
一、概述 在眾多 Hadoop 版本中, CDH(Cloudera Hadoop) 是 Hadoop 眾多分支中比較出色的版本, 它由Cloudera 發行和維護。CDH 基於 Apache 的 Hadoop 進行重新構建,提供了基於 Web 頁面的群集部署和管理操作。Hadoop發行版除了社區的A ...
目錄
- 一、概述
- 二、CDH組件介紹
- 三、Cloudera Manager
- 四、CDH環境部署
一、概述
在眾多 Hadoop 版本中, CDH(Cloudera Hadoop) 是 Hadoop 眾多分支中比較出色的版本, 它由Cloudera 發行和維護。CDH 基於 Apache 的 Hadoop 進行重新構建,提供了基於 Web 頁面的群集部署和管理操作。Hadoop發行版除了社區的
Apache hadoop外,Cloudera Hadoop(CDH)、Hortonworks、MapR、EMC、IBM、INTEL、華為等都提供自己的商業版本。
從2021年2月1日起,所有CDH和Cloudera Manager的下載都需要用戶名和密碼,說白了就是需要money,用戶只能通過購買正式許可證才能夠線上下載CM和CDH安裝包,但是有免費版,只不過不讓線上安裝了,所以這裡使用本地離線安裝方式。
官方文檔:https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/introduction.html
1)目前比較流行Hadoop版本
- Apache Hadoop
維護人員比較多,更新頻率比較快,穩定性相對比較差。
- Cloudera Hadoop(CDH)
Cloudera公司的發行版本,基於Apache Hadoop的二次開發,優化了組件相容和交互介面、簡化安裝配置、增加Cloudera相容特。
2)CDH特點
- 靈活性——存儲任何類型的數據並使用各種不同的計算框架對其進行操作,包括批處理,互動式SQL,自由文本搜索,機器學習和統計計算。
- 集成——在完整的Hadoop平臺上快速啟動並運行,該平臺可與各種硬體和軟體解決方案配合使用。
- 安全性——處理和控制敏感數據。
- 可擴展性——支持廣泛的應用程式,並擴展它們以適應您的需求。
- 高可用性——可以執行關鍵型業務任務。
- 相容性——利用現有的IT基礎架構。
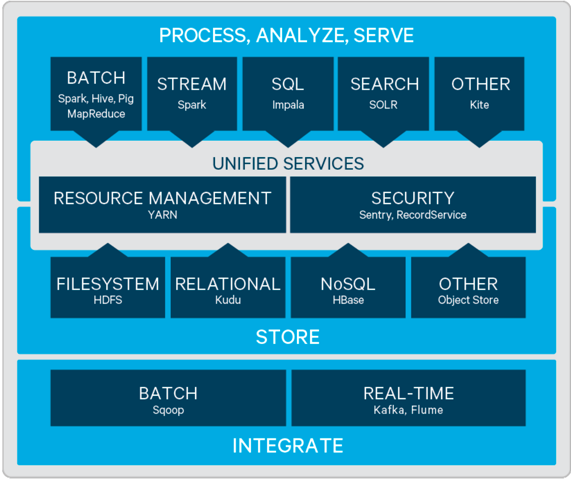
二、CDH組件介紹
1)Hive
-
Hive數據倉庫軟體支持對分散式存儲中的大型數據集進行讀寫和管理。HiveQL (Hive query language)是一種與SQL非常相似的查詢語言,通過MapReduce或Apache Spark將查詢轉換成一系列的任務,在Hadoop集群上執行。關於Hive,也可以參考我之前的文章:大數據Hadoop之——數據倉庫Hive
-
用戶可以使用Hive運行批處理工作負載,同時也可以使用Apache Impala或Apache spark等工具分析交互SQL或機器學習工作負載的相同數據——所有這些都在一個平臺中。
作為CDH的一部分,Hive還依賴於:
- YARN提供的統一資源管理;
- Cloudera Manager提供的簡化部署和管理;
- 共用安全和治理,以滿足Apache Sentry和Cloudera Navigator提供的合規需求。
2)Impala
- Impala是一款用於大數據的分散式資料庫查詢引擎。Impala並沒有取代基於MapReduce的批處理框架,比如Hive。Hive和其他構建在MapReduce上的框架最適合長時間運行的批處理作業,比如涉及Extract、Transform和Load (ETL)類型作業的批處理。
- Impala可以直接對存儲在HDFS、HBase或Amazon Simple Storage Service (S3)中的Apache Hadoop數據提供快速、互動式的SQL查詢。除了使用相同的統一存儲平臺外,Impala還使用了與Apache Hive相同的元數據、SQL語法(Hive SQL)、ODBC驅動、用戶界面(Hue中Impala查詢UI)。這為實時或面向批處理的查詢提供了熟悉的統一平臺。
1、Impala 優勢
- 在Apache Hadoop中查詢大量數據(“大數據”)的能力
- 集群環境中的分散式查詢,以便方便地擴展和利用具有成本效益的商品硬體。
- 能夠在不同的組件之間共用數據文件,沒有複製或導出/導入步驟;例如,用Pig編寫,用Hive轉換,用Impala查詢。Impala可以讀寫Hive表,通過使用Impala對Hive生成的數據進行分析,實現簡單的數據交換。
- 大數據處理和分析的單一系統,因此客戶可以避免昂貴的建模和ETL分析。
2、工作原理
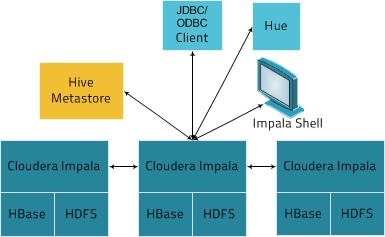
Impala解決方案由以下組件組成:
- 客戶端——實體包括Hue、ODBC客戶端、JDBC客戶端和Impala Shell都可以與Impala進行交互。這些介面通常用於發出查詢或完成管理任務,比如連接到Impala。
- Hive Metastore ——存儲關於Impala可用數據的信息。例如,metastore讓Impala知道哪些資料庫可用,以及這些資料庫的結構是什麼。當您通過Impala SQL語句創建、刪除和修改模式對象、將數據載入到表中等等時,相關的元數據更改會通過Impala 1.2中引入的專用目錄服務自動廣播到所有Impala節點。
- Impala——這個進程運行在datanode上,負責協調和執行查詢。每個Impala實例都可以接收、計劃和協調來自Impala客戶端的查詢。查詢分佈在Impala節點之間,這些節點充當工人,執行並行的查詢片段。
- HBase和HDFS低層數據存儲。
【溫馨提示】
HUE=Hadoop User Experience( Hadoop用戶體驗),直白來說就一個開源的Apache Hadoop UI系統,由Cloudera Desktop演化而來,最後Cloudera公 司將其貢獻給Apache基金會的Hadoop社區,它是基於Python Web框架Django實現的。通過使用HUE我們可以在瀏覽器端的We聯制臺上與Hadoop 集群進行交互來分析處理數據。
3、Impala查詢原理
- 用戶應用程式通過ODBC或JDBC向Impala發送SQL查詢,這些ODBC或JDBC提供了標準化的查詢介面。用戶應用程式可以連接到集群中的任何impalad。這個impalad成為查詢的協調器。
- Impala解析查詢並分析它,以確定集群中impalad實例需要執行哪些任務。執行計劃是為了達到最佳效率。
- HDFS、HBase等服務通過本地impalad實例訪問,提供數據。
- 每個impalad將數據返回給協調impalad,協調impalad將這些結果發送給客戶端。
4、Impala的特性
- Hive查詢語言(HiveQL)中最常見的SQL-92特性,包括SELECT、join和aggregate函數。
- HDFS、HBase、Amazon Simple Storage System (S3)存儲,包括:
- HDFS文件格式:delimited text files、Parquet、Avro、SequenceFile、RCFile。
- 壓縮編解碼器:Snappy, GZIP, Deflate, BZIP。
- 常用的數據存取介面包括:
- JDBC driver
- ODBC driver
3)Kudu
Apache Kudu是一個為Hadoop平臺開發的柱狀存儲管理器。Kudu擁有Hadoop生態系統應用程式的共同技術屬性:它運行在商用硬體上,具有水平可伸縮性,並支持高可用性操作。
1、Kudu 優勢
- 快速處理OLAP工作負載。
- 與MapReduce、Spark、Flume等Hadoop生態系統組件集成。
- 與Apache Impala的緊密集成,使其成為與Apache Parquet一起使用HDFS的一個很好的、可變的替代方案。
- 強大而靈活的一致性模型,允許您在每個請求的基礎上選擇一致性需求,包括嚴格序列化一致性的選項。
- 在同時運行順序和隨機工作負載方面有很強的性能。
- 通過Cloudera Manager輕鬆的管理。
- 高可用性,Tablet Servers和Master使用了Raft共識演算法,只要可用的副本比不可用的多,就可以確保可用。讀取可以由只讀的追隨者平板電腦來完成,即使是在leader平板電腦故障的情況下。
- 結構數據模型
2、Kudu-Impala集成
Apache Kudu與Apache Impala緊密集成,允許您使用Impala的SQL語法從Kudu平板電腦插入、查詢、更新和刪除數據,這是使用Kudu api構建自定義Kudu應用程式的另一種選擇。此外,您可以使用JDBC或ODBC將現有的或用任何語言、框架或商業智能工具編寫的新應用程式連接到您的Kudu數據,使用Impala作為代理。
CREATE/ALTER/DROP TABLE—Impala支持使用Kudu作為持久化層創建、修改和刪除表。這些表遵循與Impala中其他表相同的內部/外部方法,允許靈活地接收和查詢數據。INSERT—使用與HDFS或HBase持久化表相同的機制,Impala可以將數據插入到Kudu表中。UPDATE/DELETE—Impala支持UPDATE和DELETE SQL命令,可以逐行或批量修改Kudu表中的現有數據。SQL命令的語法被設計成儘可能與現有解決方案相容。除了簡單的DELETE或UPDATE命令外,您還可以在查詢的FROM子句中指定複雜的連接,使用與常規SELECT語句相同的語法。- 靈活的分區——類似於Hive中對錶的分區,Kudu允許你通過哈希或範圍動態地將表預分割成預定義數量的平板電腦,以便在集群中均勻地分配寫和查詢。您可以按任意數量的主鍵列、任意數量的散列、分割行的列表或這些列的組合進行分區。分區方案是必需的。
- 並行掃描——為了在現代硬體上實現最高的性能,Impala使用的Kudu客戶端可以在多個平板電腦上並行掃描。
- 高效查詢——在可能的情況下,Impala將謂詞計算下推到Kudu,以便謂詞的計算儘可能接近數據。在許多工作負載中,查詢性能與Parquet相當。
5)Sentry
-
Apache Sentry是Hadoop的一個基於角色的細粒度授權模塊。Sentry提供了在Hadoop集群上為經過身份驗證的用戶和應用程式控制和強制數據上的精確許可權級別的能力。目前,Sentry在Apache Hive、Hive Metastore/HCatalog、Apache Solr、Impala和HDFS(僅限於Hive表數據)上都是開箱可用的。 -
Sentry被設計成一個可插拔的Hadoop組件授權引擎。它允許您定義授權規則來驗證用戶或應用程式對Hadoop資源的訪問請求。Sentry是高度模塊化的,可以支持Hadoop中各種數據模型的授權。
6)Spark
可以參考我之前Spark的幾篇文章:
- 大數據Hadoop之——計算引擎Spark
- 大數據Hadoop之——Spark集群部署(Standalone)
- 大數據Hadoop之——Spark SQL+Spark Streaming
- 大數據Hadoop之——Spark on Hive 和 Hive on Spark的區別與實現
- 大數據Hadoop之——Spark Streaming原理
三、Cloudera Manager
Cloudera Manager是一個端到端用於管理CDH集群的應用程式。Cloudera Manager通過提供對CDH集群每個部分的細粒度可見性和控制,為運營商提高性能、提高服務質量、提高合規和降低管理成本設定了企業部署的標準。使用Cloudera Manager,您可以輕鬆地部署和集中操作完整的CDH堆棧和其他托管服務。該應用程式自動化安裝過程,將部署時間從幾周減少到幾分鐘;提供集群範圍內主機和服務運行的實時視圖;提供單一的中央控制台來執行跨集群的配置更改;並整合了一系列的報告和診斷工具,以幫助您優化性能和利用率。本入門介紹了Cloudera Manager的基本概念、結構和功能。
1)Terminology(術語)
為了有效地使用Cloudera Manager,您應該首先理解它的術語。這些術語之間的關係如下所示,它們的定義如下:
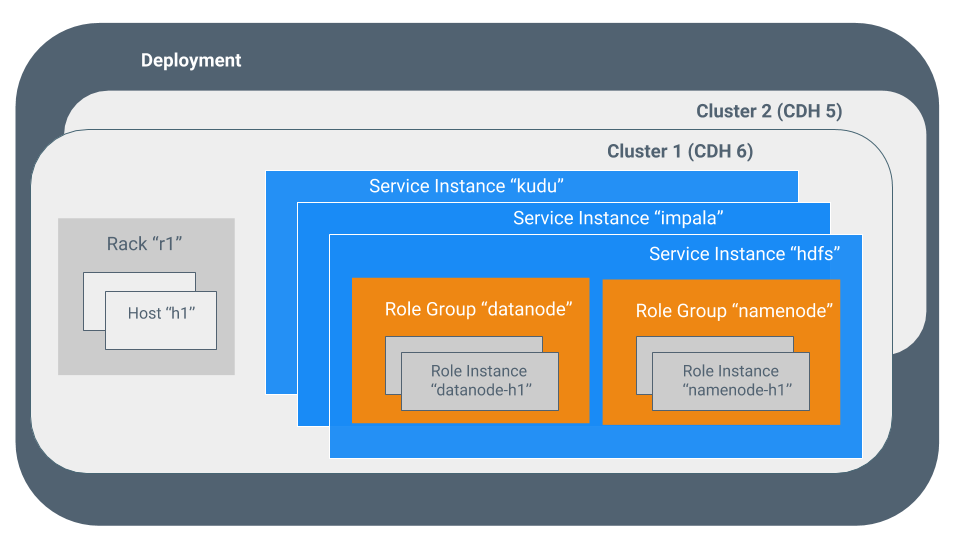
- deployment
Cloudera Manager和它管理的所有集群的配置。
- dynamic resource pool(動態資源池)
在Cloudera Manager中,一個命名的資源配置和一個用於在YARN應用程式或池中運行的Impala查詢之間調度資源的策略。
- cluster
- 一組包含HDFS文件系統的電腦或機架,併在該數據上運行MapReduce和其他進程。偽分散式集群是運行在一臺機器上的CDH安裝,對於演示和個人研究非常有用。
- 在Cloudera Manager中,包含一組主機的邏輯實體、安裝在主機上的單一版本的CDH,以及運行在主機上的服務和角色實例。一個主機只能屬於一個集群。Cloudera Manager可以管理多個CDH集群,但每個集群只能與單個Cloudera Manager伺服器或Cloudera Manager HA對關聯。
- host
在Cloudera Manager中,運行角色實例的物理或虛擬機。一個主機只能屬於一個集群。
- rack
在Cloudera Manager中,包含一組物理主機的物理實體,通常由同一臺交換機提供服務。
-
service
- Linux命令,運行
/etc/init目錄下System V init腳本在儘可能可預測的環境中,刪除大多數環境變數,並將當前工作目錄設置為/。 - clouddera Manager中的一類托管功能,可以是分散式的,也可以不是,在集群中運行。有時稱為服務類型。例如:MapReduce、HDFS、YARN、Spark、Accumulo。在傳統環境中,多個服務運行在一臺主機上;在分散式系統中,一個服務運行在許多主機上。
- Linux命令,運行
-
service instance
在Cloudera Manager中,集群中運行的服務實例。例如:“HDFS-1”、“yarn”。一個服務實例跨越多個角色實例。
- role
在Cloudera Manager中,服務中的一個功能類別。例如,HDFS服務的角色有:NameNode、SecondaryNameNode、DataNode、Balancer。有時稱為角色類型。
- role instance
在Cloudera Manager中,運行在主機上的角色實例。它通常映射到Unix進程。例如:“NameNode-h1”、“DataNode-h1”。
- role group
在Cloudera Manager中,一組角色實例的一組配置屬性。
- host template
Cloudera Manager中的一組角色組。將模板應用到主機時,每個角色組中會創建一個角色實例,並分配給該主機。
-
gateway
- 一種角色類型,通常為客戶端提供對特定集群服務的訪問。例如,HDFS、Hive、Kafka、MapReduce、Solr、Spark都有網關角色,為客戶端提供對各自服務的訪問。網關角色的名稱中並不總是包含“網關”,也不是僅供客戶端訪問。例如,Hue Kerberos Ticket Renewer是一個網關角色,它從Kerberos代理票據。
- 支持一個或多個網關角色的節點有時被稱為網關節點或邊緣節點,“邊緣”的概念在網路或雲環境中很常見。對於Cloudera集群,當從Cloudera Manager管理控制台的Actions菜單中選擇Deploy client configuration時,集群中的網關節點接收適當的客戶端配置文件。
-
parcel
一種二進位發佈格式,包含已編譯代碼和元信息,如包描述、版本和依賴關係。
- static service pool(靜態服務池)
在Cloudera Manager中,對一組服務的總集群資源(cpu、記憶體和I/O權重)進行靜態分區。
2)Architecture(架構)
如下圖所示,Cloudera Manager的核心是Cloudera Manager Server。伺服器承載管理控制台Web Server和應用程式邏輯,並負責安裝軟體、配置、啟動和停止服務,以及管理服務運行的集群。

Cloudera Manager伺服器與其他幾個組件一起工作:
- Agent——安裝在每台主機上。代理負責啟動和停止進程、解包配置、觸發安裝和監視主機。
- Management Service——由一組角色組成的服務,這些角色執行各種監視、警報和報告功能。
- **Database **——存儲配置和監控信息。通常,多個邏輯資料庫在一個或多個資料庫伺服器上運行。例如,Cloudera Manager Server和監控角色使用不同的邏輯資料庫。
- Cloudera Repository——由clouddera Manager發佈的軟體存儲庫。
- Clients——是與伺服器交互的介面:
- Admin Console——基於web的UI,管理員可以使用它管理集群和Cloudera Manager。
- API ——開發人員用來創建自定義Cloudera Manager應用程式的API。
3)心跳檢測
- 心跳是Cloudera Manager中的主要通信機制。預設情況下,代理每
15秒向Cloudera Manager伺服器發送一次心跳。然而,為了減少用戶延遲,當狀態發生變化時,頻率會增加。 - 在心跳交換期間,Agent通知Cloudera Manager Server它的活動。然後,Cloudera Manager Server響應Agent應該執行的操作。代理和Cloudera Manager伺服器最終都進行了一些協調。例如,如果啟動一個服務,Agent會嘗試啟動相關的進程;如果進程啟動失敗,則Cloudera Manager Server將啟動命令標記為失敗。
4)State Management(狀態管理)
Cloudera Manager Server維護集群的狀態。這種狀態可以分為兩類:“模型”和“運行時”,兩者都存儲在Cloudera Manager Server資料庫中。
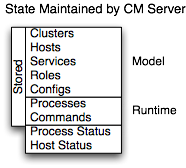
5)Configuration Management(配置管理)
Cloudera Manager定義了幾個級別的配置:
- 服務級別可以定義應用於整個服務實例的配置,例如HDFS服務的預設複製因數(dfs.replication)。
- 角色組級別可以定義應用於成員角色的配置,例如datanode的處理程式計數(dfs.datanode.handler.count)。對於不同組的datanode,可以進行不同的設置。例如,運行在性能更好的硬體上的datanode可能有更多的處理器。
- 角色實例級別可以覆蓋它從其角色組繼承的配置。這應該謹慎使用,因為它很容易導致角色組內的配置分歧。一個示例用法是在特定角色實例中臨時啟用調試日誌記錄以排除問題。
- 主機具有監控、軟體管理、資源管理等相關配置。
- Cloudera Manager本身擁有與其管理操作相關的配置。
1、Host Templates(主機模板)
在典型的環境中,主機集具有相同的硬體和運行在其上的相同的服務集。主機模板在集群中定義了一組角色組(每種類型最多一個),主要有兩個好處:
- 將新主機添加到集群中很容易——多個主機可以在單個操作中創建、配置和啟動不同服務的角色。
- 輕鬆更改——組主機上不同服務的角色配置,這有助於快速切換整個集群的配置,以適應不同的工作負載或用戶。
2、Server and Client Configuration(伺服器和客戶端配置)
- 管理員有時會感到驚訝,修改
/etc/hadoop/conf,然後重啟HDFS沒有效果。這是因為由Cloudera Manager啟動的服務實例不會從預設位置讀取配置。以HDFS為例,當不被Cloudera Manager管理時,每台主機通常會有一個HDFS配置,位於/etc/hadoop/conf/hdfs-site.xml。在同一主機上運行的伺服器端守護進程和客戶端都將使用相同的配置。 - Cloudera Manager區分了伺服器配置和客戶端配置。對於HDFS,“
/etc/hadoop/conf/hdfs-site.xml”文件中只包含與HDFS客戶端相關的配置。也就是說,預設情況下,如果您運行一個需要與Hadoop通信的程式,它將從該目錄獲取NameNode和JobTracker的地址,以及其他重要配置。/etc/hbase/conf和/etc/hive/conf採用了類似的方法。 - 相反,HDFS角色實例(例如NameNode和DataNode)從私有的每進程目錄(/var/run/cloudera-scm-agent/process/unique-process-name)中獲取配置。為每個進程提供自己的私有執行和配置環境,允許Cloudera Manager獨立控制每個進程。例如,879-hdfs-NAMENODE進程目錄的內容如下:
$ tree -a /var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/
/var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/
├── cloudera_manager_Agent_fencer.py
├── cloudera_manager_Agent_fencer_secret_key.txt
├── cloudera-monitor.properties
├── core-site.xml
├── dfs_hosts_allow.txt
├── dfs_hosts_exclude.txt
├── event-filter-rules.json
├── hadoop-metrics2.properties
├── hdfs.keytab
├── hdfs-site.xml
├── log4j.properties
├── logs
│ ├── stderr.log
│ └── stdout.log
├── topology.map
└── topology.py
區分伺服器和客戶端配置提供了幾個優點:
- 伺服器端配置中的敏感信息,如Hive Metastore RDBMS的密碼,不會泄露給客戶端。
- 依賴於另一個服務的服務可以使用自定義配置進行部署。
- 客戶機配置文件要小得多,可讀性也更好。這也避免了將非管理員Hadoop用戶與不相關的伺服器端屬性混淆。
3、部署客戶端配置和網關
- 客戶端配置是包含服務設置的相關配置文件的zip文件。每個zip文件包含服務所需的一組配置文件。
- Cloudera Manager可以在集群中部署客戶端配置;每個適用的服務都有一個Deploy Client Configuration操作。此操作並不一定要將客戶端配置部署到整個集群;它只將客戶端配置部署到該服務已分配給的所有主機。
- 要將客戶端配置部署到沒有為其分配角色的主機,您需要使用網關。網關是一個標記,用來表示服務應該可以從特定的主機訪問。與所有其他角色不同,它沒有關聯的進程。
- 網關也可以為某些主機定製客戶端配置。網關可以放置在角色組中,這些組可以進行不同的配置。然而,與角色實例不同的是,無法覆蓋網關實例的配置。
- 在我們前面討論過的集群中,沒有Hive角色實例的三個主機(tcdn501-[2-5])擁有Hive網關:
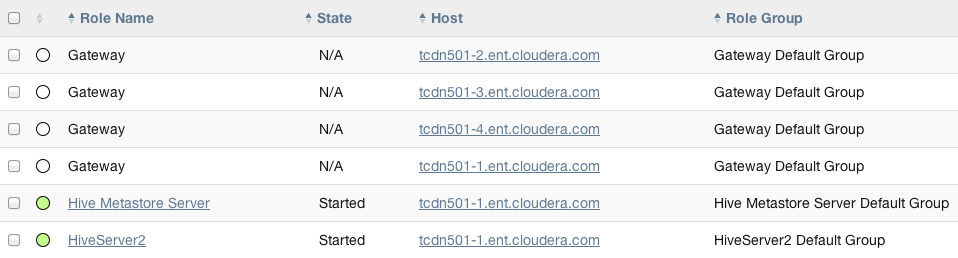
6)部署客戶端配置和網關
-
在一個非cloudera Manager管理的集群中,你很可能使用init腳本啟動一個角色實例進程,例如service hadoop-hdfs-datanode start。Cloudera Manager不為它管理的守護進程使用init腳本;在由Cloudera Manager管理的集群中,使用init腳本啟動和停止服務是無效的。
-
在由Cloudera Manager管理的集群中,只能通過Cloudera Manager啟動或停止角色實例進程。Cloudera Manager使用一個名為supervisor的開源進程管理工具,該工具啟動進程,負責重定嚮日志文件、通知進程失敗、將調用進程的有效用戶ID設置為正確的用戶,等等。Cloudera Manager支持自動重啟崩潰的進程。如果一個角色實例的進程在啟動後多次崩潰,它還會用一個糟糕的健康狀況標誌來標記它。
-
停止Cloudera Manager伺服器和Cloudera Manager代理不會導致服務停止;任何正在運行的角色實例都將繼續運行。
-
Agent以init方式啟動。d在啟動。然後,它又與Cloudera Manager Server聯繫,確定應該運行哪些進程。Agent作為Cloudera Manager主機監控的一部分被監控。如果Agent停止心跳,主機將被標記為健康狀態不良。
-
Agent的主要職責之一是啟動和停止流程。當Agent從Server heartbeat中檢測到一個新進程時,Agent會在/var/run/cloudera-scm-agent中為它創建一個目錄,並解包配置。然後它聯繫監督者,監督者開始這個過程。
-
這些行動強化了一個重要的觀點:Cloudera Manager流程從不單獨運行。換句話說,進程不僅僅是exec()的參數,它還包括配置文件、需要創建的目錄和其他信息。
7)軟體分發管理
Cloudera Manager的一個主要功能是安裝和升級CDH和其他托管服務。Cloudera Manager支持兩種軟體分發格式:
packages and parcels。
- 包是一種二進位發佈格式,包含編譯後的代碼和元信息,比如包描述、版本和依賴關係。包管理系統評估這個元信息,以允許包搜索、升級到新版本,並確保包的所有依賴項都得到滿足。Cloudera Manager為每個支持的操作系統使用本地系統包管理器。
包是一種二進位分發格式,包含程式文件,以及Cloudera Manager使用的額外元數據。包裹和包裹之間的重要區別是:
- 包裹是自包含的,並且安裝在一個版本控制的目錄中,這意味著一個給定包裹的多個版本可以同時安裝。然後,您可以將這些已安裝版本中的一個指定為活動版本。對於包,一次只能安裝一個包,因此安裝的包和活動的包之間沒有區別。
- 滾動升級需要包裹。
- 您可以在文件系統的任何位置安裝包。它們預設安裝在
/opt/cloudera/ packages目錄下。相反,包安裝在/usr/lib目錄下。
8)主機管理
- Cloudera Manager提供了幾個特性來管理Hadoop集群中的主機。第一次運行Cloudera Manager Admin Console時,您可以搜索要添加到集群中的主機,一旦主機被選中,您就可以將CDH角色的分配映射到主機。Cloudera Manager自動部署集群中所有需要作為托管主機參與的軟體:JDK、Cloudera Manager Agent、CDH、Impala、Solr等。
- 部署並運行服務之後,管理控制臺中的Hosts區域將顯示集群中受管理主機的總體狀態。包括主機上運行的CDH版本、主機所屬集群、主機上運行的角色數量。Cloudera Manager提供參與主機的生命周期管理、主機的添加、刪除等操作。Cloudera Management Service Host Monitor角色執行運行狀況測試並收集主機指標,以便監控主機的運行狀況和性能。
9)資源管理
資源管理通過定義不同服務對集群資源的影響,幫助確保可預測的行為。使用資源管理:
- 保證在合理的時間內完成關鍵的工作負荷。
- 支持基於組間資源公平分配的用戶組間合理的集群調度。
- 防止用戶剝奪其他用戶對集群的訪問許可權。
使用cgroups靜態分配資源可以通過單個靜態服務池嚮導進行配置。您按總資源的百分比分配服務,嚮導配置cgroup。
以下圖為例,HBase、HDFS、Impala、YARN服務的靜態池分別分配20%、30%、20%、30%的集群資源為例。
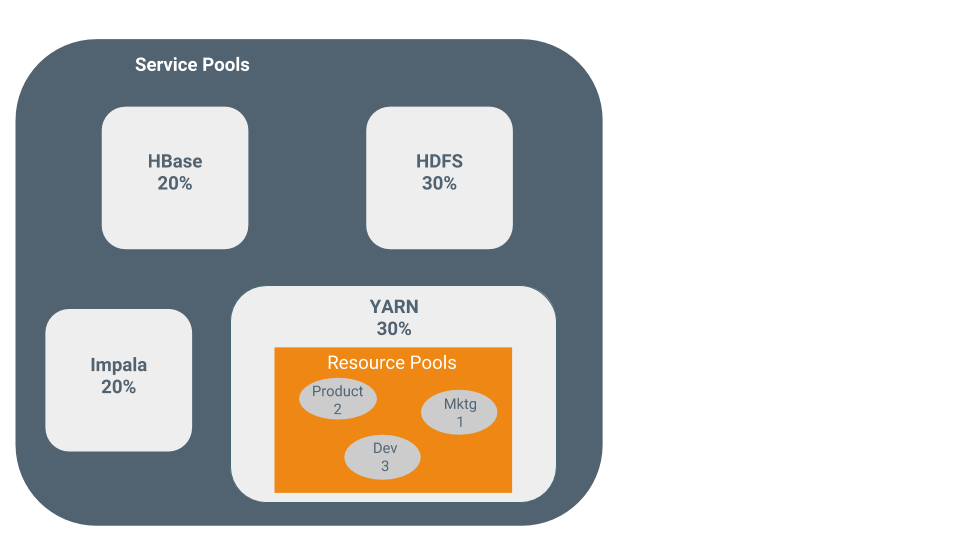
通過使用動態資源池,可以動態分配靜態分配給YARN和Impala的資源。
根據你使用的CDH版本,clouddera Manager中的動態資源池支持以下場景:
- YARN——YARN管理虛擬核、記憶體、運行的應用程式、未聲明的子池(父池)的最大資源,以及每個池的調度策略。在前面的圖中,為YARN定義了三個動態資源池Dev、Product和Mktg,權重分別為3、2和1。如果一個應用程式啟動並分配給Product池,而其他應用程式正在使用Dev和Mktg池,則Product資源池將接收到集群總資源的30% x 2/6(或10%)。如果沒有應用程式使用Dev和Mktg池,YARN Product池將分配30%的集群資源。
- Impala——Impala為運行查詢的池管理記憶體,並限制每個池中運行查詢和排隊查詢的數量。
10)用戶管理
Cloudera Manager提供了幾種用戶身份驗證機制。您可以配置Cloudera Manager,根據Cloudera Manager資料庫或外部身份驗證服務對用戶進行身份驗證。外部認證服務可以是LDAP伺服器(Active Directory或OpenLDAP相容目錄),也可以指定其他外部服務。Cloudera Manager還支持使用安全斷言標記語言(SAML)來支持單點登錄。
11)安全管理
Cloudera Manager致力於整合多個項目的安全配置。身份驗證是一個過程,在嘗試訪問系統資源時,用戶和服務需要證明他們的身份。組織通常通過各種經過時間考驗的技術來管理用戶身份和身份驗證,包括用於身份、目錄和其他服務(如組管理)的輕量級目錄訪問協議(Lightweight Directory Access Protocol, LDAP)和用於身份驗證的Kerberos。
12)Cloudera管理服務
Cloudera管理服務以一組角色的形式實現各種管理特性:
- Activity Monitor——收集MapReduce服務運行的活動的信息。預設不添加此角色。
- Host Monitor—收集主機的運行狀況和度量信息。
- Service Monitor——從YARN和Impala服務收集有關服務的運行狀況和度量信息以及活動信息。
- Event Server——聚集相關的Hadoop事件,並使它們可用來進行警告和搜索。
- Alert Publisher——為某些類型的事件生成和發送警報
- Reports Manager——生成報表,提供用戶、用戶組、目錄的磁碟利用率、用戶和YARN池的處理活動、HBase表和命名空間的歷史視圖。Cloudera Express中未添加此角色。
四、CDH環境部署
1)前期準備
1、機器信息
| OS | IP | hostname | 角色 |
|---|---|---|---|
| centos7 | 192.168.182.161 | hadoop-cdhmaster-168-182-161 | CM server、CM agent、CM deamon、CDH |
| centos7 | 192.168.182.162 | hadoop-cdhslave01-168-182-162 | CM agent、CM deamon、CDH |
| centos7 | 192.168.182.163 | hadoop-cdhslave02-168-182-163 | CM agent、CM deamon、CDH |
【溫馨提示】centos8會存在不相容問題

2、修改主機名
$ hostnamectl set-hostname hadoop-cdhmaster-168-182-161
$ hostnamectl set-hostname hadoop-cdhslave01-168-182-162
$ hostnamectl set-hostname hadoop-cdhslave02-168-182-163

3、配置hosts
$ cat >> /etc/hosts << EOF
192.168.182.161 hadoop-cdhmaster-168-182-161
192.168.182.162 hadoop-cdhslave01-168-182-162
192.168.182.163 hadoop-cdhslave02-168-182-163
EOF

4、關掉防火牆
$ systemctl stop firewalld
$ systemctl disable firewalld
5、禁用SELINUX
$ sed -i "s/.*SELINUX=.\*/SELINUX=disabled/g" /etc/selinux/config
6、時間同步
$ yum -y install chrony
$ systemctl start chronyd
$ chronyc sources -v
# 同步硬體時鐘到系統時鐘
$ hwclock --systohc
# 檢測時間
$ timedatectl
7、安裝python
CDH 6中的Hue要求Python 2.7.5或更低,預設包含在RHEL 7相容的操作系統(os)中。Centos7一般自帶了Python 2.7.5了,可以跳過,如果沒有,則按下麵命令安裝。
$ yum install python275
$ ln -s /usr/bin/python2 /usr/bin/python
$ python --version
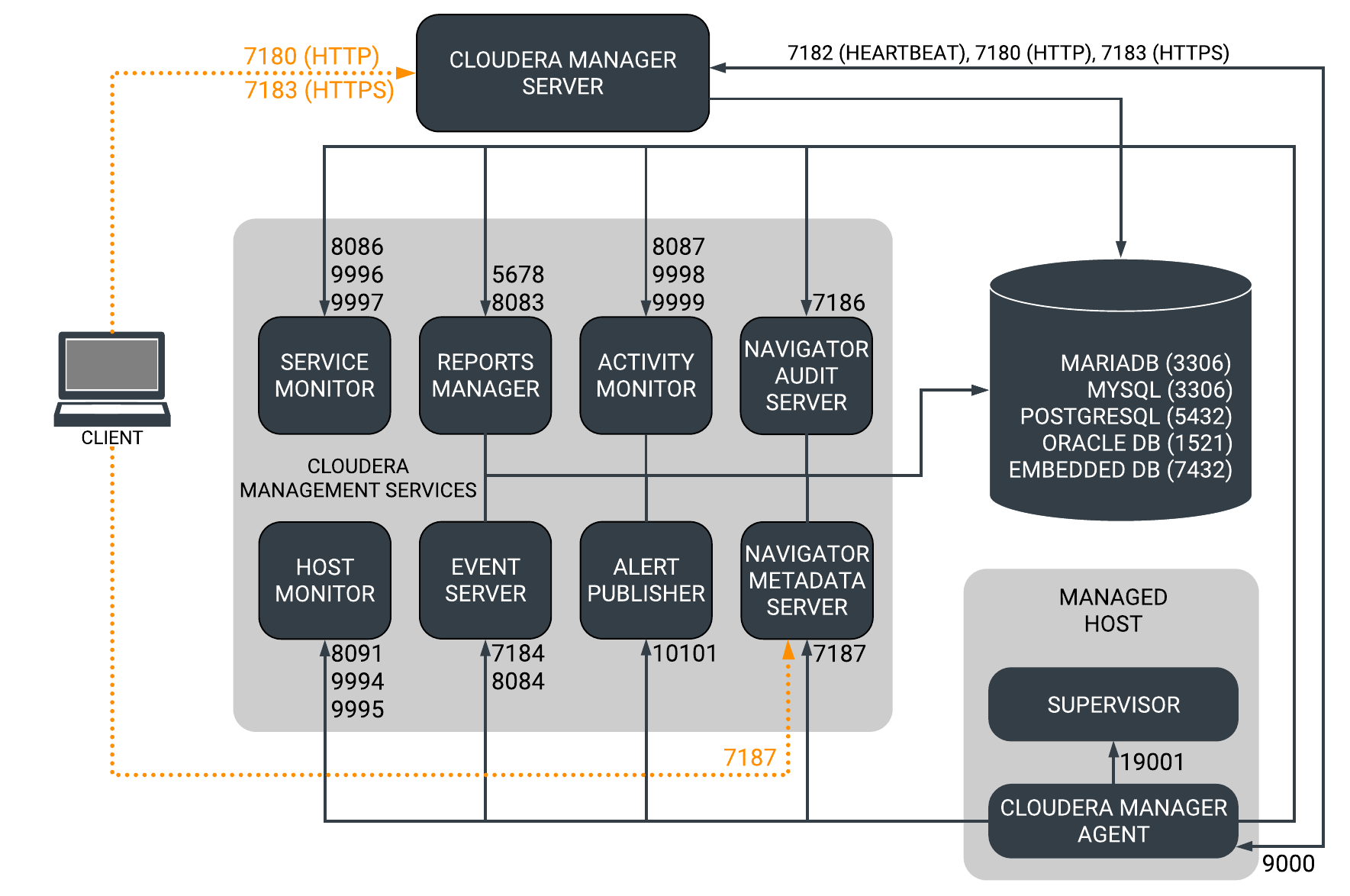
8、埠
下圖概述了Cloudera Manager、Cloudera Navigator和Cloudera Management Service角色使用的一些埠。
Cloudera Manager和Cloudera Navigator使用的埠
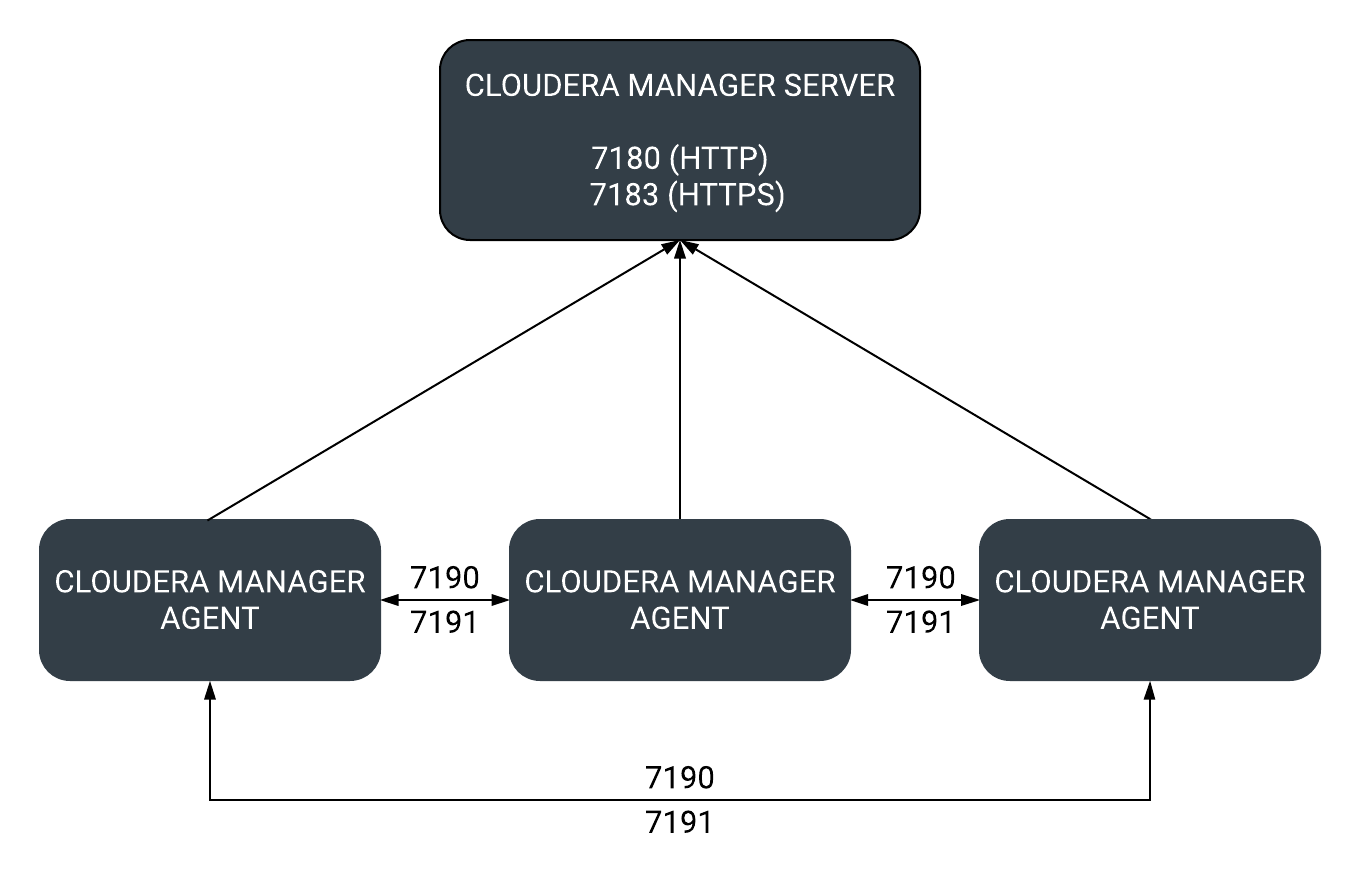
點對點包裹分發中使用的埠
更多使用的埠信息,可以參考官方文檔:https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cm_ig_ports_cm.html
9、配置免密登錄
$ ssh-keygen
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-cdhmaster-168-182-161
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-cdhslave01-168-182-162
$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop-cdhslave02-168-182-163
9、安裝JDK
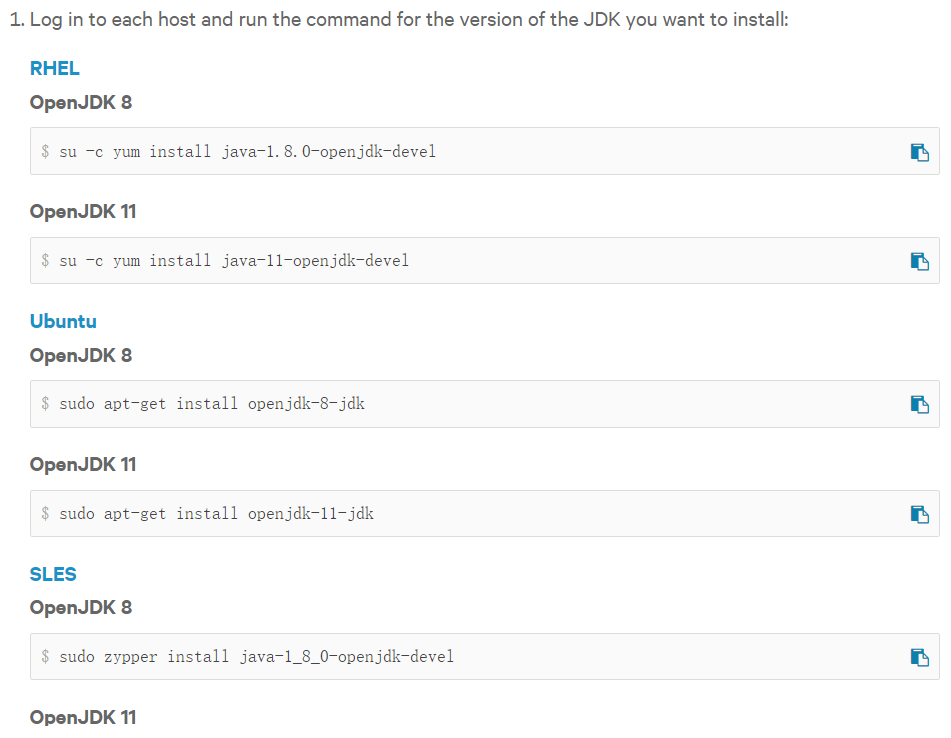
$ yum install java-1.8.0-openjdk-devel -y
【溫馨提示】最好按照官方的方式安裝jdk,要不然可能會出現服務起不來。
10、交換分區和大頁設置
所有集群節點都要執行,禁用交換分區和透明大頁,否則會在安裝配置 CDH 群集環境檢測中報錯。
$ sysctl -w vm.swappiness=0
$ echo "vm.swappiness=0" >> /etc/sysctl.conf
$ echo never > /sys/kernel/mm/transparent_hugepage/defrag
$ echo never >/sys/kernel/mm/transparent_hugepage/enabled
$ echo "echo never > /sys/kernel/mm/transparent_hugepage/defrag" >> /etc/rc.d/rc.local
$ echo "echo never > /sys/kernel/mm/transparent_hughugepage/enabled" >> /etc/rc.d/rc.local
2)安裝CM前期準備
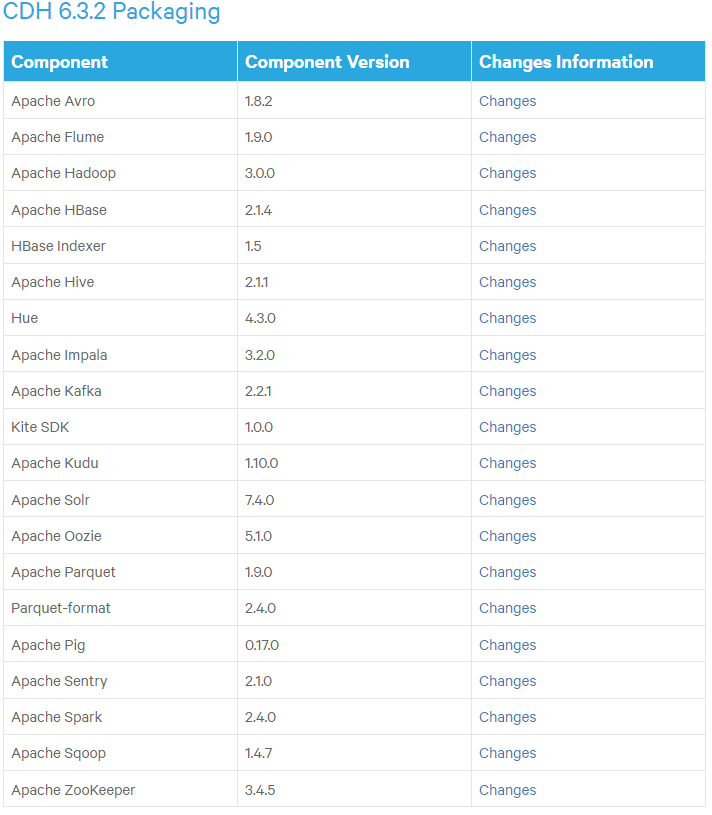
1、組件版本
2、安裝Mysql(cdhmaster)
$ wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
$ rpm -ivh mysql-community-release-el7-5.noarch.rpm
$ yum update -y
# 安裝
$ yum install mysql-server -y
配置/etc/my.cnf
$ cat >> /etc/my.cnf << EOF
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
transaction-isolation = READ-COMMITTED
# Disabling symbolic-links is recommended to prevent assorted security risks;
# to do so, uncomment this line:
symbolic-links = 0
key_buffer_size = 32M
max_allowed_packet = 16M
thread_stack = 256K
thread_cache_size = 64
query_cache_limit = 8M
query_cache_size = 64M
query_cache_type = 1
max_connections = 550
#expire_logs_days = 10
#max_binlog_size = 100M
#log_bin should be on a disk with enough free space.
#Replace '/var/lib/mysql/mysql_binary_log' with an appropriate path for your
#system and chown the specified folder to the mysql user.
log_bin=/var/lib/mysql/mysql_binary_log
#In later versions of MySQL, if you enable the binary log and do not set
#a server_id, MySQL will not start. The server_id must be unique within
#the replicating group.
server_id=1
binlog_format = mixed
read_buffer_size = 2M
read_rnd_buffer_size = 16M
sort_buffer_size = 8M
join_buffer_size = 8M
# InnoDB settings
innodb_file_per_table = 1
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 64M
innodb_buffer_pool_size = 4G
innodb_thread_concurrency = 8
innodb_flush_method = O_DIRECT
innodb_log_file_size = 512M
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
sql_mode=STRICT_ALL_TABLES
EOF
啟動服務
# 啟動
$ systemctl start mysqld
$ systemctl status mysqld
# 開機自啟動
$ systemctl enable mysqld
# 登錄,預設沒有密碼
$ mysql
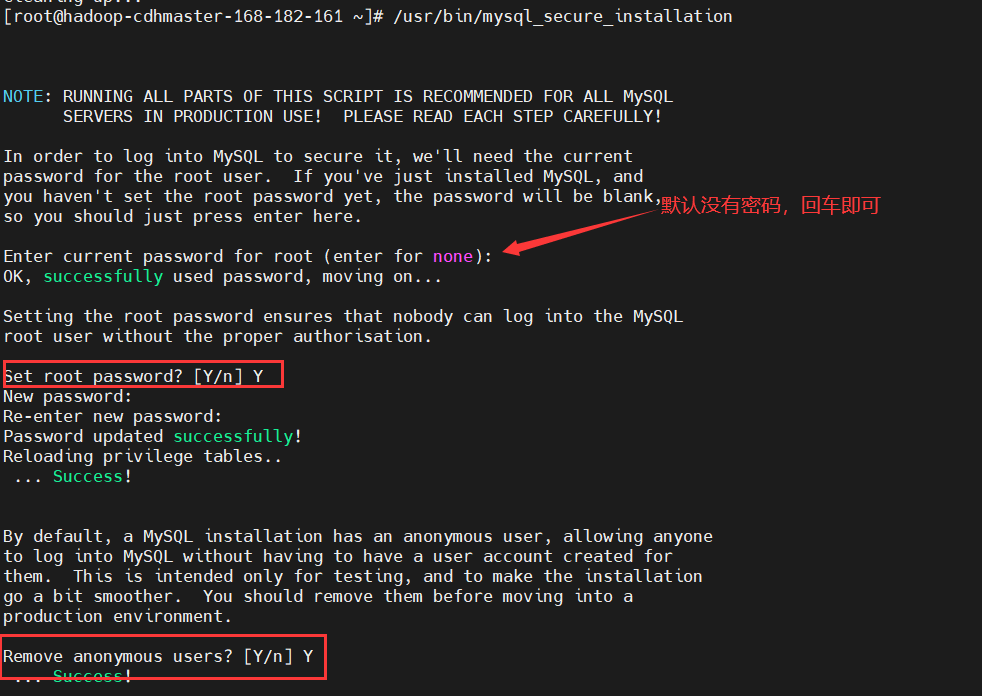
設置root密碼
$ /usr/bin/mysql_secure_installation
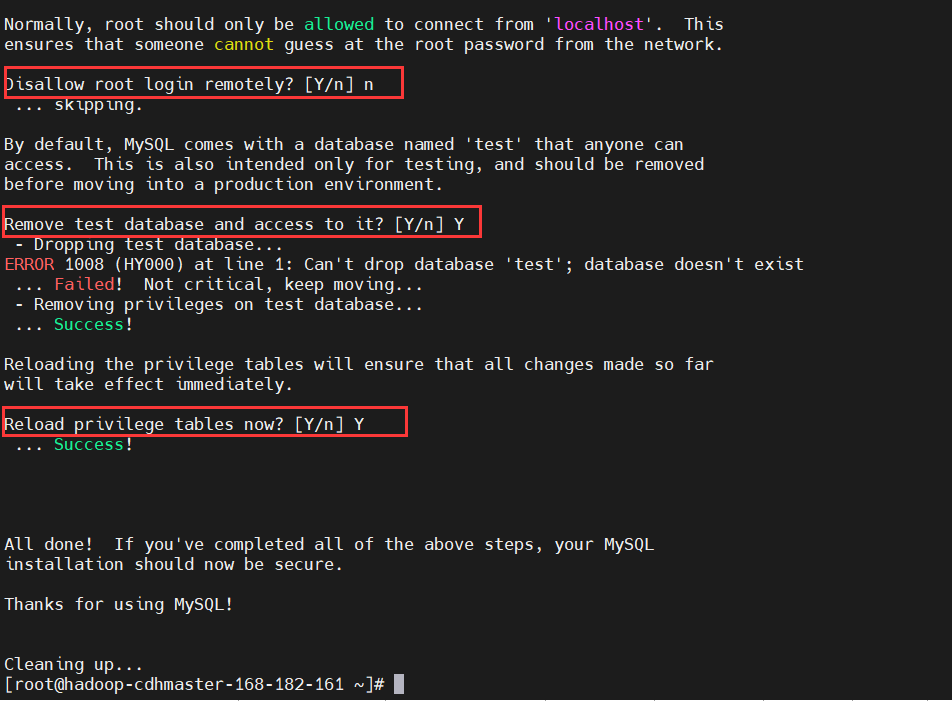
連接驗證
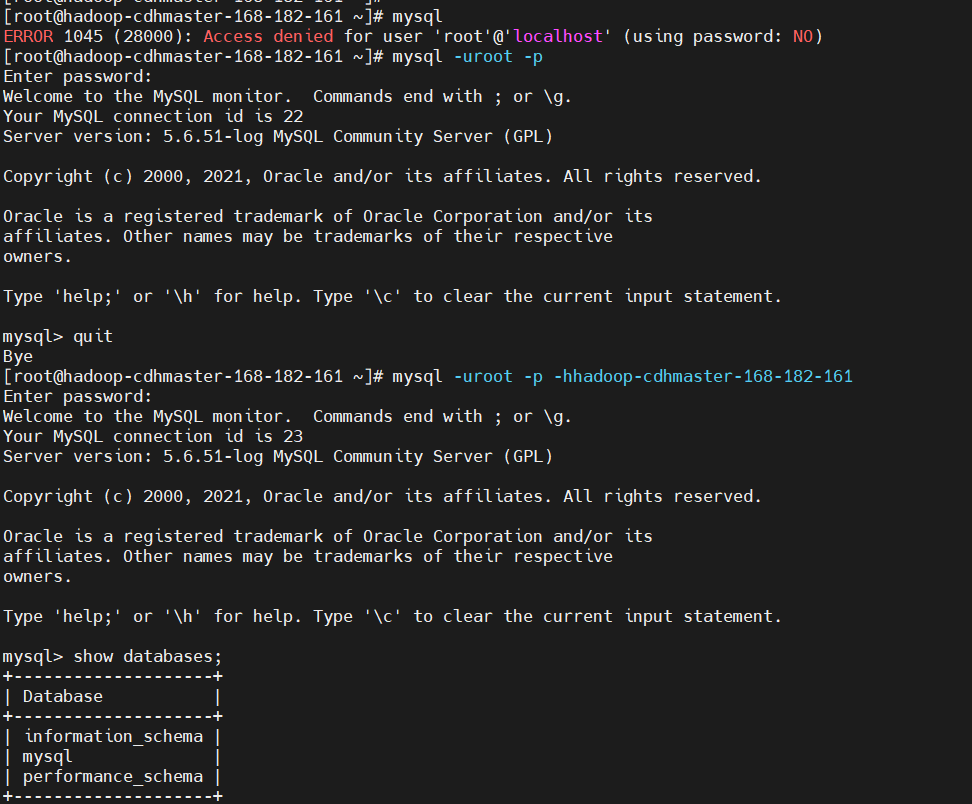
3、為 Cloudera 各軟體創建資料庫

$ mysql -uroot -p -h
密碼:123456
### scm
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY '123456';
### amon
CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY '123456';
### rman
CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY '123456';
### hue
CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY '123456';
### hive
CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY '123456';
### sentry
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY '123456';
### nav
CREATE DATABASE nav DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON nav.* TO 'nav'@'%' IDENTIFIED BY '123456';
### navms
CREATE DATABASE navms DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON navms.* TO 'navms'@'%' IDENTIFIED BY '123456';
### oozie
CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY '123456';
# 最後刷新一下
flush privileges;
### 檢查
show databases;

4、安裝 MySQL JDBC(所有節點)
用於各節點連接資料庫,JDBC的版本跟mysql版本對應。
$ mkdir /opt/software/CDH /opt/server/CDH -p
$ cd /opt/software/CDH
$ wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.46.tar.gz
$ tar -xf mysql-connector-java-5.1.46.tar.gz
# 必須放在/usr/share/java/這個目錄下,沒有就創建,而且名字得改成mysql-connector-java.jar
$ mkdir -p /usr/share/java/
$ cp mysql-connector-java-5.1.46/mysql-connector-java-5.1.46.jar /usr/share/java/mysql-connector-java.jar

3)安裝 CM Server 和 CM Agent
【溫馨提示】cloudera-manager-daemons是守護進程,所有節點都得安裝。
1、下載安裝包
CDH官方的網站已經無法直接下載安裝包了(需要賬號密碼),也就是說需要錢了,不是免費的了,這裡提供百度雲下載地址。
鏈接:https://pan.baidu.com/s/16raZeCbAxoqx6A54Fo3-Nw
提取碼:6666
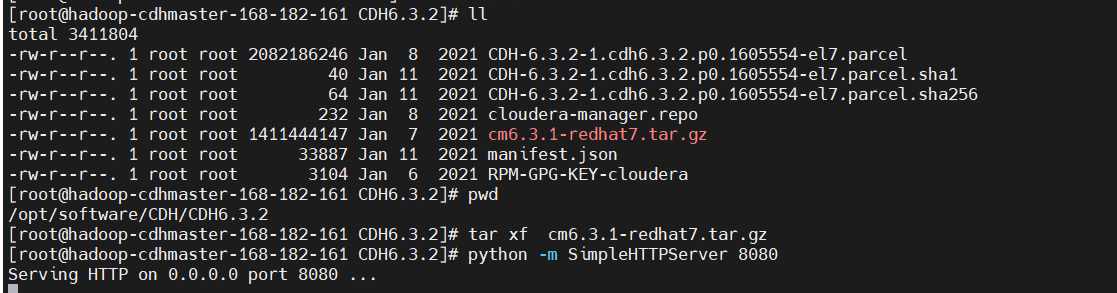
把下載好的壓縮包解壓,並用python 啟動一個本地服務作為本地倉庫
$ cd /opt/software/CDH/
$ unzip CDH6.3.2.zip
$ cd CDH6.3.2
$ tar -xf cm6.3.1-redhat7.tar.gz
$ python -m SimpleHTTPServer 8080
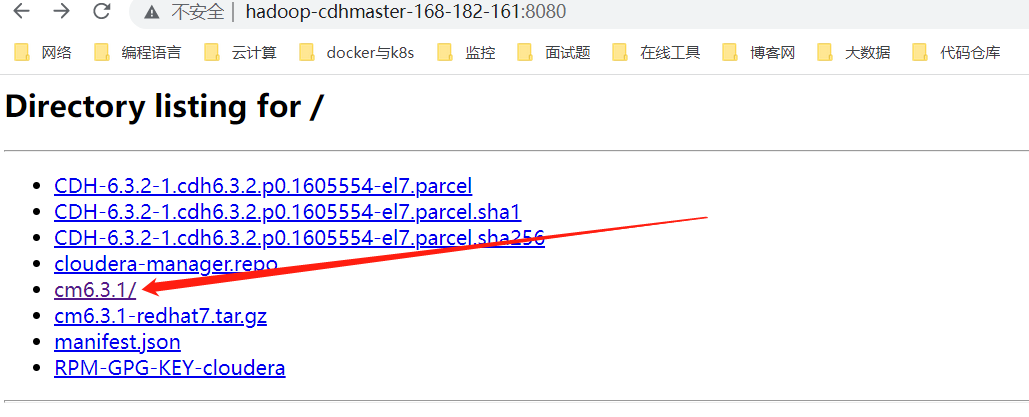
配置本地yum源(所有節點)
$ cat > /etc/yum.repos.d/cloudera-manager.repo << EOF
[cloudera-manager]
name=Cloudera-Manager
baseurl=http://hadoop-cdhmaster-168-182-161:8080/cm6.3.1/
gpgcheck=0
enabled=1
EOF
# 清除緩存並生成新的緩存
$ yum clean all
$ yum makecache
2、安裝CM Server 和Agent(cdhmaster)
$ yum install -y cloudera-manager-agent cloudera-manager-daemons cloudera-manager-server
3、安裝CM Agent(其它節點)
$ yum install -y cloudera-manager-agent cloudera-manager-daemons
4、CM 資料庫初始化
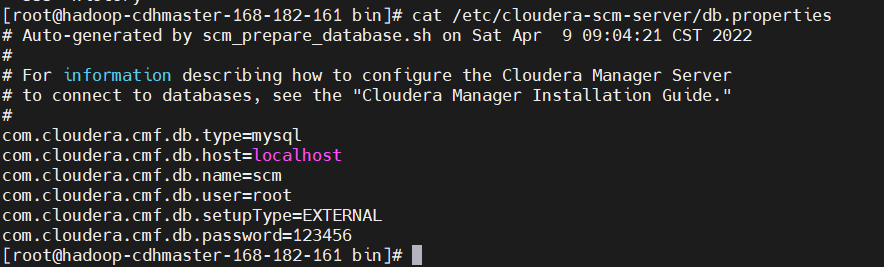
# /opt/cloudera/cm/schema/scm_prepare_database.sh <databaseType> <databaseName> <databaseUser> <password>
$ /opt/cloudera/cm/schema/scm_prepare_database.sh mysql scm root 123456

會去修改CM server的db配置文件/etc/cloudera-scm-server/db.properties
4、修改CM agent配置
# 修改server_host,跟CM心態檢測,根據自己的主機名來修改
$ sed -i '/server_host=/cserver_host=hadoop-cdhmaster-168-182-161' /etc/cloudera-scm-agent/config.ini
5、啟動CM服務(CM節點)
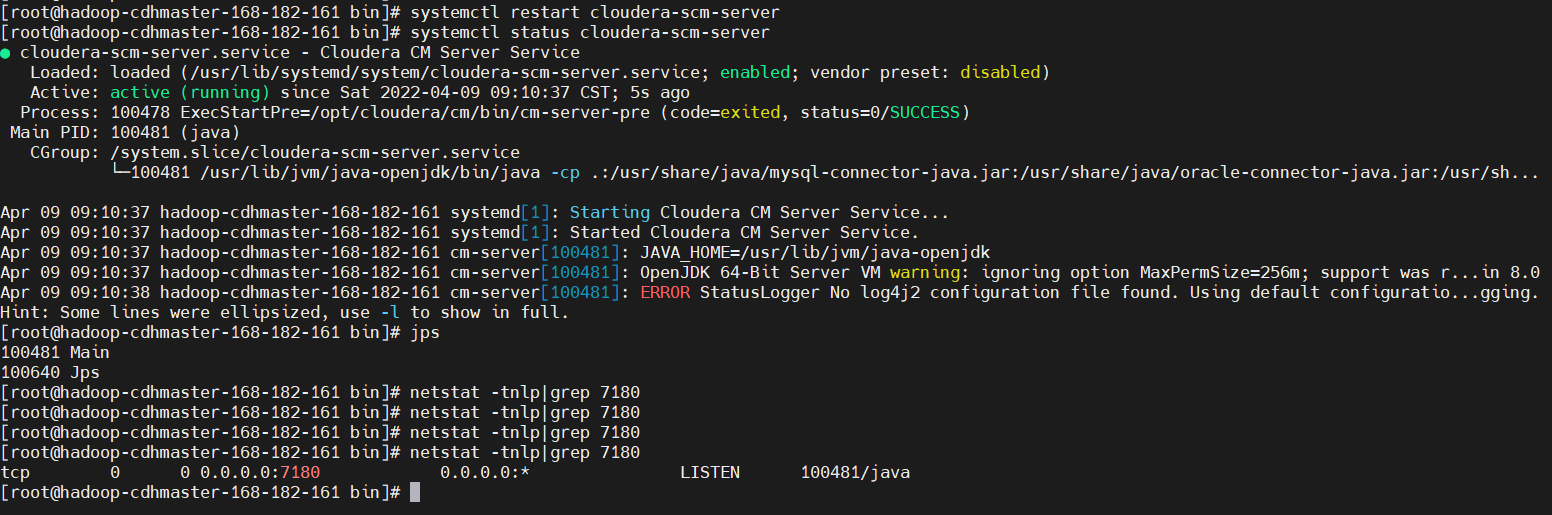
$ systemctl start cloudera-scm-server
$ systemctl status cloudera-scm-server
$ jps
# 會啟動埠7180的服務,服務啟動有點慢,需要等待一段時間
netstat -tnlp|grep 7180
# 日誌目錄:/var/log/cloudera-scm-server/
6、啟動agent(所有節點)
$ systemctl start cloudera-scm-agent
$ systemctl status cloudera-scm-agent
# 日誌目錄:/var/log/cloudera-scm-agent/
4)通過CM web安裝CDH 6.3.2
web UI訪問(賬號/密碼):http://hadoop-cdhmaster-168-182-161:7180/
1、用戶協議
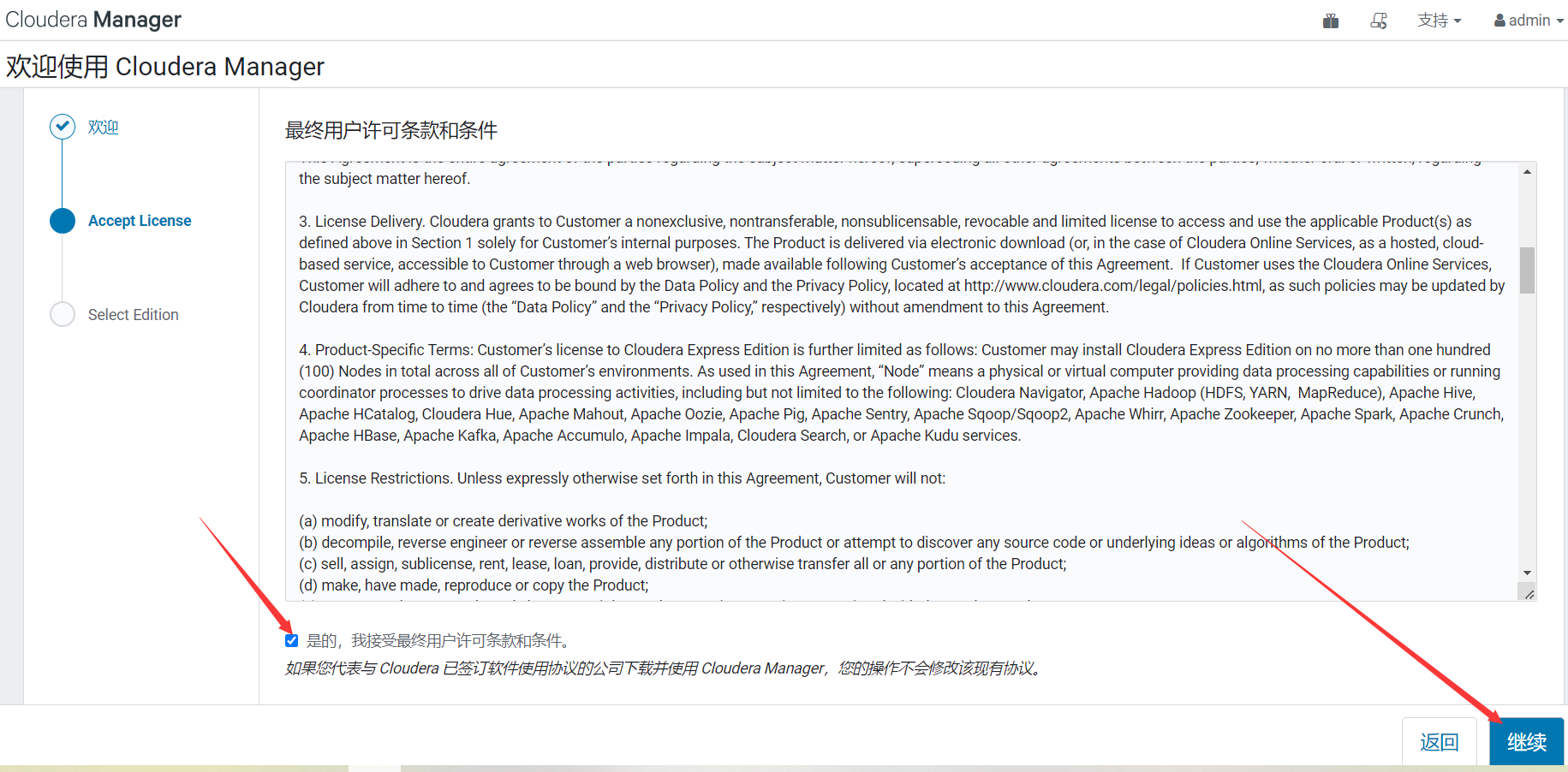
2、版本選擇
因為CDH本身就是商業版,所以需要高級功能還是需要收費的,這裡選擇免費版

下麵這個頁面需要點時間,耐心等待一下
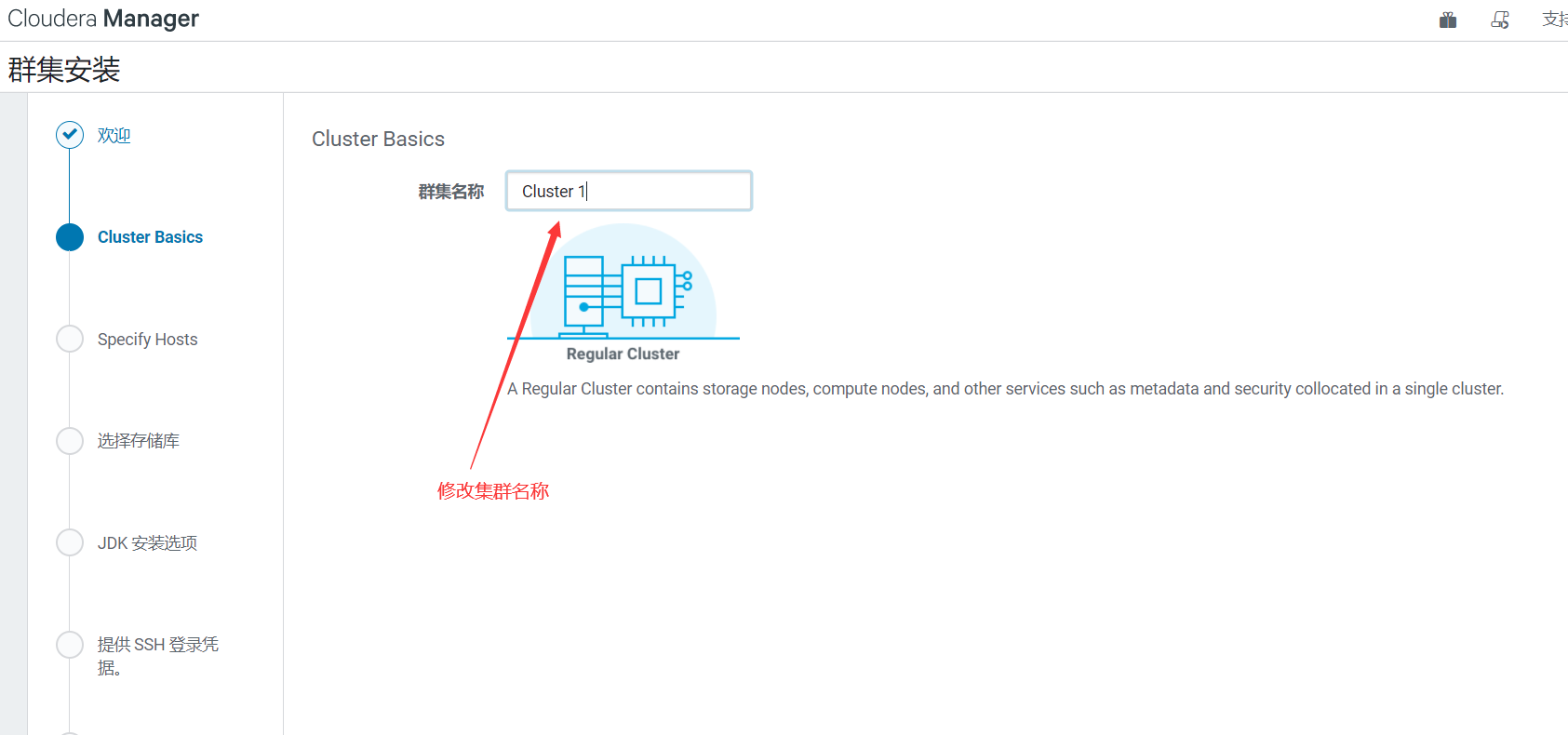
3、修改集群名稱
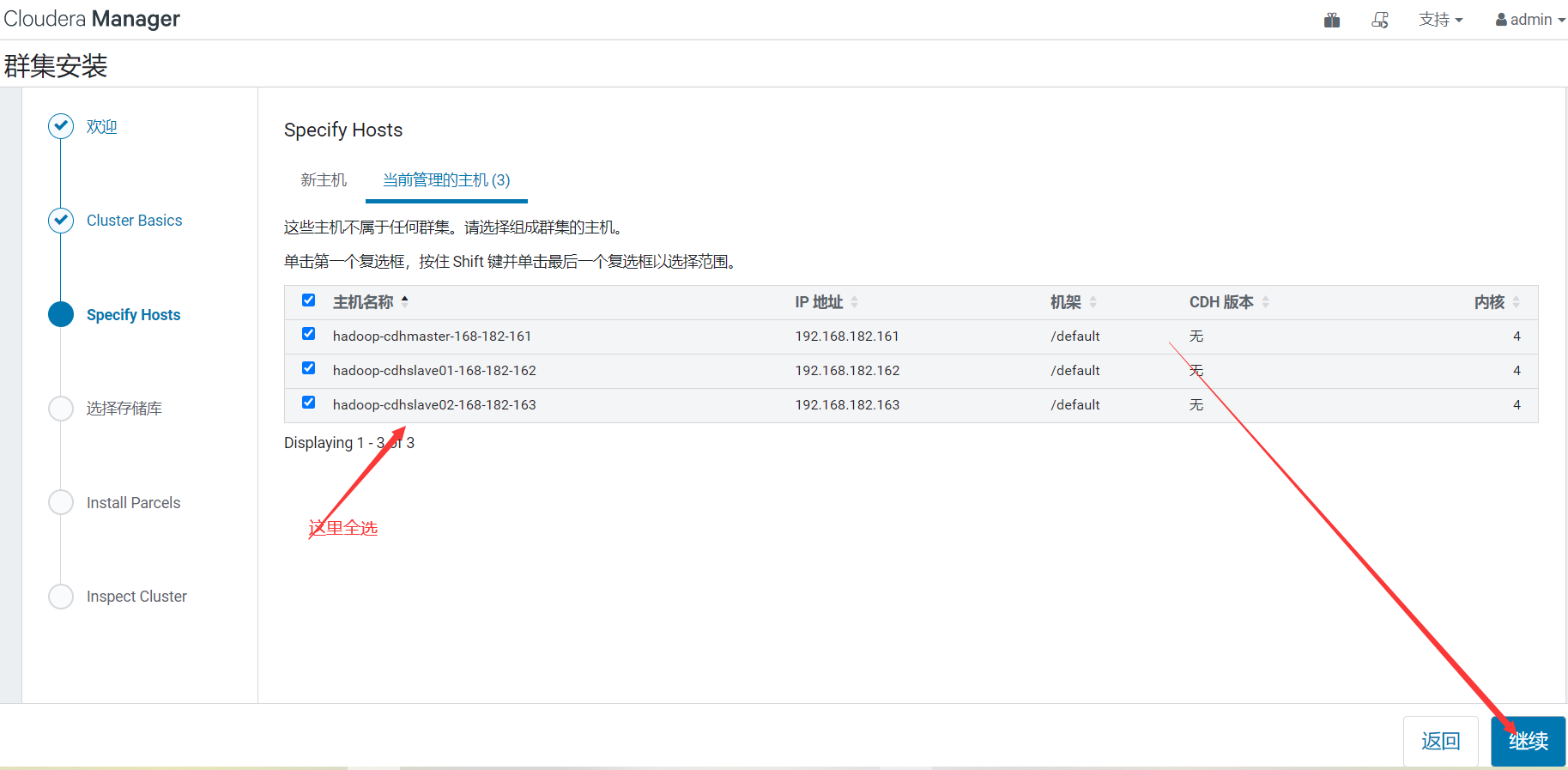
4、選擇集群機器
【溫馨提示】需要安裝CM agent才會顯示,如果看不到,請檢查CM agent服務是否正常。
5、創建本地倉庫目錄和本地安裝目錄
$ cd /opt/server/CDH
$ mkdir cloudera/parcels -p
$ mkdir cloudera/parcel-repo -p
把上面的離線包里的這些文件提前放在/opt/server/CDH/cloudera/parcel-repo目錄下
$ cp /opt/software/CDH/CDH6.3.2/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel* /opt/server/CDH/cloudera/parcel-repo/
$ cp /opt/software/CDH/CDH6.3.2/manifest.json /opt/server/CDH/cloudera/parcel-repo/
$ ll /opt/server/CDH/cloudera/parcel-repo/
# 目錄需要寫入許可權
$ chmod 777 /opt/server/CDH/cloudera/parcel-repo

6、配置本地倉庫和本地安裝目錄
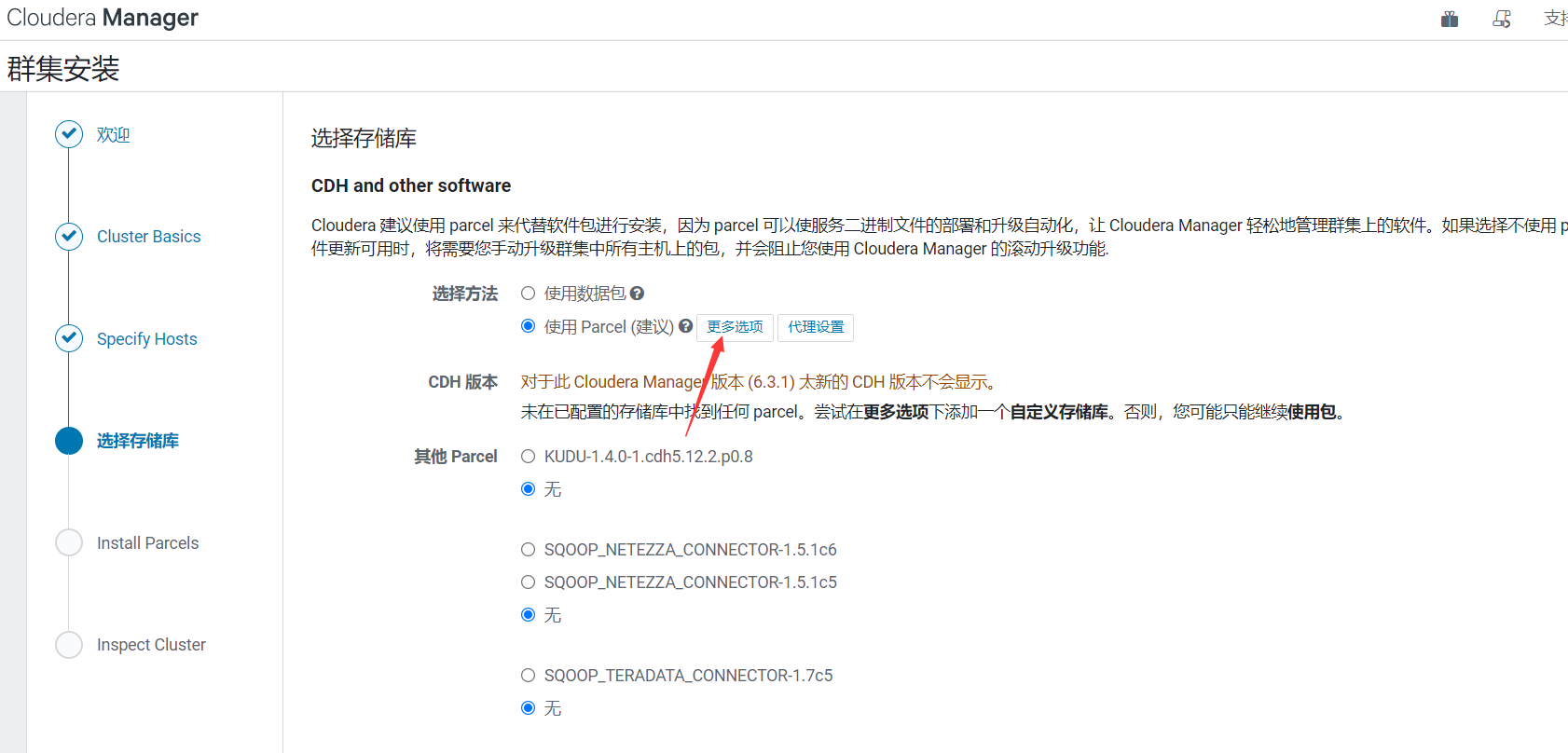

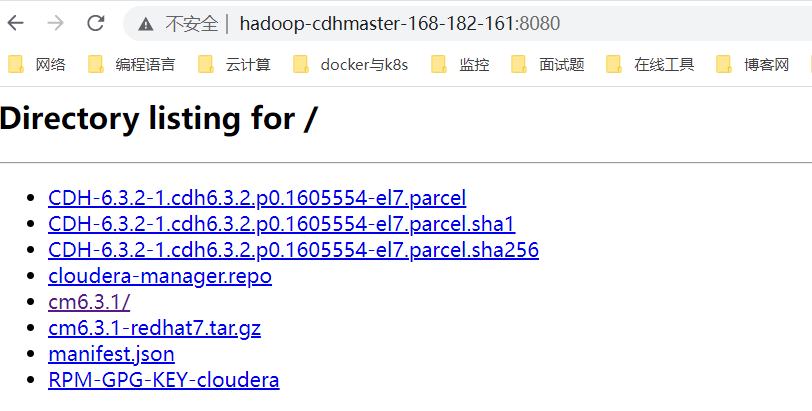
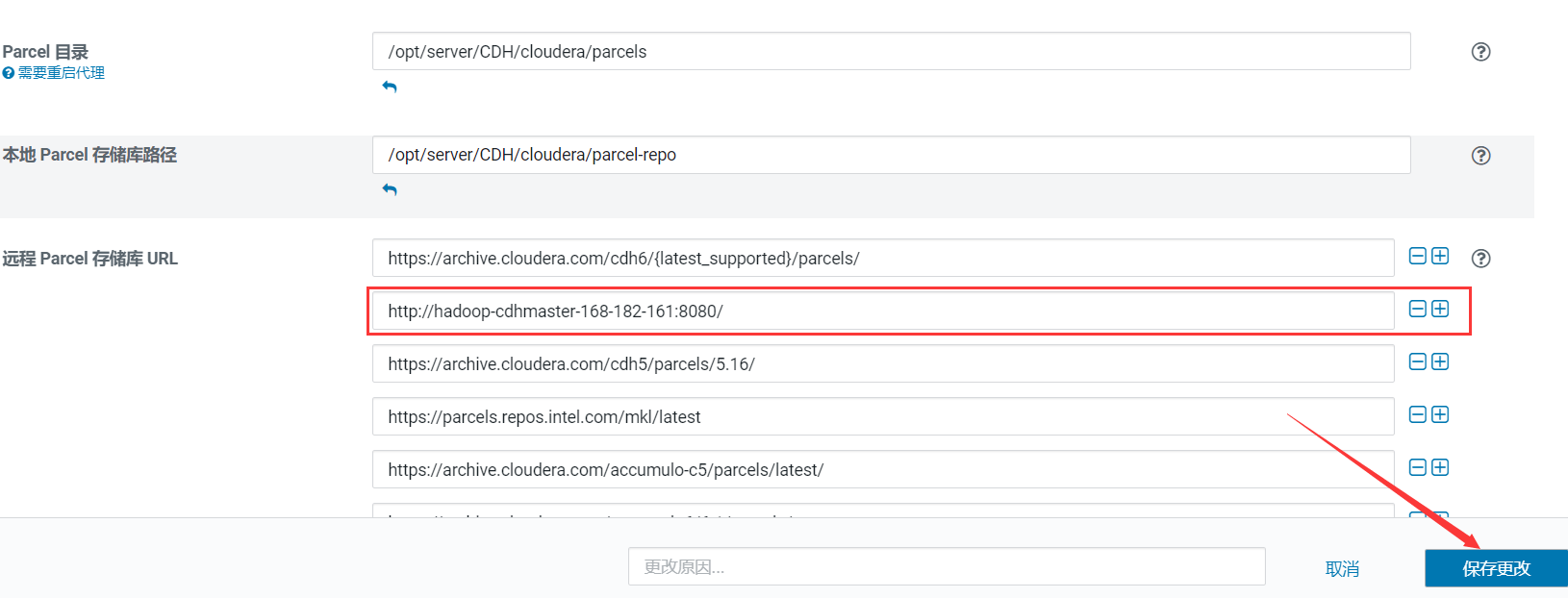
這裡也加一個本地倉庫地址,怎麼啟動本地倉庫服務,上面有講,這裡就不再重覆了。哪個快會自動選擇哪個。也可以不加,看自己選擇
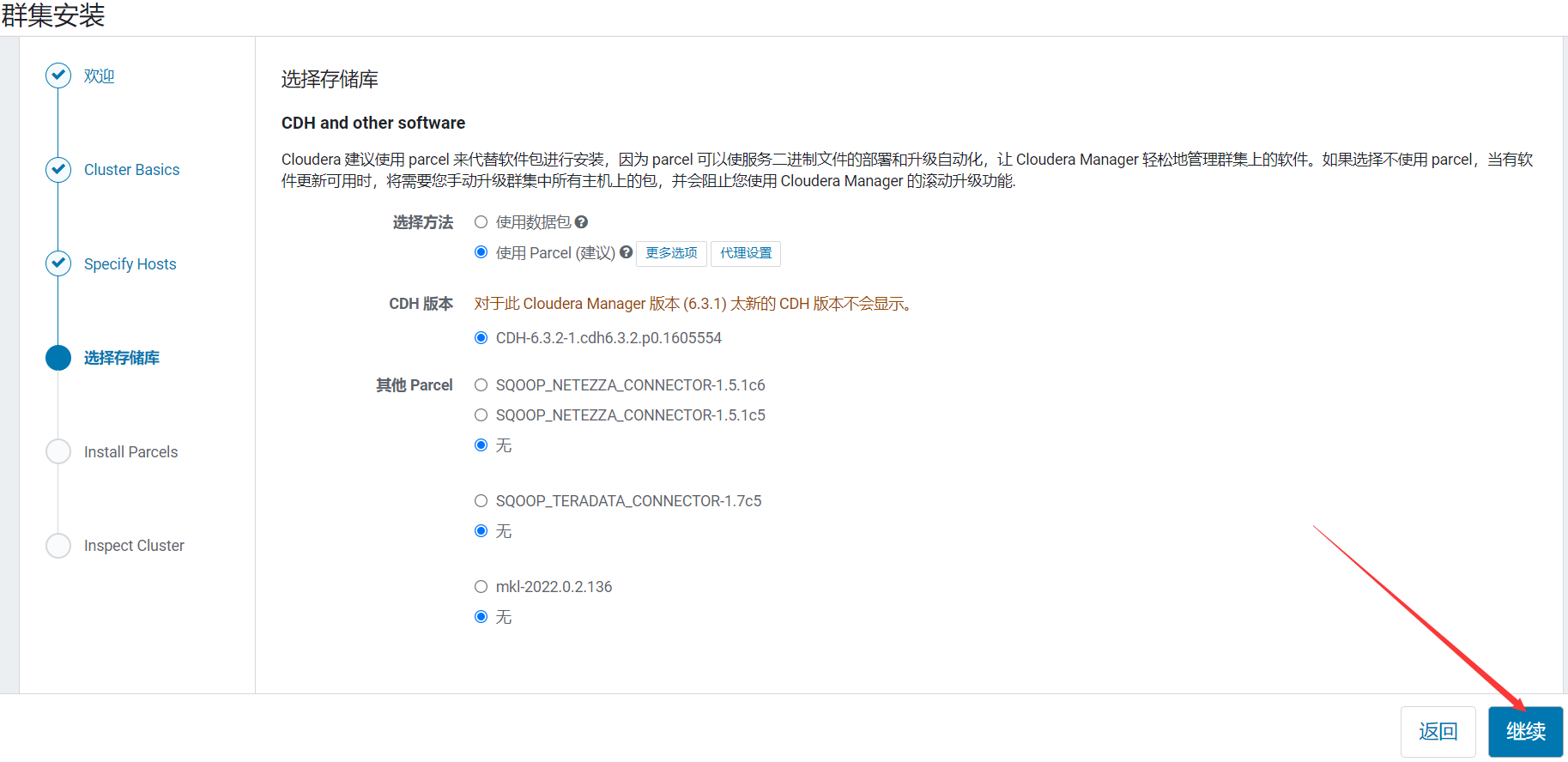
6、自動下載分配解壓激活
這裡需要比較長的時間,請耐心等待,自動完成後會自動跳轉到下一步。
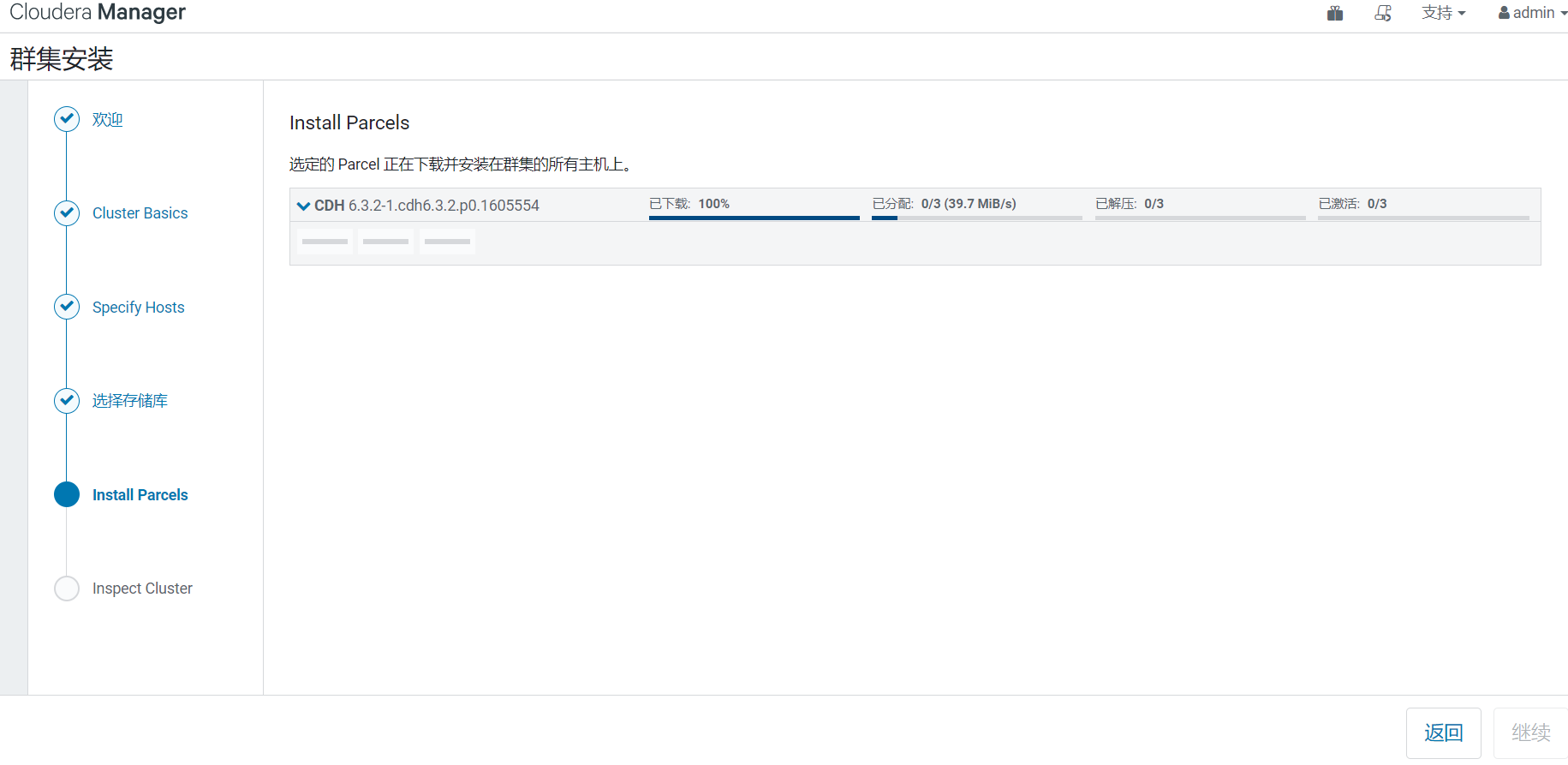
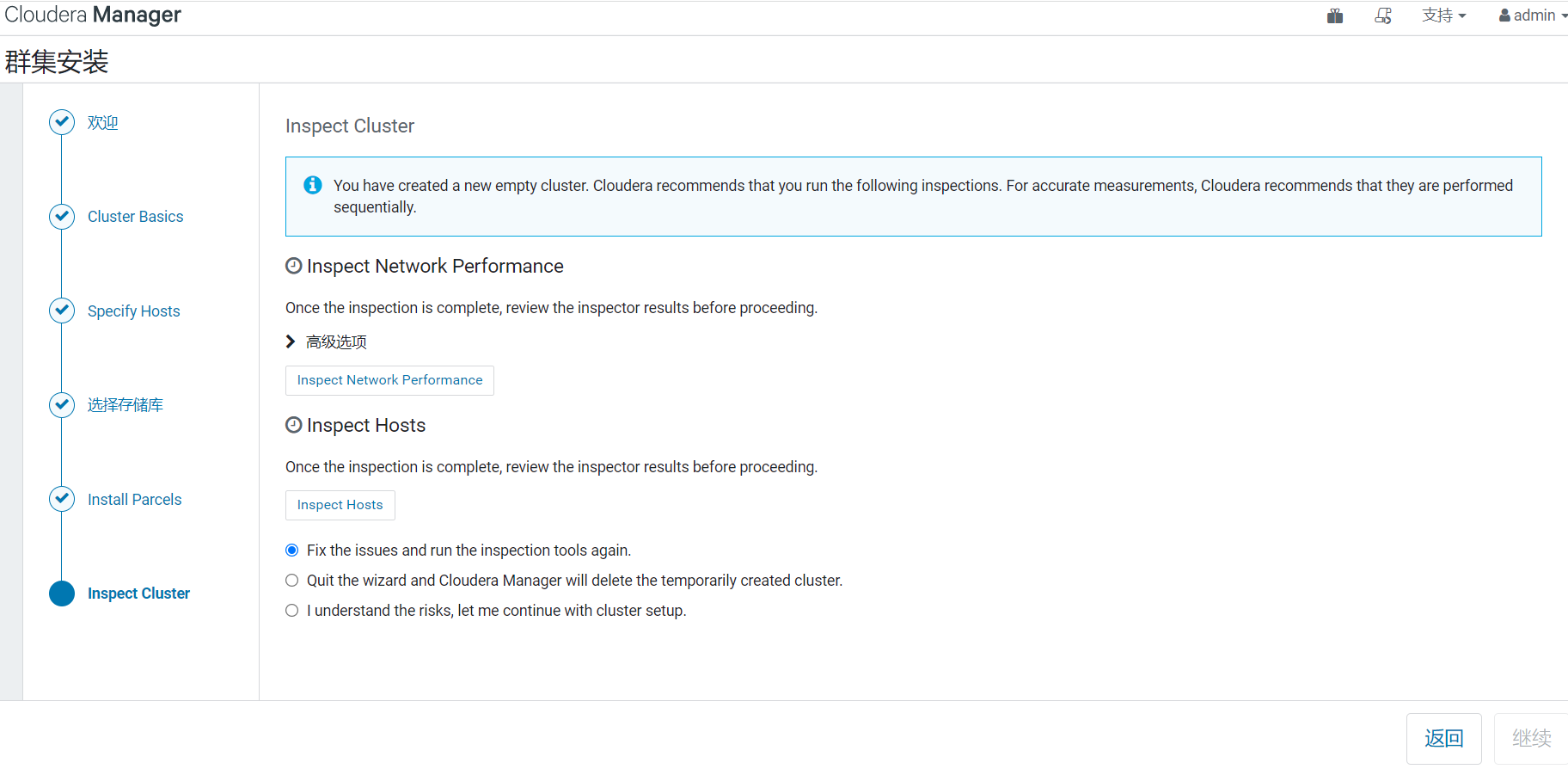
7、檢查
沒問題的話,就直接下一步了。
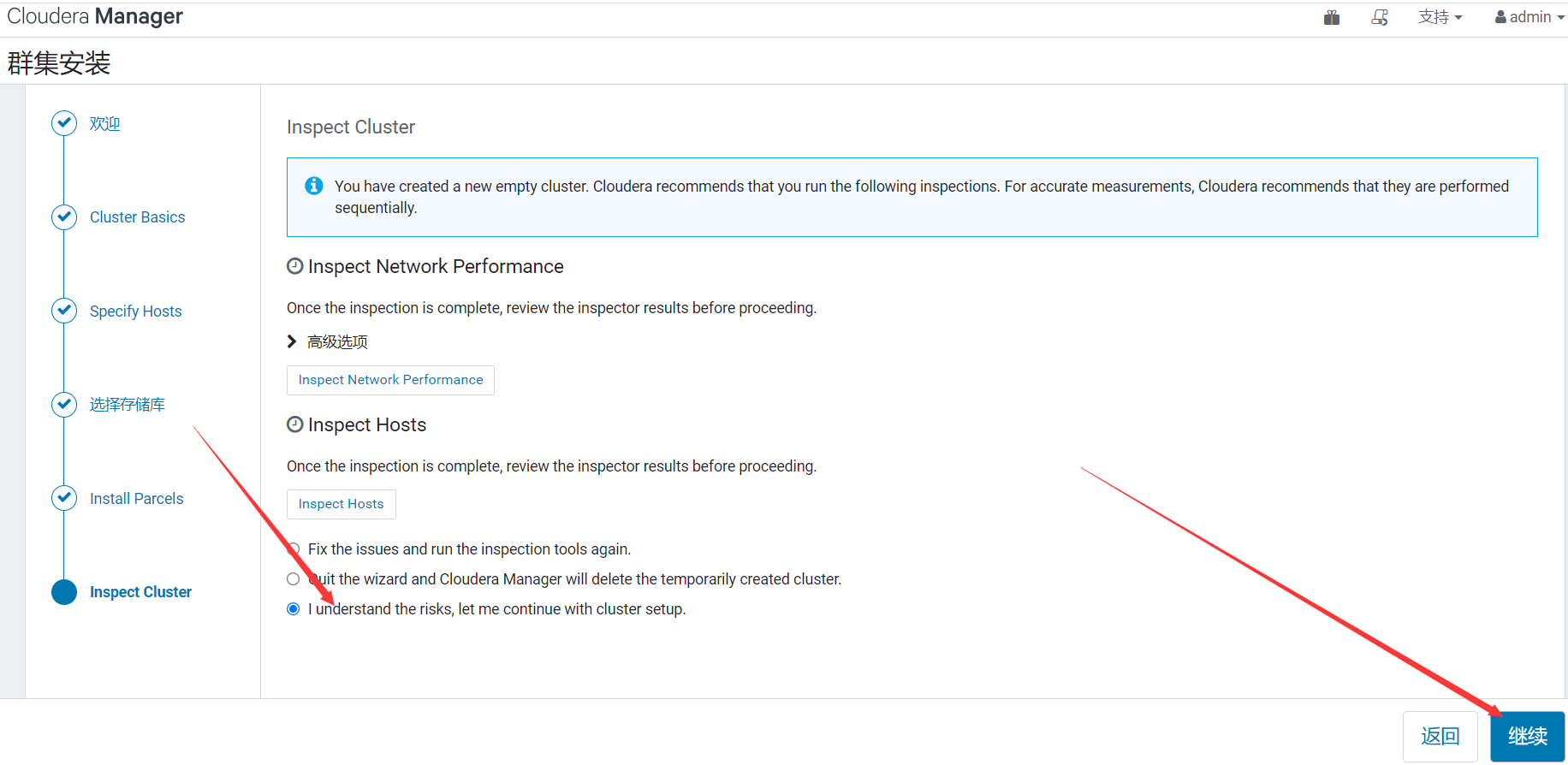
到這裡安裝包已經完成下載、分配、解壓、激活的操作了,接下來才是正真安裝CDH組件相關的服務
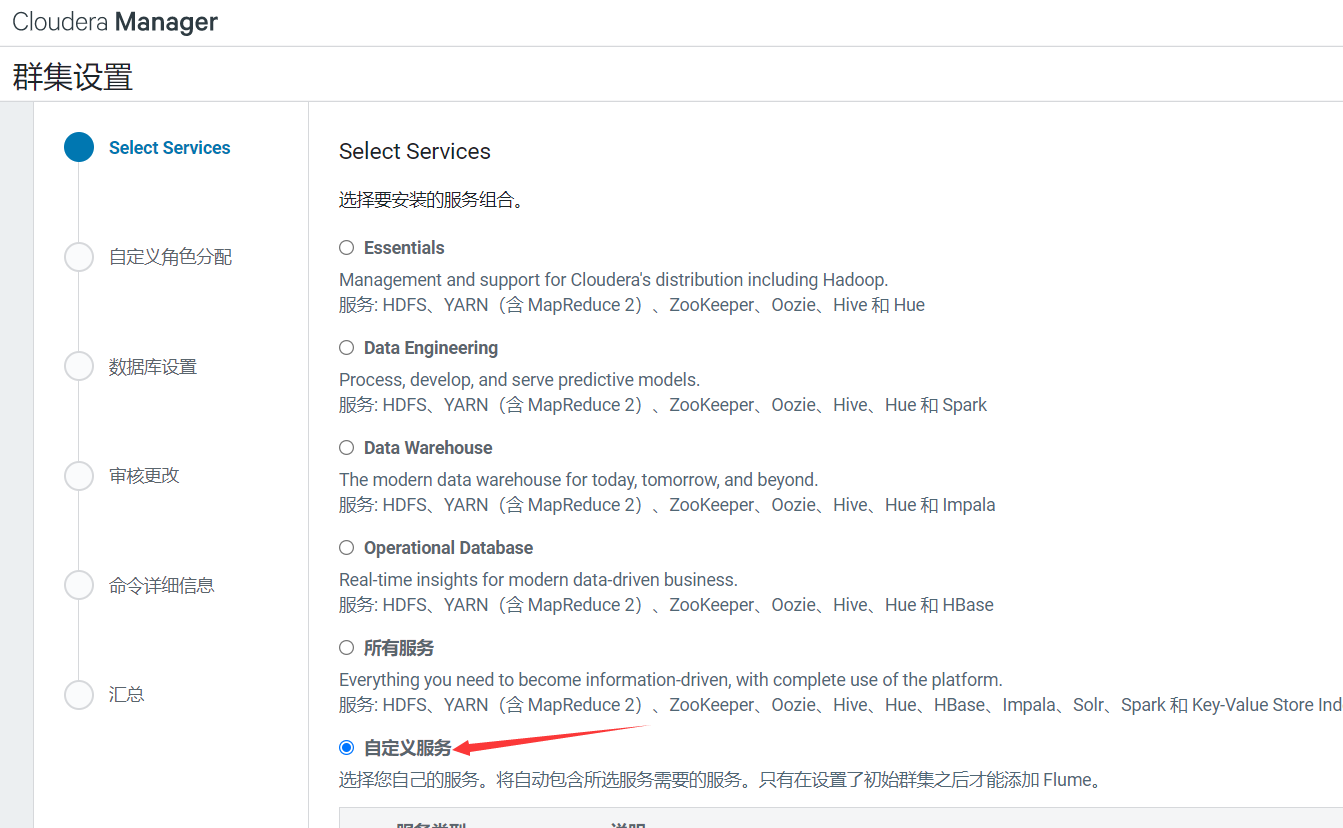
8、安裝CDH組件
選擇組件組合,也可以自定義,這裡我選擇自定義

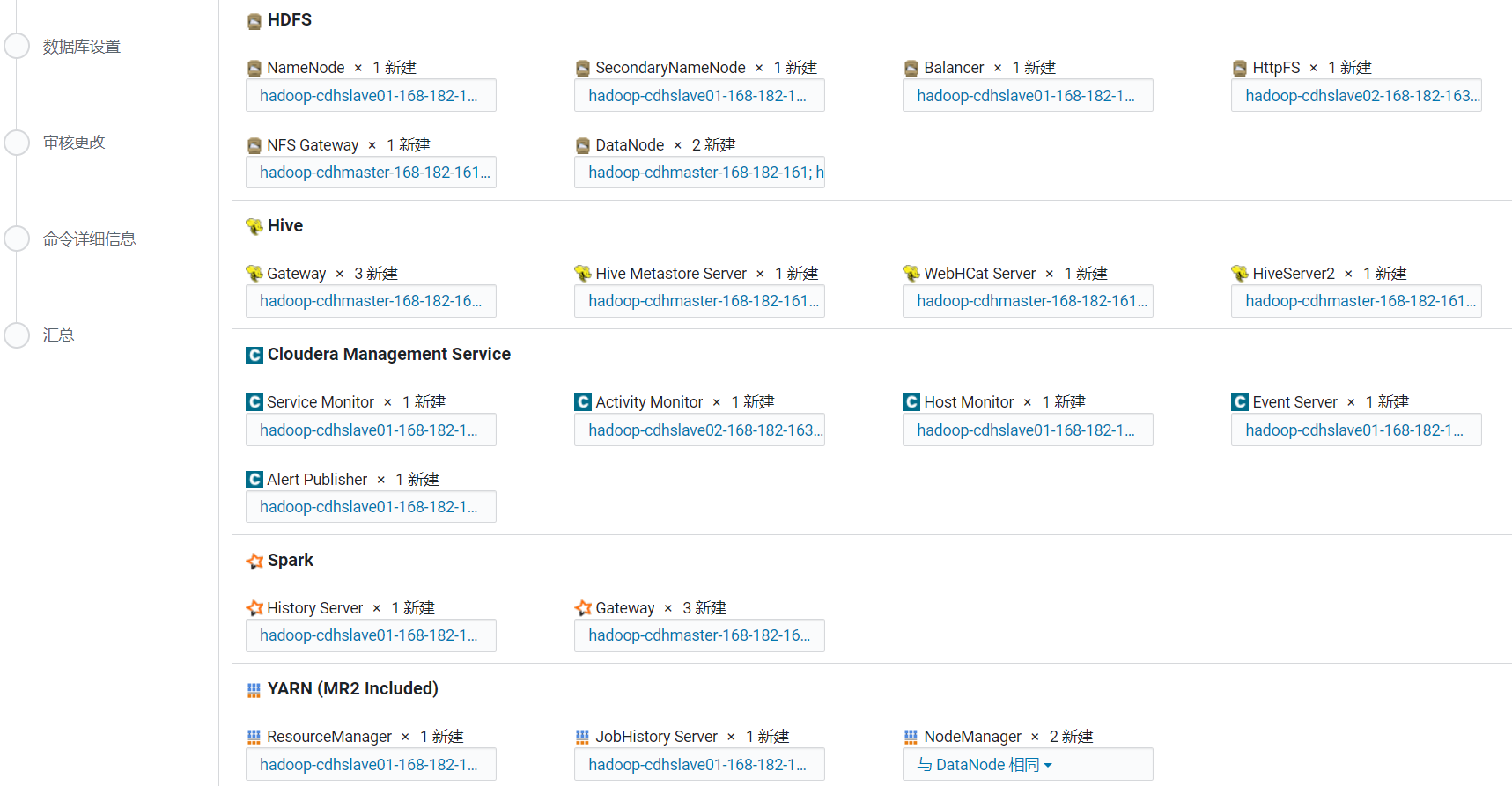
9、自定義角色分配
有些是自動分配的,有些沒分配的就得手動配置機器,hive 選擇的機器需要選擇mysql的機器,要不然檢測到機器上沒有mysql,就會有問題。
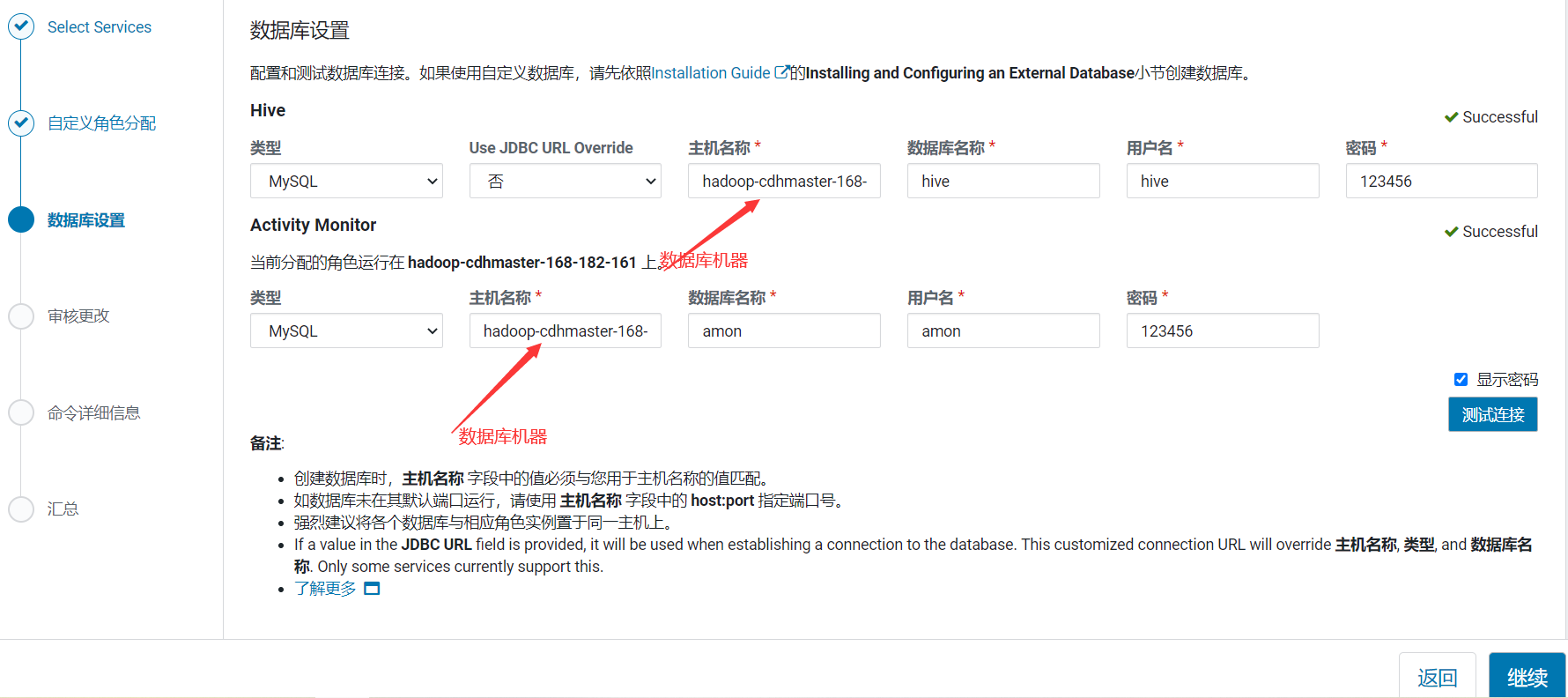
10、資料庫設置
11、審核更改
預設就行,直接下一步
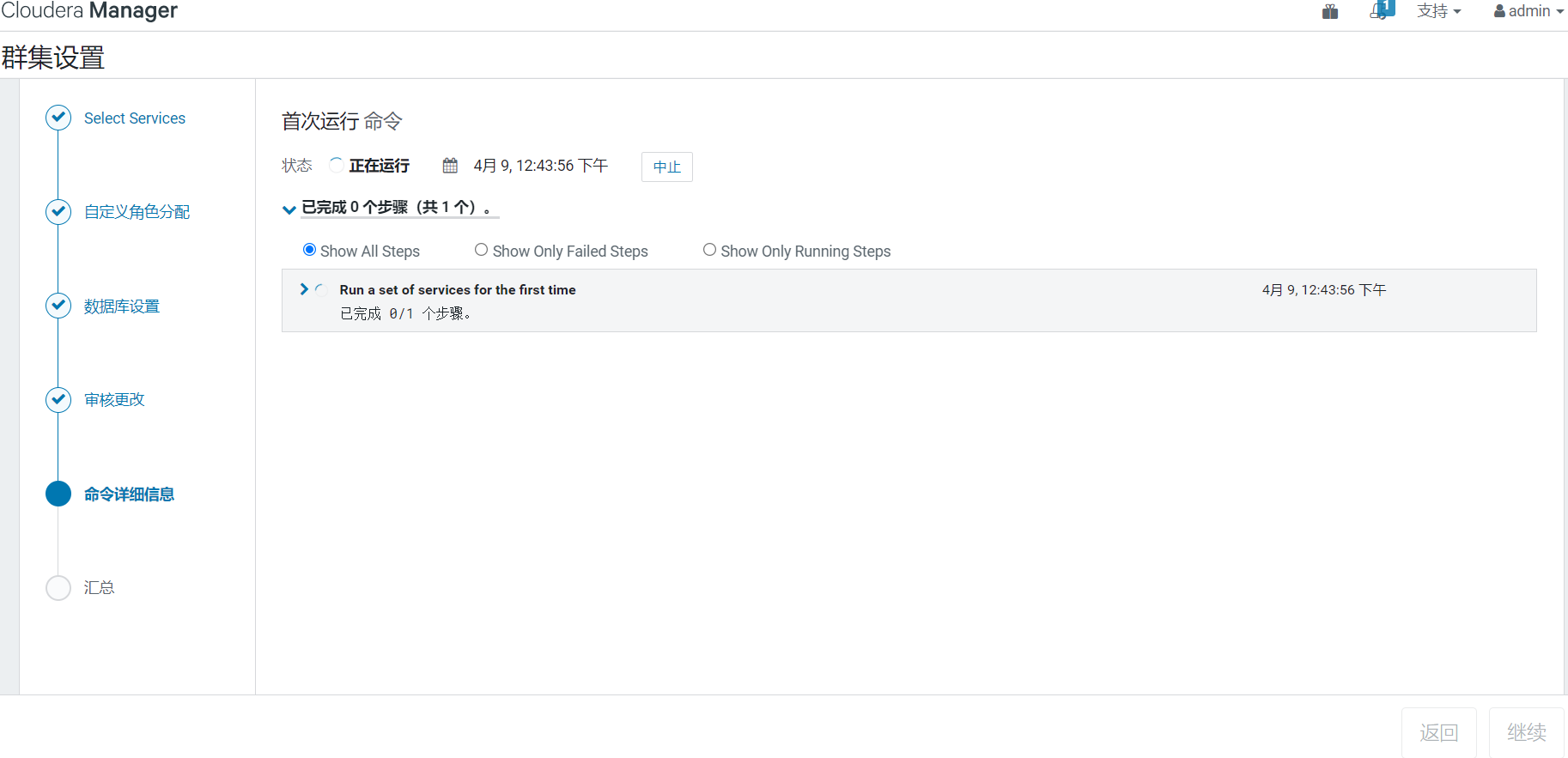
12、開始安裝
組件安裝並自動啟動,時間有點久,等待即可
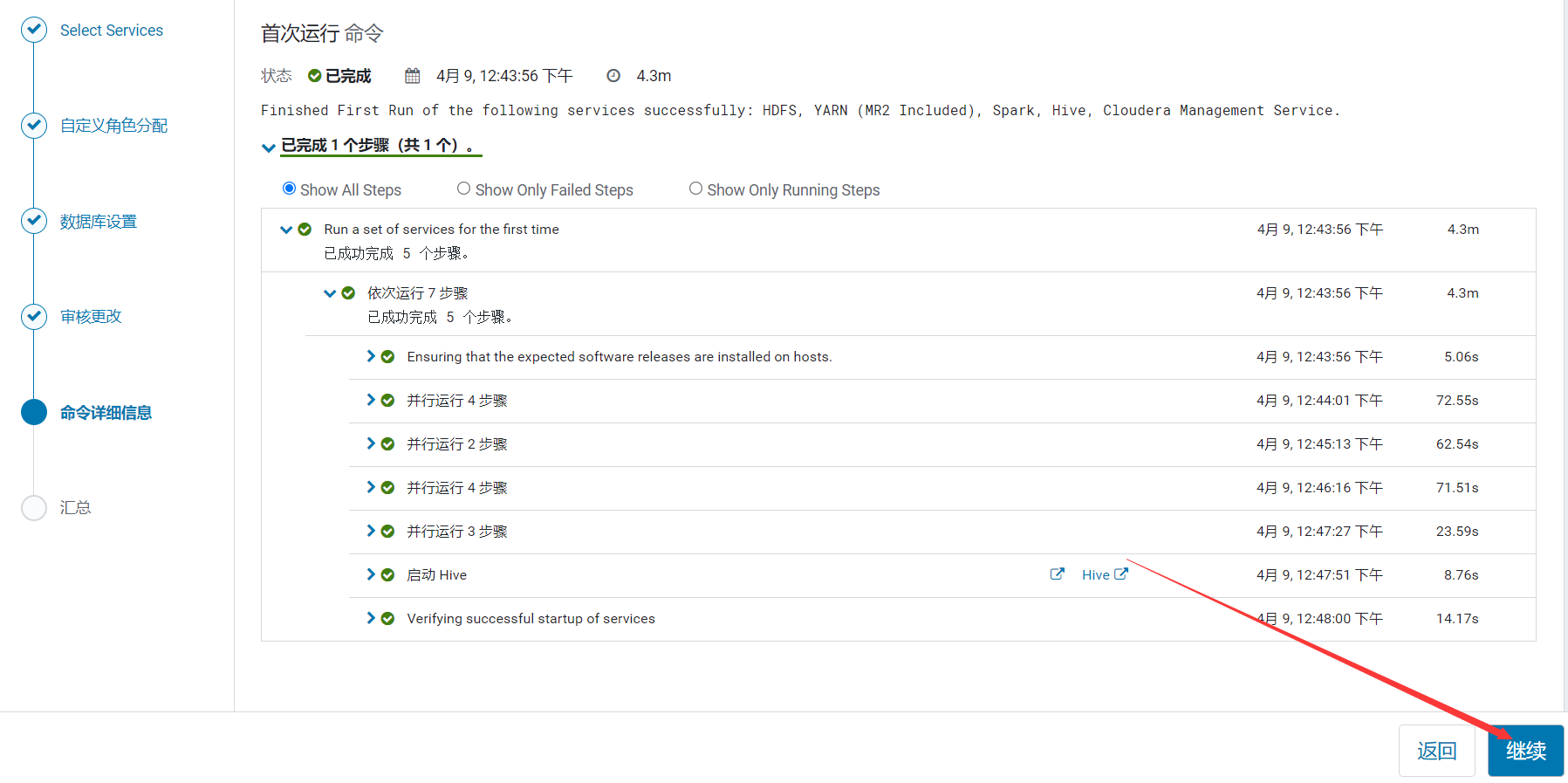
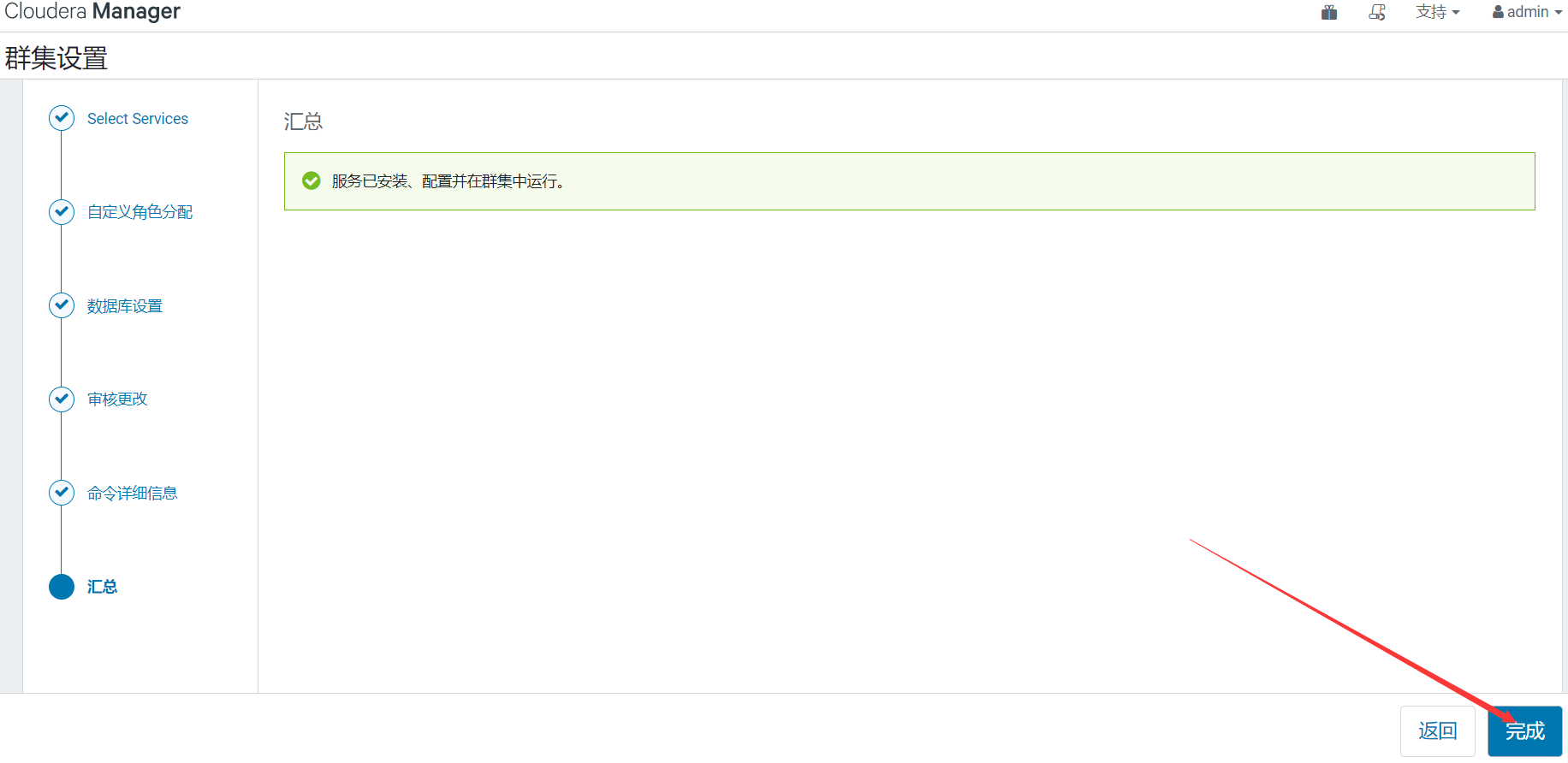
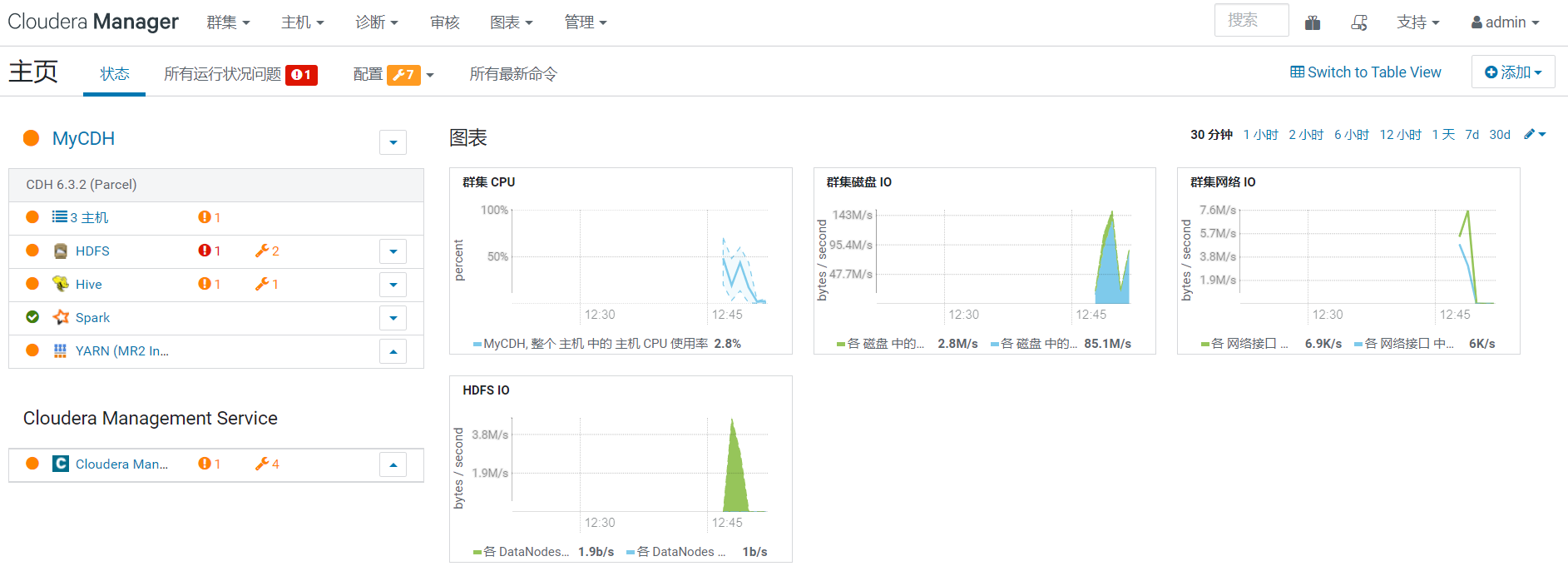
到此CDH 6.3.2環境部署就完成了,後面會有更多關於其它組件集成到CDH的文章,請小伙伴耐心等待,有什麼問題或者意見歡迎給我留言~

