
本章目錄 0x00 數據持久化 1.RDB 方式 2.AOF 方式 如何抉擇 RDB OR AOF? 0x01 備份容災 一、備份 1.手動備份redis資料庫 2.遷移Redis指定db-資料庫 3.Redis集群數據備份與遷移 二、恢復 1.系統Redis用戶被刪除後配置數據恢復流程 2.Kub ...
本章目錄
0x00 數據持久化
- 1.RDB 方式
- 2.AOF 方式
- 如何抉擇 RDB OR AOF?
0x01 備份容災
一、備份
- 1.手動備份redis資料庫
- 2.遷移Redis指定db-資料庫
- 3.Redis集群數據備份與遷移
二、恢復
- 1.系統Redis用戶被刪除後配置數據恢復流程
- 2.Kubernetes中單實例異常數據遷移恢復實踐
- 3.當Redis集群中出現從節點slave,fail,noaddr問題進行處理恢復流程。
前置知識學習補充
Redis資料庫基礎入門介紹與安裝 - https://blog.weiyigeek.top/2019/4-17-49.html
Redis資料庫基礎數據類型介紹與使用 - https://blog.weiyigeek.top/2020/5-17-50.html
Redis基礎運維之原理介紹和主從配置 - https://blog.weiyigeek.top/2019/4-17-97.html
Redis基礎運維之哨兵和集群安裝配置 - https://blog.weiyigeek.top/2019/4-17-576.html
Redis基礎運維之在K8S中的安裝與配置 - https://blog.weiyigeek.top/2019/4-17-524.html
Redis資料庫性能測試及優化配置 - https://blog.weiyigeek.top/2019/4-17-527.html
Redis資料庫客戶端操作實踐及入坑出坑 - https://blog.weiyigeek.top/2019/4-17-577.html
0x00 數據持久化
描述: Redis 是將數據存儲在記憶體之中所以其讀寫效率非常高,但是往往事物都不是那麼美好,當由於某些不可抗力導致機器宕機、redis服務停止此時您在記憶體中的數據將完全丟失;
所以為了使 Redis 在異常重啟後仍能保證數據不丟失, 我們就需要對其進行設置持久化存儲,使其將記憶體的數據通過某種方式存入磁碟中,當Redis服務端重啟後便會從該磁碟中進行讀取數據進而恢復Redis中的數據, 所以Redis數據持久化是容災恢復必備條件;
Redis支持兩種持久化方式:
- (1) RDB 持久化(預設支持): 該機制是指在指定的時間間隔內將記憶體中數據集寫入到磁碟;
- (2) AOF 持久化: 該機制將以日誌的形式記錄伺服器所處理的每一個寫操作,同時在Redis伺服器啟動之初會讀取該文件來重新構建資料庫,以保證啟動後資料庫中的數據完整;
- (3) 無持久化: 將 Redis 作為一個臨時緩存,並將數據存放到
memcached之中;
Tips: 為保證數據安全性,我們可以設置 Redis 同時使用RDB和AOF持久化方式,來保證重啟後Redis伺服器中的數據完整;
1.RDB 方式
描述: Redis 將某一時刻的快照(備份的資料庫數據)保存成一種稱為RDB格式的文件中,這種格式是經過壓縮的二進位文件,資料庫的保存和恢覆文件如下圖所示。
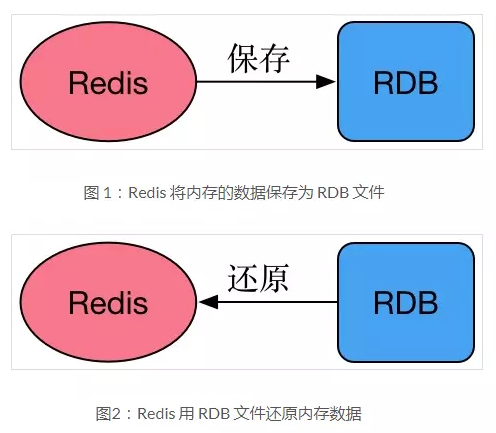
保存RDB數據的兩種方式:
- 1、save命令:save命令會阻塞redis伺服器的進程,直到RDB文件創建完,在該期間redis不能處理任何的命令請求,這就是save命令最大的缺陷。
- 2、bgsave命令:與save命令不同的是 bgsave在生成RDB文件時,會派生出一個子進程,子進程負責創建RDB文件,在此期間,主進程和子進程是同時存在的,因此不會阻塞redis伺服器進程。 (推薦方式)
說明:可用lastsave命令查看生成RDB文件是否成功
優勢
-
- 採用子線程創建RDB文件(
dump.rdb),不會對redis伺服器性能造成大的影響( 性能最大化);
- 採用子線程創建RDB文件(
-
- 快照生成的RDB文件是一種壓縮的二進位文件,可以方便的在網路中傳輸和保存。通過RDB文件可以方便的將redis數據恢復到某一歷史時刻,可以提高數據安全性,避免宕機等意外對數據的影響。
-
- 適合大規模的數據恢復, RDB的啟動恢復效率高。
-
- 如果業務對數據完整性和一致性要求不高,RDB是很好的選擇。
劣勢
-
- 在redis文件在時間點A生成,之後產生了新數據,還未到達另一次生成RDB文件的條件,redis伺服器崩潰了,那麼在時間點A之後的數據會丟失掉,數據一致性不是完美的好, 如果可以接受這部分丟失的數據,可以用生成RDB的方式;
-
- 快照持久化方法通過調用fork()方法創建子線程。當redis記憶體的數據量比較大時,創建子線程和生成RDB文件會占用大量的系統資源和處理時間,對 redis處理正常的客戶端請求造成較大影響。
-
- 數據的完整性和一致性不高,因為RDB可能在最後一次備份時宕機了。
-
- 備份時占用記憶體,因為Redis 在備份時會獨立創建一個子進程,將數據寫入到一個臨時文件(此時記憶體中的數據是原來的兩倍哦),最後再將臨時文件替換之前的備份文件。所以 Redis 的持久化和數據的恢復要選擇在夜深人靜的時候執行是比較合理的。
Q: 通過RDB文件恢複數據?
答: 將dump.rdb 文件拷貝到redis的安裝目錄的bin目錄下,重啟redis服務即可。在實際開發中,一般會考慮到物理機硬碟損壞情況,選擇備份dump.rdb 。
配置說明:
# Redis 配置文件
cat > redis.conf <<'EOF'
# 密碼認證
requirepass WeiyiGeek.top
# 持久化文件保存路徑目錄
dir /data
# RDB核心規則之觸發保存條件
說明:save <指定時間間隔> <執行指定次數更新操作>,滿足條件就將記憶體中的數據同步到硬碟中。官方出廠配置預設是 900秒內有1個更改,300秒內有10個更改以及60秒內有10000個更改, 則將記憶體中的數據快照寫入磁碟。
save 900 1 # 900秒(15分鐘)至少有1條key變化,其他同理
save 300 10
save 60 10000 #每60描述至少有1000個key發生變化時候則dump記憶體快照
# RDB 生成的文件名稱
dbfilename dump.rdb
# 是否壓縮(ZF壓縮方式),會占用部分cpu資源,預設yes(建議開啟)
rdbcompression yes
# rdb 文件校驗
rdbchecksum yes
# 備份進程出錯時,主進程停止接受寫入操作,預設yes
stop-writes-on-bgsave-error yes
# RDB自動觸發策略是否啟用,預設為yes
rdb-save-incremental-fsync yes
EOF
實際案例:
# 1.如上面配置所示,按配置情況觸發
# 比如在Redis服務終止的時候執行
# 2.手動保存數據連接redis後使用命令save、bgsave觸發
127.0.0.1:6379> SAVE #save 會阻塞redis伺服器直到完成持久化
OK
127.0.0.1:6379> BGSAVE #bgsave 不會阻塞redis伺服器(它會fork一個子進程,由子進程進行持久化。)
OK
127.0.0.1:6379> quit
# 3.redis aof 持久化文件完整性檢查與異常修正
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
# The AOF appears to start with an RDB preamble.
# Checking the RDB preamble to start:
# [offset 0] Checking RDB file --fix
# [offset 27] AUX FIELD redis-ver = '5.0.10'
# [offset 41] AUX FIELD redis-bits = '64'
# [offset 53] AUX FIELD ctime = '1631088747'
# [offset 68] AUX FIELD used-mem = '31554944'
# [offset 84] AUX FIELD aof-preamble = '1'
# [offset 86] Selecting DB ID 0
# [offset 13350761] Checksum OK
# [offset 13350761] \o/ RDB looks OK! \o/
# [info] 157070 keys read
# [info] 0 expires
# [info] 0 already expired
# RDB preamble is OK, proceeding with AOF tail...
# 0x 27b66b0: Expected prefix '*', got: 'R'
# AOF analyzed: size=116993914, ok_up_to=41641648, ok_up_to_line=1816854, diff=75352266
# This will shrink the AOF from 116993914 bytes, with 75352266 bytes, to 41641648 bytes
# Continue? [y/N]: y
# Successfully truncated AOF
# 4.再利用rdb數據文件進行恢複數據
root@dfbf8c0c0625:/data# ls
dump.rdb
# 將容器中的dump.rdb拷貝一份到宿主機中的`/var/lib/redis/`中,並需要在redis.conf中配置 `dir "/var/lib/redis/"`;
docker cp dfbf8c0c0625:/data/dump.rdb /var/lib/redis/dump.rdb
RDB文件恢複數據流程
1、先備份一份 dump.rdb 為 dump_bak.rdb(模擬線上)
2、flushall 清空數據(模擬數據丟失,需要註意 flushall 也會觸發rbd持久化)
3、將 dump_bak.rdb 替換為 dump.rdb
4、重啟redis服務,恢複數據
2.AOF 方式
描述: AOF是redis對將所有的寫命令保存到一個aof文件中,根據這些寫命令實現數據的持久化和數據恢復。

AOF文件生成機制
答: 生成過程包括三個步驟,即
命令追加、文件寫入、文件同步。
redis 打開AOF持久化功能之後,redis在執行完一個寫命令後,把執行的命令首先追加到redis內部的aof_buf緩衝區膜末尾,此時緩衝區的記錄還沒有寫到appendonly.aof文件中。然後,緩衝區的寫命令會被寫入到 AOF 文件,這一過程是文件寫入過程。對於操作系統來說,調用write函數並不會立刻將數據寫入到硬碟,為了將數據真正寫入硬碟,還需要調用fsync函數,調用fsync函數即是文件同步的過程,只有經過了文件的同步過程,寫命令才真正的被保存到了AOF文件中。選項 appendfsync 就是配置同步的頻率的。
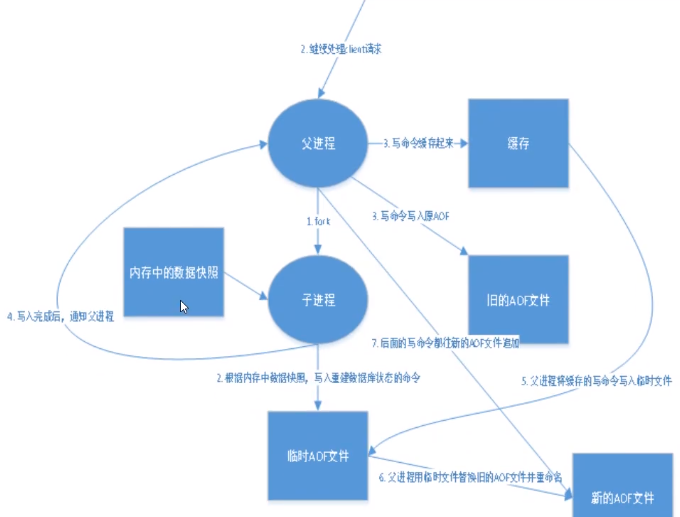
AOF文件重寫
- 1、redis不斷的將寫命令保存到AOF文件中,導致AOF文件越來越大,當AOF文件體積過大時,數據恢復的時間也是非常長的,因此,redis提供了重寫或者說壓縮AOF文件的功能。
比如對key1初始值是0,調用incr命,100次,key1的值變為100,那麼其實直接一句set key1 100 就可以頂之前的100局調用,AOF重寫功能就是乾這個事情的。重寫時,可以調用BGREWRITEAOF命令重寫AOF文件,與新建子線程bgsave命令的工作原理相似。也可以通過配置文件配置什麼條件下對AOF文件重寫。 - 2、重寫的原理:Redis 會fork出一條新進程,讀取記憶體中的數據,並重新寫到一個臨時文件中。並沒有讀取舊文件(太大了)。最後替換舊的aof文件
- 3、重寫觸發機制:當AOF文件大小是上次rewrite後大小的一倍且文件大於64M時觸發,這裡的“一倍”和“64M” 可以通過配置文件修改
優勢
-
- 該機制可以帶來更高的數據安全性,即數據持久化; 常規三種同步策略即每秒同步(
非同步完成效率高)、每修改同步(同步插入修改刪除操作效率最低)和不同步;
- 該機制可以帶來更高的數據安全性,即數據持久化; 常規三種同步策略即每秒同步(
-
- 由於該機制對日誌文件的寫入操作採用的是append模式,即使過程中出現宕機也不會破壞日誌文件中已經存在的內容,如果數據不完整在Redis下次啟動之前, 通過redis-check-aof解決數據一致性問題;
-
- 如果日誌文件體積過大可以啟動rewrite機制,即redis以append模式不斷的將修改數據寫到老的磁碟文件中,同時創建新文件記錄期間有哪些修改命令執行,此項極大的保證數據的安全性;
-
- AOF文件可讀性強,其包含一個格式清晰、易於理解的日誌文件用於記錄所有的修改操作(
可通過此文件完成數據的重構)
- AOF文件可讀性強,其包含一個格式清晰、易於理解的日誌文件用於記錄所有的修改操作(
-
- 數據的完整性和一致性更高
- 數據的完整性和一致性更高
劣勢
-
- AOF文件比RDB文件較大, 對於相同數量的數據集而言;
-
- redis負載較高時,RDB文件比AOF文件具有更好的性能;
-
- RDB使用快照的方式持久化整個redis數據,而aof只是追加寫命令,因此從理論上來說,RDB比AOF方式更加健壯,另外,官方文檔也指出,在某些情況下,AOF的確也存在一些bug,比如使用阻塞命令時,這些bug的場景RDB是不存在的。
-
- 因為AOF記錄的內容多,文件會越來越大,數據恢復也會越來越慢。
-
- 根據同步策略的不同,AOF在運行效率上往往會慢於RDB,總的來說每秒同步策略的效率還是比較高的
Q: 如何觸發AOF快照?
答: 根據配置文件觸發,可以是每次執行觸發,可以是每秒觸發,可以不同步。
Q: 如何根據AOF文件恢複數據?
答: 正常情況下,將appendonly.aof 文件拷貝到redis的安裝目錄的bin目錄下,重啟redis服務即可。但在實際開發中,可能因為某些原因導致
appendonly.aof文件格式異常,從而導致數據還原失敗,可以通過命令redis-check-aof --fix appendonly.aof進行修複 。
配置說明:
cat > redis.conf <<'EOF'
# 持久化數據存儲
dir "/data"
# 是否開啟AOF預設為否
appendonly yes
# AOF文件名字及路徑,若RDB路徑已設置這裡可不設置
appendfilename "appendonly.aof"
# AOF的3種模式,no(使用系統緩存處理,快)、always(記錄全部操作,慢但比較安全)、everysec(每秒同步,折中方案,預設使用)
appendfsync everysec
# 重寫期間是否同步數據,預設為no
no-appendfsync-on-rewrite no
# 配置重寫觸發機制: 確保AOF日誌文件不會過大,保持跟redis記憶體數據量一致。
# 配置說明:當AOF文件大小是上次rewrite後大小的一倍且文件大於64M時觸發(根據實際環境進行配置)
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 256mb
# AOF重寫策略是否啟用,預設為yes
aof-rewrite-incremental-fsync yes
# 載入AOF時如果報錯則會繼續但寫入log,如果為no則不會繼續
aof-load-truncated yes
# Redis5.0有的功能AOF重寫及恢復可以使用RDB文件及AOF文件,速度更快,預設yes
aof-use-rdb-preamble yes
EOF
Q: 如何通過AOF文件恢複數據流程?
1、執行flushall,模擬數據丟失
2、重啟 redis 服務,恢複數據
3、修改 appendonly.aof,模擬文件異常
4、重啟 Redis 服務失敗,這同時也說明瞭RDB和AOF可以同時存在,且優先載入AOF文件。
5、使用 redis-check-aof 校驗 appendonly.aof 文件。
# 針對Redis aof 持久化文件進行完整性檢測併進行修複
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
# The AOF appears to start with an RDB preamble.
# Checking the RDB preamble to start:
# [offset 0] Checking RDB file appendonly.aof
# [offset 27] AUX FIELD redis-ver = '5.0.10'
# [offset 41] AUX FIELD redis-bits = '64'
# [offset 53] AUX FIELD ctime = '1631088747'
# [offset 68] AUX FIELD used-mem = '31554944'
# [offset 84] AUX FIELD aof-preamble = '1'
# [offset 86] Selecting DB ID 0
# [offset 13350761] Checksum OK
# [offset 13350761] \o/ RDB looks OK! \o/
# [info] 157070 keys read
# [info] 0 expires
# [info] 0 already expired
# RDB preamble is OK, proceeding with AOF tail...
# 0x 27b66b0: Expected prefix '*', got: 'R'
# AOF analyzed: size=116993914, ok_up_to=41641648, ok_up_to_line=1816854, diff=75352266
# AOF is not valid. Use the option to try fixing it.
6、重啟Redis 服務後正常。
# 利用源實例生成的aof文件數據進行恢復到其它主機中。
redis-cli -h 17.20.0.2 -a password --pipe < applendonly.aof
註意:當你使用 flushall 清空數據的時候,重啟redis服務發現數據沒恢復,是因為 FLUSHALL 命令也被寫入AOF文件中,會導致數據恢復失敗,所只需要刪除aof文件中的flushall就行了
Tips : 在資料庫恢復時把 aof(append only file) 從中對redis資料庫操作的命令,增刪改操作的命令,執行了一遍即可。
實際案例:
描述: 用於非同步執行一個 AOF(AppendOnly File) 文件重寫操作, 重寫會創建一個當前 AOF 文件的體積優化版本,因為AOF為記錄每次的操作會導致實際記錄冗雜、使得文件過大,所以需要做重寫操作。
重寫方式分為以下兩種:
# (1) AOF自動重寫:按配置文件條件自動觸發重寫
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 256mb
# (2) AOF手動重寫:使用 redis-cli 連接到 server 端執行 bgrewriteaof 進行手動重寫。
# 註意:從 Redis 2.4 開始, AOF 重寫由 Redis 自行觸發, BGREWRITEAOF 僅僅用於手動觸發重寫操作。
127.0.0.1:6379> BGREWRITEAOF
# 即使 Bgrewriteaof 執行失敗,也不會有任何數據丟失,因為舊的 AOF 文件在 Bgrewriteaof 成功之前不會被修改。
Background append only file rewriting started
如何抉擇 RDB OR AOF?
描述: 在實際生產環境中不要僅使用RDB(載入快、不保證數據完整性)或僅使用AOF(載入慢、數據完整性保證), 所以推薦綜合使用AOF和RDB兩種持久化機制進行數據備份。
- AOF 機制保證數據不丟失,並且文件有一定的可讀性即可以選擇性恢復一部分數據,所以作為數據恢復的第一選擇;
- RDB 機制在AOF文件都丟失或損壞不可用的時候,可以利用其冷備文件來進行快速的數據恢復;
AOF和RDB同時工作特點:
- 當 rdb 進行 snapshotting 時, redis 便不會再執行 AOF rewrite, 反之則一樣。
- 當 rdb 進行 snapshotting 時, 其它用戶也在執行 BGREWRITEAOF 命令, 結果是只有等RDB快照生成之後,才會執行AOF rewrite;
- 當同時擁有rdb 快照文件和AOF日誌文件時, Redis 重啟時會優先使用AOF日誌進行恢復,。
- 數據恢復完全依賴於磁碟持久化,如果rdb和aof上都沒有數據,數據就無法恢復了。
Tips : 重點再記錄、為保證數據容災建議啟用rdb與aof持久化機制,前者保證數據備份而後者保證數據的完整性。
Tips : 重點再記錄、當在伺服器中同時啟用rdb與aof持久化機制時,在redis服務啟動時優先載入AOF文件(其數據的完整性)。
合併兩個不同實例的數據
描述: 我們可以利用如下方式進行集群多個主節點持久化數據的合併。
(1) AOF 備份合併: 我們說過它實際上是一些列Redis的命令文本。
例如,假設有兩台 Redis(6379, 6479),它們的AOF文件名分別為(6379.aof, 6479.aof),現在要將6379的數據合併到 6479.aof
# 首先
cp 6379.aof 6379.aof.bak, cp 6479.aof 6479.aof.bak
# 合併
cat 6379.aof 6479.aof > new.aof
# 檢查&修複
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
(2) RDB 備份合併: 註意以下方法可能由於服務端版本不同而有些許差異。
RDB格式如下:頭5個位元組是字元REDIS,之後4個位元組代表版本號,阿裡的版本分別是 00 00 00 06,之後2個位元組 FE 00,FE是標識 00是資料庫,還好我們只有一個庫, 最後的結尾9個位元組 , FF 加上8個位元組的CRC64校驗碼(實在沒空弄,後來偷了一個懶)
# 1.線上服務使用的阿裡雲的集群版本redis服務,數據量1千萬,rdb文件4GB,8個rdb文件,每個500MB。
#文件1 大小566346503,截取尾部的9個位元組
dd bs=1 if=src_1.rdb of=1.rdb count=566346494
#文件2 大小570214520,跳過頭部的11個位元組,再截取尾部的9個位元組
dd bs=1 if=src_2.rdb of=2.rdb skip=11 count=570214500
...
#文件8 大小569253061,跳過頭部的11個位元組,再截取尾部的8個位元組,保留FF。
dd bs=1 if=src_8.rdb of=8.rdb skip=11 count=569253042
# 2.合併文件(得到備份文件dump.rdb)
cat 1.rdb > dump.rdb
cat 2.rdb >> dump.rdb
...
cat 8.rdb >> dump.rdb
# 3.檢查備份文件(應該會提示沒有crc校驗)
redis-check-rdb dump.rdb
# 4.修改配置文件,因為資料庫備份文件裡面不包含crc64的校驗碼,配置文件中關閉選項。
rdbchecksum no
Tips : 數據恢復到此結束,此方法只適合用於臨時恢復和導出數據,數據完整性不敢保證。
參考地址: https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format
其它工具:
- https://github.com/leonchen83/redis-rdb-cli/ | 一個可以解析, 過濾, 分割, 合併 rdb 離線記憶體分析的工具. 也可以在兩個redis之前同步數據並允許用戶自定義同步服務來把redis數據同步到其他地方.
0x01 備份容災
一、備份
1.手動備份redis資料庫
#!/bin/bash
# 方式1.通過redis-cli內置命令將記憶體中的數據存儲到rdb文件中
echo "auth 123456\nping\nsave\n" | redis-cli -h 127.0.0.1 -p 6379
echo "auth 123456\nping\nbgsave\n" | redis-cli -h 127.0.0.1 -p 6379
# 方式2.將遠程主機Redis-Server中存儲的數據保存到本地/tmp/backup/目錄中。
redis-cli -h 127.0.0.1 -p 6379 --rdb /tmp/backup/app-6379.rdb
# 方式3.定時執行拷貝rdb與aof文件進行備份。
# 例如: 每天0點執行一次 0 0 * * * sh /tmp/redisBackup.sh
current_date=$(date +%Y%m%d-%H%M%S)
BACKUPDIR="/backup/redis"
RDBFILE="/data/dump.rdb"
AOFFILE="/data/appendonly.aof"
# del_date=$(date -d -1day +%Y%m%d)
if [ ! -d ${BACKUPDIR} ];then
mkdir -vp ${BACKUPDIR}
fi
if [ ! -f ${RDBFILE} ];then
cp -a ${RDBFILE} ${BACKUPDIR}/${current_date}-dump.rdb
fi
if [ ! -f ${AOFFILE} ];then
cp -a ${AOFFILE} ${BACKUPDIR}/${current_date}-appendonly.aof
fi
# 刪除七天前的備份
find ${BACKUPDIR} -type f -mtime +7 >> delete.log
find ${BACKUPDIR} -type f -mtime +7 -exec rm -rf {} \;
2.遷移Redis指定db-資料庫
方式1.同主機db遷移到另外一個dbn中
$ redis-cli -h localhost -a weiyigeek.top -n 0 keys "*" | while read key
do
redis-cli -h localhost -a weiyigeek.top -n 0 --raw dump $key | perl -pe 'chomp if eof' | redis-cli -h localhost -a weiyigeek.top -n 12 -x restore $key 0
done
方式2.跨主機遷移db
# redis 把db2 的數據遷移到 db14 里 (註意:某些格式的數據不能完全已此種方式進行遷移)
# 需求分析:
'''1、建立兩個redis連接
2、獲取所有的keys()
3、獲取keys的類型:string hash'''
import redis
src_redis = redis.Redis(host='211.149.218.16',
password='123456',
port=6379,
db=2)
target_redis = redis.Redis(host='211.149.218.16',
password='123456',
port=6379,
db=14)
for key in src_redis.keys(): # redis獲取的數據都是bytes類型的,所以key的類型是 bytes 類型
if src_redis.type(key) == b'string':# 也可以用decode() 把key轉換成string,這樣等號右邊就不需要加b
v = src_redis.get(key) #先獲取原來的數據
target_redis.set(key,v) #set到新的資料庫里
else:
all_hash_data = src_redis.hgetall(key) # 獲取hash類型裡面所有的數據,獲取出來的數據是字典格式的 但是有b,需要轉換
for k,v in all_hash_data.items():# 因為獲取到字典格式的hash類型的原數據有b,所以需要用for迴圈來進行轉換後重新賦值給新的資料庫
target_redis.hset(key,k,v) # key是外面的,k是裡面的key,v是k對應的value
3.Redis集群數據備份與遷移
描述: 當我們需要備份或遷移Redis集群時可以採用以下方案。
# (1) 備份集群數據到本地目錄中(已rdb格式文件存儲)。
redis-cli -a weiyigeek --cluster backup 172.16.243.97:6379 .
# >>> Node 172.16.243.97:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to './redis-node-172.16.243.97-6379-d97cb5b15b7130ca0bd5322758e0c2dce061fd7b.rdb'
# Transfer finished with success.
# >>> Node 172.16.183.95:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to './redis-node-172.16.183.95-6379-94b8d3748dc47053454e657da8d6bb90e0081f2c.rdb'
# Transfer finished with success.
# >>> Node 172.16.24.214:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to './redis-node-172.16.24.214-6379-2674f21a88a9573f51ec46f9dc248ad4a5c5974d.rdb'
# Transfer finished with success.
# (2) 把 192.168.1.187:6379 上的數據導入到 192.168.75.187:6379 這個節點所在的集群,如有密碼將詢問
redis-cli -a weiyigeek --cluster import 192.168.75.187:6379 --cluster-from 192.168.1.187:6379 --cluster-from-askpass --cluster-copy
# (3) 遷移後利用 dbsize 命令查看數據是否正確
Tips: 第三方redis集群數據遷移工具項目參考(https://github.com/alibaba/RedisShake)
二、恢復
1.系統Redis用戶被刪除後配置數據恢復流程
描述:在系統刪除了配置文件後以及用戶賬號後恢復方法流程,實際環境中建議利用rdb文件進行重新部署。
-
Step1.Redis賬戶數據恢復首先確定系統中是否還有redis用戶。(如果拷貝過來的系統也安裝了redis,那麼肯定是會有redis賬戶)
-
Step2.如果發現有redis用戶以下步驟可以跳過,否則進行手動添加。
echo "redis:x:996:994:Redis Database Server:/var/lib/redis:/sbin/nologin" >> /etc/passwd
echo "redis:!!:17416::::::" >> /etc/shadow
echo "redis:x:994:" >> /etc/group
echo "redis:!::" >> /etc/gshadow
- Step3.Redis配置文件恢復, Redis的配置文件恢復相對簡單一些,官方提供了
CONFIG REWRITE命令重寫redis.conf配置文件。
redis-cli
> CONFIG REWRITE
OK
- Step4.修改配置文件許可權
touch /etc/redis.conf
chown redis:redis /etc/redis.conf
2.Kubernetes中單實例異常數據遷移恢復實踐
方案1.利用其他kubernetes集群進行恢複原k8s集群的redis數據。
#!/bin/bash
# author: WeiyiGeek
# usage: ./K8SRedisRecovery.sh [aof|rdb] redis原持久化目錄
BACKUP_TYPE=$1
BACKUP_DIR=$2
DATA_DIR="$(pwd)/data"
echo "開始時間: $(date +%s)"
# 1.判斷備份文件以及持久化文件是否存在
if [ ! -d ${BACKUP_DIR} ];then echo -e "[Error] - Not Found ${BACKUP_DIR} Dirctory!"; return -1; fi
if [ ! -d ${DATA_DIR} ];then mkdir -vp ${DATA_DIR};else rm -rf "${DATA_DIR}/*"; fi
# 2.redis配置與k8s部署恢復redis清單
# tee redis.conf <<'EOF'
# bind 0.0.0.0
# port 6379
# daemonize no
# supervised no
# protected-mode no
# requirepass "weiyigeek"
# dir "/data"
# pidfile "/var/run/redis.pid"
# logfile "/var/log/redis.log"
# loglevel verbose
# maxclients 10000
# timeout 300
# tcp-keepalive 60
# maxmemory-policy volatile-lru
# slowlog-max-len 128
# lua-time-limit 5000
# save 300 10
# save 60 10000
# dbfilename "dump.rdb"
# rdbcompression yes
# rdb-save-incremental-fsync yes
# # appendonly yes
# appendfilename "appendonly.aof"
# appendfsync everysec
# # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
# rename-command FLUSHDB WeiyiGeekFLUSHDB
# rename-command FLUSHALL WeiyiGeekFLUSHALL
# rename-command EVAL WeiyiGeekEVAL
# rename-command DEBUG WeiyiGeekDEBUG
# rename-command SHUTDOWN WeiyiGeekSHUTDOWN
# EOF
tee redisrecovery.yaml <<'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-recovery
namespace: database
data:
redis.conf: |+
bind 0.0.0.0
port 6379
daemonize no
supervised no
protected-mode no
requirepass "weiyigeek"
dir "/data"
pidfile "/var/run/redis.pid"
logfile "/var/log/redis.log"
loglevel verbose
maxclients 10000
timeout 300
tcp-keepalive 60
maxmemory-policy volatile-lru
slowlog-max-len 128
lua-time-limit 5000
save 300 10
save 60 10000
dbfilename "dump.rdb"
rdbcompression yes
rdb-save-incremental-fsync yes
# appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
rename-command FLUSHDB WeiyiGeekFLUSHDB
rename-command FLUSHALL WeiyiGeekFLUSHALL
rename-command EVAL WeiyiGeekEVAL
rename-command DEBUG WeiyiGeekDEBUG
rename-command SHUTDOWN WeiyiGeekSHUTDOWN
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-recovery
namespace: database
spec:
serviceName: redisrecovery
replicas: 1
selector:
matchLabels:
app: redis-recovery
template:
metadata:
labels:
app: redis-recovery
spec:
containers:
- name: redis
image: redis:6.2.5-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: server
command: [ "redis-server", "/conf/redis.conf"]
volumeMounts:
# 從configmap獲取的配置文件,掛載到指定文件中
- name: conf
mountPath: /conf/redis.conf
subPath: redis.conf
- name: data
mountPath: /data
# 時區設置
- name: timezone
mountPath: /etc/localtime
volumes:
- name: conf
# 配置文件採用configMap
configMap:
name: redis-recovery
defaultMode: 0755
# redisc持久化目錄採用hostPath捲
- name: data
hostPath:
type: DirectoryOrCreate
path: {PersistentDir}
# 時區定義
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
---
apiVersion: v1
kind: Service
metadata:
name: redisrecovery
namespace: database
spec:
type: ClusterIP
ports:
- port: 6379
targetPort: 6379
name: server
selector:
app: redis-recovery
EOF
# 3.刪除原有的恢復Pod
kubectl delete -f redisrecovery.yaml
# kubectl delete configmap -n database redis-recovery
# 4.判斷redis備份格式
if [ "${BACKUP_TYPE}" == "aof" ];then
sed -i "s|# appendonly yes|appendonly yes|g" redisrecovery.yaml
cp -a ${BACKUP_DIR}/appendonly.aof ${DATA_DIR}
else
cp -a ${BACKUP_DIR}/dump.rdb ${DATA_DIR}
fi
# 5.更新redis備份恢復k8s資源清單中的持久化目錄
sed -i "s#{PersistentDir}#${DATA_DIR}#g" redisrecovery.yaml
# 6.創建configmap和部署redis備份恢復應用
# kubectl create configmap -n database redis-recovery --from-file=$(pwd)/redis.conf
kubectl create --save-config -f redisrecovery.yaml
# 7.驗證Pod狀態是否正常
flag=$(kubectl get pod -n database -o wide -l app=redis-recovery | grep -c "Running")
echo -e "\e[31m[Error]: Pod Status is not Running! \e[0m"
while [ ${flag} -ne 1 ];do
sleep 0.5
flag=$(kubectl get pod -n database -o wide -l app=redis-recovery | grep -c "Running")
done
# 8.驗證數據是否恢復
# apt install -y redis-tools
echo "[OK] redis-recovery Status is Running"
echo -e "AUTH weiyigeek\nping\ninfo" | redis-cli -h redisrecovery.database.svc.cluster.local | grep -A 16 "# Keyspace"
while [ $? -ne 0 ];do
echo -e "AUTH weiyigeek\nping\ninfo" | redis-cli -h redisrecovery.database.svc.cluster.local | grep -A 16 "# Keyspace"
done
echo "數據恢復完成......"
echo "完成時間: $(date +%s)"
命令執行示例:
# (1) 利用 AOF 文件進行恢復百萬數據
/nfsdisk-31/datastore/redis/demo2# time ./K8sredisRecovery.sh aof /nfsdisk-31/data/database-data-redis-cm-0-pvc-00ee48e8-b1ca-4640-96c5-16f7265a2c61
# # Keyspace
# db0:keys=1000000,expires=0,avg_ttl=0
# 數據恢復完成......
# 完成時間: 1631067931
# real 0m12.039s
# user 0m0.647s
# sys 0m0.199s
/nfsdisk-31/datastore/redis/demo2/data# ls -alh
# -rw-r--r-- 1 root root 41M Sep 7 22:14 appendonly.aof
# -rw-r--r-- 1 root root 41M Sep 8 2021 dump.rdb
# (2) 利用 rdb 文件進行恢復 百萬數據
root@WeiyiGeek-107:/nfsdisk-31/datastore/redis/demo2# time ./K8sredisRecovery.sh rdb /nfsdisk-31/data/database-data-redis-cm-0-pvc-00ee48e8-b1ca-4640-96c5-16f7265a2c61
# # Keyspace
# db0:keys=993345,expires=0,avg_ttl=0
# 數據恢復完成......
# 完成時間: 1631069375
# real 0m11.106s
# user 0m0.606s
# sys 0m0.192s
/nfsdisk-31/datastore/redis/demo2# ls -lah data/
# -rw-r--r-- 1 root root 41M Sep 8 2021 dump.rdb
# root@WeiyiGeek-107:/nfsdisk-31/datastore/redis/demo2#
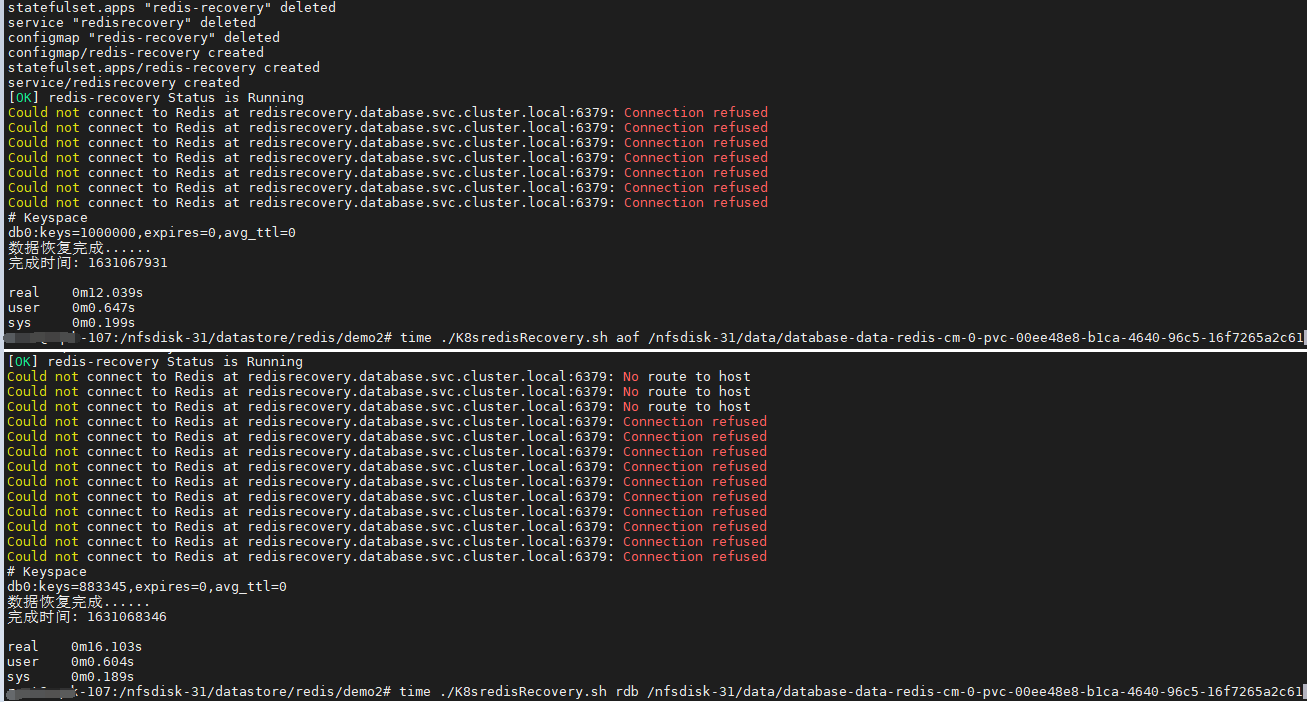
Tips : 從上述恢復結果可以看出以aof方式恢復的數據比rdb恢復的數據完整,但所載入的時間會隨著數據增大會使得AOF方式耗時比rdb耗時更多。
方案2.利用宿主機安裝編譯redis源碼,進行恢複原k8s集群的redis數據
#!/bin/bash
# author: WeiyiGeek
# usage: ./RedisRecovery.sh [aof|rdb] redis原持久化目錄
# 驗證環境: Ubuntu 20.04.1 LTS
# 腳本說明: 將Redis數據恢復到物理中
if [ $# -eq 0 ];then
echo -e "\e[31m[*] $0 [aof|rdb] redis原持久化目錄 \e[0m"
exit
fi
BACKUP_TYPE=$1
BACKUP_DIR=$2
DATA_DIR="$(pwd)/data"
REDIS_DIR="/usr/local/redis"
echo "開始時間: $(date +%s)"
if [ ! -d ${BACKUP_DIR} ];then echo -e "[Error] - Not Found ${BACKUP_DIR} Dirctory!"; return -1; fi
if [ ! -d ${DATA_DIR} ];then mkdir -vp ${DATA_DIR};else rm -rf "${DATA_DIR}/*"; fi
## 1.基礎環境準備
# - 設置記憶體分配策略
sudo sysctl -w vm.overcommit_memory=1
# - 儘量使用物理記憶體(速度快)針對內核版本大於>=3.x
sudo sysctl -w vm.swapniess=1
# - SYN隊列長度設置,此參數可以容納更多等待連接的網路。
sudo sysctl -w net.ipv4.tcp_max_syn_backlog=4096
# - 禁用 THP 特性減少記憶體消耗
echo never > /sys/kernel/mm/transparent_hugepage/enabled
# redis 客戶端: apt remove redis-tools
## 2.REDIS 源碼包
if [ ! -f /usr/local/redis/redis.conf ];then
REDIS_VERSION="redis-6.2.5"
REDIS_URL_TAR="https://download.redis.io/releases/${REDIS_VERSION}.tar.gz"
REDIS_TAR="${REDIS_VERSION}.tar.gz"
# redis 編譯環境以及編譯redis安裝在指定目錄
apt install -y gcc make gcc+ pkg-config
wget ${REDIS_URL_TAR} -O /tmp/${REDIS_TAR}
tar -zxf /tmp/${REDIS_TAR} -C /usr/local/
mv /usr/local/${REDIS_VERSION} ${REDIS_DIR}
cd ${REDIS_DIR} && make distclean
make PREFIX=${REDIS_DIR} install
cp -a ${REDIS_DIR}/redis.conf /etc/redis.conf
for i in $(ls -F ${REDIS_DIR}/bin | grep "*"| sed 's#*##g');do
sudo chmod +700 ${REDIS_DIR}/bin/${i}
sudo ln -s ${REDIS_DIR}/bin/${i} /usr/local/bin/${i}
done
fi
# 物理機運行可以將daemonize設置為後臺運行。
tee ${REDIS_DIR}/redis.conf <<'EOF'
bind 0.0.0.0
port 6379
daemonize yes
supervised no
protected-mode no
requirepass "weiyigeek"
dir "/data"
pidfile "/var/run/redis.pid"
logfile "/var/log/redis.log"
# loglevel verbose
maxclients 10000
timeout 300
tcp-keepalive 60
maxmemory-policy volatile-lru
slowlog-max-len 128
lua-time-limit 5000
save 900 1
save 300 100
save 60 10000
dbfilename "dump.rdb"
rdbcompression yes
rdb-save-incremental-fsync yes
# appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
rename-command FLUSHDB WeiyiGeekFLUSHDB
rename-command FLUSHALL WeiyiGeekFLUSHALL
rename-command EVAL WeiyiGeekEVAL
rename-command DEBUG WeiyiGeekDEBUG
rename-command SHUTDOWN WeiyiGeekSHUTDOWN
EOF
# 3.判斷要使用的備份格式
if [ "${BACKUP_TYPE}" == "aof" ];then
sed -i "s|# appendonly yes|appendonly yes|g" ${REDIS_DIR}/redis.conf
cp -a ${BACKUP_DIR}/appendonly.aof ${DATA_DIR}
else
cp -a ${BACKUP_DIR}/dump.rdb ${DATA_DIR}
fi
sed -i "s#/data#${DATA_DIR}#g" ${REDIS_DIR}/redis.conf
# 4.啟動redis服務恢複數據
${REDIS_DIR}/bin/redis-server ${REDIS_DIR}/redis.conf
ps -aux | grep redis-server
echo -e "AUTH weiyigeek\nping\ninfo" | redis-cli -h 127.0.0.1 | grep -A 16 "# Keyspace"
while [ $? -ne 0 ];do
echo -e "AUTH weiyigeek\nping\ninfo" | redis-cli -h 127.0.0.1 | grep -A 16 "# Keyspace"
done
echo "數據恢復完成......"
echo "完成時間: $(date +%s)"
方案3.利用Kubernetes部署的Redis集群,進行恢複原k8s集群的redis數據
#!/bin/bash
# author: WeiyiGeek
# K8s 中 redis 集群數據恢復
# useage: K8SRedisClusterRecovery.sh [single|cluster] PODMATCH K8SVOLUMNDIR
if [ $# -eq 0 ];then
echo -e "\e[31m[*] $0 [single|cluster] PODMATCH K8SVOLUMNDIR \e[0m"
echo -e "\e[31m[*] PODMATCH : redis-cluster {異常集群 statefulset 資源對象名稱} \e[0m"
echo -e "\e[31m[*] K8SVOLUMNDIR : /nfsdisk-31/data {K8S 持久化跟目錄} \e[0m"
exit
fi
RECTARGET="${1}"
PODMATCH="${2}"
K8SVOLUMNDIR="${3}"
AUTH="weiyigeek"
PWD=$(pwd)
AOFNAME="appendonly.aof"
DATADIR="${PWD}/database"
K8SSVCNAME="database.svc.cluster.local"
# 1.原`Redis`集群nodes信息一覽,獲取aof文件路徑。
grep "myself,master" ${K8SVOLUMNDIR}/*${PODMATCH}-[0-9]-*/nodes.conf | head -n 3 > /tmp/nodes.log
cat /tmp/nodes.log
node1=$(grep "0-5460" /tmp/nodes.log | cut -d ":" -f 1)
aofpath1=${node1%/*}
node2=$(grep "5461-10922" /tmp/nodes.log | cut -d ":" -f 1)
aofpath2=${node2%/*}
node3=$(grep "10923-16383" /tmp/nodes.log | cut -d ":" -f 1)
aofpath3=${node3%/*}
# 2.驗證aof文件是否存在並拷貝到當前路徑下,合併AOF文件到當前目錄的data下。
if [ ! -f ${aofpath1}/${AOFNAME} -o ! -f ${aofpath2}/${AOFNAME} -o ! -f ${aofpath3}/${AOFNAME} ];then echo -e "\e[31m[-] ${AOFNAME} file not found \e[0m";exit;fi
cp ${aofpath1}/${AOFNAME} ./1.${AOFNAME}
cp ${aofpath2}/${AOFNAME} ./2.${AOFNAME}
cp ${aofpath3}/${AOFNAME} ./3.${AOFNAME}
if [ ! -d ${DATADIR} ];then mkdir -v ${DATADIR};fi
cat *.aof > ${DATADIR}/${AOFNAME}
# 校驗合併的原集群aof文件並嘗試進行修複
echo "y" | /usr/local/redis/bin/redis-check-aof --fix ${DATADIR}/${AOFNAME}
ls -alh ${DATADIR}
# 3.驗證原集群相關文件是否有誤(如有誤需要人工進行相應處理)
echo -e "\e[32m[*] 請驗證原Redis集群Nodes信息是否無誤? 請輸入[Y|N] \e[0m"
read flag
if [ "${flag}" == "N" -o "${flag}" == "n" ];then echo -e "\e[31m[-] FAILED: 需要人工進行干預處理. \e[0m";exit;fi
# 4.判斷恢復到單實例還是cluster集群中。
if [ "${RECTARGET}" == "single" ];then
echo -e "\e[32m[*] 正在進行異常的K8S集群 -> 單實例數據恢復! \e[0m"
./K8SRedisRecovery.sh aof ${DATADIR}
return 0
else
echo -e "\e[32m[*] 正在進行異常的K8S集群 -> 集群數據恢復! \e[0m"
fi
# 5.redis集群資源清單(註意:此處預設是採用nfs類型的動態捲)
tee Redis-cluster-6.2.5.yaml <<'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-cluster-recovery
namespace: database
data:
update-node.sh: |
#!/bin/sh
if [ ! -f /data/nodes.conf ];then touch /data/nodes.conf;fi
REDIS_NODES="/data/nodes.conf"
sed -i -e "/myself/ s/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/${POD_IP}/" ${REDIS_NODES}
exec "$@"
redis.conf: |+
port 6379
protected-mode no
masterauth {RedisAuthPass}
requirepass {RedisAuthPass}
dir /data
dbfilename dump.rdb
rdbcompression yes
no-appendfsync-on-rewrite no
appendonly yes
appendfilename appendonly.aof
appendfsync everysec
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 128mb
# 集群模式打開
cluster-enabled yes
cluster-config-file /data/nodes.conf
cluster-node-timeout 5000
slave-read-only yes
# 當負責一個插槽的主庫下線且沒有相應的從庫進行故障恢復時集群仍然可用
cluster-require-full-coverage no
# 只有當一個主節點至少擁有其他給定數量個處於正常工作中的從節點的時候,才會分配從節點給集群中孤立的主節點
cluster-migration-barrier 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster-recovery
namespace: database
spec:
serviceName: redisclusterrecovery
replicas: 6
selector:
matchLabels:
app: redis-cluster-recovery
template:
metadata:
labels:
app: redis-cluster-recovery
spec:
containers:
- name: redis
image: redis:6.2.5-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: client
- containerPort: 16379
name: gossip
command: ["/conf/update-node.sh", "redis-server", "/conf/redis.conf"]
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: conf
mountPath: /conf
readOnly: false
- name: data
mountPath: /data
readOnly: false
- name: timezone
mountPath: /etc/localtime
volumes:
- name: conf
configMap:
name: redis-cluster-recovery
defaultMode: 0755
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
---
# headless Service
apiVersion: v1
kind: Service
metadata:
name: redisclusterrecovery
namespace: database
spec:
clusterIP: "None"
ports:
- port: 6379
targetPort: 6379
name: client
- port: 16379
targetPort: 16379
name: gossip
selector:
app: redis-cluster-recovery
EOF
sed -i "s#{RedisAuthPass}#${AUTH}#g" Redis-cluster-6.2.5.yaml
sed "s#replicas: 6#replicas: 0#g" Redis-cluster-6.2.5.yaml > Redis-cluster-6.2.5-empty.yaml
# 6.部署恢複數據的redis集群:判斷是否存在舊的資源對象,是則清理相關文件,否則創建集群。
sts=$(kubectl get sts -n database | grep -c "redis-cluster-recovery")
if [ ${sts} -eq 1 ];then
# 將副本數量至為0
kubectl apply -f Redis-cluster-6.2.5-empty.yaml;
podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery")
while [ ${run} -ne 0 ];do podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery");sleep 5;echo -n .; done
find ${K8SVOLUMNDIR}/database-data-redis-cluster-recovery-* -type f -delete;
# 清理後將副本數量至為6
kubectl apply -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
else
# 新建部署集群資源清單
kubectl create --save-config -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
fi
echo -e "\e[32m[*] Happy,redis-cluster-recovery Pod is Running....\e[0m"
kubectl get pod -n database -l app=redis-cluster-recovery
# 7.redis集群快速創建配置
echo -e "yes" | redis-cli -h redisclusterrecovery.${database.svc.cluster.local} -a weiyigeek --cluster create --cluster-replicas 1 $(kubectl get pods -n database -l app=redis-cluster-recovery -o jsonpath='{range.items[*]}{.status.podIP}:6379 '| sed "s# :6379 ##g")
# 將其他兩個Master卡槽歸於一個Master
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local} --no-auth-warning -a weiyigeek cluster nodes | grep "master" > /tmp/rnodes.log
cat /tmp/rnodes.log
m1=$(grep "0-5460" /tmp/rnodes.log | cut -d " " -f 1)
m2=$(grep "5461-10922" /tmp/rnodes.log | cut -d " " -f 1)
m3=$(grep "10923-16383" /tmp/rnodes.log | cut -d " " -f 1)
redis-cli --no-auth-warning -a weiyigeek --cluster reshard --cluster-from ${m2} --cluster-to ${m1} --cluster-slots 5462 --cluster-yes redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local}:6379 > /dev/null
redis-cli --no-auth-warning -a weiyigeek --cluster reshard --cluster-from ${m3} --cluster-to ${m1} --cluster-slots 5461 --cluster-yes redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local}:6379 > /dev/null
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local --no-auth-warning -a weiyigeek cluster nodes
echo -e "\e[32m[*] 請驗證Nodes信息是否無誤? 請輸入[Y|N] \e[0m"
read flag
if [ "${flag}" == "N" -o "${flag}" == "n" ];then echo -e "\e[31m[-] FAILED: 需要人工進行干預處理. \e[0m";exit;fi
# 8.將所有slots都歸於一個master節點後我們需要,將redisclusterrecovery 資源對象所管理的Pod先關閉。
# 將副本數量至為0
kubectl apply -f Redis-cluster-6.2.5-empty.yaml;
podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery")
while [ ${run} -ne 0 ];do podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery");sleep 5;echo -n .; done
# find ${K8SVOLUMNDIR}/database-data-redis-cluster-recovery-* -type f -delete;
# 此處只清空了redis持久化數據文件。
master=$(find /nfsdisk-31/data/*redis-cluster-recovery-0* -type d)
rm -rf ${master}/*.aof ${master}*/.rdb
cp ${DATADIR}/appendonly.aof {${master}}
# 清理後將副本數量至為6
kubectl apply -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
echo -e "\e[32m[*] Happy,redis-cluster-recovery Pod is Running....\e[0m"
kubectl get pod -n database -l app=redis-cluster-recovery
# 9.處理K8s重啟redis集群出現的fail問題,我們可以將錯誤節點剔出集群並重新指定節點信息加入到集群之中
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local --no-auth-warning -a weiyigeek cluster nodes | grep "fail" > /tmp/errnodes.log
# 將該從節點剔出集群
for err in $(cat /tmp/errnodes.log | cut -d " " -f 1);do
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -a weiyigeek cluster forget ${errid}
done
# 重新將該節點加入集群
for ip in $(kubectl get pods -n database -l app=redis-cluster-recovery -o jsonpath='{range.items[*]}{.status.podIP} '| sed "s# :6379 ##g");do
redis-cli -h -a weiyigeek cluster meet ${ip} 6379
done
# 10.集群狀態檢測以及重新分配slots卡槽到Master節點
redis-cli -h redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster check redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local:6379
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters redis-cluster-recovery-1.redisclusterrecovery.database.svc.cluster.local:6379
# 11.驗證分配的slots卡槽到各個Master節點節點信息。
redis-cli -h redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster check redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local:6379
# 12.主master節點驗證keyspace數據
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -c -a weiyigeek info keyspace
# 13.任何節點訪問恢復的數據
redis-cli -h redisclusterrecovery.database.svc.cluster.local -c -a weiyigeek
3.當Redis集群中出現從節點slave,fail,noaddr問題進行處理恢復流程。
- Step 1.利用cluster nodes查看你集群狀態,發現其中一個從節點異常(是Fail狀態)。
f86464011d9f8ec605857255c0b67cff1e794c19 :0@0 slave,fail,noaddr 2cb35944b4492748a8c739fab63a0e90a56e414a
- Step 2.在問題節點上查看節點狀態,發現它已脫離集群,且其ID都已發生了變化.
127.0.0.1:6379> cluster nodes
0cbf44ef3f9c3a8a473bcd303644388782e5ee78 192.168.109.132:6379@16379 myself,master - 0 0 0 connected 0-5461
Tips : 若id沒發生變化,直接重啟下該從節點就能解決。
- Step 3.但如果ID與Node IP都發生變化時,此時我們需要將該從節點剔出集群。
# 在集群每個正常節點上執行cluster forget 故障從節點id
echo 'cluster forget f86464011d9f8ec605857255c0b67cff1e794c19' | /usr/local/bin/redis-cli -a "weiyigeek"
- Step 4.我們重新將該節點加入集群,此時我們只需要 在集群內任意節點上執行
cluster meet命令加入新節點,握手狀態會通過信息在集群內傳播,這樣其他節點會自動發現新節點併發起握手流程。
# 1.使用集群強制聯繫指定節點(握手)
echo 'cluster meet 192.168.109.132 6379' | /usr/local/bin/redis-cli -p 6379 -a "密碼"
# 2.從節上執行cluster replicate 主節點id( 配置主從關係 )
echo 'cluster replicate 2cb35944b4492748a8c739fab63a0e90a56e414a' | /usr/local/bin/redis-cli -p 6383 -a "密碼"
- Step 5.最後檢測集群是否恢復正常,執行如下命令即可。
echo 'cluster nodes' | /usr/local/bin/redis-cli -p 6384 -a "密碼"
38287a7e715c358b5537a369646e9698a7583459 192.168.109.132:6383@16383 slave 2cb35944b4492748a8c739fab63a0e90a56e414a 0 1615233239757 8 connected
2cb35944b4492748a8c739fab63a0e90a56e414a 192.168.109.133:6383@16383 master - 0 1615233239000 8 connected 0-5461
.......
原文地址: https://blog.weiyigeek.top/2019/4-17-51.html
文章書寫不易,如果您覺得這篇文章還不錯的,請給這篇專欄 【點個贊、投個幣、收個藏、關個註,轉個發】(人間五大情),這將對我的肯定,謝謝!。
本文章來源 我的Blog站點 或 WeiyiGeek 公眾賬號 以及 我的BiliBili專欄 (
技術交流、友鏈交換請郵我喲),謝謝支持!(๑′ᴗ‵๑) ❤
歡迎各位志同道合的朋友一起學習交流,如文章有誤請留下您寶貴的知識建議,通過郵箱【master#weiyigeek.top】聯繫我喲!

