
導讀: 電商場景的搜索排序演算法根據用戶搜索請求,經過召回、粗排、精排、重排與混排等模塊將最終的結果呈現給用戶,演算法的優化目標是提升用戶轉化。傳統的有監督訓練方式,每一步迭代的過程中優化當前排序結果的即時反饋收益。但是,實際上用戶和搜索系統之間不斷交互,用戶狀態也在不斷變化,每一次交互後排序結果和用戶 ...

導讀: 電商場景的搜索排序演算法根據用戶搜索請求,經過召回、粗排、精排、重排與混排等模塊將最終的結果呈現給用戶,演算法的優化目標是提升用戶轉化。傳統的有監督訓練方式,每一步迭代的過程中優化當前排序結果的即時反饋收益。但是,實際上用戶和搜索系統之間不斷交互,用戶狀態也在不斷變化,每一次交互後排序結果和用戶反饋也會對後續排序產生影響。因此,我們通過強化學習來建模用戶和搜索系統之間的交互過程,優化長期累積收益。目前這個工作已經在京東全量上線。
今天的介紹會圍繞下麵五點展開:
- 搜索排序場景及演算法概述
- 強化學習在搜索排序中的建模過程
- 基於RNN用戶狀態轉移建模
- 基於DDPG的長期價值建模
- 規劃與展望
--
01 搜索排序場景及演算法概述
首先和大家分享下搜索排序的典型場景以及常用的演算法。
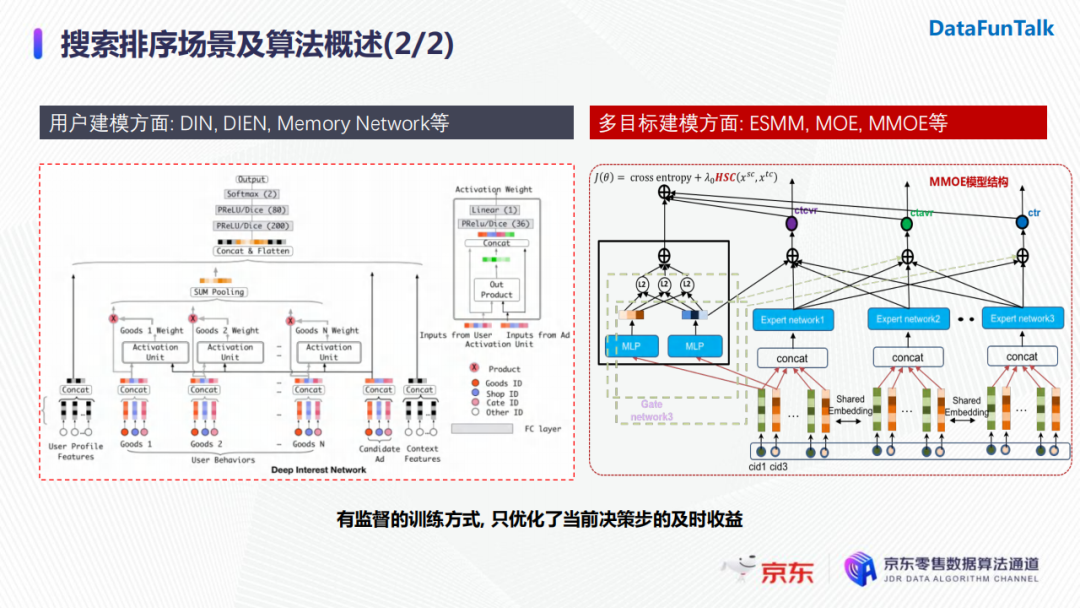
搜索排序場景下的主要優化目標是提升用戶轉化率,常用的演算法分別從用戶建模角度(DIN、DIEN、Memory Network等)和多目標建模角度(ESMM、MOE、MMOE等)進行設計。這些模型都採用了有監督的訓練方式,在每一步迭代的過程中都是優化當前排序結果的即時獎勵。而實際上用戶和搜索系統之間存在交互,用戶狀態是不斷改變的,這也使得每一步排序結果和反饋跟後續排序有相關性。為了提升搜索精排的效率,我們使用強化學習來建模用戶和搜索系統之間的交互過程,並且考慮對後續排序結果影響帶來的長期價值。
--
02 強化學習在搜索排序中的建模過程

我們的工作經過整理後發表在2021CIKM上,接下來介紹的演算法也主要與這篇論文相關。
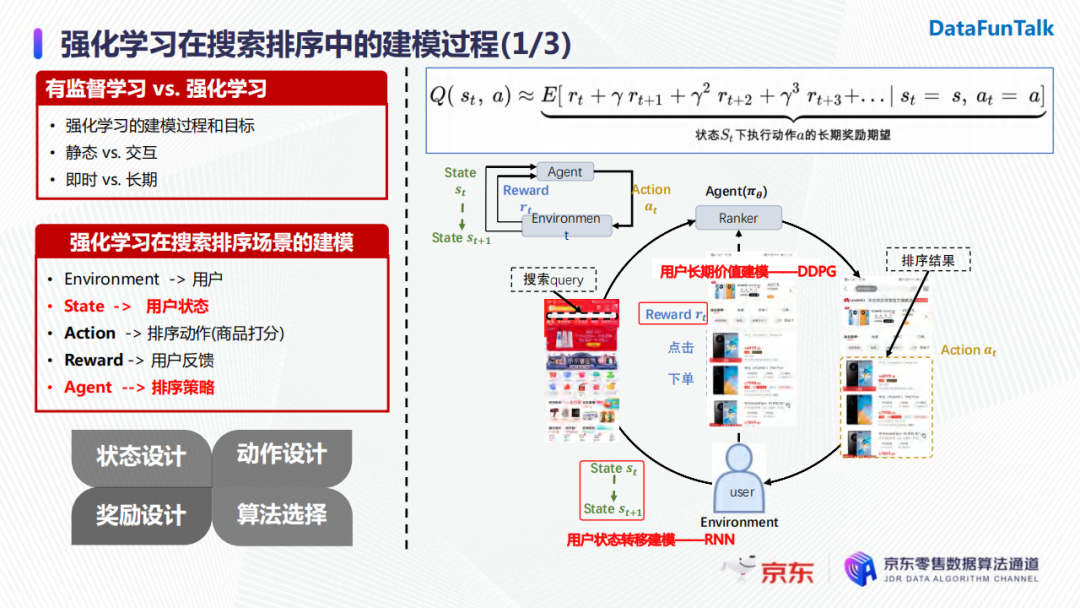
首先介紹強化學習在搜索排序中的建模。強化學習的優化目標是長期價值的期望最大化。如上圖公式中所示,長期價值期望Q是在一個狀態下,執行一個動作後,當前時刻的即時獎勵和後續時刻帶來的累積折損獎勵之和。它和有監督學習的最主要區別在於後者通常優化當前決策帶來的即時收益,而強化學習是去優化決策的長期價值。
在搜索場景下強化學習的建模過程如上圖所示,當用戶(即強化學習中的environment)發起一次搜索請求時,我們的排序引擎會基於當前用戶的狀態,選取一個排序動作(排序動作即為對候選商品進行打分)並將排序結果呈現給用戶。用戶在看到排序結果後會做出一系列反饋,如下單或者點擊。此時,用戶的狀態會發生變化,排序模塊會收到用戶的反饋(即獎勵)。排序模塊收到獎勵之後會對策略進行迭代優化,進而在收到下一次用戶請求時會基於新的用戶狀態和排序策略進行下一步動作的執行。
基於上述完整演算法流程,我們需要對用戶狀態進行建模,並且對排序策略建模優化長期價值。強化學習的建模思路主要依照其四要素:狀態、動作、獎勵的設計以及演算法的選擇。在業界對於強化學習在搜索排序的應用也有一些研究,我們主要參考了阿裡巴巴的一篇論文以及2019年YouTube強化學習在推薦中的應用的論文。但是,經過一些實驗後,我們最終的方案和業界還是存在比較大的差異。

首先,阿裡的那篇文章是建模用戶在單次搜索中多次翻頁情況下的序列決策過程,即當用戶在一次請求後,模型會考慮當前頁的及時反饋以及後續翻頁後反饋帶來的影響,對應的優化目標是用戶單次搜索多次翻頁的場景價值。而我們的方案進一步考慮了用戶多次搜索的決策過程,因為用戶在發生購買行為前會經過一系列搜索決策。具體地,我們會考慮用戶在本次搜索結果的即時獎勵以及對後續搜索結果影響的長期價值,對應的優化目標是用戶在整個搜索決策過程中的長期價值。結合具體的建模過程以及工業界落地的時候針對時效性的考慮,我們的技術路線主要包括兩個方面:
- 對狀態的建模,使用RNN來表徵用戶的狀態以及用戶狀態的轉移;
- 對用戶長期價值,使用DDPG進行建模。這一步需要以RNN狀態轉移建模作為基礎,結合動作設計、獎勵設計以及演算法的選擇來完成。
--
03 基於RNN的用戶狀態轉移建模
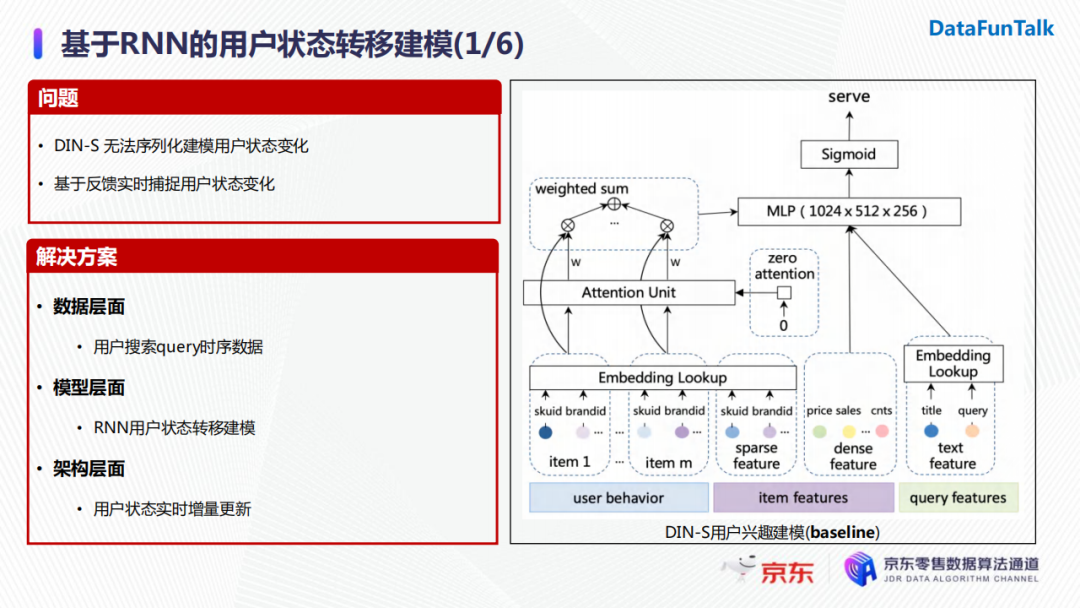
我們線上的baseline是一個基於DIN的模型, 建模目標商品與用戶歷史行為序列中商品的關係,從而對用戶的狀態進行表徵。但是我們還希望序列化建模用戶的狀態變化,這是DIN無法實現的。與此同時,線上的用戶狀態也在實時不斷地變化更新,所以我們需要通過一種方式實時捕捉線上的反饋,並對用戶狀態的變化做一個表徵。具體解決方案分為三個方面:
數據層面:用戶搜索query的時序數據;
模型層面:選擇RNN來建模用戶的狀態轉移;
架構層面:因為涉及到用戶線上的狀態更新,所以會有加入用戶狀態實時增量更新的一個通路。
1. 數據層面
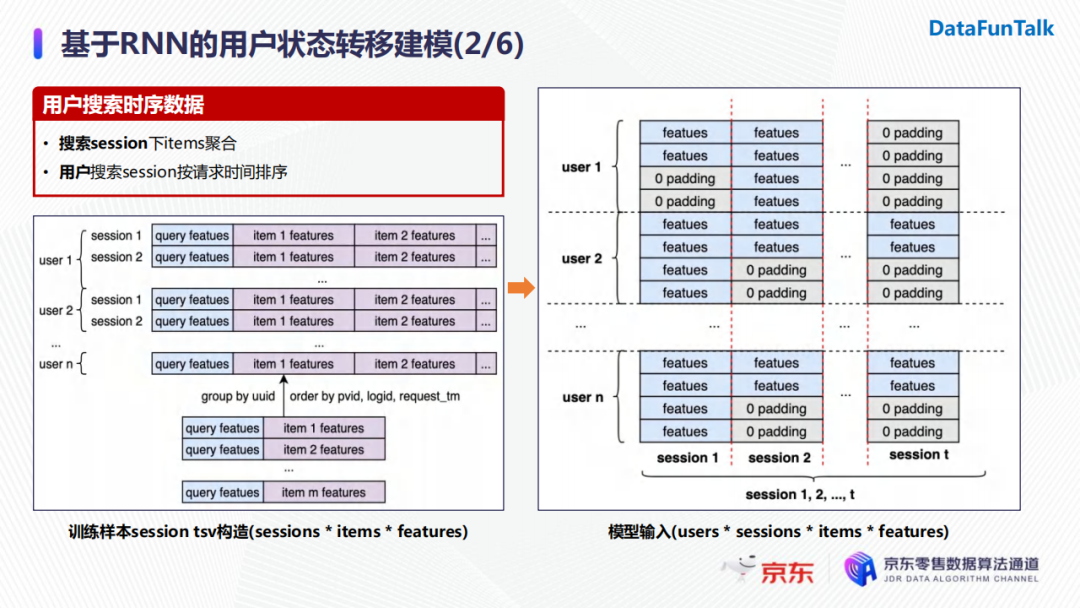
在數據層面,通常來說,訓練樣本的構造方式是用戶在某次搜索下的所有商品,併進行展開,如上圖左下所示,這些樣本就成為傳統有監督學習的訓練數據。為了把用戶的搜索數據進行時序展開,我們進行了兩步操作:
首先,我們會把用戶在一個搜索session下所有的曝光商品結合在一起(無序的);然後,用戶的搜索session會按照時間進行排序,並將其放入用戶索引下。
在樣本輸入模型之前我們需要對其進行轉化。比如在訓練RNN模型時,輸入的batch size即為用戶數量,在RNN每一個time step輸入用戶的一個session(即用戶的一次請求),其中包含請求中所有商品的特征。
2. 模型層面
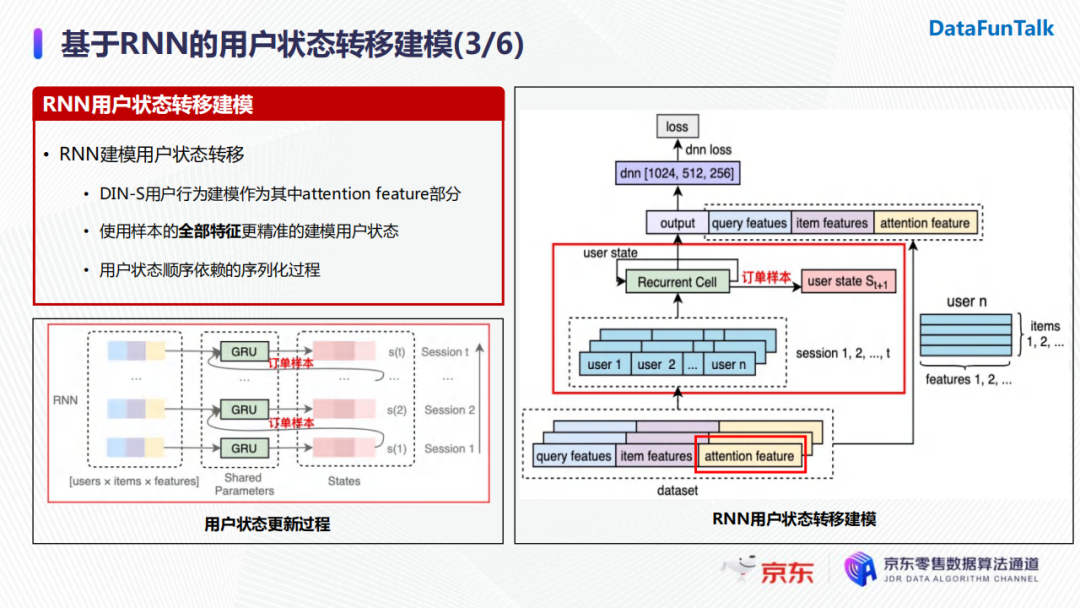
為了相容baseline的DIN模型,我們將DIN生成的特征作為attention feature加入模型。在每一個timestep,用戶對應session下的所有商品特征會經過一個GRU,得到每個商品的輸出向量以及隱狀態向量,而隱狀態向量會與下一個timestep的session特征一起作為新的輸入傳遞進GRU,並對GRU進行狀態更新。在這個過程中,用戶當前時刻的狀態依賴於上一時刻的狀態以及當前時刻的輸入,因此它是一個序列化建模的過程。
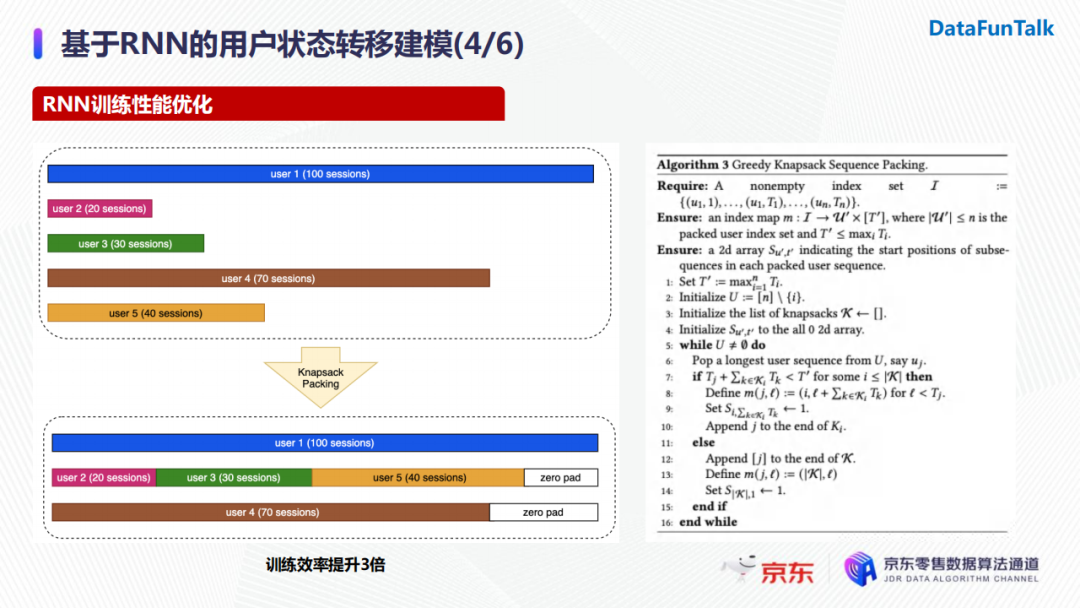
但是,實際在模型訓練時,我們需要考慮到用戶搜索數量的差異。具體地,某個用戶可能有上百次搜索請求,而其他用戶只有幾十個甚至幾個請求。訓練RNN時為了保證輸入長度的一致我們會加入padding,搜索請求數量的巨大差異導致不必要的開銷,對RNN的性能產生影響。基於這一問題,我們會將搜索長度較短的用戶進行篩選併進行拼接,進而減少不必要的padding。經過實驗,優化後的RNN訓練效率提升了約三倍。
3. 架構層面
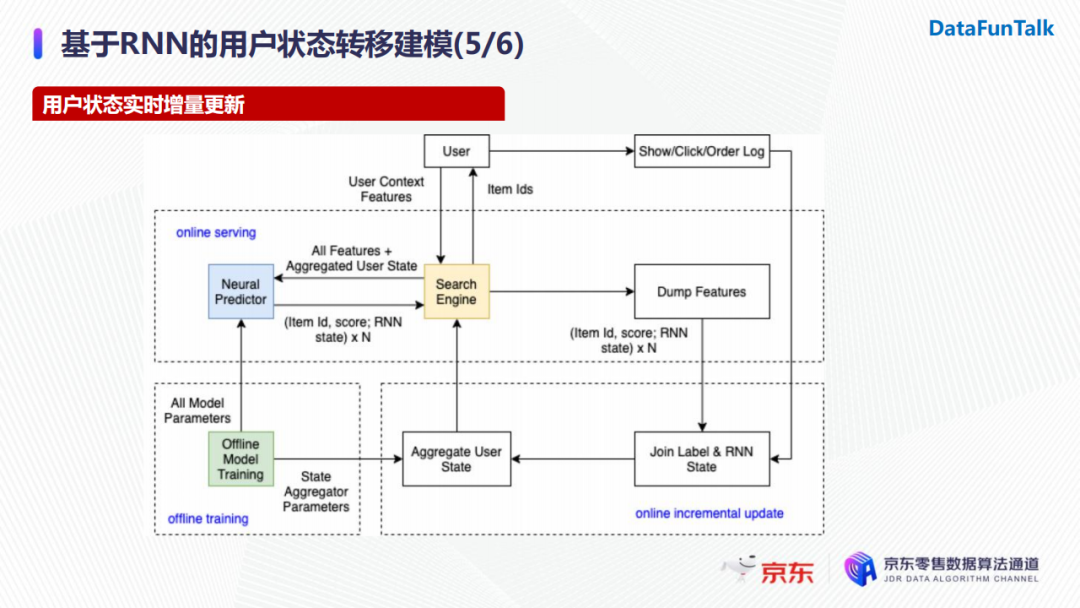
針對用戶狀態的實時增量更新,我們使用的架構可以分為三個模塊,並針對目標進行對應的優化。
- 離線訓練:我們會把訓練好的模型導出成兩個部分,一部分是用戶歷史狀態的表示,它可以作為特征提供至線上進行使用;另一部分是模型所有參數,它用於線上模型的打分。
- 線上服務:當用戶發起一次搜索請求時,系統會拿到當前待排序的所有商品以及用戶的embedding表示。我們將這兩部分輸入傳遞給模型,得到模型對候選商品的打分以及RNN的狀態向量。隨後我們會將返回的feature以及商品的打分做持久化存儲。
- 線上增量更新:增量更新時會將用戶的實時反饋(點擊或者下單行為)與持久化的樣本特征進行join,之後使用ID作為索引更新當前用戶的狀態,最終同步至特征伺服器上。在用戶embedding同步完畢後,下一次用戶請求時就已經可以使用新的用戶狀態,這樣就完成了用戶狀態的線上增量更新,避免了線上使用用戶歷史行為序列重覆計算用戶狀態。
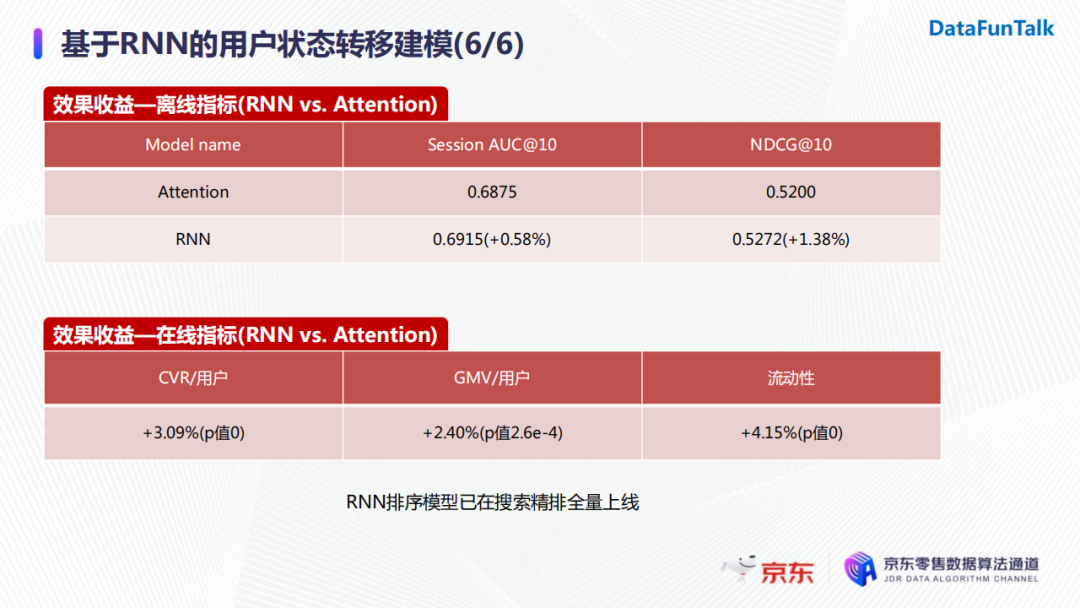
我們使用RNN用戶狀態轉移建模對精排進行了全量更新。離線情況下session的AUC@10相較於基於Attention機制的baseline模型提升了0.58%。線上AB實驗後,在用戶的轉化率以及每個用戶帶來的GMV上也分別有顯著的提升。
--
04 基於DDPG的長期價值建模
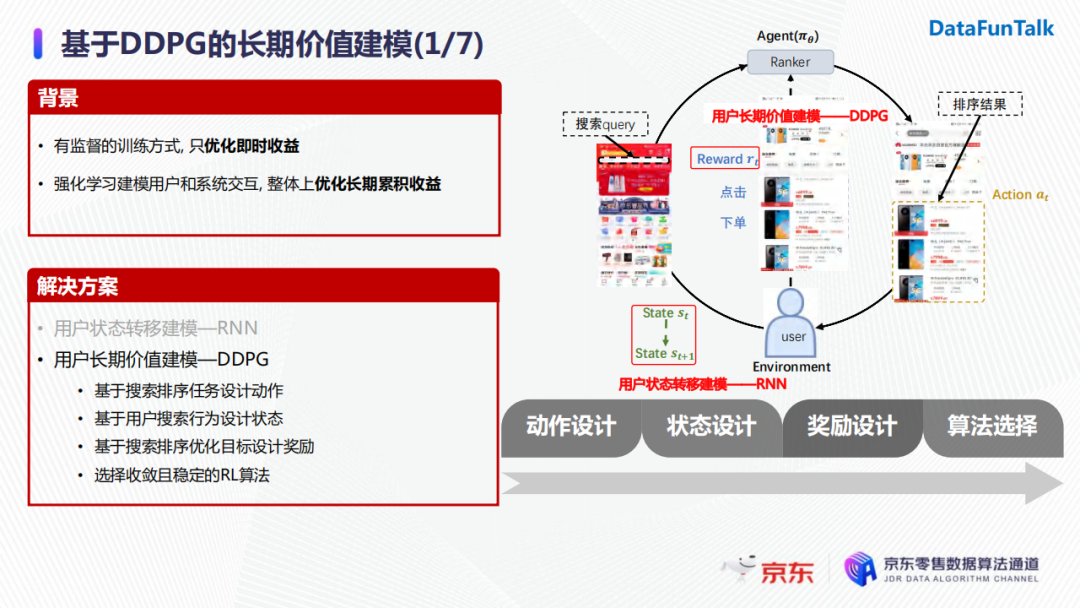
我們想通過強化學習來建模用戶和搜索系統之間的交互,在整體上優化長期累積收益。在具體落地時,演算法需要根據動作設計、狀態設計、獎勵設計、演算法選擇來分為多個階段:
首先我們基於搜索任務設計動作空間,然後基於用戶的搜索行為使用前述的RNN模型進行狀態建模,接著我們會基於搜索排序的優化目標設計獎勵,最後基於整個策略迭代的收斂性和穩定性選擇相應的學習演算法。
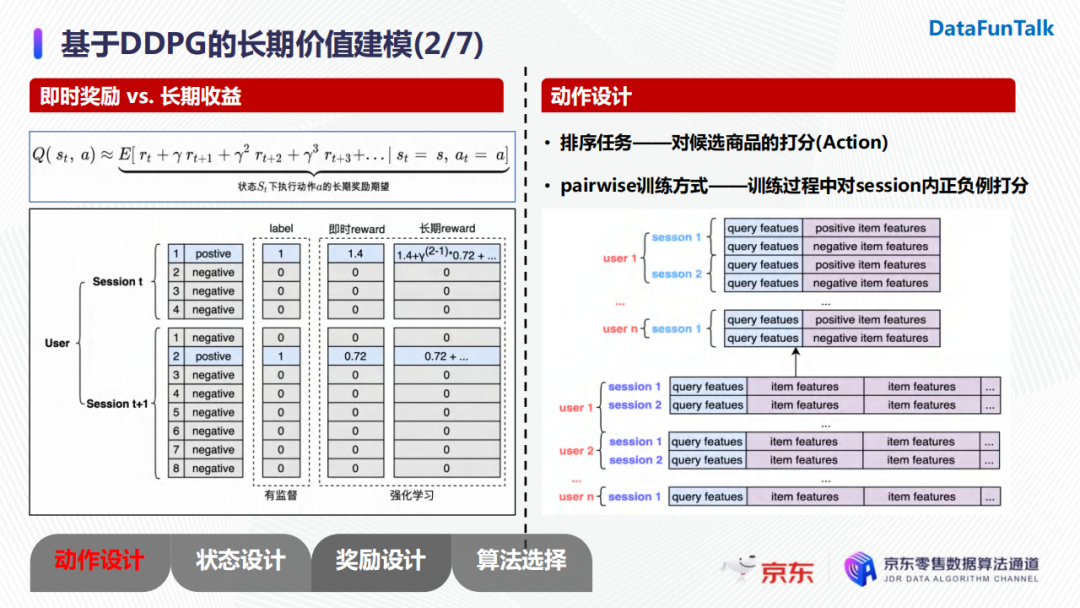
首先,考慮長期收益的優勢在於它納入了後續篩選帶來的累積收益,而有監督學習的每一步都是在優化特征與轉化label之間的直接關係。對於動作設計,由於我們面對的是一個排序任務,所以動作即為對候選商品的打分。我們在模型訓練階段選擇了pairwise的訓練方式,所以我們需要對輸入樣本的形式進行一些改動。具體地,我們會從用戶的每個session中把每一個正樣本保留下來,並對應地隨機採樣一個負樣本,從而形成一個樣本對。對應地,在訓練過程中動作便轉化為對構造的正負樣本對進行打分。

由於我們採用pairwise的訓練方式,我們採用的獎勵函數是根據正負樣本的分差進行構建的。我們的優化目標是用戶轉化率,所以我們希望在模型對正負樣本對進行打分時,不僅排序可以正確,而且正樣本與負樣本的分差儘可能大。所以,獎勵函數設計時,如果正樣本和負樣本排序正確時,分差越大獎勵越大;反之,我們希望分差越大乘法也越大。上圖中我們給出了三種獎勵函數的設計:常數reward、交叉熵reward以及sigmoidreward。
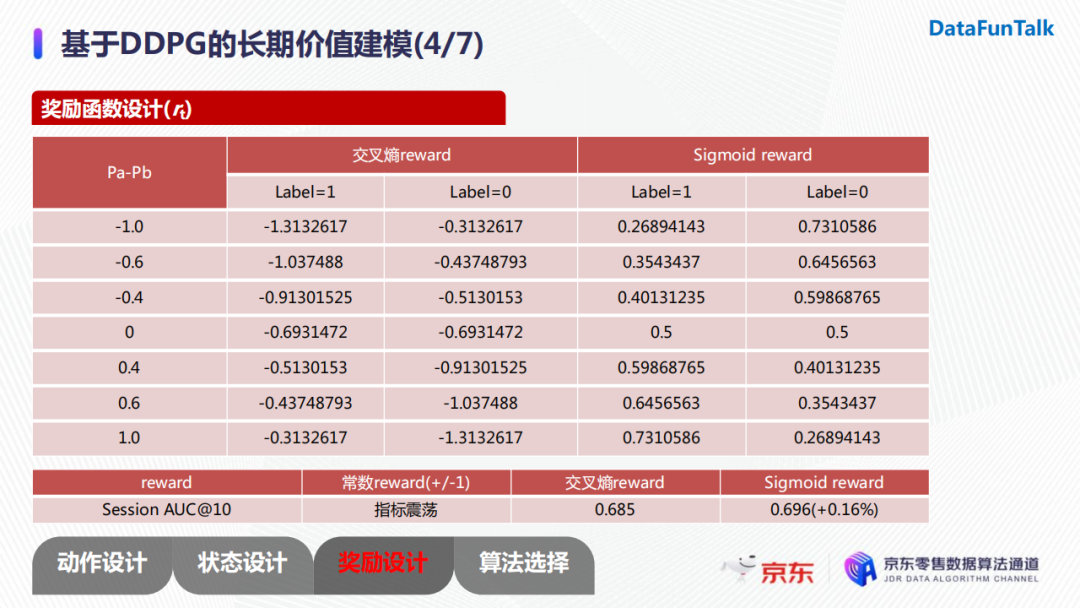
我們對這些reward做了一些實驗。常數reward在我們的場景下指標一直是振蕩的,收斂性比較差,主要原因是只要模型打分順序正確,它給予的都是固定的獎勵,這就導致了若兩個商品打分分別為0.51與0.49,雖然它們的區分度不高,但是獎勵與其他樣本對是一致的。
此外,在比較交叉熵reward以及sigmoid reward時,我們發現交叉熵reward一直是一個負值,而具有正值收益的sigmoid reward相較於前者有了0.16%的指標提升。
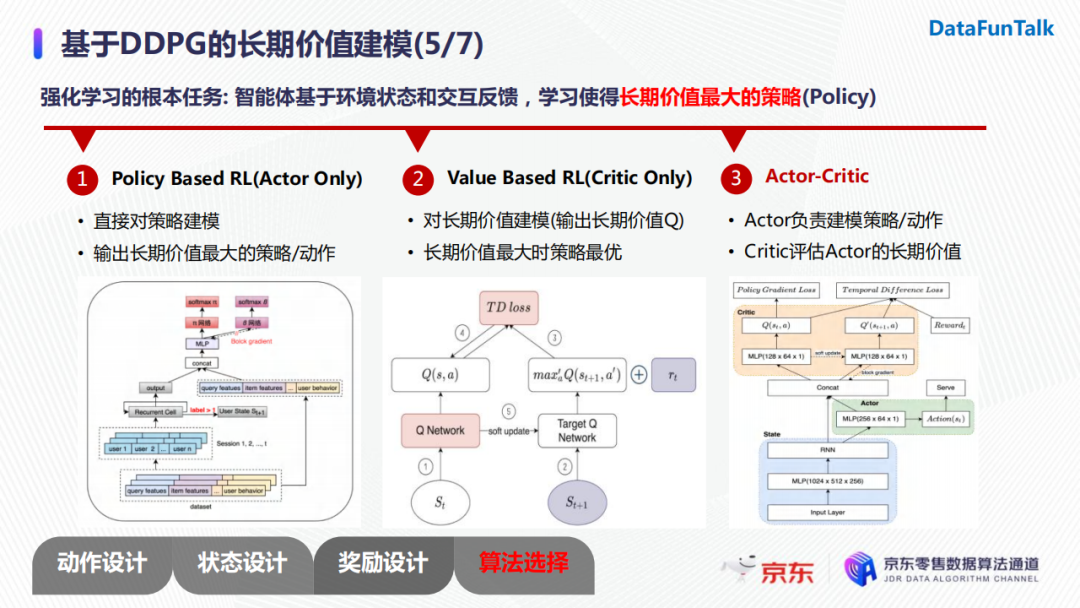
強化學習的根本任務是智能體基於環境狀態和交互反饋,學習能讓長期價值最大化的策略。一般地,有三種方法進行建模:
- 基於策略:直接對策略進行建模,讓策略不斷地朝著長期價值最大的方向進行迭代,最終輸出長期價值最大的策略/動作。策略可以理解為使基於輸入用戶狀態,對候選的商品進行直接打分;
- 基於長期價值:典型的模型是DQN。當長期價值最大的時候,其對應的策略也是最優的。但是DQN無法解決連續的動作空間,只能建模離散的動作空間;
- Actor-critic:Actor負責對策略或者動作進行建模,Critic負責評價Actor生成的策略或者動作的長期價值。
我們線上上分別對這第一、第三種方式進行過實驗,最後發現Actor-critic的建模方法效果較好,於是選擇使用這種框架進行演算法迭代。
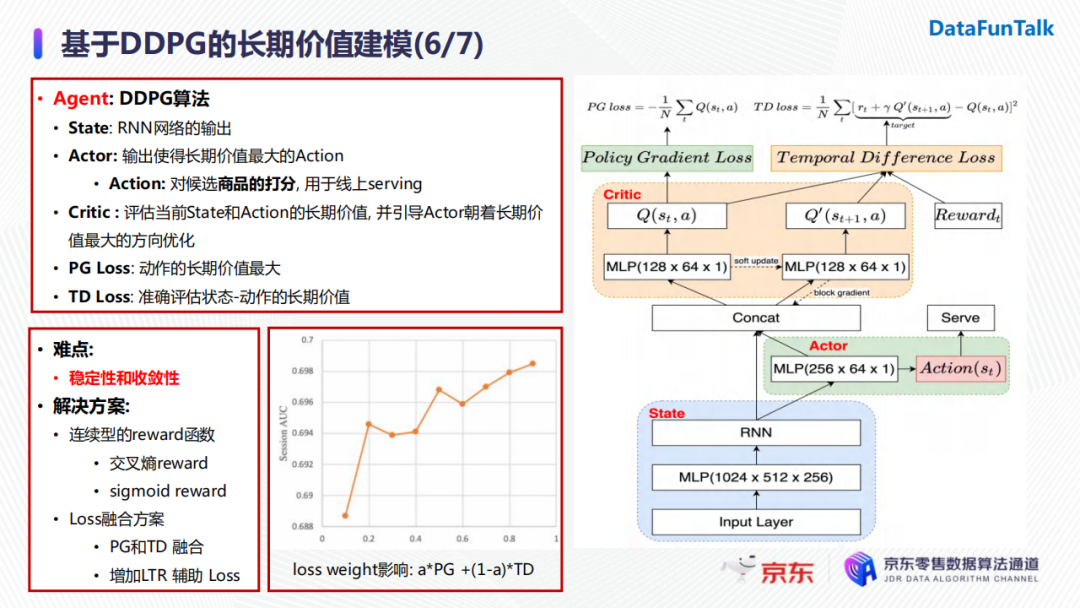
現在就來具體介紹一下DDPG的網路結構。整個網路包含三個模塊:
- ** State網路**:使用RNN進行用戶狀態轉移建模;
- Actor網路: 使用State網路生成的狀態向量作為輸入,輸出對候選商品的打分(即action);
- Critic網路:使用State網路生成的狀態向量以及Actor網路生成的action作為輸入,輸出對應的長期價值,並引導Actor朝著長期價值最大的方向進行優化。
整個網路設計了兩種損失函數。第一個為PolicyGradient的損失函數,它的作用是優化Actor網路的參數,使得其輸出的action的長期價值最大;另一個為時間差分的損失函數,作用是優化Critic網路,使得其可以對Actor輸出的動作給出的長期價值的評估越來越準。
在網路訓練過程中我們也遇到了很多難點,其中最重要也是最常見的問題便是穩定性和收斂性問題。我們最終給出的具體解決方案是使用連續型的reward函數以及採用損失函數融合的方法。Loss的融合最直接的方式是將Policy Gradient的loss和時間差分loss進行加權求和。我們通過實驗發現隨著loss weight的增加,我們的指標也有上升的趨勢。值得註意的是,當權重等於0或1時,模型都是不收斂的,這也證明瞭單獨使用Policy Gradient損失或者時間差分損失進行模型優化是無法滿足模型的穩定性與收斂性的。
另外,我們也嘗試增加了一些有監督的輔助損失函數,其也會對指標帶來一定的提升。
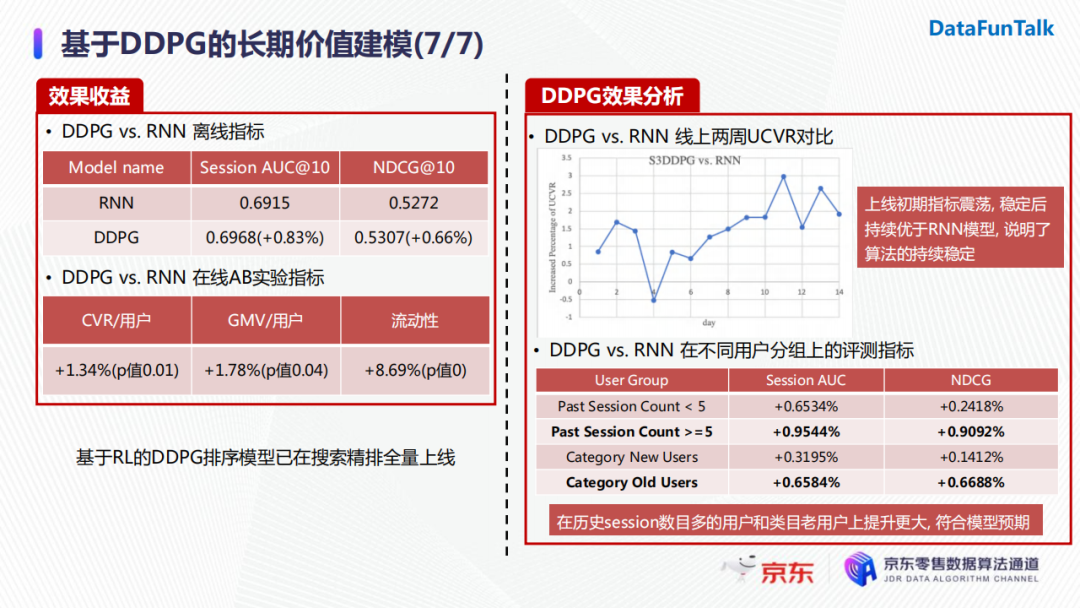
DDPG在離線指標上相較於RNN模型在Session AUC@10上有了0.83%的提升,線上AB實驗指標如用戶轉化率以及GMV也均有大於1個點的顯著提升。
目前DDPG也在搜索精排中進行了一次全量更新。其實大家也會很擔心DDPG線上上的穩定性問題,我們對此也做了很多分析。
首先,我們對比了兩周的線上指標(後續其實觀察了更長時間),發現DDPG在上線初期指標出現震蕩,但是模型穩定之後其指標持續優於RNN模型,證明瞭演算法的穩定性。
另外,我們考慮了不同用戶分組上的評測指標,例如將用戶按照他的歷史搜索次數進行篩選和分組。實驗發現,DDPG在用戶歷史搜索越多時,其對長期價值的建模越準確。這在使用新老用戶進行分組實驗時也體現了相似的結論,與我們的建模預期吻合。
--
05 規劃與展
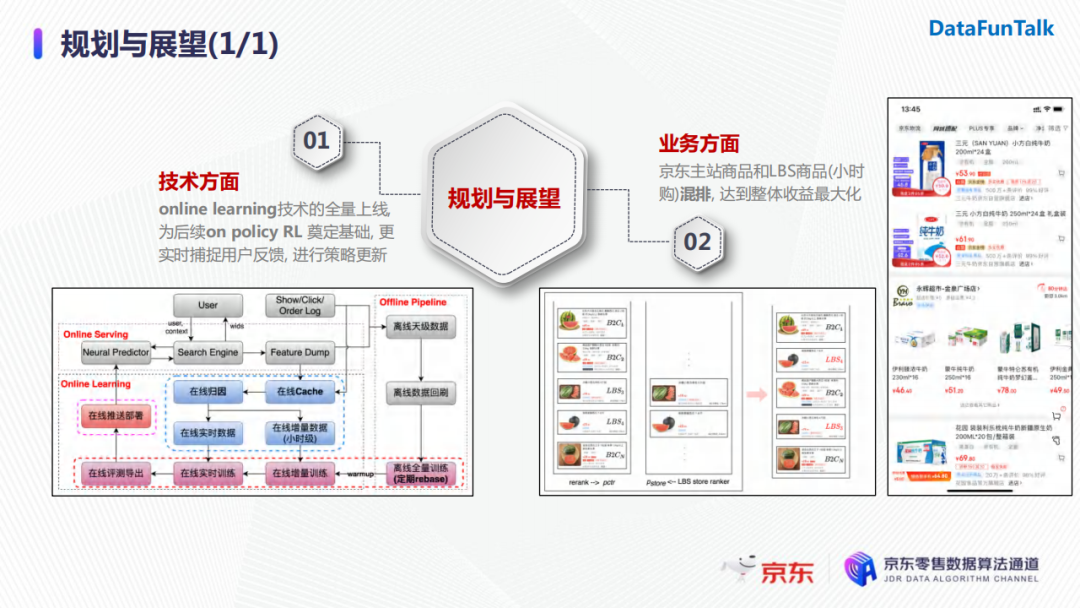
首先,在技術方面,因為我們一開始強化學習的模型並沒有線上上使用online learning,所以剛開始迭代的時候模型還是進行離線更新。目前我們online learning的技術已經全量上線了,後續會做一些更複雜的探索,為on-policy的強化學習演算法奠定基礎。採用on-policy強化學習演算法能夠更加實時捕捉用戶反饋,不斷地進行策略的更新。
另一方面,在業務層面,京東主站商品和LBS商品(小時購)部署的排序模塊是兩個獨立模型。那麼如何對這兩種類型的商品進行混排來達到整體收益最大化是我們想要探索的目標。
--
06 精彩問答
Q1:Dump feature中包含什麼內容?
A:首先,dump feature包含用戶在此次請求時模型使用到的所有商品特征;此外,RNN模型生成的hidden state也會一起加入dump feature中,為後續RNN狀態線上增量更新做準備。
Q2:請問有沒有嘗試過offline強化學習的方法?
A:其實剛纔介紹的模型就是一個offline RL的方法。我們的模型會使用歷史上一段時間的數據,在訓練時我們先離線地使模型達到收斂狀態,再將其推至線上進行服務。模型一般一天更新一次,所以在一天之內模型的參數是不變的,但是用戶的狀態向量會做不斷的增量更新。
Q3:請問模型是使用什麼方式進行部署的,性能怎麼樣?
A:其實這是我們京東內部模型部署的一個架構,我們稱其為Predictor。在正常情況下,我們模型導出之後會有一些驗分的流程,之後會將其推送至Predictor進行線上部署。針對性能的話,雖然線上上有RNN模塊,但是我們已經把使用用戶歷史的搜索計算出的用戶狀態保存下來並作為RNN的初始狀態,所以每一步RNN前向計算都是一個增量計算的過程,對性能沒有特別大的影響。
Q4:請問我們的環境是靜態數據嗎?如果是靜態數據,怎麼做探索?
A:在訓練的過程中,環境是一個靜態數據,我們使用用戶的歷史session,通過RNN不斷地學習下一個session的狀態。線上服務時,當模型有了初始狀態之後,線上環境會給予它實時反饋,進而做線上的更新。
Q5:請問有沒有考慮過listwise的排序方法?
A:Listwise排序更多地會用在有監督學習中。在我們強化學習的建模中,我們除了考慮當前的即時獎勵之外還會考慮後續的長期價值。但是,我們並沒有在用戶當前搜索下考慮商品與商品之間的關係, session內樣本構造還是一個pairwise的方法。
Q6:請問為什麼會設計這種連續的reward函數?
A:這和我們動作的設計有關。我們的動作是對候選商品的排序打分,這是一個連續的動作空間。另外,我們的目標是輸出排序動作後,模型對正負樣本存在一定的區分性,即在排序正確的情況下得分相差越多,獎勵越高。此外,如果給予打分接近、沒有太大區分度的兩個商品同等的獎勵對模型的收斂性不是特別好。
Q7:請問模型線上上會有探索的過程嗎?探索的過程是否會造成收益的損失?
A:目前我們的模型是離線訓練好後推至線上服務的,並且在一天之內不會進行參數更新,所以也沒有線上的探索過程。目前online learning的模型已經全量上線了,之後我們會採用離線預訓練好一個模型、線上做探索的方法進行一些嘗試。但是,直接去線上做策略探索的話,損失是我們承擔不起的,所以一般還是會有一個離線預訓練模型,加上線上online learning進行policy的探索。

