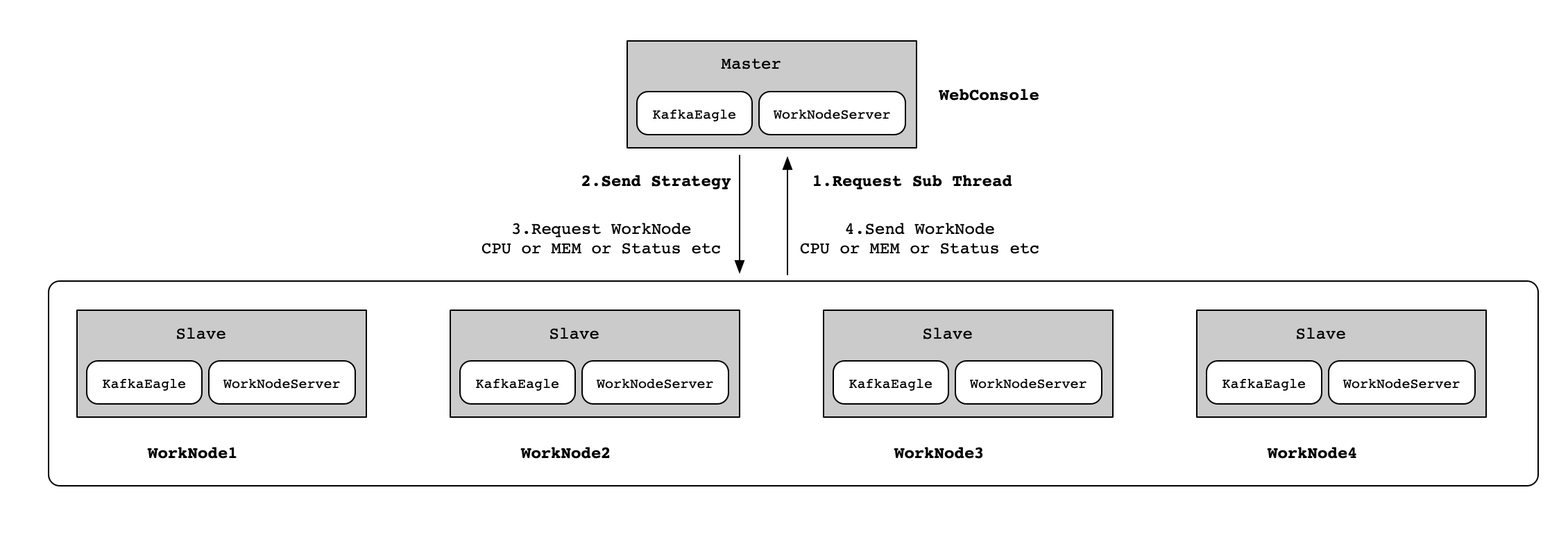
二、EFAK架構
EFAK分散式模式部署,這裡以5個節點為例子(1個Master和4個Slave),各個節點的角色如下如所示:
三、EFAK數據採集原理
對於 Kafka,我們可以收集以下數據
- Kafka broker常用機器載入信息:記憶體、cpu、IP、版本等。
- 服務監控數據:TPS、QPS、RT等
- 應用程式監控:組、消費者、生產者、主題等。

因為EFAK是kafka的監控系統,所以前提是需先安裝Kafka和Zookeeper。
四、安裝Kafka
kafka官網文檔:https://kafka.apache.org/documentation/
1)Kafka下載
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/kafka/3.1.1/kafka_2.13-3.1.1.tgz
$ tar -xf kafka_2.13-3.1.1.tgz -C /opt/bigdata/hadoop/server/
2)配置環境變數
$ vi /etc/profile
export KAFKA_HOME=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1
export PATH=$PATH:$KAFKA_HOME/bin
$ source /etc/profile
3)創建logs目錄
$ mkdir $KAFKA_HOME/logs
4)修改kafka配置
$ cd $KAFKA_HOME
# 查看現有配置,去掉空行和註釋
$ cat config/server.properties |grep -v '^$\|^#'
$ cat > $KAFKA_HOME/config/server.properties <<EOF
#broker的全局唯一編號,不能重覆
broker.id=0
#刪除topic功能使能
delete.topic.enable=true
#處理網路請求的線程數量
num.network.threads=3
#用來處理磁碟IO的現成數量
num.io.threads=8
#發送套接字的緩衝區大小
socket.send.buffer.bytes=102400
#接收套接字的緩衝區大小
socket.receive.buffer.bytes=102400
#請求套接字的緩衝區大小
socket.request.max.bytes=104857600
#kafka數據的存儲位置
log.dirs=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1/logs
#topic在當前broker上的分區個數
num.partitions=1
#用來恢復和清理data下數據的線程數量
num.recovery.threads.per.data.dir=1
#segment文件保留的最長時間,超時將被刪除
log.retention.hours=168
#配置連接Zookeeper集群地址
zookeeper.connect=hadoop-node1:12181,hadoop-node2:12181,hadoop-node3:12181
#zookeeper連接超時時間
zookeeper.connection.timeout.ms=60000
EOF
5)修改zookeeper配置
# 創建zookeeper data和logs目錄
$ mkdir $KAFKA_HOME/zookeeper_data $KAFKA_HOME/zookeeper_logs
$ vi $KAFKA_HOME/config/zookeeper.properties
# 配置主要修改如下:
#數據目錄
dataDir=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1/zookeeper_data
#日誌目錄
dataLogDir=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1/zookeeper_logs
#心跳間隔時間,zookeeper中使用的基本時間單位,毫秒值。每隔2秒發送一個心跳,session時間tickTime*2
tickTime=2000
#leader與客戶端連接超時時間。表示5個心跳間隔
initLimit=5
#Leader與Follower之間的超時時間,表示2個心跳間隔
syncLimit=2
#客戶端連接埠,預設埠2181
clientPort=12181
# zookeeper集群配置項,server.1,server.2,server.3是zk集群節點;hadoop-node1,hadoop-node2,hadoop-node3是主機名稱;2888是主從通信埠;3888用來選舉leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
6)配置Zookeeper myid
# 在hadoop-node1配置如下:
$ echo 1 > $KAFKA_HOME/zookeeper_data/myid
# 在hadoop-node2配置如下:
$ echo 2 > $KAFKA_HOME/zookeeper_data/myid
# 在hadoop-node3配置如下:
$ echo 3 > $KAFKA_HOME/zookeeper_data/myid
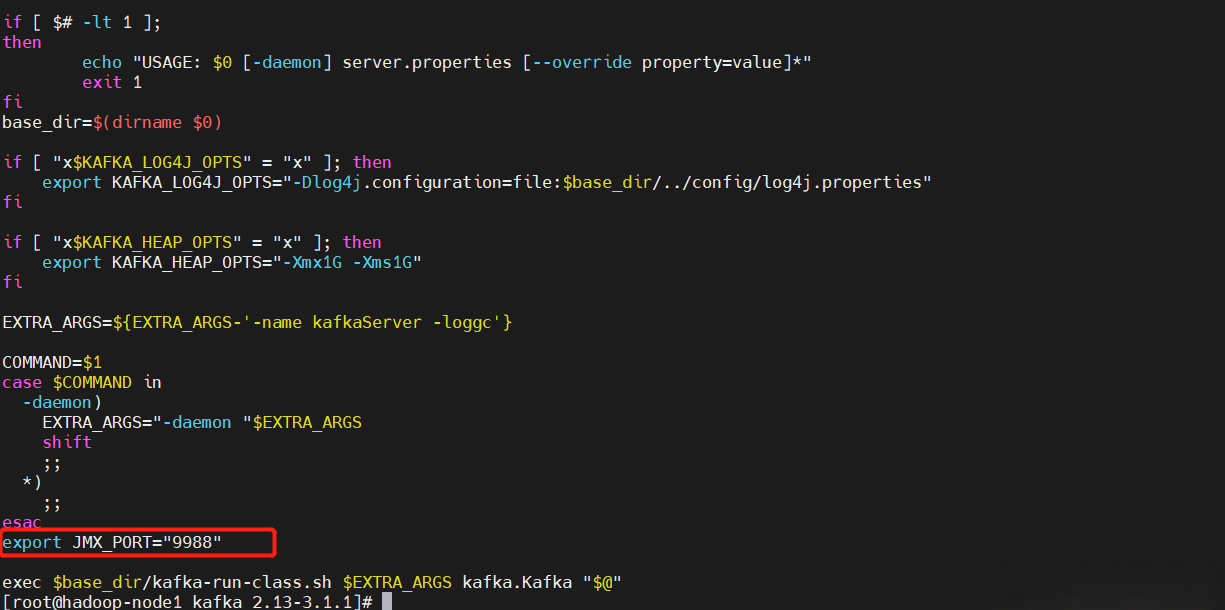
7)開啟Kafka JMX監控
# 在kafka-server-start.sh文件中添加export JMX_PORT="9988",埠自定義就行
$ vi $KAFKA_HOME/bin/kafka-server-start.sh
重啟kafka
$ $KAFKA_HOME/bin/kafka-server-stop.sh ; $KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
【問題】如遇以下報錯:
ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer) kafka.common.InconsistentClusterIdException: The Cluster ID ELIH-KKbRP-NnPnHt4z-lA doesn't match stored clusterId Some(2HC_x7bTR_u2bCxrqw0Otw) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong. at kafka.server.KafkaServer.startup(KafkaServer.scala:228) at kafka.Kafka$.main(Kafka.scala:109) at kafka.Kafka.main(Kafka.scala)

【解決】在server.properties找到log.dirs配置的路徑。將該路徑下的meta.properties文件刪除,或者編輯meta.properties文件修改裡面的cluster.id即可。
8)將kafka目錄推送到其它節點
$ scp -r $KAFKA_HOME hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r $KAFKA_HOME hadoop-node3:/opt/bigdata/hadoop/server/
# 在hadoop-node2和hadoop-node3節點上設置環境變數
$ vi /etc/profile
export KAFKA_HOME=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1
export PATH=$PATH:$KAFKA_HOME/bin
$ source /etc/profile
# 修改advertised.listeners,值改成對應的hostname或者ip
【溫馨提示】修改hadoop-node2上server.properties文件的
broker.id,設置為1和2,只要不重覆就行,advertised.listeners地址改成對應機器IP。
9)啟動服務
啟動zookeeper集群之後再啟動kafka集群
$ cd $KAFKA_HOME
# -daemon後臺啟動
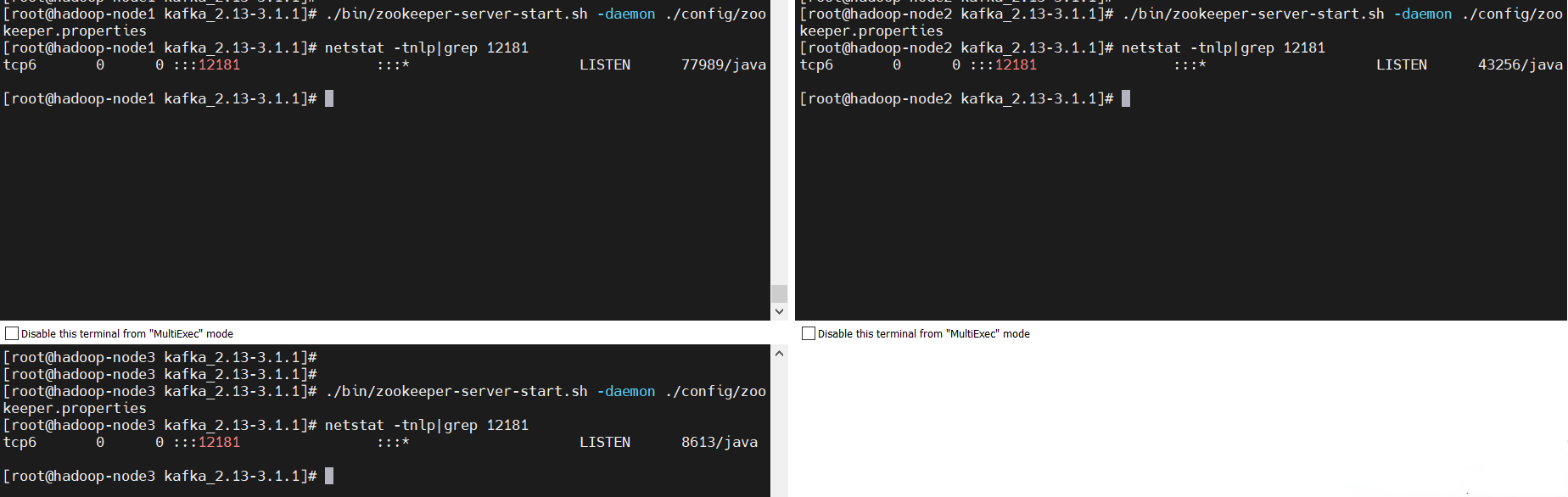
$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
# 預設埠2181,可以在配置自定義,這裡修改為12181埠
$ netstat -tnlp|grep 12181
啟動Kafka
$ cd $KAFKA_HOME
# 預設埠9092,這裡修改成了19092,可以修改listeners和advertised.listeners
$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
$ netstat -tnlp|grep 9092
$ jps
五、安裝EFAK
1)下載EFAK
$ cd /opt/bigdata/hadoop/software
$ wget https://github.com/smartloli/kafka-eagle-bin/archive/v2.1.0.tar.gz
$ tar -xf kafka-eagle-bin-2.1.0.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/
$ tar -xf
2)創建資料庫
$ mysql -uroot -p
123456
create database ke;
2)設置環境變數
$ vi /etc/profile
export KE_HOME=/opt/bigdata/hadoop/server/kafka-eagle-bin-2.1.0/efak-web-2.1.0
export PATH=$PATH:$KE_HOME/bin
$ source /etc/profile
3)配置
這裡設置hadoop-node1為master節點,其它兩個節點為slave節點,修改參數
$ vi $KE_HOME/conf/system-config.properties
# Multi zookeeper&kafka cluster list -- The client connection address of the Zookeeper cluster is set here
efak.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop-node1:12181,hadoop-node2:12181,hadoop-node3:12181
######################################
# kafka jmx 地址,預設Apache發佈的Kafka基本是這個預設值,
# 對於一些公有雲Kafka廠商,它們會修改這個值,
# 比如會將jmxrmi修改為kafka或者是其它的值,
# 若是選擇的公有雲廠商的Kafka,可以根據實際的值來設置該屬性
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
# Zkcli limit -- Zookeeper cluster allows the number of clients to connect to
# If you enable distributed mode, you can set value to 4 or 8
kafka.zk.limit.size=16
# EFAK webui port -- WebConsole port access address
efak.webui.port=8048
######################################
# EFAK enable distributed,啟用分散式部署
######################################
efak.distributed.enable=true
# 設置節點類型slave or master
# master worknode set status to master, other node set status to slave
efak.cluster.mode.status=master
# deploy efak server address
efak.worknode.master.host=hadoop-node1
efak.worknode.port=8085
# Kafka offset storage -- Offset stored in a Kafka cluster, if stored in the zookeeper, you can not use this option
cluster1.efak.offset.storage=kafka
# Whether the Kafka performance monitoring diagram is enabled
efak.metrics.charts=true
# EFAK keeps data for 30 days by default
efak.metrics.retain=15
# If offset is out of range occurs, enable this property -- Only suitable for kafka sql
efak.sql.fix.error=false
efak.sql.topic.records.max=5000
# Delete kafka topic token -- Set to delete the topic token, so that administrators can have the right to delete
efak.topic.token=keadmin
# 關閉自帶的sqlite資料庫,使用外部的mysql資料庫
# Default use sqlite to store data
# efak.driver=org.sqlite.JDBC
# It is important to note that the '/hadoop/kafka-eagle/db' path must be exist.
# efak.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
# efak.username=root
# efak.password=smartloli
# 配置外部資料庫
# (Optional) set mysql address
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://hadoop-node1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456
4)調整啟動參數
EFAK預設啟動記憶體大小為2G,考慮到伺服器情況可以將其調小
## 在 efak 安裝目錄執行
$ vi $KE_HOME/bin/ke.sh
## 將 KE_JAVA_OPTS 最大最小容量調小,例如:
export KE_JAVA_OPTS="-server -Xmx512m -Xms512m -XX:MaxGCPauseMillis=20 -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
6)修改 works配置
預設是localhost
$ cat >$KE_HOME/conf/works<<EOF
hadoop-node2
hadoop-node3
EOF
7)將EFAK推送其它節點
# hadoop-node1推送
$ scp -r /opt/bigdata/hadoop/server/kafka-eagle-bin-2.1.0 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r /opt/bigdata/hadoop/server/kafka-eagle-bin-2.1.0 hadoop-node3:/opt/bigdata/hadoop/server/
# 在hadoop-node2和hadoop-node3配置環境變數修改節點類型為slave
8)啟動
上面配置文件配置的是分散式部署,當然也可以單機跑,但是不建議單機跑
# 在master節點上執行
$ cd $KE_HOME/bin
$ chmod +x ke.sh
# 單機版啟動
$ ke.sh start
# 集群方式啟動
$ ke.sh cluster start
$ ke.sh cluster restart
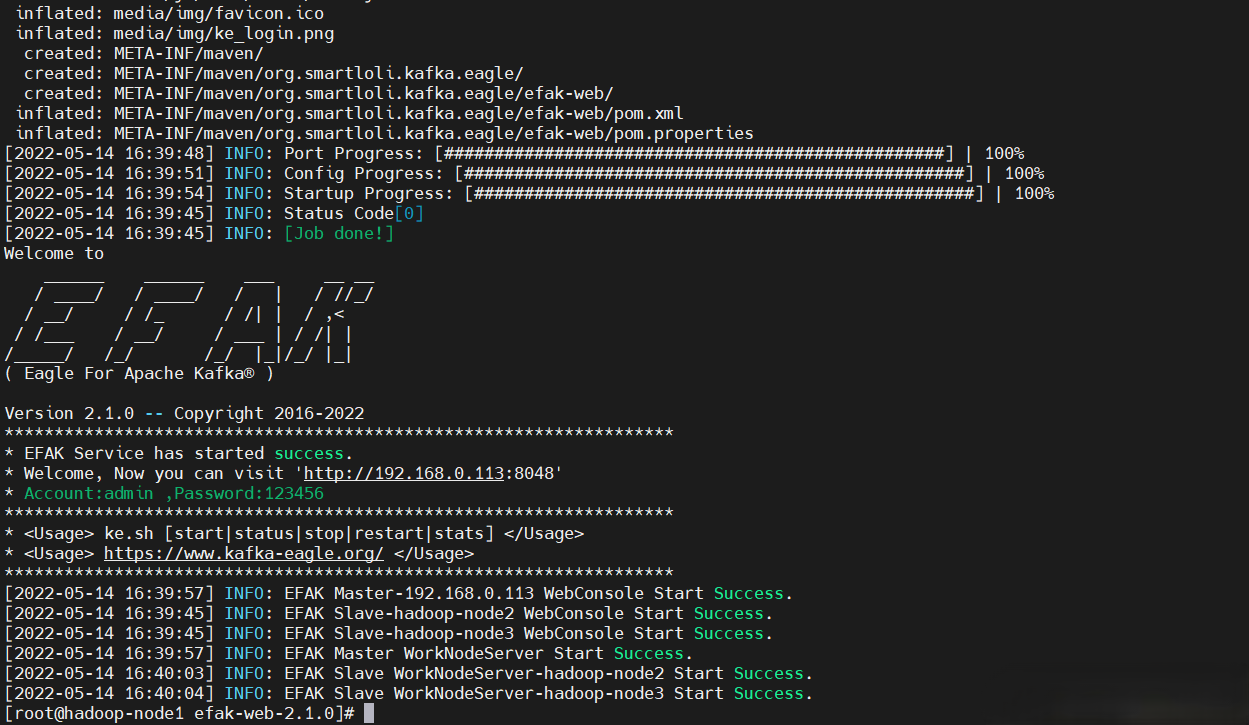
web UI:http://192.168.0.113:8048/
賬號密碼:admin/123456
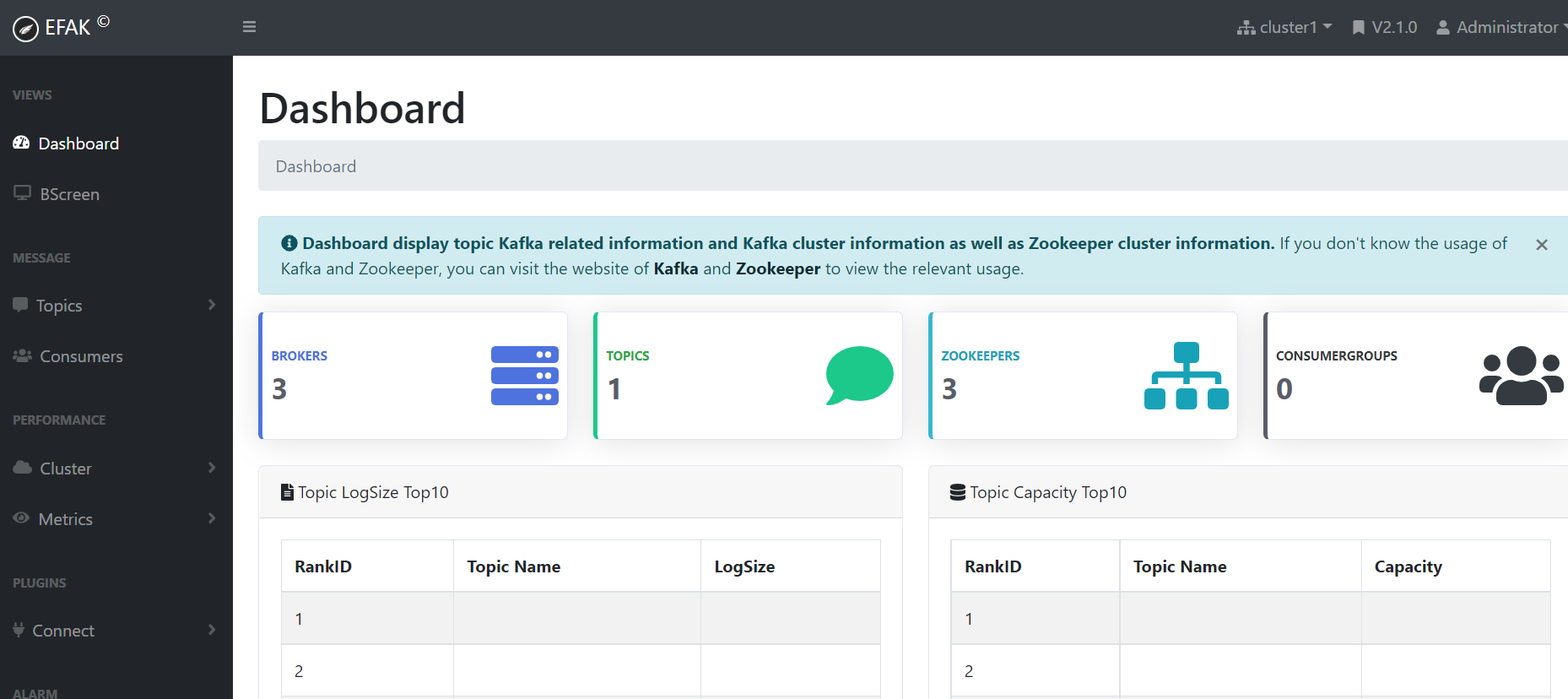

六、簡單使用
1)Kafka CLI簡單使用
【增】添加topic
# 創建topic,1副本,1分區,設置數據過期時間72小時(-1表示不過期),單位ms,72*3600*1000=259200000
$ kafka-topics.sh --create --topic test002 --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --partitions 1 --replication-factor 1 --config retention.ms=259200000
【查】
# 查看topic列表
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --list
# 查看topic列表詳情
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe
# 指定topic
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe --topic test002
# 查看消費者組
$ kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --list
$ kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --describe --group test002
【改】這裡主要是修改最常用的三個參數:分區、副本,過期時間
# 修改分區,擴分區,不能減少分區
$ kafka-topics.sh --alter --bootstrap-server hadoop-node1:9092 --topic test002 --partitions 2
# 修改過期時間,下麵兩行都可以
$ kafka-configs.sh --bootstrap-server hadoop-node1:9092 --alter --topic test002 --add-config retention.ms=86400000
$ kafka-configs.sh --bootstrap-server hadoop-node1:9092 --alter --entity-name test002 --entity-type topics --add-config retention.ms=86400000
# 修改副本數,將副本數修改成3
$ cat >1.json<<EOF
{"version":1,
"partitions":[
{"topic":"test002","partition":0,"replicas":[0,1,2]},
{"topic":"test002","partition":1,"replicas":[1,2,0]},
{"topic":"test002","partition":2,"replicas":[2,0,1]}
]}
EOF
$ kafka-topics.sh --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092 --describe --topic test002
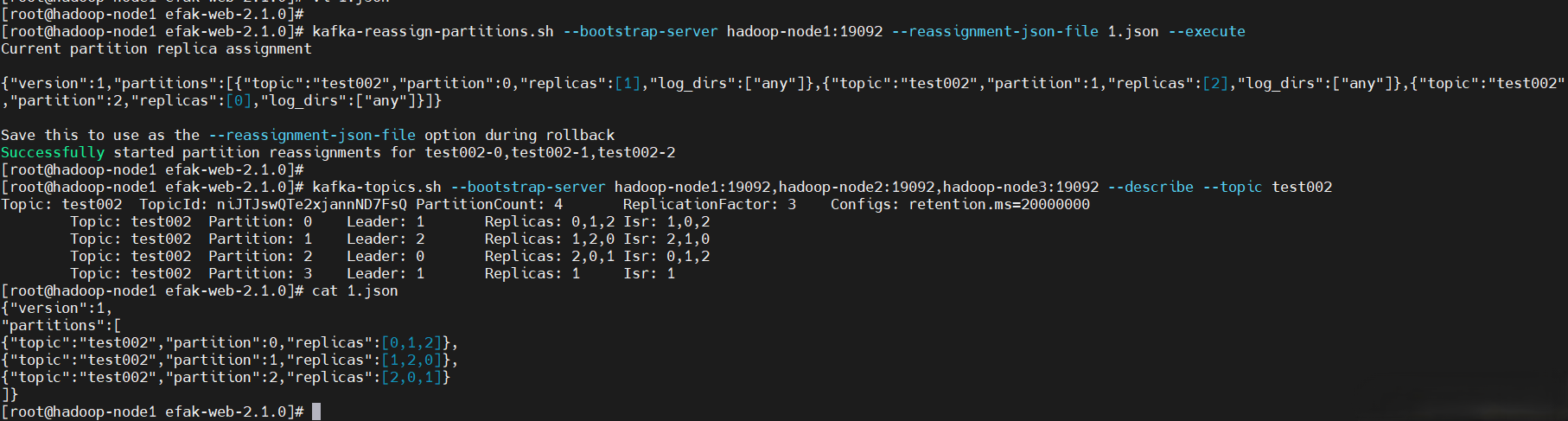
【刪】
$ kafka-topics.sh --delete --topic test002 --bootstrap-server hadoop-node1:9092,hadoop-node2:9092,hadoop-node3:9092
【生成者】
$ kafka-console-producer.sh --broker-list hadoop-node1:9092 --topic test002
{"id":"1","name":"n1","age":"20"}
{"id":"2","name":"n2","age":"21"}
{"id":"3","name":"n3","age":"22"}
【消費者】
# 從頭開始消費
$ kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --from-beginning
# 指定從分區的某個位置開始消費,這裡只指定了一個分區,可以多寫幾行或者遍歷對應的所有分區
$ kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --partition 0 --offset 100
【消費組】
$ kafka-console-consumer.sh --bootstrap-server hadoop-node1:9092 --topic test002 --group test002
【查看數據積壓】
$ kafka-consumer-groups.sh --bootstrap-server hadoop-node1:9092 --describe --group test002

2)EFAK常用命令
$KE_HOME/bin/ke.sh啟動腳本中包含以下命令:
| 命令 | 描述 |
|---|---|
| ke.sh start | 啟動 EFAK 伺服器。 |
| ke.sh status | 查看 EFAK 運行狀態。 |
| ke.sh stop | 停止 EFAK 伺服器。 |
| ke.sh restart | 重新啟動 EFAK 伺服器。 |
| ke.sh stats | 查看 linux 操作系統中的 EFAK 句柄數。 |
| ke.sh find [ClassName] | 在 jar 中找到類名的位置。 |
| ke.sh gc | 查看 EFAK 進程 gc。 |
| ke.sh version | 查看 EFAK 版本。 |
| ke.sh jdk | 查看 EFAK 安裝的 jdk 詳細信息。 |
| ke.sh sdate | 查看 EFAK 啟動日期。 |
| ke.sh cluster start | 查看 EFAK 集群分散式啟動。 |
| ke.sh cluster status | 查看 EFAK 集群分散式狀態。 |
| ke.sh cluster stop | 查看 EFAK 集群分散式停止。 |
| ke.sh cluster restart | 查看 EFAK 集群分散式重啟。 |
EFAK環境部署,和kafka的一些簡單操作就到這裡了,後續會分享KSQL和其它更詳細的頁面化操作,請小伙伴耐心等待~


