
大家好,我是大D。 不知是否有小伙伴們疑問,為什麼列式存儲會廣泛地應用在 OLAP 領域,和行式存儲相比,它的優勢在哪裡?今天我們一起來對比下這兩種存儲方式的差別。 其實,列式存儲並不是一項新技術,最早可以追溯到 1983 年的論文 Cantor。然而,受限於早期的硬體條件和應用場景,傳統的事務型數 ...
大家好,我是大D。
不知是否有小伙伴們疑問,為什麼列式存儲會廣泛地應用在 OLAP 領域,和行式存儲相比,它的優勢在哪裡?今天我們一起來對比下這兩種存儲方式的差別。
其實,列式存儲並不是一項新技術,最早可以追溯到 1983 年的論文 Cantor。然而,受限於早期的硬體條件和應用場景,傳統的事務型資料庫(OLTP)如 Oracle、MySQL 等關係型資料庫都是以行的方式來存儲數據的。
直到近幾年分析型資料庫(OLAP)的興起,列式存儲這一概念又變得流行,如 HBase、Cassandra 等大數據相關的資料庫都是以列的方式來存儲數據的。
行式存儲的原理與特點
對於 OLAP 場景,大多都是對一整行記錄進行增刪改查操作的,那麼行式存儲採用以行的行式在磁碟上存儲數據就是一個不錯的選擇。
當查詢基於需求欄位查詢和返回結果時,由於這些欄位都埋藏在各行數據中,就必須讀取每一條完整的行記錄,大量磁碟轉動定址的操作使得讀取效率大大降低。
舉個例子,下圖為員工信息emp表。
數據在磁碟上是以行的形式存儲在磁碟上,同一行的數據緊挨著存放在一起。
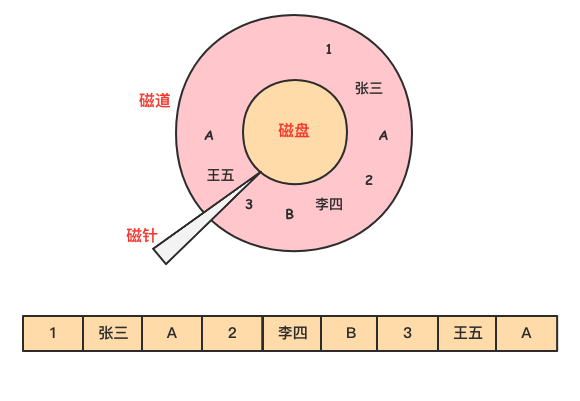
對於 emp 表,要查詢部門 dept 為 A 的所有員工的名字。
select name from emp where dept = A
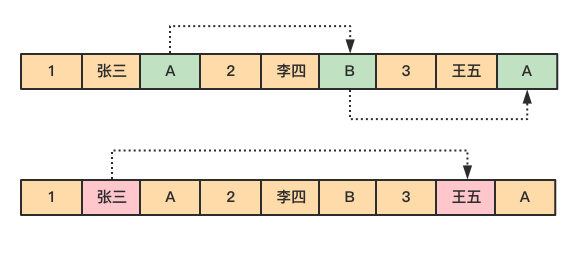
由於 dept 的值是離散地存儲在磁碟中,在查詢過程中,需要磁碟轉動多次,才能完成數據的定位和返回結果。
列式存儲的原理與特點
對於 OLAP 場景,一個典型的查詢需要遍歷整個表,進行分組、排序、聚合等操作,這樣一來行式存儲中把一整行記錄存放在一起的優勢就不復存在了。而且,分析型 SQL 常常不會用到所有的列,而僅僅對其中某些需要的的列做運算,那一行中無關的列也不得不參與掃描。
然而在列式存儲中,由於同一列的數據被緊挨著存放在了一起,如下圖所示。
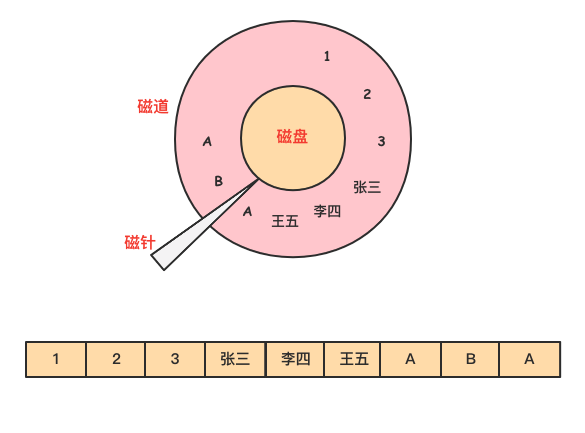
那麼基於需求欄位查詢和返回結果時,就不許對每一行數據進行掃描,按照列找到需要的數據,磁碟的轉動次數少,性能也會提高。
還是上面例子中的查詢,由於在列式存儲中 dept 的值是按照順序存儲在磁碟上的,因此磁碟只需要順序查詢和返回結果即可。
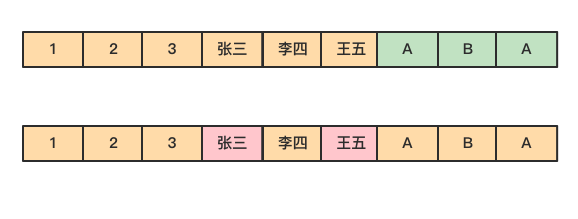
列式存儲不僅具有按需查詢來提高效率的優勢,由於同一列的數據屬於同一種類型,如數值類型,字元串類型等,相似度很高,還可以選擇使用合適的編碼壓縮可減少數據的存儲空間,進而減少IO提高讀取性能。
總的來說,行式存儲和列式存儲沒有說誰比誰更優越,只能說誰更適合哪種應用場景。
非常歡迎大家加我微信:Abox_0226,備註「進群」,有關大數據技術的問題在群里一起探討。


