
一、概述 Oozie是一個基於工作流引擎的開源框架,依賴於MapReduce來實現,是一個管理 Apache Hadoop 作業的工作流調度系統。是由Cloudera公司貢獻給Apache的,它能夠提供對Hadoop MapReduce和Pig Jobs的任務調度與協調。Oozie需要部署到Java ...
目錄
一、概述
Oozie是一個基於工作流引擎的開源框架,依賴於MapReduce來實現,是一個管理 Apache Hadoop 作業的工作流調度系統。是由Cloudera公司貢獻給Apache的,它能夠提供對Hadoop MapReduce和Pig Jobs的任務調度與協調。Oozie需要部署到Java Servlet容器中運行。
官網:https://oozie.apache.org/
官方文檔:https://oozie.apache.org/docs/5.2.1/index.html
安裝包下載地址:https://dlcdn.apache.org/oozie/5.2.1/
github源碼地址:https://github.com/apache/oozie.git
Oozie的特點:
- Oozie是管理hadoop作業的調度系統;
- Oozie的工作流作業是一系列動作的有向無環圖(DAG);
- Oozie協調作業是通過時間(頻率)和有效數據觸發當前的Oozie工作流程;
- 工作流通過
hPDL定義(一種XML流程定義語言); - 資源文件(腳本、jar包等)存放在HDFS
- Oozie支持各種hadoop作業,例如:java map-reduce、Streaming map-reduce、pig、hive、sqoop和distcp等等,也支持系統特定的作業,例如java程式和shell腳本;
- Oozie是一個可伸縮,可靠和可拓展的系統。
二、Oozie架構


Oozie三層結構:
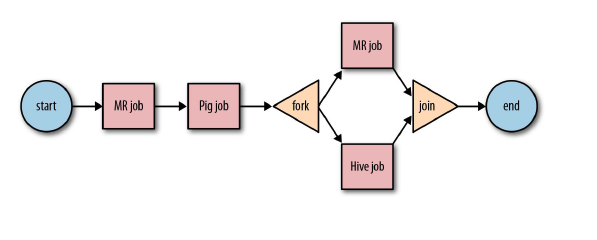
Workflow:工作流,由我們需要處理的每個工作組成,進行需求的流式處理,是對要進行的順序化工作的抽象。- 控制節點(CONTROL NODE):控制流節點一般都是定義在工作流開始或者結束的位置,比如
start,end,kill等。以及提供工作流的執行路徑機制,如decision, fork, join等。 - 動作節點(ACTION NODE) : 負責執行具體動作的節點,比如:拷貝文件,執行某個
hive、shell、sqoop、pig、mr等等。
- 控制節點(CONTROL NODE):控制流節點一般都是定義在工作流開始或者結束的位置,比如
流程圖如下:
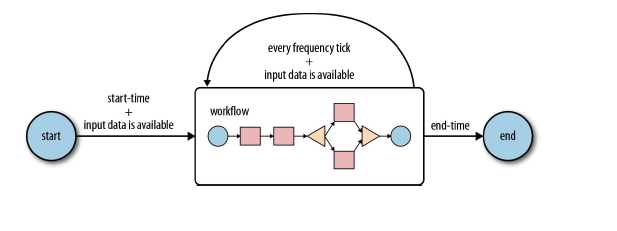
Coordinator:協調器,可以理解為工作流的協調器,可以將多個工作流協調成一個工作流來進行處理,是對要進行的順序化的workflow的抽象,定時觸發一個workflow。流程圖如下:
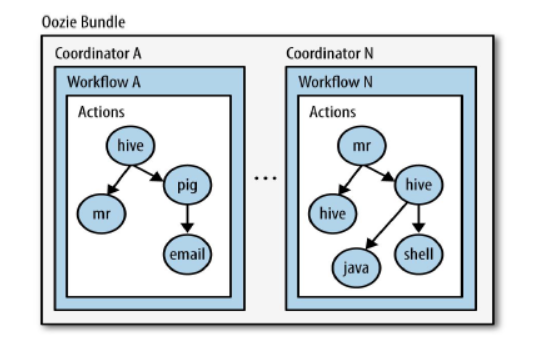
Bundle:捆,束。將一堆的coordinator進行彙總處理,是對一堆coordiantor的抽象,用來綁定多個coordinator或者多個workflow,流程圖如下:
三、Oozie環境部署(Oozie與CDH集成)
一般Oozie是集成到CDH上使用的,所以這裡部署就通過CM去部署了,沒有部署CDH的小伙伴,可以參考我之前的文章:大數據Hadoop之——Cloudera Hadoop(CM 6.3.1+CDH 6.3.2環境部署)
1)添加服務

2)將 Oozie 服務添加到 CDH
3)自定義角色分配
4)資料庫設置
還在是在大數據Hadoop之——Cloudera Hadoop(CM 6.3.1+CDH 6.3.2環境部署)這篇文章初始化的配置。


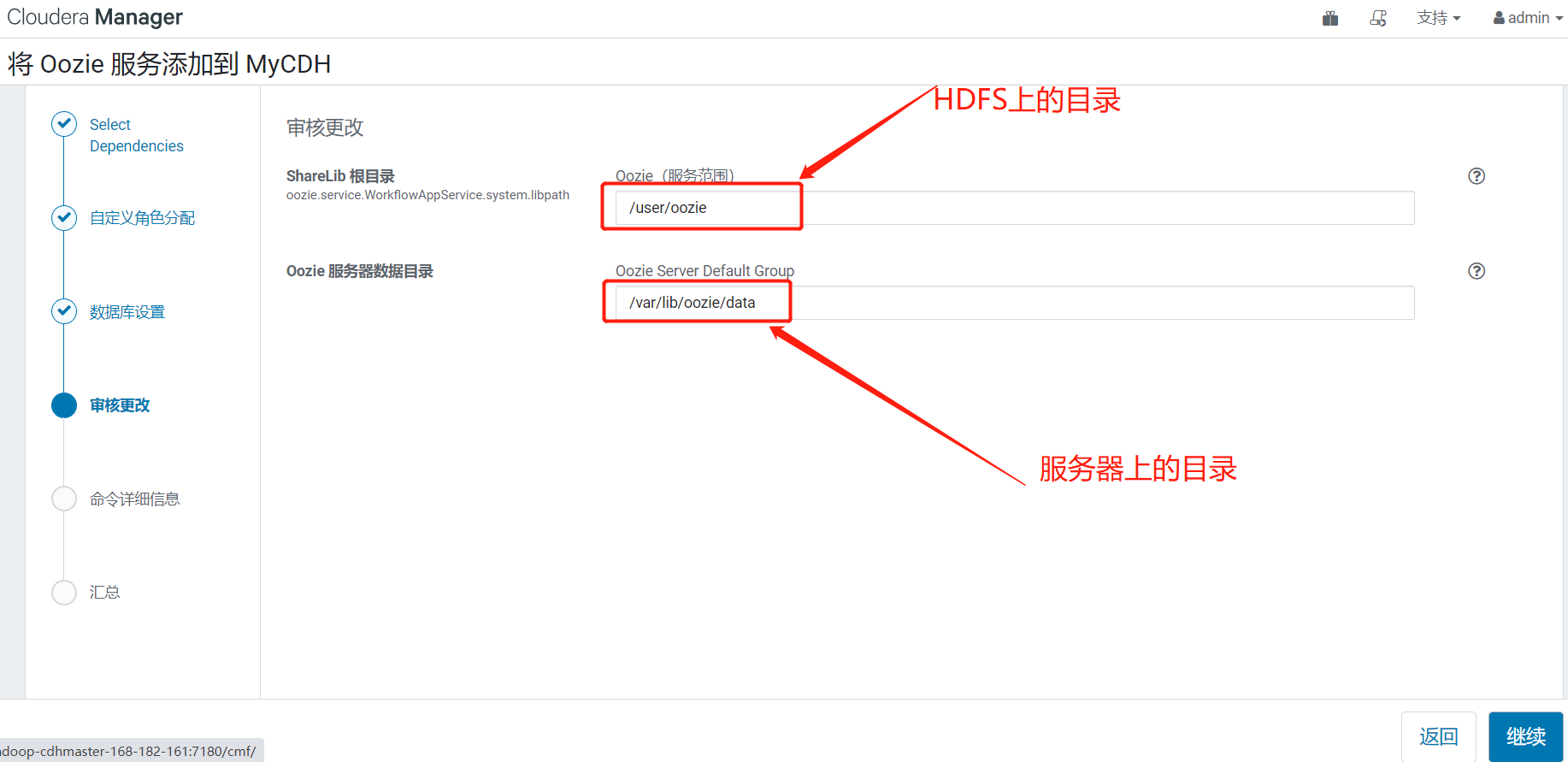
5)審核更改
預設就行,當然可以自行修改
6)開始自動安裝並自啟

到這裡Oozie服務就安裝完成了。
四、CDH的 Hue 整合 Oozie
由於oozie的xml配置執行各種任務調度是在太過於繁瑣,所有一般都使用hue整合oozie來使用。
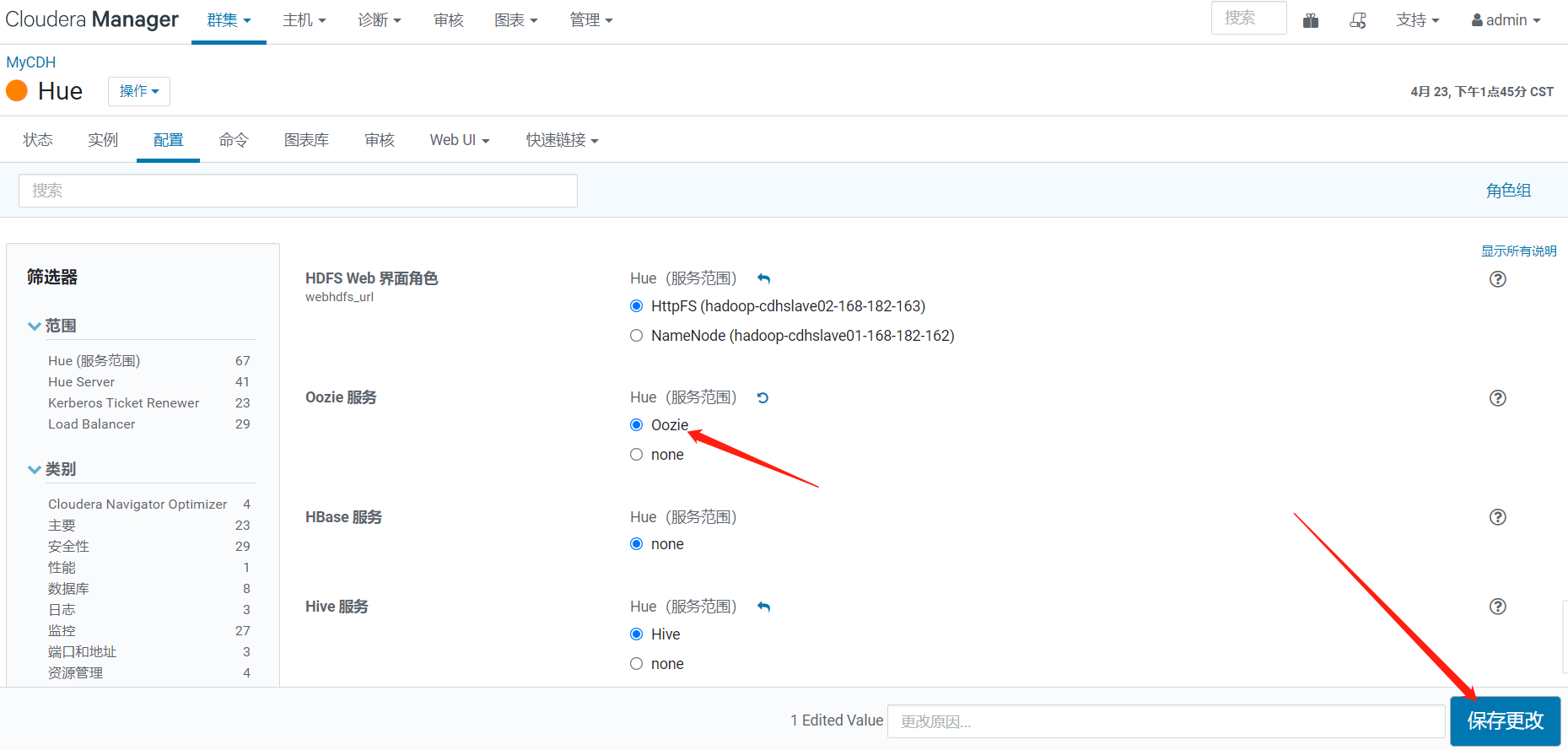
修改配置
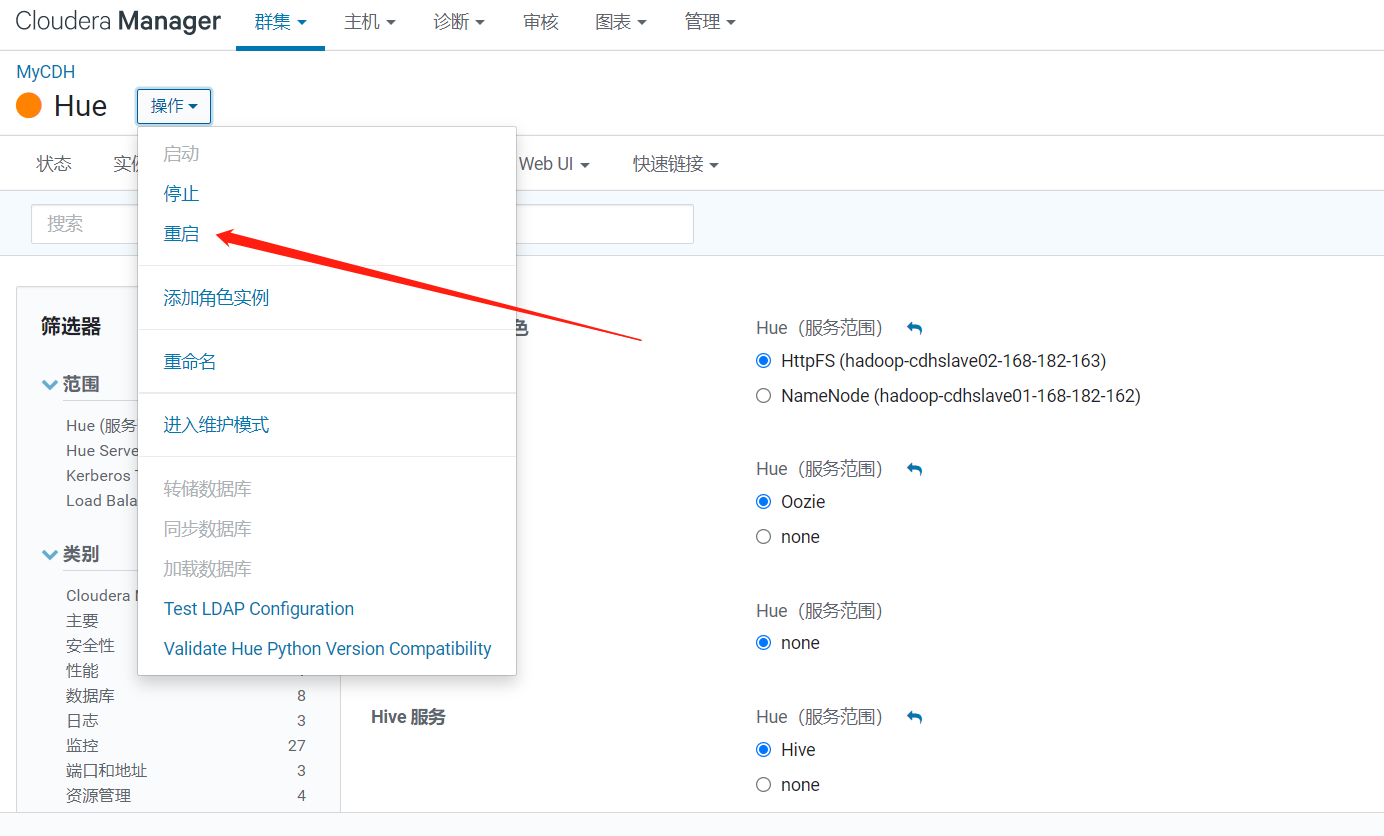
重啟Hue服務
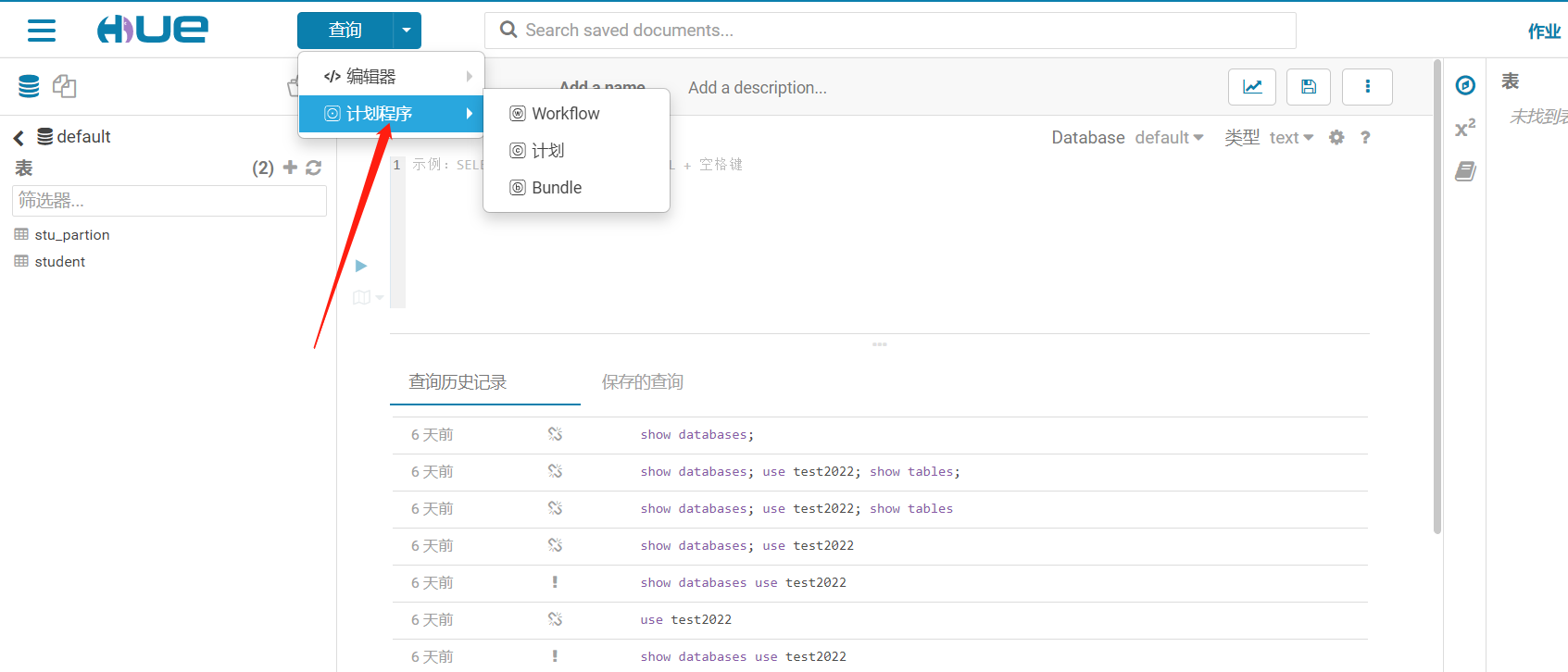
重新登錄Hue web

發現多了計劃程式,這就是Oozie的計劃程式
五、Oozie簡單使用
1)在Hue上操作Oozie
1、利用 Hue 調度 shell 腳本
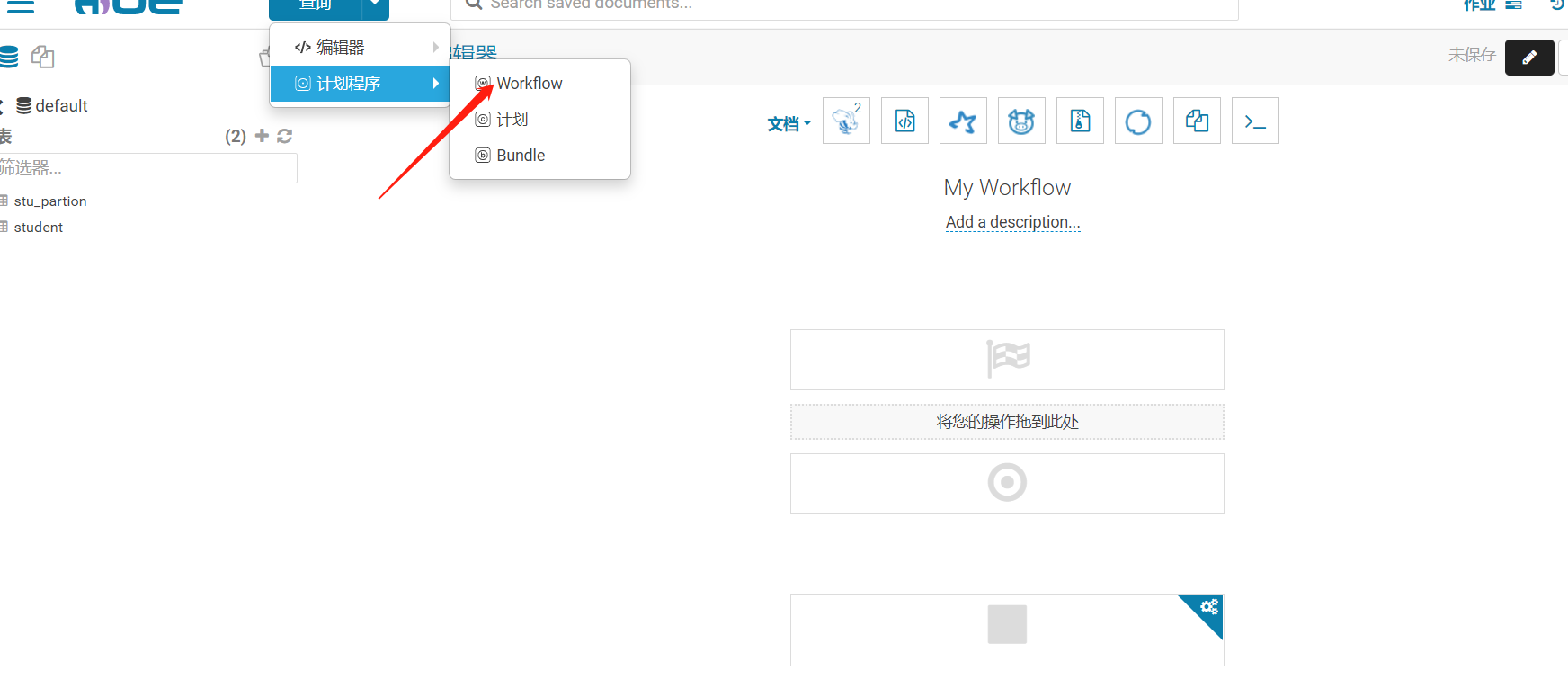
1、創建workflow
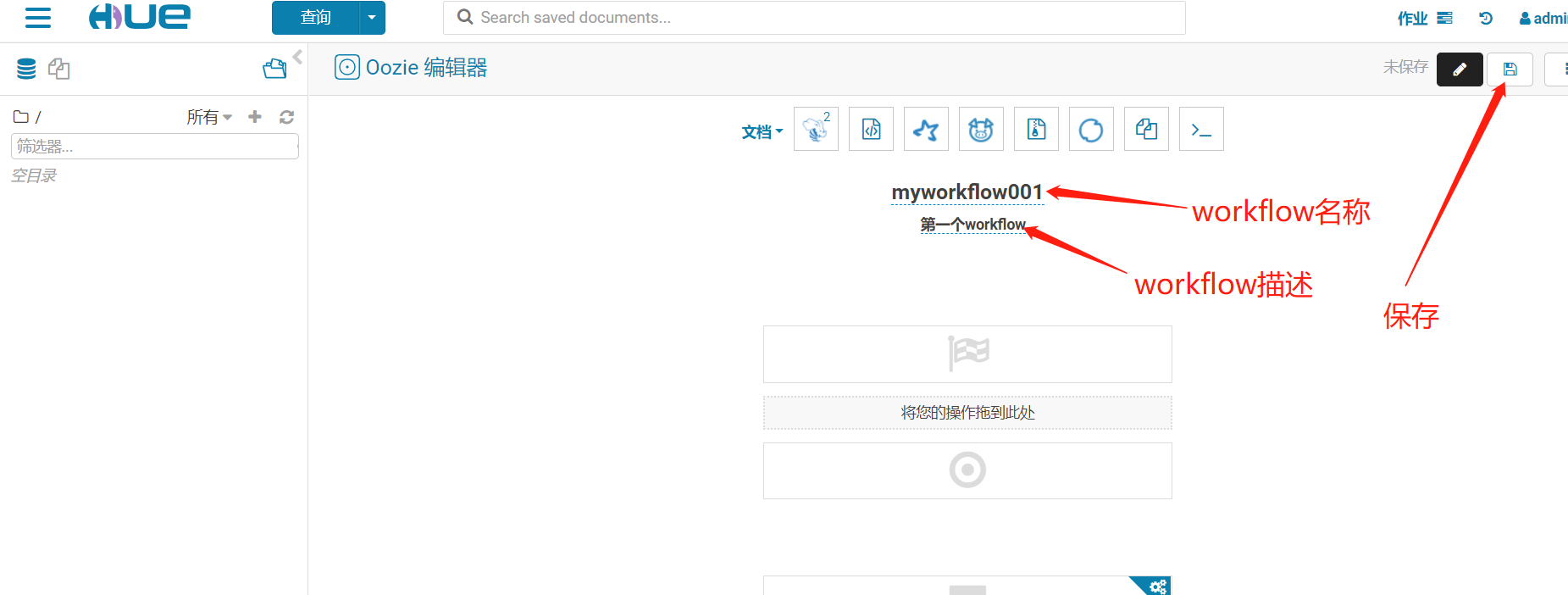
2、查看workflow
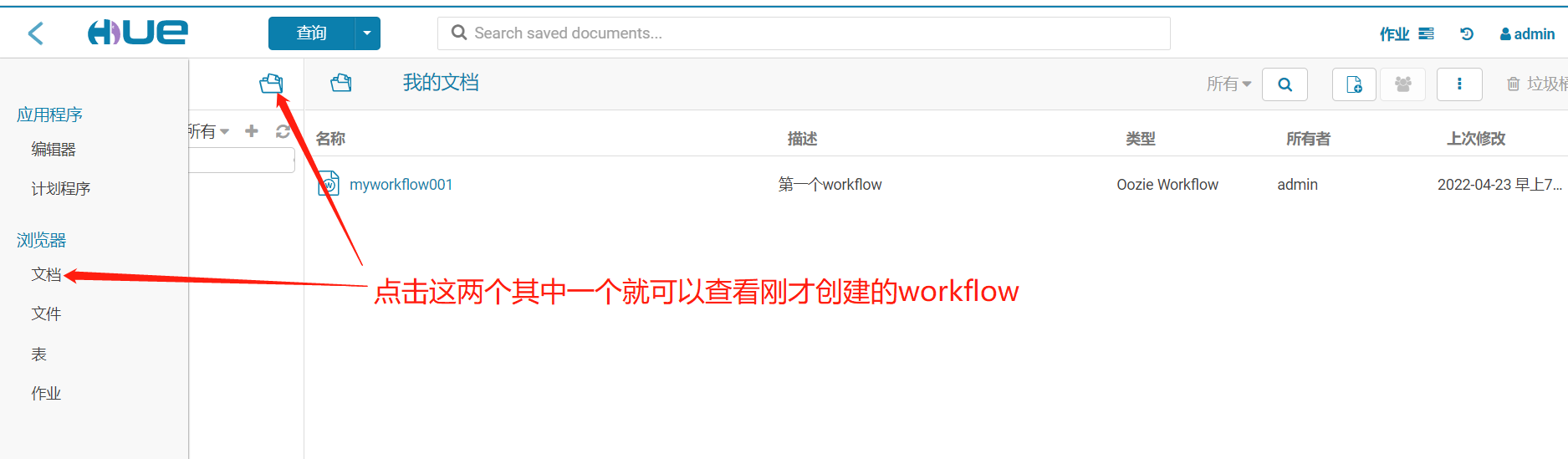
3、配置調用任務
這裡選擇shell腳本,很多選擇
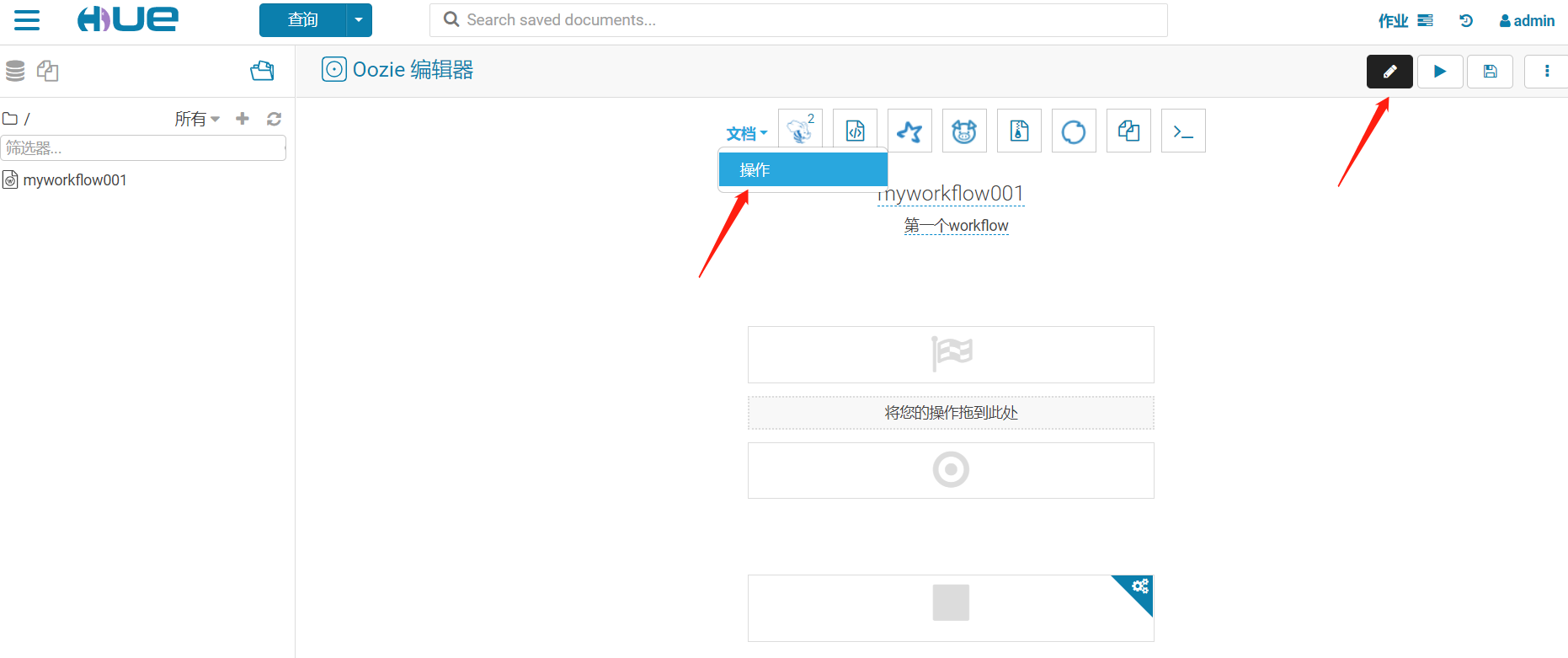



保存

4、立即執行
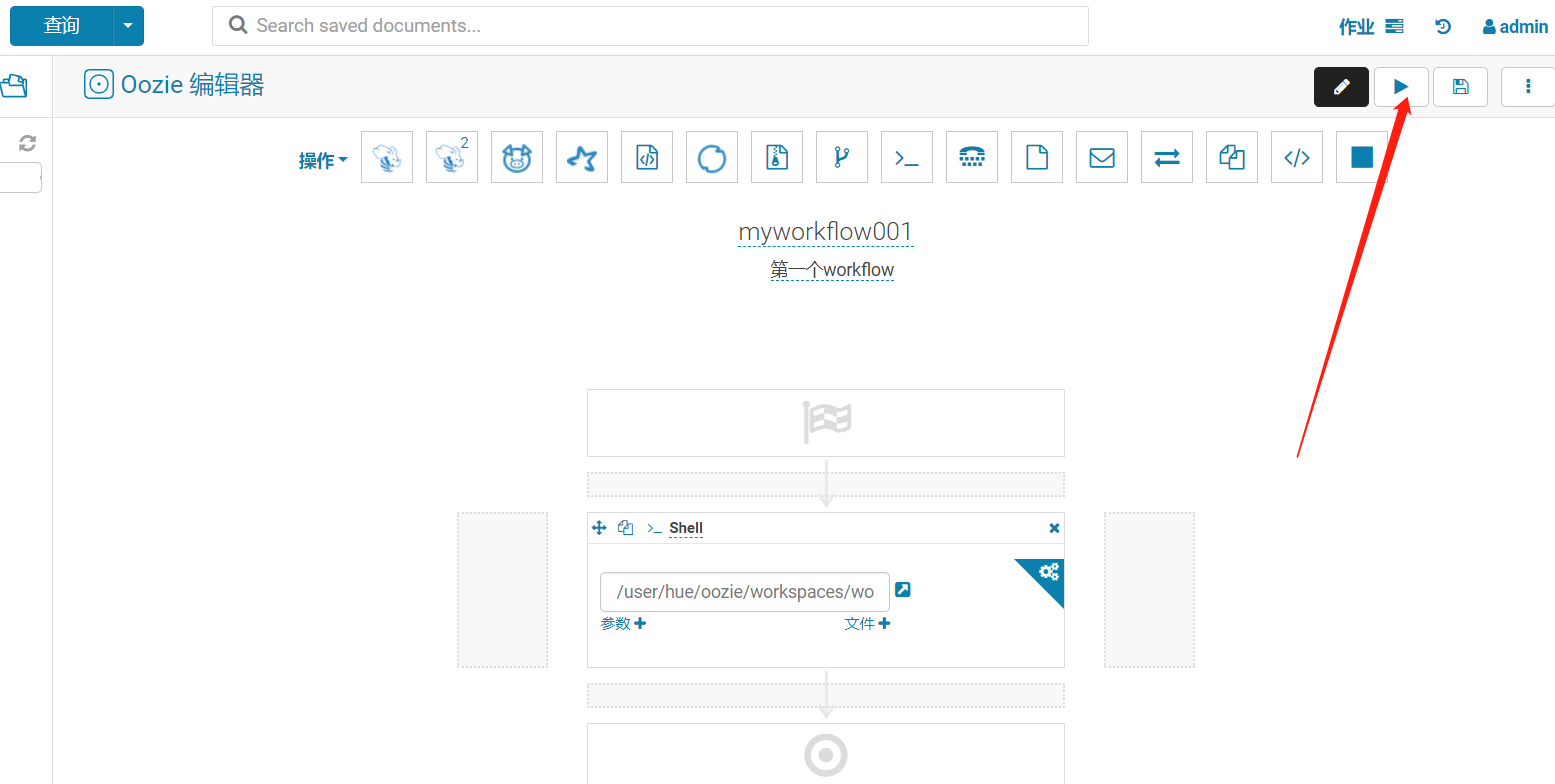

發現報錯了
WARN org.apache.oozie.command.wf.ActionStartXCommand: SERVER[hadoop-cdhslave02-168-182-163] USER[admin] GROUP[-] TOKEN[] APP[myworkflow001] JOB[0000003-220423133048789-oozie-oozi-W] ACTION[0000003-220423133048789-oozie-oozi-W@shell-52b4] Error starting action [shell-52b4]. ErrorType [TRANSIENT], ErrorCode [JA009], Message [JA009: Invalid resource request! Cannot allocate containers as requested resource is greater than maximum allowed allocation. Requested resource type=[memory-mb], Requested resource=<memory:2048, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:1024, vCores:4>
原因是 yarn配置的最大容器申請資源是1024M,oozie配置的啟動資源要2048M,在CM中修改oozie的相關配置。
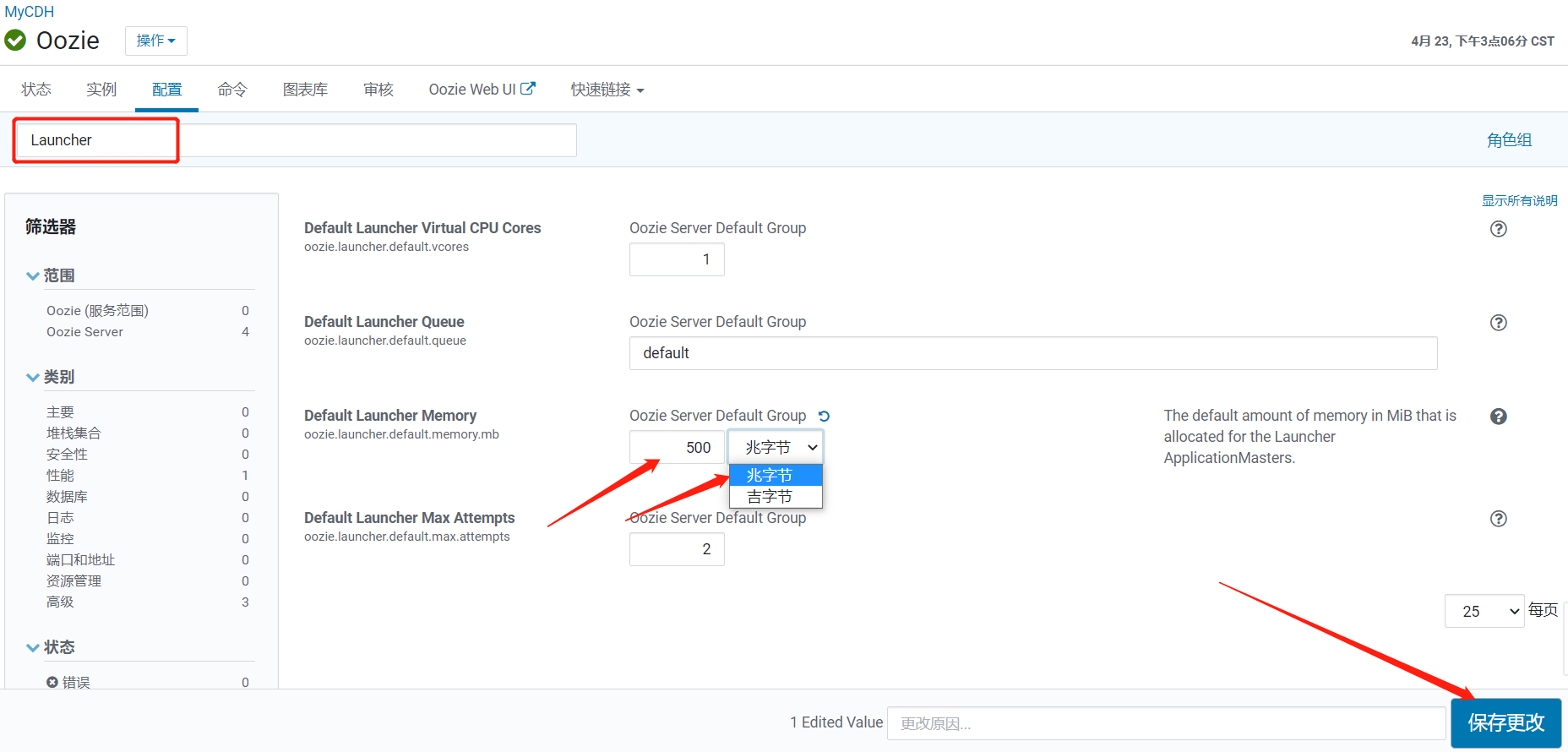
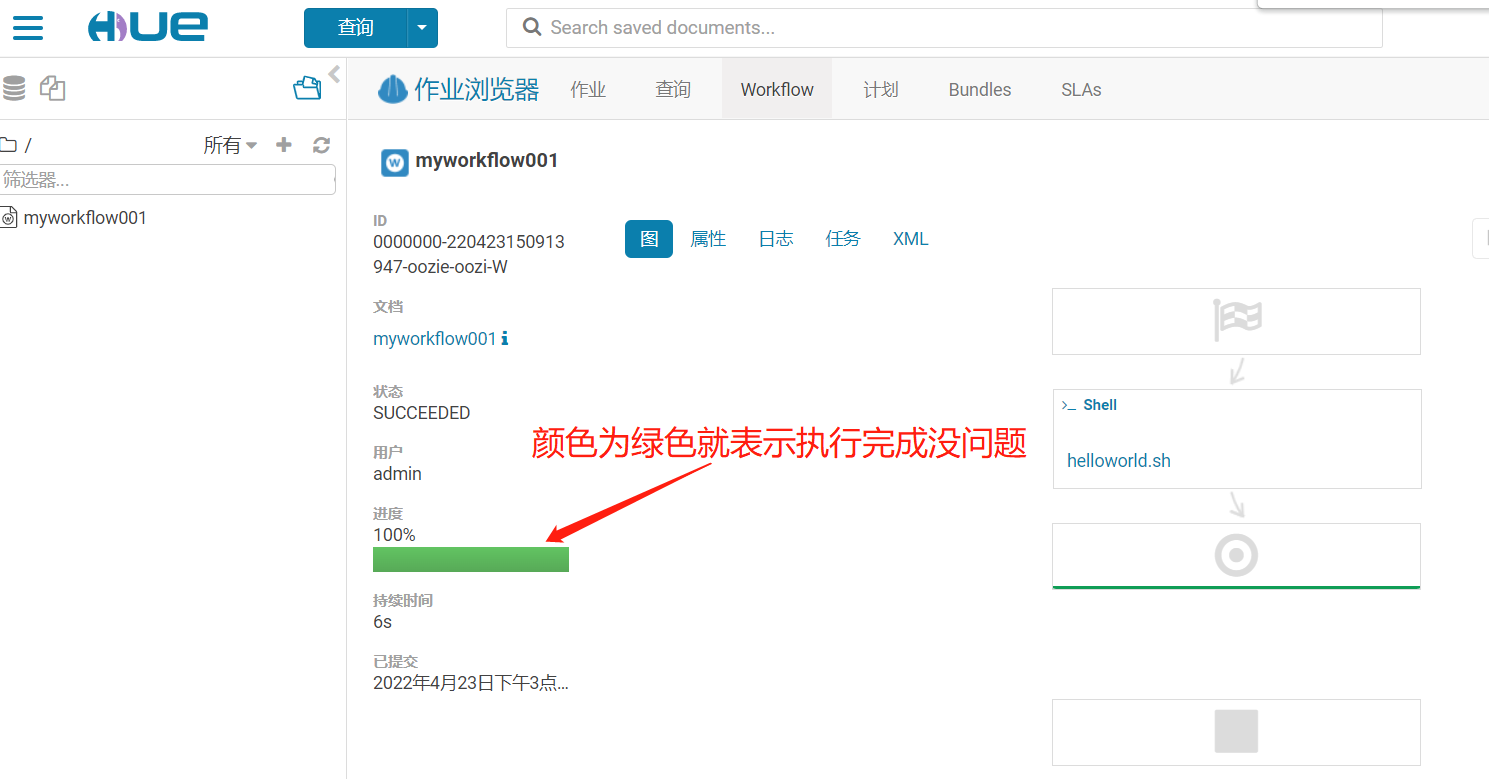
重啟服務後重新執行
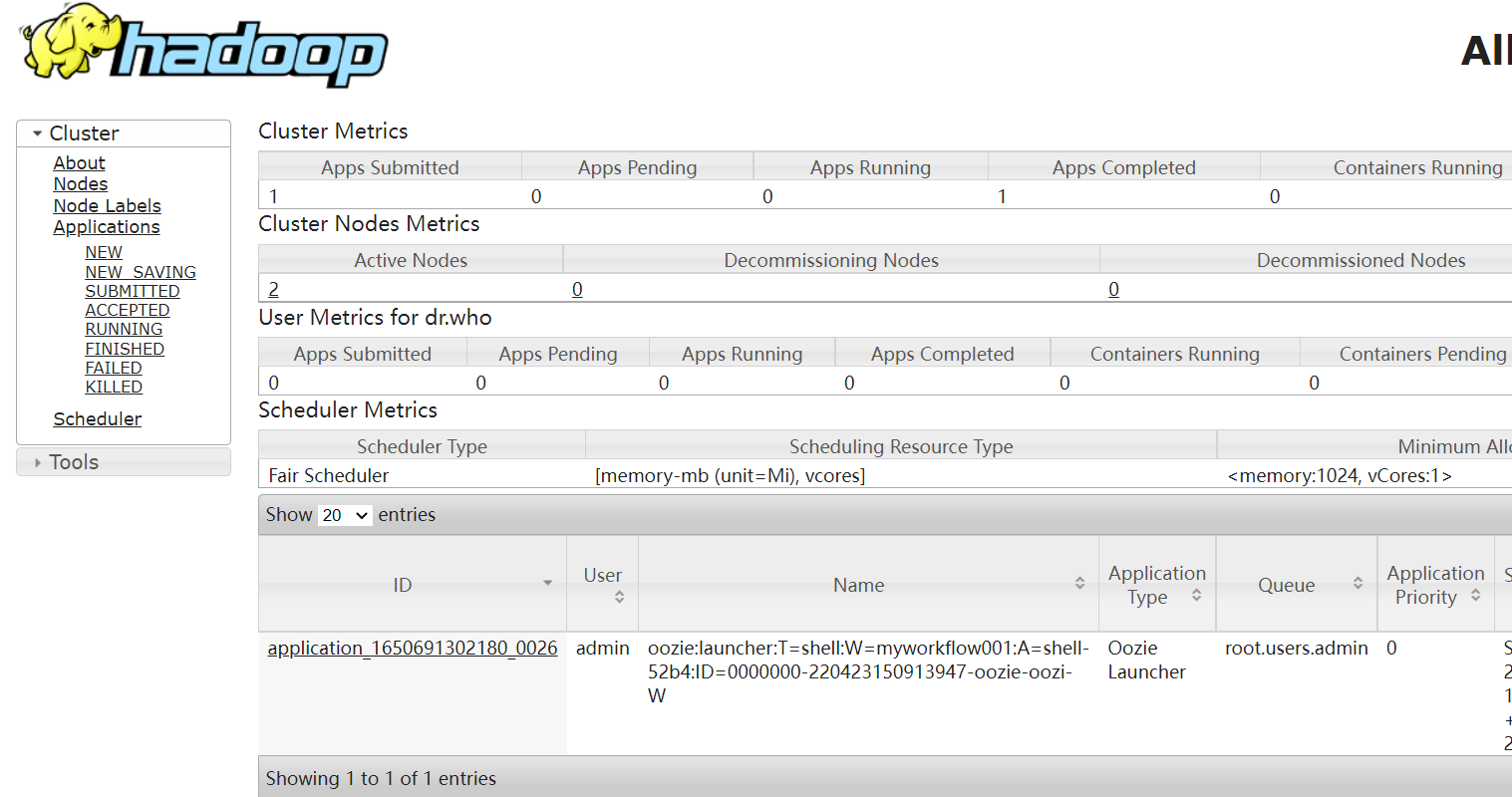
再去看Yarn任務
其實這裡只是加了一個任務,其實可以加很多任務,接下來就可自行擴展了
2、利用 Hue 調度 hive 腳本
sql文件
create database test001;
CREATE TABLE IF NOT EXISTS test001.person_1 (
id INT COMMENT 'ID',
name STRING COMMENT '名字',
age INT COMMENT '年齡',
likes ARRAY<STRING> COMMENT '愛好',
address MAP<STRING,STRING> COMMENT '地址'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
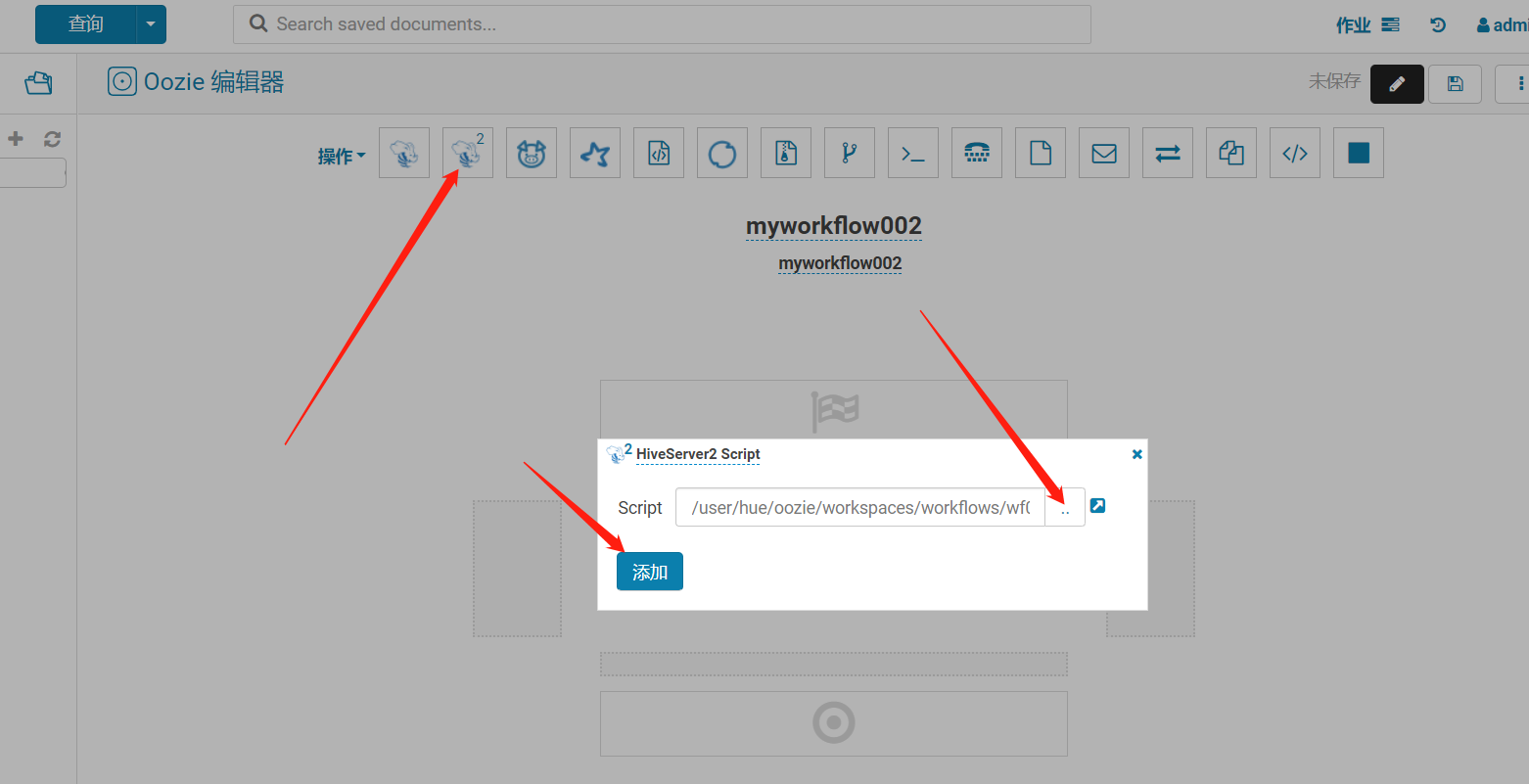
跟前面的步驟一樣,只是調度的任務不同和腳本不同而已,這裡就不再過多截圖介紹了。

通過beeline連接hive檢查
$ beeline -u jdbc:hive2://hadoop-cdhmaster-168-182-161:10000 -n root
show databases;
show tables from test001;
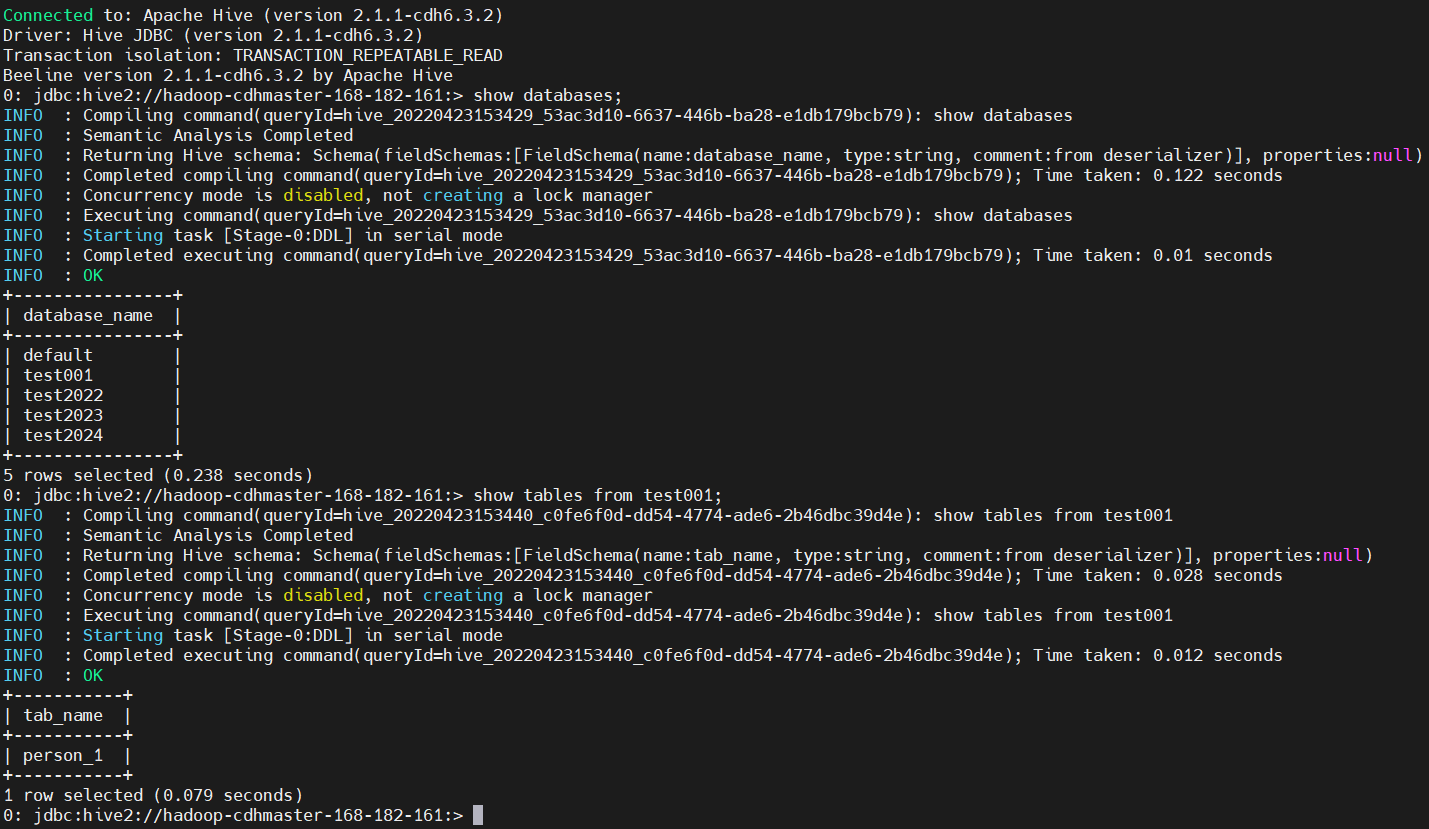
當然也對應有個yarn任務

3、 利用 Hue 配置定時調度任務
選擇workflow

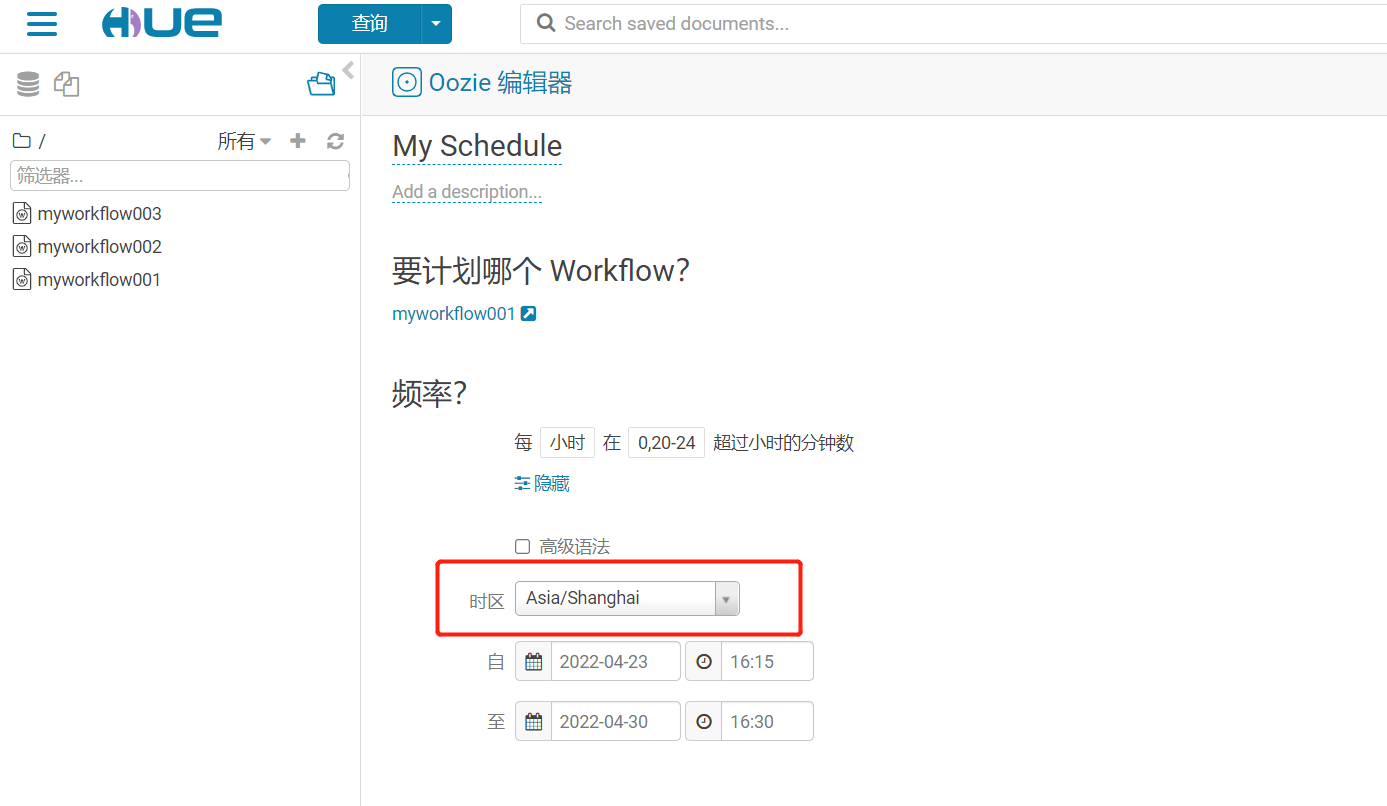
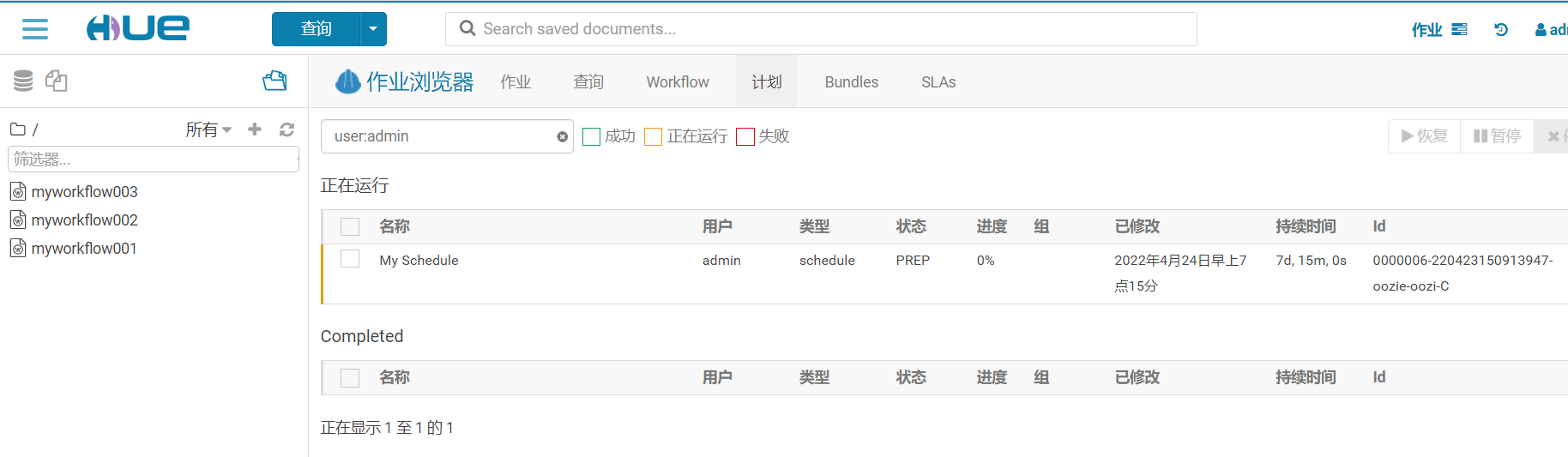
【溫馨提示】一定要註意時區的問題,否則調度就出錯了。保存之後就可以提交定時任務。
提交Schedule

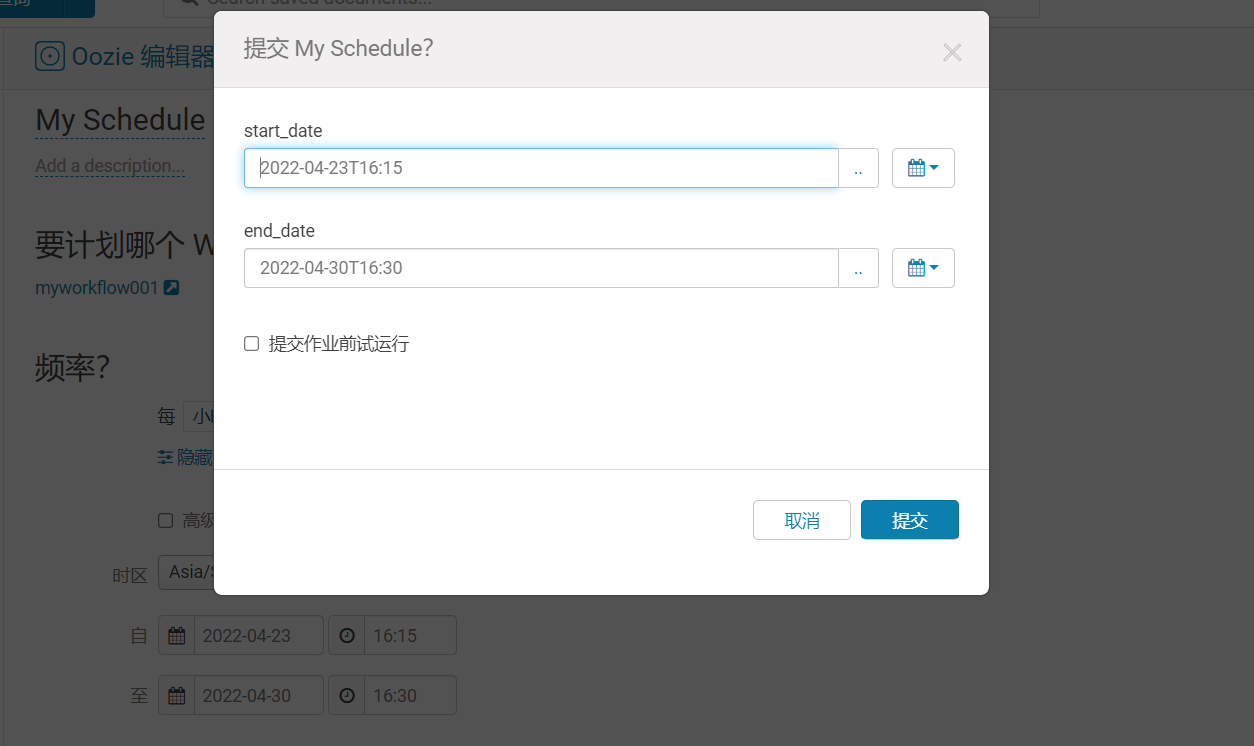
2)CLI操作Oozie
Oozie 提供了一個命令行實用程式oozie來執行作業和管理任務。所有操作都是通過oozie CLI 的子命令完成的。
一個Oozie 的 job 一般由以下文件組成:
job.properties:記錄了job的屬性workflow.xml:使用hPDL 定義任務的流程和分支腳本文件/lib目錄:用來執行具體的任務的文件
job.properties
| key | 含義 |
|---|---|
| nameNode | HDFS地址 |
| jobTracker | jobTracker(ResourceManager)地址 |
| queueName | Oozie隊列(預設填寫default) |
| examplesRoot | 全局目錄(預設填寫examples) |
| oozie.usr.system.libpath | 是否載入用戶lib目錄(true/false) |
| oozie.libpath | 用戶lib庫所在的位置 |
| oozie.wf.application.path | Oozie流程所在hdfs地址(workflow.xml所在的地址) |
| user.name | 當前用戶 |
| oozie.coord.application.path | Coordinator.xml地址(沒有可以不寫) |
| oozie.bundle.application.path | Bundle.xml地址(沒有可以不寫) |
【溫馨提示】這個文件如果是在本地通過命令行進行任務提交的話,這個文件在本地就可以了,當然也可以放在hdfs上,與workflow.xml和lib處於同一層級。
nameNode,jobTracker和oozie.wf.application.path在hdfs中的位置必須設置。
1、CLI 調度 shell 腳本
oozie官方提供的oozie-examples.tar.gz
這個包里也有:https://dlcdn.apache.org/oozie/5.2.1/oozie-5.2.1.tar.gz
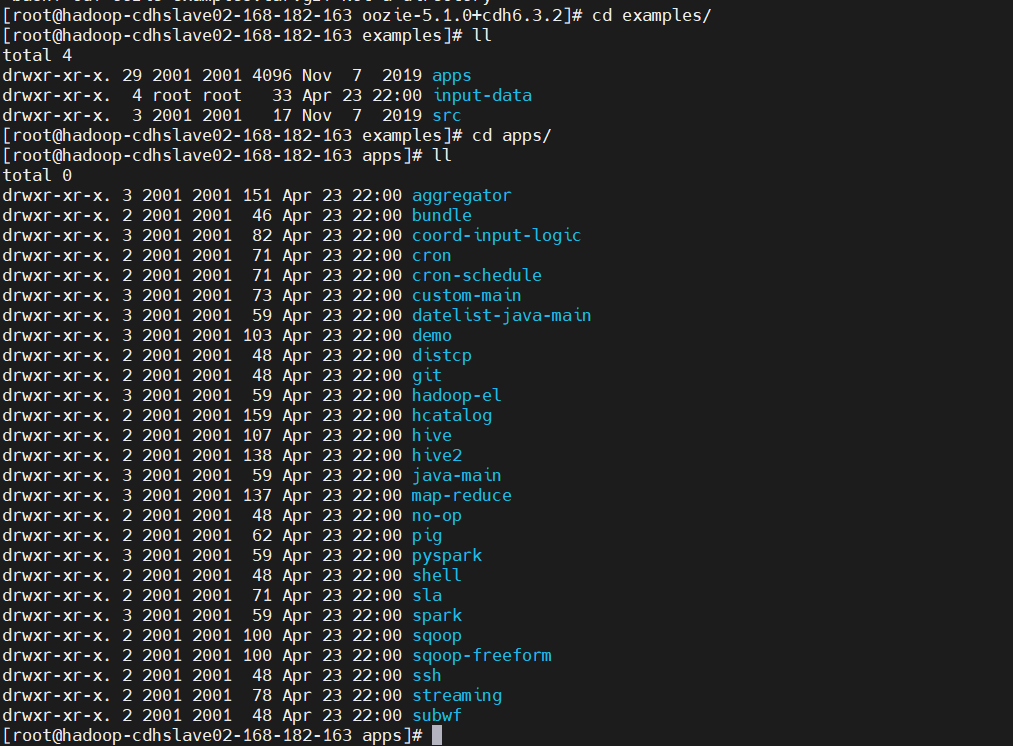
$ tar -xf oozie-examples.tar.gz
$ cd examples/apps/
$ ll
很多示例,這裡只演示幾個,其餘的小伙伴可以自行練習一下
進入到shell的示例目錄,發現有兩個配置文件job.properties,workflow.xml
$ cd shell
修改job.properties
# 配置hdfs,地址記得改成自己環境的
nameNode=hdfs://hadoop-cdhslave01-168-182-162:8020
# 配置yarn,8088是web埠,8032是yarn的服務埠號
resourceManager=hadoop-cdhslave01-168-182-162:8032
queueName=default
examplesRoot=examples
# HDFS腳本文件存放目錄
oozie.wf.application.path=${nameNode}/user/${user.name}/workflow/shell
# 定義腳本變數,也可以直接寫腳本名字
shellScript=helloworld.sh
修改workflow.xml
預設是echo輸出,這裡修改成執行腳本
<workflow-app xmlns="uri:oozie:workflow:1.0" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${shellScript}</exec>
<file>/user/oozie/workflow/shell/${shellScript}#${shellScript}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
腳本:helloworld.sh
#!/bin/bash
echo `date` " hello world" >> /tmp/helloworld.log
可以在job.properties定義一個變數,在workflow.xml中使用變數
把三個文件都上傳到/user/oozie/workflow/shell/目錄下
$ sudo -u oozie hadoop fs -mkdir -p /user/oozie/workflow/shell/
$ sudo -u oozie hadoop fs -put * /user/oozie/workflow/shell/
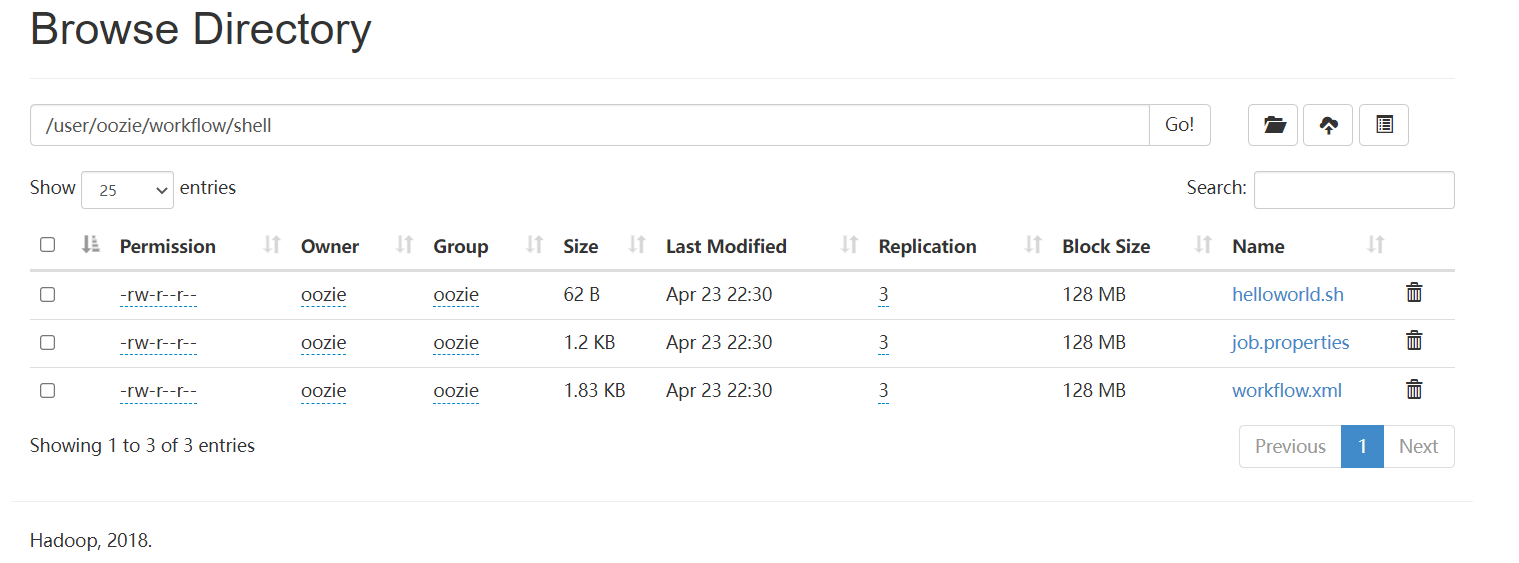
立即執行任務
$ sudo -u oozie /usr/bin/oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/ -config job.properties -run

Oozie web UI查看,登錄web時,發現有問題

Oozie web console is disabled.
To enable Oozie web console install the Ext JS library.
Refer to Oozie Quick Start documentation for details.
【Oozie web console is disabled 問題解決】
$ find /opt/ -name libext
$ cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/oozie/libext
$ wget http://archive.cloudera.com/gplextras/misc/ext-2.2.zip
$ sudo unzip ext-2.2.zip
$ sudo chown oozie:oozie -R ext-2.2
執行成功了
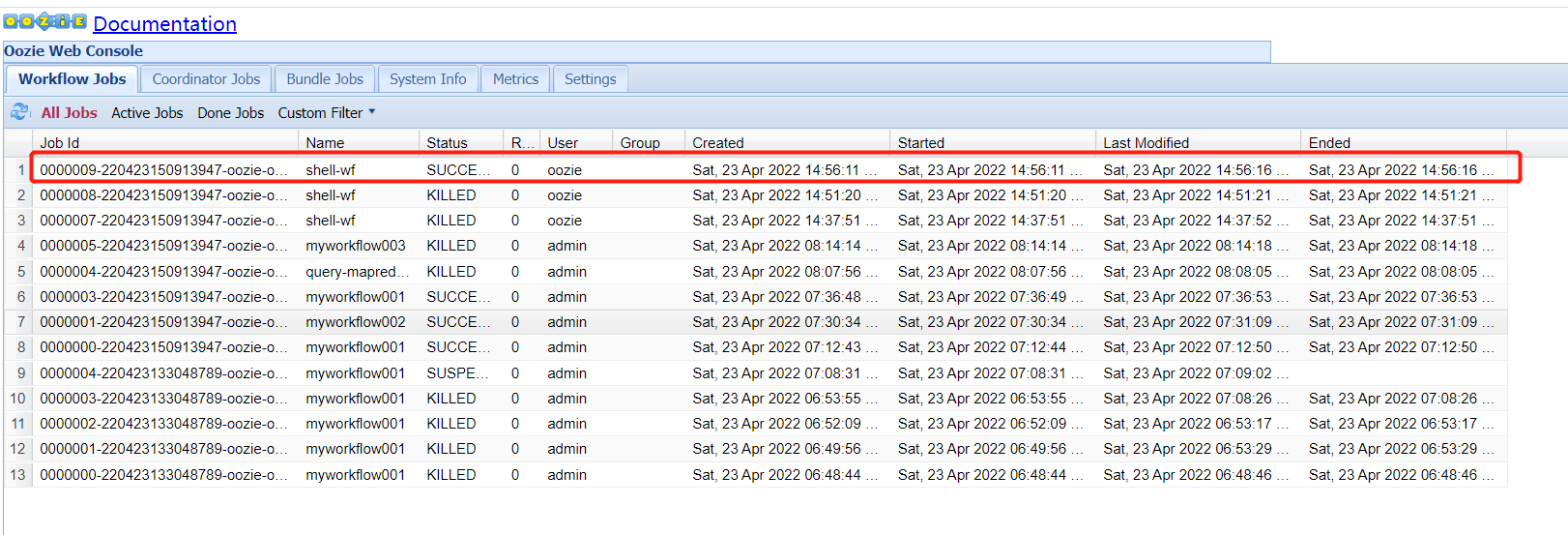
再去看一下yarn任務
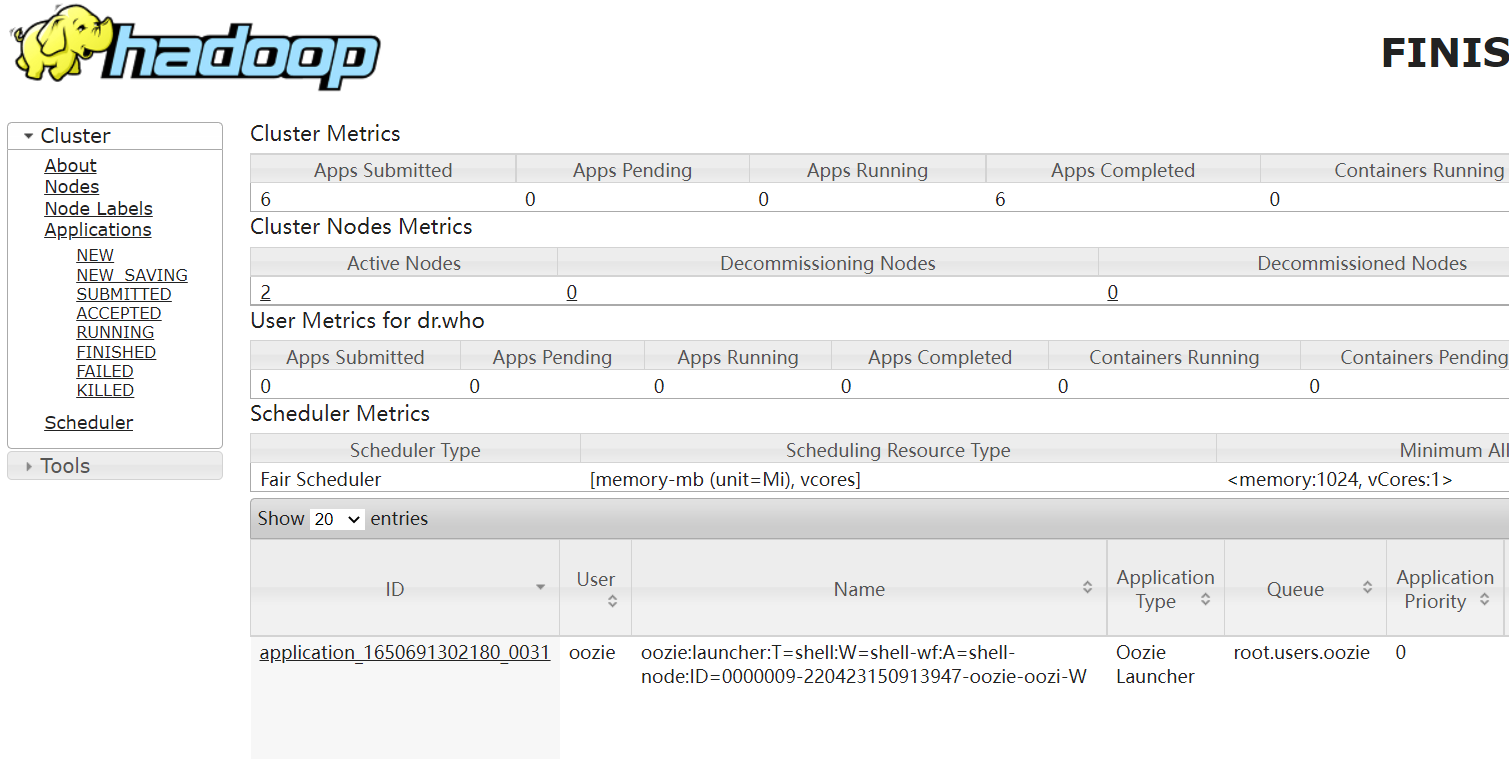
2、執行多個任務job
$ cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/share/doc/oozie-5.1.0+cdh6.3.2/examples/apps
# copy一份shell文件
$ cp -r shell shell02
$ cd shell02
新建一個shell腳本,test02.sh
#!/bin/bash
echo "test mutil workflow" >> /tmp/test02.log
修改job.properties
# 配置hdfs,地址記得改成自己環境的
nameNode=hdfs://hadoop-cdhslave01-168-182-162:8020
# 配置yarn,8088是web埠,8032是yarn的服務埠號
resourceManager=hadoop-cdhslave01-168-182-162:8032
queueName=default
examplesRoot=examples
# HDFS腳本文件存放目錄
oozie.wf.application.path=${nameNode}/user/${user.name}/workflow/shell
# 定義腳本變數,也可以直接寫腳本名字
shellScript=helloworld.sh
# 新增一個腳本變數
shellScript02=test02.sh
修改workflow.xml,新增一個action
<workflow-app xmlns="uri:oozie:workflow:1.0" name="shell-wf">
<start to="shell-node01"/>
<action name="shell-node01">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${shellScript}</exec>
<file>/user/oozie/workflow/shell/${shellScript}#${shellScript}</file>
<capture-output/>
</shell>
<ok to="shell-node02"/>
<error to="fail"/>
</action>
<action name="shell-node02">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${shellScript02}</exec>
<file>/user/oozie/workflow/shell/${shellScript02}#${shellScript02}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
強制覆蓋
$ sudo -u oozie hadoop fs -put -f * /user/oozie/workflow/shell/
執行任務
$ sudo -u oozie /usr/bin/oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/ -config job.properties -run


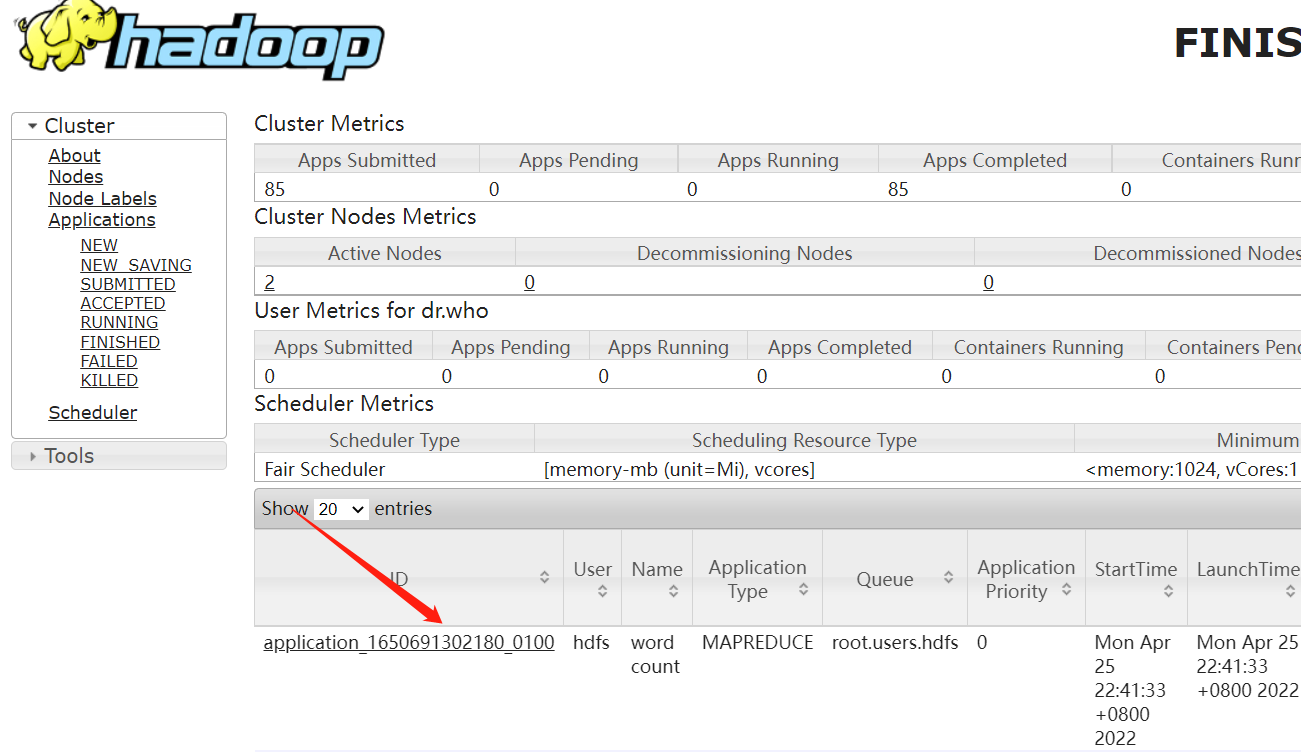
3、調度MR任務
直接使用官方模板修改(wordcount示例)
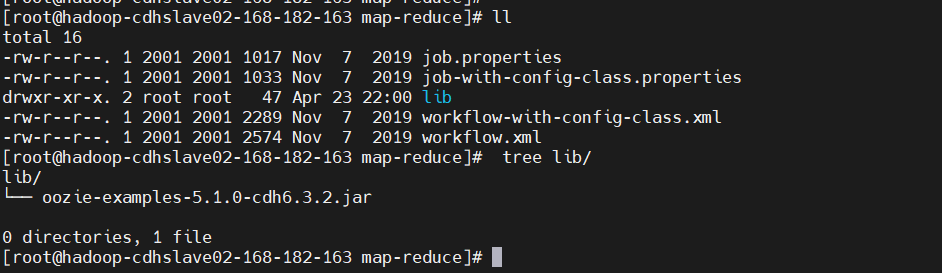
$ cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/share/doc/oozie-5.1.0+cdh6.3.2/examples/apps/map-reduce
$ ll
$ tree lib/
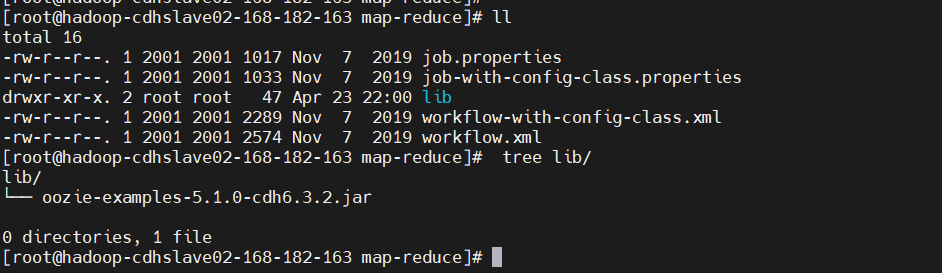
先用傳統方式驗證一把
$ cat>./wordcount.txt<< EOF
hello oozie
hello hadoop
hadoo oozie
hello world
hello bigdata
bigdata hadoop
hello flink
EOF
$ sudo -u hdfs hadoop fs -put wordcount.txt /
# 找到hadoop-mapreduce-examples*.jar包
$ find /opt/ -name hadoop-mapreduce-examples*.jar
$ sudo -u hdfs yarn jar /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hadoop-mapreduce-examples-3.0.0-cdh6.3.2.jar wordcount /wordcount.txt /out
配置workflow.xml
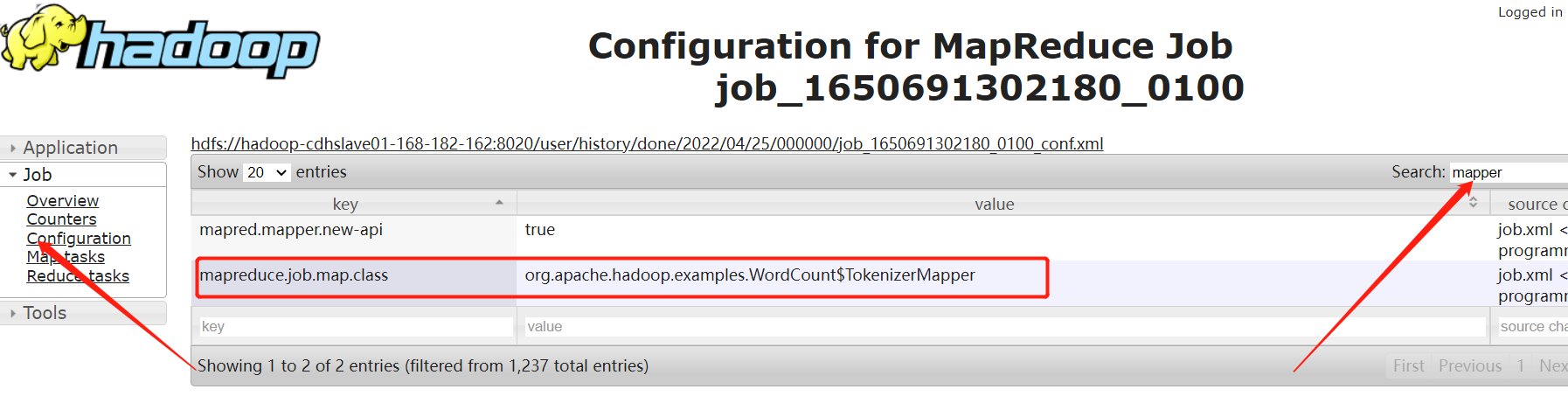
先在上面的跑的任務中查找map類和reduce
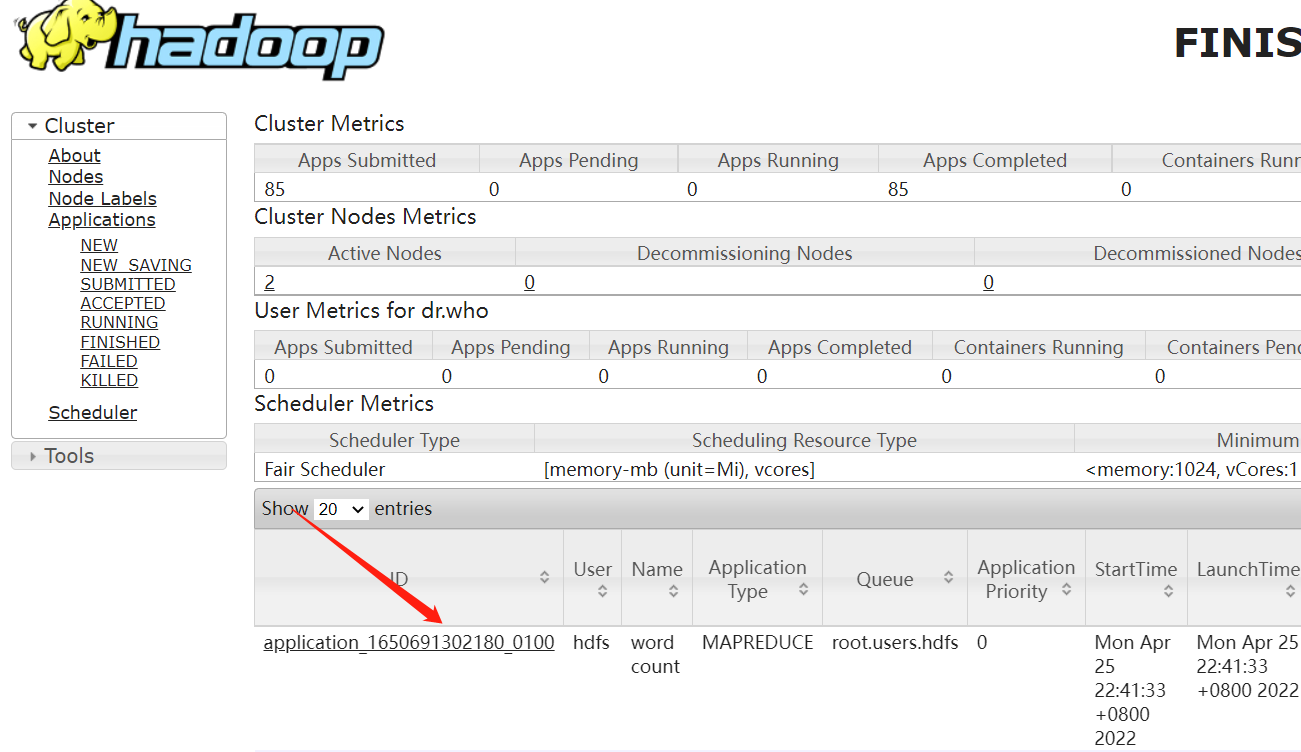
map類
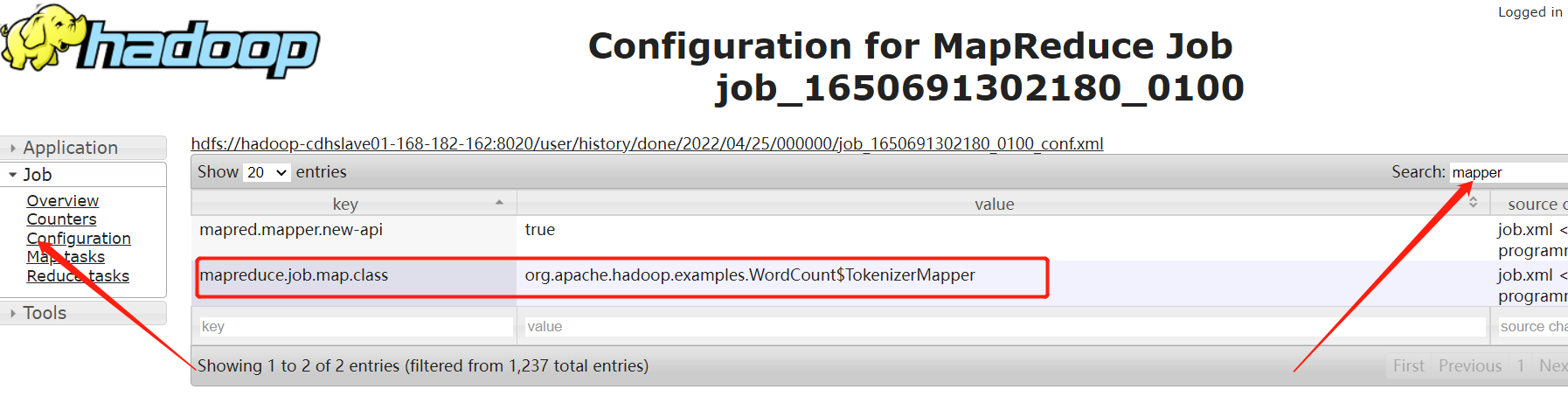
reduce類
修改後的workflow.xml內容如下:
<workflow-app xmlns="uri:oozie:workflow:1.0" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/oozie/workflow/map-reduce/output/"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!-- 配置MR調度任務時,設置使用新的API-->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定job key輸出類型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定job value輸出類型 -->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定輸入路徑 -->
<property>
<name>mapred.input.dir</name>
<value>/user/oozie/workflow/map-reduce/wordcount.txt</value>
</property>
<!-- 指定輸出路徑 -->
<property>
<name>mapred.output.dir</name>
<value>/user/oozie/workflow/map-reduce/output/</value>
</property>
<!-- 指定map類 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定reduce類 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
修改job.properties,內容如下:
# 配置hdfs,地址記得改成自己環境的
nameNode=hdfs://hadoop-cdhslave01-168-182-162:8020
# 配置yarn,8088是web埠,8032是yarn的服務埠號
resourceManager=hadoop-cdhslave01-168-182-162:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/${user.name}/workflow/map-reduce/workflow.xml
# 定義腳本變數,也可以直接寫腳本名字
outputDir=map-reduce
換掉lib下麵的jar包,使用新API
$ cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/share/doc/oozie-5.1.0+cdh6.3.2/examples/apps
$ cp /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hadoop-mapreduce-examples-3.0.0-cdh6.3.2.jar map-reduce/lib/
$ rm -f map-reduce/lib/oozie-examples-5.1.0-cdh6.3.2.jar
把map-reduce目錄推到HDFS上
$ sudo -u oozie hadoop fs -put -f map-reduce /user/oozie/workflow/

執行任務
$ sudo -u oozie /usr/bin/oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/ -config map-reduce/job.properties -run
登錄Oozie web UI:http://hadoop-cdhslave02-168-182-163:11000/oozie/

登錄yarn web查看任務
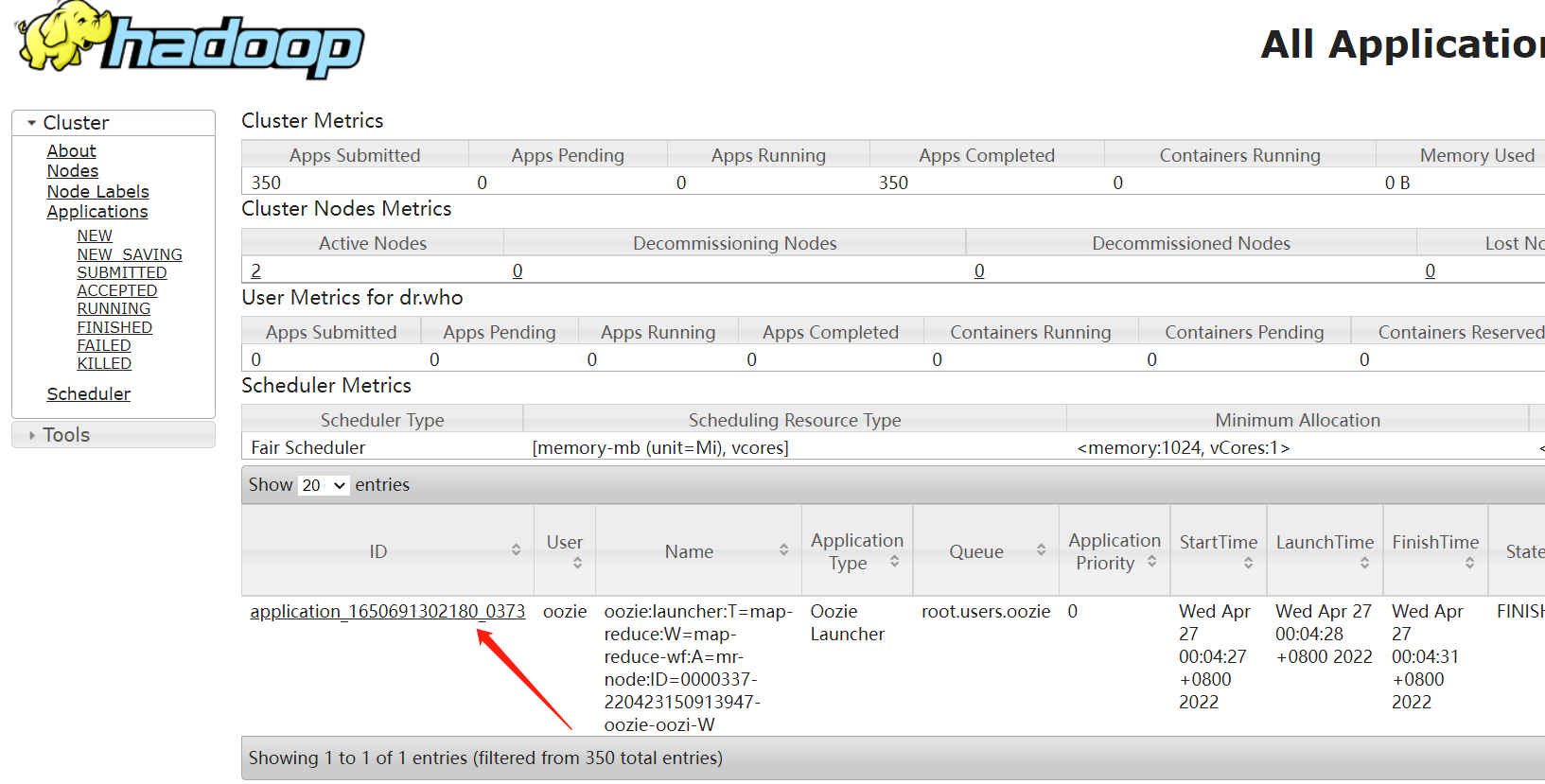
4、調度定時任務
$ cd /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/share/doc/oozie-5.1.0+cdh6.3.2/examples/apps
$ cd cron
修改job.properties,內容如下:
nameNode=hdfs://hadoop-cdhslave01-168-182-162:8020
resourceManager=hadoop-cdhslave01-168-182-162:8032
queueName=default
examplesRoot=examples
oozie.coord.application.path=${nameNode}/user/${user.name}/workflow/cron
# start必須設置未來時間,否則任務會失敗
start=2022-04-27T23:30Z
end=2022-04-29T01:00Z
workflowAppUri=${nameNode}/user/${user.name}/workflow/cron
shellScript=test001.sh
修改workflow.xml,其實也是上面第一個示例
<workflow-app xmlns="uri:oozie:workflow:1.0" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${shellScript}</exec>
<file>/user/oozie/workflow/cron/${shellScript}#${shellScript}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
修改coordinator.xml,內容如下:
frequency頻率最低五分鐘,時區調整為中國時區
<coordinator-app name="cron-coord" frequency="${coord:minutes(5)}" start="${start}" end="${end}" timezone="GMT+0800"
xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>resourceManager</name>
<value>${resourceManager}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
把cron整個目錄推送到HDFS
$ cd ..
$ sudo -u oozie hadoop fs -put cron /user/oozie/workflow/
執行
$ sudo -u oozie /usr/bin/oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/ -config cron/job.properties -run
3)Java API操作Oozie
1、編輯好shell腳本和workflow.xml文件
$ mkdir -p /opt/test/oozie/workflow/shell
$ vi /opt/test/oozie/workflow/shell/ooziehello.sh
#!/bin/bash
name=$1
echo "hello $name" >> /tmp/oozieshell.log
$ vi /opt/test/oozie/workflow/shell/workflow.xml
<workflow-app xmlns="uri:oozie:workflow:1.0" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${shellScript}</exec>
<file>/user/oozie/workflow/oozieshell/${shellScript}#${shellScript}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
3、把上面兩個文件上傳到HDFS
$ sudo -u oozie hadoop fs -mkdir /user/oozie/workflow/oozieshell/
$ sudo -u oozie hadoop fs -put * /user/oozie/workflow/oozieshell/
4、代碼執行提交任務
package com.bigdata;
/**
* workflow shell test
*/
import org.apache.oozie.client.OozieClient;
import org.apache.oozie.client.WorkflowAction;
import org.apache.oozie.client.WorkflowJob;
import java.util.List;
import java.util.Properties;
public class WorkFlowShellTest {
public static void main(String[] args) {
System.setProperty("user.name", "oozie");
OozieClient oozieClient = new OozieClient("http://hadoop-cdhslave02-168-182-163:11000/oozie/");
try {
System.out.println(oozieClient.getServerBuildVersion());
Properties properties = oozieClient.createConfiguration();
properties.put("oozie.wf.application.path", "${nameNode}/user/${user.name}/workflow/oozieshell");
properties.put("queueName", "default");
properties.put("nameNode", "hdfs://hadoop-cdhslave01-168-182-162:8020");
properties.put("resourceManager", "hadoop-cdhslave01-168-182-162:8032");
properties.put("shellScript", "ooziehello.sh");
properties.put("argument", "oozie");
//運行workflow
String jobid = oozieClient.run(properties);
System.out.println("jobid:" + jobid);
//根據workflow id獲取作業運行情況
WorkflowJob workflowJob = oozieClient.getJobInfo(jobid);
//獲取作業日誌
System.out.println(oozieClient.getJobLog(jobid));
//獲取workflow中所有ACTION
List<WorkflowAction> list = workflowJob.getActions();
for (WorkflowAction action : list) {
//輸出每個Action的 Appid 即Yarn的Application ID
System.out.println(action.getExternalId());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
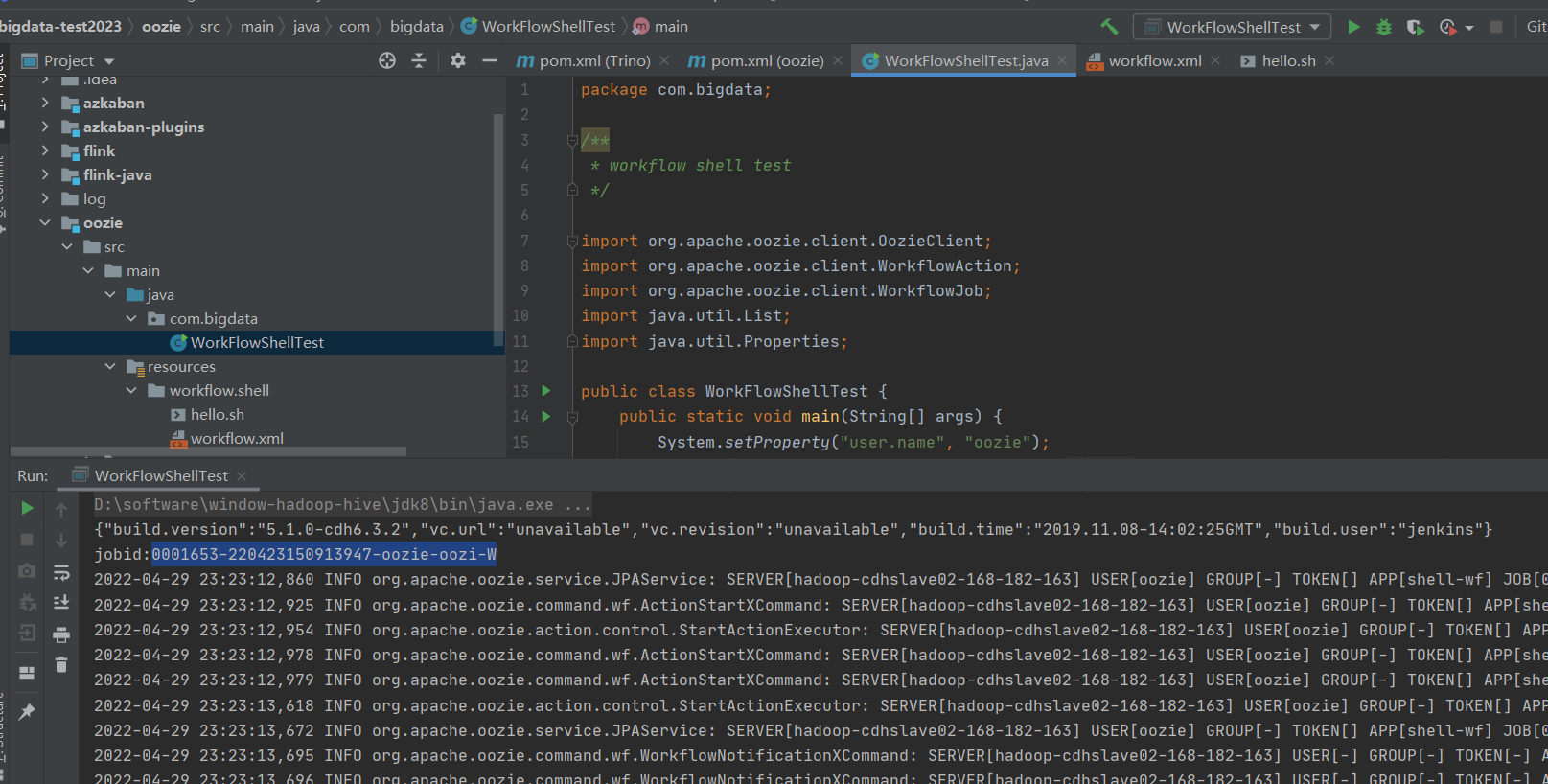

其它的示例也類似,就是把之前的job.properties,用java格式載入,運行,查詢,其它都一樣。所以其它示例就由小伙伴自行練習了。
六、常用命令
# 啟動
$ oozied.sh start
# 停止
$ oozied.sh stop
# 提交任務並啟動任務(submit和start命令合併)
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie -config job.properties –run
# 提交任務不啟動
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie -config job.properties –submit
# 啟動任務
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie -start 0001837-220423150913947-oozie-oozi-W
### workflow任務
# 查看所有workflow任務
$ oozie jobs
# 查看信息
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie -info 0001837-220423150913947-oozie-oozi-W
# 查看日誌
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie -log 0001837-220423150913947-oozie-oozi-W
# Kill任務
$ oozie job -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/ -kill 0001831-220423150913947-oozie-oozi-W
# 或者下麵這句
$ oozie job -kill 0001831-220423150913947-oozie-oozi-W
### coordinator 定時任務
# 查看定時任務
$ oozie jobs -jobtype coordinator -oozie http://hadoop-cdhslave02-168-182-163:11000/oozie/
$ oozie jobs -jobtype coordinator
# 刪除定時任務
$ oozie job -kill 0000345-220423150913947-oozie-oozi-C
七、Oozie與Azkaban對比
| 對比指標 | Azkaban | Oozie |
|---|---|---|
| 功能 | Azkaban與Oozie均可以調度mapreduce、pig、java腳本工作流任務;Azkaban與Oozie均可以定時執行工作流任務。 | 與Azkaban 一樣 |
| 工作流傳參 | Azkaban支持直接傳參,例如${input}。 | Oozie支持參數和EL表達式,例如${fs:dirSize(myInputDir)}。 |
| 定時執行 | Azkaban的定時執行任務是基於時間的。 | Oozie的定時執行任務是基於時間和輸入數據資源管理。 |
| 工作流執行 | Azkaban有兩種運行模式,分別是solo server mode(executor server和web server部署在同⼀台節點)和multi server mode(executor server和web server可以部署在不同節點)。 | Oozie作為工作流服務運行,支持多用戶和多工作流。 |
綜上所述,Oozie相比Azkaban是一個重量級的任務調度系統,功能全面,但配置使用也更複雜(xml)。如果可以不在意某些功能的缺失,輕量級調度Azkaban是很不錯的候選對象。所以如果不是用CDH,還是使用Azkaban方便簡單~
關於Azkaban,可以參考我之前的文章:
大數據Hadoop之——任務調度器Azkaban(Azkaban環境部署)
大數據Hadoop之——Azkaban API詳解
關於Oozie的概述和簡單使用就到這結束了,如果小伙伴有疑問,歡迎給我留言,未完待續,請耐心等待~

