
導讀: 美團是一個生活服務領域的平臺,需要大量知識來理解用戶的搜索意圖,同時對於商家側我們也需要利用現有的知識對海量信息進行挖掘與提取,進而優化用戶體驗。今天分享的主題是知識圖譜在美團推薦場景中的應用。主要包括以下幾方面內容: 美團知識圖譜介紹 美團推薦場景介紹 美團推薦中的知識應用 總結與展望 - ...

導讀: 美團是一個生活服務領域的平臺,需要大量知識來理解用戶的搜索意圖,同時對於商家側我們也需要利用現有的知識對海量信息進行挖掘與提取,進而優化用戶體驗。今天分享的主題是知識圖譜在美團推薦場景中的應用。主要包括以下幾方面內容:
- 美團知識圖譜介紹
- 美團推薦場景介紹
- 美團推薦中的知識應用
- 總結與展望
--
01 美團知識圖譜介紹
首先介紹美團的知識圖譜:美團大腦。
美團所涉足的生活服務領域需要大量知識。例如,當用戶搜索“10人聚餐”的query時,我們需要對它結合知識進行理解,得到用戶想找大桌或者找包間的意圖。同時,對於商家側,我們也需要利用UGC評論中挖掘出類似於“有大桌”、“有包間”這樣的標簽。基於知識的理解和匹配,我們可以把滿足需求的商家推薦給用戶,當用戶點擊進入商家詳情頁時,有別於之前用戶需要逐條查看海量評論,費時費力,我們從UGC中挖掘出細粒度的情感標簽,把大部分用戶關心的細粒度特征顯式地展示出來,從而節省用戶的時間,提升用戶體驗。

因為生活服務領域需要大量的知識,美團NLP中心從2018年開始就著手構建了生活娛樂領域超大規模的知識圖譜——美團大腦。我們從餐飲圖譜開始,後來逐漸擴展至標簽圖譜、場景圖譜、商品圖譜、到綜圖譜等。
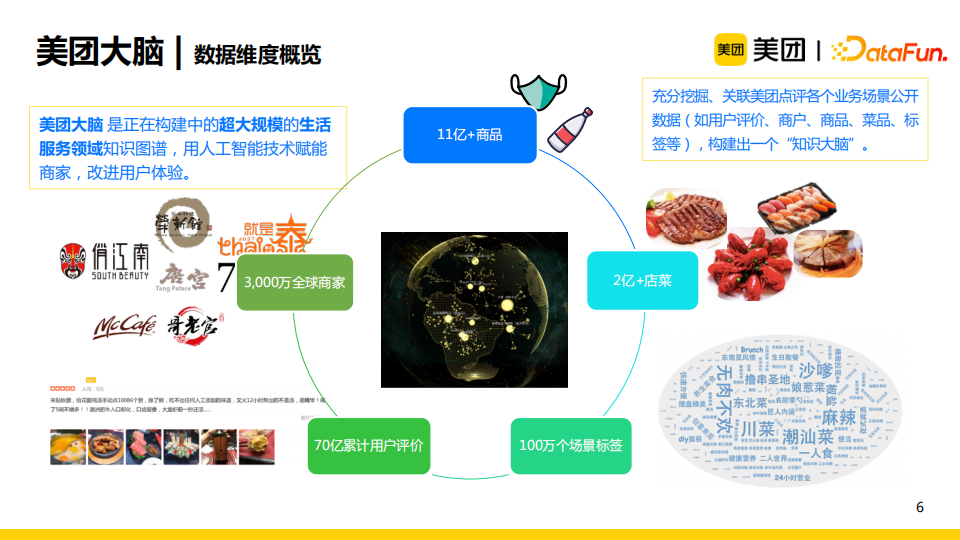
美團大腦目前是正在構建中的超大規模的生活服務領域知識圖譜,其主要的主體類型是商家(千萬級)、商品(十億級)、店菜(億級)、海量的用戶評價(70億量級)以及從評價中挖掘出的場景標簽(百萬級)。
--
02 美團推薦場景介紹
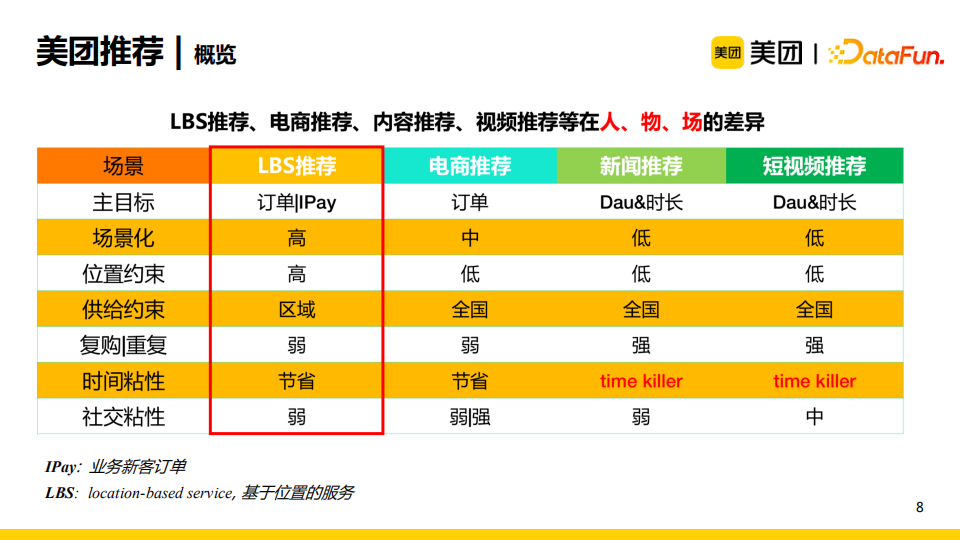
美團推薦屬於LBS(基於位置的服務)推薦,它與電商推薦、新聞推薦、視頻推薦等存在很大差異。LBS推薦中位置約束以及場景化的要求很高,供給約束是區域型的,其主目標是訂單或者IPay(業務新客訂單)而非Dau或者時長。此外,LBS推薦的社交粘性較弱。
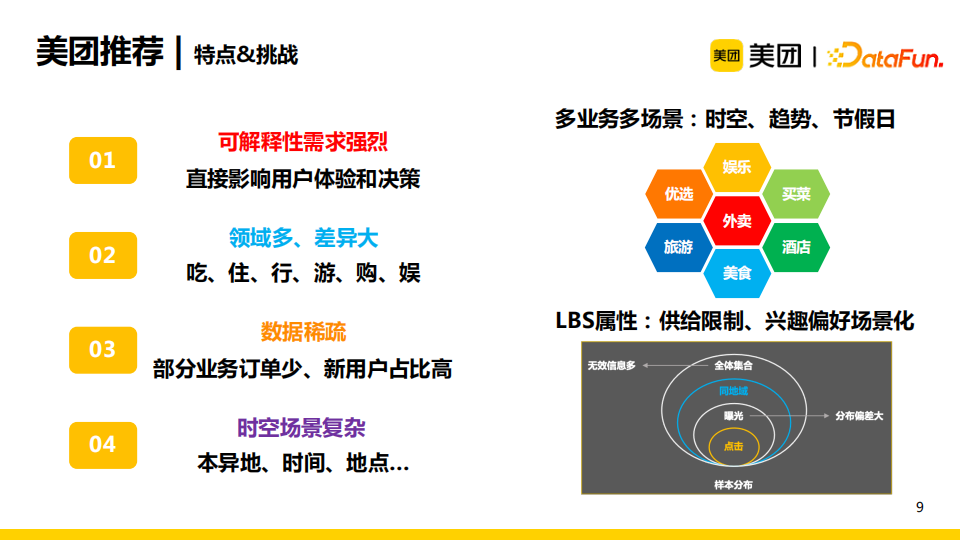
美團推薦存在著以下四點挑戰:
- 可解釋性需求強烈:可解釋性可以直接影響用戶的體驗和決策,從而促進交易,達成美團的業務目標;
- 美團涉及的領域多、差異大:領域包含了吃、住、行、游、購、娛等;
- 數據稀疏:除了到餐外賣等高頻業務外,大部分業務的訂單相對較少,且新用戶的占比偏高;
- 時空場景複雜:我們需要考慮到本異地、時間、地點等因素。一個典型的本異地的場景例子是一個用戶在出差前需要查看目的地酒店。有關時間因素的例子如一個用戶在早上喜歡吃豆漿油條,中午就喜歡吃正餐。又如一個用戶在家和在公司喜歡點的外賣不一樣,這就是一個考慮地點因素的例子。
--
03 美團推薦中的知識應用
1. 可解釋性需求強烈
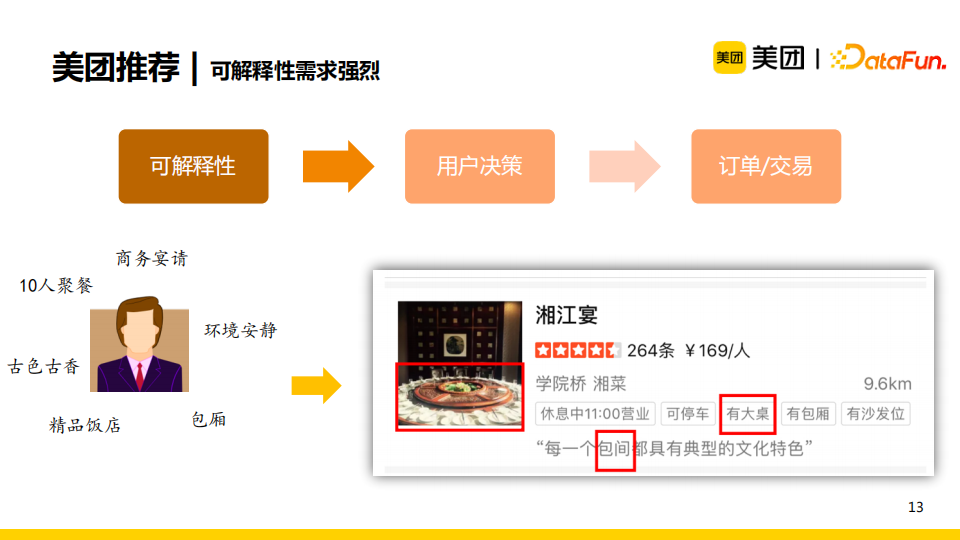
比如對於一個商務人士,他的搜索需求是“商務宴請”,若我們僅僅直接向他推薦“湘江宴”與標簽“湘菜”,那麼他無法得知商家是否能滿足自己的宴請需求。如果我們將商家的“有大桌”,“包間”等知識信息展示給他時,那麼他就可以輕鬆地判斷出推薦的商家可以滿足自己的需求。
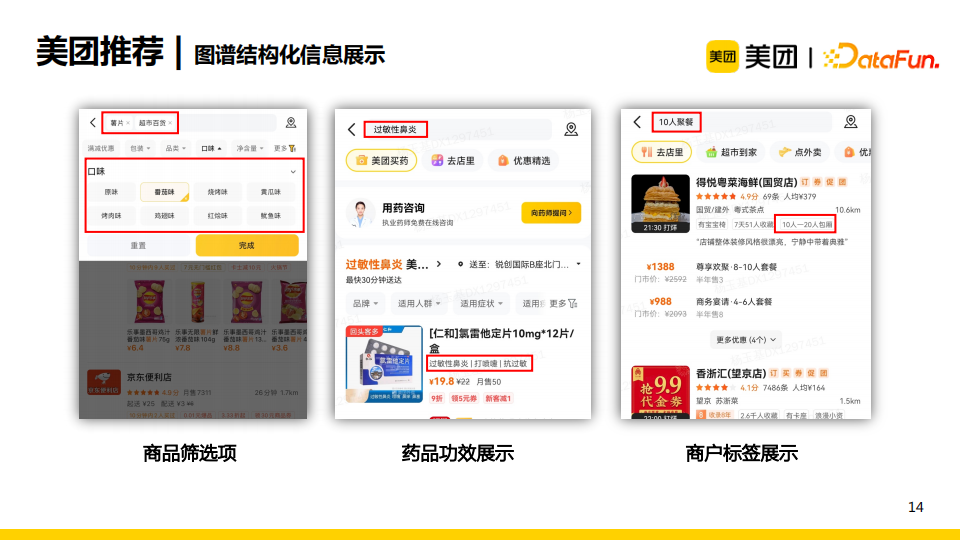
因此,知識圖譜最典型的應用是結構化信息展示。例如,我們可以從藥品的說明書中挖掘出藥品的功效來展示給消費者;我們可以將知識圖譜利用在商品篩選項中,如用戶搜索薯片時向其展示按口味區分的篩選項,從而使他能夠快速地選擇符合口味的薯片進行購買。
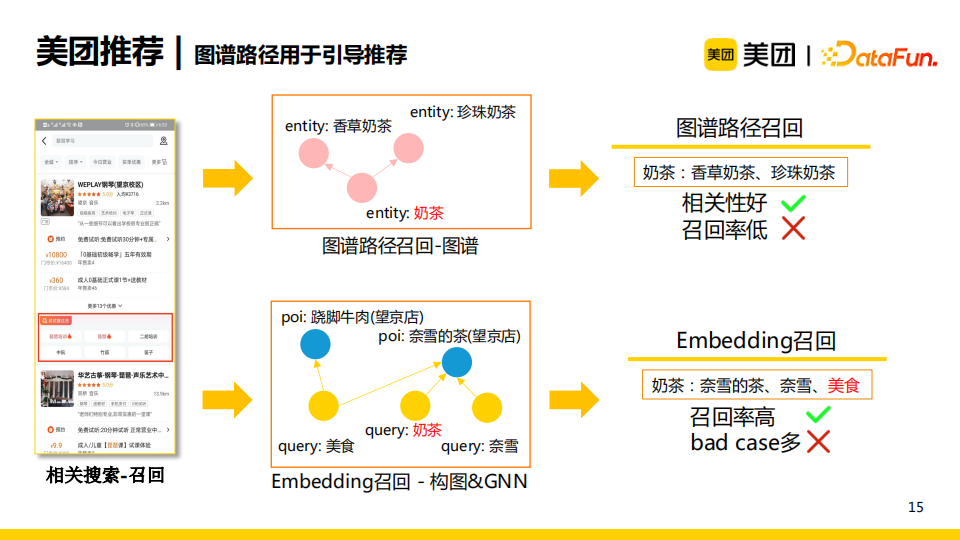
除了利用知識圖譜來向用戶進行結構化信息展示之外,我們還利用圖譜路徑來引導推薦。如相關搜索-召回的業務場景,當一個用戶輸入一個query以後下滑了很久都沒有進行點擊,那麼我們就會為其推薦一部分更好的query。一個簡單的做法就是直接使用知識圖譜路徑召回,將query對應的實體在圖譜中有連接的下位實體推薦給用戶,如“奶茶”對應的“珍珠奶茶”、“香草奶茶”等。這一方法的優點在於其召回的相關性較好,這得益於知識圖譜的質量很高,缺點是召回率低,因為用戶的query含有雜訊信息,而知識圖譜的實體較為純凈。在實際業務中,我們更常用的做法是利用embedding進行召回,具體做法是將用戶歷史query以及點擊poi進行構圖,之後使用GNN模型來訓練embedding。當用戶輸入一個query時,我們在訓練好的向量空間中搜索query向量的近鄰向量作為候選召回。這一做法的優點是召回率高,但是召回的bad case較多,且即便embedding的質量非常高也無法避免bad case的出現。
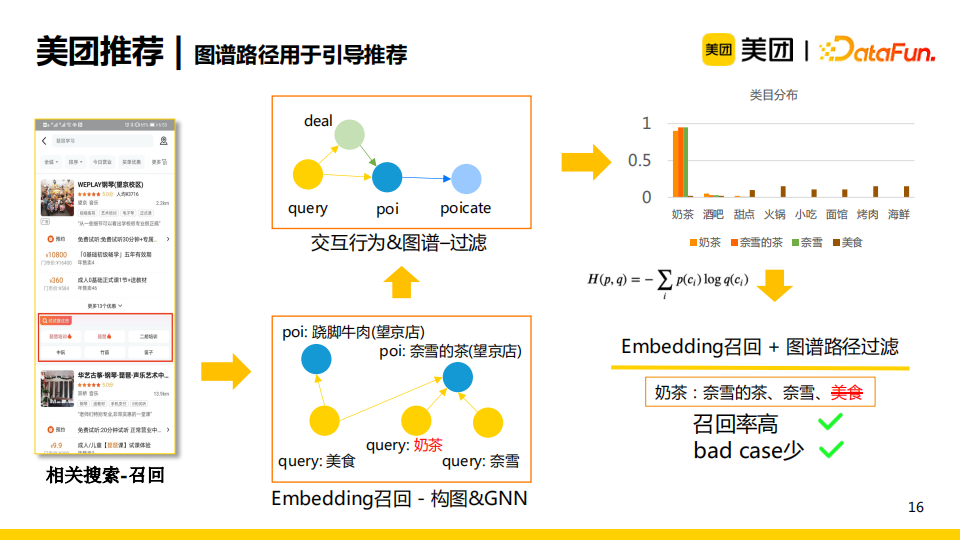
美團在業務中會首先使用embedding召回的方法生成一系列候選召回集合。隨後,我們使用用戶交互行為與知識圖譜來進行構圖。如上圖所示,query與poi、query與deal(商家的團單)是點擊關係,這部分來源於點擊行為;deal屬於poi,且每個poi都從屬於一個類目,這部分信息來源於知識圖譜。我們通過兩部分信息的結合構成一系列路徑,可以通過每一條路徑來計算query屬於哪一類poi類目的得分,其對應於query對應的類目分佈。通過計算交叉熵,將不符合要求的候選召回過濾掉,從而實現在召回率高的同時減少bad case。
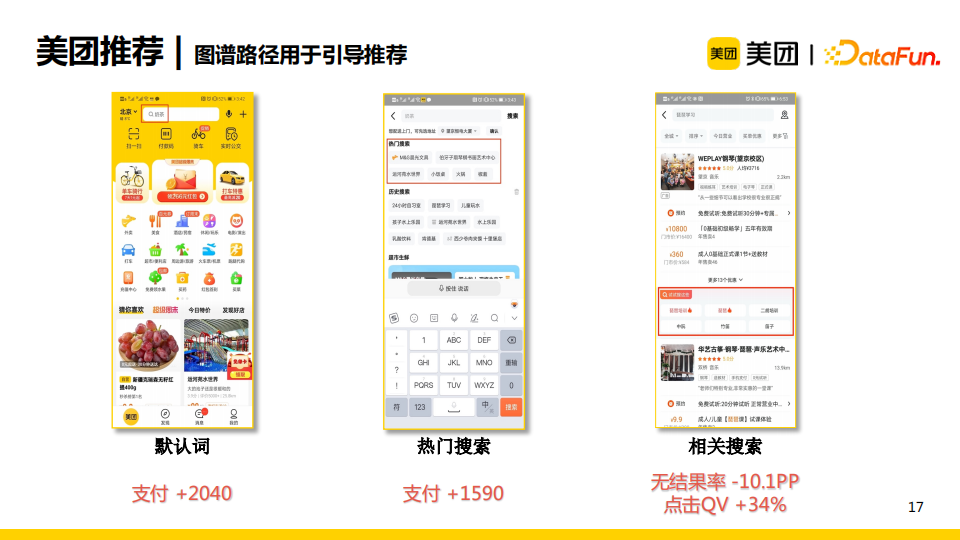
基於上述embedding召回+圖譜路徑過濾的方法,美團推薦的預設詞模塊、熱門搜索模塊、相關搜索模塊都得到顯著的業務指標的提升,尤其是相關搜索模塊,無結果率下降了10個百分點,點擊QV提升了34%。
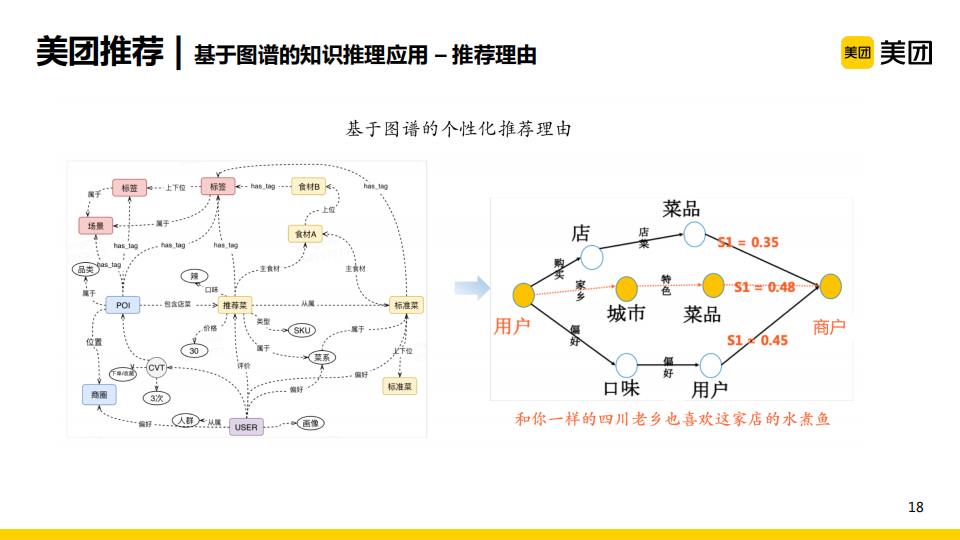
我們還基於圖譜的知識推理來生成推薦理由。以上圖為例,左側是知識圖譜,可以通過它來學習每個用戶到每個商戶的路徑分。比如學習到用戶的家鄉屬於某一個城市,以及這個城市的特色菜品,同時這個菜品又隸屬於某個商戶,若此時這一路徑在當前用戶對當前商戶的所有路徑中得分最高,就可以按照這條路徑生成推薦理由,如“和你一樣的四川老鄉也喜歡這家店的水煮魚”。可以看出,這一方法生成的推薦理由是十分個性化的,且其吸引力較強。
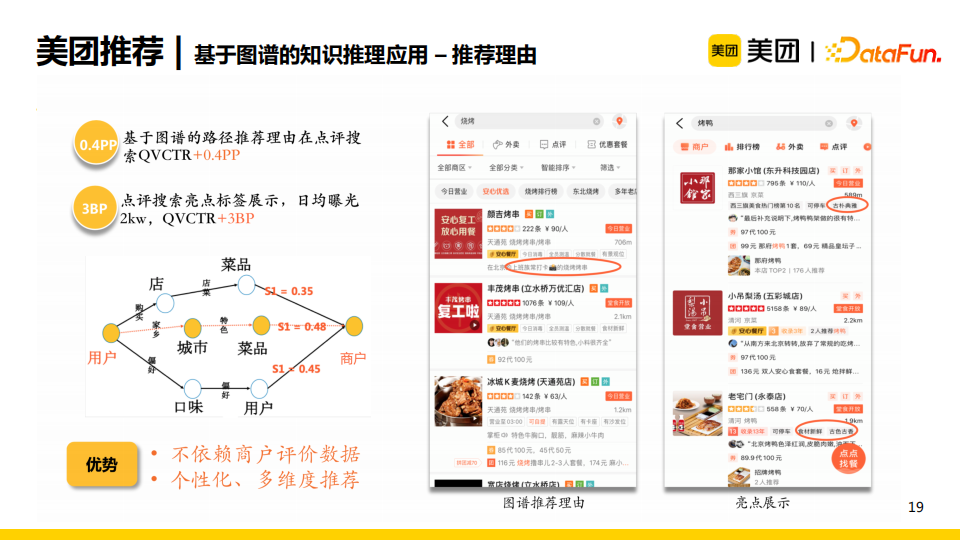
基於圖譜的推薦理由生成線上上也取得了很好的收益。與從UGC中挖掘的推薦理由相比,這一方法有兩個優勢。
首先,這一方法不依賴商戶評價數據,這對新店較為友好,我們可以使用用戶交互行為和知識圖譜來為用戶提供個性化推薦理由。
第二,由於生成的路徑很靈活,我們可以輕鬆地為用戶從個性化與多維度的角度生成推薦理由。
2. 領域多、差異大

在美團推薦的場景下,我們需要為用戶同時推薦多個領域的內容。例如點評內容推薦,我們需要為用戶推薦的領域包括寵物、露營、旅游、運動、親子、美食、野生動物等。傳統模型使用一個向量表徵用戶,其對用戶多興趣的建模比較粗糙。最近有一些多興趣模型的工作,使用多個向量表徵用戶,對用戶的興趣建模更加精細。

已有的工作使用用戶item序列id作為輸入,使用諸如多通道或者動態路由的結構來輸出用戶多個興趣向量,但存在兩個問題。首先,它們都以item為最小粒度,忽視了item蘊含的豐富語義信息,興趣建模不精細。其次,這些模型的可解釋性不強,它們無法回答用戶的興趣具體是什麼以及item所從屬的興趣是什麼。
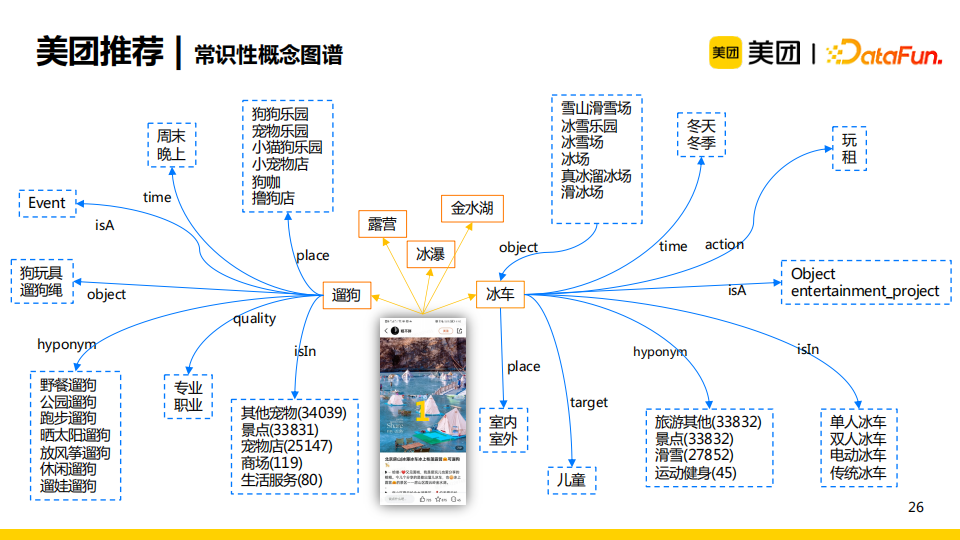
在美團推薦場景中,我們使用海量數據構建了基於常識的概念圖譜。圖譜中包含了事實、事件,它們都包含了具體的語義信息,如遛狗這一事件發生在周末晚上,地點在狗咖或者擼狗店等,需要使用到狗玩具、遛狗繩等。

我們想將概念圖譜加入多興趣建模中,使得興趣建模更加精細。如上圖所示,第一個點評內容包含了圖譜中多個實體,每個實體都對應於多個興趣集合。我們想要建模的可解釋性更強,這就對應了三個目標:
- items需要有一個整體的興趣集合
- 每個item對應一個興趣分佈
- 每個user對應一個興趣分佈
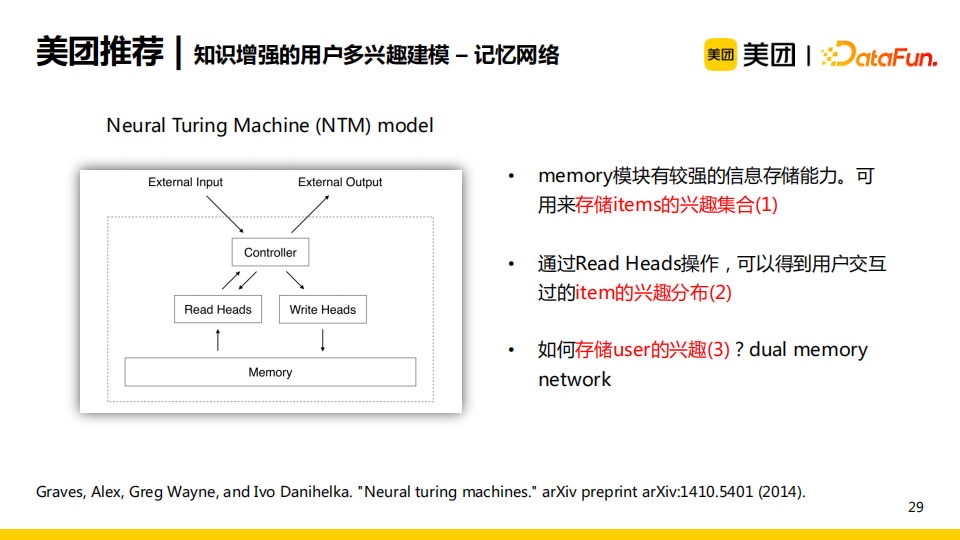
為了實現上述可解釋性的目標,我們採用了基於神經圖靈機(Neural Turing Machine,NTM)的記憶網路結構。NTM中的memory模塊具有存儲信息的能力,控制器controller用於控制讀寫操作。NTM的好處在於可以使用memory模塊存儲items的興趣集合,實現了上述第一個目標;通過read操作,NTM可以得到用戶交互的item的興趣分佈,實現了前述第二個目標。但是,原始的NTM無法存儲user的興趣,於是我們提出了基於雙重記憶力模塊的NTM。
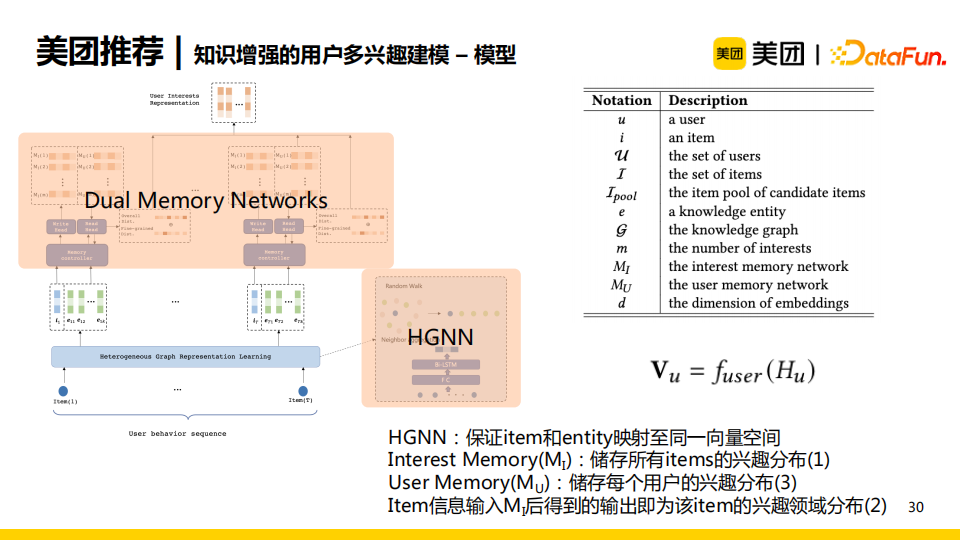
模型的輸入是用戶對應的item序列,包含點擊序列以及點擊的item多關聯的entity。
首先,輸入序列會通過異質圖神經網路模型(HGNN),將item與entity在統一的向量空間中進行建模。
之後,item和entity向量會輸入至雙重記憶網路(Dual Memory Networks),通過讀寫操作更新MI(儲存item的興趣分佈)和MU(儲存user的興趣分佈)。我們可以通過目標item,使用讀操作得到對應的興趣分佈。
最後,我們使用聚合操作可以得到用戶的興趣分佈。通過這一網路結構,可以滿足提出的三個目標。
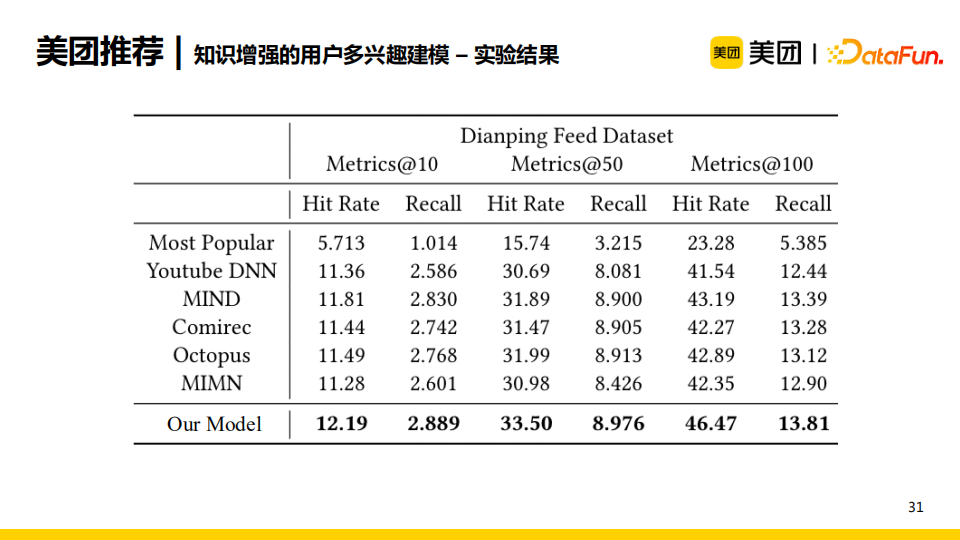
我們使用上述網路架構在點評業務上進行了對比實驗。實驗結果發現與單興趣模型與已有的多興趣模型相比,我們的模型在所有指標上都有不同程度的提升。
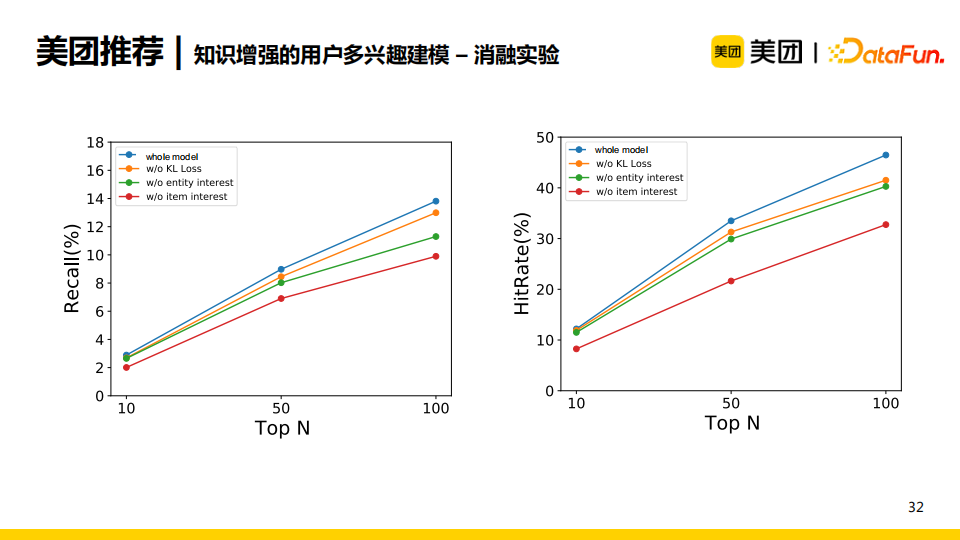
我們也進行了一些消融實驗。當我們將網路結構中item memory去除後,模型效果下降得最明顯;當我們將user interest去除後,模型效果也有所下降。為了保證item與對應的entity所學習到的分佈的一致性,我們加入了KL散度損失函數進行約束。如果去除這一限制,模型效果也略有下降。消融實驗有力地證明瞭雙重記憶網路的有效性。
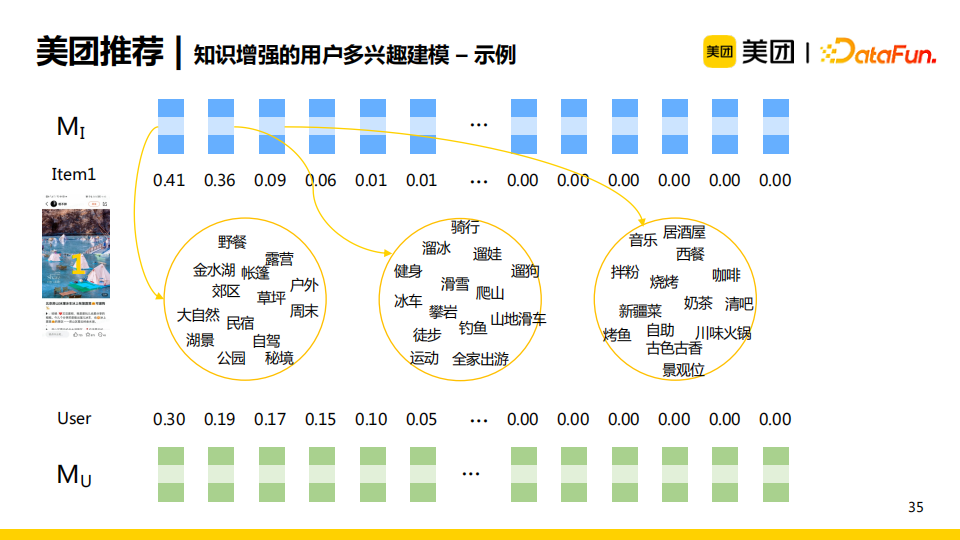
模型訓練完成後MI可以被看作一系列“槽”,對應了每一個領域的興趣。每個“槽”中存儲了一些實體,那麼所有item有一個整體的興趣集合。當一個item輸入記憶網路時,我們可以使用網路中的讀操作得到item對應的興趣分佈。類似地,user也可以得到對應的興趣分佈。
3. 數據稀疏
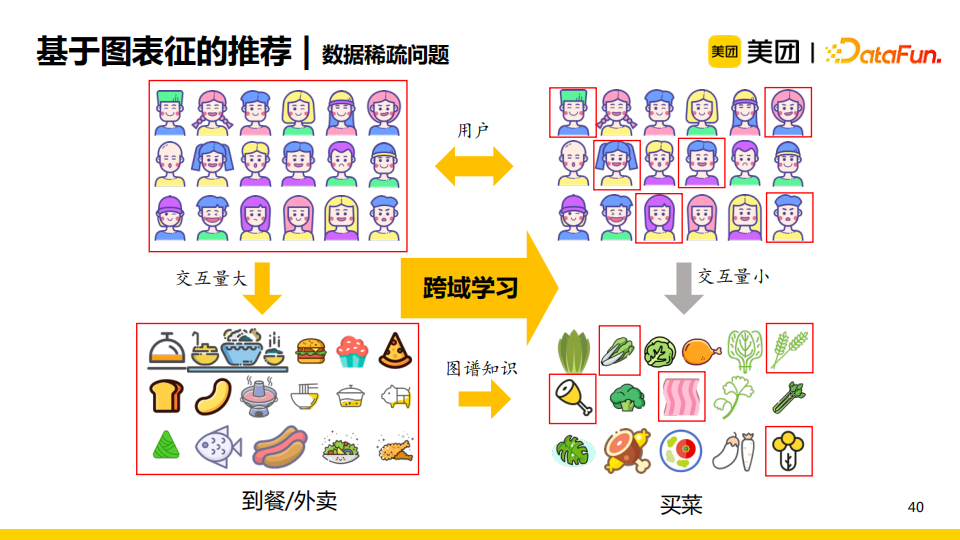
在美團的業務中,到餐/外賣這一業務交互量較大,但是如買菜業務的交互量就較小,只有部分用戶與部分item進行交互。美團擁有豐富的圖譜知識,我們發現買菜業務中的菜品其實與到餐/外賣業務中的菜品有一定關係。基於這一事實,我們考慮使用知識圖譜與交互量較大的業務領域,使用跨域學習的方法來增強數據稀疏領域的業務效果。
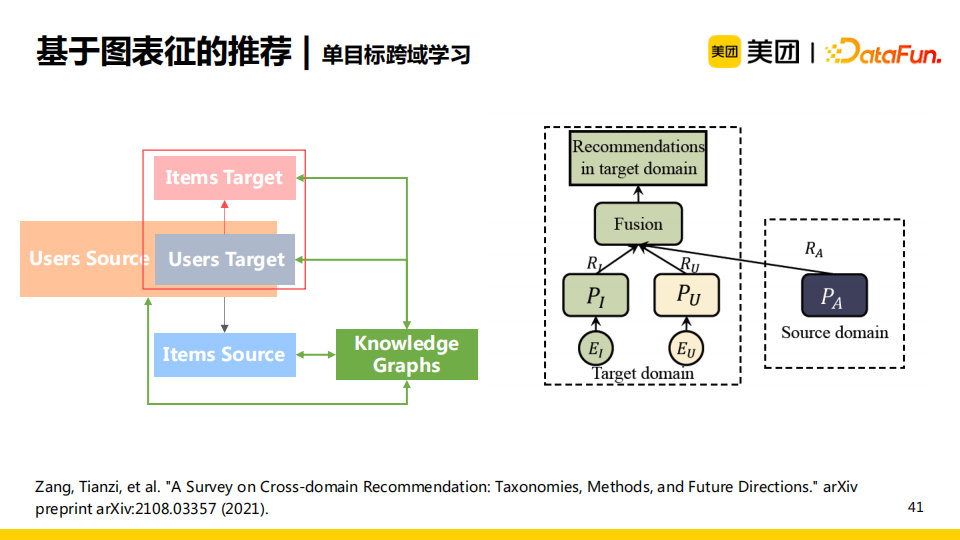
我們採用的是單目標的跨域學習,即只關註目標域中user和item的推薦效果。源域中的user、item以及知識圖譜都作為網路的輸入。這一方法的重點在於如何更好地將源域中的信息以及知識圖譜中的信息融入目標域的向量表達中。
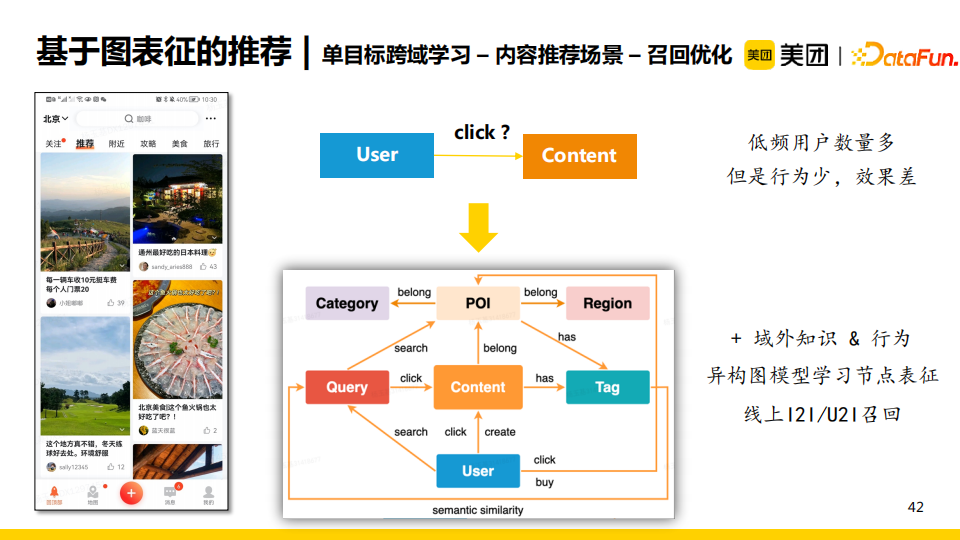
比如內容推薦場景包含的低頻用戶數量較多,他們的點擊行為少,導致推薦效果較差。我們的解決方案是加入域外的知識圖譜以及域外的交互行為。例如,用戶在域外的點擊、搜索行為,點擊的poi在知識圖譜中包含的知識(如屬於的類目、商圈、標簽等)都可以被用來構建一張更大的異構圖,進而在這張圖上學習節點表徵。最後,我們線上上使用增強後的表徵進行I2I/U2I的召回。
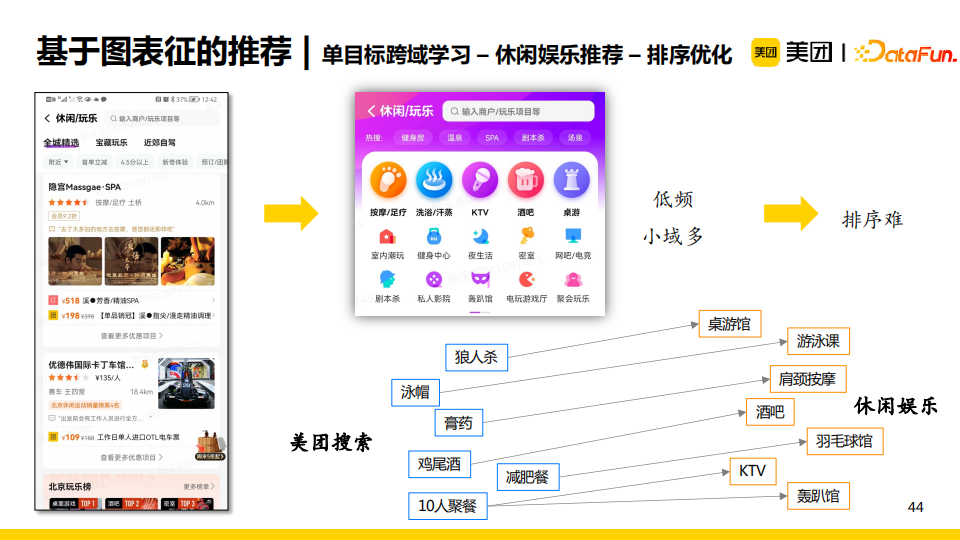
休閑娛樂推薦領域也屬於低頻的場景。不僅如此,該領域內還包含了很多小域,如按摩/足療、洗浴/汗蒸、KTV等。這更加重了小域中的數據稀疏問題,導致針對眾多小域中的item進行整體排序十分困難。這時,我們發現在“美團搜索”這個大域中很多實體或者搜索query可以對應於休閑娛樂小域中的實體或者用戶意向,例如用戶搜索“狼人殺”時隱含了桌游的意向,那麼在休閑娛樂域我們就可以給他推薦“桌游館”。
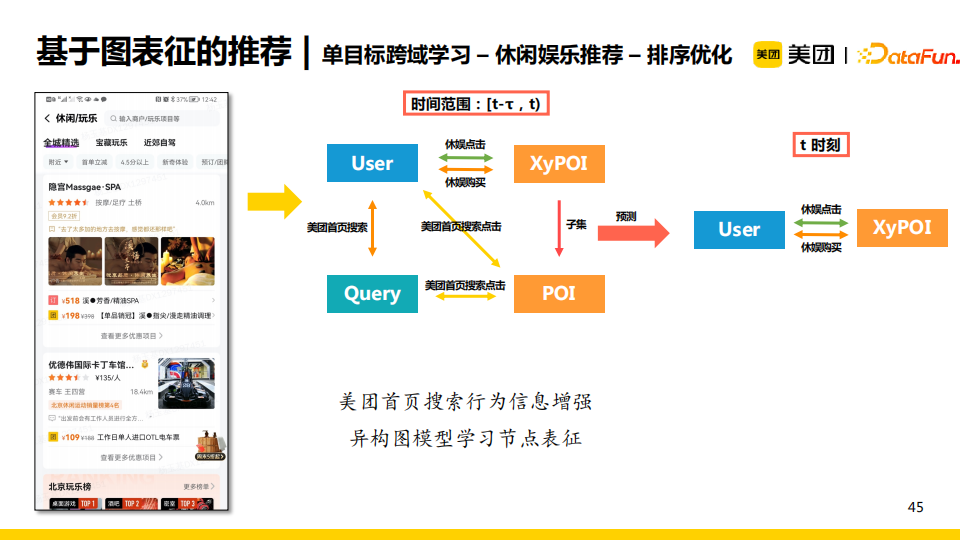
所以,我們考慮使用美團首頁搜索行為與休閑娛樂領域的行為構建一張異構圖,使得我們可以利用美團首頁搜索行為信息增強休閑娛樂領域的節點表徵。更具體地,我們認為首頁搜索行為僅在一個時間間隔內(過去一周或者過去一個月)對目標域有效,所以我們採用了基於時序的採樣和聚合。最終實驗結果顯示,在原有模型中增加了跨域學習後,在點擊ndcg的指標上提升了26BP。
04 總結與展望
知識圖譜在美團推薦中是一個十分重要的信息輸入源。知識圖譜的應用可以分為顯式應用和隱式應用。顯式應用是指直接將知識圖譜應用於推薦中的展示引導和結構召回(如知識展示、路徑召回、圖譜推薦理由),解決了可解釋需求強烈的問題。隱式應用是指將知識圖譜通過表徵更容易、更廣泛地嵌入下游任務。它可以通過引入概念性常識圖譜解決用戶多興趣建模中領域差異大的問題,還可以通過知識跨域增強改善目標域的數據稀疏問題。
之後我們會在兩個方向上繼續探索知識圖譜在推薦中的應用。首先,我們會繼續聚焦於通用推薦場景建模,如繼續優化用戶多興趣、引入物品多模態、對用戶與物品交互行為進一步探索場景時空性等。其次,針對很多業務中面臨的數據稀疏問題,我們會著重探索推薦公平性、跨域學習以及圖預訓練。
--
05 精彩問答
Q1:知識圖譜在圖譜路徑引導推薦中召回階段和排序階段是不是使用一個演算法模型?還是一個模型將兩個階段的任務全部完成了?
A:首先,我們在做圖譜路徑引導推薦時,召回階段使用的是GNN模型,如同質圖模型GraphSage或者異質圖模型R-GAT、R-GCN等。圖譜其實在召回中的作用是對召回候選集進行過濾,去掉不太相關的bad case。其次,在一般工業級應用中,不會在召回層和排序層使用同一個模型,這可以讓不同業務的同學分開優化各自負責的部分。
Q2:圖譜路徑到推薦理由的轉化是人工適配還是機器自動完成?
A:目前我們會通過人工提前確定一些模板。模型利用知識圖譜得到路徑分最高的路徑後去填充模板中對應的槽。在工業級的產品中,因為基於模型的文本生成演算法出現bad case的概率較高且不太可控,影響用戶體驗,實際業務場景中會比較慎重地使用。
Q3:雙重記憶網路線上上使用性能如何?
A:雙重記憶網路主要用於用戶多興趣建模的召回場景。我們目前的使用方式是t+1調度更新,定期離線訓練模型得到模型參數和item向量,每天infer得到user向量。線上使用時,我們直接使用得到的向量作為user和item的興趣向量表徵,在向量空間中通過ANN演算法索引,性能不是問題。
今天的分享就到這裡,謝謝大家。
閱讀更多技術乾貨文章,請關註微信公眾號“DataFunTalk”。


