
一、概述 Presto是Facebook開源的MPP(Massively Parallel Processing:大規模並行處理)架構的OLAP(on-line transaction processing:聯機事務處理),完全基於記憶體的並⾏計算,可針對不同數據源,執行大容量數據集的一款分散式SQL ...
目錄
一、概述
Presto是Facebook開源的MPP(Massively Parallel Processing:大規模並行處理)架構的OLAP(on-line transaction processing:聯機事務處理),完全基於記憶體的並⾏計算,可針對不同數據源,執行大容量數據集的一款分散式SQL互動式查詢引擎。 它是為瞭解決Hive的MapReduce模型太慢以及不能通過BI或Dashboards直接展現HDFS數據等問題。
但是Presto目前有兩大分支:PrestoDB(背靠Facebook)和PrestoSQL現在改名為Trino(Presto的創始團隊),雖然PrestoDB背靠Facebook,但是社區活躍度和使用群體還是遠不如Trino。所以這裡以Trino為主展開講解。
PrestoDB官方文檔:https://prestodb.io/docs/current/
Trino官方文檔:https://trino.io/docs/current/
二、Trino特點
Trino是基於java開發的,對於大部分開發者和使用者而言,Trino容易學習並對特定的場景進行二次開發和性能優化等。多數據源、支持SQL、擴展性強、高性能,流水線模式。
-
多數據源:目前版本支持20多種數據源,幾乎能覆蓋所有常見情況,Elasticsearch 、Hive 、JMX 、Kafka Kudu 、Local File、Memory 、MongoDB 、MySQL 、Redis等等
-
支持SQL:完成支持ANSI SQL,提供SQL shell
-
擴展性:支持開發自己的特定數據源的connector
-
高性能:Trino基於記憶體計算,在絕大多數情況下,Trino的查詢性能是hive的10倍以上,完全能實現互動式,實時查詢
-
流水線:Trino是基於PipeLine設計的,在進行大量設計處理過程中,終端不需要等待所有的數據計算完畢之後才能看到結果,計算一部分就可以看部分結果
三、Trino架構
1)架構和服務節點
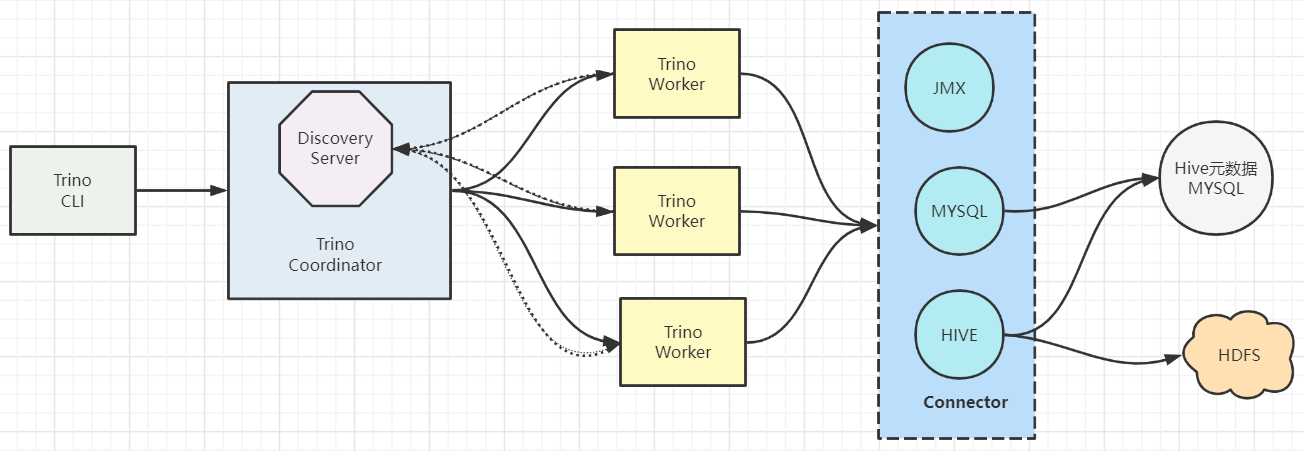
- Trino查詢引擎是一個Master-Slave的架構,有兩種進程
Coordinator服務進程和worker服務進程組成。細分的話還有一個Discovery Server節點,Discovery Server通常內嵌於Coordinator節點中。 Coordinator主要作用是接收查詢請求,解析查詢語句,生成查詢執行計劃,任務調度和worker管理。Worker服務進程執行被分解的查詢執行任務:taskWorker節點啟動後向Discovery Server服務註冊,Coordinator從Discovery Server獲得可以正常工作的Worker節點。- 如果配置了Hive Connector,需要配置一個Hive MetaStore服務為Trino提供Hive元信息,Worker節點與HDFS交互讀取數據。
2)Trino數據模型
Trino就是通過Connector來訪問不同的數據源的,相當於訪問不同數據源的驅動程式,每種connector都實現了Trino的標準SPI介面,因此只要實現了標準SPI介面就可以制定特殊的Connector來訪問數據源。
Trino採取三層表結構:
- Catalog
Trino中Catalog類似於mysql中的一個資料庫實例,Schema類似於mysql當中的一個database。如用Trino去連接一個hive中的一個庫
trino --server ip:port --catalog hive --schema xxx 這樣就可以訪問hive的中的xxx庫。
- Schema
Trino中的schema就相當於mysql中的一個具體的database。
- Table
Trino中的table和mysql中table含義一樣
四、Trino安裝部署
官方安裝文檔:https://trino.io/docs/current/installation/deployment.html
1)單機版(Coordinator和Worker同進程)
1、安裝JDK11
【溫馨提示】JDK最低要求版本為11.0.11
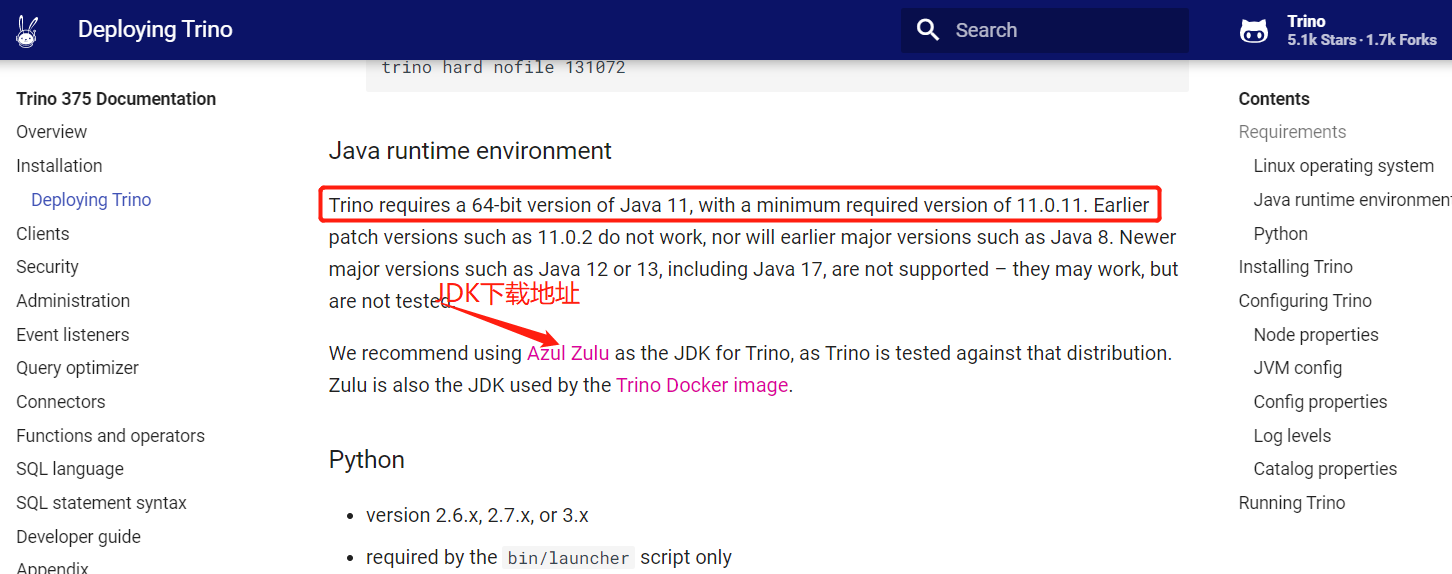

$ cd /opt/bigdata/hadoop/software/
$ wget https://cdn.azul.com/zulu/bin/zulu11.54.25-ca-jdk11.0.14.1-linux_x64.zip
$ unzip zulu11.54.25-ca-jdk11.0.14.1-linux_x64.zip -d /opt/bigdata/hadoop/server/
配置環境變數,在/etc/profile添加如下內容:
export JAVA_HOME=/opt/bigdata/hadoop/server/zulu11.54.25-ca-jdk11.0.14.1-linux_x64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
載入生效
$ source /etc/profile
$ java -version

2、安裝python
一般linux機器自帶了python,所以自帶了就可以不用再裝了,沒python環境,就得安裝下麵步驟安裝python環境
$ yum -y install python3
$ python3 --version
$ ln -s /usr/bin/python3 /usr/bin/python
當然也可以離線安裝,各個版本下載地址:https://www.python.org/ftp/python/
3、下載Trino安裝包
$ cd /opt/bigdata/hadoop/software
$ wget https://repo1.maven.org/maven2/io/trino/trino-server/375/trino-server-375.tar.gz
$ tar -xvf trino-server-375.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server
$ mv trino-server-375 presto375
4、配置
首先創建etc和data目錄,後面配置文件需要用到
$ cd /opt/bigdata/hadoop/server/presto375
$ mkdir etc data
- Node properties
$ cat << EOF > etc/node.properties
# 環境的名字。集群中所有的Trino節點必須具有相同的環境名稱。
node.environment=presto
# 此Trino安裝的唯一標識符。這對於每個節點都必須是唯一的。
node.id=presto-worker
# 數據目錄的位置(文件系統路徑)。Trino在這裡存儲日誌和其他數據。
node.data-dir=/opt/bigdata/hadoop/server/presto375/data
EOF
- JVM config
【溫馨提示】
-Xmx最大堆記憶體大小,根據機器配置來定,但是一般jvm堆記憶體分配<32G。
$ cat << EOF > etc/jvm.config
-server
-Xmx2G
-XX:-UseBiasedLocking
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
EOF
- Config properties
$ cat << EOF > etc/config.properties
# 設置該節點為coordinator節點
coordinator=true
# 允許在協調器上調度工作,也就是coordinator節點又充當worker節點用
node-scheduler.include-coordinator=true
# 指定HTTP伺服器的埠。Trino使用HTTP進行內部和外部web的所有通信。
http-server.http.port=9000
# 查詢可以使用的最大分散式記憶體。【註意】不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory=1GB
# 查詢可以在任何一臺機器上使用的最大用戶記憶體。【註意】也是不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory-per-node=1GB
# hadoop-node1也可以是IP
discovery.uri=http://hadoop-node1:9000
EOF
- Log levels
$ cat << EOF > etc/log.properties
# 設置日誌級別,有四個級別:DEBUG, INFO, WARN and ERROR
io.trino=INFO
EOF
5、配置jmx連接器
Java管理擴展(JMX)提供有關JVM中運行的Java虛擬機和軟體的信息。JMX連接器用於在Trino伺服器中查詢JMX信息。
配置
$ cd /opt/bigdata/hadoop/server/presto375
# 先創建catalog目錄
$ mkdir etc/catalog/ -p
$ echo "connector.name=jmx" > etc/catalog/jmx.properties
6、啟動服務
$ cd /opt/bigdata/hadoop/server/presto375
$ bin/launcher start
$ netstat -tnlp|grep :9000

7、測試驗證
web訪問驗證:http://hadoop-node1:9000
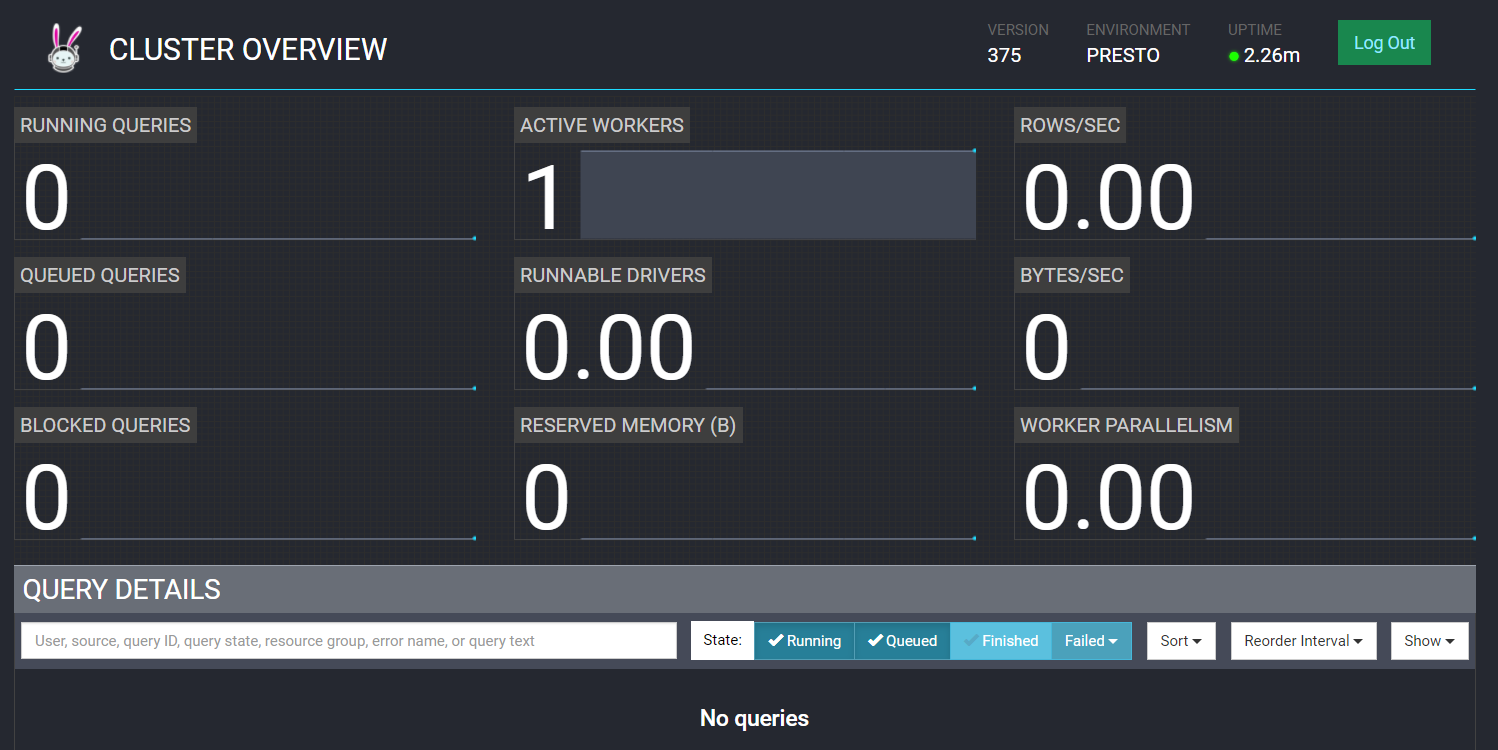
8、下載客戶端
$ cd /opt/bigdata/hadoop/server/presto375/bin/
$ wget https://repo1.maven.org/maven2/io/trino/trino-cli/375/trino-cli-375-executable.jar
# 改名,加執行許可權
$ mv trino-cli-375-executable.jar trino
$ chmod +x trino
### 連接測試
$ cd /opt/bigdata/hadoop/server/presto375
$ ./bin/trino --server hadoop-node1:9000
# 命令不區分大小寫
show catalogs;
# 查庫
show schemas from system;
# 查表
show tables from system.runtime;
# 查具體記錄,查看當前node節點記錄
select * from system.runtime.nodes;
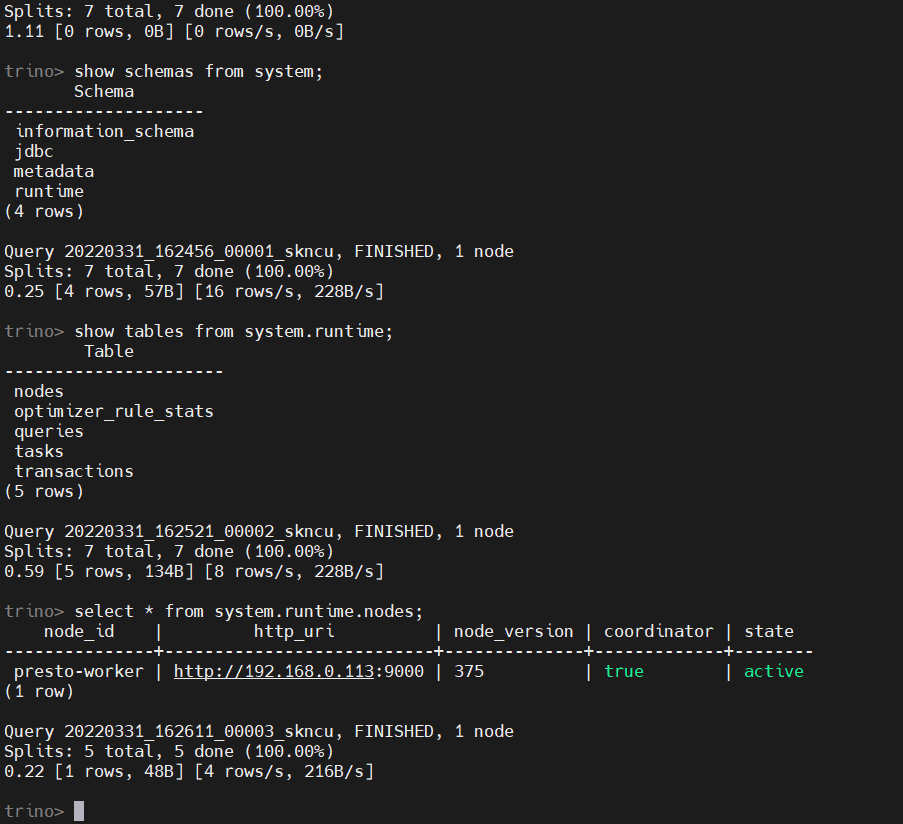
2)單機版(Coordinator和Worker不同進程)
其實上面的部署方式,是Coordinator和Worker在同一個進程中,現在需要分開。
- 先停掉服務
$ cd /opt/bigdata/hadoop/server/presto375
$ ./bin/launcher stop
- 創建coordinator和worker目錄
$ cd mkdir coordinator worker
# copy to coordinator
$ cp -r bin data etc lib NOTICE plugin README.txt coordinator/
# copy to worker
$ cp -r bin data etc lib NOTICE plugin README.txt worker/
- 修改coordinator配置
$ cd /opt/bigdata/hadoop/server/presto375/coordinator
### etc/node.properties
$ cat << EOF > etc/node.properties
node.environment=presto
node.id=presto-coordinator
node.data-dir=/opt/bigdata/hadoop/server/presto375/coordinator/data
EOF
### etc/jvm.config
$ cat << EOF > etc/config.properties
# 設置該節點為coordinator節點
coordinator=true
# 允許在協調器上調度工作,也就是coordinator節點又充當worker節點用
node-scheduler.include-coordinator=false
# 指定HTTP伺服器的埠。Trino使用HTTP進行內部和外部web的所有通信。
http-server.http.port=9000
# 查詢可以使用的最大分散式記憶體。【註意】不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory=1GB
# 查詢可以在任何一臺機器上使用的最大用戶記憶體。【註意】也是不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory-per-node=1GB
# hadoop-node1也可以是IP
discovery.uri=http://hadoop-node1:9000
EOF
- 啟動coordinator
$ ./bin/launcher start
- 修改worker配置
$ cd /opt/bigdata/hadoop/server/presto375/worker
### etc/node.properties
$ cat << EOF > etc/node.properties
node.environment=presto
node.id=presto-worker
node.data-dir=/opt/bigdata/hadoop/server/presto375/worker/data
EOF
$ cat << EOF > etc/config.properties
# 設置該節點為worker節點
coordinator=false
# 指定HTTP伺服器的埠。Trino使用HTTP進行內部和外部web的所有通信。這裡埠得改,要不然會存在埠衝突
http-server.http.port=8080
# 查詢可以使用的最大分散式記憶體。【註意】不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory=1GB
# 查詢可以在任何一臺機器上使用的最大用戶記憶體。【註意】也是不能配置超過jvm配置的最大堆棧記憶體大小
query.max-memory-per-node=1GB
# hadoop-node1也可以是IP
discovery.uri=http://hadoop-node1:9000
EOF
- 啟動worker
$ ./bin/launcher start
$ netstat -tnlp|grep 8080
$ jps
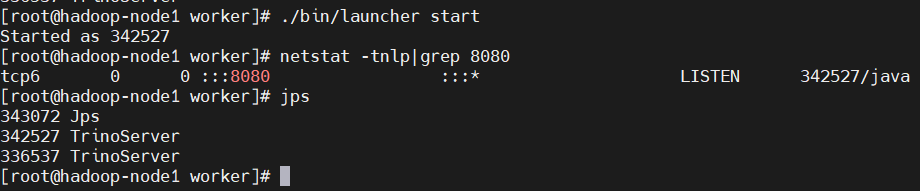
3)集群模式(多worker節點)
把worker目錄全部copy到另外的機器(hadoop-node2)啟動即可,修改配置,啟動即可以。操作如下:
1、安裝JDK11
$ cd /opt/bigdata/hadoop/software/
$ wget https://cdn.azul.com/zulu/bin/zulu11.54.25-ca-jdk11.0.14.1-linux_x64.zip
$ unzip zulu11.54.25-ca-jdk11.0.14.1-linux_x64.zip -d /opt/bigdata/hadoop/server/
配置環境變數,在/etc/profile添加如下內容:
export JAVA_HOME=/opt/bigdata/hadoop/server/zulu11.54.25-ca-jdk11.0.14.1-linux_x64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
載入生效
$ source /etc/profile
$ java -version
2、安裝python
一般linux機器自帶了python,所以自帶了就可以不用再裝了,沒python環境,就得安裝下麵步驟安裝python環境
$ yum -y install python3
$ python3 --version
$ ln -s /usr/bin/python3 /usr/bin/python
3、copy worker目錄到其它節點
# hadoop-node2上創建目錄
$ mkdir -p /opt/bigdata/hadoop/server/presto375
# 在hadoop-node1上執行下麵操作
$ cd /opt/bigdata/hadoop/server/presto375
$ scp -r worker hadoop-node2:/opt/bigdata/hadoop/server/presto375/
4、修改配置
$ /opt/bigdata/hadoop/server/presto375/worker
# 只需要修改etc/node.properties
$ cat << EOF > etc/node.properties
# node.environment所有節點都是一樣的
node.environment=presto
# node.id唯一性
node.id=presto-worker02
node.data-dir=/opt/bigdata/hadoop/server/presto375/worker/data
EOF
5、啟動worker節點服務
$ cd /opt/bigdata/hadoop/server/presto375/worker
$ ./bin/launcher start
$ netstat -tnlp|grep 8080
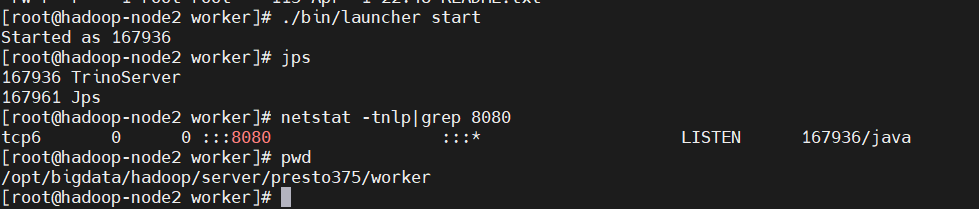

查表驗證
$ cd /opt/bigdata/hadoop/server/presto375/coordinator
# 非互動式,以TSV_HEADER格式展示
$ ./bin/trino --server hadoop-node1:9000 --execute "select * from system.runtime.nodes;" --output-format=TSV_HEADER
# 下麵這句跟上面等價
$ ./bin/trino --server hadoop-node1:9000 --catalog system --schema runtime --execute "select * from nodes;" --output-format=TSV_HEADER

五、配置HTTPS(coordinator)
1)生成證書
$ cd /opt/bigdata/hadoop/server/presto375/coordinator
$ mkdir certificate
$ cd certificate
# 生成 CA 證書私鑰
$ openssl genrsa -out clustercoord.key 4096
# 生成 CA 證書
$ openssl req -x509 -new -nodes -sha512 -days 3650 \
-subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=mypresto.com" \
-key clustercoord.key \
-out clustercoord.cert
# 合併
$ cat clustercoord.key clustercoord.cert > clustercoord.pem
2、配置
$ cd /opt/bigdata/hadoop/server/presto375/coordinator
在etc/config.properties添加如下配置:
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/opt/bigdata/hadoop/server/presto375/coordinator/certificate/clustercoord.pem
3、重啟服務並驗證
$ ./bin/launcher restart
$ jps
$ netstat -tnlp|grep 9000
$ netstat -tnlp|grep 8443
web UI:https://hadoop-node1:8443/

【溫馨提示】之前的http也還是可以訪問的:http://hadoop-node1:9000/
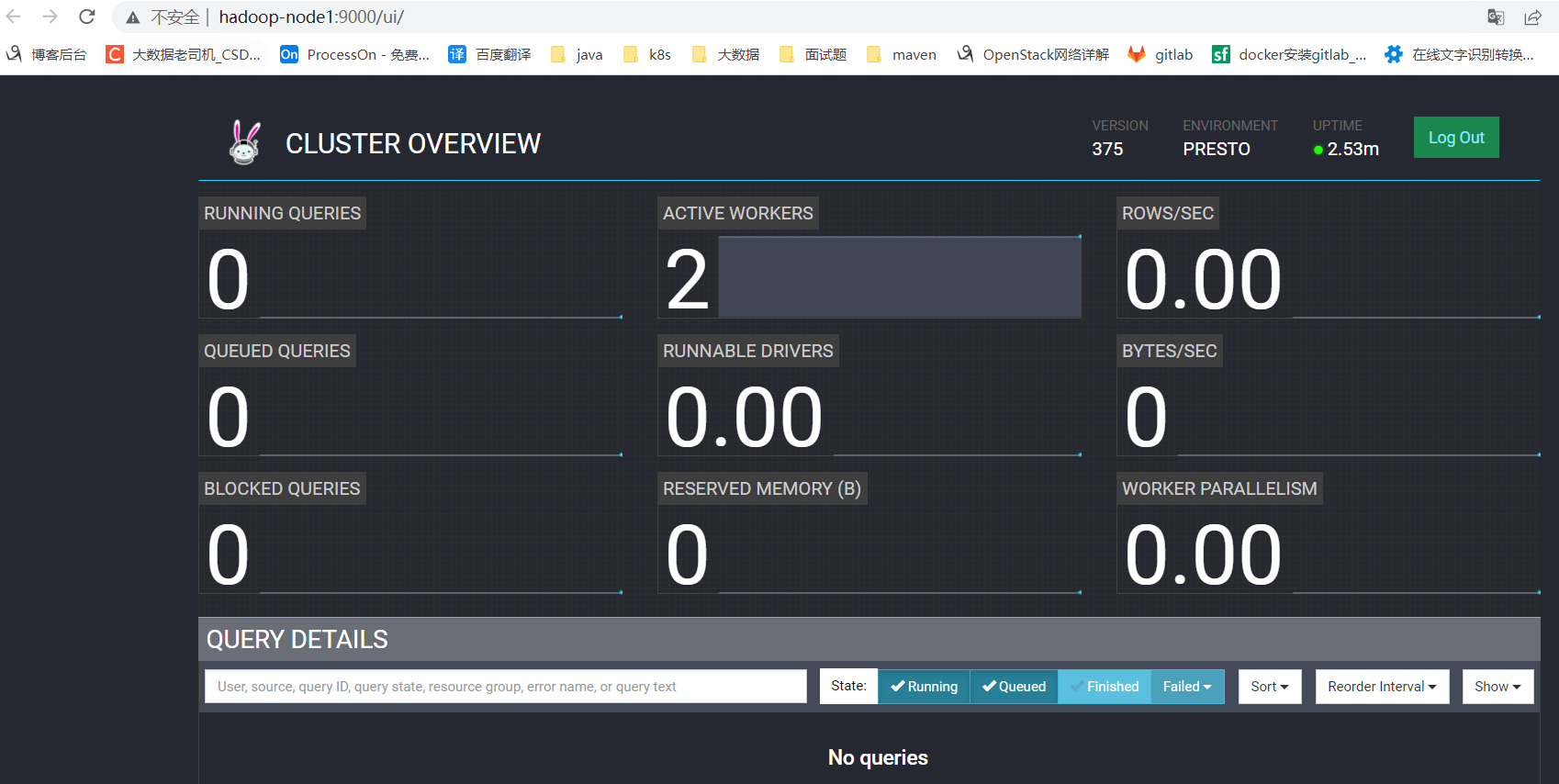
4、配置賬號密碼訪問
# etc/config.properties增加如下配置:
http-server.authentication.type=PASSWORD
創建配置etc/password-authenticator.properties,此處可以配置使用LDAP或密碼文件認證,這裡測試採用密碼文件認證。配置內容如下:
password-authenticator.name=file
file.password-file=/opt/bigdata/hadoop/server/presto375/coordinator/etc/password.db
創建密碼文件etc/password.db,配置賬號和密碼,密碼是bcrypt格式密文密碼,這裡賬號密碼自定義就好,這裡使用,admin/123456
這裡提供一個線上bcrypt加密地址:http://www.ab126.com/goju/10822.html
etc/password.db內容如下:
admin:$2y$10$9O.FnPn27br2ebxzns3QkOj22OTQAaTvIBPjZd1dAjS5MOXaOJFxK
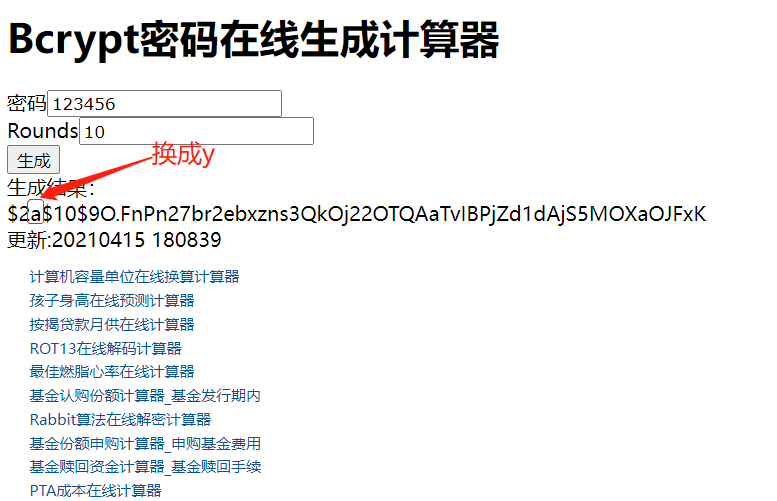
【溫馨提示】生成出來的密文密碼,開頭必須是
$2y$,所以把上面的a換成了y了,要不然登錄不了。
重啟服務驗證
$ cd /opt/bigdata/hadoop/server/presto375/coordinator
$ ./bin/launcher restart
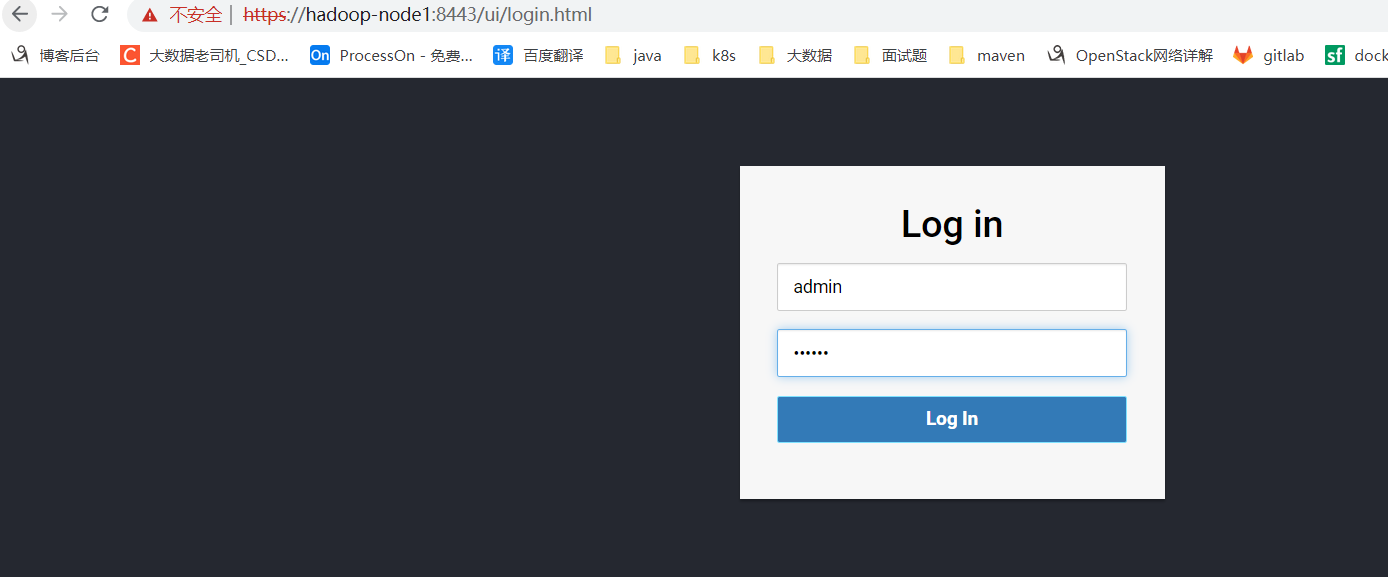
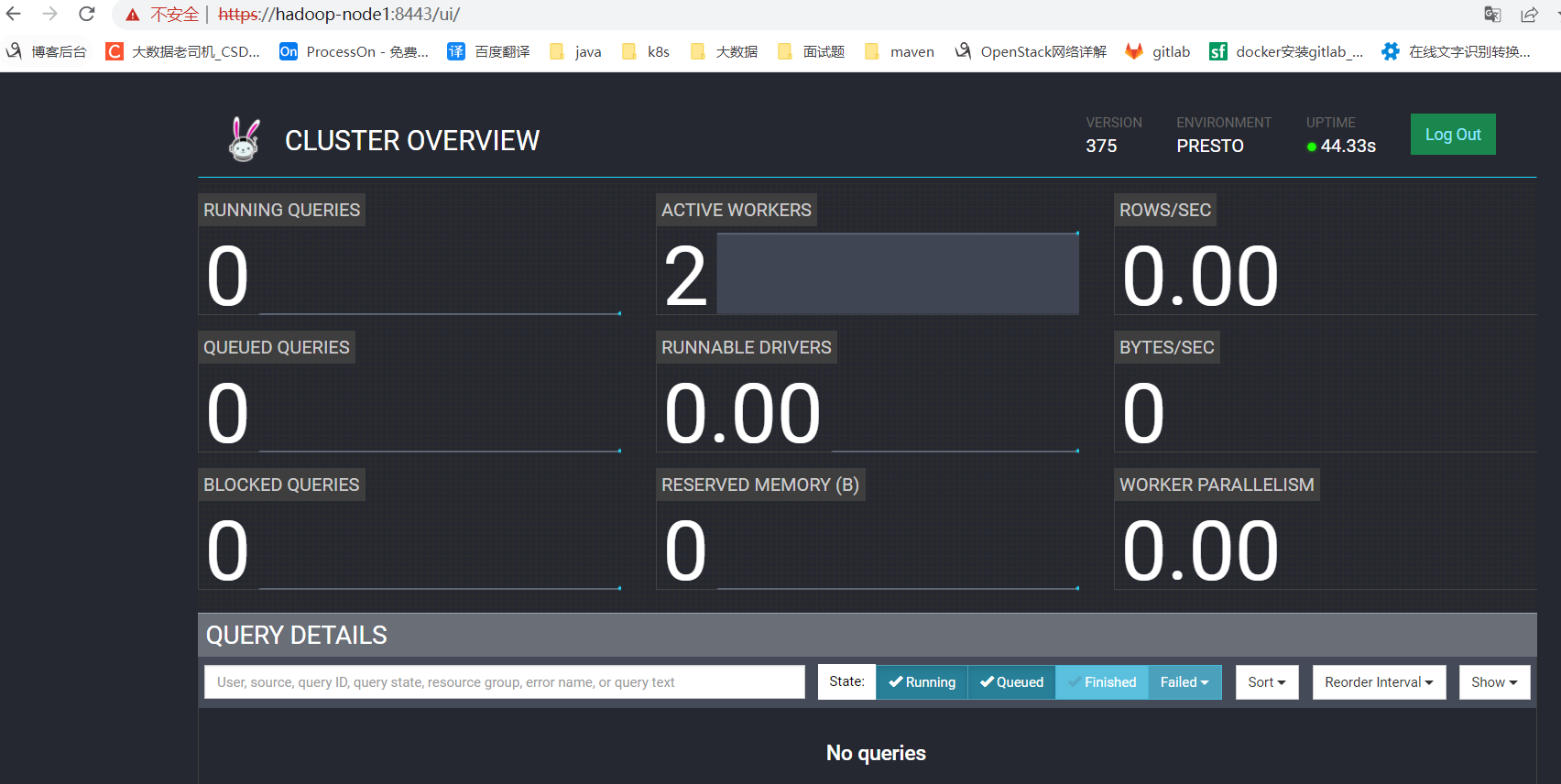
到這裡就配置完成了。還有其它認證方式,可以查看官方文檔。
六、連接器
連接器其實就是指定某種數據源,上面已經配置過了jmx,這裡就不再重覆,這裡主要講mysql和hive這兩個連接器,mysql和hive的安裝可以參考我之前的文章:大數據Hadoop之——數據倉庫Hive。其它的連接器,可以自行查看官方文檔。
1)MySQL連機器
MySQL連接器允許在外部MySQL實例中查詢和創建表。
在etc/catalog目錄下,增加mysql配置,配置文件為mysql.properties,具體配置如下:
# 所有節點都得添加
$ cat << EOF > etc/catalog/mysql.properties
connector.name=mysql
connection-url=jdbc:mysql:/hadoop-node1:3306
connection-user=root
connection-password=123456
EOF
重啟Trino服務
$ ./bin/launcher restart
# 註意下麵連接方式會報錯,因為是使用https方式,而我們上面生成的證書是不可信的,所以需要加--insecure,去跳過證書驗證。
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password
# 互動式登錄
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure
show catalogs;
show schemas from mysql;
show tables from mysql.azkaban;
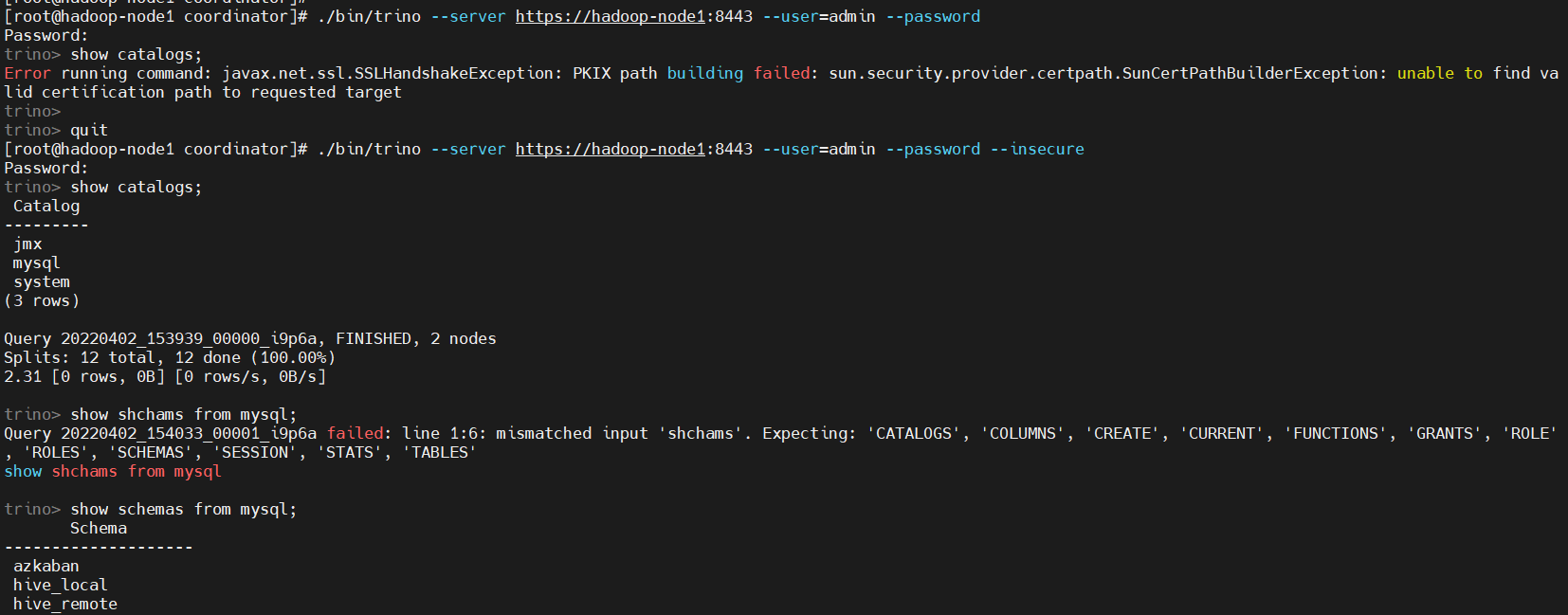
非交互登錄
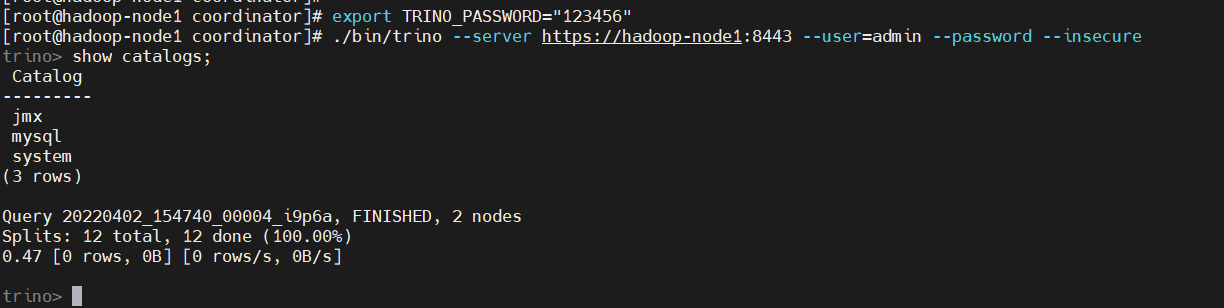
# 非交互登錄設置一個TRINO_PASSWORD 環境變數
$ export TRINO_PASSWORD="123456"
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure
show catalogs;
非互動式執行SQL,加上這個參數--execute="sql語句"和TRINO_PASSWORD 環境變數
$ export TRINO_PASSWORD="123456"
## --execute=
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure --execute="show catalogs;"
# 以不同的格式輸出,--output-format
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure --execute="show catalogs;" --output-format=JSON
# 如果覺得這條命令太長,可以設置別名
$ alias trino='./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure'
$ trino --execute="show catalogs;" --output-format=JSON
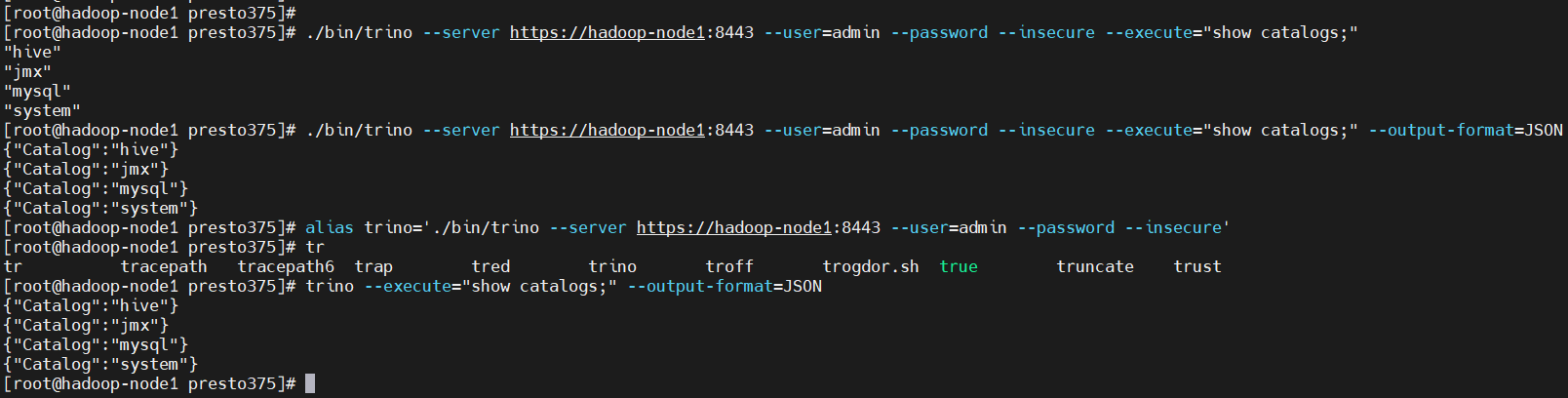

到這步就可以開始愉快的寫sql了。
2)Hive連接器
Hive依賴於hadoop的基礎服務,可以參考我之前的文章:大數據Hadoop原理介紹+安裝+實戰操作(HDFS+YARN+MapReduce)
Hive的安裝部署可以參考我之前的文章::大數據Hadoop之——數據倉庫Hive
啟動hdfs、yarn、hive服務
# 啟動hdfs、yarn服務,hdfs webui埠:9870,yarn webui埠:8088
$ start-all.sh
# 啟動hive metastore服務,埠:9083
$ nohup hive --service metastore &
準備好基礎服務後,就可以開始配置Trino了。
$ cat << EOF > etc/catalog/hive.properties
connector.name=hive
hive.metastore.uri=thrift://hadoop-node1:9083
EOF
重啟服務
$ ./bin/launcher restart
驗證
$ ./bin/trino --server https://hadoop-node1:8443 --user=admin --password --insecure
show catalogs;
show schemas from hive;
show tables from hive.default;

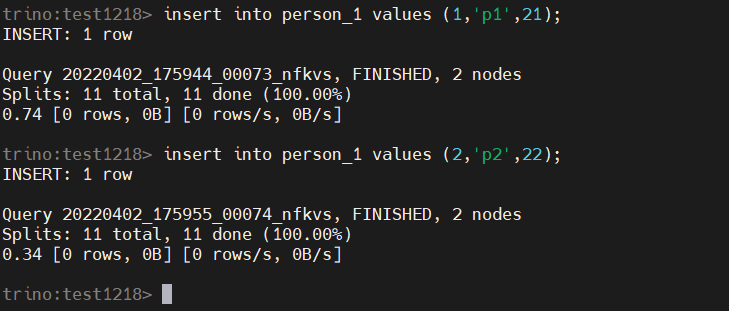
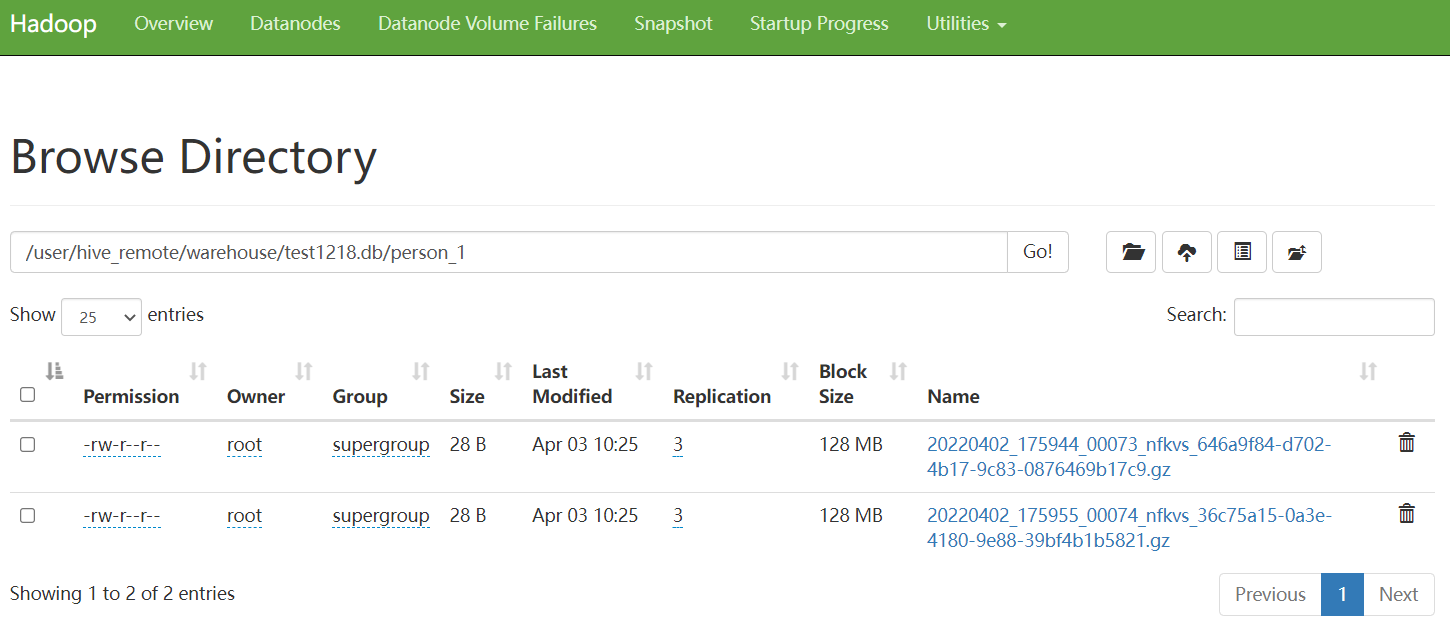
【溫馨提示】雖然是連hive,但是計算不會再走MR了,直接在記憶體中計算輸出結果,insert添加數據也是直接在記憶體完成,把數據推到HDFS,元數據還是存在mysql,非常快,這也是Trino的優勢。示例如下:
insert into person_1 values (1,'p1',21);
insert into person_1 values (2,'p2',22);
更多連接器,請查閱官方文檔:https://trino.io/docs/current/connector.html
七、Trino JDBC driver
Trino JDBC驅動程式允許用戶使用基於java的應用程式和運行在JVM中的其他非java應用程式訪問Trino。其實就是java大數據開發。
環境搭建可以參考我之前的文章:大數據Hadoop之——搭建本地flink開發環境詳解(window10)
1)Maven配置
在pom.xml添加如下內容:
<dependencies>
<dependency>
<groupId>io.trino</groupId>
<artifactId>trino-jdbc</artifactId>
<version>375</version>
</dependency>
</dependencies>
2)示例演示
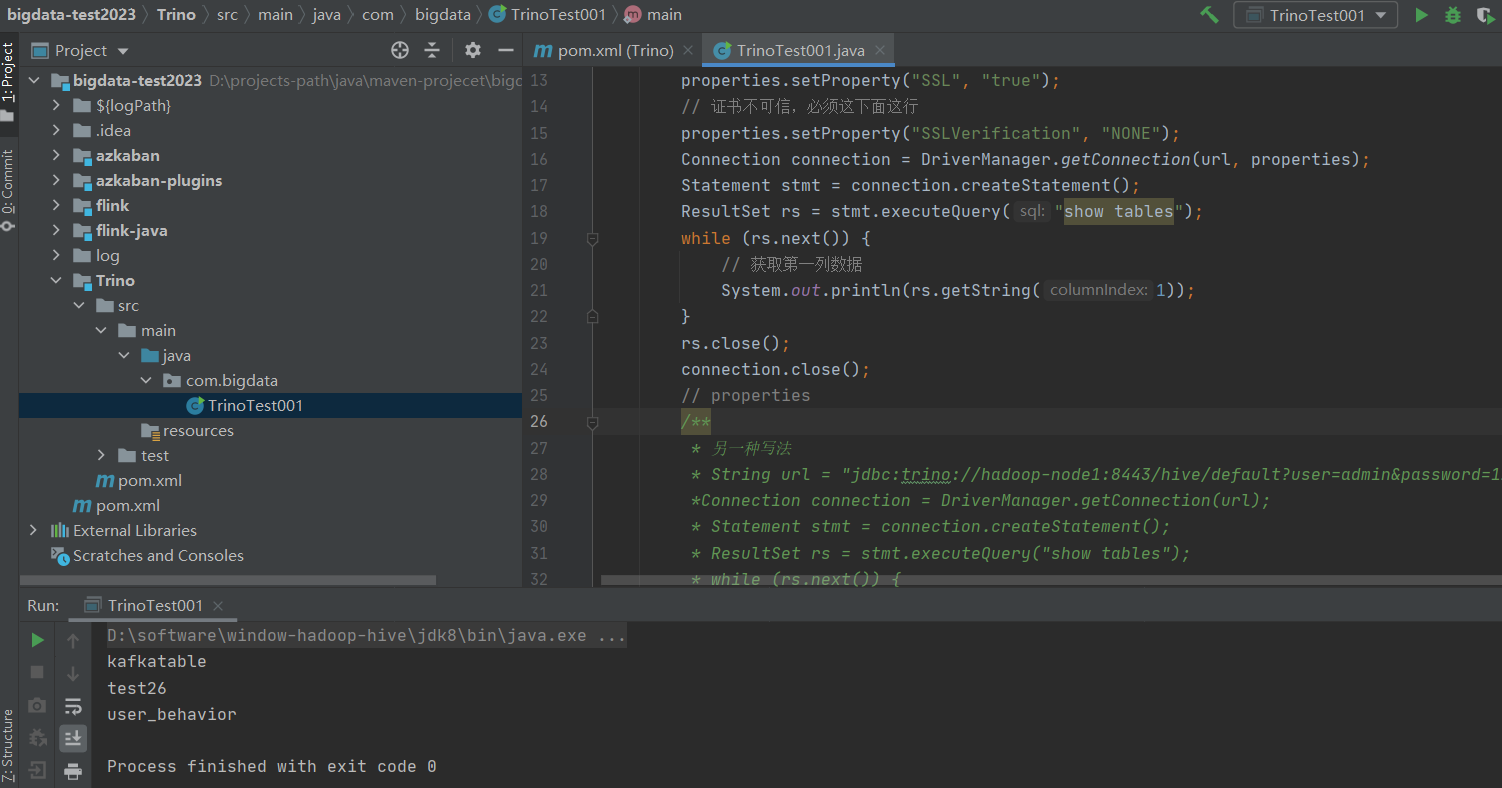
package com.bigdata;
import java.sql.*;
import java.util.Properties;
public class TrinoTest001 {
public static void main(String[] args) throws SQLException {
// URL parameters
String url = "jdbc:trino://hadoop-node1:8443/hive/default";
Properties properties = new Properties();
properties.setProperty("user", "admin");
properties.setProperty("password", "123456");
properties.setProperty("SSL", "true");
// 證書不可信,必須這下麵這行
properties.setProperty("SSLVerification", "NONE");
Connection connection = DriverManager.getConnection(url, properties);
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("show tables");
while (rs.next()) {
// 獲取第一列數據
System.out.println(rs.getString(1));
}
rs.close();
connection.close();
// properties
/**
* 另一種寫法
* String url = "jdbc:trino://hadoop-node1:8443/hive/default?user=admin&password=123456&SSL=true&SSLVerification=NONE";
*Connection connection = DriverManager.getConnection(url);
* Statement stmt = connection.createStatement();
* ResultSet rs = stmt.executeQuery("show tables");
* while (rs.next()) {
* // 獲取第一列數據
*
* System.out.println(rs.getString(1));
* }
* rs.close();
* connection.close();
*
*/
}
}
Trino的基礎部分就到這結束了,如果疑問歡迎給我留言,關於更Trino的知識可以參考官方文檔:https://trino.io/docs/current/index.html,關於更多大數據相關知識,請耐心等待~

