
一、概述 Impala 直接針對存儲在 HDFS、HBase或 Amazon Simple Storage Service (S3)中的 Apache Hadoop 數據提供快速的互動式 SQL 查詢。Impala是一個基於Hive、分散式、大規模並行處理(MPP:Massively Paralle ...
目錄
一、概述
Impala 直接針對存儲在 HDFS、HBase或 Amazon Simple Storage Service (S3)中的 Apache Hadoop 數據提供快速的互動式 SQL 查詢。Impala是一個基於Hive、分散式、大規模並行處理(MPP:Massively Parallel Processing)的資料庫引擎。除了使用相同的統一存儲平臺外,Impala 還使用與 Apache Hive 相同的元數據、SQL 語法(Hive SQL)、ODBC 驅動程式和用戶界面(Hue 中的 Impala 查詢 UI)。關於Hive的介紹,可以看我之前的文章:大數據Hadoop之——數據倉庫Hive。Impala官方文檔
- Impala 是可用於查詢大數據的工具的補充。Impala 不會替代基於 MapReduce 構建的批處理框架,例如 Hive。Hive 和其他基於 MapReduce 構建的框架最適合長時間運行的批處理作業,例如涉及提取、轉換和載入 (ETL) 類型作業的批處理。
- Impala 於 2017 年 11 月 15 日從 Apache 孵化器畢業。在文檔中以前稱為“Cloudera Impala”的地方,現在正式名稱為“Apache Impala”。
1)Impala優點
- 基於記憶體運算,不需要把中間結果寫入磁碟,省掉了大量的I/O開銷。
- 無需轉換為Mapreduce,直接訪問存儲在HDFS, HBase中的數據進行作業調度,速度快。
- 使用了支持Data locality的I/O調度機制,儘可能地將數據和計算分配在同一臺機器上進行,減少了網路開銷。
- 支持各種文件格式,如TEXTFILE、SEQUENCEFILE、RCFile. Parqueto
- 可以訪問hive的metastore,對hive數據直接做數據分析。
2)Impala缺點
- 對記憶體的依賴大,且完全依賴於hive。
- 實踐中,分區超過1萬,性能嚴重下降。
- 只能讀取文本文件,而不能直接讀取自定義二進位文件。
- 每當新的記錄/文件被添加到HDFS中的數據目錄時,該表需要被刷新。
二、Impala架構
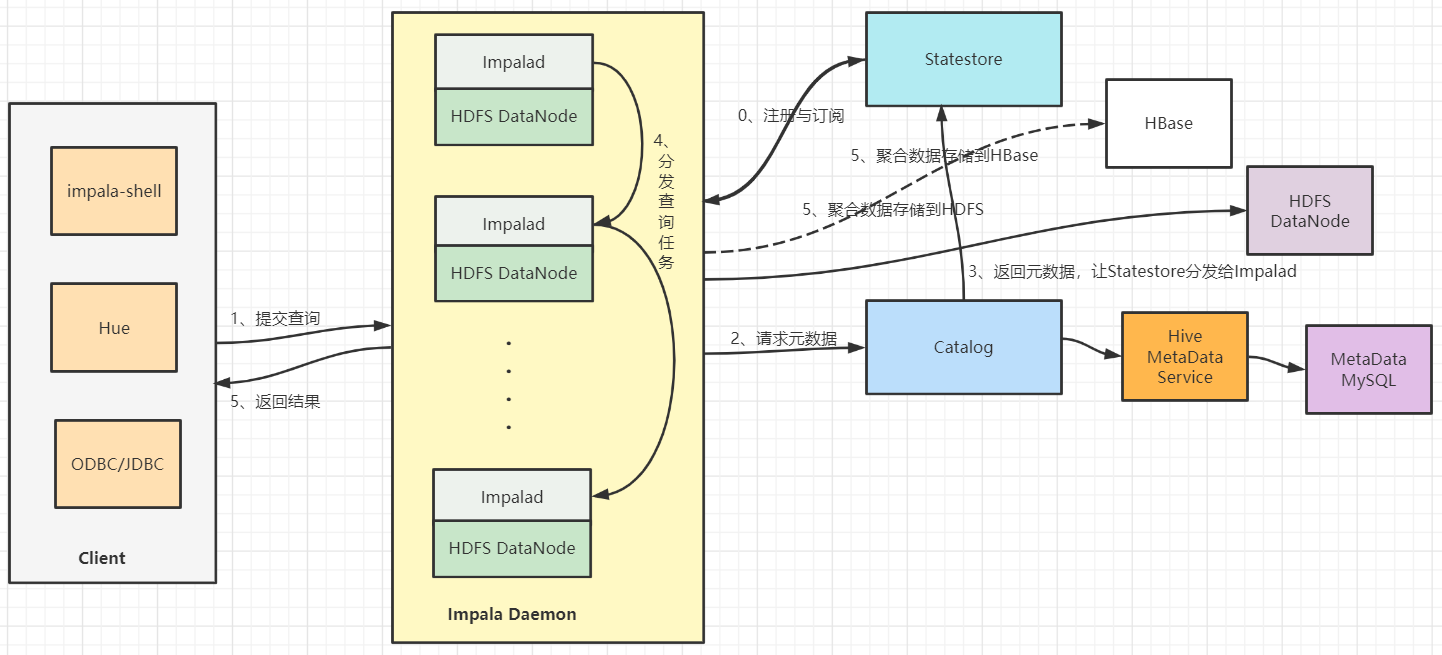
1)Impala組件組成
一張圖帶你瞭解全貌:
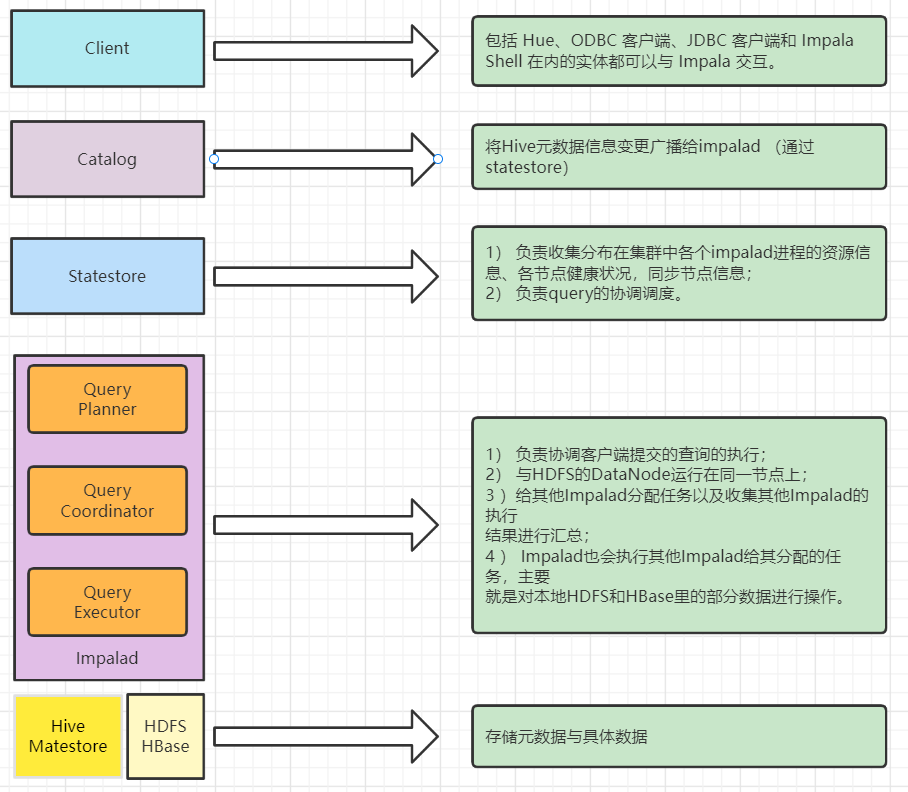
下麵的概述更官方
1、Client
客戶端——包括 Hue、ODBC 客戶端、JDBC 客戶端和 Impala Shell 在內的實體都可以與 Impala 交互。這些介面通常用於發出查詢或完成管理任務,例如連接到 Impala。
2、Impalad
Impala的核心組件是Impala守護進程,它的物理代表是impalad進程。Impala守護進程的幾個關鍵功能是:
- 讀寫數據文件。
- 接受從impala-shell命令、Hue、JDBC或ODBC傳輸的查詢。
- 並行化查詢併在集群中分配工作。
- 將中間查詢結果傳回中央協調器。
【溫馨提示】
- HDFS和Impala是共存的,每個Impala守護進程和DataNode運行在同一個主機上。
- Impala單獨部署在計算集群中,可以遠程從HDFS、S3、ADLS等讀取數據。
3、Statestore
Statestore服務主要負責metadata的廣播,檢查集群中所有Impala守護進程的健康狀況,並不斷地將其發現傳遞給每一個這些守護進程。它在物理上由一個名為stateststored的守護進程表示。該進程只需要在集群中的一臺主機上運行。如果一個Impala守護進程由於硬體故障、網路錯誤、軟體問題或其他原因而離線,StateStore會通知所有其他的Impala守護進程,這樣以後的查詢就可以避免向這個不可達的Impala守護進程發出請求。
4、Catalog
Catalog 服務負責metadata的獲取和DDL的執行,將Impala SQL語句的元數據更改傳遞給集群中的所有Impala守護進程。它在物理上由一個名為catalogd的守護進程表示。該進程只需要在集群中的一臺主機上運行。因為請求是通過StateStore守護進程傳遞的,所以在同一主機上運行StateStore和Catalog服務是更好的。
當通過Impala發出的語句執行元數據更改時,catalog服務避免發出REFRESH和INVALIDATE METADATA語句。當你通過Hive創建表、載入數據等等時,在執行查詢之前,你需要在Impala守護進程上發出REFRESH或INVALIDATE元數據。
5、數據存儲服務
- HBase或HDFS——用於存儲要查詢的數據。
2)Impalad服務的三種角色
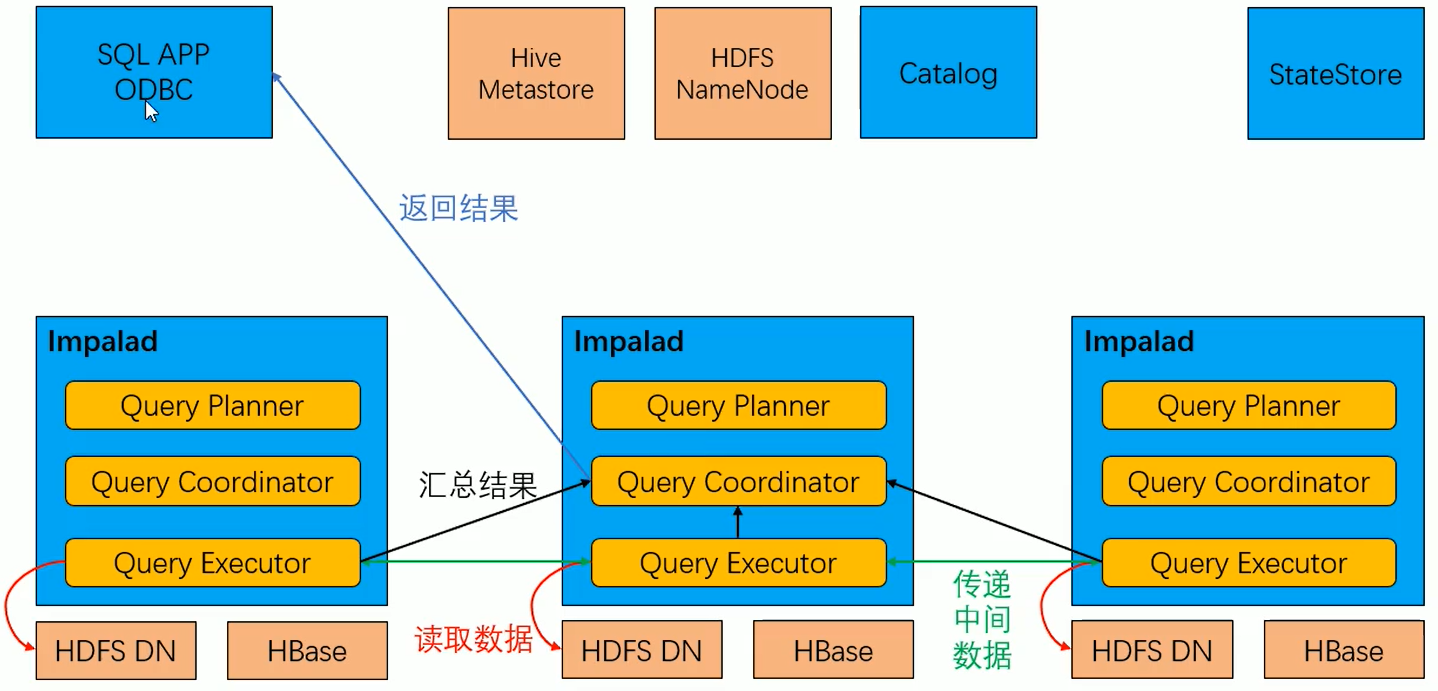
Impala的核心進程Impalad,部署在所有的數據節點上,接收客戶端的查詢請求,讀寫數據,並行執行來自集群中其他節點的查詢請求,將中間結果返回給調度節點。調用節點將結果返回給客戶端。Impalad進程通過持續與StateStore通信來確認自己所在的節點是否健康以及是否可以接受新的任務請求。

- Query Planner——Java編寫的,解析SQL生成QueryPlanTree執行計劃樹。
- Query Coordinator——用戶在Impala集群上的某個節點提交數據處理請求(例如impala-shell提交SQL),則該Impalad節點稱為Coordinator Node(協調節點),負責定位數據位置,拆分請求(Fragment),將任務分解為多個可並行執行的小請求,發送這些請求到多個Query Executor,接收Query Executor處理後返回的數據並構建最終結果返回給用戶。
- Query Executor——執行數據計算,比如scan,Aggregation,Merge等,返回數據。
3)Impala運行原理
1、啟動服務時執行的操作

2、查詢SQL的運行流程

3、數據計算流程
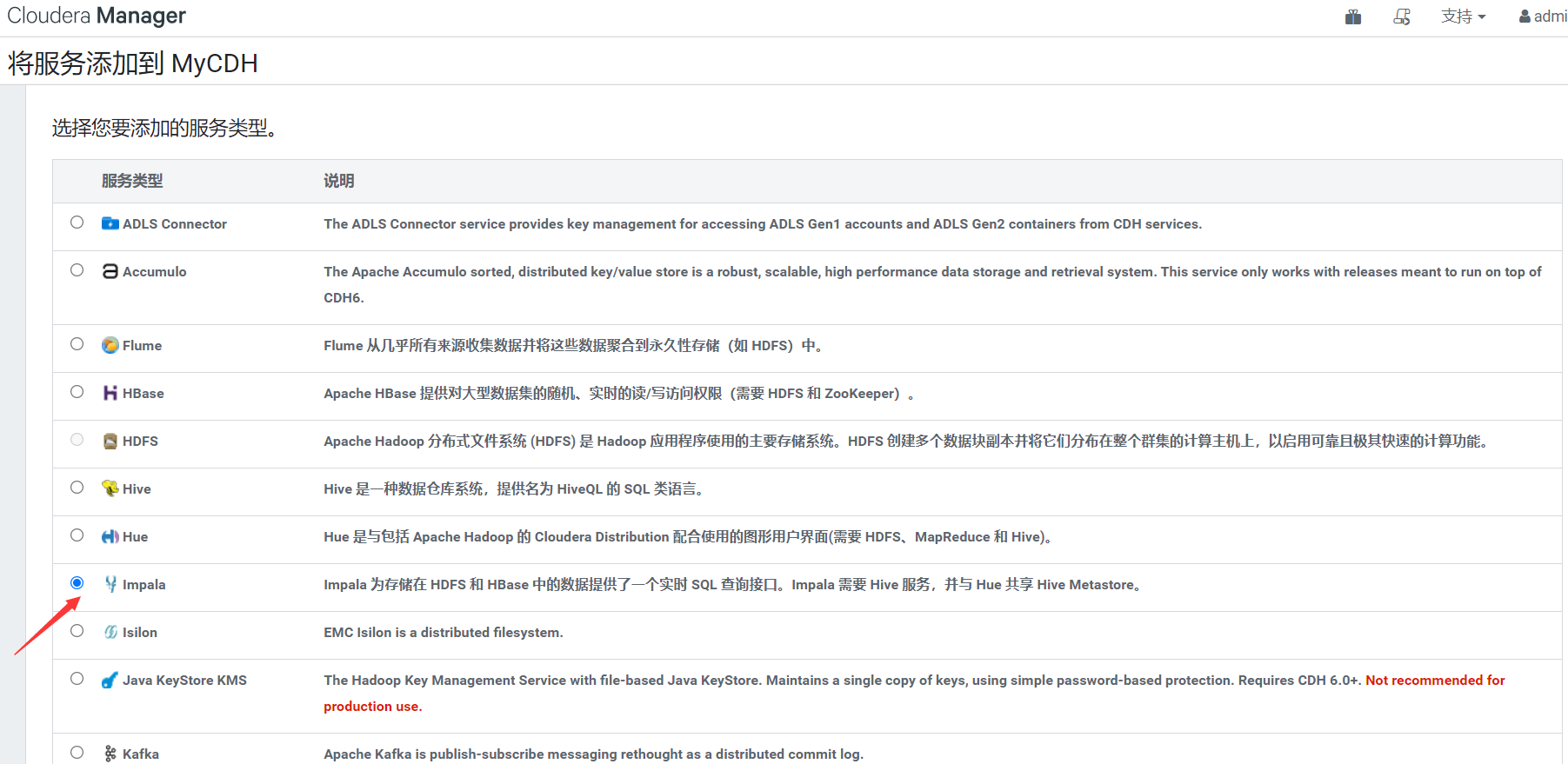
三、Impala環境部署(CDH集成)
這裡通過CM安裝方式集成到CDH,方便管理,CDH的安裝可以看我之前的文章:
大數據Hadoop之——Cloudera Hadoop(CM 6.3.1+CDH 6.3.2環境部署)
1)添加服務

2)自定義角色分配
3)審核更改

下一步就進入自動安裝過程,時間有點久,耐心等待安裝完即可
4)安裝完成

5)啟動服務

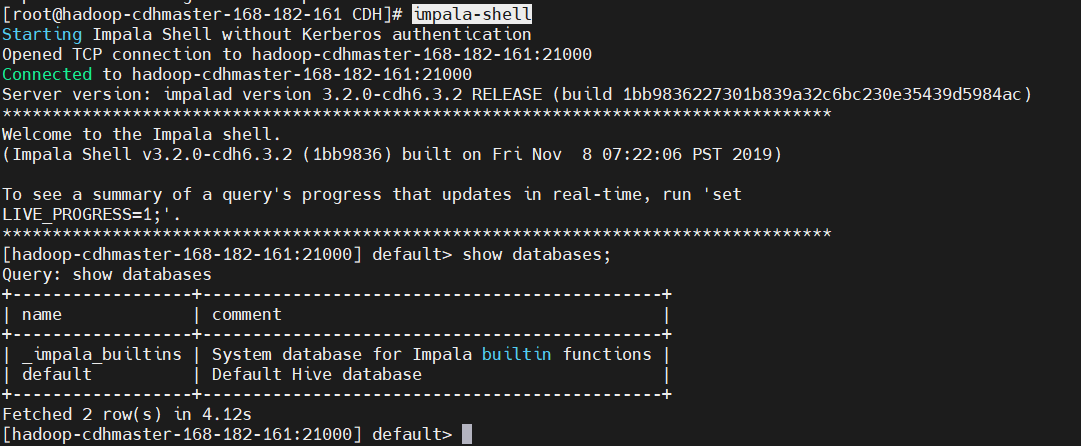
6)驗證
$ impala-shell
show databases
四、Impala與其它對比
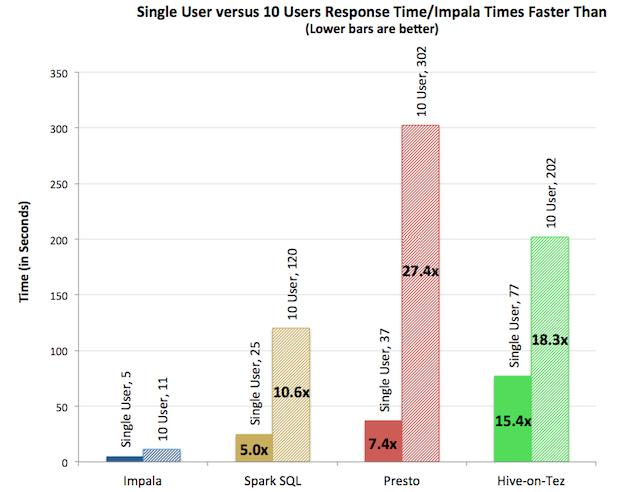
多用戶如下圖所示(引用自Apache Impala官網):
查詢吞吐率如下圖所示(引用自Apache Impala官網):
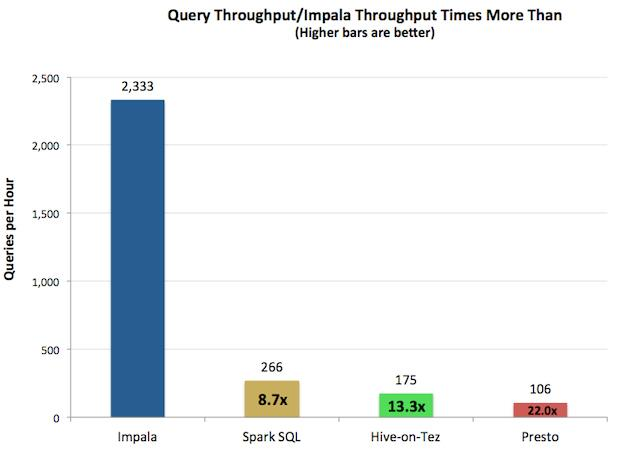
由上圖測試結果可知,對於單用戶查詢,Impala比其它方案最多快13倍,平均快6.7倍。對於多用戶查詢,差距進一步拉大:Impala比其它方案最多快27.4倍,平均快18倍。
五、Impala shell簡單使用
1)Impala 外部shell(非互動式)
標紅的就是常用的
| 選項 | 描述 |
|---|---|
| -h, --help | 顯示幫助信息 |
| -v or --version | 顯示版本信息 |
| -i hostname, impalad=hostname | 指定連接運行impalad守護進程的主機。預設埠是21000 |
-q query, --query=query |
從命令行中傳遞一個shell命令。執行完這一語句後 |
| shell會立即退出。非互動式 | |
-f query_file,--query_file=query_file |
傳遞一個文件中的SQL查詢。文件內容必須以分號分隔 |
| -o filename or --output_file_filename | 保存所有查詢結果到指定的文件。通常用於保存在命令行使用-q選項執行單個查詢時的查詢結果 |
| -c | 查詢執行失敗時繼續執行 |
| -d default_db or --default_db=default_db | 指定啟動後使用的資料庫,與建立連接後使用use語句選擇資料庫作用相同,如果沒有指定,那麼使用default資料庫d |
-p, --show_profiles |
對shell中執行的每一個查詢,顯示其查詢執行計劃 |
-r or --refresh_after_connect |
建立連接後刷新 Impala 元數據,新版已經沒有這個參數了。換成這樣刷新:impala-shell -q "invalidate metadata",不刷新的話,就看不到新創建的庫表了。 |
| -B (--delimited) | 去格式化輸出 |
| --output_delimiter=character | 指定分隔符 |
| --print_header | 列印列名 |
操作都是很簡單,查看幫忙執行幾個例子演示一下就行,這就不再演示了。主要是sql操作,sql的話,懂編程的人,應該對sql不陌生,也不是很難。
2)Impala內部shell(互動式)
標紅的就是常用的
| 選項 | 描述 |
|---|---|
| help | 查看幫助信息 |
| explain |
顯示執行計劃 |
| profile | (查詢完成後執行)查詢最近一次查詢的底層信息 |
shell <shell> |
不退出impala-shell執行shell命令 |
| version | 顯示版本信息(同於impala-shell -v) |
| connects | 連接 impalad 主機,預設埠 21000(同於 impala-shell -i) |
refresh <tablename> |
增量刷新元資料庫 |
invalidate metadata |
全量刷新元資料庫(慎用) |
| history | 查看歷史命令 |
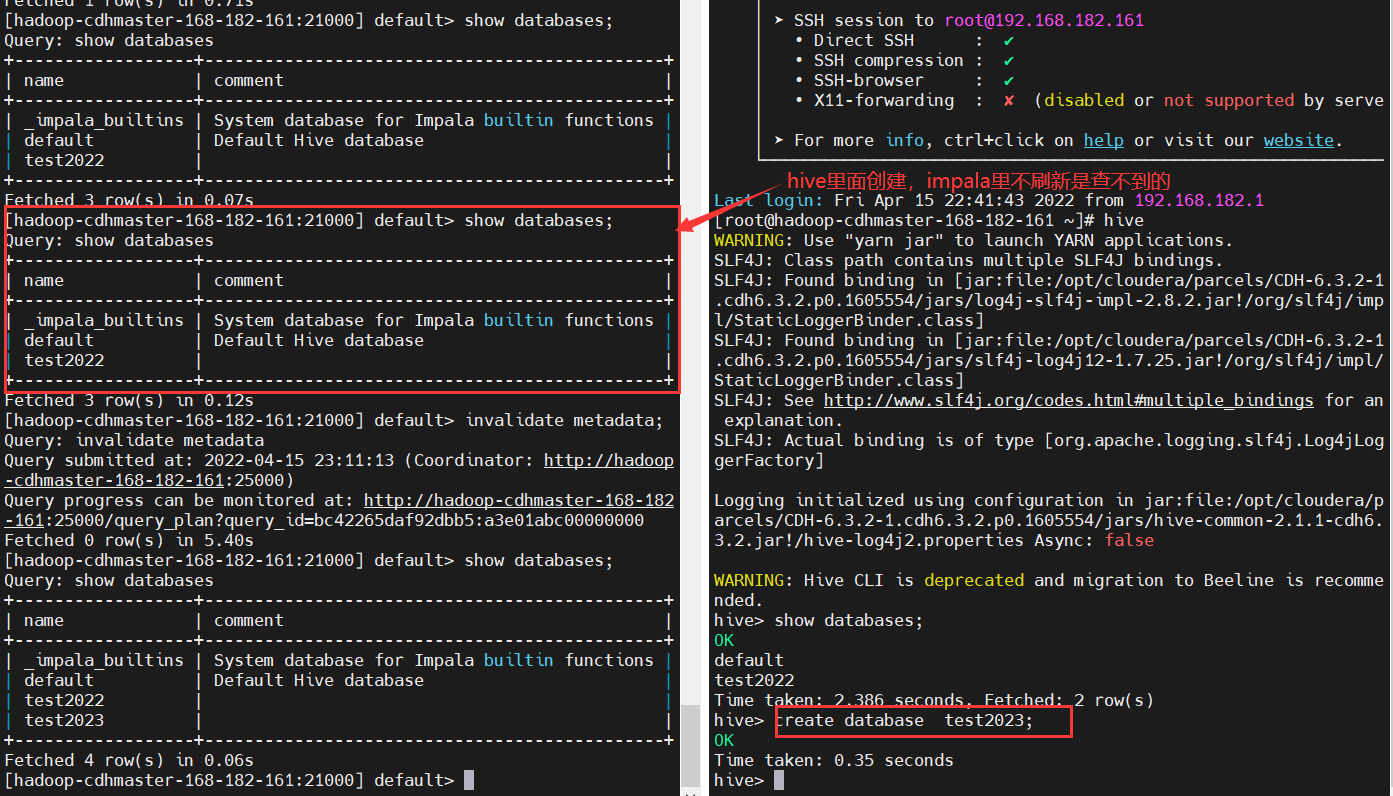
3)Impala數據類型
| Hive數據類型 | Impala數據類型 | 長度 |
|---|---|---|
| TINYINT | TINYINT | 1 byte有符言整數 |
| SMALINT | SMALINT | 2 byte有符號整數 |
| INT | INT | 4 byte有符號整數 |
| BIGINT | BIGINT | 8 byte有符號整數 |
| BOOLEAN | BOOLEAN | 布爾類型,true或者false |
| FLOAT | FLOAT | 單精度浮點數 |
| DOUBLE | DOUBLE | 雙精度浮點數 |
| STRINGS | STRINGS | 字元系列。可以指定字元集。可以使用單引號或者雙引號。 |
| TIMESTAMPS | TIMESTAMPS | 時間類型 |
| BINARY | 不支持 | 位元組數組 |
【溫馨提示】Impala雖然支持array, map, struct複雜數據類型,但是支持並不完全,一般處理方法,將複雜類型轉化為基本類型,通過hive創建表。
4)DDL數據定義
都是一些很基礎的操作
1、創建資料庫
create database db_name
【溫馨提示】Impala不支持WITH DBPROPERTIE...語法
2、查詢資料庫
show databases;
3、刪除資料庫
drop database db_name
【溫馨提示】Impala不支持修改資料庫(alter database )
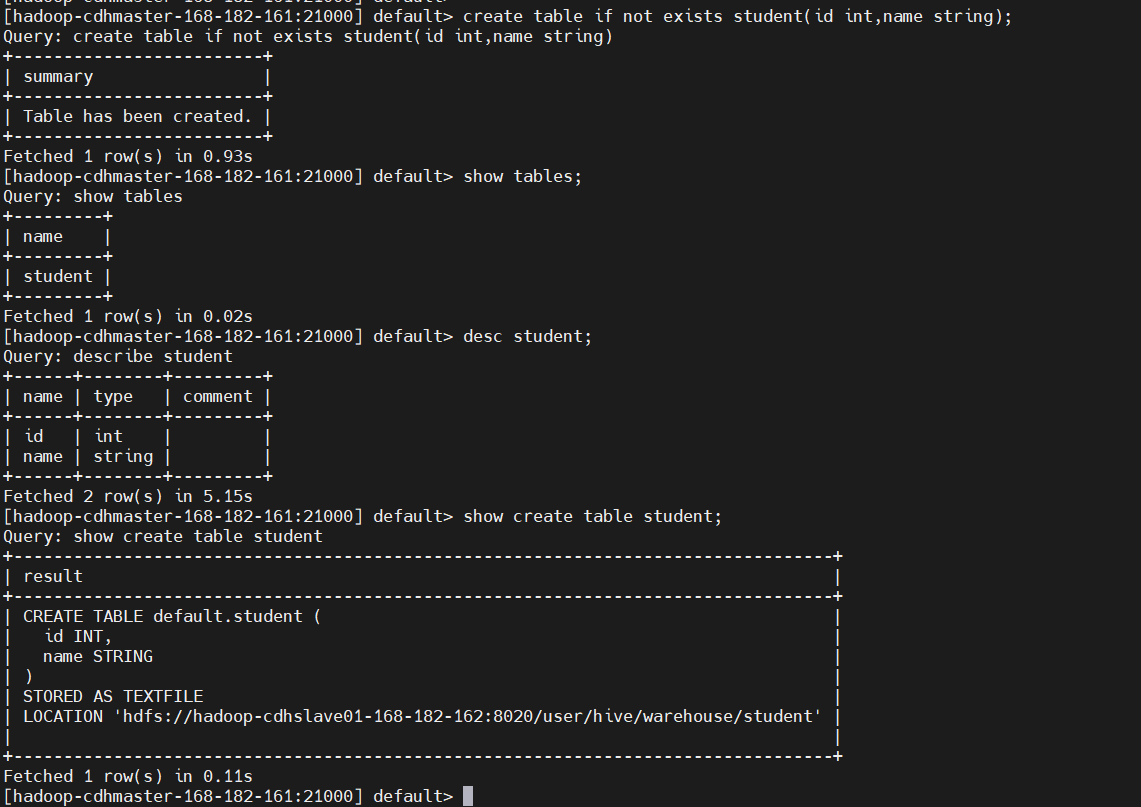
4、創建表
create table if not exists student(id int,name string);
show tables;
desc student;
show create table student;
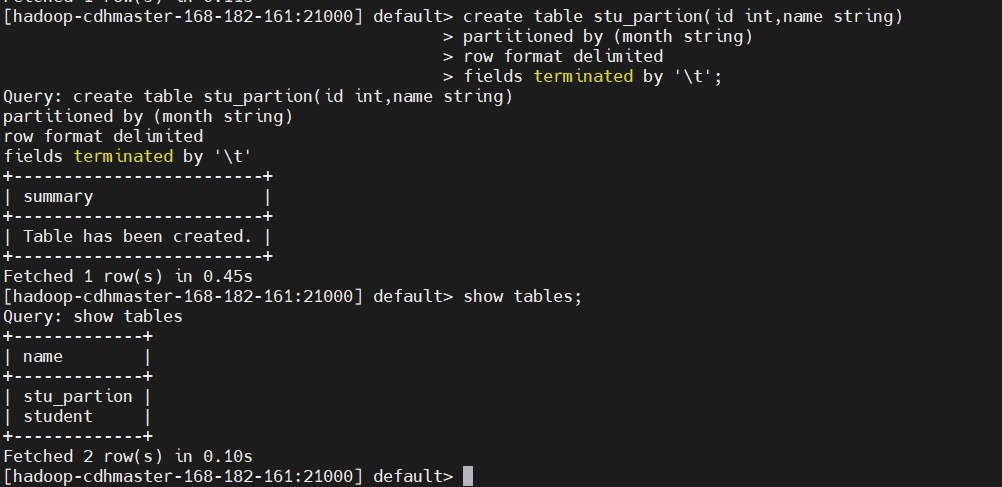
5、創建分區表
create table stu_partion(id int,name string)
partitioned by (month string)
row format delimited
fields terminated by '\t'
show tables;
5)DML數據操作
1、向表中導數據
# 文件欄位一tab分隔,上面創建表時定義了分隔符
$ cat > /tmp/student.txt << EOF
1 stu1
2 stu2
3 stu3
4 stu4
EOF
$ sudo -u hdfs hadoop fs -put /tmp/student.txt /tmp/
# 授權,要不然沒有許可權
$ sudo -u hdfs hadoop fs -chown impala:hive /tmp/student.txt
$ impala-shell
# 【溫馨提示】hdfs集群上更改許可權之後,一定要記住登錄到impala-shell上使用invaladate metadata命令進行元數據更新,否則更改的許可權在impala狀態下是不生效的!!!,執行下麵這句就行了。
invalidate metadata;
# 添加分區
alter table stu_partion add partition (month='20220415');
# 刪除分區,這裡不執行
alter table stu_partion drop partition (month='20220415');
# 載入數據,載入完,這個文件/tmp/student.txt會被刪掉
load data inpath '/tmp/student.txt' into table stu_partion partition (month='20220415');
# 查看檢查
select * from stu_partion;

【溫馨提示】如果分區沒有,load data 導入數據時,不能自動創建分區。還有就是不能到本地數據,只能到hdfs上的數據。
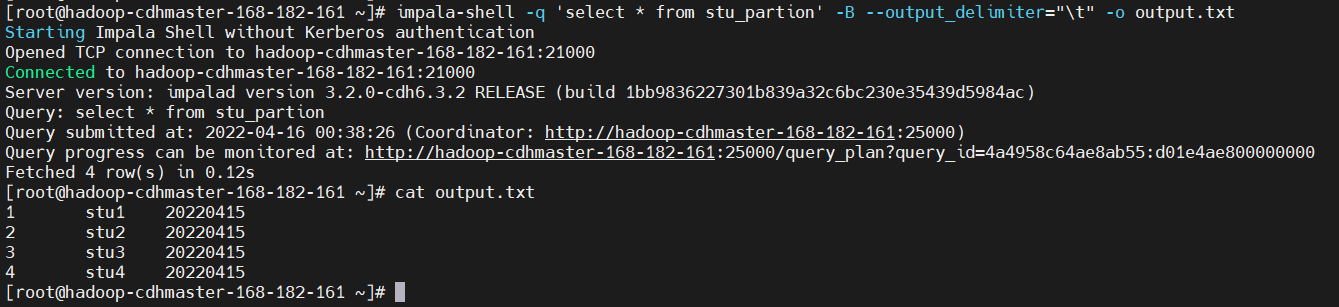
2、數據導出
impala 數據導出一般使用impala -o
$ impala-shell -q 'select * from stu_partion' -B --output_delimiter="\t" -o output.txt
一般DML由hive來操作,impala負責查詢。
6)DQL數據查詢
- 基本的語法跟hive的查詢語句大體一樣
- Impala 不支持 CLUSTER DISTRIBUTE BY; SORT BY*
- Impala中不支持分桶表
- Impala 不支持 COLLECT_SET(col)和 explode (col)函數
- Impala支持開窗函數
因為查詢sql跟mysql的一樣,所以這裡就不演示了。
7)函數
跟hive和mysql函數差不多,像count、sum等內置函數,當然也支持自定義函數。有興趣的小伙伴可以去練習一下,比較簡單。
impala的簡單使用就到這裡了,有疑問的話,歡迎給我留言,後續會更新更多關於大數據的文章,請耐心等待~

