
分享嘉賓:牟娜 阿裡巴巴 高級演算法工程師 編輯整理:孫鍇 內容來源:DataFun AI Talk《定向廣告新一代點擊率預估主模型——深度興趣演化網路》 出品社區:DataFun 導讀: 本次帶給大家分享是阿裡媽媽在2018年做的模型上的創新——深度興趣演化網路(Deep Interest Evol ...
分享嘉賓:牟娜 阿裡巴巴 高級演算法工程師
編輯整理:孫鍇
內容來源:DataFun AI Talk《定向廣告新一代點擊率預估主模型——深度興趣演化網路》
出品社區:DataFun
導讀: 本次帶給大家分享是阿裡媽媽在2018年做的模型上的創新——深度興趣演化網路(Deep Interest Evolution Network),分享將從以下幾個方面展開——
-
提出該模型的背景及原因
-
該模型的結構詳解
-
該模型的最終效果
--
01 背景
#1、業務形態

在介紹該模型創新背景之前,先來看一下我們的業務形態:當我們打開淘寶的時候,首先呈現的是一個banner形式的廣告;在首頁猜你喜歡場景下,或者購物鏈路的其他場景下,會出現一些單品的廣告:在推薦的商品瀏覽列表,即信息流場景下,會在列表中穿插廣告投放,且投放位置固定,這些廣告將和正常推薦瀏覽的商品一起呈現出來。
tips:如果廣告的形態特別明顯,會破壞用戶的體驗,比如瀏覽的順暢感。所以,推薦用戶感興趣的東西,使得用戶感覺不到廣告的存在,是十分重要的。
在一般的廣告建模里,通常根據廣告信息、用戶信息、上下文信息,去判斷用戶是否會點擊這個廣告。區別於搜索廣告這種用戶帶有明顯意圖的主動的query查詢行為,在展示廣告業務場景下,用戶並沒有明確的意圖。此時,應當如何建模,用戶會有什麼樣的興趣,瞭解並解決這些問題,對我們工作非常重要。
2、簡單模型
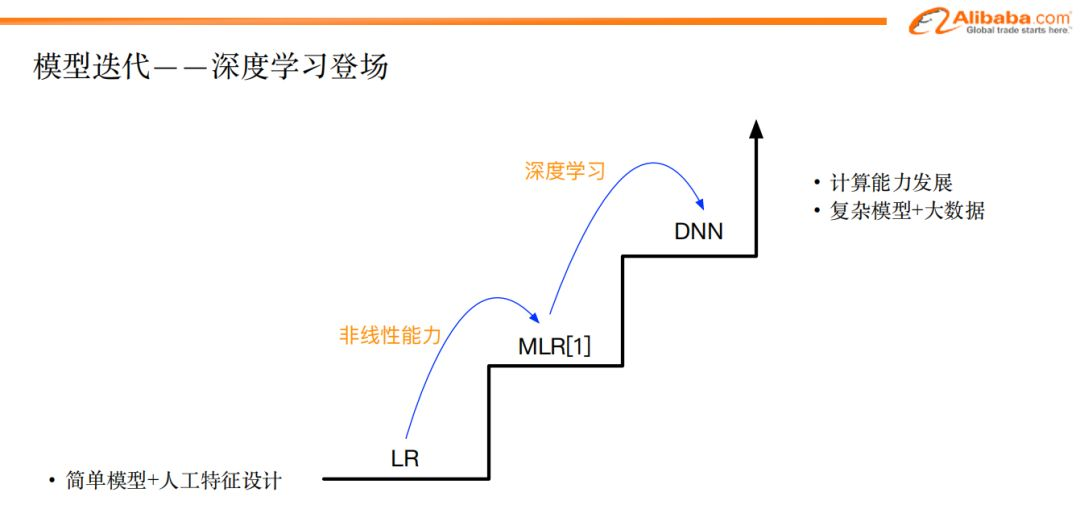
從模型的視角來看,早期的模型形態為:簡單模型+複雜的人工設計特征。很多公司在初期都是這樣的形式:LR模型+非常複雜的特征工程。
而隨著電腦的性能的提升,大家能夠利用的數據和計算資源也越來越多的時候,我們便嘗試把挖掘潛在特征的工作交給模型來做,這就是深度學習出場的過程。
在LR時代,我們團隊做了一些嘗試,其中一個是引入了MLR模型,即:把LR模型分成多片,每片建模一部分數據,此方式相當於引入一部分非線性能力。在這個過程中,我們發現,與只用LR相比,MLR模型引入的這部分非線性,對我們的最終效果產生了明顯的提升。
在2016年的時候,我們團隊開始嘗試引入深度學習來解決ctr提升的問題。
3、神經網路
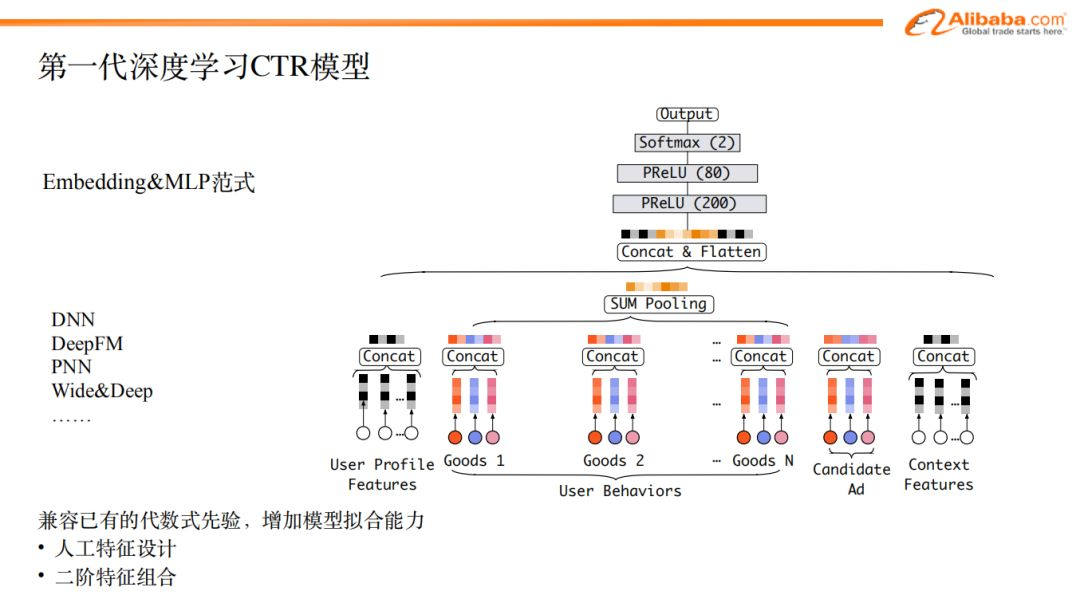
第一代神經網路ctr模型如圖所示,第一層是非常簡單的原生特征,包括:用戶特征,候選廣告特征,上下文特征。這些特征在經過lookup的方式做embedding之後,被concat一起,送入多層的dnn網路,最後做一個softmax。這是一個最基礎的ctr神經網路模型。
在這種最簡單的dnn模型基礎之上,衍生出了非常多的其他的模型,比如DeepFm,做一些特征之間的交叉;pnn也是;然後是deep&wide模型,其中的deep部分可以通過多層MLP學習數據中的非線性規律,同時設計了wide部分以復用傳統淺層模型時代保留下來的豐富的人工設計特征。
tips:模型演進的路線:增強泛化能力、保留記憶能力、挖掘組合關係。

然而上述通用的設計,還不足以應對我們的業務場景,因為淘寶的用戶個性化程度非常高,千人千面,每個人看的東西都不一樣,每個人的興趣點也不一樣,行為非常豐富,所以一些簡單的神經網路模型,單靠增加人工設計的特征或者簡單的代數式先驗設計,在我們的場景下太過於低效了,還不足以把用戶的興趣挖掘的特別透徹。
如圖所示,根據用戶的歷史行為,我們看到用戶的興趣點是非常寬泛並且雜亂的。此時,在通用的Embedding&MLP範式下設計出的模型,是無法針對用戶豐富多樣的興趣,做出特別操作的,僅僅是把所有行為的Embedding sum在一起作為用戶的歷史行為表達。而這一操作存在大量信息損失。
tips:這裡需要強調的是,用戶行為的多樣性,反映了用戶興趣的多樣性,即每個人感興趣的物品、種類是很多的,尤其是在淘寶這樣綜合性的購物網站。
此外,興趣本身也會隨著時間逐漸演化,前面提到的模型對於這種包含演化信息的數據,就更加無能為力了。
tips:大家可以想象一下,自己在網路上購物,比如買衣服的時候,一年前喜歡的風格和現在喜歡的風格可能是不一樣的,是存在一個逐漸演變的過程的,如果用前面提出的模型,會把這種逐漸演變的信息丟失掉。
面對這些問題,我們提出了對模型的改造。
4、深度興趣網路
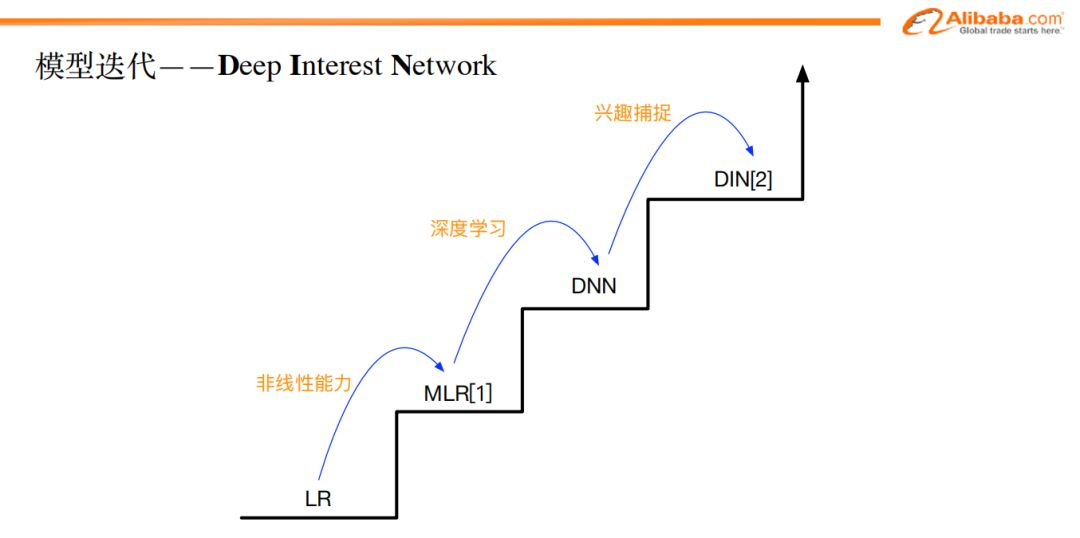
針對用戶的興趣信息的挖掘,我們邁出的第一步對模型的改造是DIN(Deep Interest Network),這是我們在2017年展開的主要工作。

雖然說用戶的興趣是多種多樣的,但是我們回過頭看一下我們的ctr預估要解決的是什麼問題。我們是在給定一個候選廣告和用戶的情況下,去預測點擊的結果。當候選廣告給定的時候,我們可以用候選廣告去反向激活歷史行為中的商品,把跟廣告相關的商品拉出來,計算用戶的興趣可能是什麼。我們利用了候選廣告集,最終通過反向激活挖掘出歷史行為中與候選廣告相關的興趣。
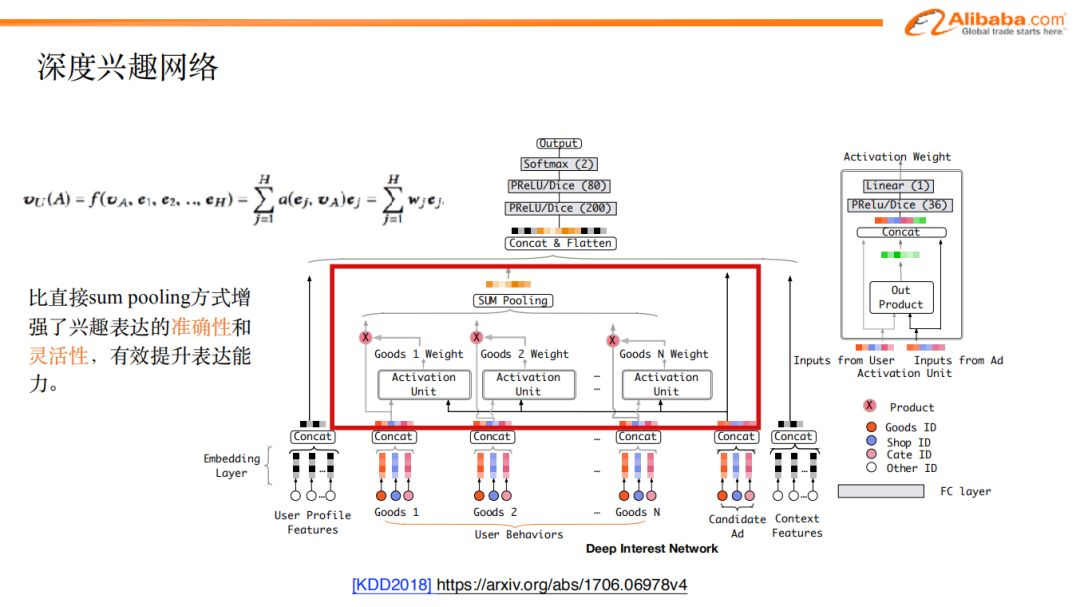
具體的模型設計如圖:通過候選廣告,用反向激活的方式,與用戶歷史行為相關聯,按照候選廣告與歷史點擊商品的相關性的高低,來賦予歷史行為不同的權重。通過這種方式獲取到和當前廣告相關的歷史行為表達向量以及對應的相關權重,做weighted sum pooling之後,就得到了跟候選廣告相關的用戶興趣向量表達。這種方式比直接對所有歷史行為做sum pooling增加了興趣表達的靈活性,同時,隨著候選廣告的不同,該方式也會得到不同的興趣表達。

如圖是一個基於din所得到不同歷史行為中包含的廣告的權重的例子。候選廣告是羽絨服,我們看到歷史行為集中衣服相關的廣告權重較高,而杯子之類的廣告相關性很低。這個例子我們也可以看到din的優點。但是,從剛纔的過程中,我們也發現到din還是有一些不足, 這個模型忽略了興趣隨著時間之間演化這樣一個重要的性質。
同樣一件羽絨服,你會發現以前喜歡的款式和現在喜歡的款式會發生一些變化。

那麼在2018年,我們的工作重點就是針對這樣一個興趣隨時間演化的特點來進行建模以及模型的改造。
--
02 深度興趣演化網路
由此引出DIEN(Deep Interest Evolution Netowork)。

首先,用戶的興趣隨時間演化這樣一個特點,做過深度學習的同學們會容易想到序列建模,即把歷史行為按時間序列鋪開做序列建模。這樣一個直觀的想法,我們當然也做過嘗試,但是效果並不理想。
如圖是一個用戶的真實足跡,用戶在看窗帘,突然買了別的產品;用戶在看旅游產品,突然買了貓咪用品。
tips:選購旅游產品的時間線一般拉的比較長,因此選購期間難免會看一些日常的其他商品。
這樣一個行為序列是一個雜亂無章的過程,這樣的序列與自然語言處理遇到的有序序列是完全不同的,在這樣的場景下,序列被打斷是一個常規行為。因此單純的序列建模在這種場景下會失敗就不難理解了。用戶的興趣是隱藏在雜亂無章的行為序列背後的,針對這樣的情況,我們提出了新的解決方案。

我們已知:用戶的興趣隱藏在行為之後,雖然行為雜亂無章,透過行為,我們發現,其實興趣的表達要比行為的表達更為穩定的。
當我們提取了興趣表達之後,還需要對興趣隨時間演化的趨勢進行建模。
因此我們將這些問題歸納、抽象、並最終設計了兩個模塊:興趣提取模塊、興趣演化模塊。
1、興趣提取模塊
關於興趣提取模塊:

假設用戶瀏覽了一條褲子,那麼褲子id是一個特征,該特征對於推薦系統來說是一個較為隨機的特征,然而這個id類特征代表的物品的背後,比如用戶是喜歡這個褲子的顏色、樣式、功能等某些特點,這些特點是我們希望興趣提取模塊可以獲取到的,也即,找到與這些隨機特征相關聯的泛化特征,併進行建模。
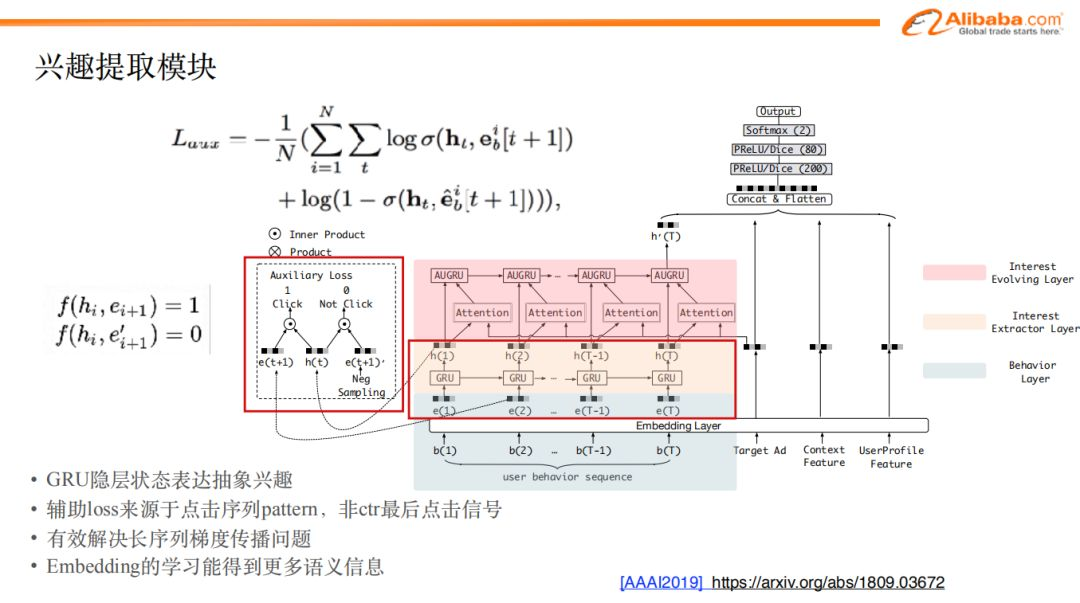
如圖我們可以看到,在embedding層之後,我們對用戶特征,上下文特征,廣告特征的處理方式並沒有改變。而行為序列特征做embedding之後,我們增加了興趣提取模塊。
由於我們的目標是挖掘商品背後的興趣表達,用戶某一時刻的興趣,不僅與當前的行為相關,也與歷史各個時刻的行為相關,因此,我們決定使用GRU模型來對歷史行為序列建模,並提取興趣特征。
tips:我們用GRU代替LSTM是因為在效果相差無幾的前提下,前者比後者要節省更多的參數。在神經網路模型整體結構非常複雜的大前提下,我們會儘量將每一個模塊簡單化、輕量化。
通過GRU提取出隱層狀態的表達,我們認為這是對用戶興趣的抽象。除了使用GRU之外,我們還引入了輔助loss的功能,用來輔助提取興趣表達。
tips:引入輔助loss的原因在於:原始的GRU所提取的隱層狀態的表達,受到最後時刻的興趣的影響程度更高一些,而歷史時刻的興趣隨著時間越來越遠,會被模型慢慢遺忘。輔助loss將所有歷史時刻的loss疊加,學習時可以學到更多歷史興趣特征。
並且,由於輔助loss的數據的來源是全網的點擊信息,而不僅僅是廣告樣本的點擊,這樣會增加很多額外的信息,會更好的刻畫用戶在全網的興趣。
輔助loss的作用有三點:
- 輔助loss利用的label反饋是點擊序列pattern而不僅僅是ctr信號;
- 能有效解決長序列梯度傳播問題,因為在現實場景中,用戶興趣序列有可能非常長,若直接用GRU,沒有輔助loss,則會面臨長序列梯度消失問題;
- 通過點擊pattern的學習,出來hidden state能學的更好,Embedding通過反向傳播也能學到更多語義表達,使得學習更加有效。
輔助loss的構建方式:我們將歷史行為序列中的有點擊行為的樣本label標記為1,有曝光無點擊行為的樣本label標記為0併進行負採樣,組合後送入GRU模型,並構建輔助的loss信號,與最終的loss相加後進行學習。
2、興趣演化模塊
在興趣演化模塊,回想我們的業務場景,有兩點值得註意:
- 用戶行為的隨機跳轉較多,無規律可言;
- 具體到某個興趣,存在隨時間演化的趨勢。
那麼我們有沒有辦法使我們的模型可以有區別對待這些歷史行為,然後只關註與候選廣告相關性較強演化。這就是興趣演化模塊引入的背景。
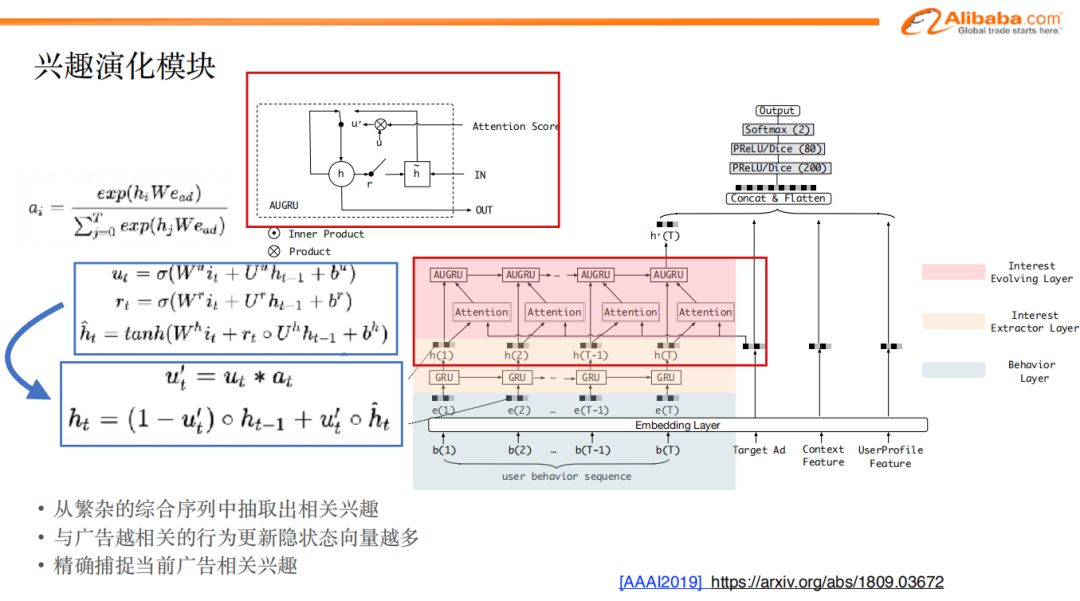
現在的狀態如下:
- 由於候選廣告已經給定,而我們也只關心跟候選廣告相關的興趣點;
- 在歷史行為序列經過GRU之後,用戶的興趣表達已經提取出來了。
此刻,我們開始針對性的對演化過程進行建模。
首先是加入attention機制,根據與候選廣告的相關性,對歷史序列里的商品進行加權;以此得到attention score。
在attention機制之後,再加入一層改進的GRU,稱之為AUGRU。
tips:引入該模型的原因在於,在AUGRU裡面,我們使用attention score來控制update門的權重,這樣既保留了原始的更新方向,又能根據與候選廣告的相關程度來控制隱層狀態的更新力度。
舉個極端的例子:假如該時刻的行為與候選廣告相關度為1,我們希望這個行為能更新用戶興趣的隱狀態即h(t)=f(h(t-1), i_t),而當行為與候選廣告不相關的時候我們要保留當前狀態,即:h(t)=h(t-1)。
假如我們不採用這種改進的GRU方式,而直接把attention score乘在每個興趣向量上作為下一層普通GRU的輸入的話, 這種做法會直接影響了輸入的scale,而不是準確的控制什麼時候該更新,更新的程度和方向是怎麼樣的,因此可能存在信息的損失。
還是舉個極端的例子:假如某行為與候選廣告不相關,那麼隱狀態的更新是h(t)=f(h(t-1), 0), 0向量並不會不更新,而是會將hidden state更新到一個新的地方去,這並不是我們期望的。
通過attention機制,我們得以從繁雜的商品中選取相關的興趣,並通過AUGRU模型,最終更精準的得到廣告的相關興趣。
--
03 效果
1、離線效果
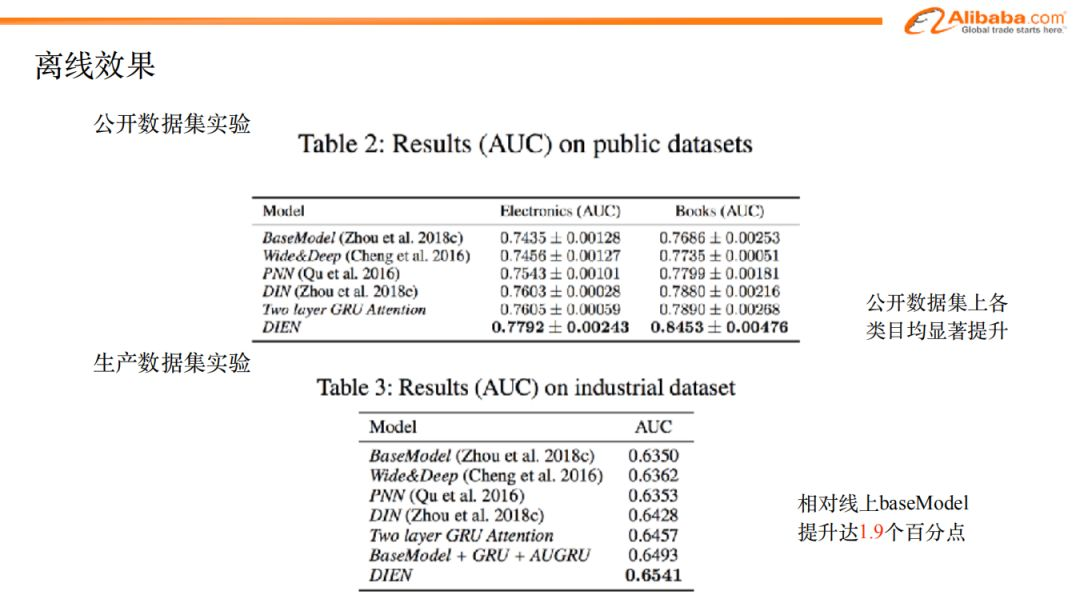
最後,我們給大家介紹一下實際的效果。這個模型不僅在生產任務上取得了良好的效果,在學術界也取得了不錯的成果。
如圖,上半部分是我們在公開數據集(來自於亞馬遜商城)上所做的實驗。我們對電子產品、書籍兩個類目的數據用不同的模型做了實驗。可以看出來,DIEN模型的效果是最好的。
圖中下半部分是生產任務數據集的實驗,我們採用了和公開數據集相同的模型,圖中也可以看出,DIEN在列出的模型中,表現也是最優的,而且相對base_model,AUC提升了1.9個百分點。
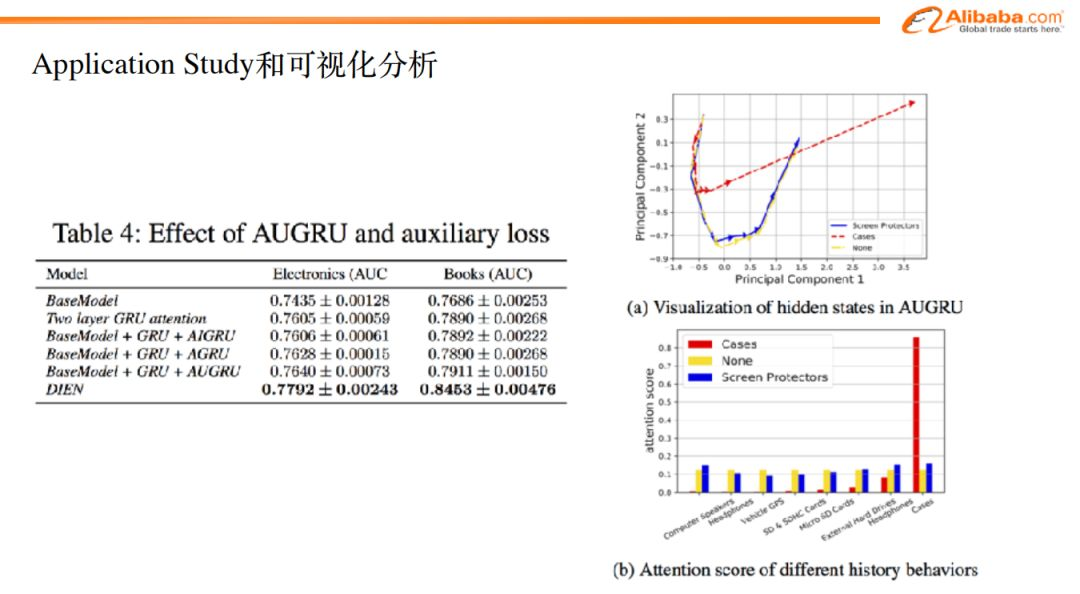
在公開數據集上,我們將不同步驟進行了拆分,可以看到每個模塊的提升效果。
2、線上效果

我們通過A/B test 觀察了一個月的數據,平均帶來了17%的ecpm提升,帶來了巨大的商業價值。
今天的分享就到這裡,謝謝大家。
閱讀更多技術原創文章,請關註微信公眾號“DataFunTalk”。
本文首發於微信公眾號“DataFunTalk”。


