
導讀: 今天和大家分享京東零售OLAP平臺的建設和場景的實踐,主要包括四大部分: 管控面建設 優化技巧 典型業務 大促備戰 -- 01 管控面建設 1. 管控面介紹 管控面可以提供高可靠高效可持續運維保障、快速部署小時交付的能力,尤其是針對ClickHouse這種運維較弱但是性能很高的OLAP核心引 ...

導讀: 今天和大家分享京東零售OLAP平臺的建設和場景的實踐,主要包括四大部分:
- 管控面建設
- 優化技巧
- 典型業務
- 大促備戰
--
01 管控面建設
1. 管控面介紹
管控面可以提供高可靠高效可持續運維保障、快速部署小時交付的能力,尤其是針對ClickHouse這種運維較弱但是性能很高的OLAP核心引擎,管控面就顯示得尤其重要。

2. 架構設計
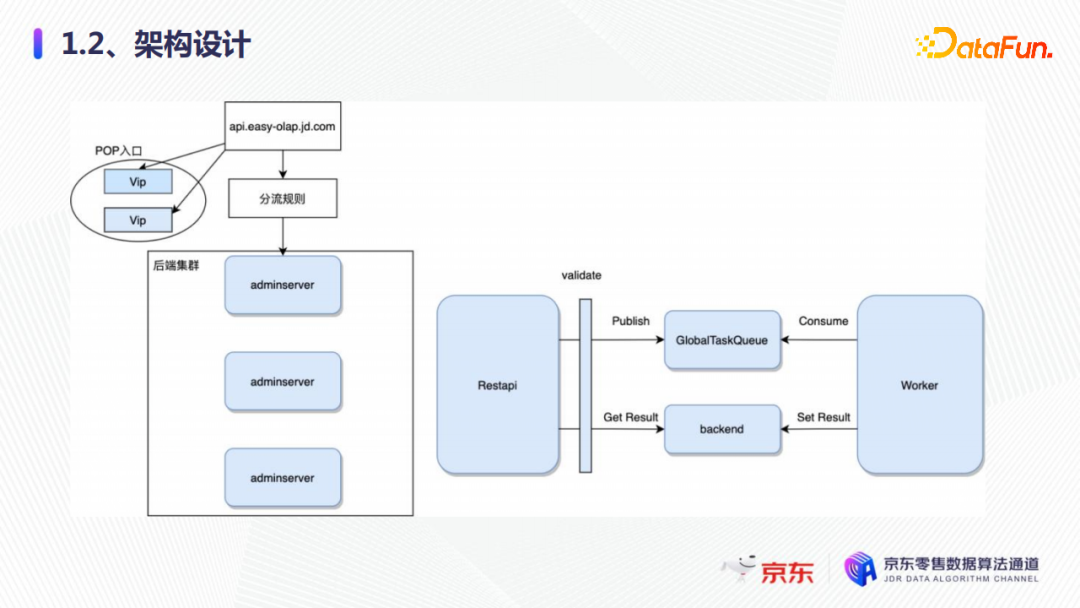
管控面的整體架構設計如上圖所示,從開始請求、功能變數名稱解析和分流規則,到達後端服務adminServer,adminServer有一層校驗層,校驗完成後會向隊列中發送任務,worker會不斷地消費隊列中的任務,消費完成後會將任務的結果寫到後端的存儲。如果有大量的集群的部署、配額的更改,就會有一系列的任務在這裡完成。完成之後,再到數據部門進行保存,這就是整體的架構設計。
3. 業務管理
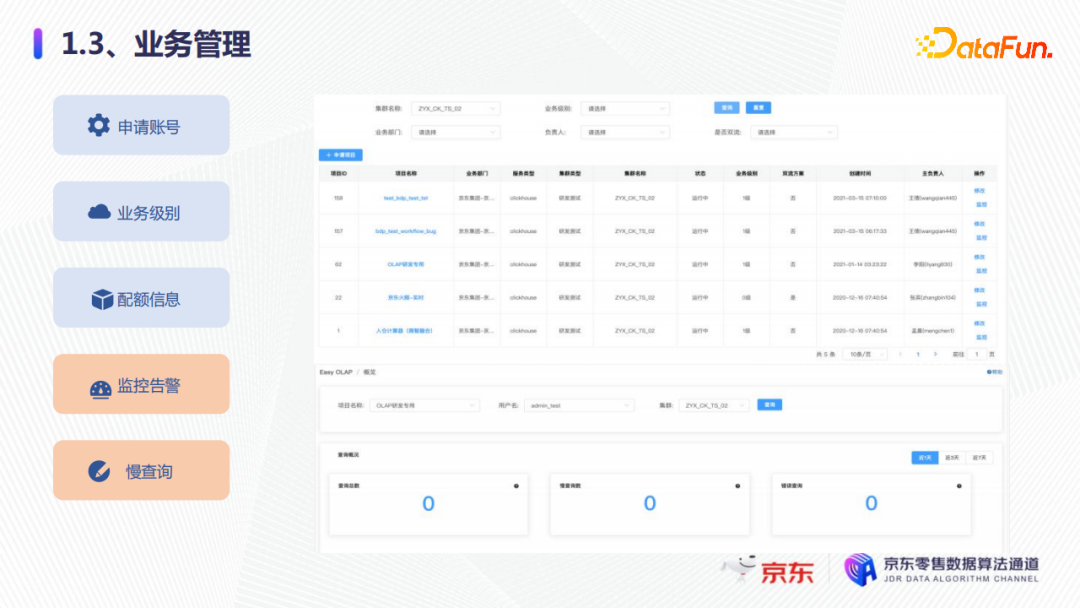
在業務管理方面,管控面可以提供以下功能:
- 可以用於用戶的集群賬號的申請;
- 業務級別的登記;
- 用戶可以進行配額查詢,這些配額主要包括查詢數、執行的併發以及超時等;
- 用戶可以自定義監控告警,通過這些監控告警去實時探索自己的整體服務的可靠性和穩定性;
- 慢查詢統計告警,可以通過管控面看到當前集群業務有多少慢查詢以及錯誤的查詢、查詢的總數等。
4. 運維管理
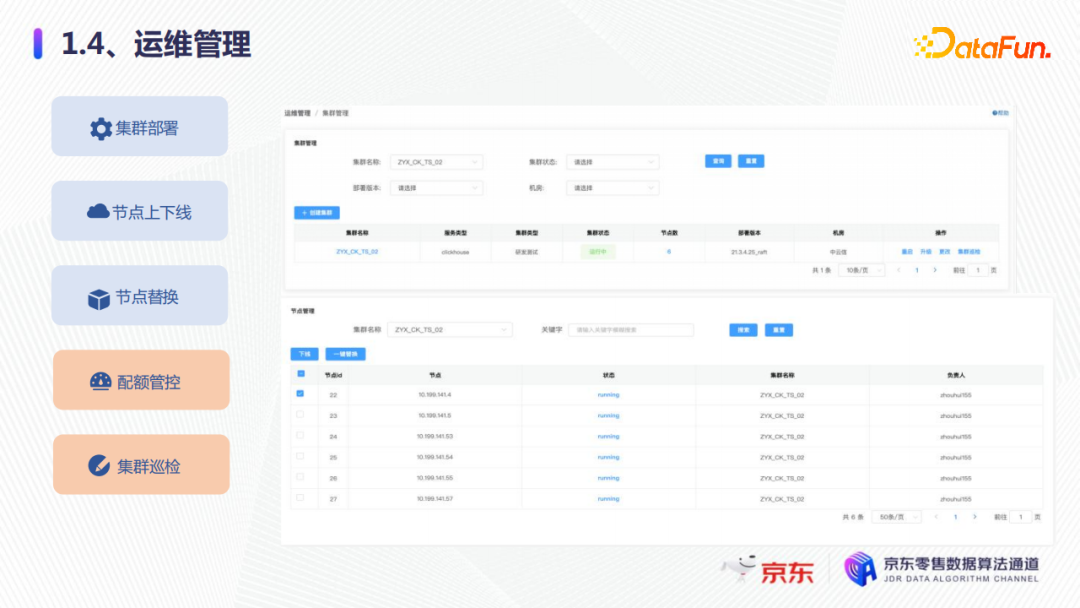
在運維管理方面:
第一,可以進行新集群的部署,比如物理資源或者容器資源已經申請好之後,可以及時進行創建資源,並及時給用戶使用;
第二,比如ClickHouse有節點故障時(例如硬體故障如CPU、記憶體或磁碟故障),要進行及時的節點上下線或者節點替換,否則就會影響整個集群,一是影響DDL,二是影響寫入。
第三,可以做配額的管控,這一點在大促中非常有用,它可以用於限制用戶的查詢數、併發還有超時等,防止突增的流量,導致集群的不穩定。
第四,可以進行集群的巡檢,集群巡檢之後,可以查看每個集群的服務狀態,比如它是否可以創建表、刪除表、插入數據、查詢數據是否都正常等,也有實時告警集群巡檢的服務狀態。
以上就是我們京東零售OLAP管控面核心功能,它在集群運維方面不僅提升集群交付的效率,還節約運維的成本。
--
02 優化技巧
1. 場景難點
京東零售是以電商交易和用戶流量為核心的場景,有以下兩方面難點:
- 第一點是交易的業務比較複雜,需要關聯多張表、sql中的邏輯多,另外就是數據會實時更新,比如交易的狀態和金額的變化、組織架構的變化等;
- 第二點是流量數據,它有個特點,首先追加不修改,其次是量大,因為包含了用戶的點擊和瀏覽等各類行為的數據,以及衍生的各種指標,比如UV的計算。最後是它的數據質量也會經常變化。
針對以上場景難點,我們主要用到了實時的數據更新,還有物化視圖、join的優化。接下來通過一些具體案例詳細講解。
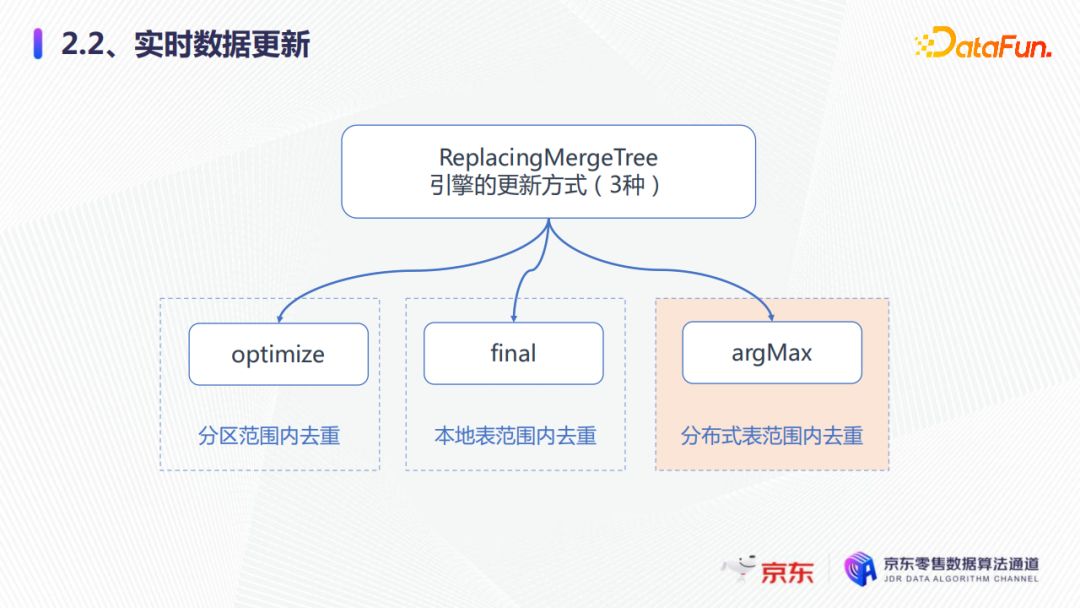
2. 實時數據更新
首先看一下實時數據更新。我們創建了兩張表,一張是本地表,還有一張是分散式表。

本地表主要採用ReplacingMergeTree去重的引擎,欄位分別是create_time創建時間、ID、comment註釋,還有數據的版本,分區是創建時間進行格式化得到的天分區,然後按照ID進行排序鍵去重。現在的需求是對相同的ID進行實時的數據更新。

我們在集群的兩個分片中,比如分片1插入了三條數據,分片2插入了三條數據都是相同的ID(0),但是查詢分散式表發現,數據並沒有去重。

第一種解決方式是使用optmize去重。通過執行一個optmize去重之後,通過查詢本地表就發現optmize在多分區間和分片間不能去重,只能在同一個分區中去重。

第二種方式是使用final去重。通過查詢一個本地表的final,發現剛纔的11日和12日的數據只保留了一條數據,這時再通過查詢分散式表final去重,發現有兩條12日的數據,所以我們的結論是final的方式在多個分區間可以去重,但是在多分片間不能去重。

因為我們的集群都是多分片的,所以還有第三種方式——使用argMax。我們通過argMax加了一個數據的版本,可以選擇最大的一個版本號,然後通過去查詢分散式表,發現argMax可以在多分片間去重,這也是我們推薦使用的一種方式。
所以實時數據更新方式一般有以上三種,但是各種方案更新的範圍不同,我們可以根據自己的業務場景去使用不同的去重方式,optmize可以在分區範圍內去重,final可以在本地表範圍內驅動,而argMax可以在分散式表範圍內去重。
3. 物化視圖
接下來,我們看一下物化視圖。使用物化視圖的場景,比如:業務最近3小時看小時的數據,三天之前想看天粒度的數據,這時候物化視圖,就是很好的選擇。那麼物化視圖該如何使用?我們看一下這個案例,有一張明細表test,它大概有13億行左右,直接實時的count聚合進行查詢,發現它的耗時大概是2.1秒左右,怎樣能讓查詢變得更快一些?

我們創建了一張物化視圖,對原始表進行預聚合,物化視圖選用了SummingMergeTree,這是聚合的一種引擎,大家也可以選擇其他引擎去聚合。它會根據排序鍵進行二次聚合,也就是 Date 欄位。還有一個select語句,它的作用是通過批次寫入,把這個select語句寫入到物化視圖列表中。

我們創建物化視圖之後,再去執行相同的語句,查詢性能提升了大概113倍,耗時0.002秒左右,所以物化視圖在比如量大而且可以預聚合的這種場景下非常好用。

那麼物化視圖就又是什麼原理能夠達到這樣的效果?整體如圖所示。
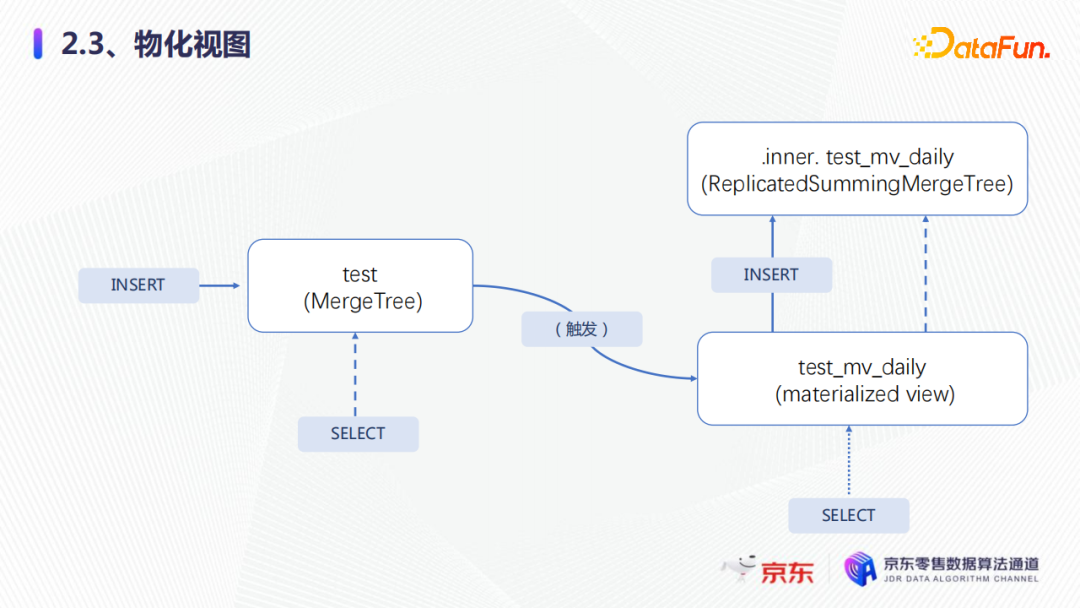
物化視圖會創建一個隱藏的內表來保存視圖裡面的數據,然後物化視圖會將寫入原始表的數據,也就是通過select第一次聚合後的結果,寫入物化視圖的內表中列表,再根據排序鍵進行二次聚合,這樣原始表的數據量會大量減少,查詢就可以得到加速。
4. join優化
在正式介紹join優化前先補充一點基礎知識:對本地表的查詢我們稱之為部分查詢,以下劃線L為結尾的表稱為本地表。在做這種優化之前,先看一下整體的分散式表執行的流程。
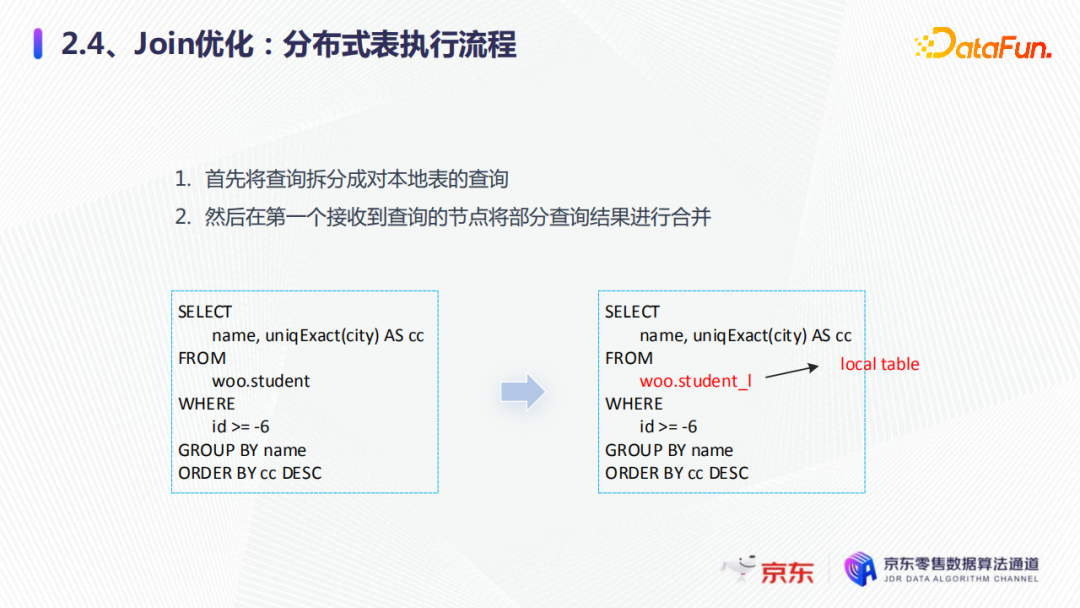
首先分散式表會將查詢拆分成對本地表的查詢。比如city在精確去重之後,查詢分散式表,通過路由下發到各個分片的本地表上面進行查詢,然後第一個接收到的查詢的節點,再將本地的查詢部分的結果進行合併,返回給用戶,這是整體分散式表執行的流程。
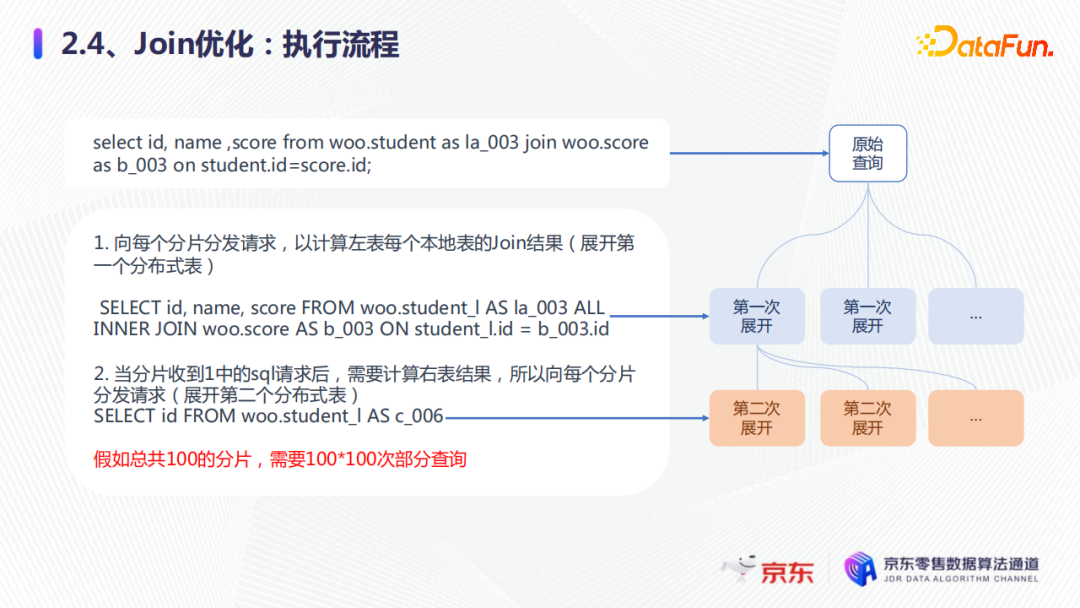
join的執行過程如上圖所示。比如select id, name, score from student join score,首先展開分散式表,向每個分片分發請求,計算左表的每個本地表join的結果,第二步當分片收到1中的請求後,需要計算右表的結果,向每個分片再發送請求。這樣假如集群有100個分片,就需要100×100的部分查詢,每一次展開都要通過磁碟網卡,都會有耗時。
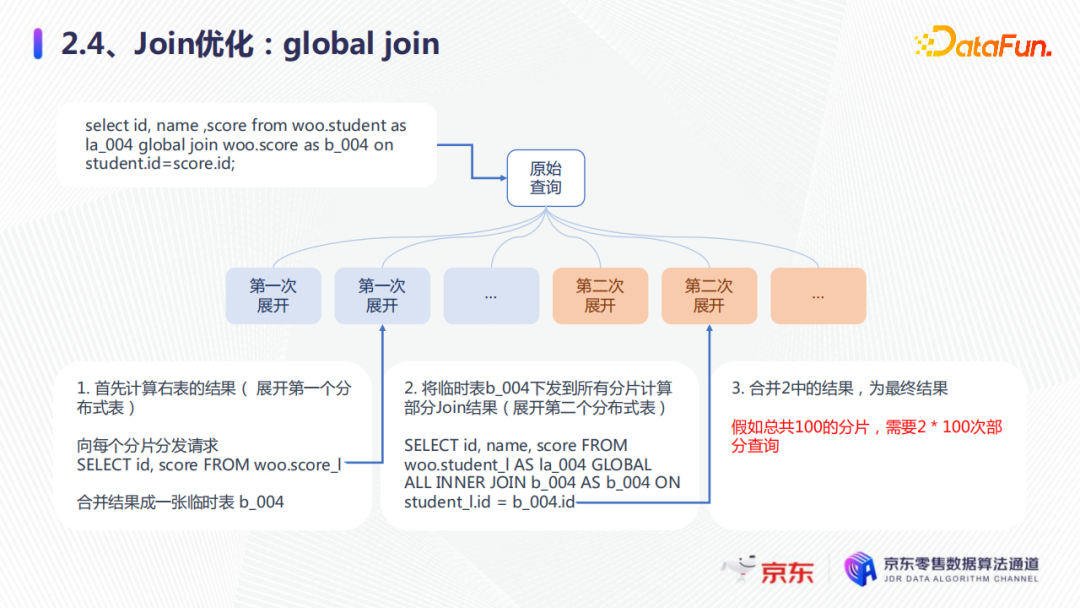
第一種優化是global join。在原始的查詢中,會先計算右表結果,展開第一個分散式表,然後合併,成為一個臨時表,假設命名為b_004,這是第一次展開。第二次展開時,它會將臨時表b_004發送,所有的分片計算部分的join結果,就是第二次展開的分散式表,然後第三步,合併2中的結果,為最終的結果。這樣整體的global join就是,假如我們有100個分片,就只需要2×100次的部分查詢,大大減少了查詢。

第二種優化方案就是本地join,將右表的分散式表改成本地表。這種方式的執行流程是,我們展開左表,只需要把左表的分散式表下發到各個分片上面,而右邊它本身就是本地表,就直接進行合併計算,最後會合併整個部分結果即為最終的結果。假如總共有100個分片,只需要展開100次,下發每個分片,100次的查詢就行了,這樣就減少了帶寬消耗,提升了性能。
可以優先使用本地join,其次是global join,最後要小表放在右邊,這樣就可以提升join的性能。
以上就是我們針對業務場景難點的一些優化技巧。
--
03 典型業務
我們也希望實現高併發查詢,有大吞吐的寫入,但是ClickHouse在預設的配置下,不支持高併發的查詢,而且寫入也很慢,這是我們業務上的兩大痛點。下麵具體看一下兩種場景。
1. 高併發查詢
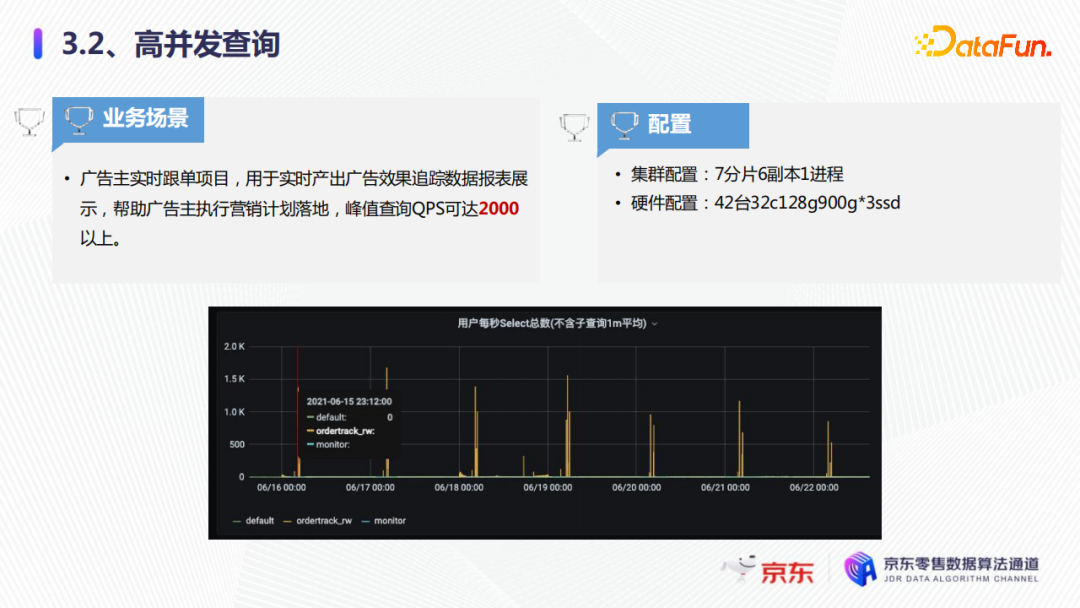
以廣告實時跟單項目為例,它是用於實時產生廣告效果,最終數據報表展示,幫助廣告主執行營銷計劃落地。如圖所示,可以看到每秒的QPS達到將近2000,這是618時候的一個截圖。我們的集群整體的配置是7分片6副本1進程,硬體的配置是42台32C128G,900G*3的SSD的磁碟,整個集群的QPS可以達到2000。當然這個配置如果要達到2000的話,我們要進行一系列的技術優化。
首先第一點技術優化就要增加副本,因為增加副本可以提升整個集群的併發能力。第二是max_threads,減少每一個查詢所用的線程數,ClickHouse如果不設置這個參數,會用物理內核的所有線程去進行查詢,這樣就會導致有些任務無法調度,所以要設置這個參數。第三就是要調整query_thread_log的存儲,因為大量的QPS過來,會有很多的請求日誌,如果我們不調整存儲,很快就會將磁碟打滿,造成集群的不可用。
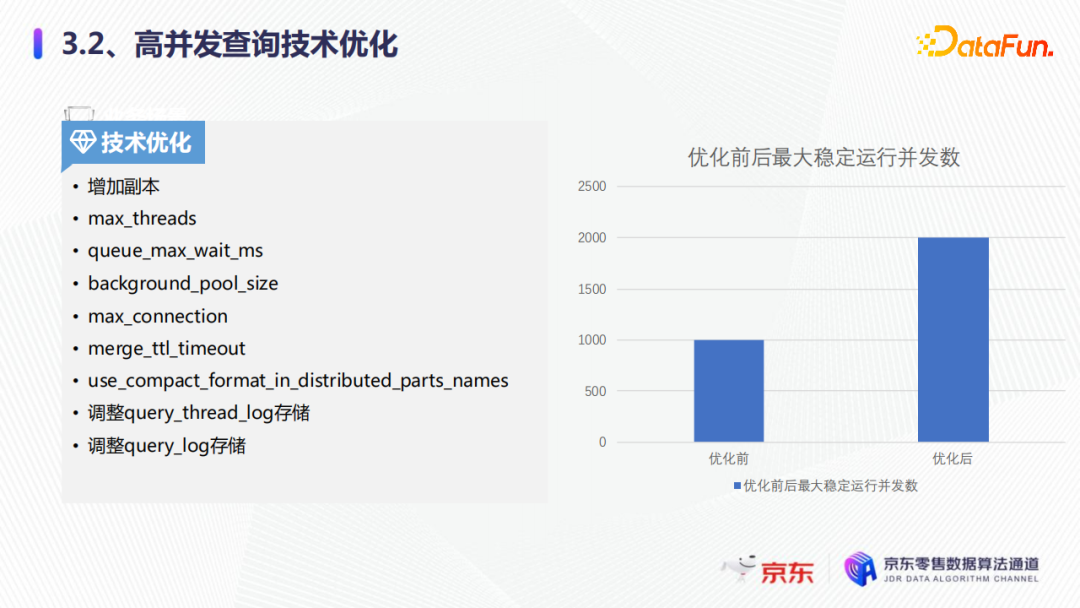
上圖展示了優化前後的最大穩定運行併發數。優化前,大概只能達到1000QPS,同樣的集群下優化後可以穩地運行在2000QPS左右,可以滿足業務需求。
2. 大吞吐寫入
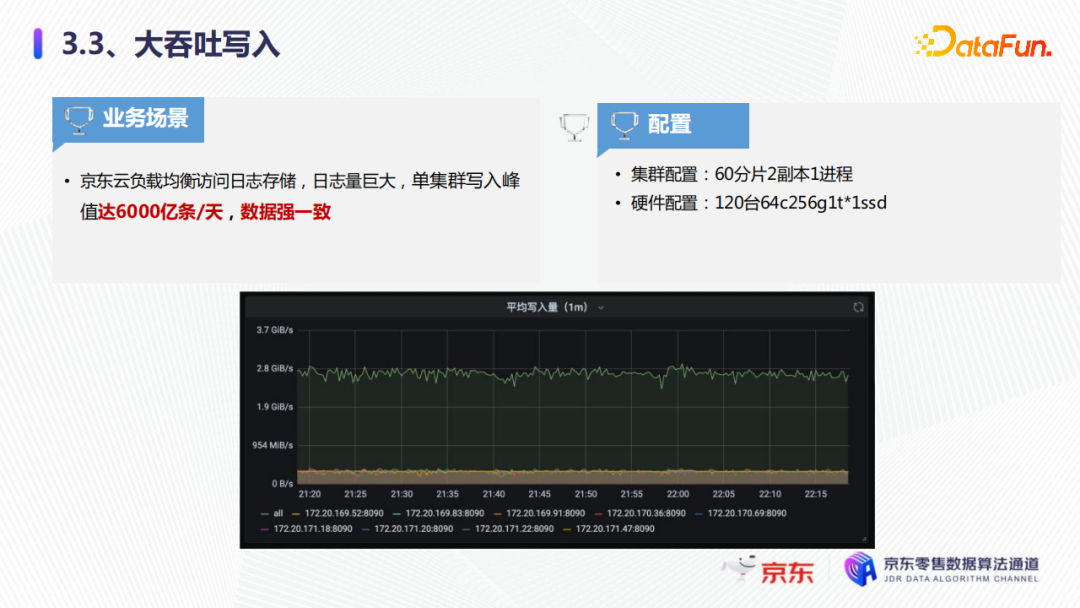
第二個典型業務是大吞吐的寫入。以京東雲監控項目為例,它負責京東雲負載均衡訪問日誌的存儲,日誌量極其大,單集群寫作的峰值可以達到6000億條/天,還可以保持數據的強一致。可以看到集群日常大概是3G/秒,大促可達到6G/秒。我們的集群配置是60分片兩副本1進程,硬體配置是120台64核的256G1T*1的SSD。
這樣集群配置下,我們可以實現這6000億條每天的寫入。為支持這個寫入量,我們也需要一系列的技術優化。
第一點就是引入了chproxy流量負載均衡,請求粒度細化至每條sql,這樣每一個sql請求都會路由到不同的節。如果不引入chproxy,就會通過功能變數名稱的方式直連客戶端,直連集群,如果連接不及時釋放,就會一直往節點里寫,很容易就把集群單節點打爆了。引入了chproxy的流量負載平衡之後,sql就可以均衡地路由到各個節點。
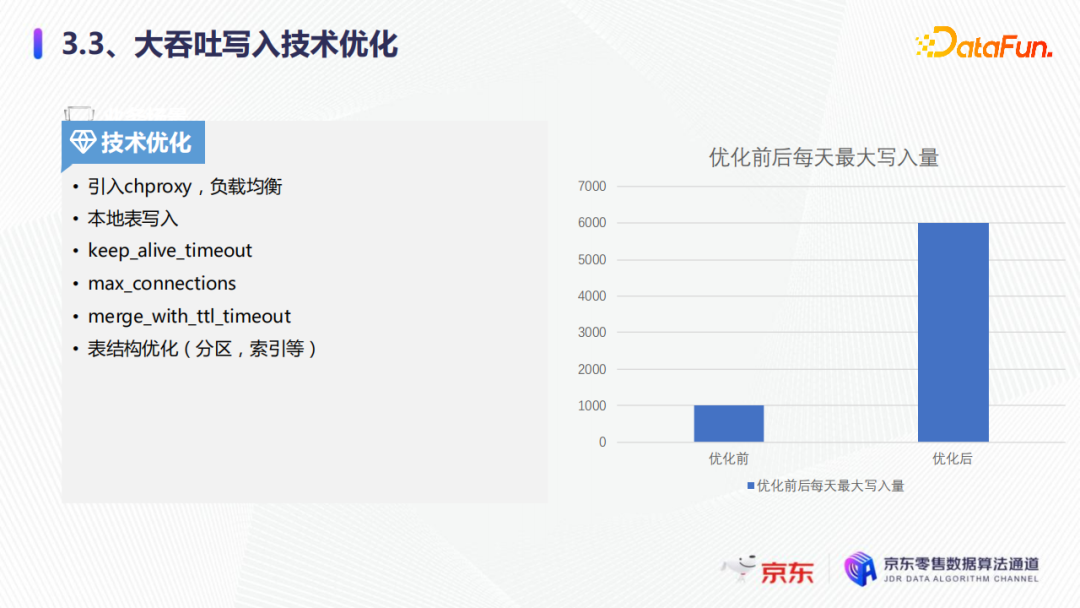
第二點就是本地表的寫入,可以提升整體的寫入性能,大概是分散式表的兩到三倍左右。
最後我們看一下優化前後,每天最大的寫入量,優化前大概是1000億每天,優化後可以達到6000億每天,這樣就實現了大吞吐的寫入。
--
04 大促備註
電商場景下,經常遇到大促備戰,需要保證olap服務的穩定性。
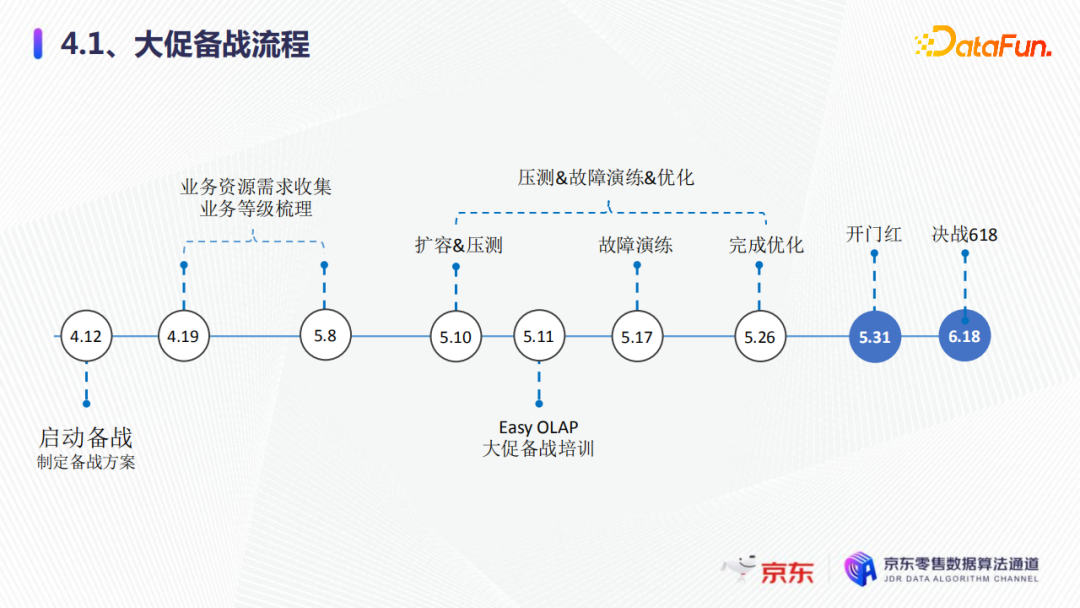
大促備戰的整體流程如圖所示,我們在不同的時間段需要做不同的事情。一開始是啟動備戰制定備戰方案,收集業務的資源需求,梳理業務等級,接下來是集群的擴容壓測,還有故障演練優化等,最後迎來開門紅,決戰618。
我們的OLAP是如何保證業務的呢?
第一,業務資源收集以及等級確認。大促前,我們平臺會向業務收集有資源的需求以及等級確認,並做合理的規劃和分配,來保障大促的流量急增時有足夠的資源支撐運轉。比如資源需求,可能有新上線的業務、擴容的業務、遷移的業務,還有替換已有集群的業務,這些都是我們大促之前要進行梳理的,這樣可以提前做好預案。

第二,業務方要及時的訂閱監控和報警。比如監控有CH系統層的、服務層的,還有CH查詢和寫入層的監控。我們有兩個告警系統:一個是服務層的,比如監控CH的一些重要的指標,ZK的一些監控告警,以及chproxy流量負載的一些監控報警等;另一個是系統層的MDC告警,例如CPU、記憶體、磁碟、連通性,這些主要是監控硬體是否有故障。右圖就是報警和監控的樣例,我們可以通過它們來及時修複集群故障,也需要業務方去訂閱這些監控和報警,來一起監督整個集群的穩定性和可靠性。
大促集群是如何保障的呢?
第一點是壓測。我們要進行高保真的一些壓測,壓測的結果,要設置合理的配額,比如我們共用集群的CPU一般是40%,獨占集群是80%,我們通過這些目標值設置業務的合理的配額。如果壓測有問題,我們可以及時的協助業務方進行優化,來滿足他們的QPS和集群的穩定性。
第二點是故障演練。我們的故障演練有很多,其中第一就是雙流切換。比如我們的零級業務就是非常核心的業務,要進行主備雙流,在不同的機房分別部署了兩個集群,如果同一個機房有問題,要及時切到備用集群去。另外就是故障的修複。故障發生後,我們要通過管控面進行及時下線或者替換,來保證集群的穩定性和業務的可用性。
第三點就是降級措施。我們的降級措施會針對不同的業務等級進行合理分配,尤其是大促的時候不參加壓測的業務。如果不參加壓測,我們就會在大促前期進行業務降級,防止他們的突增流量影響大促核心業務,以保證大促時整體的集群穩定性。
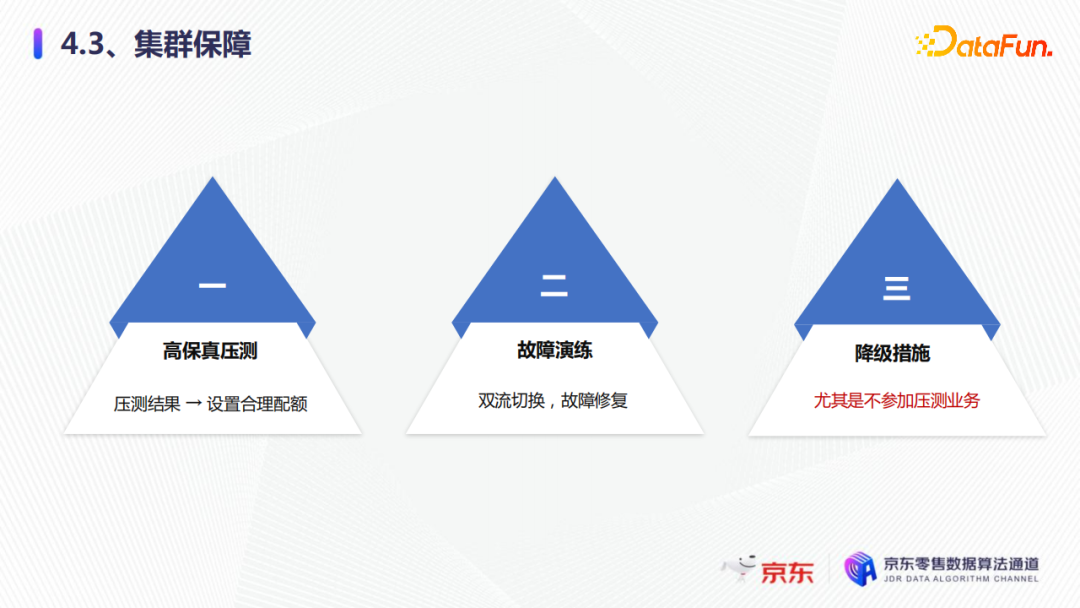
以上三點就是我們集群保障最核心的三個步驟,從一開始的高保真壓測,到故障的演練,再到最後的降級措施,我們都會和業務方一起去完成,以保證整體穩定運行。
--
05 精彩問答
Q:請問老師您在這個話題中遇到的最大的挑戰是什麼?
A:我遇到的最大挑戰就是解決高併發的問題,因為高併發瞬間QPS能達到2000以上,而我們的ClickHouse預設就是100個併發。我們在高併發方面做出了很多技術調優,可以讓業務達到高併發的場景。高併發的場景,遇到過很多問題,我們首先增加了多副本(一般預設情況下就是三副本或者兩副本來保證數據的安全),因為每增加一臺副本,就可以提升整體的一個分片的查詢能力。我們還進行了一些參數調優,比如如果高併發過來,有很多的隊列,這些線程我們都要去控制好,不然很容易就無法調度了。另外,高併發場景會很容易把集群的一些日誌給打滿,因為我們的每一條查詢都會記錄一條日誌,我們要把日誌的表的存儲周期設置小一點。還要加快它的merge,因為如果不加快merge,刪除數據就很慢,也很容易將磁碟打滿,這是查詢日誌的方面。第三點就是高併發很容易觸發我們的一些配額的限制,我們要對它進行一些放大。我們要進行記憶體的一些限制,如果不進行這些限制,或者是不放大這些限制都會引發QPS達不到,造成整體的穩定性和可用性不夠。
還有一個難點是join的優化,效能優化裡面其中有一個是本地join,本地join我們也做了很多的測試。比如和字典表做對比,我們發現字典表在100萬以下的數據量,就是使用字典表做join性能較好,100萬以上我們發現用本地join就非常好,我們通過一系列的測試實驗才得到這個結論。一開始我們都是用字典表去進行黃金眼刷,但是我們最後發現在一定的性能之上,字典表還不如本地表的join。大量的POC才得到了這個結論。所以大家在字典表和本地join,也可以自己做一下全面的性能測試。
以上就是我們的兩點挑戰。
Q:OLAP是什麼?主要用哪些引擎?
A:OLAP是線上的多維高性能實時分析服務,專業術語就是線上聯機查,和mysql OLTP線上事務查詢是兩種不同的類型。OLAP主要面向海量數據。
我們京東零售主要用clickhouse為主、doris為輔的兩個引擎。現在最流行的就是ClickHouse,其次是doris和druid這兩個引擎,但是現在很多大廠,包括騰訊阿裡位元組都在往ClickHouse上面轉,當然京東零售也應用ClickHouse兩三年了。我們也進行了一系列的內核的研發,解決一些zookeeper的性能,還有線上彈性伸縮系統的一些東西,因為ClickHouse在彈性伸縮系統方面不太好,所以我們也在做這方面的工作。
Q:看到有一個業務場景中使用了120台高配置的機器,那麼如果申請到這麼多的資源進行業務支持,怎麼考慮投入產出?
A:我們投入了120台,產出就是可以把整個京東雲的所有的負載均衡。第一,我們為什麼要用120台,為什麼要用SSD的機型?還有為什麼這麼高配的機器?因為它的寫入量很大,平均每天大概6000億,算出每秒大概有1000萬的數據量在往集群里寫,如果不用這麼高配的機器,磁碟已經是SSD了,它的性能永遠達不到這個效果。第二點就是投入產出比,我們可以通過這個集群監控整個京東雲的日誌,還有負載均衡的效果。比如京東雲,一是對外,二是對內,監控和負載均衡都是非常重要的,所以用了我們的京東零售的OLAP來實監控京東雲的一個整體效果,還有整體穩定性,這樣產出比就非常大。
Q:主備庫切換時數據有延遲嗎,如何做到讓用戶感知最小?
A:主備庫切換,我們採用的是雙寫的流程,我們核心的業務都是雙寫的,就算在日常也都是雙寫,然後分流去查詢,不會造成主備儲備的集群的空閑。大促的時候,會採用一個百分比,比如說或者100%在主機型另一個集群就是當做備用,或者是會按照一定的比例80%-20%左右採用雙寫。業務方切換的時候基本上沒有任何延遲,只是將功能變數名稱切換了一下,數據都是在實時寫入,兩個集群,基本上沒有延遲。這是我們準備切換的一個功能。
Q:想問一下咱們的調優過程是怎麼樣的?
A:我們的調優過程先是結合自己的經驗,去優化一些參數,業務再進行壓測。因為想達到這麼大的QPS和這麼高的大吞吐的寫入,要時常進行壓測,壓測時如果遇到問題,會進行內核源碼的分析,然後再進行一系列參數調優或者內核優化。
本文首發於微信公眾號“DataFunTalk”。


