
**導讀:**京東智能商客之推薦賣點是基於NLP的產品,目前已廣泛地助力和賦能於京東商城的各個平臺。今天和大家分享一下自然語言處理如何在工業界落地實現。主要圍繞以下5個方面展開: 推薦賣點技術背景 架構描述 核心AI技術 模型研發與實踐 產品的落地與回報 -- 01 推薦賣點技術背景 1. 什麼是推 ...

導讀:京東智能商客之推薦賣點是基於NLP的產品,目前已廣泛地助力和賦能於京東商城的各個平臺。今天和大家分享一下自然語言處理如何在工業界落地實現。主要圍繞以下5個方面展開:
- 推薦賣點技術背景
- 架構描述
- 核心AI技術
- 模型研發與實踐
- 產品的落地與回報
--
01 推薦賣點技術背景
1. 什麼是推薦賣點,用推薦賣點能做什麼事情?

如何提升推薦系統的可解釋性?京東智能推薦賣點技術全解析
推薦賣點是一種商品文案,或者稱之為對商品的描述。商品文案,即電商平臺中線上利用文字來描述商品的特征、特色點、詳細信息,以輔助商家吸引顧客、促進商品銷售,豐富商品的推薦理由。
商品文案有多種類型,不同類型的商品文案有著不同的功能,主要包括長文案(商品標題和商品描述),短文案(賣點)。
商品標題是一種綜合性描述信息的文字,在有限的字數內,信息完整且客觀地闡述商品,例如描述商品的品牌、是什麼物品、主要功能等。
商品描述類似於商品廣告,可圍繞某些特色點進行宣傳,引導用戶購買該商品。
商品賣點的目標是突出商品的特色,通常在8個字以內,用於豐富商品推薦理由。
傳統的商品文案多是由人工撰寫,費時費力,撰寫速度也很難跟上新商品的迭代速度。隨著自然語言處理飛速地迭代和發展,尤其是深度語言生成模型,通過商品文案自動化生成技術,可以幫助商鋪的店家以又快又省的方式進行商品宣傳。
2. 目前常用的文案生產技術
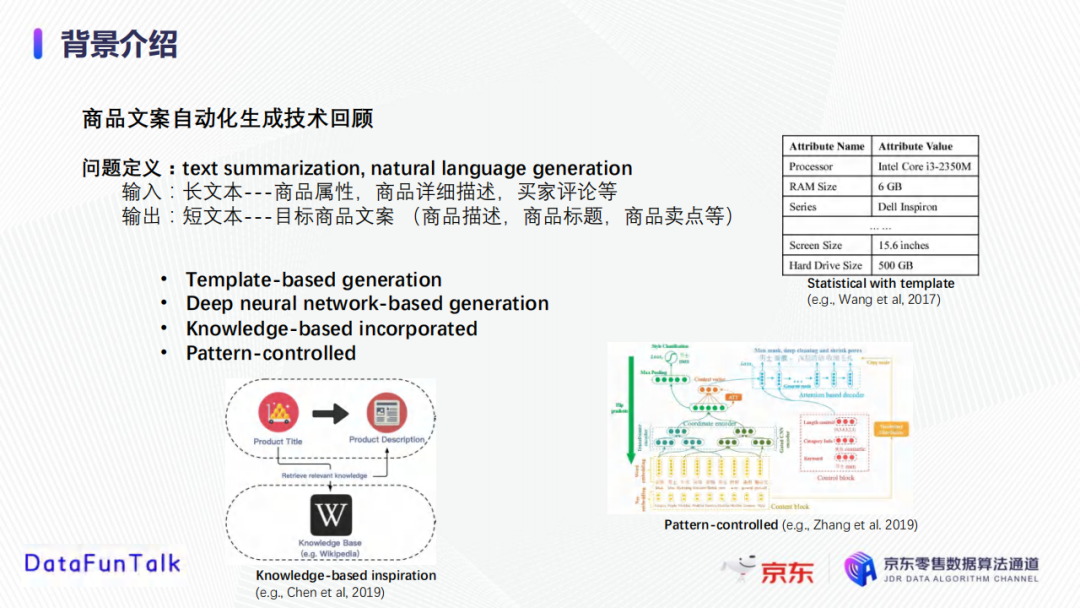
商品文案自動寫作屬於自然語言處理領域中text summarization或者natural language generation的問題。
輸入是長文本形式,包括商品屬性、商品詳細描述、買家評論等,輸出是目標商品文案,包括商品描述、商品標題、商品賣點等。
目前有以下幾種文案生成模型的方法,如Template-based generation、Deep neural network-based generation、Knowledge-based incorporate、Pattern-controlled等。
- Template-based generation:一種較為傳統的方式,需要預先定義某類別商品的屬性,然後進行商品的屬性值提取,最後基於提取的商品屬性做文案生成;
- Deep neural network-based generation:隨著深度學習的出現,開始使用深度生成模型做自然語言的生成,大多依靠的是典型的編碼器和解碼器結構,基於transformer等特征處理技術;
- Knowledge-based incorporate:引入知識圖譜和知識庫等技術使生成的文案信息鏈更全,即使輸入的信息不夠完整,也可進行知識整合;
- Pattern-controlled:該種方式能夠控制生成文案的過程,比如可以控制生成的主題、重點、語言風格,以及文案長度等。
以上這幾種方式主要針對長文本文案生成,目前還沒有針對賣點短文案的生成技術。
3. 推薦賣點價值

賣點文案生成的核心是服務於推薦系統,可增加推薦系統的可解釋性,向用戶展示推薦理由;結合用戶喜好進行個性化推薦,從而傳達準確信息供用戶決策;向用戶展示特色優勢如服務和優惠等信息,可以提升用戶的滿意度,促進點擊行為,同時增加用戶對平臺的信任度以及延長停留時間。
4. 賣點短文案自動生成技術

通過賣點自動化生成技術,避免人工文案寫作,節約了時間成本;同時,賣點短文案不需要複雜的文學表達,比較適合採用自動化文案生成的方式。為了生成高質量的賣點文案,需要做到以下幾點:
- 能夠捕捉到內容的特色點,足夠吸睛;
- 文案長度有限,需要簡短精巧,但包含重要信息;
- 能夠實現個性化分發,針對不同的目標用戶展示不同的推薦理由。
--
02 架構描述
接下來通過介紹推薦賣點在推薦系統中的架構設計來介紹賣點如何與推薦系統結合發揮作用。
首先是當請求被初始化時,混合模塊(SOA)會觸發前端(Broadway)收集用戶信息、商品信息等數據;基於收集到的客戶資料,Index模塊作為Broadway和後端推薦的中轉站,將信息提供給推薦模塊;AI-flow是推薦模塊,執行召回和排序,以獲取推薦候選產品,根據產品的庫存和受歡迎程度進行篩選,最後確定要推薦的產品同時將請求發送給賣點模塊,進行賣點的提取和個性化分發。
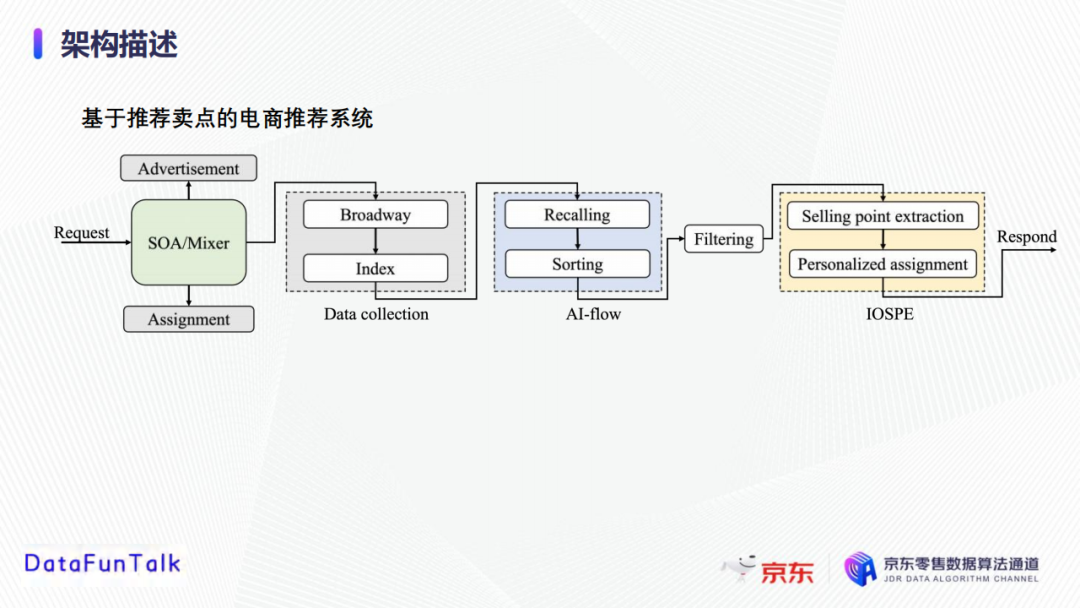
- SOA/Mixer:協調廣告、推薦和分配應用的混合模塊/平臺。所有請求最初都發送到這個混合模塊,然後分配給每個應用程式。
- Broadway:推薦系統的前端。收集客戶的資料信息和購買歷史,以及產品信息(包括屬性、評論、描述、和圖像等),這些數據被髮送到索引模塊。
- Index:作為broadway和後端推薦部分的中轉站。Index準備好來自broadway的輸入數據並轉發給推薦模塊,並從AI-flow和filtering模塊接收推薦產品及賣點。
- AI-flow(召回):推薦模塊中負責召回特征的關鍵組件。這裡用到的特征都是離線提取出來的,召回是AI-flow的第一步,它根據用戶和產品特征從海量庫存中檢索出少量可能感興趣的物品,然後將他們傳遞給排序模塊。
- AI-flow(排序):這裡我們採用非線性和線性的排序方法。GBDT用於非線性排序,可以更好地從特征中捕捉非線性模式,邏輯回歸用於線性特征排序;為了更好地捕捉動態數據分佈,我們實施一種基於FTRL(McMahan2011)的線上學習策略來處理線上數據流。
- Intelligent Online Product Selling Point Extraction (IOPSE) :用於產生賣點以支持產品推薦。具體來說,給定一個推薦商品,從賣點池中提取幾個優質的賣點,然後根據目標客戶的個人資料,通過個性化分配演算法選擇最適合的賣點,然後將客戶ID、產品推薦和賣點發送回前端進行展示。
--
03 核心AI技術
1. 智能賣點創作的技術流程
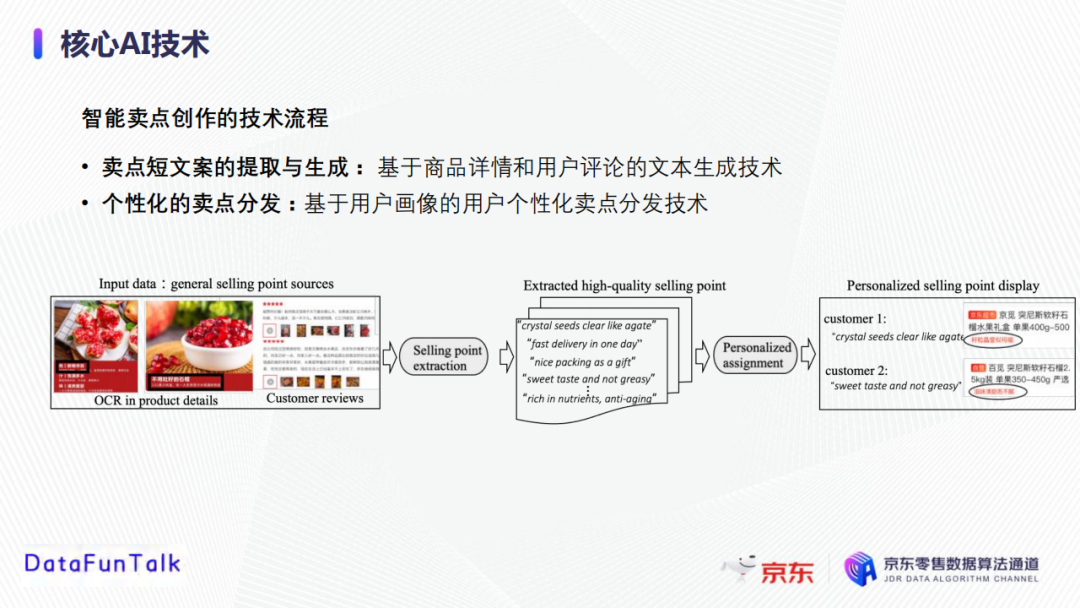
整個智能賣點創作模塊分為兩個部分:
賣點短文案的提取和生成,採用基於商品詳情和用戶評論的文本生成技術;
個性化賣點分發,採用基於用戶畫像的用戶個性化賣點分發技術。
以石榴這個商品為例,首先獲取賣點素材,比如石榴的屬性表,商品標題,以及採用OCR文字識別技術從商品詳情圖片中提取的文字,買家的正向評論等;然後將獲取的賣點素材輸入到賣點提取和生產模塊中,生成針對一個商品的多個優質賣點;在個性化分配模塊中,結合客戶興趣給不同的用戶進行不同的推薦賣點展示。
2. 賣點短文案的提取和生成
賣點短文案的提取和生成,主要包括賣點粗篩、賣點生成、賣點精篩這三個步驟。
① 賣點粗篩
目標是從商品文案素材庫里(商詳頁OCR,用戶評論,達人文案等)提取初始賣點候選,主要基於self-adversarialBERT對文案素材(句子或者短語)進行打分,然後根據打分排序並選擇top-K作為賣點生成素材,大範圍地過濾掉與商品無實質性意義的短語或者句子。
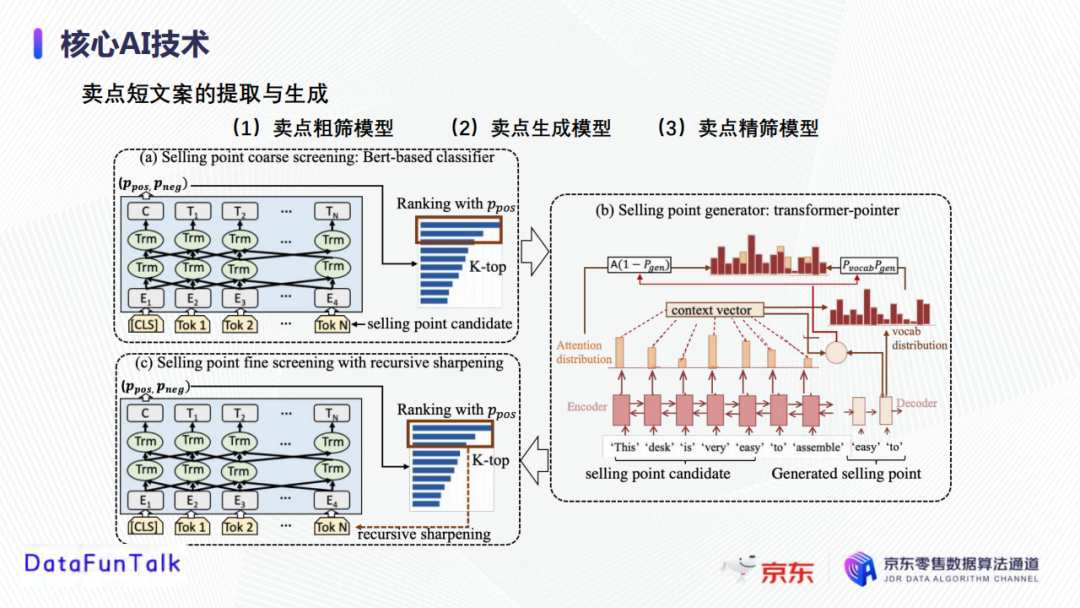
在素材文案評分中,將人工寫作的賣點(達人文案)定義為正樣本,將用戶評論或者商詳頁OCR等作為負樣本,使用自對抗的BERT模型做分類訓練。在實踐的過程中,當句子輸入模型之後,獲取Bert模型的softmax層輸出概率,表示該句子被分到高質量的概率,根據句子的概率進行排序。這裡簡單介紹一下Bert模型。它是基於Transformer的雙向預訓練語言模型,在預訓練階段有Mask語言模型和預測句子關係兩個任務,在此基礎上進行finetune從而完成文本相似度計算、文本分類、序列標註、問答類問題等。文本輸入表徵包括了語義表徵、segment表徵(分割信息表徵)、位置表徵;最後將softmax層輸出作為該文案的質量評分:
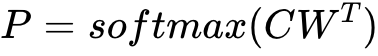

② 賣點生成
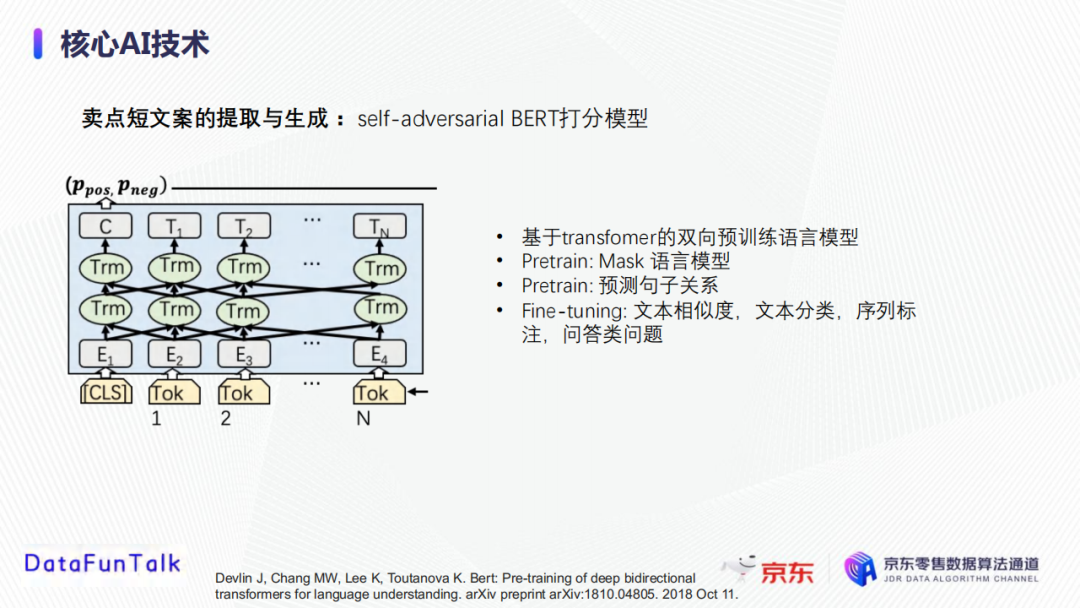
由於粗篩中選出的文案素材口語化、不簡練,因此我們接下來依據Transformer和Pointer generator的文本生成模型基於已經篩選出的文案素材庫進行賣點文案生成。
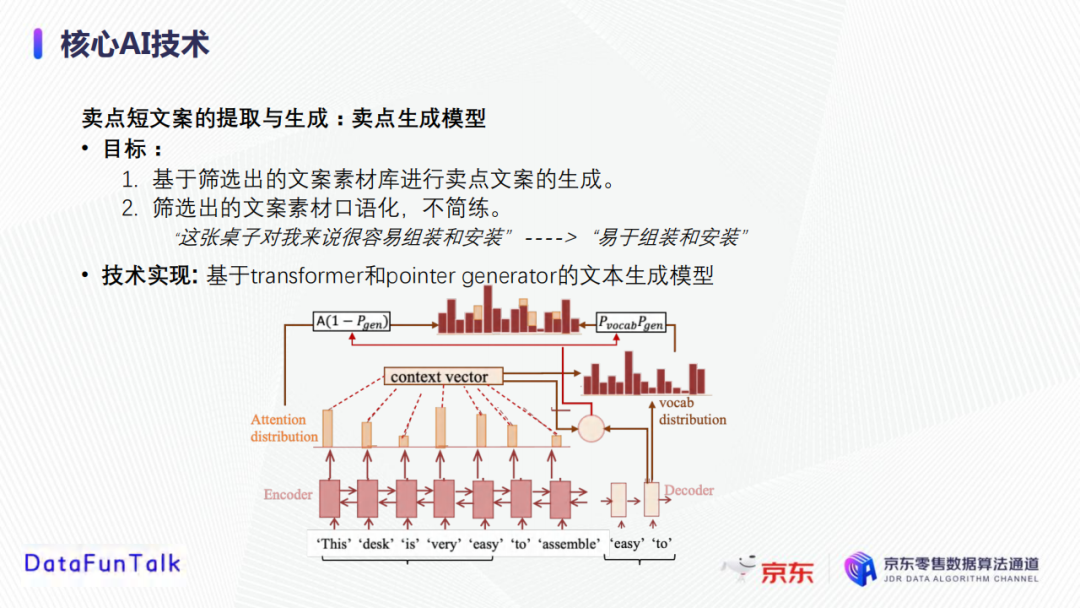
Transformer是用於學習輸入文本的表徵向量,它的重要組成部分包括自註意力機制(multi-head self-attention)和位置編碼(positional embedding)。自註意力機制本質上會對句子中的每個字構建全連接的圖,通過計算attention學習每個字的表徵向量,考慮到句子中所有的字對該字的影響。位置表徵中,每一個位置點都有一個編碼,是一個周期函數。
將上一步獲取到表徵進行Decoder生成賣點文案。Pointer generator與其他的語言生產模型的區別在於,其不僅可以從詞庫挑選要學習到的字,還可以從輸入的句子中挑選字。首先分別計算從詞庫中選擇字和從輸入中選擇字的概率,然後再將詞庫中的概率分佈和輸入中的概率分佈結合獲得最終的概率分佈。
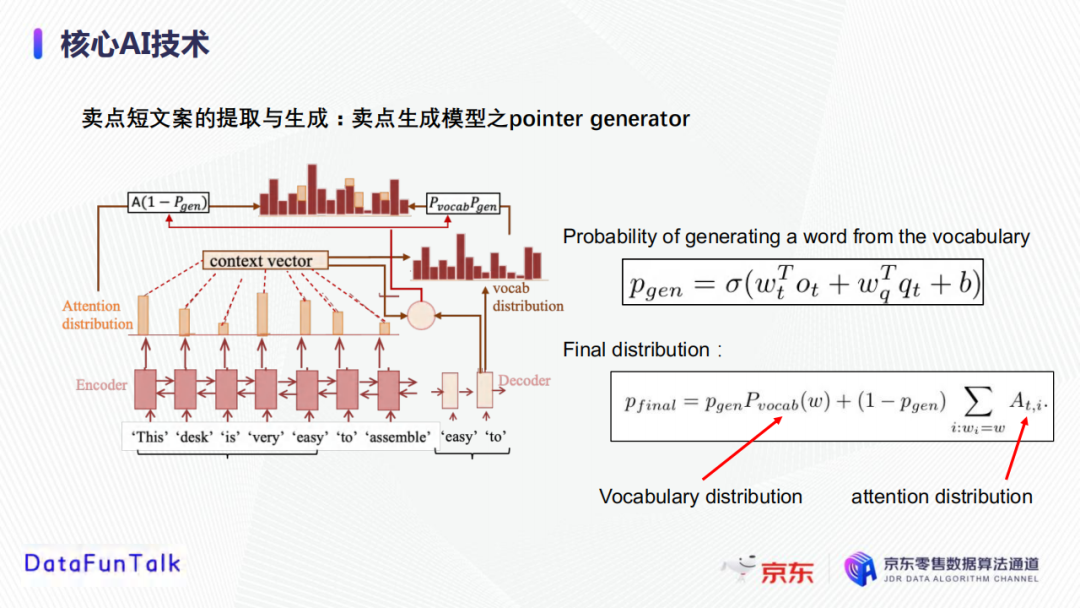
③賣點精篩
賣點精篩模型區別於粗篩模型,將生成後的賣點文案,輸入到一種遞歸銳化的BERT模型中進行訓練。具體來說,首先將達人賣點寫作當做正樣本,素材庫文案/初始模型生成文案當做負樣本,輸入到Bert初始分類模型中進行訓練;然後將前一步生成的排名靠前的高質量文案作為負樣本,達人賣點文案作為正樣本,再次輸入到Bert模型中做優化訓練,迴圈多次獲得最終的高質量賣點文案。

3. 個性化分發
接下來,我們介紹基於用戶畫像的個性化分發。每一個產品有不同的特色點,可以產生多個高質量的賣點,我們希望根據客戶的興趣點為其分配最有吸引力的賣點,以引導用戶購買該商品。個性化分發分為兩個步驟,首先生成賣點文案的表徵向量和用戶興趣的表徵向量,然後匹配賣點表徵向量和用戶表徵向量,從而實現賣點個性化分發。

用戶興趣嵌入表徵:通過work2vector方式獲得產品詞里每個字的word embedding,將產品詞中每個字的表徵向量求和獲取該產品詞的表徵,結合用戶對每個產品詞的喜好權重,然後對所有的產品詞進行加權平均,獲取用戶對產品詞的喜好的表徵向量。
賣點文案的特征向量:通過work2vector方式獲得賣點文案里每個字的word embedding,然後對賣點文案中每個字的表徵向量求和得到賣點文案特征向量。

個性化分發:通過計算用戶興趣表徵向量和賣點文案表徵向量的相似度來實現。可用的向量相似度計算的主要方法有餘弦相似度、皮爾森繫數、歐式距離和基於Kernel的相似度計算等。

--
04 模型研發與實踐
1. 文案輸出素材選擇
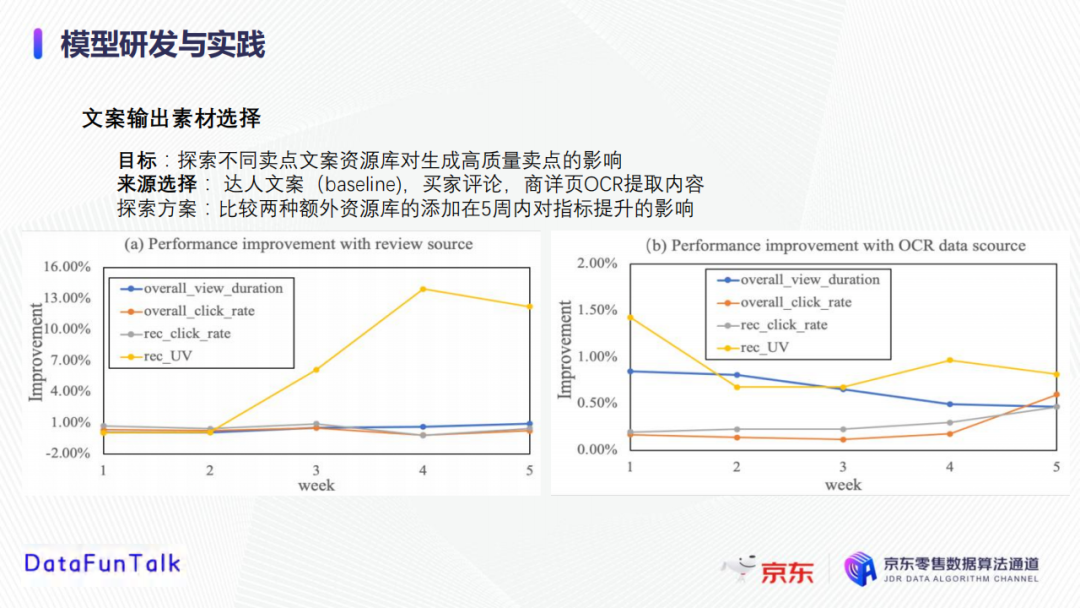
在模型開發的過程中,首先需要探索不同的賣點文案資源庫對生成高質量賣點的影響。候選的賣點素材庫除了基本的商品描述外,還有買家評論和商詳頁OCR提取文字。為了探索這兩種素材來源的優劣,我們對比了這兩種文案(買家評論、商詳頁OCR提取內容)在5周內對指標提升的影響。從下圖中可以觀察到,買家評論和商詳頁OCR提取內容均可以提高與銷售相關的性能指標。特別地,買家評論素材源可將UV提升7%左右,原因可能是其他用戶的評論更能激發用戶的興趣,即所謂的買家更瞭解買家;此外,商詳頁OCR素材源可能會帶來1%左右的提升;這些數據告訴我們可以將這兩個素材庫作為初始素材庫。
2. 線上賣點文案質量監管
在實踐過程中,我們希望能夠實時地檢測和過濾歷史數據中對購買行為產生負面影響的低質量賣點或者對購買行為產生促進作用的高質量賣點。由於人工很難綜合評估賣點是否對客戶有吸引力,所以我們希望通過業務端的反饋作為指標來幫助我們去識別高質量賣點或低質量賣點,在此基礎上,可以過濾掉低質量賣點,同時通過實際生產過程中的高質量賣點來重新優化模型。對於線上監控模塊,我們需要通過與業務相關的指標(曝光率、點擊價值、客戶停留時間等)計算相對提升指標。

3. 離線賣點文案模型優化
對於離線優化模塊,我們發現經過業務反饋過濾出的低質量賣點和高品質賣點可以使模型對高質量賣點文案選擇更加敏感,起到優化模型的作用。在實踐過程中,我們將相對提升指標大於30%並且基礎點擊PV > 5%的短文案作為高質量正樣本,剩餘文案作為負樣本,然後輸入到BERT模型中進行finetune,重新打分排序獲取高質量文案;同時我們將基礎點擊PV大於對比點擊PV或者對比點擊PV小於某個閾值的短文案作為低品質負樣本,剩餘文案作為正樣本,然後輸入到BERT模型中進行finetune, 從而打分排序同時過濾低評分的賣點文案。

--
05 產品落地與回報
當目前為止,我們已經完成了億級別的賣點挖掘和生產,覆蓋了上億的SKU,62個品類(包括家電、運動、生鮮、處方藥等);同時,生成的賣點是多樣化的,包括商品特色類、特色服務類、名人同款類、用戶行為類、用戶評價類、特色人群類,旨在能夠挖掘商品特點以助力體驗提升或者引入用戶數據激發從眾行為;另一方面,從銷售指標上看,賣點技術可以有效幫助提升商品點擊率(+2%)和停留時長(0.32%+),日常效果正向促進活動頁賦能;基於LBS信息建設特色人群賣點(消費升級或者同城偏好),效果正向,目前在賦能極速版助力下沉市場用戶運營。此外,推薦賣點也廣泛地賦能於主站、京喜、極速版、通天塔活動頁等多個應用場景。



