
hive 存儲格式有很多,但常用的一般是 TextFile、ORC、Parquet 格式,在我們單位最多的也是這三種 hive 預設的文件存儲格式是 TextFile。 除 TextFile 外的其他格式的表不能直接從本地文件導入數據,要先導入到 TextFile 格式的表中,再從表中用 inser ...
hive 存儲格式有很多,但常用的一般是 TextFile、ORC、Parquet 格式,在我們單位最多的也是這三種
hive 預設的文件存儲格式是 TextFile。
除 TextFile 外的其他格式的表不能直接從本地文件導入數據,要先導入到 TextFile 格式的表中,再從表中用 insert 導入到其他格式的表中。
一、TextFile
TextFile 是行式存儲。
建表時無需指定,一般預設這種格式,以這種格式存儲的文件,可以直接在 HDFS 上 cat 查看數據。
可以用任意分隔符對列分割,建表時需要指定分隔符。
不會對文件進行壓縮,因此載入數據的時候會比較快,因為不需要解壓縮;但也因此更占用存儲空間。
二、ORCFile
ORCFile 是列式存儲。
建表時需指定 STORED AS ORC,文件存儲方式為二進位文件。
Orc表支持None、Zlib、Snappy壓縮,預設支持Zlib壓縮。
Zlib 壓縮率比 Snappy 高,Snappy 效率比 Zlib 高。
這幾種壓縮方式都不支持文件分割,所以壓縮後的文件在執行 Map 操作時只會被一個任務所讀取。
因此若壓縮文件較大,處理該文件的時間比處理其它普通文件的時間要長,造成數據傾斜。
另外,hive 建事務表需要指定為 orc 存儲格式。
ORC 格式如下所示:
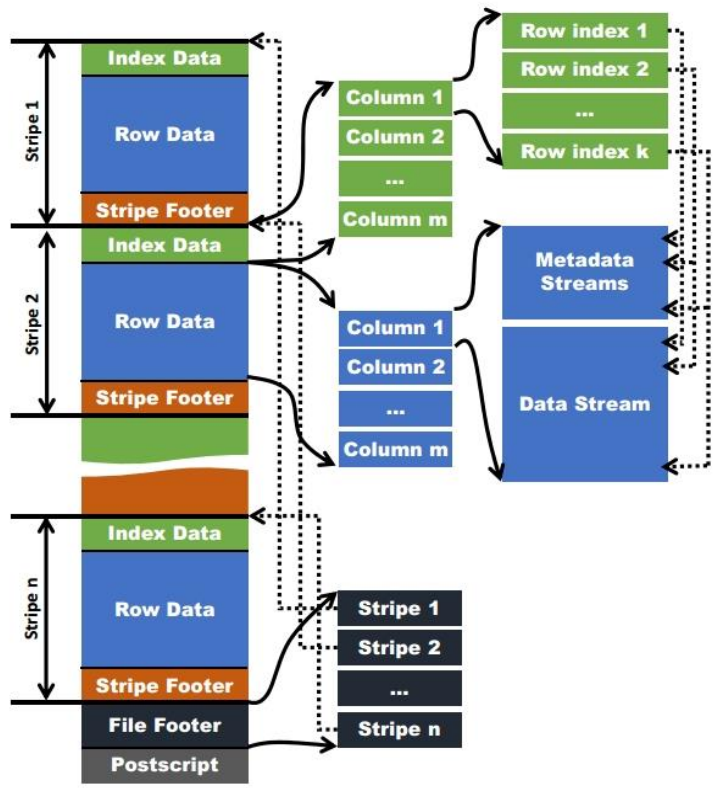
- stripe:存儲數據的地方,包括實際數據、數據的索引信息
- index data:保存了數據在 stripe 中位置的索引信息
- rows data:數據實際存儲的地方,數據以流的形式進行存儲
- stripe footer:保存數據所在的文件目錄
- file footer:包含了文件中 stripe 的列表,每個 stripe 的行數,以及每個列的數據類型。它還包含每個列的最小值、最大值、行計數、求和等聚合信息。
- postscript:含有壓縮參數和壓縮大小相關的信息
三、Parquet
Parquet 也是列式存儲。
建表時需指定 STORED AS PARQUET,文件存儲方式為二進位文件。
可以使用的壓縮方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO。預設值為 UNCOMPRESSED,表示頁的壓縮方式
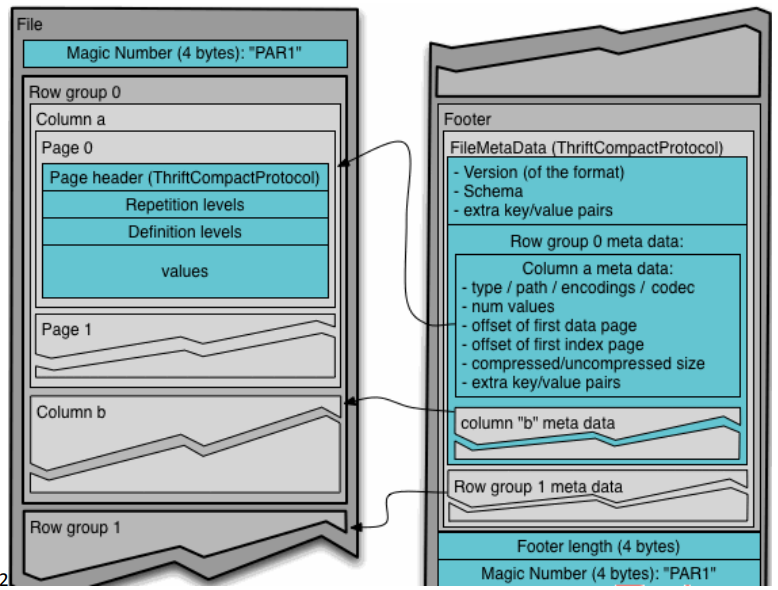
-
行組(Row Group):每一個行組包含一定的行數,在一個HDFS文件中至少存儲一個行組,類似於orc的stripe的概念。
-
列塊(Column Chunk):在一個行組中每一列保存在一個列塊中,行組中的所有列連續的存儲在這個行組文件中。一個列塊中的值都是相同類型的,不同的列塊可能使用不同的演算法進行壓縮。
四、三者對比
同樣的數據,TextFile 為 2.4G 的情況下,將原數據存放為 ORC 以及 Parquet 格式後,其占用存儲大小以及查詢效率大致如下:
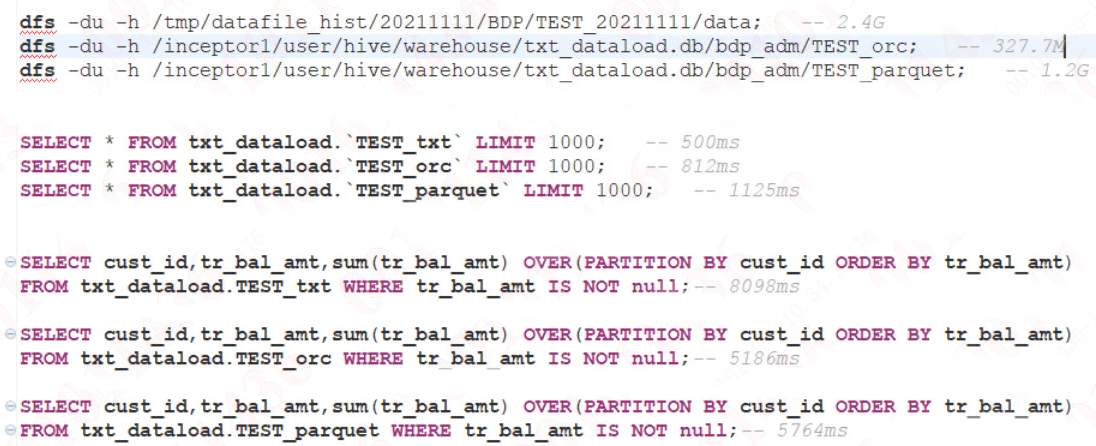
由此可以看出壓縮比:ORC > Parquet > TextFile
在只有 Fecth 的情況下,由於 TextFile 不需要解壓縮,因此效率較高。
對於需要 MapReduce 操作的查詢,效率:ORC >= Parquet > TextFile
當然,這隻是我自己簡單的測試,有些變數並沒有控制好。
比如在單個文件比較大的情況下,可能 Parquet 的效率會比較高。
在實際生產中,使用 Parquet 存儲 lzo 壓縮的方式比較常見,這種情況下可以避免由於讀取不可分割的大文件引發的數據傾斜。
但是,如果數據量並不大,使用 ORC 存儲 snappy 壓縮的效率還是非常高的;對於需要事務的場景,還是用 ORC。
至於要用哪種存儲格式,需要基於自身業務進行考量。
今天的文章到這裡就結束了,如果覺得寫的不錯的話,可以隨手點個贊和關註!
關註“大數據的奇妙冒險”,轉載請註明出處!


