
1.什麼是Elasticserach? 一個由Java語言開發的全文搜索引擎,全文檢索就是根據用戶輸入查詢字元的片段,能查詢出包含片段的數據,簡單來說就是一個分散式的搜索與分析引擎,它可以完成分散式部署,結構化檢索,以及數據分析功能,主要是應用在微服務系統中。 我們使用大白話簡單的形式解釋,舉個例子 ...
1.什麼是Elasticserach?
一個由Java語言開發的全文搜索引擎,全文檢索就是根據用戶輸入查詢字元的片段,能查詢出包含片段的數據,簡單來說就是一個分散式的搜索與分析引擎,它可以完成分散式部署,結構化檢索,以及數據分析功能,主要是應用在微服務系統中。
我們使用大白話簡單的形式解釋,舉個例子,例如我們HR下發漲薪公告“今年統一漲工資,真的666666翻了”這段字元串存在資料庫中,我們還有很多其他的公告,我們想快速找到關於漲工資的信息,我們在客戶端輸入"漲工資"或者"真翻了"系統能查詢出來這一整段話,或者類似的字元串,如果你還覺得不夠形象,相信使用過谷歌吧,你在谷歌輸入隨意你感興趣的關鍵字,都會給你搜索到相關信息,這個就是全文檢索。
2.Elasticserach的全局設計
我們需要從Elasticserach中查詢數據,必須先將微服務系統的數據,同步到Elasticserach中,使它介於系統和資料庫之間,作為一個緩衝區,用作對高併發全文檢索查詢提供支持,當然最主要的是可以利用它的全文檢索和數據分析功能,按照上面介紹的業務場景,如果你有相關需求,你不想每次的查詢都是直接去資料庫中模糊匹配吧,這樣做先不說設計是否正確,最起碼模糊查詢的性能是極低的,遇到併發量高直接對資料庫是致命的威脅,所以選擇合適的技術做合適的事。
1.寫入數據方式
首先先看下麵的圖,在腦海中對寫入數據到Elasticserach的過程有個簡單的理解,然後再分析Elasticserach本身如何存儲數據的

我們看到圖片有幾個關鍵字Document、In-memory buffer、cache、以及segment 這幾部分正是組成Elasticserach寫入數據流程的核心內容,那麼我們來解析一下大致流程如下:
- Elasticserach首先不斷的將數據
Document寫入到In-memory buffer - 當滿足一定條件後
In-memory buffer中的 Documents 會刷新到cache,預設是一秒鐘一次,所以新寫入的 Document 最慢 1 秒就可以在 cache 中被搜索到 - 在
cache中生成新的segment,這時候還沒有寫入磁碟,但是已經可以被讀取了 - 從
cache將數據非同步寫入到磁碟
2.如何防止數據丟失
我們簡單的分析了上面的步驟,知道了cache存儲了供客戶端寫入和查詢數據的支撐,但是弊端必然存在,如果緩存cache宕機數據就會丟失 ,所以為了防止數據丟失,就採用持久化的策略,將數據非同步(fsync)寫入到磁碟 中。
其實 Document在寫入數據到In-memory buffer 時,此時Elasticserach會追加translog, 每隔 5s 會 fsync 到磁碟,當translog 累加變得越來越大,大到一定程度或者每隔一段時間,Elasticserach會執行 flush。
一般translog 每 5s 刷新一次磁碟,所以故障重啟,可能會丟失 5s 的數據,可以通過配置文件來配置縮短寫入磁碟的周期,translog 預設 30 分鐘或者當數據太大,達到2G左右,會執行執行 flush 操作。
3.數據結構設計
在Elasticserach中有幾個比較核心的概念
Dcoument就是數據在ES中的一種表現形式,以Json的格式存儲 。Index(資料庫)用於Document存儲,數據在Elasticserach中的是以2進位的格式存儲到一個個尾碼為.fdt的文檔中。Index(查詢)表示文檔 的索引,我們的Index索引是存儲在尾碼為.fdx的文檔中,索引文件預設 是以Elasticserach的文檔ID生成
通常Elasticserach接收到存儲數據請求,首先會生成 一個索引fdx文件,然後再把具體數據存儲到fdt文件中,索引和文檔一一對應的關係 ,查找時根據索引快速找到文檔數據,我們將這種關係稱之為正排索引
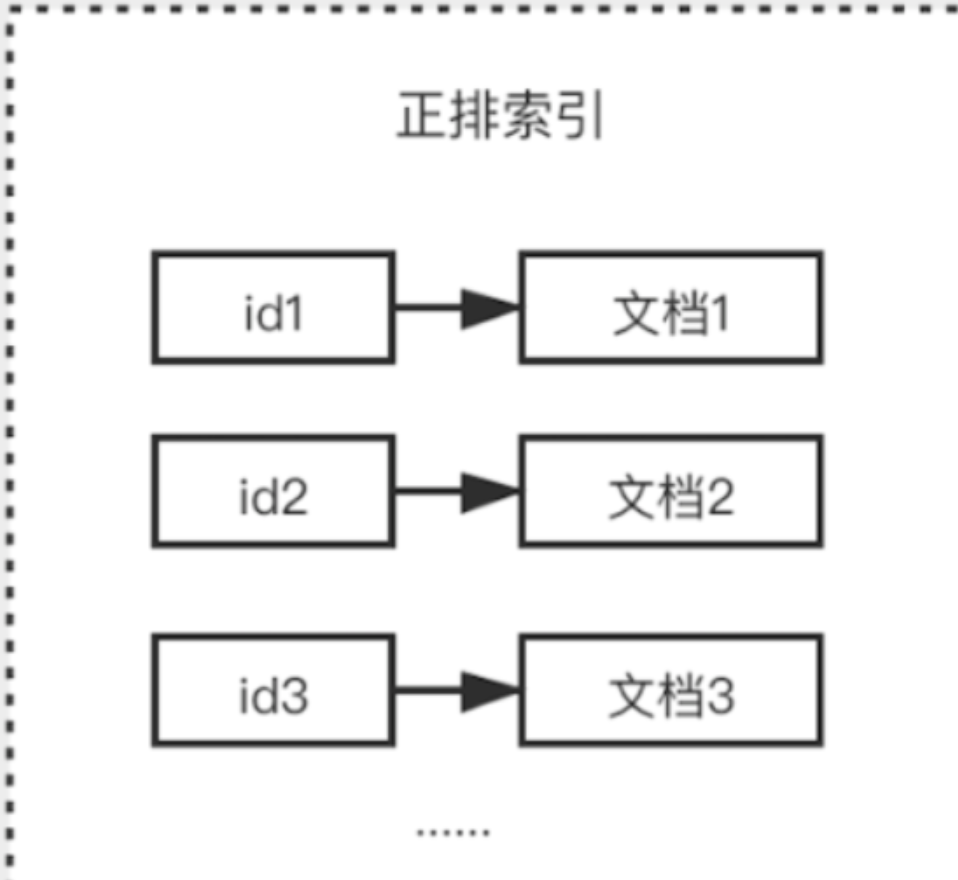
但是存在一些影響性能的問題 ,如果有成千上萬的數據,要查詢某個文檔數據,就需要去迴圈找出對應的文檔數據,隨著數據量增大,對性能的損耗是相當嚴重的,所以就需要使用 倒排索引,,倒排索引指的是將文檔內容中的單詞作為索引,將包含該詞的文檔 ID 作為記錄的結構。
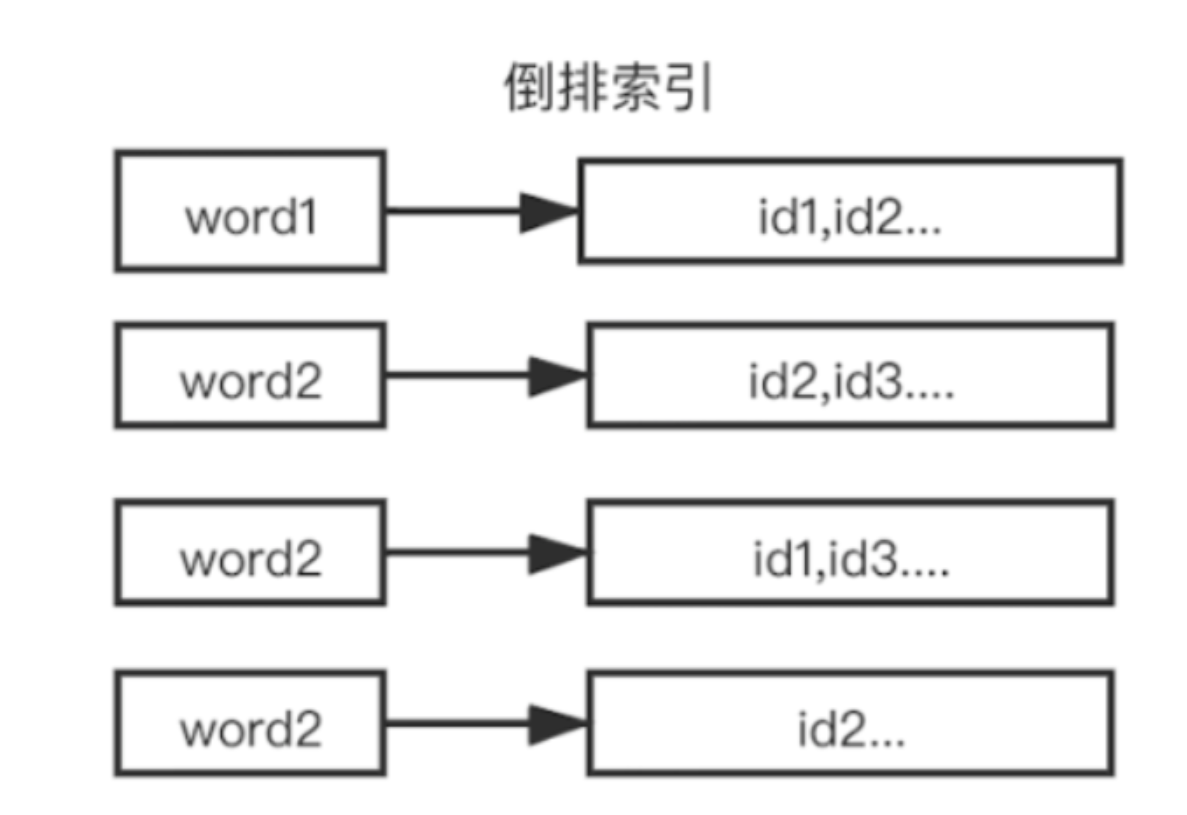
3.搜索數據的原理
1.分詞概念
在去分析 倒排索引之前我們需要瞭解什麼是分詞,簡單的解釋就是將一段話可能分為不同的關鍵詞或關鍵字 ,也許你會好奇它是如何通過某種規則分詞的,其實在全文檢索中如何分詞與分詞器是密切相關的 ,後面我們會單獨學習分詞 。下麵示例簡單說明分詞:
title:"搜索數據的原理";
//分詞之後
搜索
數據
原理
搜索數據
數據的原理
2.倒排索引生成過程
我們通過一個簡單的例子來說明倒排索引的生成過程,假設目前有2條數據
message:今年統一漲工資,真的666666翻了;
message:老闆說,今年統一不漲工資;
1.正排索引會給 每一個Document進行 編號,作為 唯一標識
| 文檔 id | 內容 |
|---|---|
| 1 | 今年統一漲工資,真的666666翻了 |
| 2 | 老闆說 ,今年統一不漲工資 |
2.生成倒排索引首先會對 欄位內容進行分詞,例如2個 Document包含 6、統一、工資,漲工資 、老闆這些關鍵字。然後 按照關鍵詞 來作為 索引,對應 文檔的id建立鏈表,就能構成 倒排索引,有了倒排索引,就能快速、靈活地實現各類搜索需求。整個搜索過程中我們不需要做任何文本的模糊匹配。
| 6 | 1 |
|---|---|
| 統一 | 1,2 |
| 漲工資 | 1,2 |
| 老闆 | 2 |
3.例如需要查詢 “漲工資老闆說”,通過 詞倒排首先查詢到文檔 id 1,2,再通過“老闆”找到文檔id 2,然後 取交集 得到 id為2的 文檔
4.我們在使用倒排索引,其中分詞得到的單詞是利用一個Term Dictionary的概念來存儲的,一個分詞就是一個 Term,它在文件中的變現形式是存儲在尾碼為.tim的文檔中,而文檔id是存儲在Postings List的集合中,對應穩健表現形式是存儲在尾碼為.doc的文件中
5.此時我們應該考慮,按照這樣存儲,文檔和分詞的關係是1>N的 ,也就是說一個文檔對應多個分詞,例如1000條文檔,可能對應2000條分詞,甚至更多,取決於文檔大小和分詞精度,那我們在對大量的分詞進行查找時,Cpu會將這些Term從磁碟載入到記憶體,由於磁碟預讀一次最多載入4M大小數據,所以會分段載入多次,此時如果我只需要查詢2個單詞 ,是不是也要將所有的Term載入到記憶體呢 ,顯然這樣做是非常浪費性能的,那該如何解決呢?
6.其實Elasticserach為瞭解決上述問題,提高查詢Term的效率 ,會在Term Dictionary之上再抽象出一層索引(Index)的策略,將Term索引文件存儲,它在文件中表現形式存儲在一個尾碼為.tip的文件中,查詢時根據索引找到Term單詞,然後載入到記憶體中,在找到文檔id,直到最終找到文檔。
4.聚合場景
首先我們要知道什麼是聚合,根據Google上說的聚合在信息科學中是指對有關的數據進行內容挑選、分析、歸類,最後分析得到人們想要的結果,說白了就是做統計。
其實Elasticserach為瞭解決提高統計的效率和性能,在對數據統計存儲方面做了一些對應的設計策略,我們知道在關係型資料庫中,數據存儲是以行為單位存儲,而Elasticserach採用的是列式存儲,列式存儲有利於做聚合操作,我們書面化稱為doc_values。
doc_values欄位文件在實際文件中存儲表現形式是以.fnm尾碼文件存儲,而doc_values值文件是以.tmd尾碼文件存儲

