
時間真是好快啊,又到每日跟大家分享Python小技巧的時候了,今天跟大家分享的是爬取豆瓣top250電影。這篇文章我會把源碼 以及視頻教程給大家,想學的小伙伴可以動手操辦起來。話不多說,這就來。 ## 1.python程式 Python學習交流Q群:906715085### #導入庫 import ...
時間真是好快啊,又到每日跟大家分享Python小技巧的時候了,今天跟大家分享的是爬取豆瓣top250電影。這篇文章我會把源碼
以及視頻教程給大家,想學的小伙伴可以動手操辦起來。話不多說,這就來。

## 1.python程式
Python學習交流Q群:906715085### #導入庫 import requests import parsel import xlsxwriter
Python學習交流Q群:906715085### #導入庫 import requests import parsel import xlsxwriter
Python學習交流Q群:906715085### #創建excel,設置列寬 wb=xlsxwriter.Workbook('豆瓣電影.xlsx') ws=wb.add_worksheet('豆瓣電影海報') ws.set_column('A:A',7) ws.set_column('B:B',30) ws.set_column(2,3,50) ws.set_column('G:G',30)
#標題行 headings=['海報','名稱','導演','主演','年份','國家','類型']
#設置excel風格 ws.set_tab_color('red') head_format=wb.add_format({'bold':1,'fg_color':'cyan','align':'center','font_name':u'微軟雅黑','valign':'vcenter'}) cell_format=wb.add_format({'bold':0,'align':'center','font_name':u'微軟雅黑','valign':'vcenter'}) ws.write_row('A1',headings,head_format)
#創建空列表 j=0 actor_1=[] actor_2=[] year=[] country=[] movie_type=[]
#發送請求,獲取響應,遍歷豆瓣電影信息 for i in range(0,250,25): url='https://movie.douban.com/top250?start='+str(i) response=requests.get(url,headers=headers) response.encoding=response.apparent_encoding selector=parsel.Selector(response.text) lis=selector.css('#content>div>div.article>ol>li>div>div.pic>a>img::attr(src)').getall() title=selector.css('#content>div>div.article>ol>li>div>div.info>div.hd>a>span:nth-child(1)::text').getall() director_info=selector.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]').getall() movie_info = selector.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[2]').getall()
# 提取並清洗導演、主演標簽信息 for director in director_info: director=director.strip().replace('\xa0\xa0\xa0',' ').replace('...','').replace('導演: ','').split('主演: ') if len(director)>1: actor_1.append(director[0]) actor_2.append(director[1]) else: actor_1.append(director[0]) actor_2.append('None')
#提取並清洗電影年份、國家、類型標簽信息 for detail in movie_info: detail=detail.strip().split('\xa0/\xa0') year.append(detail[0]) country.append(detail[1]) movie_type.append(detail[2])
#下載電影海報信息到本地 for n in range(len(lis)): img=requests.get(lis[n]).content with open(f'./圖片/{title[n]}.jpg','wb') as f: f.write(img)
# 將獲取到的各種標簽信息寫入excel for k in range(len(lis)): ws.set_row(k+1+j*25,60) ws.insert_image('A'+str(k+2+j*25),f'./圖片/{title[k]}.jpg',{'x_scale':0.2,'y_scale':0.2}) ws.write(k+1+j*25,1,title[k],cell_format) ws.write(k+1+j*25,2,actor_1[k+j*25],cell_format) ws.write(k+1+j*25,3,actor_2[k+j*25],cell_format) ws.write(k+1+j*25,4,year[k+j*25],cell_format) ws.write(k+1+j*25,5,country[k+j*25],cell_format) ws.write(k+1+j*25,6,movie_type[k+j*25],cell_format) j+=1 wb.close()
## 2.效果

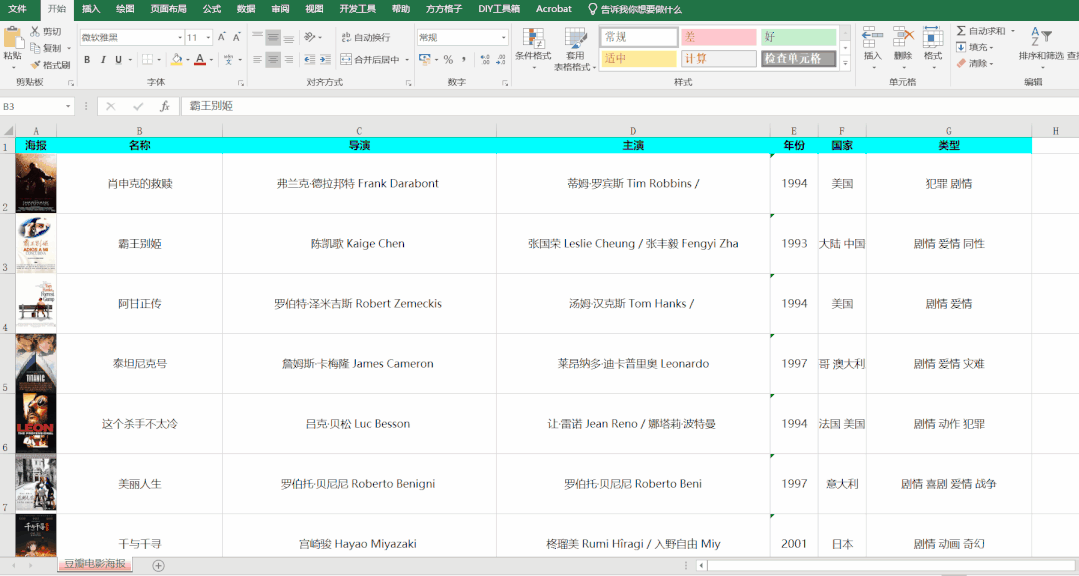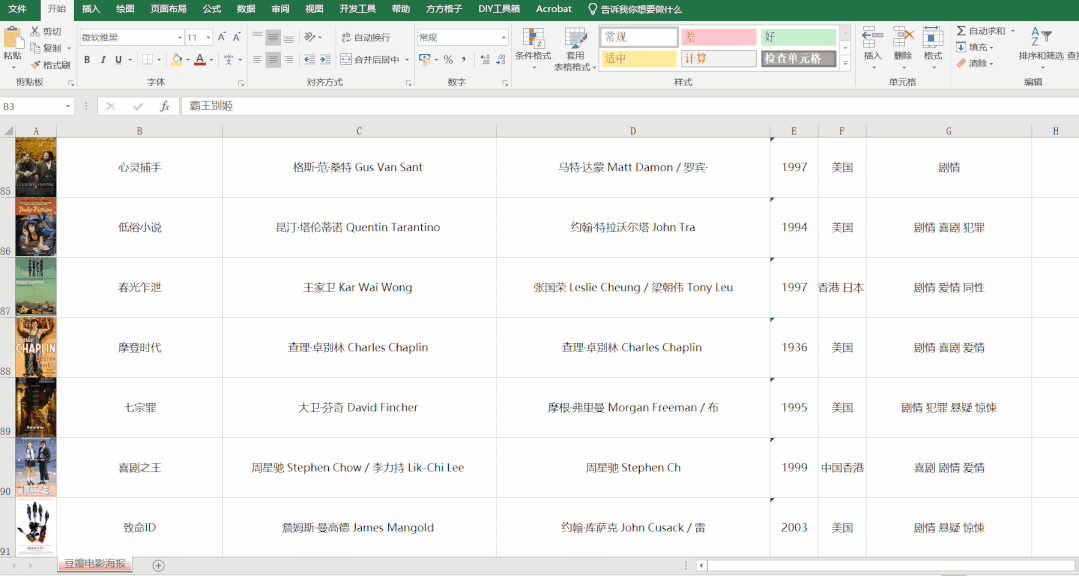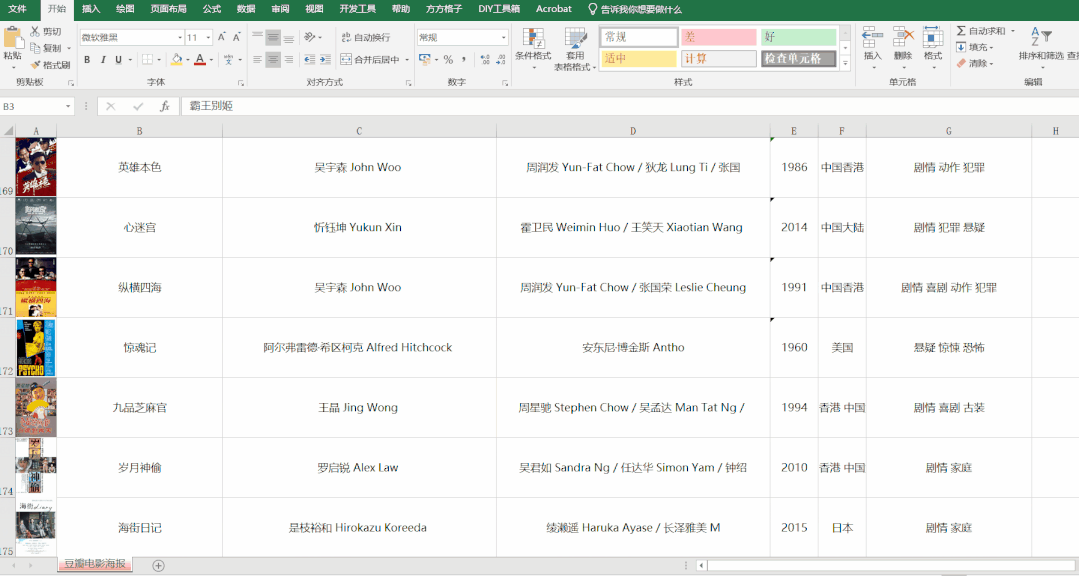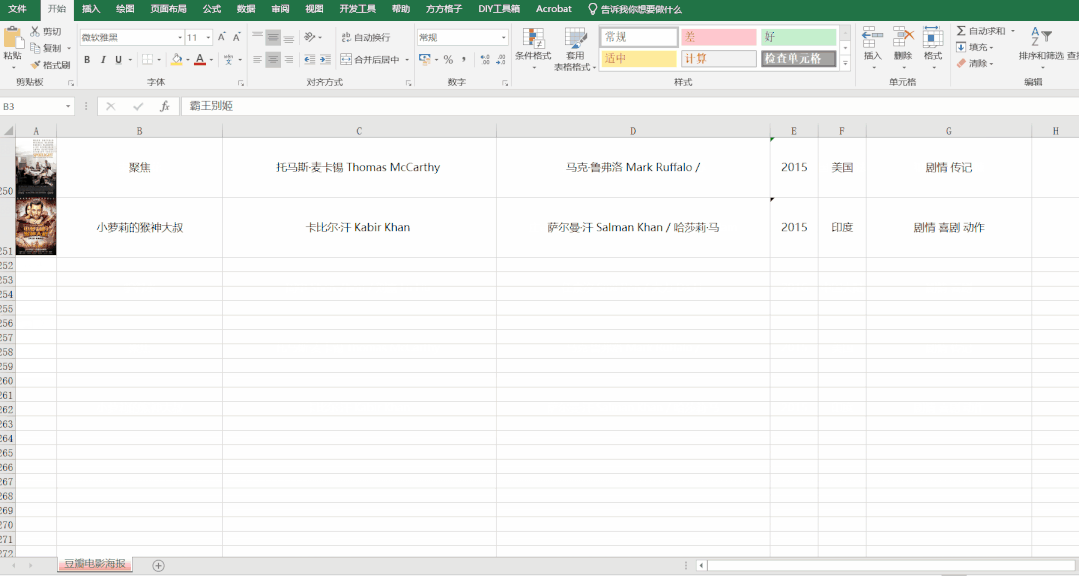
## 3.視頻教程
視頻鏈接: https://www.bilibili.com/video/BV1hL4y1L7mq?share_source=copy_web 學不會的跟視頻做
## 4.結尾
源碼以及視頻教程都給大家放在上面了,各位小伙伴不妨動手試試。疫情居家沒有劇看是很痛苦的,記得點一個大大的贊。



