
一、Hadoop概述 Hadoop是Apache軟體基金會下一個開源分散式計算平臺,以HDFS(Hadoop Distributed File System)、MapReduce(Hadoop2.0加入了YARN,Yarn是資源調度框架,能夠細粒度的管理和調度任務,還能夠支持其他的計算框架,比如sp ...
目錄
一、Hadoop概述
Hadoop是Apache軟體基金會下一個開源分散式計算平臺,以HDFS(Hadoop Distributed File System)、MapReduce(Hadoop2.0加入了YARN,Yarn是資源調度框架,能夠細粒度的管理和調度任務,還能夠支持其他的計算框架,比如spark)為核心的Hadoop為用戶提供了系統底層細節透明的分散式基礎架構。hdfs的高容錯性、高伸縮性、高效性等優點讓用戶可以將Hadoop部署在低廉的硬體上,形成分散式系統。目前最新版本已經是3.x了,官方文檔。也可以參考我之前的文章:Hadoop生態系統介紹
二、HDFS詳解
1)HDFS概述
HDFS(Hadoop Distributed File System)是Hadoop項目的核心子項目,是分散式計算中數據存儲管理的基礎,是基於流數據模式訪問和處理超大文件的需求而開發的,可以運行於廉價的商用伺服器上。它所具有的高容錯、高可靠性、高可擴展性、高獲得性、高吞吐率等特征為海量數據提供了不怕故障的存儲,為超大數據集(Large Data Set)的應用處理帶來了很多便利。HDFS 源於 Google 在2003年10月份發表的GFS(Google File System) 論文。 它其實就是 GFS(Google File System) 的一個克隆版本。
HDFS的設計特點
之所以選擇 HDFS 存儲數據,因為 HDFS 具有以下優點:
- 高容錯性:數據自動保存多個副本。它通過增加副本的形式,提高容錯性。某一個副本丟失以後,它可以自動恢復,這是由 HDFS 內部機制實現的,我們不必關心。
- 適合批處理:它是通過移動計算而不是移動數據。它會把數據位置暴露給計算框架。
- 適合大數據處理:處理數據達到 GB、TB、甚至PB級別的數據。能夠處理百萬規模以上的文件數量,數量相當之大。能夠處理10K節點的規模。
- 流式文件訪問:一次寫入,多次讀取。文件一旦寫入不能修改,只能追加。它能保證數據的一致性。
- 可構建在廉價機器上:它通過多副本機制,提高可靠性。它提供了容錯和恢復機制。比如某一個副本丟失,可以通過其它副本來恢復。
當然 HDFS 也有它的劣勢,並不適合所有的場合:
-
低延時數據訪問:它適合高吞吐率的場景,就是在某一時間內寫入大量的數據。但是它在低延時的情況下是不行的,比如毫秒級以內讀取數據,這樣它是很難做到的。
-
小文件存儲:存儲大量小文件(這裡的小文件是指小於HDFS系統的Block大小的文件(Hadoop 3.x預設128M)的話,它會占用 NameNode大量的記憶體來存儲文件、目錄和塊信息。這樣是不可取的,因為NameNode的記憶體總是有限的。小文件存儲的尋道時間會超過讀取時間,它違反了HDFS的設計目標。
-
併發寫入、文件隨機修改:一個文件只能有一個寫,不允許多個線程同時寫。僅支持數據 append(追加),不支持文件的隨機修改。
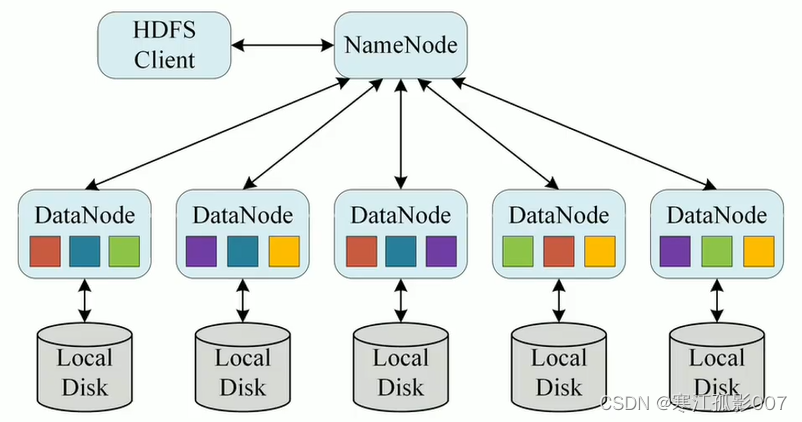
2)HDFS組成
HDFS 採用Master/Slave的架構來存儲數據,這種架構主要由四個部分組成,分別為HDFS Client、NameNode、DataNode和Secondary NameNode。下麵我們分別介紹這四個組成部分 :
1、Client
Client就是客戶端
- 文件切分。文件上傳 HDFS 的時候,Client 將文件切分成 一個一個的- Block,然後進行存儲。
- 與 NameNode 交互,獲取文件的位置信息。
- 與 DataNode 交互,讀取或者寫入數據。
- Client 提供一些命令來管理 HDFS,比如啟動或者關閉HDFS。
- Client 可以通過一些命令來訪問 HDFS。
2、NameNode(NN)
NameNode就是 master,它是一個主管、管理者。
3、DataNode(DN)
DataNode就是Slave。NameNode 下達命令,DataNode 執行實際的操作。
- 存儲實際的數據塊。
- 執行數據塊的讀/寫操作。
4、Secondary NameNode(2NN)
Secondary NameNode並非 NameNode 的熱備。當NameNode 掛掉的時候,它並不能馬上替換 NameNode 並提供服務。
- Secondary NameNode僅僅是NameNode的一個工具,這個工具幫助NameNode管理元數據信息。
- 定期合併 fsimage和fsedits,並推送給NameNode。
- 在緊急情況下,可輔助恢復 NameNode。
3)HDFS具體工作原理
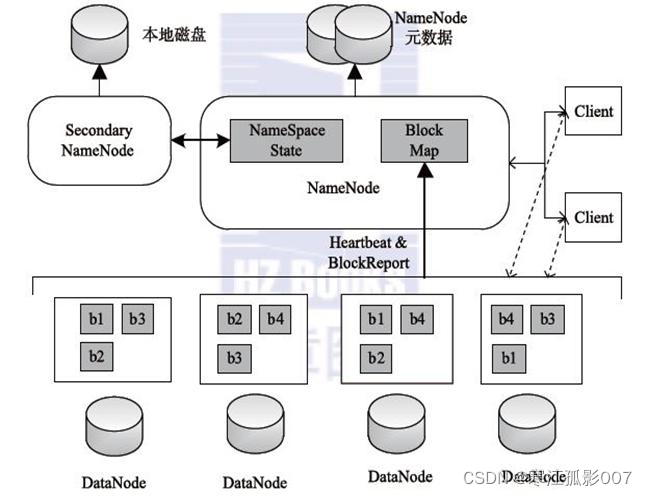
1、兩個核心的數據結構: Fslmage和EditLog
- FsImage負責維護文件系統樹和樹中所有文件和文件夾的元數據。
———維護文件結構和文件元信息的鏡像 - EditLog操作日誌文件中記錄了所有針對文件的創建,刪除,重命名操作。
———記錄對文件的操作
PS:
1.NN的元數據為了讀寫速度塊是寫在記憶體里的,FsImage只是它的一個鏡像保存文件
2.當每輸入一個增刪改操作,EditLog都會單獨生成一個文件,最後EL會生成多個文件
3.2NN不是NN的備份(但可以做備份),它的主要工作是幫助NN合併edits log,減少NN啟動時間。
4.拓撲距離:根據節點網路構成的樹形結構計算最短路徑
5.機架感知:根據拓撲距離得到的節點擺放位置
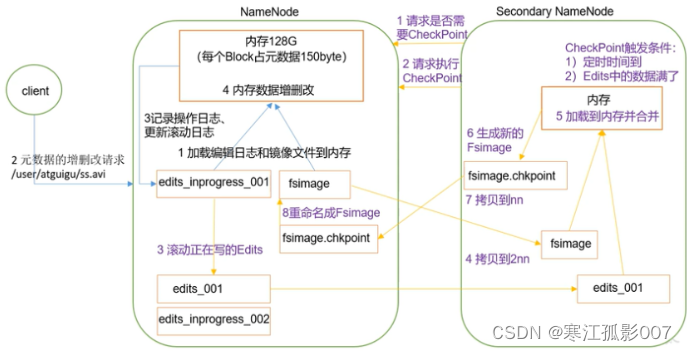
2、工作流程
- 第一步: 當客戶端對元數據進行增刪改請求時,由於hadoop安全性要求比較高,它會先將操作寫入到editlog文件里,先持久化。
- 第二步: 然後將具體增刪改操作,將FSimage和edit寫入記憶體里進行具體的操作,先寫文件,即使宕機了也可以恢複數據,不然先記憶體數據就會消失,此時2NN發現時間到了,或者edit數據滿了或者剛開機時,就會請求執行輔助操作,NN收到後將edit瞬間複製一份,這個時候客戶端傳過來的數據繼續寫到edit里。
- 第三步:我們把複製的edit和fsimage拷貝到2NN(SecondaryNameNode)里,操作寫在2NN的記憶體里合併,合併後將文件返回給NN做為新的Fsimage。所以一旦NN宕機2NN比NN差一個edit部分,無法完全恢複原先狀態,只能說輔助恢復。
3、HDFS讀文件流程
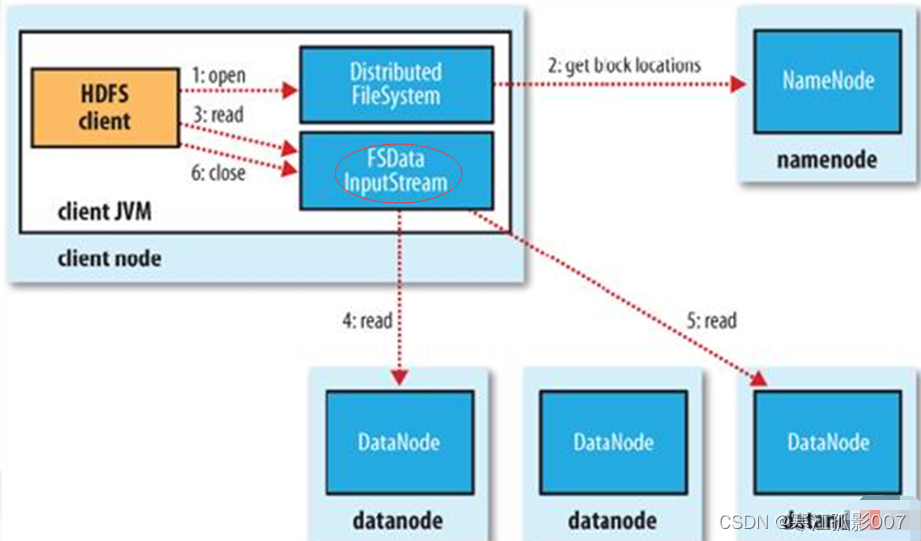
【第一步】Client調用FileSystem.open()方法
- FileSystem通過RPC與NN通信,NN返回該文件的部分或全部block列表(含有block拷貝的DN地址)。
- 選取舉慄客戶端最近的DN建立連接,讀取block,返回FSDataInputStream。
【第二步】Client調用輸入流的read()方法
- 當讀到block結尾時,FSDataInputStream關閉與當前DN的連接,並未讀取下一個block尋找最近DN。
- 讀取完一個block都會進行checksum驗證,如果讀取DN時出現錯誤,客戶端會通知NN,然後再從下一個擁有該block拷貝的DN繼續讀。
- 如果block列表讀完後,文件還未結束,FileSystem會繼續從NN獲取下一批block列表。
【第三步】關閉FSDataInputStream
4、HDFS文件寫入流程
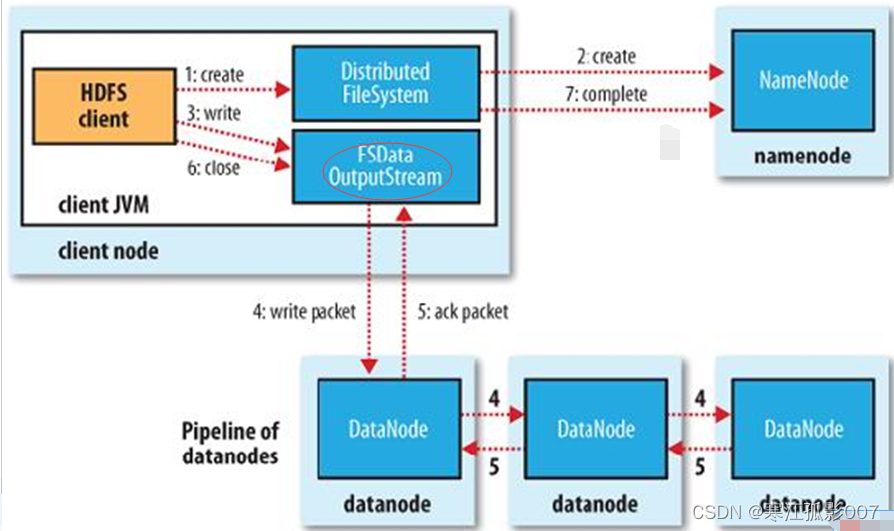
【第一步】Client調用FileSystem的create()方法
- FileSystem向NN發出請求,在NN的namespace裡面創建一個新的文件,但是並不關聯任何塊。
- NN檢查文件是否已經存在、操作許可權。如果檢查通過,NN記錄新文件信息,併在某一個DN上創建數據塊。
- 返回FSDataOutputStream,將Client引導至該數據塊執行寫入操作。
【第二步】Client調用輸出流的write()方法
- HDFS預設將每個數據塊放置3份。FSDataOutputStream將數據首先寫到第一節點,第一節點將數據包傳送並寫入第二節點,第二節點 --> 第三節點。
【第三步】Client調用流的close()方法
- flush緩衝區的數據包,block完成複製份數後,NN返回成功消息。
三、Yarn詳解
1)Yarn概述
Apache Yarn(Yet Another Resource Negotiator的縮寫)是hadoop集群資源管理器系統,Yarn從hadoop 2引入,最初是為了改善MapReduce的實現,但是它具有通用性,同樣執行其他分散式計算模式。
Yarn特點:
- 支持非mapreduce應用的需求
- 可擴展性
- 提高資源是用率
- 用戶敏捷性
- 可以通過搭建為高可用
2)YARN架構組件
Yarn從整體上還是屬於master/slave模型,主要依賴於三個組件來實現功能,第一個就是ResourceManager,是集群資源的仲裁者,它包括兩部分:一個是可插拔式的調度Scheduler,一個是ApplicationManager,用於管理集群中的用戶作業。第二個是每個節點上的NodeManager,管理該節點上的用戶作業和工作流,也會不斷發送自己Container使用情況給ResourceManager。第三個組件是ApplicationMaster,用戶作業生命周期的管理者它的主要功能就是向ResourceManager(全局的)申請計算資源(Containers)並且和NodeManager交互來執行和監控具體的task。架構圖如下:
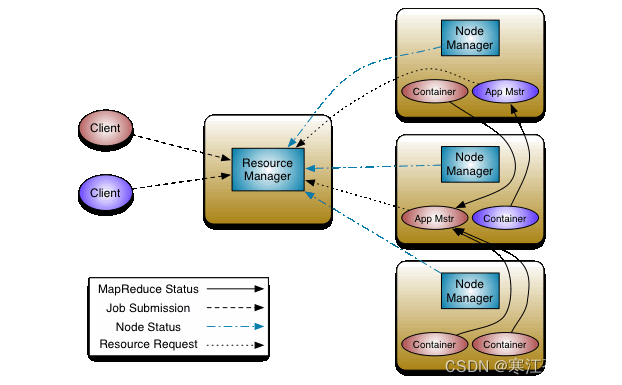
1、ResourceManager(RM)
RM是一個全局的資源管理器,管理整個集群的計算資源,並將這些資源分配給應用程式。包括:
- 與客戶端交互,處理來自客戶端的請求
- 啟動和管理ApplicationMaster,併在它運行失敗時重新啟動它
- 管理NodeManager ,接收來自NodeManager 的資源彙報信息,並向NodeManager下達管理指令
- 資源管理與調度,接收來自ApplicationMaster 的資源申請請求,併為之分配資源
RM關鍵配置參數:
- 最小容器記憶體: yarn.scheduler.minimum-allocation-mb
- 容器記憶體增量: yarn.scheduler.increment-allocation-mb
- 最大容器記憶體: yarn.scheduler.maximum-allocation-mb
- 最小容器虛擬 CPU 內核數量: yarn.scheduler.minimum-allocation-mb
- 容器虛擬 CPU 內核增量: yarn.scheduler.increment-allocation-vcores
- 最大容器虛擬 CPU 內核數量: yarn.scheduler.maximum-allocation-mb
- ResourceManager Web 應用程式 HTTP 埠: yarn.resourcemanager.webapp.address
2、ApplicationMaster(AM)
應用程式級別的,管理運行在YARN上的應用程式。包括:
- 用戶提交的每個應用程式均包含一個AM,它可以運行在RM以外的機器上。
- 負責與RM調度器協商以獲取資源(用Container表示)
- 將得到的資源進一步分配給內部的任務(資源的二次分配)
- 與NM通信以啟動/停止任務。
- 監控所有任務運行狀態,併在任務運行失敗時重新為任務申請資源以重啟任務
AM關鍵配置參數:
- ApplicationMaster 最大嘗試次數: yarn.resourcemanager.am.max-attempts
- ApplicationMaster 監控過期: yarn.am.liveness-monitor.expiry-interval-ms
3、NodeManager(NM)
YARN中每個節點上的代理,它管理Hadoop集群中單個計算節點。包括:
- 啟動和監視節點上的計算容器(Container)
- 以心跳的形式向RM彙報本節點上的資源使用情況和各個Container的運行狀態(CPU和記憶體等資源)
- 接收並處理來自AM的Container啟動/停止等各種請求
NM關鍵配置參數:
- 節點記憶體: yarn.nodemanager.resource.memory-mb
- 節點虛擬 CPU 內核: yarn.nodemanager.resource.cpu-vcores
- NodeManager Web 應用程式 HTTP 埠: yarn.nodemanager.webapp.address
4、Container
Container是YARN中資源的抽象,它封裝了某個節點上的多維度資源,如記憶體、CPU、磁碟、網路等。Container由AM向RM申請的,由RM中的資源調度器非同步分配給AM。Container的運行是由AM向資源所在的NM發起。
一個應用程式所需的Container分為兩大類:
- 運行AM的Container:這是由RM(向內部的資源調度器)申請和啟動的,用戶提交應用程式時,可指定唯一的AM所需的資源;
- 運行各類任務的Container:這是由AM向RM申請的,並由AM與NM通信以啟動之。
以上兩類Container可能在任意節點上,它們的位置通常而言是隨機的,即AM可能與它管理的任務運行在一個節點上。
3)YARN運行流程
Application在Yarn中的執行過程如下圖所示:
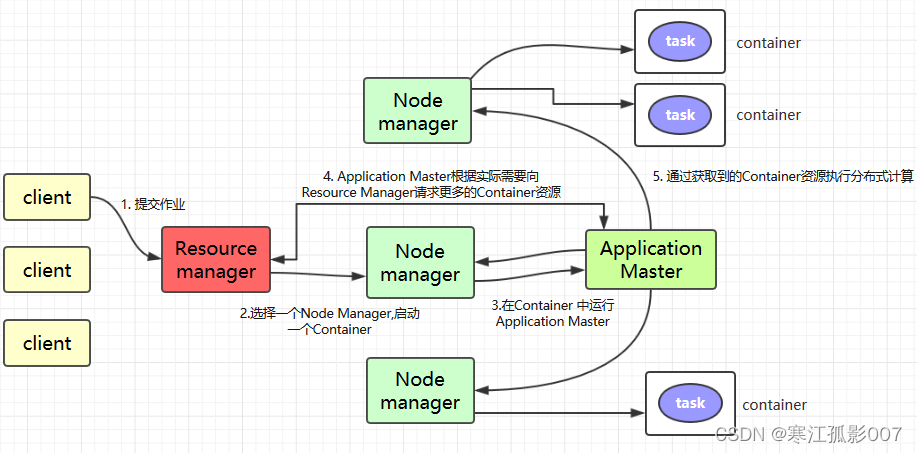
-
客戶端程式向ResourceManager提交應用並請求一個ApplicationMaster實例,ResourceManager在應答中給出一個applicationID以及有助於客戶端請求資源的資源容量信息。
-
ResourceManager找到可以運行一個Container的NodeManager,併在這個Container中啟動ApplicationMaster實例
- Application Submission Context發出響應,其中包含有:ApplicationID,用戶名,隊列以及其他啟動ApplicationMaster的信息,Container Launch Context(CLC)也會發給ResourceManager,CLC提供了資源的需求,作業文件,安全令牌以及在節點啟動ApplicationMaster所需要的其他信息。
- 當ResourceManager接收到客戶端提交的上下文,就會給ApplicationMaster調度一個可用的container(通常稱為container0)。然後ResourceManager就會聯繫NodeManager啟動ApplicationMaster,並建立ApplicationMaster的RPC埠和用於跟蹤的URL,用來監控應用程式的狀態。
-
ApplicationMaster向ResourceManager進行註冊,註冊之後客戶端就可以查詢ResourceManager獲得自己ApplicationMaster的詳細信息,以後就可以和自己的ApplicationMaster直接交互了。在註冊響應中,ResourceManager會發送關於集群最大和最小容量信息,
-
在平常的操作過程中,ApplicationMaster根據resource-request協議向ResourceManager發送resource-request請求,ResourceManager會根據調度策略儘可能最優的為ApplicationMaster分配container資源,作為資源請求的應答發個ApplicationMaster
-
當Container被成功分配之後,ApplicationMaster通過向NodeManager發送container-launch-specification信息來啟動Container, container-launch-specification信息包含了能夠讓Container和ApplicationMaster交流所需要的資料,一旦container啟動成功之後,ApplicationMaster就可以檢查他們的狀態,Resourcemanager不在參與程式的執行,只處理調度和監控其他資源,Resourcemanager可以命令NodeManager殺死container,
-
應用程式的代碼在啟動的Container中運行,並把運行的進度、狀態等信息通過application-specific協議發送給ApplicationMaster,隨著作業的執行,ApplicationMaster將心跳和進度信息發給ResourceManager,在這些心跳信息中,ApplicationMaster還可以請求和釋放一些container。
-
在應用程式運行期間,提交應用的客戶端主動和ApplicationMaster交流獲得應用的運行狀態、進度更新等信息,交流的協議也是application-specific協議
-
一但應用程式執行完成並且所有相關工作也已經完成,ApplicationMaster向ResourceManager取消註冊然後關閉,用到所有的Container也歸還給系統,當container被殺死或者回收,Resourcemanager都會通知NodeManager聚合日誌並清理container專用的文件。
4)YARN三種資源調度器
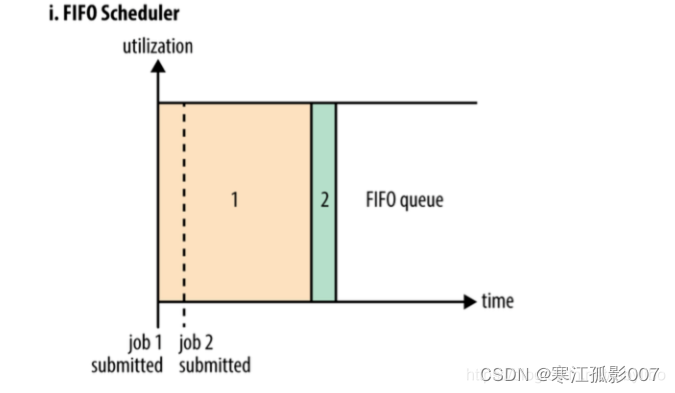
1、FIFO調度器(FIFO Scheduler)
FIFO調度器的優點是簡單易懂不需要任何配置,但是不適合共用集群。大型應用會占用集群中的所有資源,所以每個應用必須等待直到輪到自己運行。在一個共用集群中,更適合使用容量調度器或公平調度器。這兩種調度器都允許長時間運行的作業能及時完成,同時也允許正在進行較小臨時查詢的用戶能夠在合理時間內得到返回結果。
2、容量調度器(Capacity Scheduler)
容量調度器允許多個組織共用一個Hadoop集群,每個組織可以分配到全部集群資源的一部分。每個組織被配置一個專門的隊列,每個隊列被配置為可以使用一定的集群資源。隊列可以進一步按層次劃分,這樣每個組織內的不同用戶能夠共用該組織隊列所分配的資源。在一個隊列內,使用FIFO調度策略對應用進行調度。
- 單個作業使用的資源不會超過其隊列容量。然而如果隊列中有多個作業,並且隊列資源不夠了呢?這時如果仍有可用的空閑資源那麼容量調度器可能會將空餘的資源分配給隊列中的作業,哪怕這會超出隊列容量。這被稱為彈性隊列(queue elasticity)。
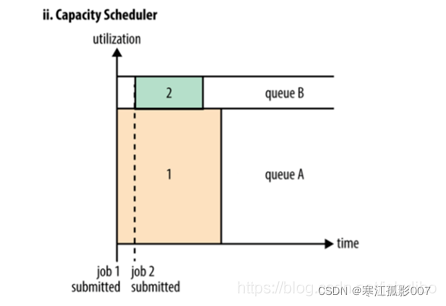
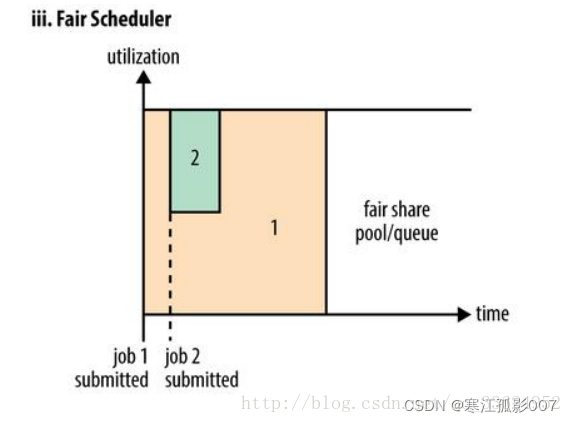
3、資源調度器- Fair
公平調度是一種對於全局資源,對於所有應用作業來說,都均勻分配的資源分配方法。預設情況,公平調度器FairScheduler基於記憶體來安排公平調度策略。也可以配置為同時基於記憶體和CPU來進行調度(Dominant Resource Fairness)。在一個隊列內,可以使用FIFO、FAIR、DRF調度策略對應用進行調度。FairScheduler允許保障性的分配最小資源到隊列。
- 【註意】在下圖 Fair 調度器中,從第二個任務提交到獲得資源會有一定的延遲,因為它需要等待第一個任務釋放占用的 Container。小任務執行完成之後也會釋放自己占用的資源,大任務又獲得了全部的系統資源。最終效果就是 Fair 調度器即得到了高的資源利用率又能保證小任務及時完成。
四、MapReduce詳解
1)MapReduce概述
MapReduce是一種編程模型(沒有集群的概念,會把任務提交到yarn集群上跑),用於大規模數據集(大於1TB)的並行運算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分散式並行編程的情況下,將自己的程式運行在分散式系統上。 當前的軟體實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定併發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共用相同的鍵組。(MapReduce在企業里幾乎不再使用了,稍微瞭解即可)
2)MapReduce運行流程
作業的運行過程主要包括如下幾個步驟:
1、作業的提交
2、作業的初始化
3、作業任務的分配
4、作業任務的執行
5、作業執行狀態更新
6、作業完成
具體作業執行過程的流程圖如下圖所示:
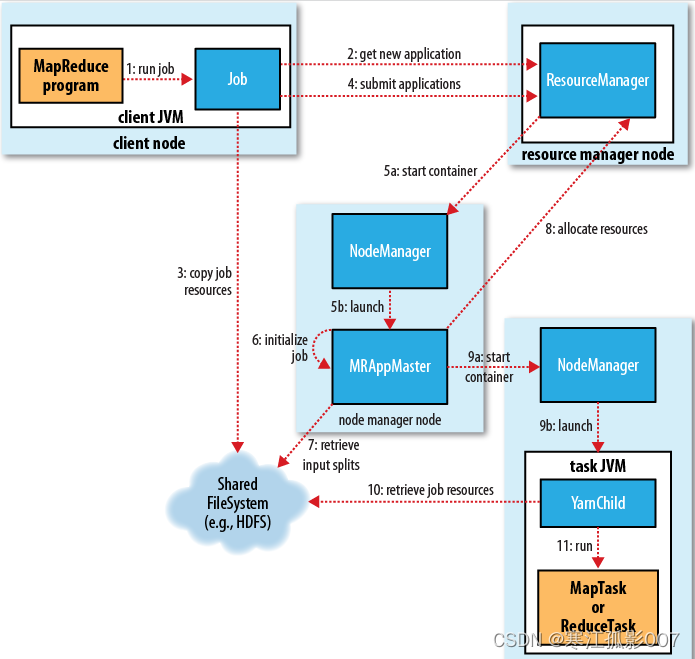
1、作業的提交
在MR的代碼中調用waitForCompletion()方法,裡面封裝了Job.submit()方法,而Job.submit()方法裡面會創建一個JobSubmmiter對象。當我們在waitForCompletion(true)時,則waitForCompletion方法會每秒輪詢作業的執行進度,如果發現與上次查詢到的狀態有差別,則將詳情列印到控制台。如果作業執行成功,就顯示作業計數器,否則將導致作業失敗的記錄輸出到控制台。
其中JobSubmmiter實現的大概過程如下:
- 向資源管理器resourcemanager提交申請,用於一個mapreduce作業ID,如圖步驟2所示
- 檢查作業的輸出配置,判斷目錄是否已經存在等信息
- 計算作業的輸入分片的大小
- 將運行作業的jar,配置文件,輸入分片的計算資源複製到一個以作業ID命名的hdfs臨時目錄下,作業jar的複本比較多,預設為10個(通過參數mapreduce.client.submit.file.replication控制),
- 通過資源管理器的submitApplication方法提交作業
2、作業的初始化
-
當資源管理器通過方法submitApplication方法被調用後,便將請求傳給了yarn的調度器,然後調度器在一個節點管理器上分配一個容器(container0)用來啟動application master(主類是MRAppMaster)進程。該進程一旦啟動就會向resourcemanager註冊並報告自己的信息,application master並且可以監控map和reduce的運行狀態。因此application master對作業的初始化是通過創建多個薄記對象以保持對作業進度的跟蹤。
-
application master接收作業提交時的hdfs臨時共用目錄中的資源文件,jar,分片信息,配置信息等。並對每一個分片創建一個map對象,以及通過mapreduce.job.reduces參數(作業通過setNumReduceTasks()方法設定)確定reduce的數量。
-
application master會判斷是否使用uber(作業與application master在同一個jvm運行,也就是maptask和reducetask運行在同一個節點上)模式運行作業,uber模式運行條件:map數量小於10個,1個reduce,且輸入數據小於一個hdfs塊
可以通過參數:
mapreduce.job.ubertask.enable #是否啟用uber模式
mapreduce.job.ubertask.maxmaps #ubertask的最大map數
mapreduce.job.ubertask.maxreduces #ubertask的最大reduce數
mapreduce.job.ubertask.maxbytes #ubertask最大作業大小
- application master調用setupJob方法設置OutputCommiter,FileOutputCommiter為預設值,表示建立做的最終輸出目錄和任務輸出的臨時工作空間
3、作業任務的分配
-
在application master判斷作業不符合uber模式的情況下,那麼application master則會向資源管理器為map和reduce任務申請資源容器。
-
首先就是為map任務發出資源申請請求,直到有5%的map任務完成時,才會為reduce任務所需資源申請發出請求。
-
在任務的分配過程中,reduce任務可以在任何的datanode節點運行,但是map任務執行的時候需要考慮到數據本地化的機制,在給任務指定資源的時候每個map和reduce預設為1G記憶體,可以通過如下參數配置:
mapreduce.map.memory.mb
mapreduce.map.cpu.vcores
mapreduce.reduce.memory.mb
mapreduce.reduce.cpu.vcores
4、作業任務的執行
application master提交申請後,資源管理器為其按需分配資源,這時,application master就與節點管理器通信來啟動容器。該任務由主類YarnChild的一個java應用程式執行。在運行任務之前,首先將所需的資源進行本地化,包括作業的配置,jar文件等。接下來就是運行map和reduce任務。YarnChild在單獨的JVM中運行。
5、作業任務的狀態更新
每個作業和它的每個任務都有一個狀態:作業或者任務的狀態(運行中,成功,失敗等),map和reduce的進度,作業計數器的值,狀態消息或描述當作業處於正在運行中的時候,客戶端可以直接與application master通信,每秒(可以通過參數mapreduce.client.progressmonitor.pollinterval設置)輪詢作業的執行狀態,進度等信息。
6、作業的完成
- 當application master收到最後一個任務已完成的通知,便把作業的狀態設置為成功。
- 在job輪詢作業狀態時,知道任務已經完成,然後列印消息告知用戶,並從waitForCompletion()方法返回。
- 當作業完成時,application master和container會清理中間數據結果等臨時問題。OutputCommiter的commitJob()方法被調用,作業信息由作業歷史服務存檔,以便用戶日後查詢。
3)MapReduce中的shuffle過程
mapreduce確保每個reduce的輸入都是按照鍵值排序的,系統執行排序,將map的輸入作為reduce的輸入過程稱之為shuffle過程。shuffle也是我們優化的重點部分。shuffle流程圖如下圖所示:
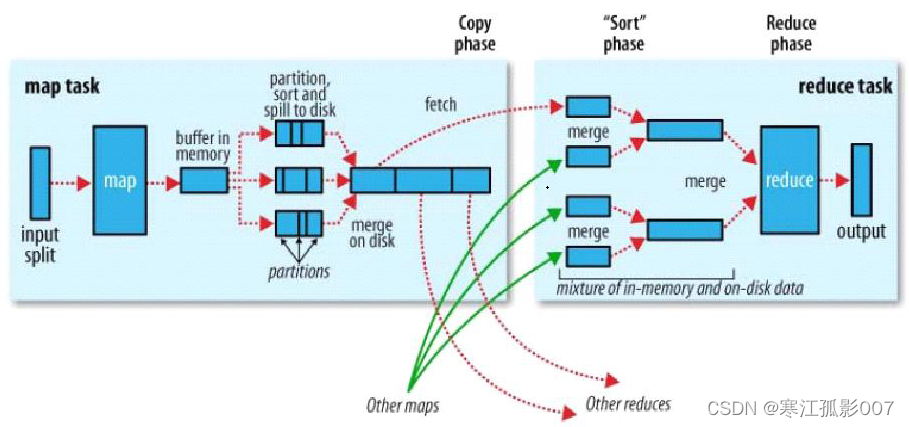
1、map端
-
在生成map之前,會計算文件分片的大小
-
然後會根據分片的大小計算map的個數,對每一個分片都會產生一個map作業,或者是一個文件(小於分片大小*1.1)生成一個map作業,然後通過自定的map方法進行自定義的邏輯計算,計算完畢後會寫到本地磁碟。
-
在這裡不是直接寫入磁碟,為了保證IO效率,採用了先寫入記憶體的環形緩衝區,並做一次預排序(快速排序)。緩衝區的大小預設為100MB(可通過修改配置項mpareduce.task.io.sort.mb進行修改),當寫入記憶體緩衝區的大小到達一定比例時,預設為80%(可通過mapreduce.map.sort.spill.percent配置項修改),將啟動一個溢寫線程將記憶體緩衝區的內容溢寫到磁碟(spill to disk),這個溢寫線程是獨立的,不影響map向緩衝區寫結果的線程,在溢寫到磁碟的過程中,map繼續輸入到緩衝中,如果期間緩衝區被填滿,則map寫會被阻塞到溢寫磁碟過程完成。溢寫是通過輪詢的方式將緩衝區中的記憶體寫入到本地mapreduce.cluster.local.dir目錄下。在溢寫到磁碟之前,我們會知道reduce的數量,然後會根據reduce的數量劃分分區,預設根據hashpartition對溢寫的數據寫入到相對應的分區。在每個分區中,後臺線程會根據key進行排序,所以溢寫到磁碟的文件是分區且排序的。如果有combiner函數,它在排序後的輸出運行,使得map輸出更緊湊。減少寫到磁碟的數據和傳輸給reduce的數據。
-
每次環形換沖區的記憶體達到閾值時,就會溢寫到一個新的文件,因此當一個map溢寫完之後,本地會存在多個分區切排序的文件。在map完成之前會把這些文件合併成一個分區且排序(歸併排序)的文件,可以通過參數mapreduce.task.io.sort.factor控制每次可以合併多少個文件。
-
在map溢寫磁碟的過程中,對數據進行壓縮可以提交速度的傳輸,減少磁碟io,減少存儲。預設情況下不壓縮,使用參數mapreduce.map.output.compress控制,壓縮演算法使用mapreduce.map.output.compress.codec參數控制。
-
2、reduce端
- map任務完成後,監控作業狀態的application master便知道map的執行情況,並啟動reduce任務,application master並且知道map輸出和主機之間的對應映射關係,reduce輪詢application master便知道主機所要複製的數據。
- 一個Map任務的輸出,可能被多個Reduce任務抓取。每個Reduce任務可能需要多個Map任務的輸出作為其特殊的輸入文件,而每個Map任務的完成時間可能不同,當有一個Map任務完成時,Reduce任務就開始運行。Reduce任務根據分區號在多個Map輸出中抓取(fetch)對應分區的數據,這個過程也就是Shuffle的copy過程。。reduce有少量的複製線程,因此能夠並行的複製map的輸出,預設為5個線程。可以通過參數mapreduce.reduce.shuffle.parallelcopies控制。
- 這個複製過程和map寫入磁碟過程類似,也有閥值和記憶體大小,閥值一樣可以在配置文件里配置,而記憶體大小是直接使用reduce的tasktracker的記憶體大小,複製時候reduce還會進行排序操作和合併文件操作。
- 如果map輸出很小,則會被覆制到Reducer所在節點的記憶體緩衝區,緩衝區的大小可以通過mapred-site.xml文件中的mapreduce.reduce.shuffle.input.buffer.percent指定。一旦Reducer所在節點的記憶體緩衝區達到閥值,或者緩衝區中的文件數達到閥值,則合併溢寫到磁碟。
- 如果map輸出較大,則直接被覆制到Reducer所在節點的磁碟中。隨著Reducer所在節點的磁碟中溢寫文件增多,後臺線程會將它們合併為更大且有序的文件。當完成複製map輸出,進入sort階段。這個階段通過歸併排序逐步將多個map輸出小文件合併成大文件。最後幾個通過歸併合併成的大文件作為reduce的輸出
五、安裝Hadoop(HDFS+YARN)
1)環境準備
這裡準備三台VM虛擬機
| OS | hostname | ip | 運行角色 |
|---|---|---|---|
| Centos8.x | hadoop-node1 | 192.168.0.113 | namenode,datanode ,resourcemanager,nodemanager |
| Centos8.x | hadoop-node2 | 192.168.0.114 | secondarynamedata,datanode,nodemanager |
| Centos8.x | hadoop-node3 | 192.168.0.115 | datanode,nodemanager |
2)下載最新的Hadoop安裝包
下載地址:https://dlcdn.apache.org/hadoop/common/

這裡下載源碼包安裝,預設的編譯好的文件不支持snappy壓縮,因此我們需要自己重新編譯。
$ mkdir -p /opt/bigdata/hadoop && cd /opt/bigdata/hadoop
$ wget https://dlcdn.apache.org/hadoop/common/stable/hadoop-3.3.1-src.tar.gz
# 解壓
$ tar -zvxf hadoop-3.3.1-src.tar.gz
為什麼需要重新編譯Hadoop源碼?
匹配不同操作系統本地庫環境,Hadoop某些操作比如壓縮,IO需要調用系統本地庫(.so|.dll)
重構源碼
源碼包目錄下有個 BUILDING.txt,因為我這裡的操作系統是Centos8,所以選擇Centos8的操作步驟,小伙伴們找到自己對應系統的操作步驟執行即可。
$ grep -n -A40 'Building on CentOS 8' BUILDING.txt
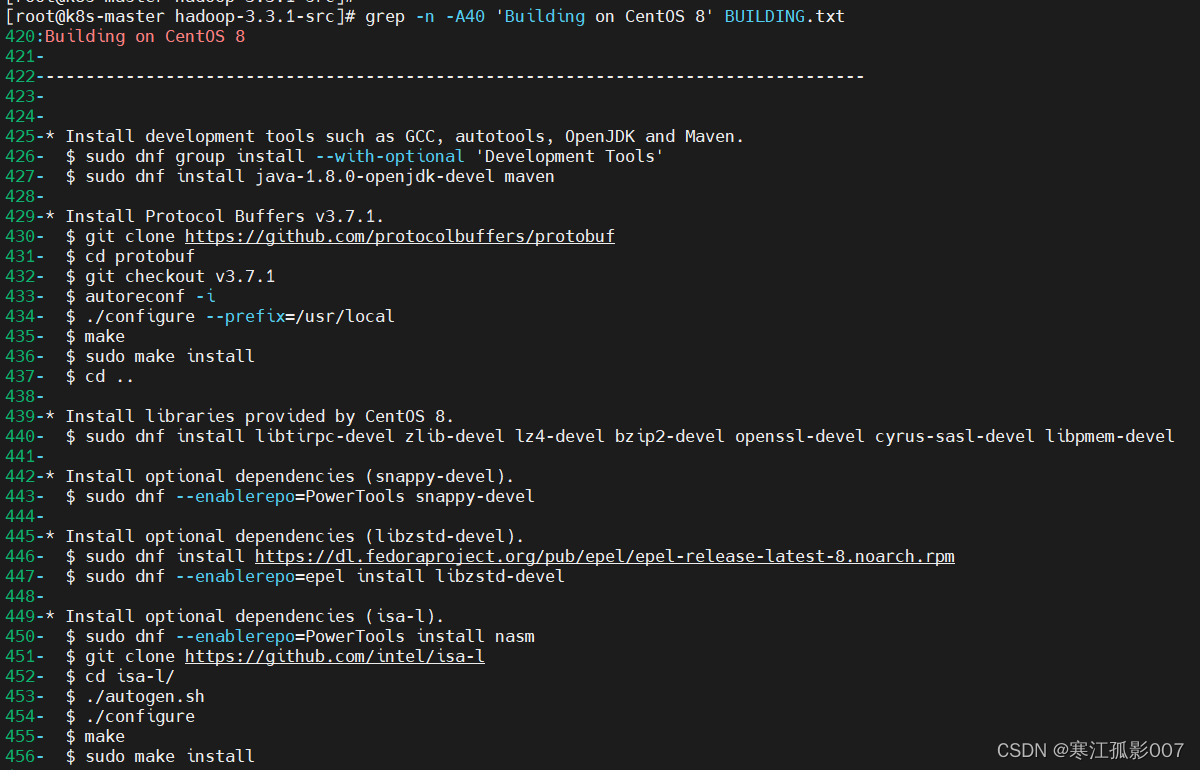
Building on CentOS 8
----------------------------------------------------------------------------------
* Install development tools such as GCC, autotools, OpenJDK and Maven.
$ sudo dnf group install --with-optional 'Development Tools'
$ sudo dnf install java-1.8.0-openjdk-devel maven
* Install Protocol Buffers v3.7.1.
$ git clone https://github.com/protocolbuffers/protobuf
$ cd protobuf
$ git checkout v3.7.1
$ autoreconf -i
$ ./configure --prefix=/usr/local
$ make
$ sudo make install
$ cd ..
* Install libraries provided by CentOS 8.
$ sudo dnf install libtirpc-devel zlib-devel lz4-devel bzip2-devel openssl-devel cyrus-sasl-devel libpmem-devel
* Install optional dependencies (snappy-devel).
$ sudo dnf --enablerepo=PowerTools snappy-devel
* Install optional dependencies (libzstd-devel).
$ sudo dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
$ sudo dnf --enablerepo=epel install libzstd-devel
* Install optional dependencies (isa-l).
$ sudo dnf --enablerepo=PowerTools install nasm
$ git clone https://github.com/intel/isa-l
$ cd isa-l/
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
----------------------------------------------------------------------------------
將進入Hadoop源碼路徑,執行maven命令進行Hadoop編譯
$ cd /opt/bigdata/hadoop/hadoop-3.3.1-src
# 編譯
$ mvn package -Pdist,native,docs -DskipTests -Dtar
【問題】Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 19:49 min
[INFO] Finished at: 2021-12-14T09:36:29+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-banned-dependencies) on project hadoop-client-check-test-invariants: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn-rf :hadoop-client-check-test-invariants
【解決】
- 方案一:跳過enforcer的強制約束,在構建的命令加上跳過的指令,如:-Denforcer.skip=true
- 方案二:設置規則校驗失敗不影響構建流程,在構建的命令上加指令,如: -Denforcer.fail=false
具體原因目前還不明確,先使用上面兩個方案中的方案一跳過,有興趣的小伙伴,可以打開DEBUG模式(-X)查看具體報錯
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar -Denforcer.skip=true
所以編譯命令
# 當然還有其它選項
$ grep -n -A1 '$ mvn package' BUILDING.txt
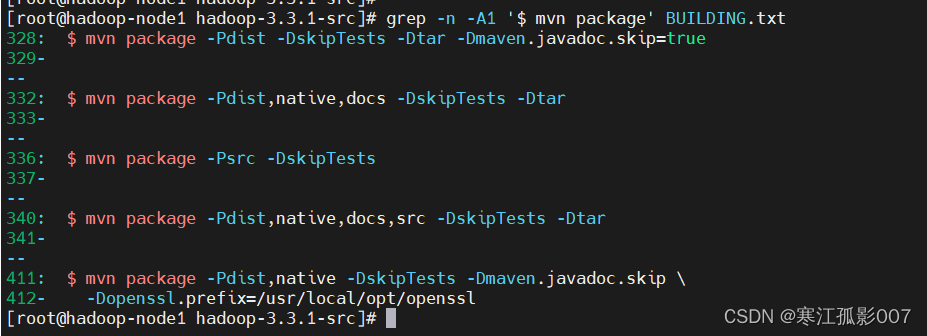
$ mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=true
$ mvn package -Pdist,native,docs -DskipTests -Dtar
$ mvn package -Psrc -DskipTests
$ mvn package -Pdist,native,docs,src -DskipTests -Dtar
$ mvn package -Pdist,native -DskipTests -Dmaven.javadoc.skip \
-Dopenssl.prefix=/usr/local/opt/openssl
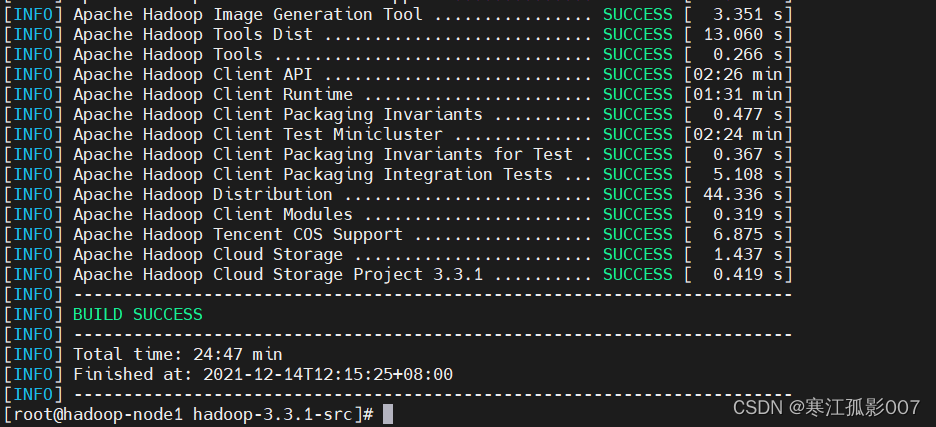
至此~Hadoop源碼編譯完成,
編譯後的文件位於源碼路徑下 hadoop-dist/target/
將編譯好的二進位包copy出來
$ cp hadoop-dist/target/hadoop-3.3.1.tar.gz /opt/bigdata/hadoop/
$ cd /opt/bigdata/hadoop/
$ ll

這裡也把編譯好的包放在百度雲上,如果小伙伴不想自己編譯,可以直接用我這裡的:
鏈接:https://pan.baidu.com/s/1hmdHY20zSLGyKw1OAVCg7Q
提取碼:8888
3)進行伺服器及Hadoop的初始化配置
1、修改主機名
# 192.168.0.113機器上執行
$ hostnamectl set-hostname hadoop-node1
# 192.168.0.114機器上執行
$ hostnamectl set-hostname hadoop-node2
# 192.168.0.115機器上執行
$ hostnamectl set-hostname hadoop-node3
2、修改主機名和IP的映射關係(所有節點都執行)
$ echo "192.168.0.113 hadoop-node1" >> /etc/hosts
$ echo "192.168.0.114 hadoop-node2" >> /etc/hosts
$ echo "192.168.0.115 hadoop-node3" >> /etc/hosts
3、關閉防火牆和selinux(所有節點都執行)
$ systemctl stop firewalld
$ systemctl disable firewalld
# 臨時關閉(不用重啟機器):
$ setenforce 0 ##設置SELinux 成為permissive模式
# 永久關閉修改/etc/selinux/config 文件
將SELINUX=enforcing改為SELINUX=disabled
4、時間同步(所有節點都執行)
$ dnf install chrony -y
$ systemctl start chronyd
$ systemctl enable chronyd
/etc/chrony.conf配置文件內容
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#pool 2.centos.pool.ntp.org iburst (這一行註釋掉,增加以下兩行)
server ntp.aliyun.com iburst
server cn.ntp.org.cn iburst
重新載入配置並測試
$ systemctl restart chronyd.service
$ chronyc sources -v
5、配置ssh免密(在hadoop-node1上執行)
# 1、在hadoop-node1上執行如下命令生成公私密鑰:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
# 2、然後將master公鑰id_dsa複製到hadoop-node1|hadoop-node2|hadoop-node3進行公鑰認證。
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node1
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node2
$ ssh-copy-id -i /root/.ssh/id_dsa.pub hadoop-node3
$ ssh hadoop-node1
$ exit
$ ssh hadoop-node2
$ exit
$ ssh hadoop-node3
$ exit
6、安裝統一工作目錄(所有節點都執行)
# 軟體安裝路徑
$ mkdir -p /opt/bigdata/hadoop/server
# 數據存儲路徑
$ mkdir -p /opt/bigdata/hadoop/data
# 安裝包存放路徑
$ mkdir -p /opt/bigdata/hadoop/software
7、安裝JDK(所有節點都執行)
官網下載:https://www.oracle.com/java/technologies/downloads/
百度下載
鏈接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取碼:8888
$ cd /opt/bigdata/hadoop/software
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/bigdata/hadoop/server/
# 在文件加入環境變數/etc/profile
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# source載入
$ source /etc/profile
# 查看jdk版本
$ java -version
4)開始安裝Hadoop
1、解壓上面我編譯好的安裝包
$ cd /opt/bigdata/hadoop/software
$ tar -zxvf hadoop-3.3.1.tar.gz -C /opt/bigdata/hadoop/server/
$ cd /opt/bigdata/hadoop/server/
$ cd hadoop-3.3.1/
$ ls -lh
2、安裝包目錄說明
| 目錄 | 說明 |
|---|---|
| bin | hadoop最基本的管理腳本和使用腳本的目錄,這些腳本是sbin目錄下管理腳本的基礎實現,用戶可以直接使用這些腳本管理和使用hadoop |
| etc | hadoop配置文件所在的目錄 |
| include | 對外提供的編程庫頭文件(具體動態庫和靜態庫在lib目錄中),這些文件均是用c++定義,通常用於c++程式訪問HDFS或者編寫MapReduce程式。 |
| lib | 該目錄包含了hadoop對外提供的編程動態庫和靜態庫,與include目錄中的頭文件結合使用。 |
| libexec | 各個服務隊用的shell配置文件所在的免疫力,可用於配置日誌輸出,啟動參數(比如JVM參數)等基本信息。 |
| sbin | hadoop管理腳本所在的目錄,主要包含HDFS和YARN中各類服務的啟動、關閉腳本。 |
| share | hadoop 各個模塊編譯後的jar包所在的目錄。官方示例也在其中 |
3、修改配置文件
配置文件目錄:/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
官方文檔:https://hadoop.apache.org/docs/r3.3.1/
- 修改hadoop-env.sh
# 在hadoop-env.sh文件末尾追加
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
- 修改core-site.xml #核心模塊配置
在<configuration></configuration>中間添加如下內容
<!-- 設置預設使用的文件系統 Hadoop支持file、HDFS、GFS、ali|Amazon雲等文件系統 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-node1:8082</value>
</property>
<!-- 設置Hadoop本地保存數據路徑 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop/data/hadoop-3.3.1</value>
</property>
<!-- 設置HDFS web UI用戶身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 聚合hive 用戶代理設置 -->
<property>
<name>hadoop.proxyuser.hosts</name>
<value>*</value>
</property>
<!-- 用戶代理設置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系統垃圾桶保存時間 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
- hdfs-site.xml #hdfs文件系統模塊配置
在<configuration></configuration>中間添加如下內容
<!-- 設置SNN進程運行機器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-node2:9868</value>
</property>
<!-- 必須將dfs.webhdfs.enabled屬性設置為true,否則就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夾狀態的命令,因為這些信息都是由namenode來保存的。 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
- 修改mapred.xml #MapReduce模塊配置
在<configuration></configuration>中間添加如下內容
<!-- 設置MR程式預設運行模式,yarn集群模式,local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程式歷史服務地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-node1:10020</value>
</property>
<!-- MR程式歷史服務web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-node1:19888</value>
</property>
<!-- yarn環境變數 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- map環境變數 -->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- reduce環境變數 -->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
- 修改yarn-site.xml #yarn模塊配置
在<configuration></configuration>中間添加如下內容
<!-- 設置YARN集群主角色運行集群位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否將對容器實施物理記憶體限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否將對容器實施虛擬記憶體限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 開啟日誌聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 設置yarn歷史伺服器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-node1:19888/jobhistory/logs</value>
</property>
<!-- 設置yarn歷史日誌保存時間 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604880</value>
</property>
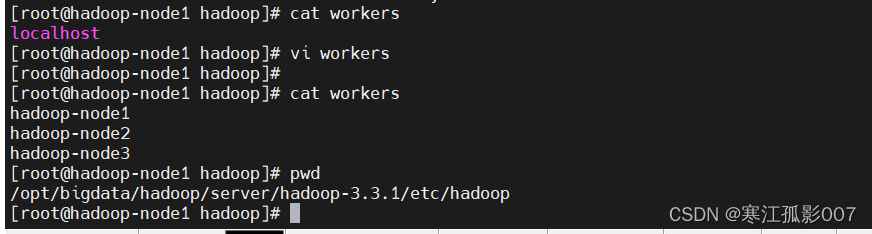
- 修改workers
將下麵內容覆蓋文件,預設只有localhost
hadoop-node1
hadoop-node2
hadoop-node3
4、分發同步hadoop安裝包到另外幾台機器
$ cd /opt/bigdata/hadoop/server/
$ scp -r hadoop-3.3.1 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r hadoop-3.3.1 hadoop-node3:/opt/bigdata/hadoop/server/
5、將hadoop添加到環境變數(所有節點)
$ vi /etc/profile
export HADOOP_HOME=/opt/bigdata/hadoop/server/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 載入
$ source /etc/profile
6、Hadoop集群啟動(hadoop-node1上執行)
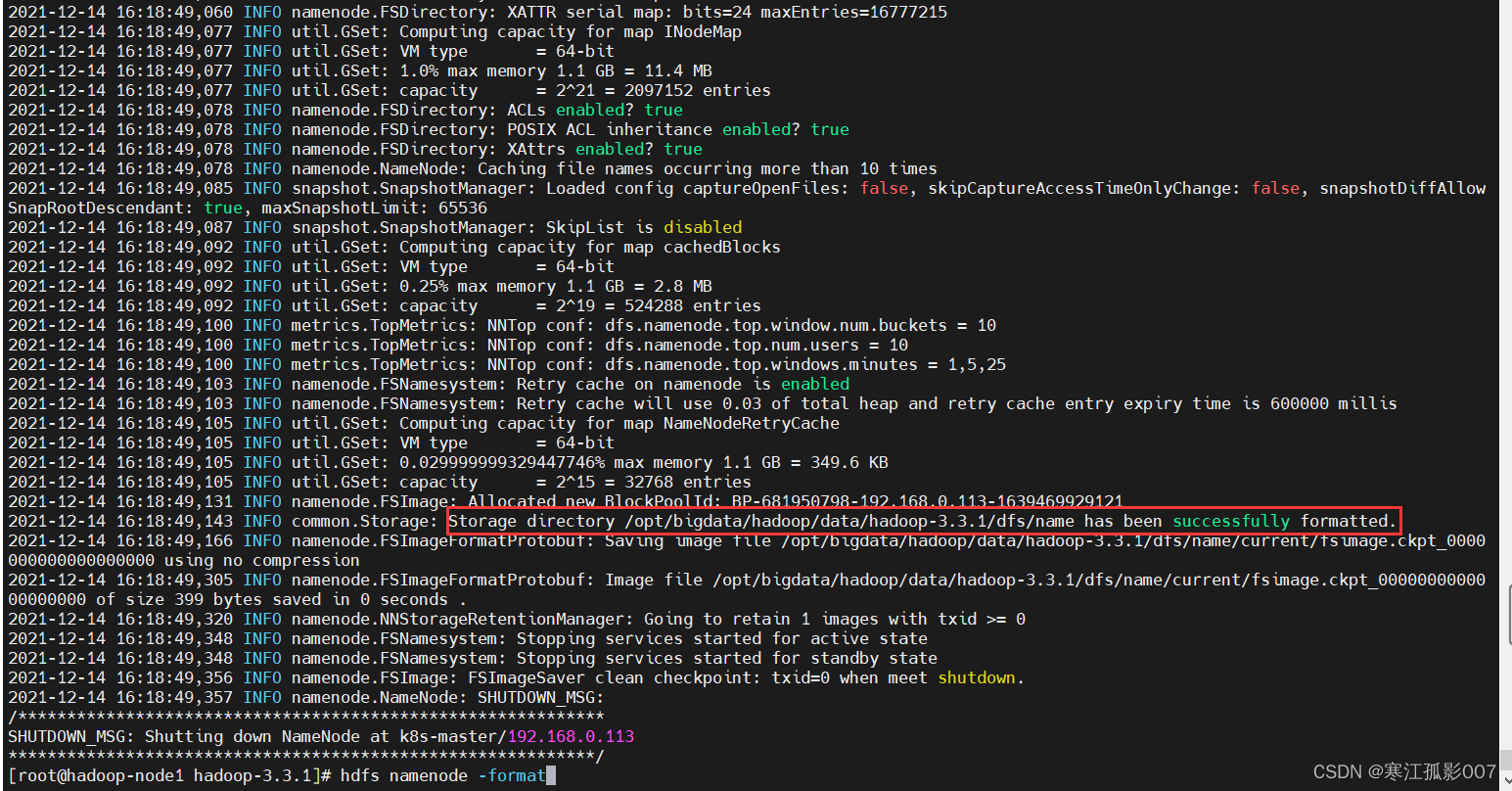
1)(首次啟動)格式化namenode(只能執行一次)
- 首次啟動HDFS時,必須對其進行格式化操作
- format本質上初始化工作,進行HDFS清理和準備工作
$ hdfs namenode -format
2)手動逐個進程啟停
每台機器每次手動啟動關閉一個角色進程,可以精確控制每個進程啟停,避免群起群停
1、HDFS集群啟動
$ hdfs --daemon start|stop namenode|datanode|secondarynamenode
2、YARN集群啟動
$ yarn --daemon start|stop resourcemanager|nodemanager
3)通過shell腳本一鍵啟動
在hadoop-node1上,使用軟體自帶的shell腳本一鍵啟動。前提:配置好機器之間的SSH免密登錄和works文件
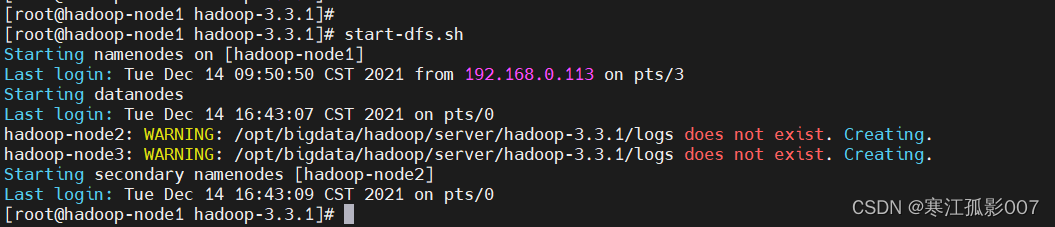
- HDFS集群啟停
$ start-dfs.sh
$ stop-dfs.sh #這裡不執行
檢查java進程
$ jps

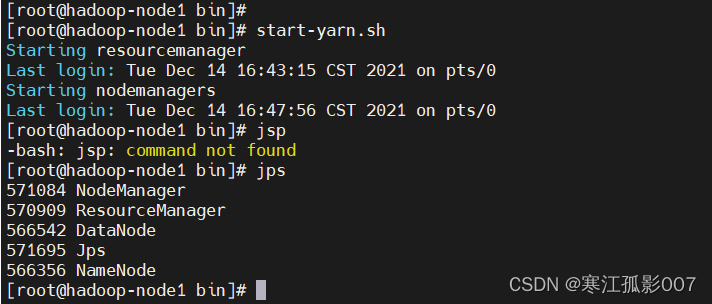
- YARN集群啟停
$ start-yarn.sh
$ stop-yarn.sh # 這裡不執行
# 查看java進程
$ jps
通過日誌檢查,日誌路徑:/opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/logs
$ ll
- Hadoop集群啟停(HDFS+YARN)
$ start-all.sh
$ stop-all.sh
4)通過web頁面訪問
【註意】在window C:\Windows\System32\drivers\etc\hosts文件配置功能變數名稱映射,hosts文件中增加如下內容:
192.168.0.113 hadoop-node1
192.168.0.114 hadoop-node2
192.168.0.115 hadoop-node3
1、HDFS集群
地址:http://namenode_host:9870
這裡地址為:http://192.168.0.113:9870
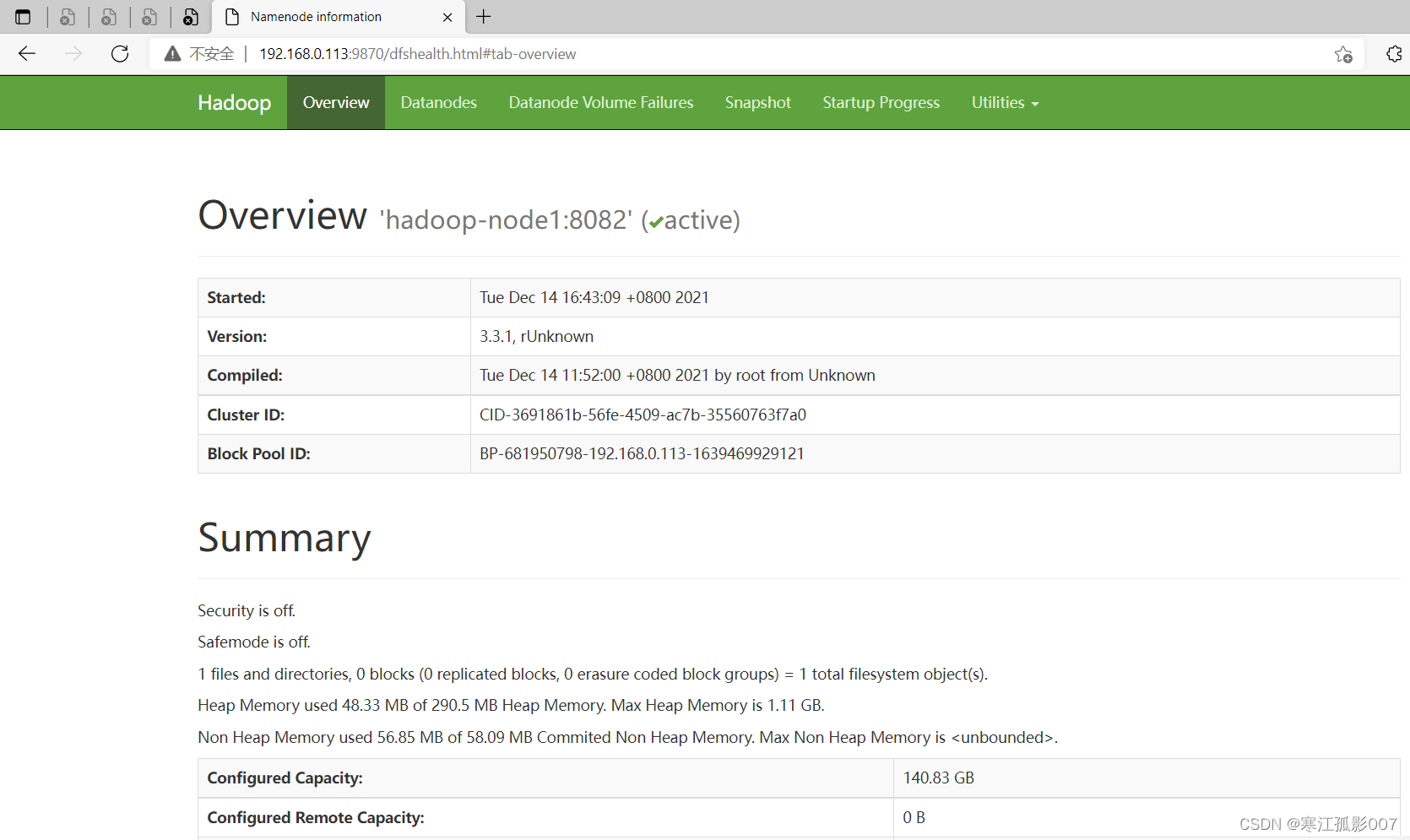
2、YARN集群
地址:http://resourcemanager_host:8088
這裡地址為:http://192.168.0.113:8088
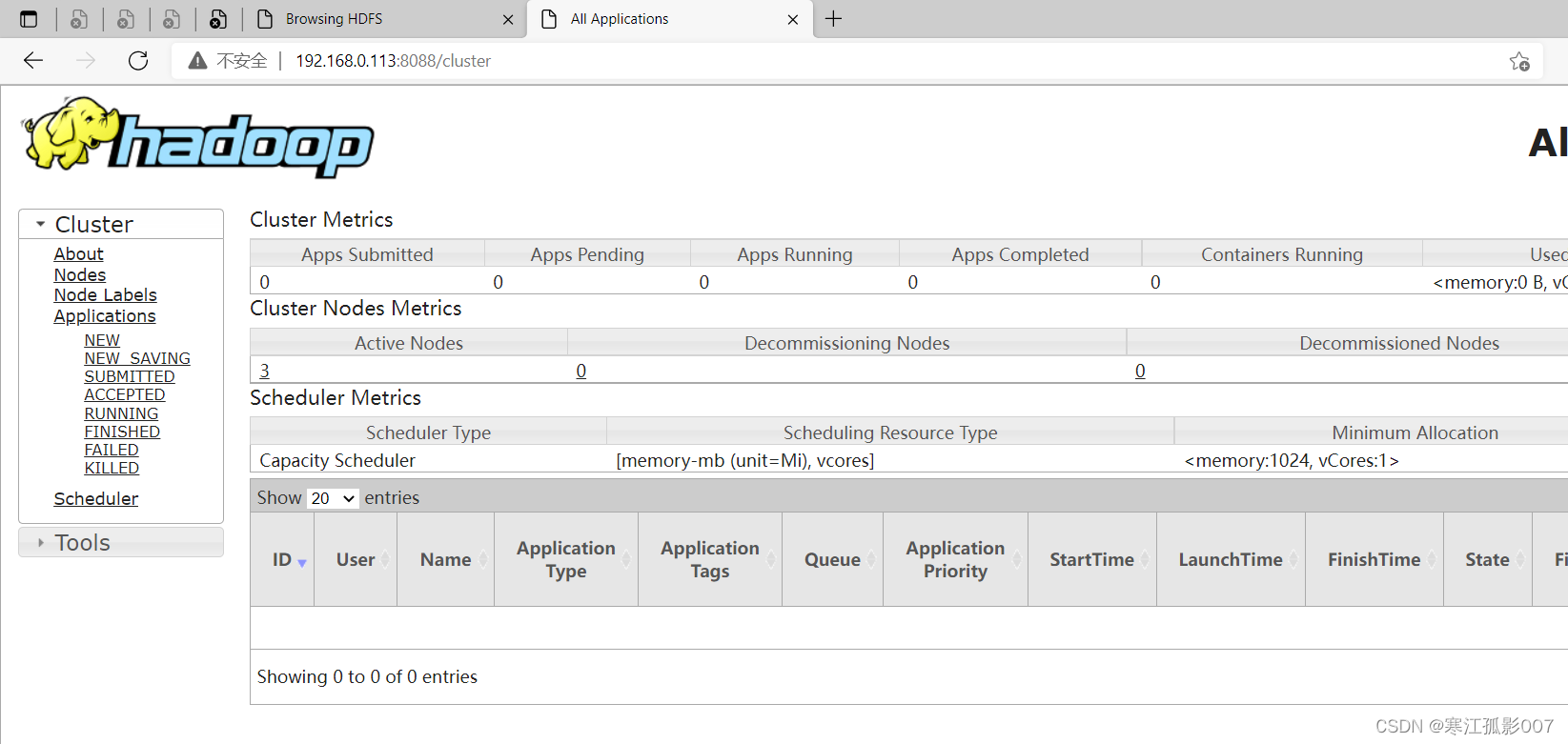
到此為止,hadoop和yarn集群就已經部署完了~
六、Hadoop實戰操作
1)HDFS實戰操作
- 命令介紹
# 訪問本地文件系統
$ hadoop fs -ls file:///
# 預設不帶協議就是訪問hdfs文件系統
$ hadoop fs -ls /
- 查看配置
$ cd /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop
$ grep -C5 'fs.defaultFS' core-site.xml
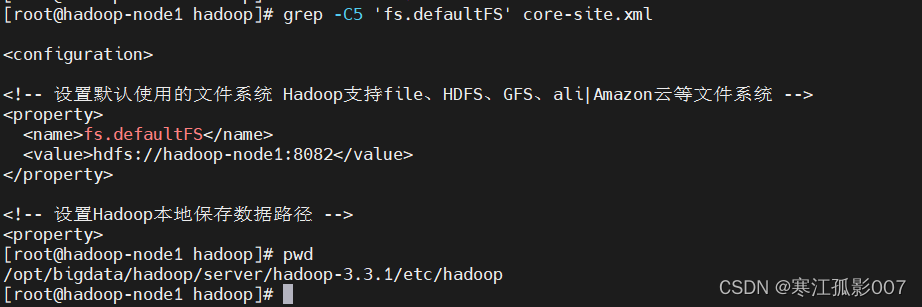
# 這裡加上hdfs協議與不帶協議等價 $ hadoop fs -ls hdfs://hadoop-node1:8082/


