
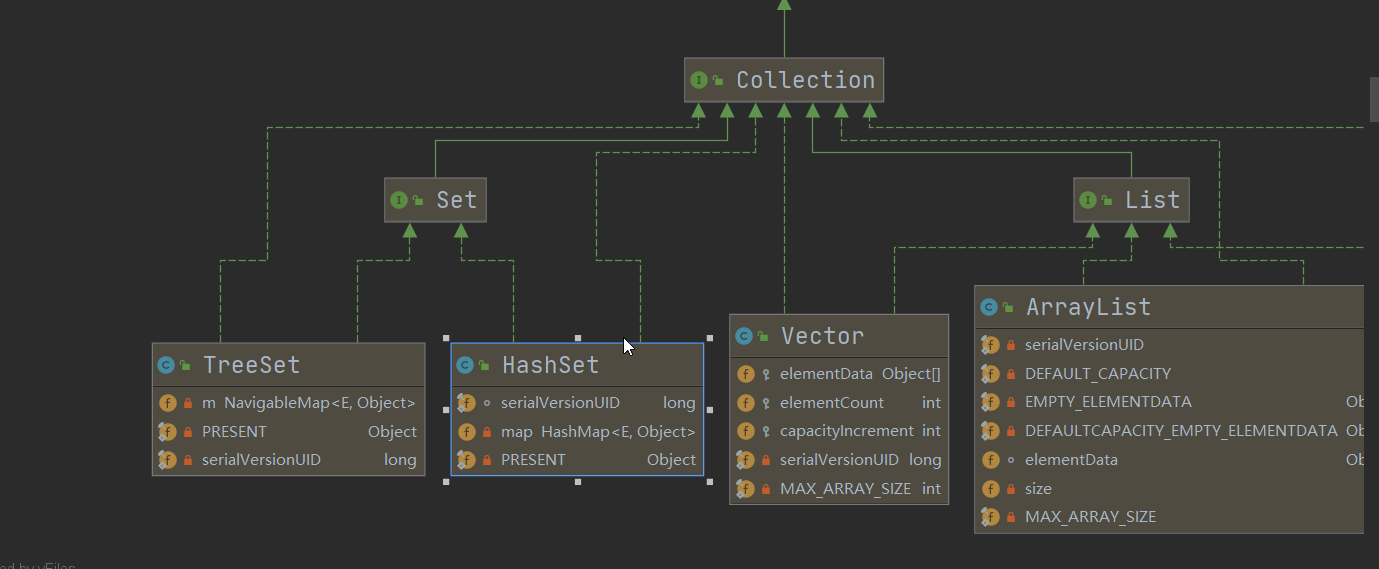
Set介面 介紹 無序(添加和取出的順序不一致),沒有索引 不允許重覆,所以最多包含一個null JDK API中Set介面實現類有 Set介面常用方法 和List介面一樣,Set介面也是Collection的子介面,因此,常用方法和Collection介面一樣 特點 不能存放重覆的元素 set介面 ...
Set介面
介紹
- 無序(添加和取出的順序不一致),沒有索引
- 不允許重覆,所以最多包含一個null
- JDK API中Set介面實現類有
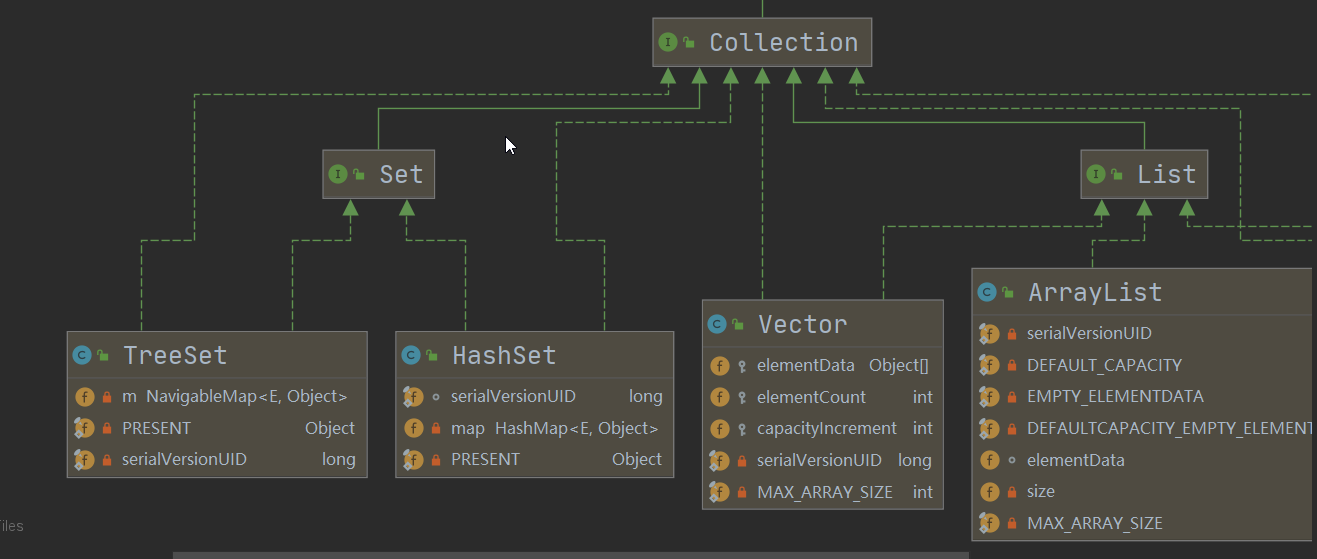
Set介面常用方法
和List介面一樣,Set介面也是Collection的子介面,因此,常用方法和Collection介面一樣
特點
- 不能存放重覆的元素
- set介面對象存放數據是無序的(即添加的順序和取出的順序不一致)
- 註意:取出的順序雖然不是添加的順序,但是他是固定的
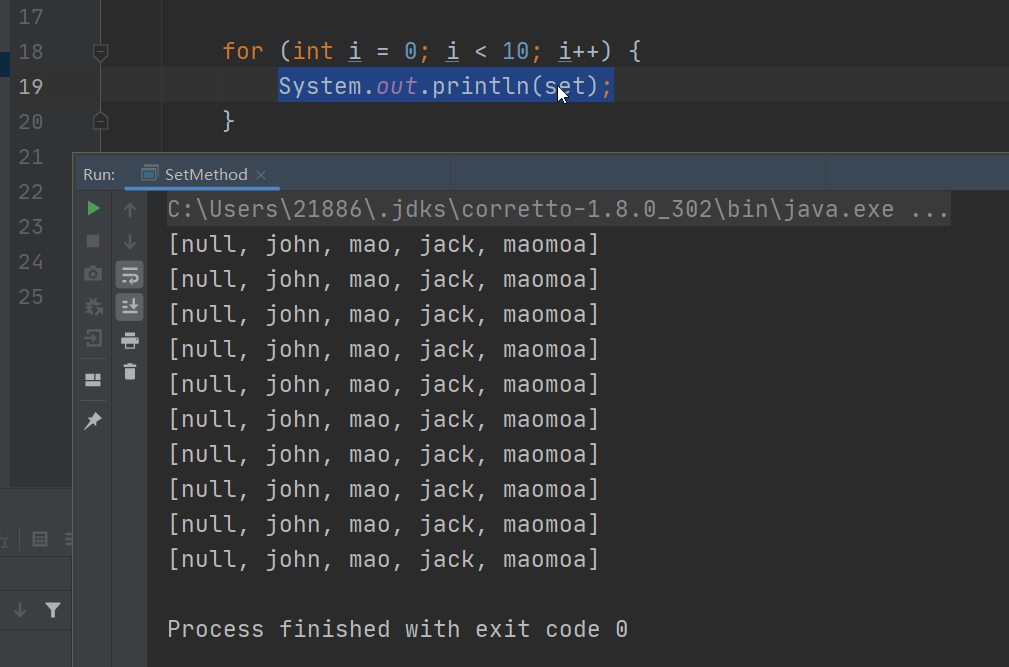
Set遍歷方法
同Collection的遍歷方法一樣,因為Set介面是Collection介面的子介面
- 可以使用迭代器
- 增強for
- 註意!!!:不能使用索引的方式來獲取 set沒有get方法
- set不用用普通for迴圈遍歷
已Set介面的實現類HashSet來看Set介面的方法
註意:編譯不會報錯,無序的
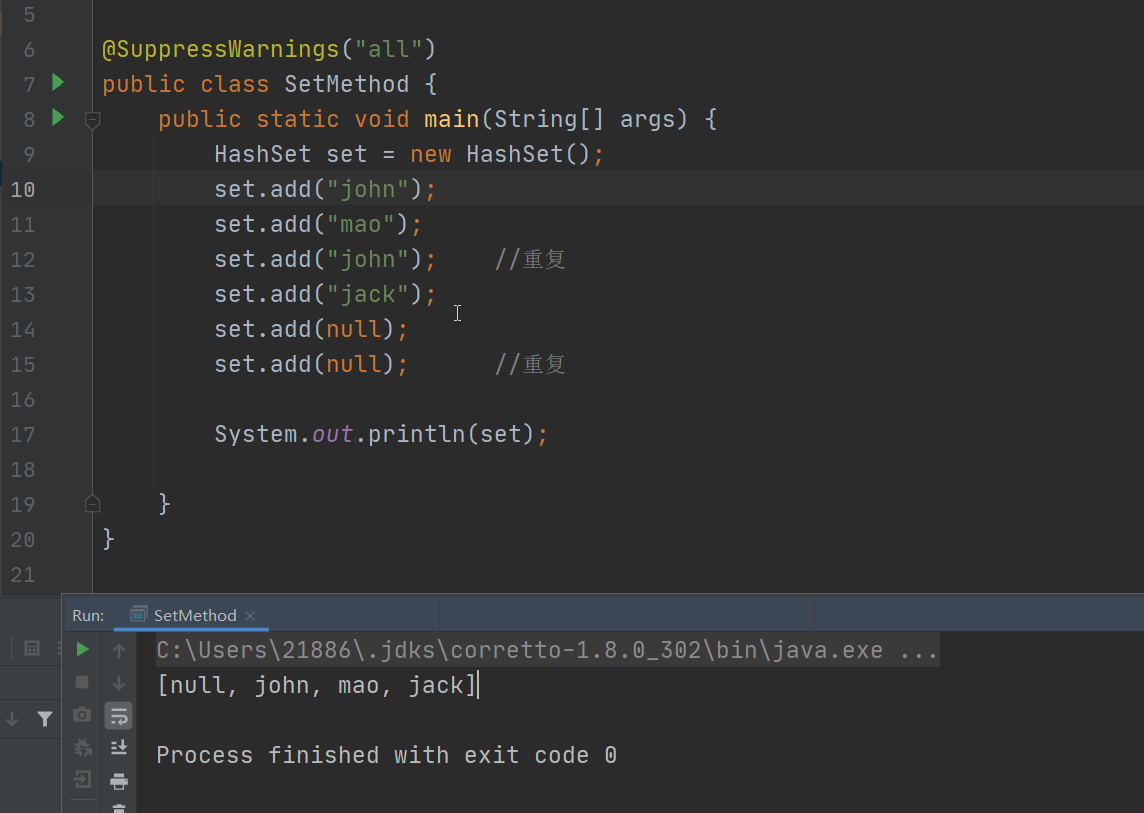
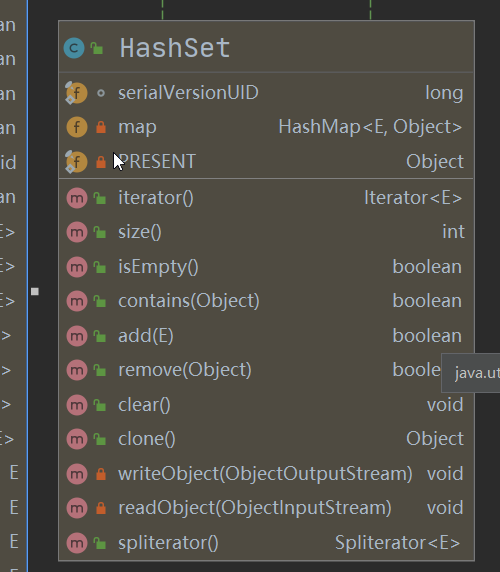
Set介面實現類-HashSet
說明
- HashSet實現了Set介面
- HashSet實際上是HashMap實現的
- 可以存放null值,但是只能有一個null
- HashSet不保證元素是有序v的,取決於hash後,再確定索引的結果(即不保證存放元素的順序和取出順序一致)
- 不能有重覆元素/對象
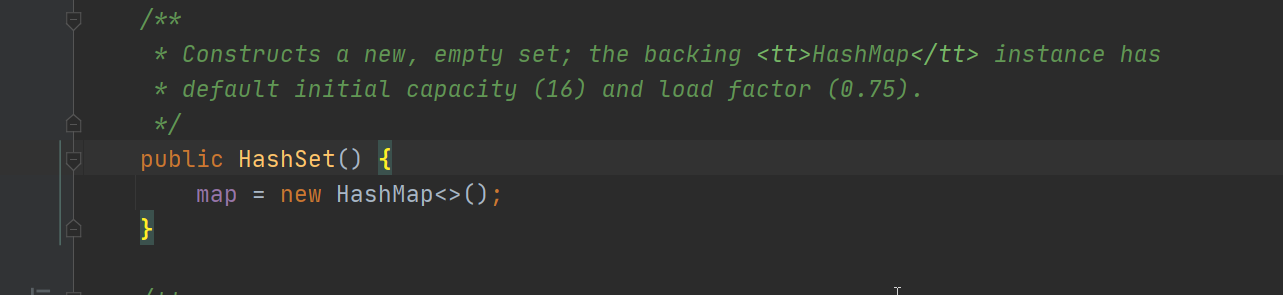
HashSet實際上是HashMap實現的
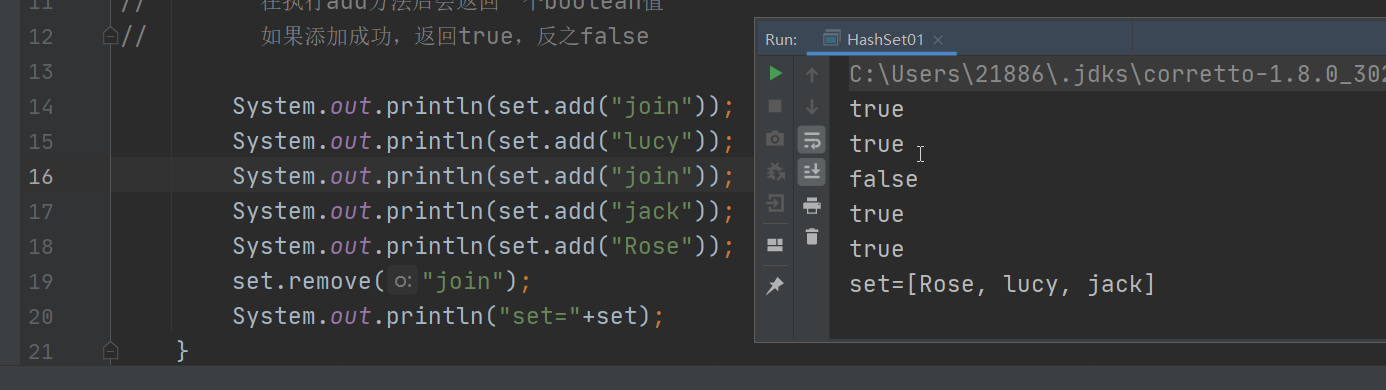
HashSet不保證元素是有序的,取決於hash後,再確定索引的結果
HashSet底層機制說明
HashSet底層是HashMap,HashMap底層是(數組+鏈表+紅黑樹)
package cn.itcast.set;
public class HashSetStructure {
public static void main(String[] args) {
// 模擬一個HashSet的底層(HashMap的底層結構)
// 創建一個數組,數組類型是Node[]
Node[] table=new Node[16]; //有些人直接把Node[]數組稱為table
System.out.println("table"+table);
// 創建節點
Node john = new Node("john", null);
table[2]=john;
Node jack = new Node("jack", null);
Node rose = new Node("Rose", null);
Node lucy = new Node("lucy", null);
// 把lucy放到table表的索引為3的位置
table[3]=lucy;
//將jack節點掛載到john
john.next=jack;
//將Rose節點掛載到jack
jack.next=rose;
System.out.println("table"+table);
}
}
//節點 存儲數據 可以指向下一個節點,從而形成鏈表
class Node{
Object item; //存放數據
Node next; //指向下一個節點
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
HashSet底層源碼分析
1、執行HashSet()

2、重新進入執行add方法

PRESENT是hashSet裡面的一個靜態的final類型的

3、追進put方法看一下,不要怕怕怕怕怕怕 執行可愛的put方法(狗頭保護) value=PRESENT:共用的

4、進入hash(key)
註意hashCode是Object的方法都可以用
無符號右移16位----->主要是防止衝突 (hashCode是native方法,底層用的c實現的)

5、最重要的方法 拿到了hash值然後執行putValue方法
源碼
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i; //定義了輔助變數
//這裡的table是Node[]
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
結論
- HashSet底層是HashMap
- 添加一個元素時,先得到hash值-會轉成->索引
- 找到存儲數據表table,看這個索引位置是否已經存放的有元素
- 如果沒有,直接加入
- 如果有,調用equals比較,如果相同,就放棄添加,如果不相同,則添加到最後
- 在java8中,如果一條鏈表的元素個數到達TREEIFY_THRESHOLD(預設為8)並且table的大小>=MIN_TAEEIFY_CAPACITY(預設為64),就會進行樹化(紅黑樹)

