
五種 I/O 模型 先花費點時間瞭解這幾種 I/O 模型,有助於後面的理解。 阻塞 I/O 與非阻塞 I/O 阻塞和非阻塞的概念能應用於所有的文件描述符,而不僅僅是 socket。我們稱阻塞的文件描述符為阻塞 I/O,稱非阻塞的文件描述符為非阻塞 I/O。 socket 在創建的時候預設是阻塞的,我 ...
五種 I/O 模型
先花費點時間瞭解這幾種 I/O 模型,有助於後面的理解。
阻塞 I/O 與非阻塞 I/O
阻塞和非阻塞的概念能應用於所有的文件描述符,而不僅僅是 socket。我們稱阻塞的文件描述符為阻塞 I/O,稱非阻塞的文件描述符為非阻塞 I/O。
socket 在創建的時候預設是阻塞的,我們可以給 socket 系統調用的第 2 個參數傳遞 SOCK_NONBLOCK 標誌,或者通過 fcntl 系統調用的 F_SETFL 命令將其設置為非阻塞的。
-
針對阻塞 I/O 執行的系統調用可能因為無法立即完成而被操作系統掛起,直到等待的事件發生為止。可能被阻塞的系統調用為 accept、send、recv 和 connect;
-
針對非阻塞 I/O 執行的系統調用則總是立即返回,而不管事件是否已經發生。如果事件沒有立即發生,這些系統調用就返回
-1,和出錯的情況一樣。此時我們必鬚根據errno來區分這兩種情況。-
對 accept、send、recv 而言,事件未發生時
errno通常被設置為EAGAIN(意為“再來一次”)或者EWOUDBLOCK(意為“期望阻塞”); -
對 connect 而言,
errno則被設置成EINPROGRESS(意為“在處理中”)。
-
很顯然,只有在事件已經發生的情況下操作非阻塞 I/O(讀、寫等),才能提高程式的效率。因此,非阻塞 I/O 通常要和其他 I/O 通知機制一起使用,比如 I/O 復用和 SIGIO 信號。
筆者認為,我們使用非阻塞 I/O 的最佳情況是:【當我們進行系統調用的時候,它所需要的事件已經發生了】,這樣系統調用就不會被阻塞,直接進行處理。比如 accept 函數,I/O 復用的好處就是當我們調用 accept 函數的時候,已經有客戶端在請求連接,這樣直接調用 accept,提高運行效率。
I/O 復用
I/O 復用是一種 I/O 通知機制,而且是最常用的通知機制。
I/O 復用是指應用程式通過 I/O 復用函數(select、poll、epoll_wait)向內核註冊一組事件,內核通過 I/O 復用函數把其中就緒的事件通知給應用程式。
需要註意的是 I/O 復用函數本身是阻塞的,它們能提高程式效率的原因在於它們具有同時監聽多個 I/O 事件的能力。
信號驅動 I/O
為一個目標文件描述符指定宿主進程,那麼被指定的宿主進程將捕獲到 SIGIO 信號。這樣,當文件描述符上有事件發生時,SIGIO 信號的信號處理函數將被觸發,我們也就可以在該信號處理函數中對目標文件描述符執行非阻塞 I/O 操作了。
非同步 I/O
理論上講,阻塞 I/O、非阻塞 I/O、信號驅動 I/O 和 I/O 復用都是同步 I/O。
- 同步I/O:內核嚮應用程式通知的是就緒事件,比如只通知有客戶端連接,要求用戶代碼自動執行I/O操作(將數據從內核緩衝區讀入用戶緩衝區,或將數據從用戶緩衝區寫入內核緩衝區);
- 非同步I/O:內核嚮應用程式通知的是完成事件,比如讀取客戶端的數據之後才通知應用程式,由內核完成I/O操作(數據在內核緩衝區和用戶緩衝區之間的移動是由內核在“後臺”完成的)。
對非同步 I/O 而言,用戶可以直接對 I/O 執行讀寫操作,這些操作告訴內核用戶讀寫緩衝區的位置,以及 I/O 操作完成之後內核通知應用程式的方式。非同步 I/O 的讀寫操作總是立即返回,不論 I/O 是否是阻塞的,因為真正的讀寫操作已經由內核接管。
兩種高效的事件處理模式
Reactor 模式
Reactor 模式要求主線程(I/O 處理單元)只負責監聽文件描述符上是否有事件發生。有的話立即通知工作線程(邏輯單元),讀寫數據、接受新的連接及處理客戶請求均在工作線程中完成。通常由同步I/O實現。
工作流程:
-
主線程向 epoll 內核事件表中註冊 socket 上的讀就緒事件;
告訴 socket 的對方(客戶端):我這邊準備好讀數據啦,你可以發數據啦!
-
主線程調用
epoll_wait()等待 socket 上有數據可讀; -
當 socket 上有數據可讀時,
epoll_wait()通知主線程,主線程將 socket 可讀事件插入請求隊列;主線程:幹活啦幹活啦,這有個活,你們看看誰幹了它!
-
睡眠在請求隊列上的某個工作線程被喚醒,它從 socket 上讀取數據,並處理客戶請求,然後往 epoll 內核事件表中註冊該 socket 上的寫就緒事件;
某一個苦工(工作線程)幹完活之後告訴 socket 的對方:我準備好寫了!
-
主線程調用
epoll_wait()等待 socket 可寫; -
當 socket 可寫時,
epoll_wait()通知主線程,主線程將 socket 可寫事件放入請求隊列;主線程:又來活啦,你們看看誰來乾!
-
睡眠在請求隊列上的某個工作線程被喚醒,它往 socket 上寫入伺服器處理客戶請求的結果。
某個苦工又被喚醒來幹活,寫入處理結果。
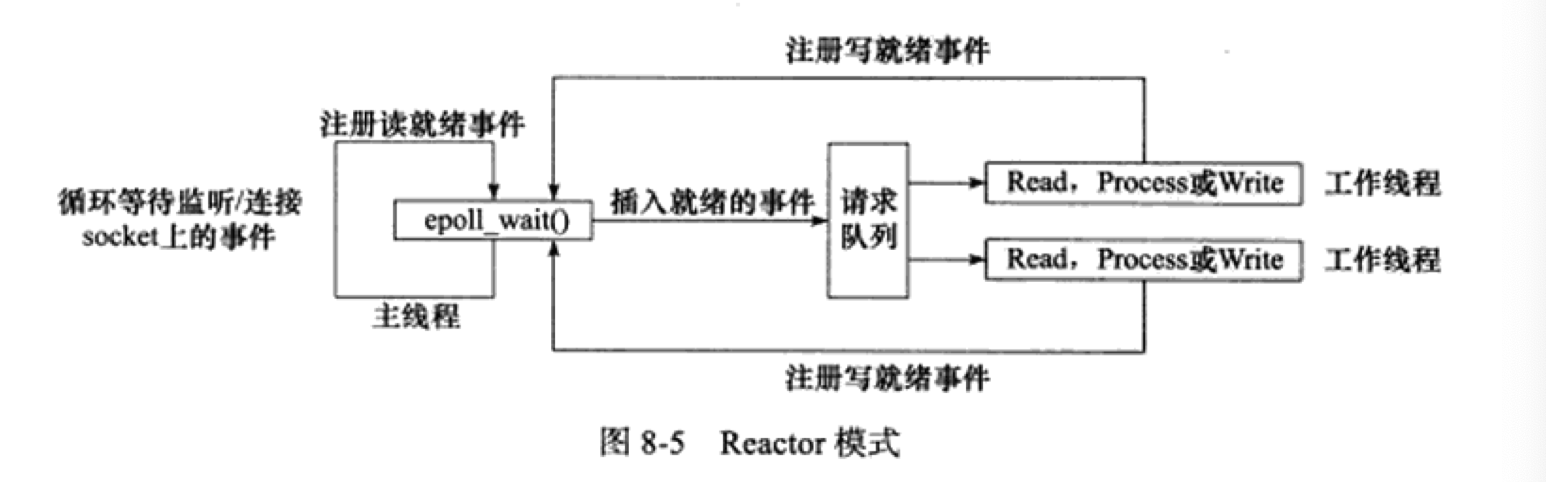
Reacto 模式類似於老闆(主線程)與苦工(工作線程)之間的關係,有活了老闆就派給苦工來乾(哭了.....莫名被 cue 到)
Proactor 模式
Proactor 模式將所有的 I/O 操作都交給主線程和內核來處理,工作線程僅僅負責業務邏輯。通常由非同步 I/O (aio_read()和aid_write())實現。
工作流程
-
主線程調用
aio_read()向內核註冊 socket 上的讀完成事件,並告訴內核 用戶讀緩衝區的位置,以及讀操作完成時如何通知應用程式(這裡以信號為例);主線程告訴內核:用戶這邊準備好收貨了,你直接把貨卸在這!你卸完了直接給用戶打電話!
-
主線程繼續處理其他邏輯;
溜了溜了,我先乾點別的...
-
當 socket 上的數據被讀入用戶緩衝區後,內核將嚮應用程式發送一個信號,以通知應用程式數據已經可用;
苦逼的內核幹完活,給用戶打了電話通知他活幹完了...
-
應用程式預先定義好的信號處理函數選擇一個工作線程來處理客戶請求。工作線程處理完客戶請求之後,調用
aio_write()函數向內核註冊 socket 上的寫完成事件,並告訴內核 用戶寫緩衝區的位置,以及寫操作完成時如何通知應用程式(仍然以信號為例);用戶這邊有很多苦工(工作線程),預先指定好了一個苦工來對接這批貨物。這個苦工加工完所有的貨物,告訴內核我這邊貨加工好了,放在老地方了,你直接過來拿!
-
主線程繼續處理其他邏輯;
沒我什麼事,繼續摸魚(bushi
-
當用戶緩衝區的數據被寫入 socket 之後,內核將嚮應用程式發送一個信號,以通知應用程式數據已經發送完畢;
然後,內核就來拉貨了,拉完貨之後又給用戶打電話:貨我全拉走了!
-
應用程式預先定義好的信號處理函數選擇一個工作線程來做善後處理,比如決定是否關閉 socket。
苦工收到消息,來看看是否需要清理場地...
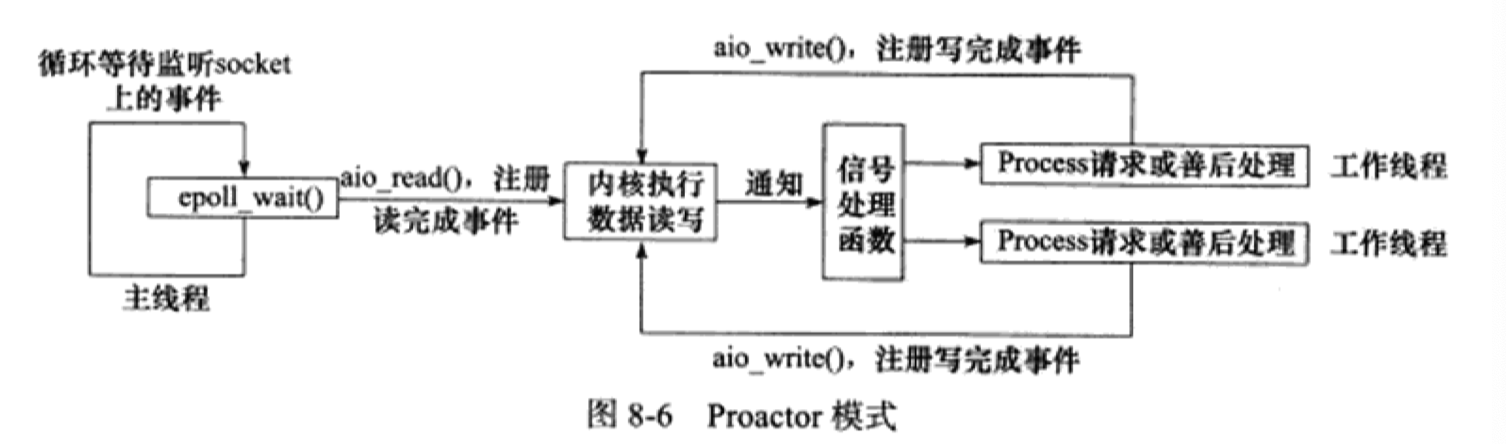
可以看到,Proactor 模式相當於找了個快遞員(內核)來幫助運輸貨物(讀寫數據),工作線程只需要處理業務邏輯,主線程只需要監聽連接事件,讀寫事件由內核和工作線程直接通信。
模擬 Proactor 模式
由於 Proactor 模式需要非同步 I/O 來實現,這裡提出使用同步 I/O 的方式模擬出 Proactor 模式的一種方法。其原理是:主線程執行數據讀寫操作,讀寫完成後,主線程向工作線程通知這一“完成事件”。那麼從工作線程的角度來看,它們就直接獲得了數據讀寫的結果,接下來要做的只是對讀寫的結果進行邏輯處理。
工作流程
- 主線程往 epoll 內核事件表中註冊 socket 上的讀就緒事件;
- 主線程調用
epoll_wait()等待 socket 上有數據可讀; - 當 socket 上有數據可讀時,
epoll_wait()通知主線程。主線程從 socket 迴圈讀取數據,直到沒有更多數據可讀,然後將讀到的數據封裝成一個請求對象並插入請求隊列; - 睡眠在請求隊列上的某個工作線程被喚醒,它獲得請求對象並處理客戶請求,然後往 epoll 內核事件表中註冊 socket 上的寫就緒事件;
- 主線程調用
epoll_wait()等待 socket 可寫; - 當 socket 可寫時,
epoll_wait()通知主線程,主線程往 socket 上寫入伺服器處理客戶請求的結果。
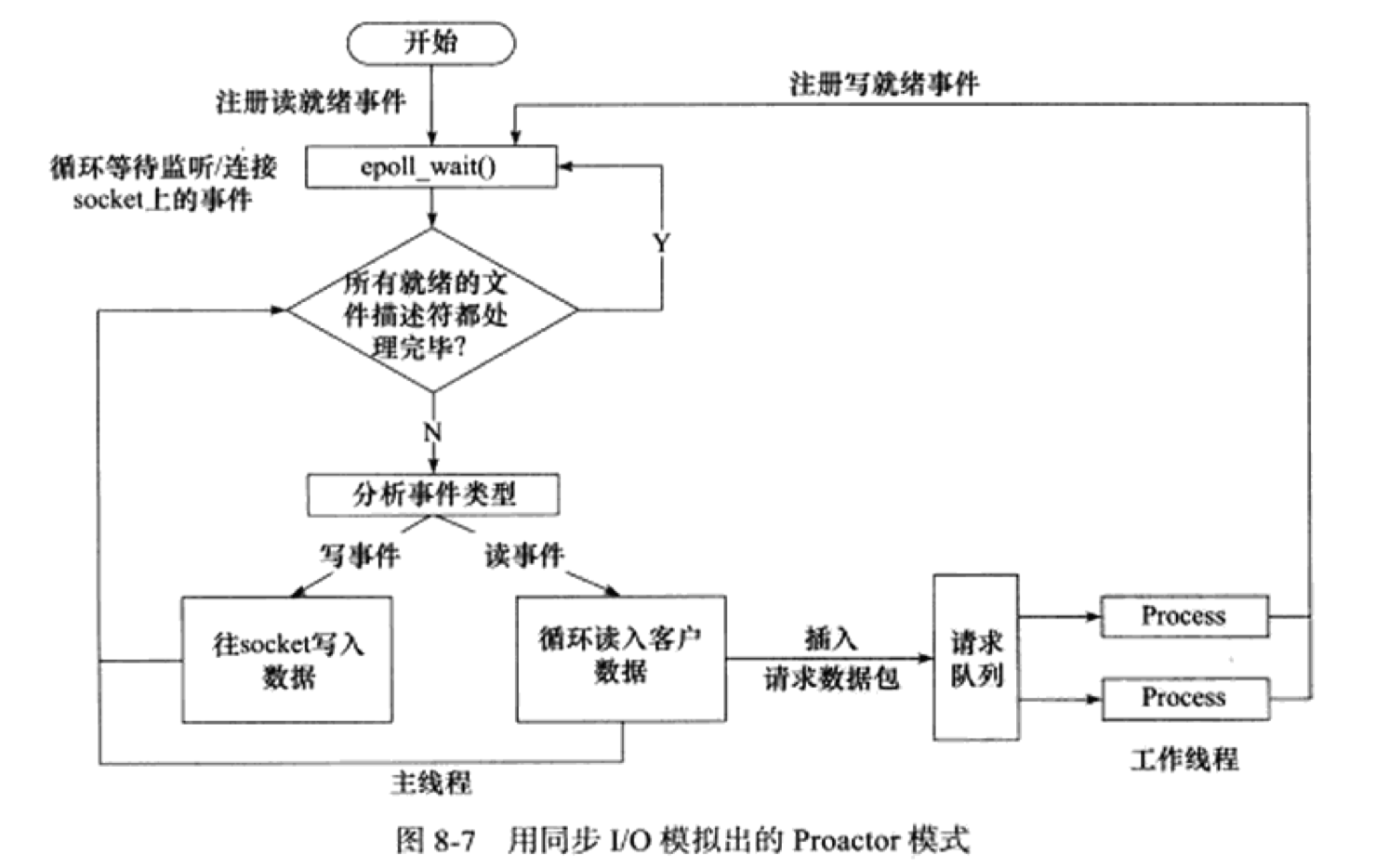
可以看到,模擬 Proactor 模式其實就是主線程自己來充當快遞員(內核)的角色,所以在工作線程的角度來看與 Proactor 模式差不多。
本文參考自游雙大神的《Linux 高性能伺服器編程》一書。


