
一、概述 Flink核心是一個流式的數據流執行引擎,並且能夠基於同一個Flink運行時,提供支持流處理和批處理兩種類型應用。其針對數據流的分散式計算提供了數據分佈,數據通信及容錯機制等功能。基於流執行引擎,Flink提供了跟多高抽象層的API便於用戶編寫分散式任務,下麵稍微介紹一下Flink的幾種A ...
目錄
- 一、概述
- 二、Flink工作原理
- 三、Flink核心概念
- 四、對比常用的實時計算框架
- 五、Flink環境部署(Flink On Yarn)
- 六、Spark與Flink對比
一、概述
Flink核心是一個流式的數據流執行引擎,並且能夠基於同一個Flink運行時,提供支持流處理和批處理兩種類型應用。其針對數據流的分散式計算提供了數據分佈,數據通信及容錯機制等功能。基於流執行引擎,Flink提供了跟多高抽象層的API便於用戶編寫分散式任務,下麵稍微介紹一下Flink的幾種API:
Flink官網:https://flink.apache.org/
官方文檔(1.14.2版本):https://nightlies.apache.org/flink/flink-docs-release-1.14/
官方中文文檔(1.14.2版本):https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/
不同版本的文檔:https://nightlies.apache.org/flink/
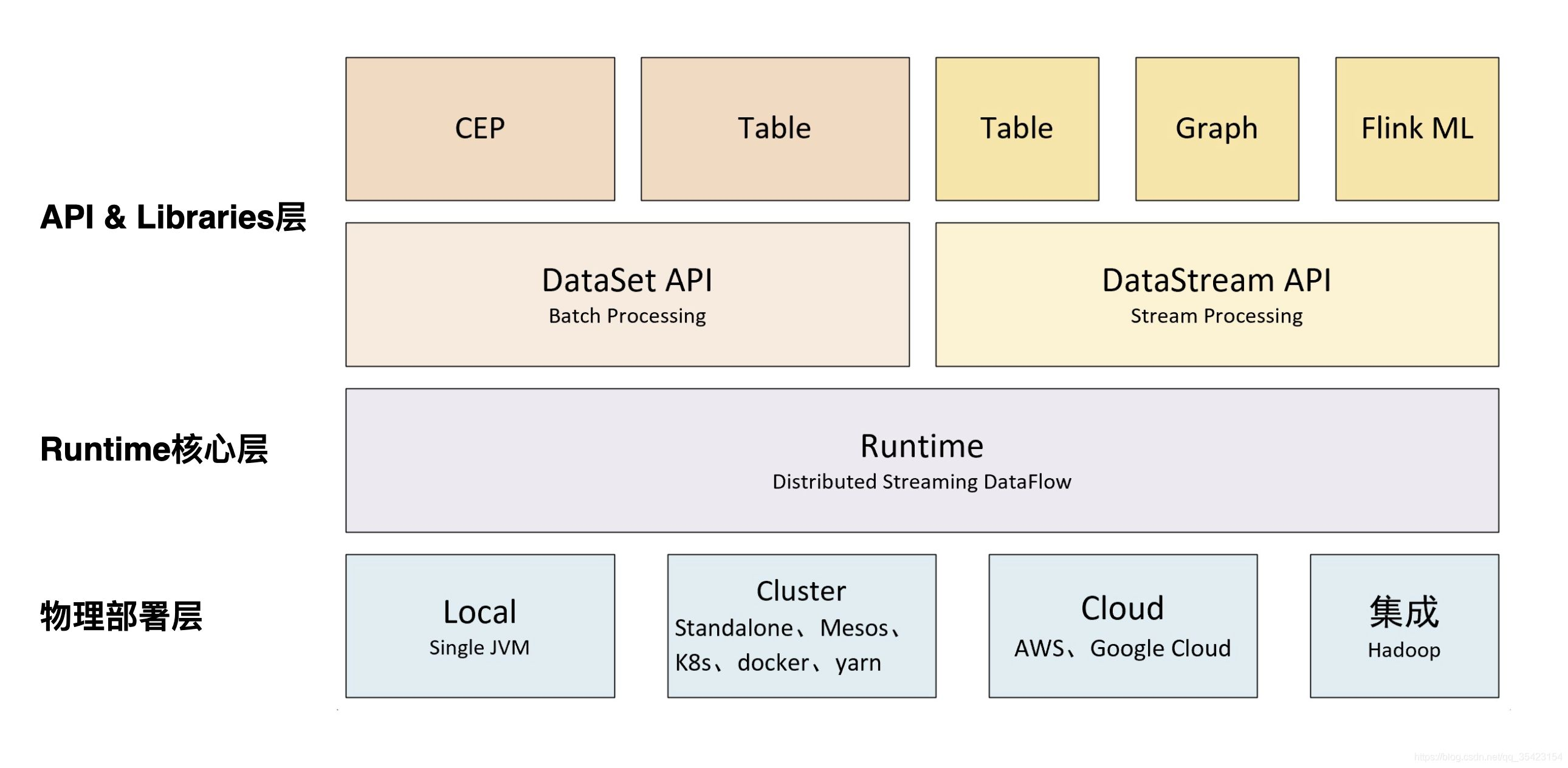
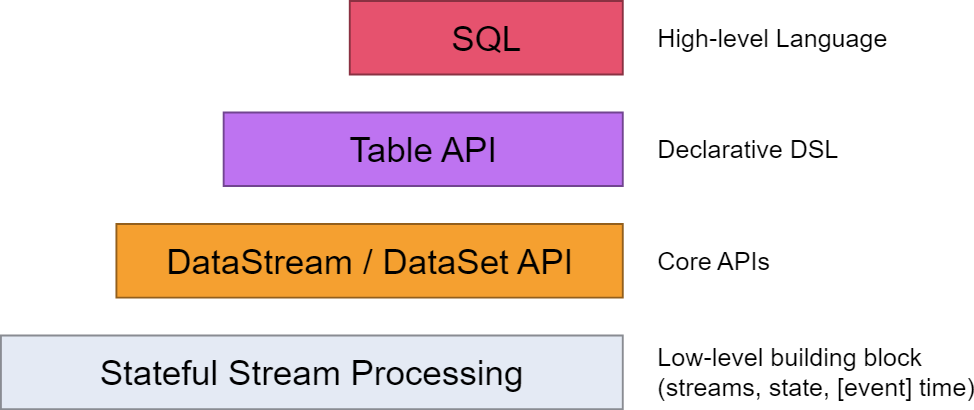
- SQL & Table API:Flink 支持兩種關係型的 API,Table API 和 SQL。這兩個 API 都是批處理和流處理統一的 API,這意味著在無邊界的實時數據流和有邊界的歷史記錄數據流上,關係型 API 會以相同的語義執行查詢,並產生相同的結果。Table API 和 SQL藉助了 Apache Calcite 來進行查詢的解析,校驗以及優化。它們可以與 DataStream 和DataSet API 無縫集成,並支持用戶自定義的標量函數,聚合函數以及表值函數。
- DataStream API:DataStream API為許多通用的流處理操作提供了處理原語。這些操作包括視窗、逐條記錄的轉換操作,在處理事件時進行外部資料庫查詢等。DataStream API 支持 Java 和Scala 語言,預先定義了例如 map()、reduce()、aggregate() 等函數。你可以通過擴展實現預定義介面或使用 Java、Scala 的 lambda 表達式實現自定義的函數。
- DataSet API:DataSet API 是 Flink 用於批處理應用程式的核心 API。DataSet API 所提供的基礎運算元包括 map、reduce、(outer) join、co-group、iterate 等。所有運算元都有相應的演算法和數據結構支持,對記憶體中的序列化數據進行操作。如果數據大小超過預留記憶體,則過量數據將存儲到磁碟。Flink 的 DataSet API 的數據處理演算法借鑒了傳統資料庫演算法的實現,例如混合散列連接(hybrid hash-join)和外部歸併排序(external merge-sort)。
- StateFul Stream Processing:最低級抽象只提供有狀態流,通過Process Function嵌入到DataStream API中,它允許用戶自由處理來自一個或者多個流的時間,並使用一致的容錯狀態,此外用戶可以註冊event time和processing time回調,允許程式實現複雜的計算。
- 擴展庫
- 複雜事件處理(CEP):模式檢測是事件流處理中的一個非常常見的用例。Flink 的 CEP庫提供了 API,使用戶能夠以例如正則表達式或狀態機的方式指定事件模式。CEP 庫與Flink 的 DataStream API 集成,以便在 DataStream 上評估模式。CEP 庫的應用包括網路入侵檢測,業務流程監控和欺詐檢測。
- Gelly: Gelly 是一個可擴展的圖形處理和分析庫。Gelly 是在 DataSet API 之上實現的,並與 DataSet API 集成。因此,它能夠受益於其可擴展且健壯的操作符。Gelly 提供了內置演算法,如 label propagation、triangle enumeration 和 page rank 演算法,也提供了一個簡化自定義圖演算法實現的 Graph API。
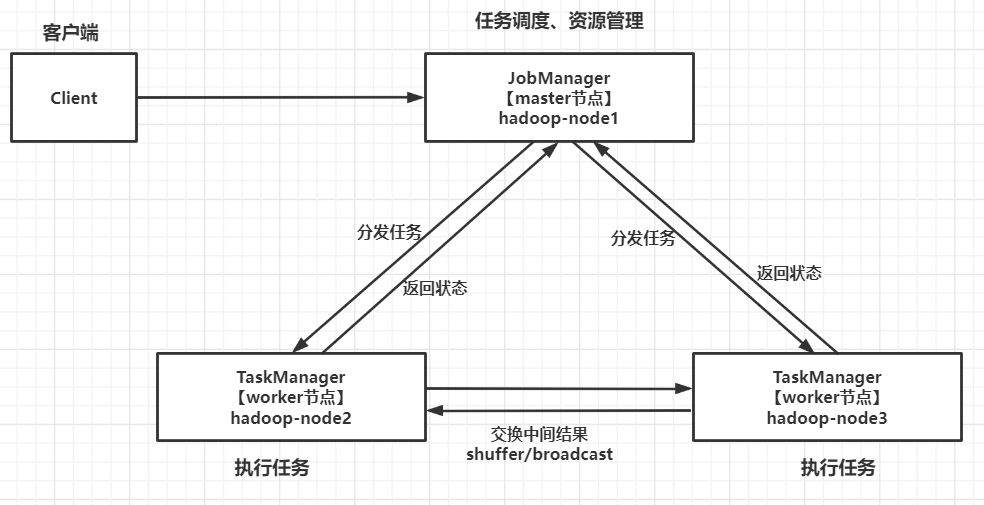
二、Flink工作原理
Flink的基礎架構圖:
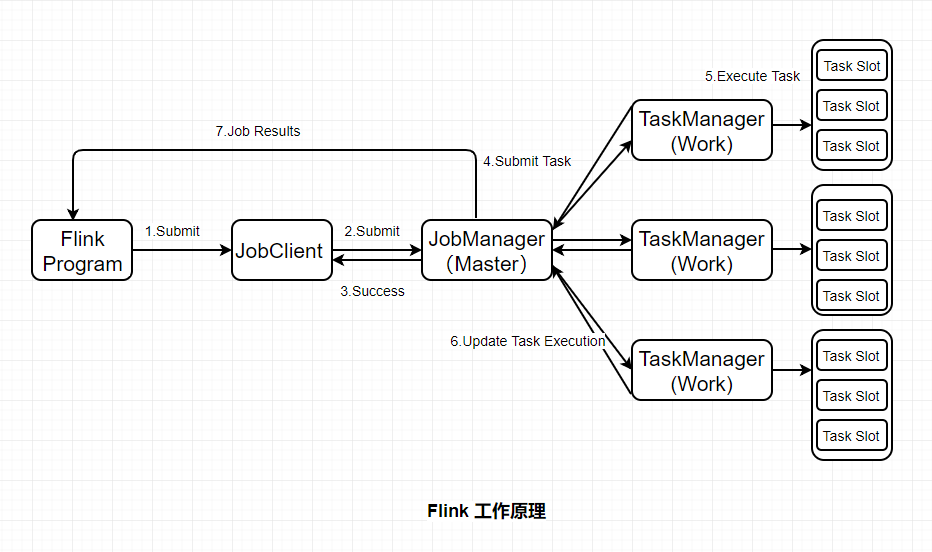
-
JobClient:負責接收程式,解析和優化程式的執行計劃,然後提交執行計划到JobManager。這裡執行的程式優化是將相鄰的Operator融合,形成Operator Chain,Operator的融合可以減少task的數量,提高TaskManager的資源利用率。為了瞭解Flink的解析過程,需要簡單介紹一下Flink的Operator,在Flink主要有三類Operator:
- Source Operator :顧名思義這類操作一般是數據來源操作,比如文件、socket、kafka等,一般存在於程式的最開始
- Transformation Operator: 這類操作主要負責數據轉換,map,flatMap,reduce等運算元都屬於Transformation Operator,
- Sink Operator:意思是下沉操作,這類操作一般是數據落地,數據存儲的過程,放在Job最後,比如數據落地到Hdfs、Mysql、Kafka等等。
-
JobManagers:負責申請資源,協調以及控制整個job的執行過程,具體包括,調度任務、處理checkpoint、容錯等等。
-
TaskManager:TaskManager運行在不同節點上的JVM進程,負責接收並執行JobManager發送的task,並且與JobManager通信,反饋任務狀態信息,如果說JobManager是master的話,那麼TaskManager就是worker用於執行任務。每個TaskManager像是一個容器,包含一個或者多個Slot。
-
Slot:Slot是TaskManager資源粒度的劃分,每個Slot都有自己獨立的記憶體。所有Slot平均分配TaskManager的記憶體,值得註意的是,Slot僅劃分記憶體,不涉及CPU的劃分,即CPU是共用使用。每個Slot可以運行多個task。Slot的個數就代表了一個程式的最高並行度。
-
Task:Task是在operators的subtask進行鏈化之後形成的,具體Flink job中有多少task和operator的並行度和鏈化的策略有關。
-
SubTask:因為Flink是分散式部署的,程式中的每個運算元,在實際執行中被分隔為一個或者多個subtask,運算符子任務(subtask)的數量是該特定運算符的並行度。數據流在運算元之間流動,就對應到SubTask之間的數據傳輸。Flink允許同一個job中來自不同task的subtask可以共用同一個slot。每個slot可以執行一個並行的pipeline。可以將pipeline看作是多個subtask的組成的。
三、Flink核心概念
1)Time(時間語義)
Flink 中的 Time 分為三種:事件時間、達到時間與處理時間。
-
事件時間:是事件真實發生的時間。
-
達到時間:是系統接收到事件的時間,即服務端接收到事件的時間。
-
處理時間:是系統開始處理到達事件的時間。
【溫馨提示】在某些場景下,處理時間等於達到時間。因為處理時間沒有亂序的問題,所以服務端做基於處理時間的計算是比較簡單的,無遲到與亂序數據。
Flink 中只需要通過 env 環境變數即可設置Time:
//創建環境上下文
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 設置在當前程式中使用 ProcessingTime
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
2)Window(視窗)
視窗本質就是將無限數據集沿著時間(或者數量)的邊界切分成有限數據集。
-
Time Window:基於時間的,分為Tumbling Window(無數據重疊)和Sliding Window(有數據重疊) 。
-
Count Window:基於數量的,分為Tumbling Window(無數據重疊)和Sliding Window(有數據重疊)。
-
Session Window:基於會話的,一個session window關閉通常是由於一段時間沒有收到元素。
-
Global Window:全局視窗。
【溫馨提示】在實際操作中,window又分為兩大類型的視窗:Keyed Window 和 Non-keyed Window,兩種類型的視窗操作API有細微的差別。
3) Trigger
1、自定義觸發器
觸發器決定了視窗何時會被觸發計算,Flink 中開發人員需要在 window 類型的操作之後才能調用 trigger 方法傳入觸發器定義。Flink 中的觸發器定義需要繼承並實現 Trigger 介面,該介面有以下方法:
- onElement(): 每個被添加到視窗中的元素都會被調用
- onEventTime():當事件時間定時器觸發時會被調用,比如watermark到達
- onProcessingTime():當處理時間定時器觸發時會被調用,比如時間周期觸發
- onMerge():當兩個視窗合併時兩個視窗的觸發器狀態將會被調動併合並
- clear():執行需要清除相關視窗的事件
以上方法會返回決定如何觸發執行的 TriggerResult:
- CONTINUE:什麼都不做
- FIRE:觸發計算
- PURGE:清除視窗中的數據
- FIRE_AND_PURGE:觸發計算後清除視窗中的數據
2、預定義觸發器
如果開發人員未指定觸發器,則 Flink 會自動根據場景使用預設的預定義好的觸發器。在基於事件時間的視窗中使用 EventTimeTrigger,該觸發器會在watermark通過視窗邊界後立即觸發(即watermark出現關閉改視窗時)。在全局視窗(GlobalWindow)中使用 NeverTrigger,該觸發器永遠不會觸發,所以在使用全局視窗時用戶需要自定義觸發器。
4)State
- Managed State 是由flink runtime管理來管理的,自動存儲、自動恢復,在記憶體管理上有優化機制。且Managed State 支持常見的多種數據結構,如value、list、map等,在大多數業務場景中都有適用之處。總體來說是對開發人員來說是比較友好的,因此 Managed State 是 Flink 中最常用的狀態。Managed State 又分為 Keyed State 和 Operator State 兩種。
- Raw State 由用戶自己管理,需要序列化,只能使用位元組數組的數據結構。Raw State 的使用和維度都比 Managed State 要複雜,建議在自定義的Operator場景中酌情使用。
5)狀態存儲
Flink中狀態的實現有三種:MemoryState、FsState、RocksDBState。三種狀態存儲方式與使用場景各不相同,詳細介紹如下:
1、MemoryStateBackend
-
構造函數:MemoryStateBackend(int maxStateSize, boolean asyncSnapshot)
-
存儲方式:State存儲於各個 TaskManager記憶體中,Checkpoint存儲於 JobManager記憶體
-
容量限制:單個State最大5M、maxStateSize<=akka.framesize(10M)、總大小不超過JobManager記憶體
-
使用場景:無狀態或者JobManager掛掉不影響的測試環境等,不建議在生產環境使用
2、FsStateBackend
-
構造函數:FsStateBackend(URI checkpointUri, boolean asyncSnapshot)
-
存儲方式:State存儲於 TaskManager記憶體,Checkpoint存儲於 外部文件系統(本次磁碟 or HDFS)
-
容量限制:State總量不超過TaskManager記憶體、Checkpoint總大小不超過外部存儲空間
-
使用場景:常規使用狀態的作業,分鐘級的視窗聚合等,可在生產環境使用
3、RocksDBStateBackend
-
構造函數:RocksDBStateBackend(URI checkpointUri, boolean enableincrementCheckpoint)
-
存儲方式:State存儲於 TaskManager上的kv資料庫(記憶體+磁碟),Checkpoint存儲於 外部文件系統(本次磁碟 or HDFS)
-
容量限制:State總量不超過TaskManager記憶體+磁碟、單key最大2g、Checkpoint總大小不超過外部存儲空間
-
使用場景:超大狀態的作業,天級的視窗聚合等,對讀寫性能要求不高的場景,可在生產環境使用
根據業務場景需要用戶選擇最合適的 StateBackend ,代碼中只需在相應的 env 環境中設置即可:
// flink 上下文環境變數
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 設置狀態後端為 FsStateBackend,數據存儲到 hdfs /tmp/flink/checkpoint/test 中
env.setStateBackend(new FsStateBackend("hdfs://ns1/tmp/flink/checkpoint/test", false))
6)Checkpoint
Checkpoint 是分散式全域一致的,數據會被寫入hdfs等共用存儲中。且其產生是非同步的,在不中斷、不影響運算的前提下產生。
用戶只需在相應的 env 環境中設置即可:
// 1000毫秒進行一次 Checkpoint 操作
env.enableCheckpointing(1000)
// 模式為準確一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 兩次 Checkpoint 之間最少間隔 500毫秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 過程超時時間為 60000毫秒,即1分鐘視為超時失敗
env.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一時間只允許1個Checkpoint的操作在執行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
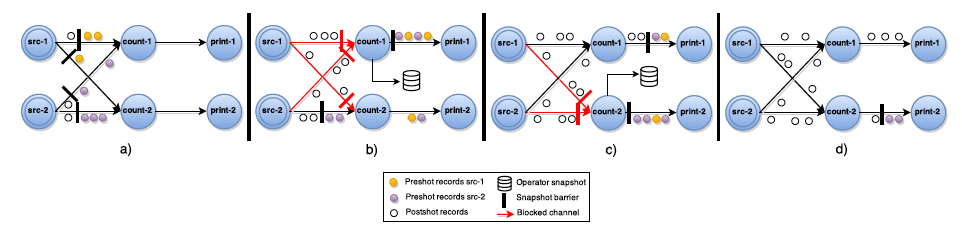
1、Asynchronous Barrier Snapshots(ABS)
非同步屏障快照演算法,這個演算法基本上是Chandy-Lamport演算法的變體,針對DAG(有向無環圖)的ABS演算法執行流程如下所示:
- Barrier周期性的被註入到所有的Source中,Source節點看到Barrier後,會立即記錄自己的狀態,然後將Barrier發送到Transformation Operator。
- 當Transformation Operator從某個input channel收到Barrier後,它會立刻Block住這條通道,直到所有的input channel都收到Barrier,這個等待的過程就叫做屏障對齊(barrier alignment),此時該Operator就會記錄自身狀態,並向自己的所有output channel廣播Barrier。
- Sink接受Barrier的操作流程與Transformation Oper一樣。當所有的Barrier都到達Sink之後,並且所有的Sink也完成了Checkpoint,這一輪Snapshot就完成了。
下麵這個圖展示了一個ABS演算法的執行過程:
2、Exactly-Once vs At-Least-Once
- 上面講到的屏障對齊過程是Flink exactly-once語義的基礎,因為屏障對齊能夠保證多輸入流的運算元正常處理不同checkpoint區間的數據,避免它們發生交叉,即不會有數據被處理兩次。
- 但是對齊過程需要時間,有一些對延遲特別敏感的應用可能對準確性的要求沒有那麼高。所以Flink也允許在StreamExecutionEnvironment.enableCheckpointing()方法里指定At-Least-Once語義,會取消屏障對齊,即運算元收到第一個輸入的屏障之後不會阻塞,而是觸發快照。這樣一來,部分屬於檢查點n + 1的數據也會包括進檢查點n的數據里, 當恢復時,這部分交叉的數據就會被重覆處理。
7)Watermark
Flink 程式並 不能自動提取數據源中哪個欄位/標識為數據的事件時間,從而也就無法自己定義 Watermark 。開發人員需要通過 Flink 提供的 API 來 提取和定義 Timestamp/Watermark,可以在 數據源或者數據流中 定義。
1、自定義數據源設置 Timestamp/Watermark
自定義的數據源類需要繼承並實現 SourceFunction[T] 介面,其中 run 方法是定義數據生產的地方:
//自定義的數據源為自定義類型MyType
class MySource extends SourceFunction[MyType]{
//重寫run方法,定義數據生產的邏輯
override def run(ctx: SourceContext[MyType]): Unit = {
while (/* condition */) {
val next: MyType = getNext()
//設置timestamp從MyType的哪個欄位獲取(eventTimestamp)
ctx.collectWithTimestamp(next, next.eventTimestamp)
if (next.hasWatermarkTime) {
//設置watermark從MyType的那個方法獲取(getWatermarkTime)
ctx.emitWatermark(new Watermark(next.getWatermarkTime))
}
}
}
}
2、在數據流中設置 Timestamp/Watermark
在這裡插入代碼片在數據流中,可以設置 stream 的 Timestamp Assigner ,該 Assigner 將會接收一個 stream,並生產一個帶 Timestamp和Watermark 的新 stream。
val withTimestampsAndWatermarks: DataStream[MyEvent] = stream.assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks())
8)廣播狀態(Broadcast State)
-
和 Spark 中的廣播變數一樣,Flink 也支持在各個節點中各存一份小數據集,所在的計算節點實例可在本地記憶體中直接讀取被廣播的數據,可以避免Shuffle提高並行效率。
-
廣播狀態(Broadcast State)的引入是為了支持一些來自一個流的數據需要廣播到所有下游任務的情況,它存儲在本地,用於處理其他流上的所有傳入元素。
// key the shapes by color
KeyedStream<Item, Color> colorPartitionedStream = shapeStream.keyBy(new KeySelector<Shape, Color>(){...});
// a map descriptor to store the name of the rule (string) and the rule itself.
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>("RulesBroadcastState",BasicTypeInfo.STRING_TYPE_INFO, TypeInformation.of(new TypeHint<Rule>() {}));
// broadcast the rules and create the broadcast state
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
DataStream<Match> output = colorPartitionedStream.connect(ruleBroadcastStream).process(new KeyedBroadcastProcessFunction<Color, Item, Rule, String>(){...});
9)Operator Chain
-
Flink作業中,可以指定相關的chain將相關性非常強的轉換操作(operator)綁定在一起,使得上下游的Task在同一個Pipeline中執行,避免因為數據在網路或者線程之間傳輸導致的開銷。
-
一般情況下Flink在Map類型的操作中預設開啟 Operator Chain 以提高整體性能,開發人員也可以根據需要創建或者禁止 Operator Chain 對任務進行細粒度的鏈條控制。
//創建 chain
dataStream.filter(...).map(...).startNewChain().map(...)
//禁止 chain
dataStream.map(...).disableChaining()
創建的鏈條只對當前的操作符和之後的操作符有效,不不影響其他操作,如上代碼只針對兩個map操作進行鏈條綁定,對前面的filter操作無效,如果需要可以在filter和map之間使用 startNewChain方法即可。
10)Side Output
除了從DataStream操作的結果中獲取主數據流之外,Flink還可以產生任意數量額外的側輸出(Side Output)結果流。側輸出結果流的數據類型不需要與主數據流的類型一致,不同側輸出流的類型也可以不同。當要拆分數據流時(通常必須複製流),從每個流過濾出不想擁有的數據時Side Output將非常有用。
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// 將數據發送到常規輸出中
out.collect(value);
// 將數據發送到側輸出中
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
四、對比常用的實時計算框架
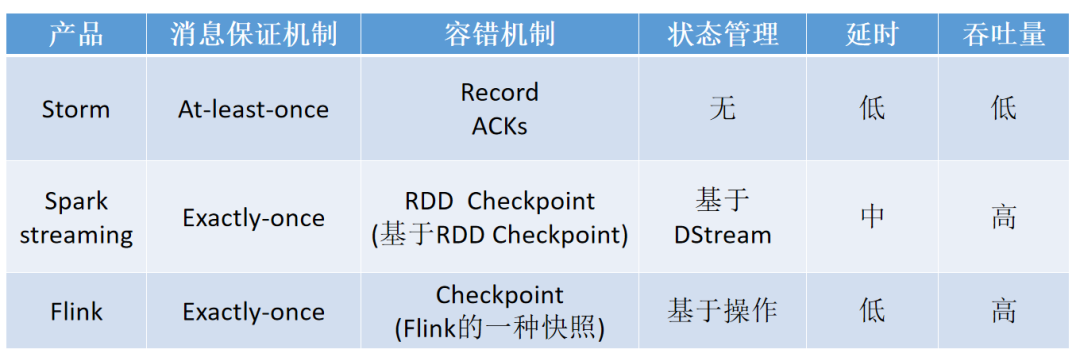
- Flink 是有狀態的和容錯的,可以在維護一次應用程式狀態的同時無縫地從故障中恢復。
- 它支持大規模計算能力,能夠在數千個節點上併發運行。
- 它具有很好的吞吐量和延遲特性。
- 同時,Flink 提供了多種靈活的視窗函數。
- Flink 在流式計算里屬於真正意義上的單條處理,每一條數據都觸發計算,而不是像 Spark 一樣的 Mini Batch 作為流式處理的妥協。
- Flink的容錯機制較為輕量,對吞吐量影響較小,而且擁有圖和調度上的一些優化,使得 Flink 可以達到很高的吞吐量。
- 而 Strom 的容錯機制需要對每條數據進行ack,因此其吞吐量瓶頸也是備受詬病。
五、Flink環境部署(Flink On Yarn)
下載地址:http://flink.apache.org/downloads.html
1)Local模式
對於 Local 模式來說,JobManager 和 TaskManager 會公用一個 JVM 來完成 Workload。如果要驗證一個簡單的應用,Local 模式是最方便的。實際企業中大多使用Flink On Yarn模式,而local模式只是將安裝包解壓啟動(./bin/start-cluster.sh)即可。其實local模式就是單節點,master和woker節點都是同一臺機器。
Local Cluster模式是開箱即用的,直接解壓安裝包,然後啟動即可。
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/flink/flink-1.14.2/flink-1.14.2-bin-scala_2.12.tgz
# 解壓
$ tar -zxvf flink-1.14.2-bin-scala_2.12.tgz -C /opt/bigdata/hadoop/server/
# 進入bin目錄運行啟動腳本
$ cd /opt/bigdata/hadoop/server/flink-1.14.2
$ ./bin/start-cluster.sh
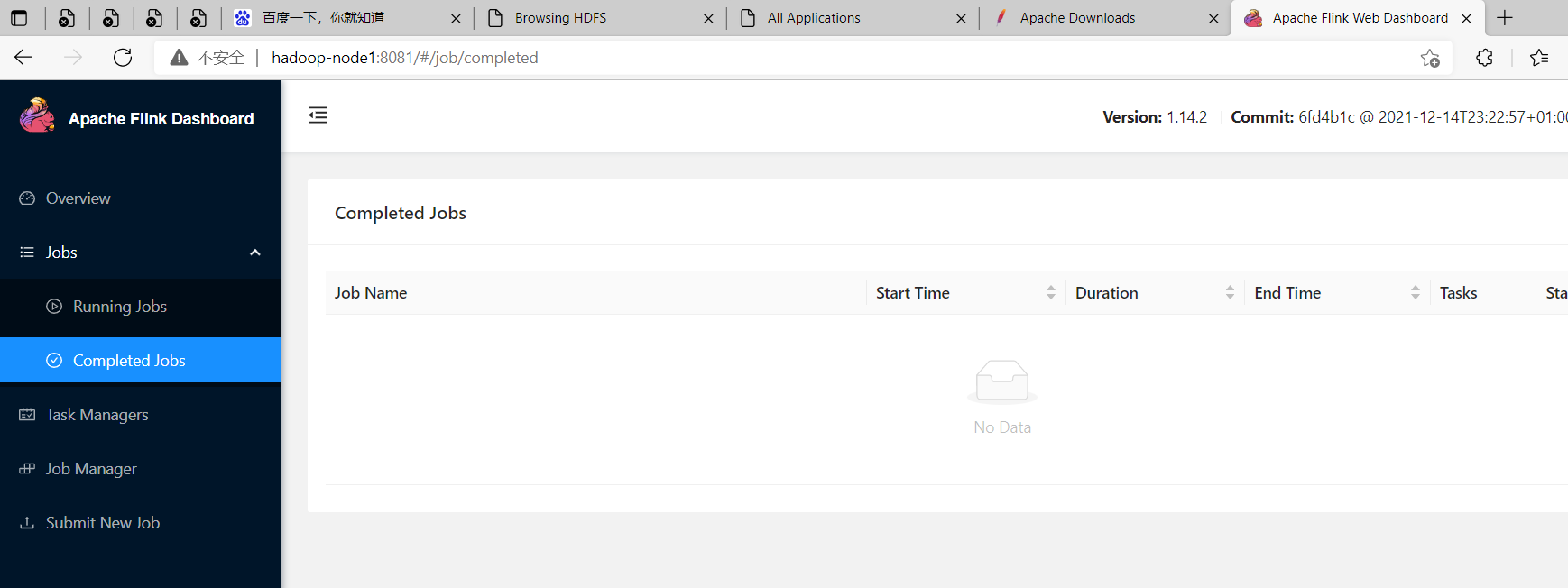
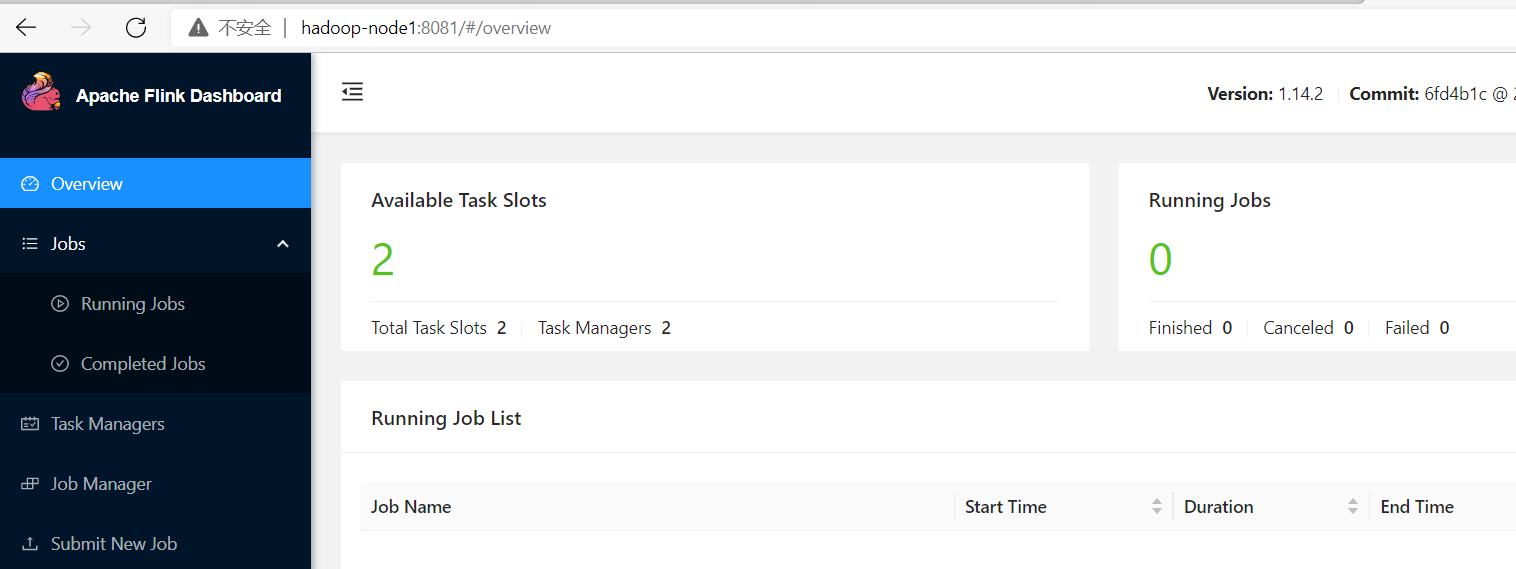
打開瀏覽器輸入http://IP:8081,查看WEBUI監控界面
我這裡地址:http://hadoop-node1:8081
2)Standalone模式
Stanalone CLuster是一種獨立的集群模式,集群運行不需要依賴外部系統,完全自己獨立進行管理。
1、機器及角色劃分
| 機器IP | 機器名 | 節點類型 |
|---|---|---|
| 192.168.0.113 | hadoop-node1 | Master |
| 192.168.0.114 | hadoop-node2 | Worker |
| 192.168.0.115 | hadoop-node3 | Worker |
1、下載
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/flink/flink-1.14.2/flink-1.14.2-bin-scala_2.12.tgz
# 解壓
$ tar -zxvf flink-1.14.2-bin-scala_2.12.tgz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/flink-1.14.2
2、修改配置文件
- 修改flink-conf.yaml文件
$ cd /opt/bigdata/hadoop/server/flink-1.14.2/conf
$ vi flink-conf.yaml
## jobmanager節點地址,也是master節點地址
jobmanager.rpc.address: hadoop-node1
其它使用預設配置,其中有一些HA高可用、容錯、安全、HistoryServer相關配置,按需進行配置即可,HistoryServer需單獨運行啟動腳本來啟動服務。
- 修改masters文件
把預設的localhost:8081刪掉,添加如下內容:
hadoop-node1:8081
- 修改workers文件,內容如下:
把預設的localhost刪掉,添加如下內容:
hadoop-node2
hadoop-node3
3、將安裝目錄複製到另外兩台節點
$ cd /opt/bigdata/hadoop/server
$ scp -r flink-1.14.2 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r flink-1.14.2 hadoop-node3:/opt/bigdata/hadoop/server/
4、配置環境變數,修改/etc/profile
在/etc/profile文件中添加如下內容(所有節點):
export FLINK_HOME=/opt/bigdata/hadoop/server/flink-1.14.2
export PATH=$PATH:$FLINK_HOME/bin
使配置文件生效
$ source /etc/profile
5、啟動集群
$ start-cluster.sh

3)On Yarn模式(推薦)
On Yarn官方文檔:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/resource-providers/yarn/
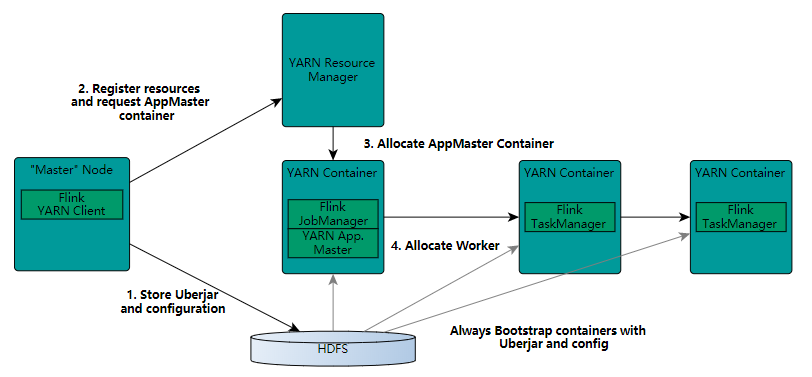
YARN模式是使用YARN做為Flink運行平臺,JobManager、TaskManager、用戶提交的應用程式都運行在YARN上。
FLink on yarn 有三種運行模式:
- yarn-session模式(Seesion Mode)
- yarn-cluster模式(Per-Job Mode)
- Application模式(Application Mode)
官方介紹:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/overview/
下載
$ cd /opt/bigdata/hadoop/software
$ wget https://dlcdn.apache.org/flink/flink-1.14.2/flink-1.14.2-bin-scala_2.12.tgz
# 解壓
$ tar -zxvf flink-1.14.2-bin-scala_2.12.tgz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/flink-1.14.2
配置
在/etc/profile文件中追加如下內容:
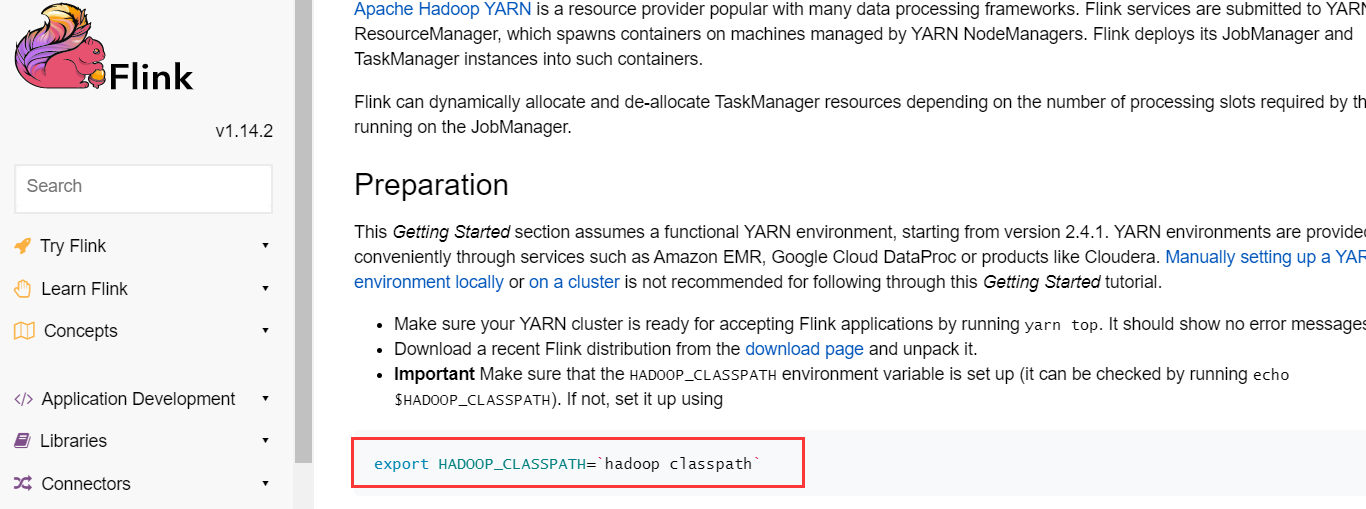
export FLINK_HOME=/opt/bigdata/hadoop/server/flink-1.14.2
export PATH=$PATH:$FLINK_HOME/bin
# 上面兩句如果加過,可以忽略
export HADOOP_CLASSPATH=`hadoop classpath`
載入配置
$ source /etc/profile
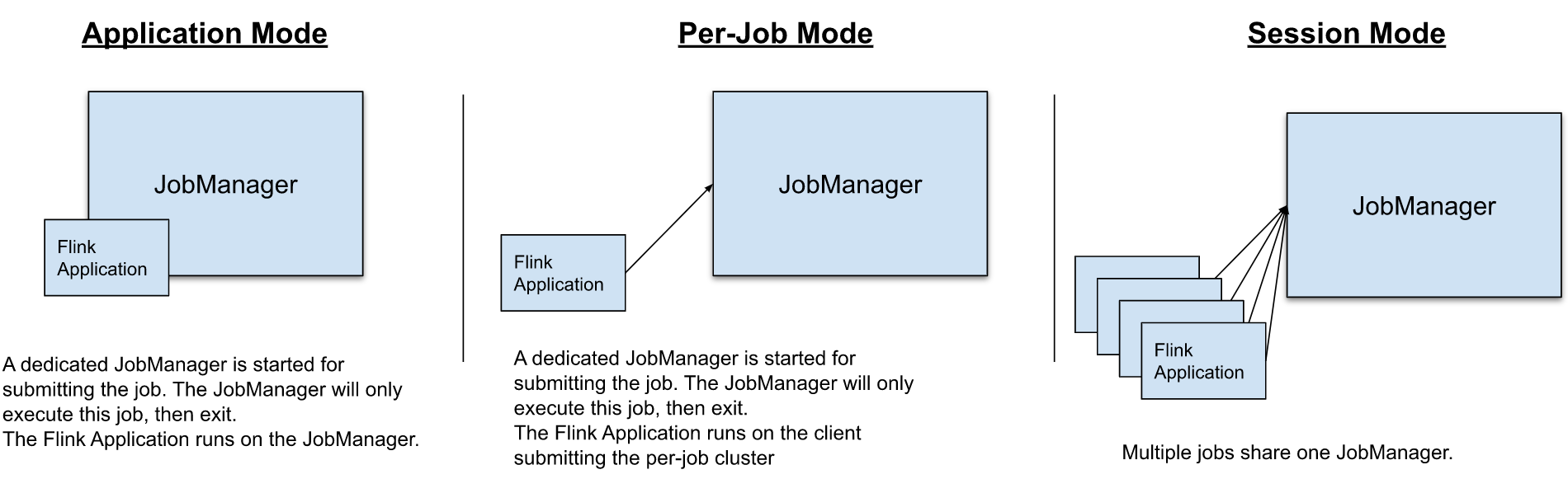
1、yarn-session模式(Seesion Mode)
Yarn-session模式下,首先向Yarn提交一個長時運行的空應用,運行起來之後,任務跑完集群也不釋放,可以重覆使用在Yarn上開啟的Flink集群,也稱為共用型集群,適合小任務。
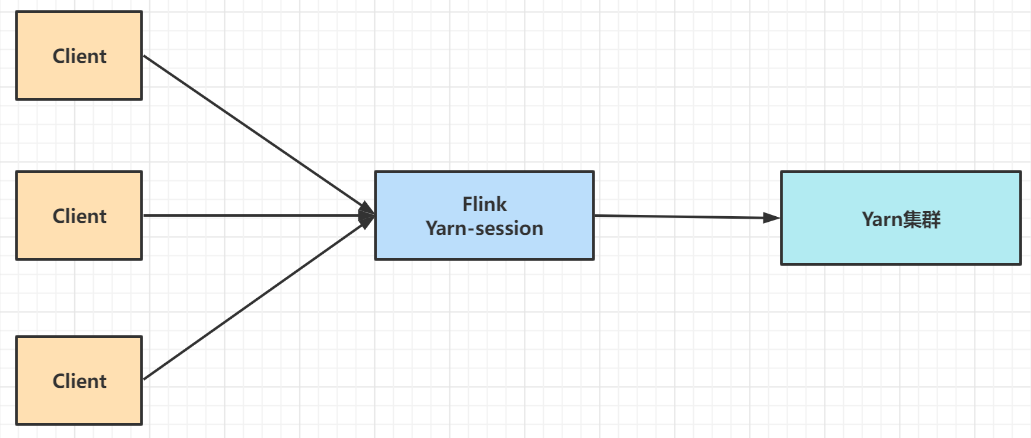
實驗
第一種模式分為兩步:yarn-session.sh(啟動,開闢/申請資源)+flink run(提交任務)
- 【第一步】開源資源,使用如下命令:
$ yarn-session.sh -n 2 -jm 1024 -tm 1024 -d
### 參數解釋:
#-n 2 表示指定兩個容器
# -jm 1024 表示jobmanager 1024M記憶體
# -tm 1024表示taskmanager 1024M記憶體
#-d 任務後臺運行
### 如果你不希望flink yarn client一直運行,也可以啟動一個後臺運行的yarn session。使用這個參數:-d 或者 --detached。在這種情況下,flink yarn client將會只提交任務到集群然後關閉自己。註意:在這種情況下,無法使用flink停止yarn session,必須使用yarn工具來停止yarn session。
# yarn application -kill $applicationId
#-nm,--name YARN上為一個自定義的應用設置一個名字
#-q,--query 顯示yarn中可用的資源 (記憶體, cpu核數)
#-z,--zookeeperNamespace <arg> 針對HA模式在zookeeper上創建NameSpace
#-id,--applicationId <yarnAppId> YARN集群上的任務id,附著到一個後臺運行的yarn session中
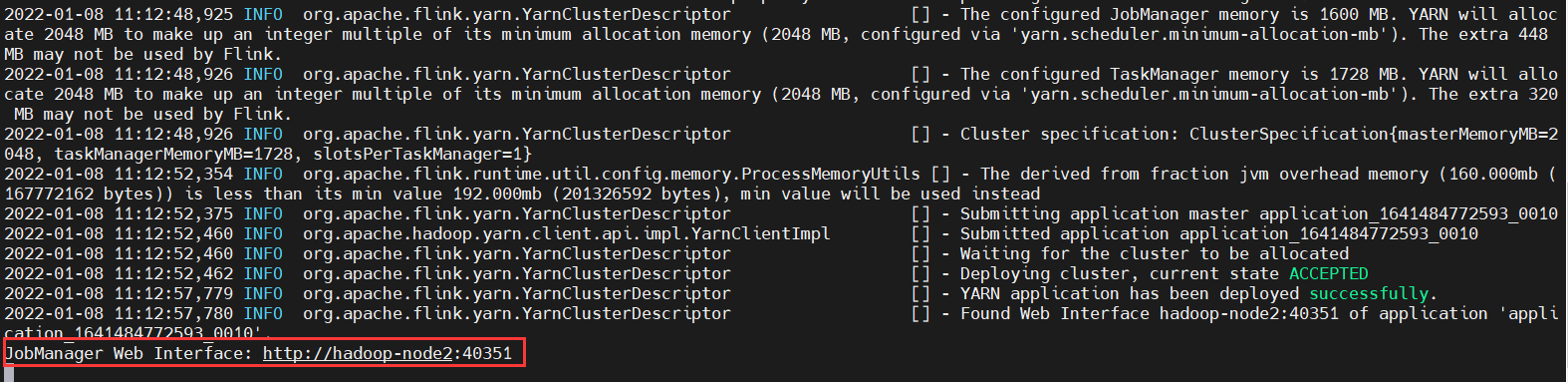
JobManager Web Interface: http://hadoop-node2:41787,埠是隨機的。

通過yarn入口訪問flink
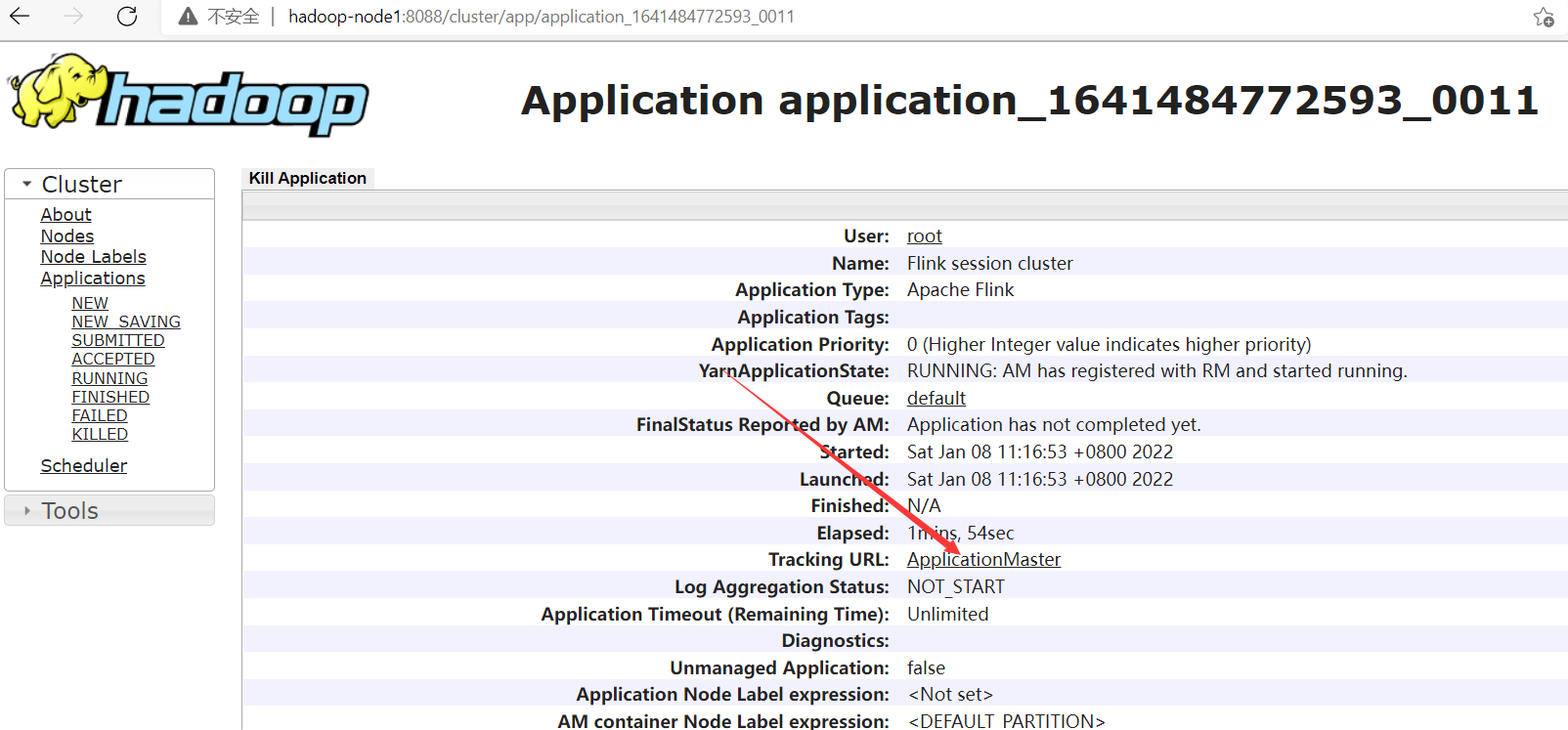
- 【第二步】提交任務
為了進行測試,我們對Flink目錄下的LICENSE文件進行詞頻統計
$ cd $FLINK_HOME
$ hadoop fs -put LICENSE /
$ hadoop fs -ls /LICENSE
# 提交任務
$ flink run ./examples/batch/WordCount.jar -input hdfs://hadoop-node1:8082/LICENSE -output hdfs://hadoop-node1:8082/wordcount-result.txt
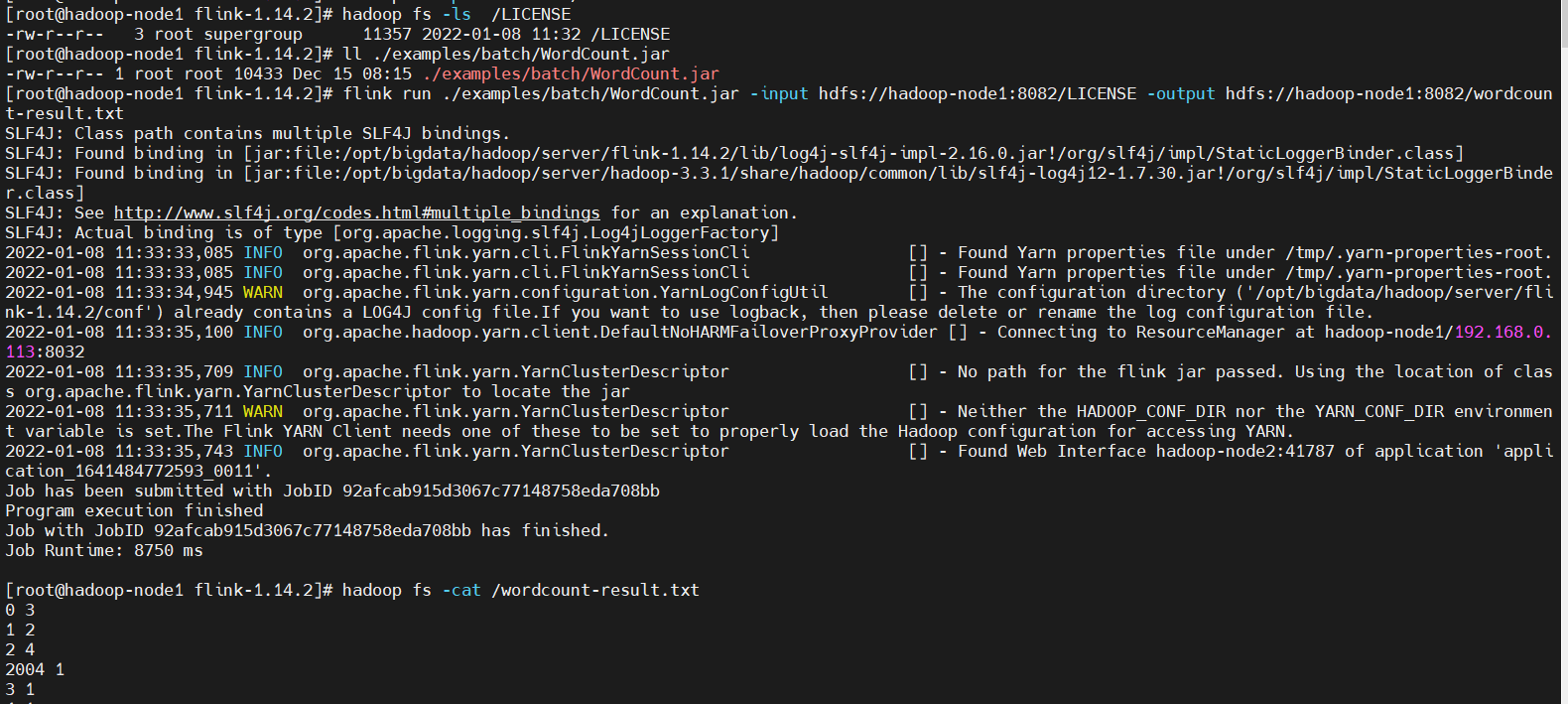
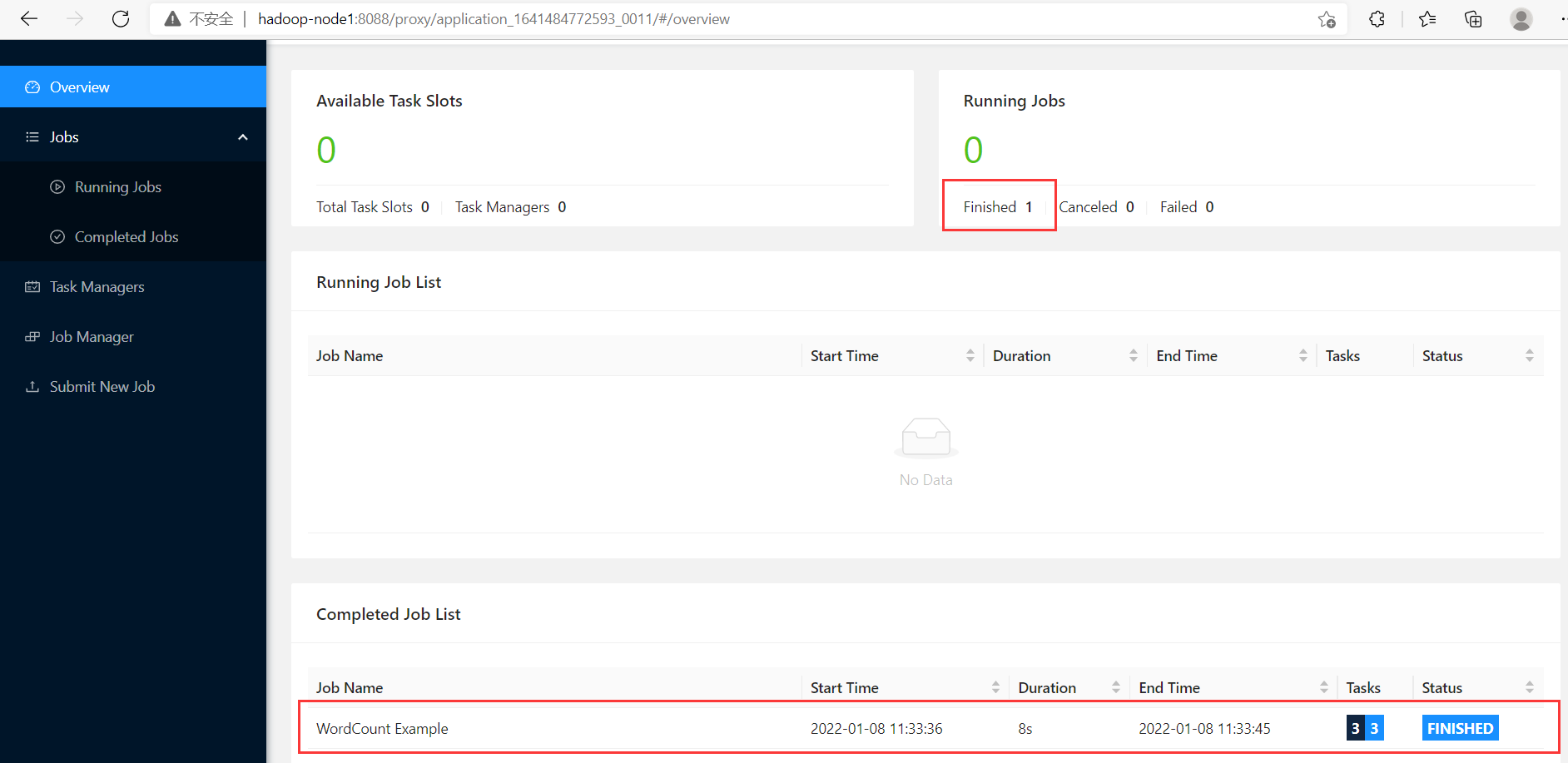
再提交一次任務
【註意】-output一定是不存在的文件,有flink自動創建寫入
$ flink run ./examples/batch/WordCount.jar -input hdfs://hadoop-node1:8082/LICENSE -output hdfs://hadoop-node1:8082/wordcount-result2.txt
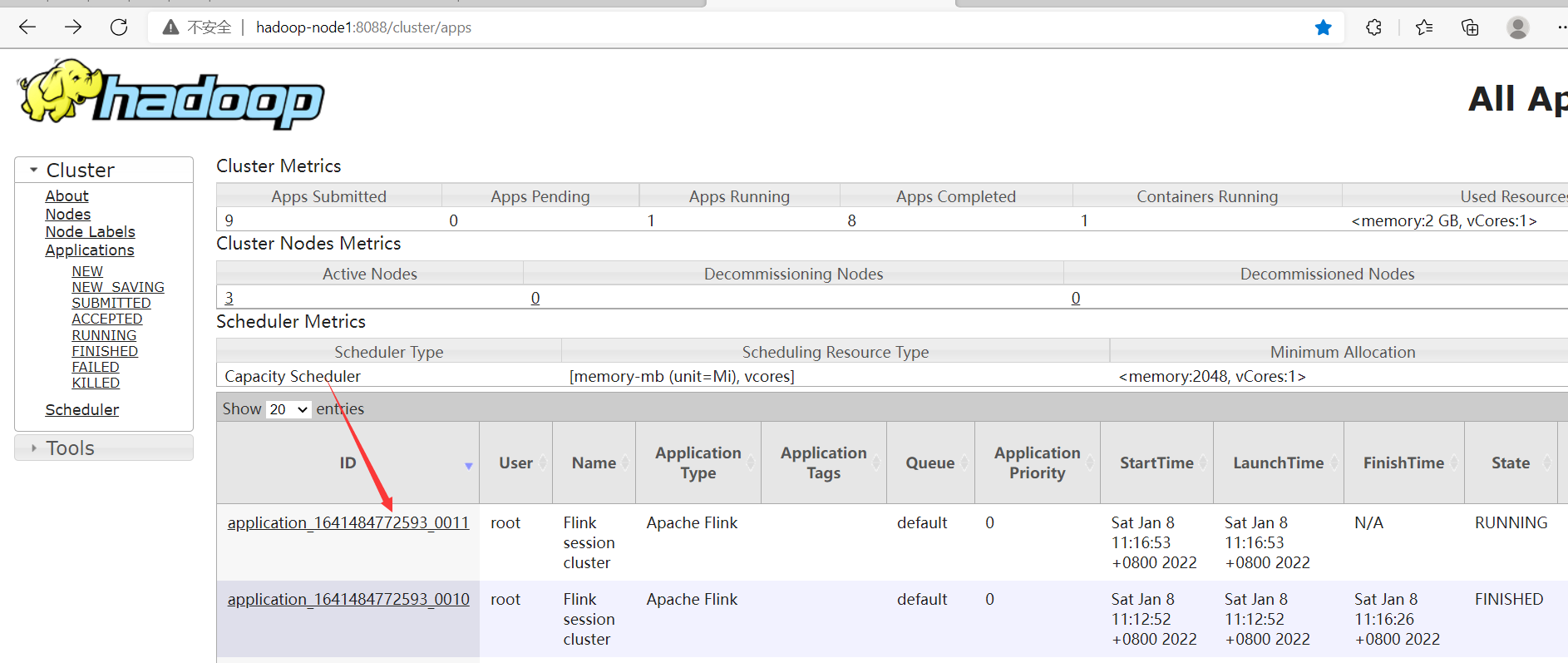
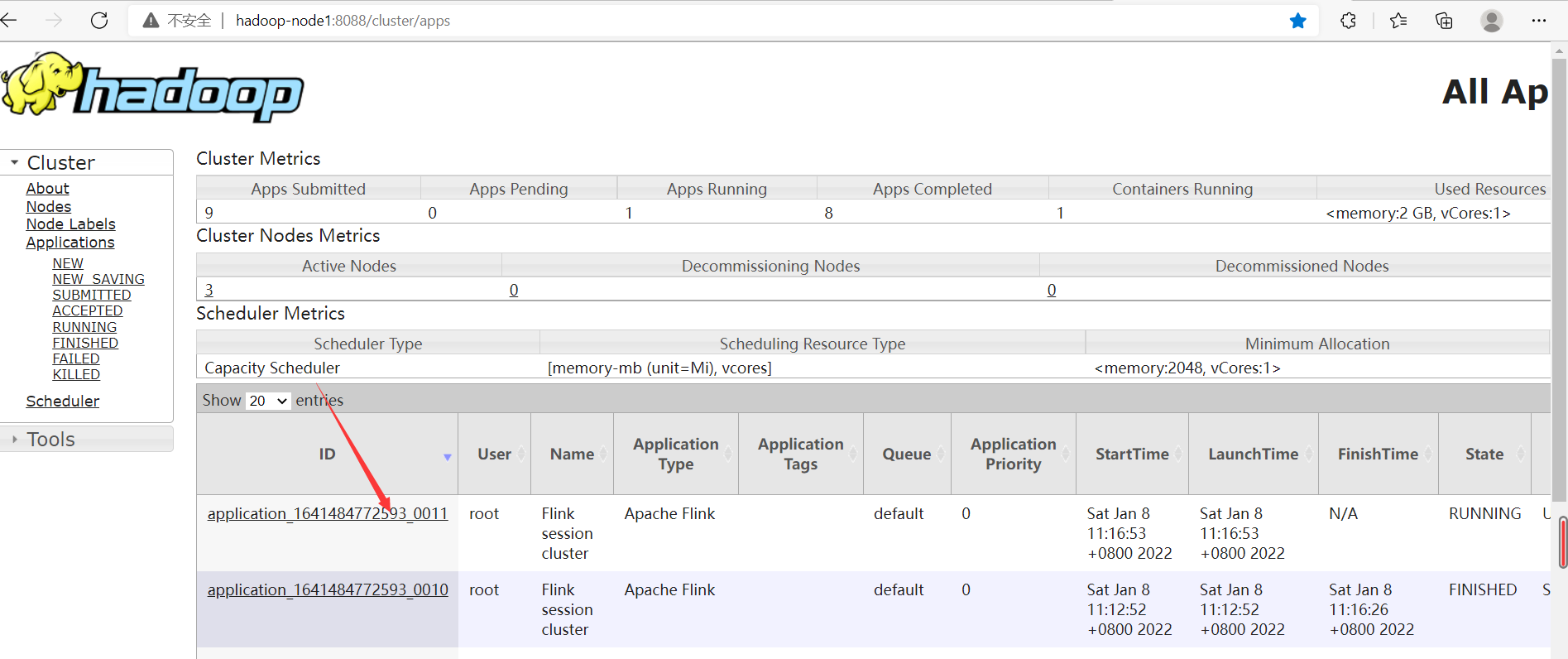
發現現在已經有兩個跑完的任務了,但是只有一個flink集群,從而驗證了yarn-session模式
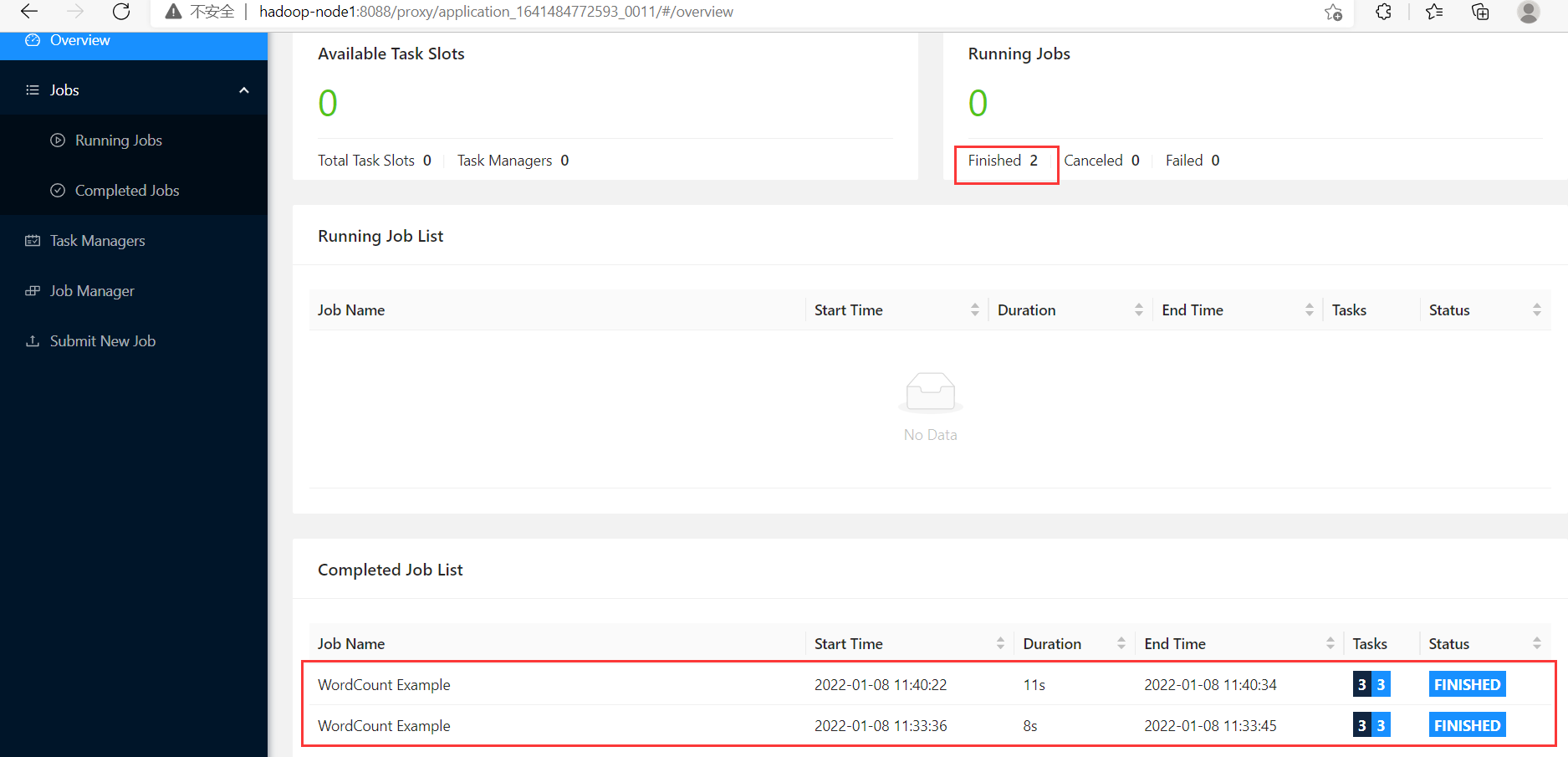
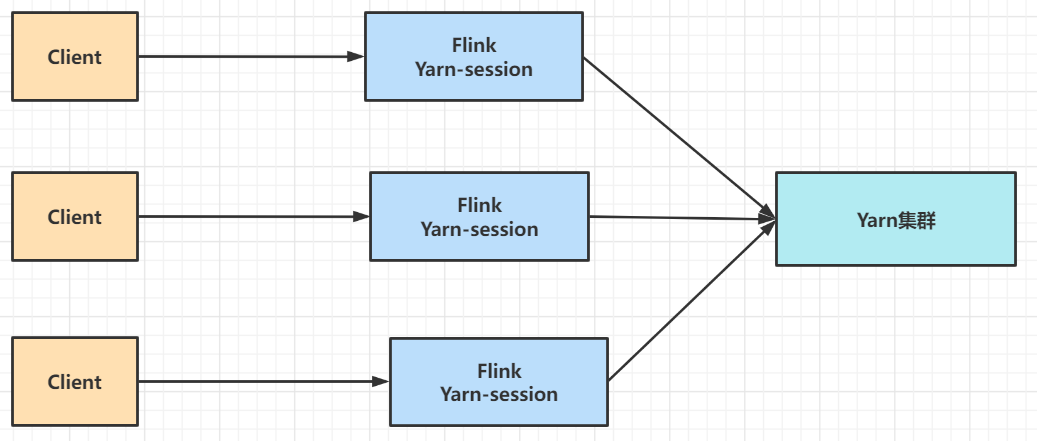
2、yarn-cluster模式(Per-Job Mode)【推薦】
Yarn-cluster模式下,每個任務單獨在Yarn上啟動一套Flink集群,適合大任務,運行完後結束,集群釋放,資源釋放,再有任務,會再起新的Flink集群,需要頻繁的在Yanr上開啟Flink集群,集群相互獨立,適合大任務。
當然除了on yarn模式,還有on k8s,有興趣的小伙伴,可以試試,當時目前企業里用的最多的還是on yarn模式,但是現在不是流行容器化嘛,以後很大可能會慢慢轉到 on k8s模式。
實驗
第二種模式其實也分為兩個部分,依然是開闢資源和提交任務,但是在Job模式下,這兩步都合成一個命令了。
$ cd $FLINK_HOME
$ flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
# 查看幫助
$ flink --help
### 參數詳解,這裡只列出了部分參數
Options for yarn-cluster mode:
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <arg> Set to yarn-cluster to use YARN
execution mode.
-yat,--yarnapplicationType <arg> Set a custom application type for the
application on YARN
-yD <property=value> use value for given property
-yd,--yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,--yarnhelp Help for the Yarn session CLI.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-yj,--yarnjar <arg> Path to Flink jar file
-yjm,--yarnjobManagerMemory <arg> Memory for JobManager Container with
optional unit (default: MB)
-ynl,--yarnnodeLabel <arg> Specify YARN node label for the YARN
application
-ynm,--yarnname <arg> Set a custom name for the application
on YARN
-yq,--yarnquery Display available YARN resources
(memory, cores)
-yqu,--yarnqueue <arg> Specify YARN queue.
-ys,--yarnslots <arg> Number of slots per TaskManager
-yt,--yarnship <arg> Ship files in the specified directory
(t for transfer)
-ytm,--yarntaskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yz,--yarnzookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
【溫馨提示】上面命令中沒有指定-input 和 -output,這是由於有預設的數據集和輸出方式,看看效果。
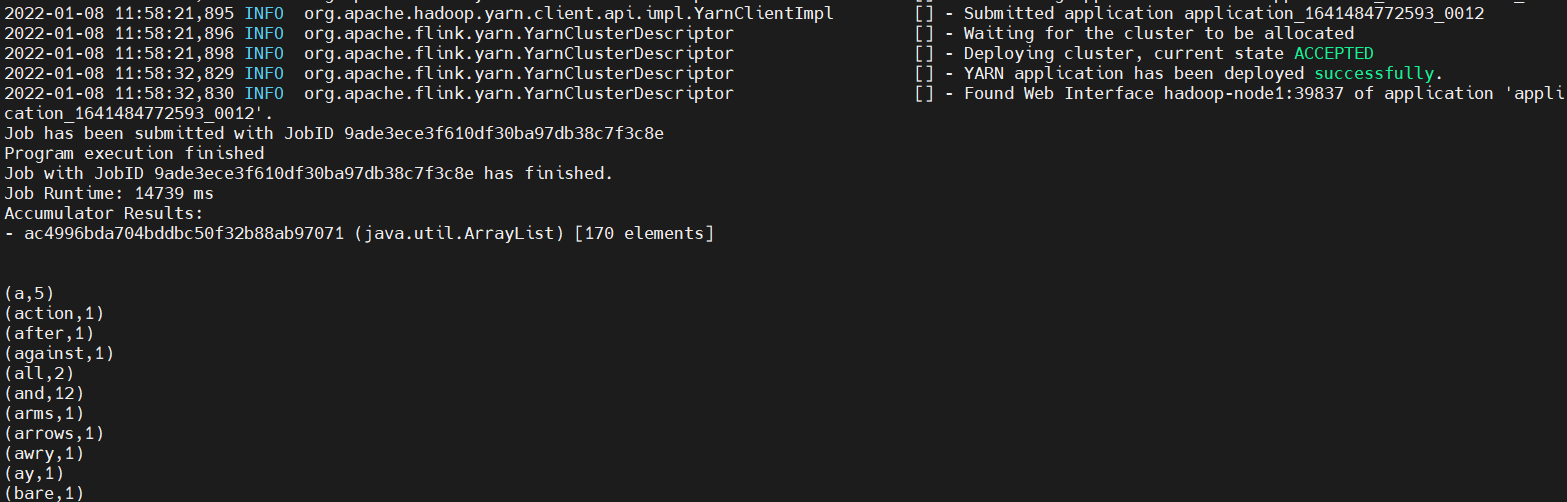
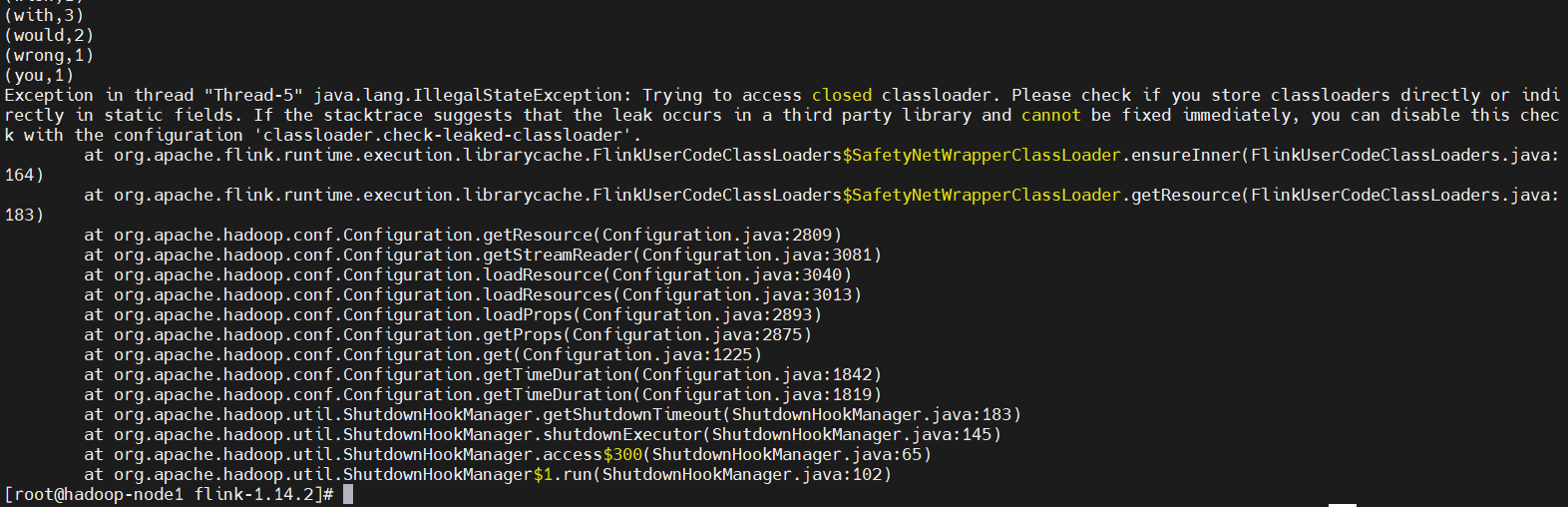
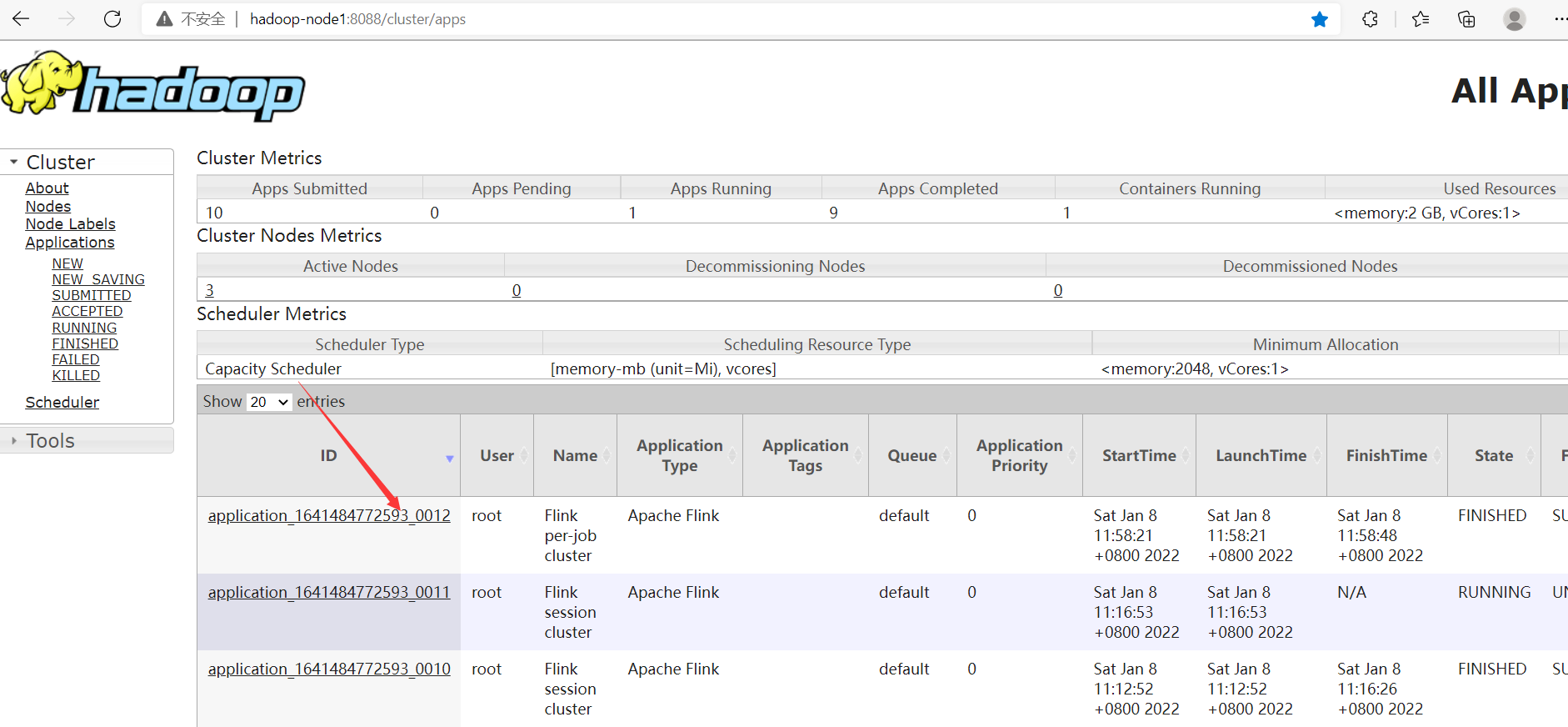
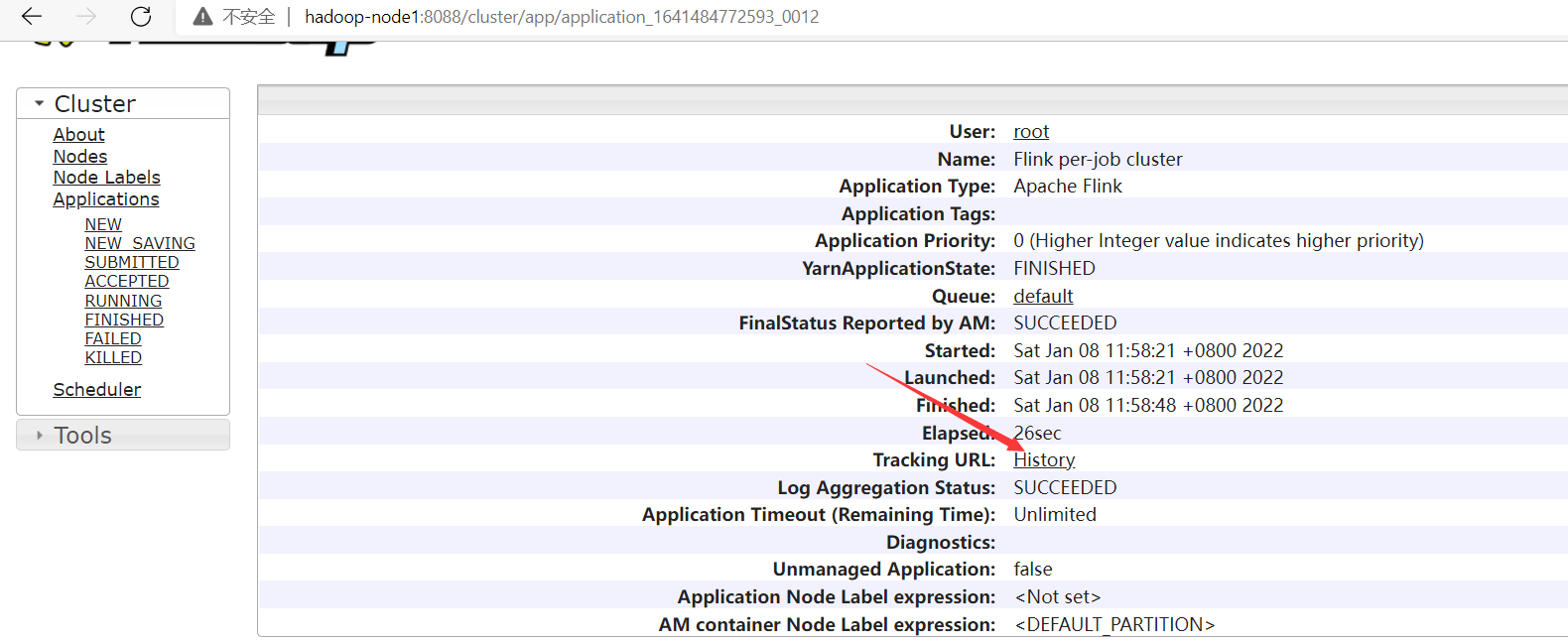
發現查看不了History,是因為沒起History服務,下麵啟動這個服務
historyserver簡介與配置
History Server允許查詢由JobManager歸檔的已完成作業的狀態和統計信息。已完成作業的歸檔在JobManager上進行,JobManager會將歸檔的作業信息upload到文件系統目錄,這個文件系統可以是本地文件系統、HDFS、H3等,這個目錄是可以在配置文件中指定的。然後還需要配置History Server去掃描這個目錄,並且可以配置掃描的間隔時間。
配置historyserver
$ cd $FLINK_HOME/bin
# 選創建目錄
$ hdfs://hadoop-node1:8082/flink/completed-jobs/
# conf/flink-conf.yaml
# 指定由JobManager歸檔的作業信息所存放的目錄,這裡使用的是HDFS
jobmanager.archive.fs.dir: hdfs://hadoop-node1:8082/flink/completed-jobs/
# 指定History Server掃描哪些歸檔目錄,多個目錄使用逗號分隔
historyserver.archive.fs.dir: hdfs://hadoop-node1:8082/flink/completed-jobs/
# 指定History Server間隔多少毫秒掃描一次歸檔目錄
historyserver.archive.fs.refresh-interval: 10000
# History Server所綁定的ip,hadoop-node1代表允許所有ip訪問
historyserver.web.address: hadoop-node1
# 指定History Server所監聽的埠號,預設埠是8082
historyserver.web.port: 9082
啟動historyserver
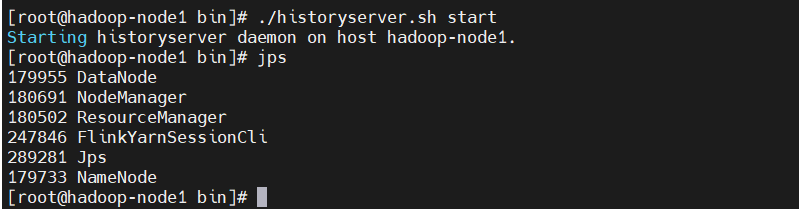
$ ./historyserver.sh start
$ jps
重新跑一次任務
$ flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
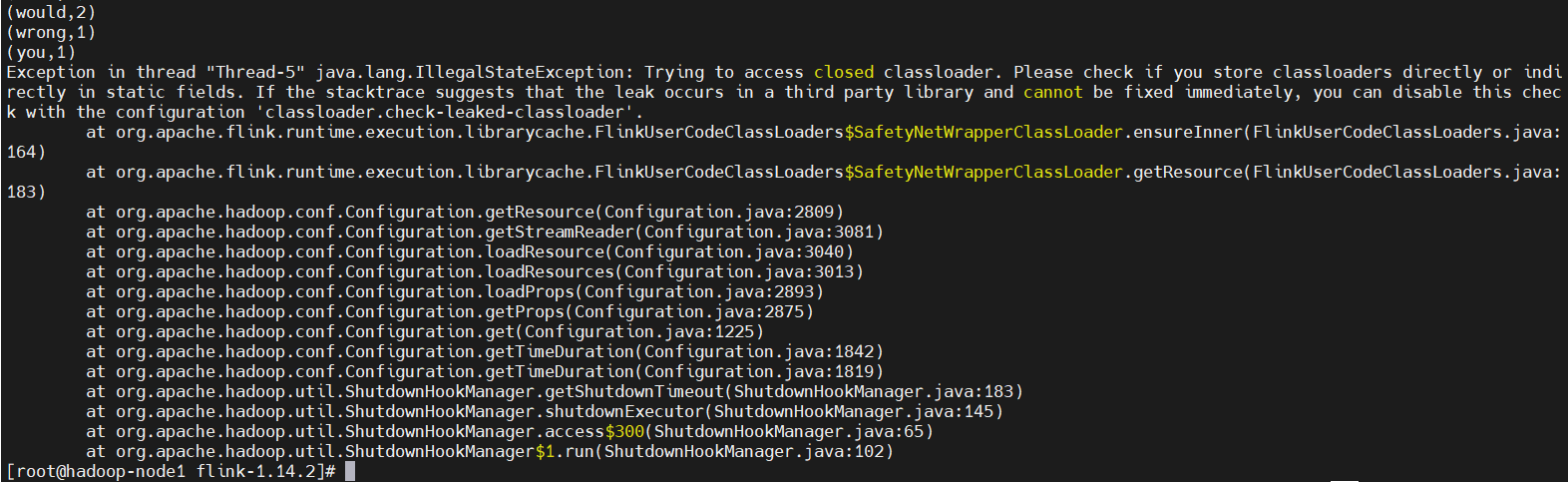

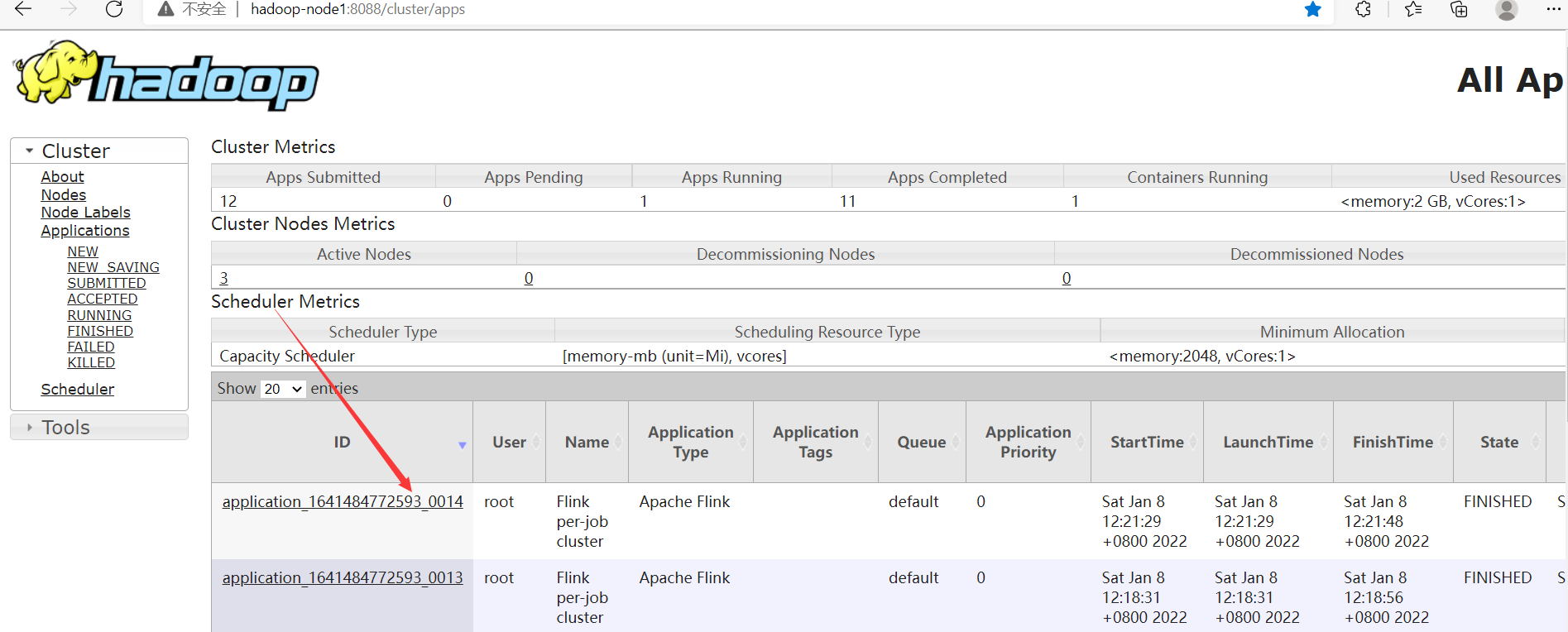
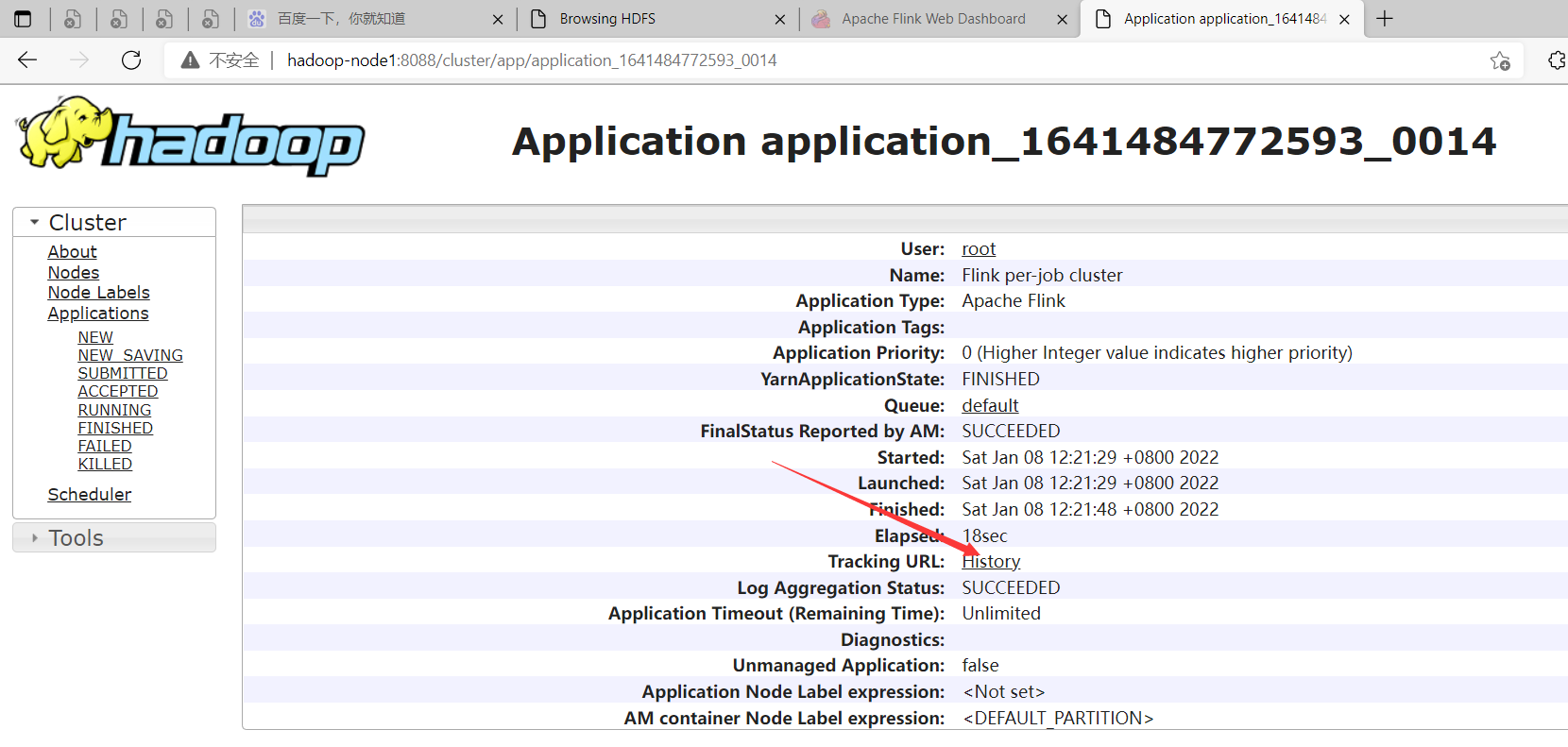
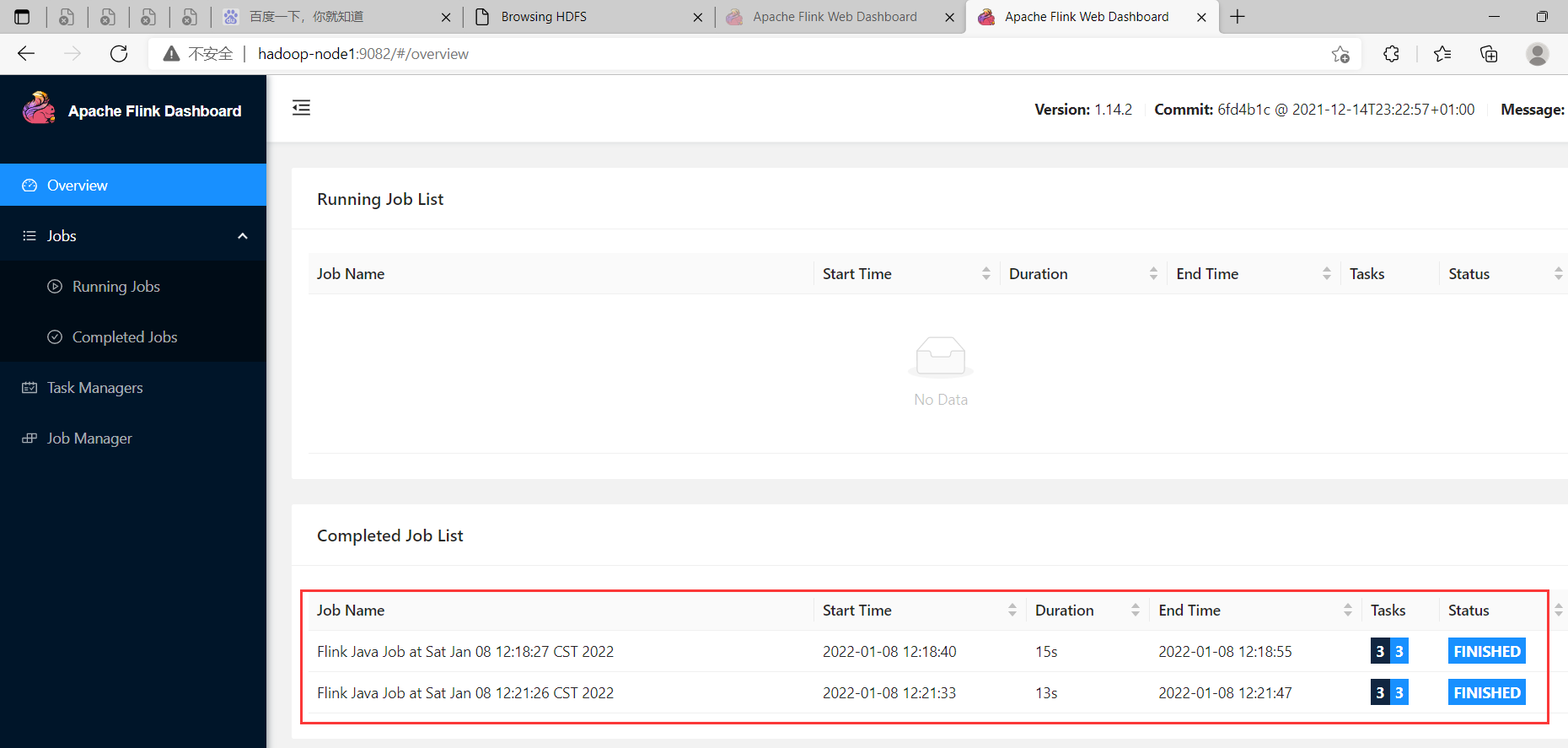
查看正在運行任務的日誌,yarn容器退出之後,就下麵入口就訪問不了了。
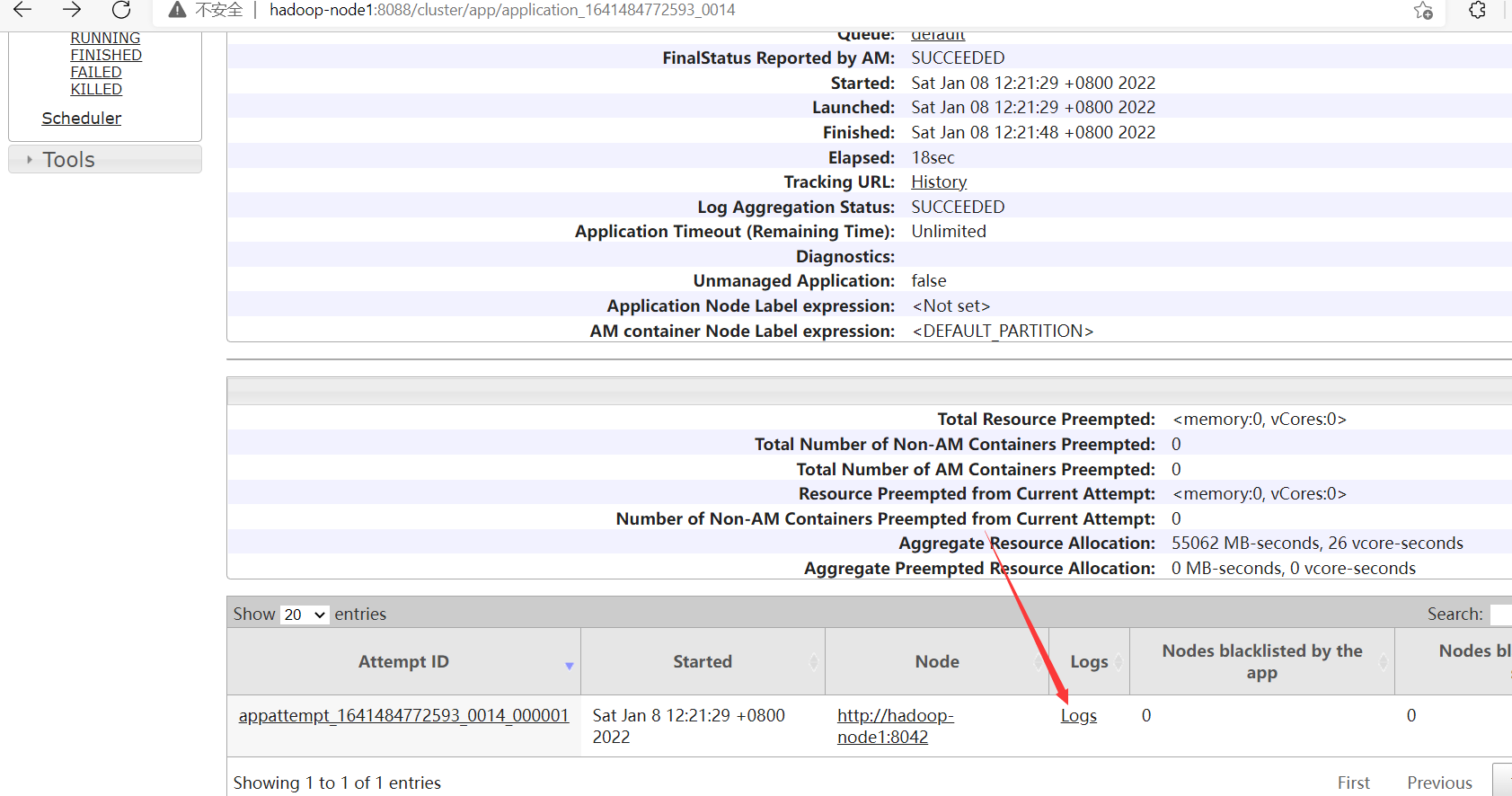
3、Application模式(Application Mode)
Application模式的由來
其實前面兩種模式client端還是需要乾三件事情的:
- 獲取作業所需的依賴項;
- 通過執行環境分析並取得邏輯計劃,即StreamGraph→JobGraph;
- 將依賴項和JobGraph上傳到集群中。
只有在這些都完成之後,才會通過env.execute()方法觸發Flink運行時真正地開始執行作業。試想,如果所有用戶都在Deployer上提交作業,較大的依賴會消耗更多的帶寬,而較複雜的作業邏輯翻譯成JobGraph也需要吃掉更多的CPU和記憶體,客戶端的資源反而會成為瓶頸——不管Session還是Per-Job模式都存在此問題。為瞭解決它,社區在傳統部署模式的基礎上實現了Application模式。
Application模式概述
Application模式原本需要客戶端做的三件事被轉移到了JobManager里,也就是說main()方法在集群中執行(入口點位於ApplicationClusterEntryPoint),Deployer只需要負責發起部署請求了。另外,如果一個main()方法中有多個env.execute()/executeAsync()調用,在Application模式下,這些作業會被視為屬於同一個應用,在同一個集群中執行(如果在Per-Job模式下,就會啟動多個集群)。可見,Application模式本質上是Session和Per-Job模式的折衷。
實驗
$ cd $FLINK_HOME
$ ./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dparallelism.default=10 \
-Dyarn.application.name="MyFlinkApp" \
./examples/batch/WordCount.jar
【溫馨提示】
-t參數用來指定部署目標,目前支持YARN(yarn-application)和K8S(kubernetes-application)。-D參數則用來指定與作業相關的各項參數,具體可參見官方文檔。
六、Spark與Flink對比
可以先看我之前寫的Spark文章:https://blog.csdn.net/qq_35745940/article/details/122011664
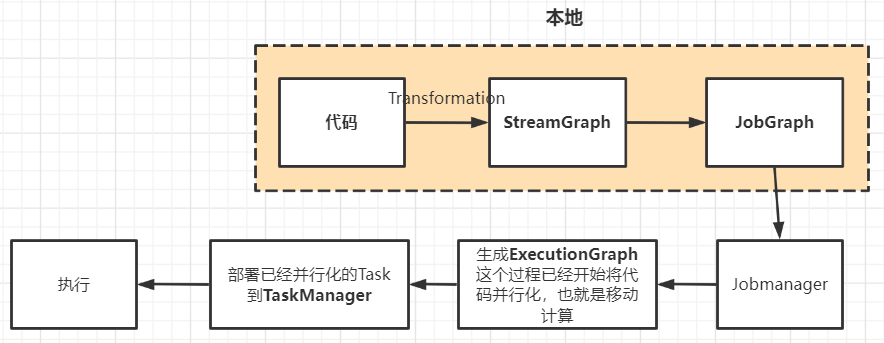
Flink執行流程圖如下:
| 對比維度 | Spark | Flink |
|---|---|---|
| 設計理念 | Spark的技術理念是使用微批來模擬流的計算,基於Micro-batch,數據流以時間為單位被切分為一個個批次,通過分散式數據集RDD進行批量處理,是一種偽實時。 | Flink是基於事件驅動的,是面向流的處理框架, Flink基於每個事件一行一行地流式處理,是真正的實時流式計算, 另外他也可以基於流來模擬批進行計算實現批處理。 |
| 架構方面 | Spark在運行時的主要角色包括:Master、Worker、Driver、Executor。 | Flink 在運行時主要包含:Jobmanager、Taskmanager和Slot。 |
| 任務調度 | Spark Streaming 連續不斷的生成微小的數據批次,構建有向無環圖DAG,根據DAG中的action操作形成job,每個job有根據窄寬依賴生成多個stage。 | 使用DataStream API開發的應用程式,首先被轉換為Transformation,再被映射為StreamGraph,在客戶端進行StreamGraph、JobGraph的轉換,提交JobGraph到Flink集群後,Flink集群負責將JobGraph轉換為ExecutionGraph,之後進入調度執行階段。 |
| 時間機制 | Spark Streaming 支持的時間機制有限,只支持處理時間。使用processing time模擬event time必然會有誤差, 如果產生數據堆積的話,誤差則更明顯。 | flink支持三種時間機制:事件時間,註入時間,處理時間,同時支持 watermark 機制處理遲到的數據,說明Flink在處理亂序大實時數據的時候,更有優勢。 |
| 容錯機制 | SparkStreaming的容錯機制是基於RDD的容錯機制,會將經常用的RDD或者對寬依賴加Checkpoint。利用SparkStreaming的direct方式與Kafka可以保證數據輸入源的,處理過程,輸出過程符合exactly once。 | Flink 則使用兩階段提交協議來保證exactly once。 |
| 吞吐量與延遲 | spark是基於微批的,而且流水線優化做的很好,所以說他的吞入量是最大的,但是付出了延遲的代價,它的延遲是秒級。 | 而Flink是基於事件的,消息逐條處理,而且他的容錯機制很輕量級,所以他能在兼顧高吞吐量的同時又有很低的延遲,它的延遲能夠達到毫秒級。 |
Flink原理介紹先寫到這裡了,更多關於Flink的知識點,請您耐心等待,當然也可以先自行去看官方文檔:https://nightlies.apache.org/flink/。


