
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages HDFS 簡介及操作 HDFS概述 HDFS產出背景及定義 HDFS優缺點 HDFS組成架構 HDFS文件塊大小(重點) 塊在傳輸時,每64K還需要校驗一次,因此塊大小,必須為2的n次方,最接近100M的就是128M! ...
目前CSDN,博客園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages
目錄
HDFS 簡介及操作
HDFS概述
HDFS產出背景及定義

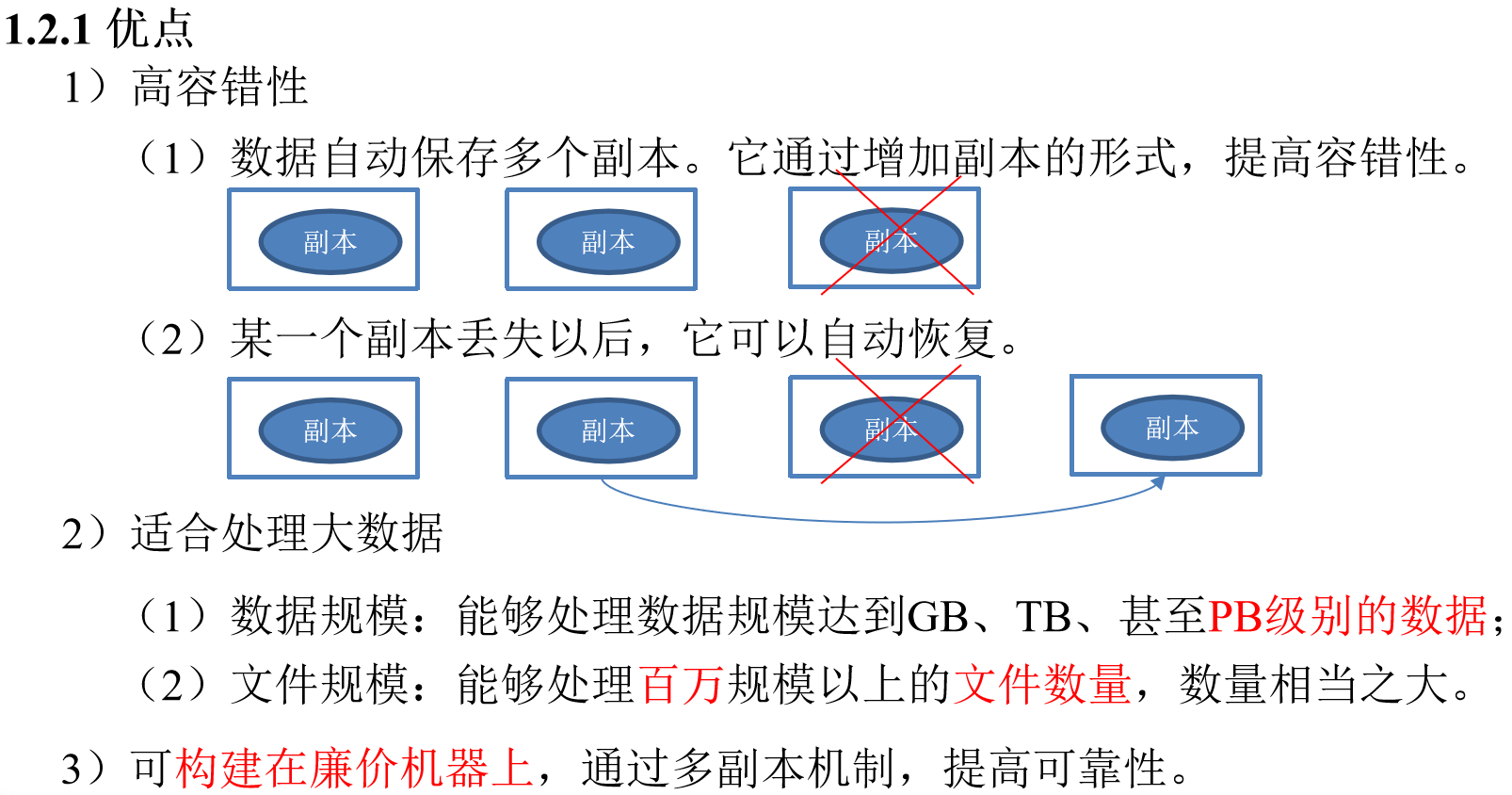
HDFS優缺點

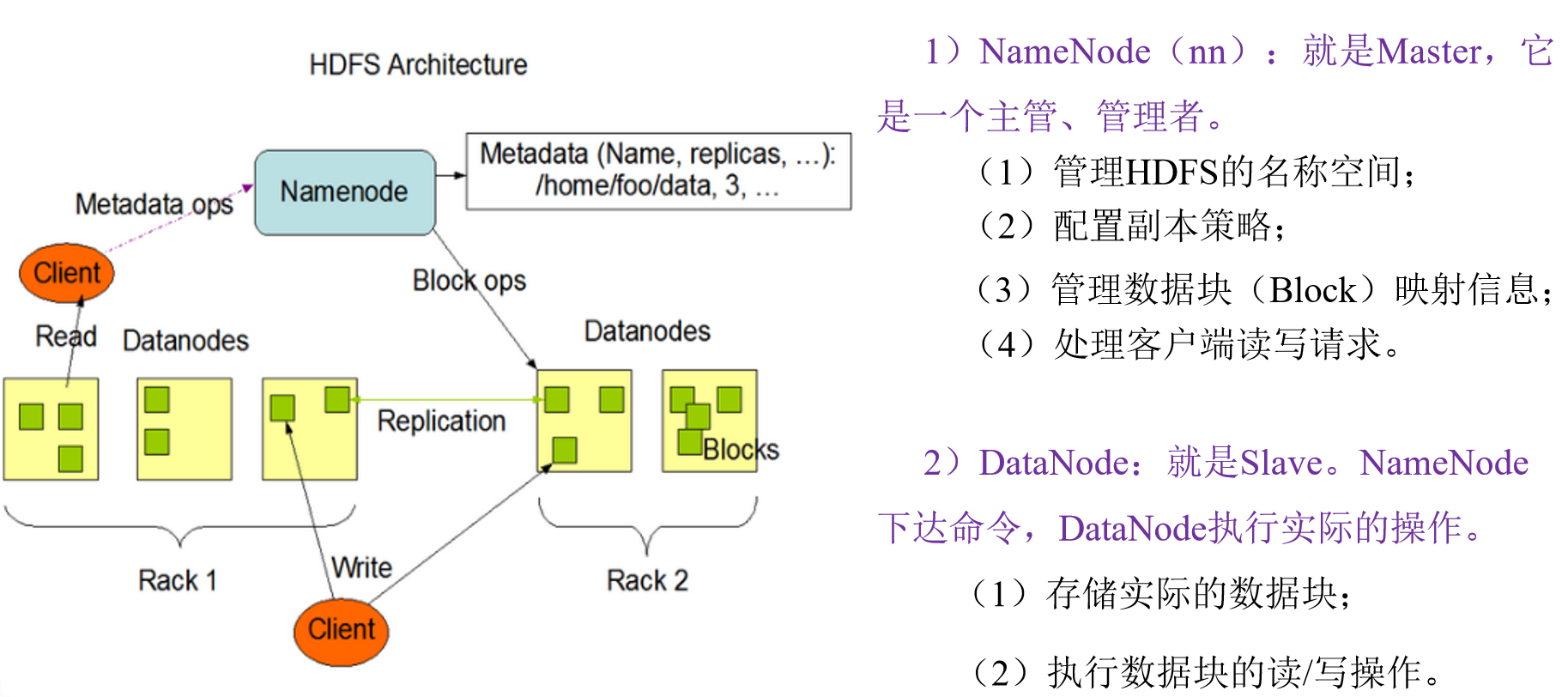
HDFS組成架構

HDFS文件塊大小(重點)
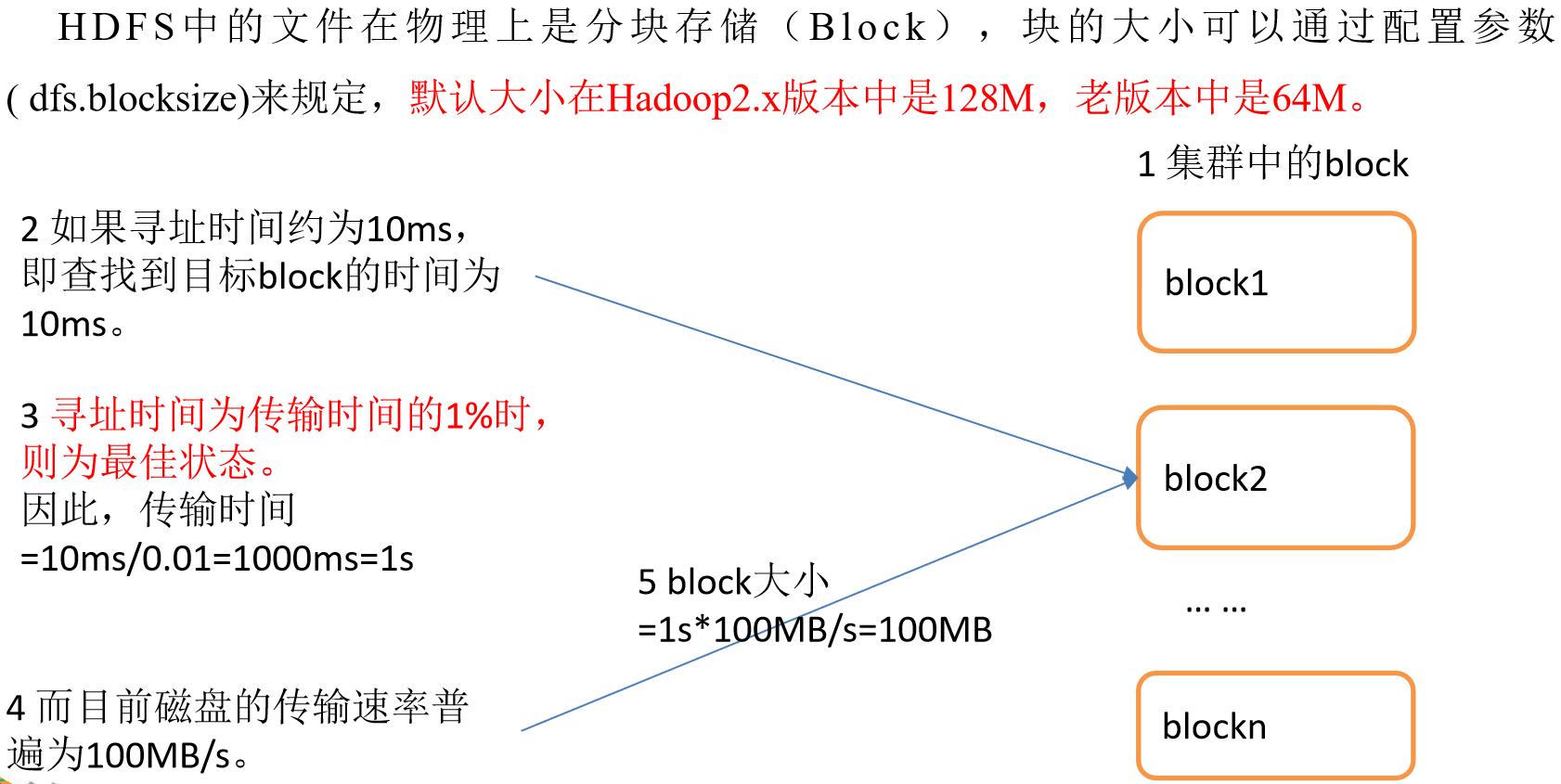
塊在傳輸時,每64K還需要校驗一次,因此塊大小,必須為2的n次方,最接近100M的就是128M!
如果公司使用的是固態硬碟,寫的速度是300M/S,將塊大小調整到 256M
如果公司使用的是固態硬碟,寫的速度是500M/S,將塊大小調整到 512M
-
但是塊的大小不能設置太小,也不能設置太大
-
太大
- 在一些分塊讀取的場景,不夠靈活,會帶來額外的網路消耗
- 在上傳文件時,一旦發生故障,會造成資源的浪費
-
太小
- 同樣大小的文件,會占用過多的NN的元數據空間
- 在進行讀寫操作時,會消耗額外的定址時間
-

HDFS的Shell操作(開發重點)
基本語法
bin/hadoop fs 具體命令 OR bin/hdfs dfs 具體命令
dfs是fs的實現類。
命令大全
[atguigu@hadoop102 ~]$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
常用命令實操
-
啟動Hadoop集群(方便後續的測試)
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh -
-help:輸出這個命令參數
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -help rm -
-ls: 顯示目錄信息
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -ls / -
-mkdir:在HDFS上創建目錄
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir -p /sanguo/shuguo -
-moveFromLocal:從本地剪切粘貼到HDFS
[atguigu@hadoop102 hadoop-2.7.2]$ touch kongming.txt [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo -
-appendToFile:追加一個文件到已經存在的文件末尾
[atguigu@hadoop102 hadoop-2.7.2]$ touch liubei.txt [atguigu@hadoop102 hadoop-2.7.2]$ vi liubei.txt 輸入 san gu mao lu [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt -
-cat:顯示文件內容
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cat /sanguo/shuguo/kongming.txt -
-chgrp 、-chmod、-chown:Linux文件系統中的用法一樣,修改文件所屬許可權
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo/kongming.txt -
-copyFromLocal:從本地文件系統中拷貝文件到HDFS路徑去
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyFromLocal README.txt / -
-copyToLocal:從HDFS拷貝到本地
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./ -
-cp :從HDFS的一個路徑拷貝到HDFS的另一個路徑
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt -
-mv:在HDFS目錄中移動文件
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/ -
-get:等同於copyToLocal,就是從HDFS下載文件到本地
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./ -
-getmerge:合併下載多個文件,比如HDFS的目錄 /aaa/下有多個文件:log.1, log.2,log.3,...
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -getmerge /sanguo/shuguo* ./zaiyiqi.txt -
-put:等同於copyFromLocal
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -put ./zaiyiqi.txt / -
-tail:顯示一個文件的末尾
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -tail /sanguo/shuguo/kongming.txt -
-rm:刪除文件或文件夾
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rm -r -f /zaiyiqi.txt -
-rmdir:刪除空目錄
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir /test [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rmdir /test -
-du統計文件夾的大小信息
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -du -s -h /sanguo/shuguo 26 /sanguo/shuguo [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -du -h /sanguo/shuguo 13 /sanguo/shuguo/kongming.txt 13 /sanguo/shuguo/zhuge.txt -
-setrep:設置HDFS中文件的副本數量
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
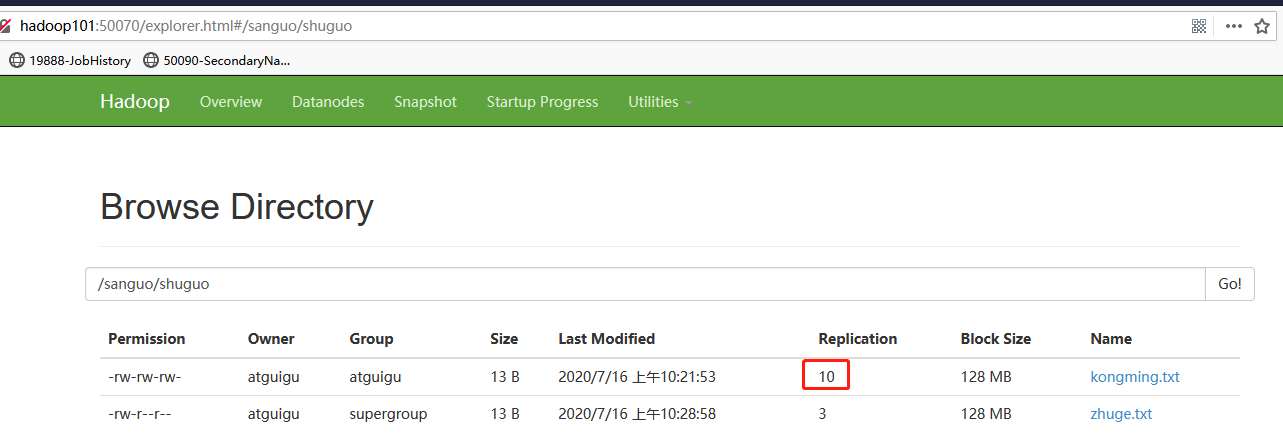
這裡設置的副本數只是記錄在NameNode的元數據中,是否真的會有這麼多副本,還得看DataNode的數量。因為目前只有3台設備,最多也就3個副本,只有節點數的增加到10台時,副本數才能達到10。
HDFS客戶端操作(開發重點)
HDFS客戶端環境準備
-
根據自己電腦的操作系統拷貝對應的編譯後的hadoop jar包到非中文路徑
-
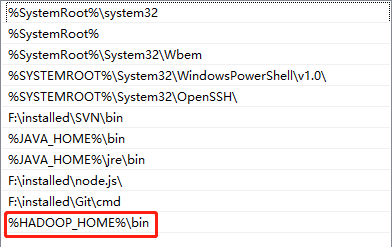
配置HADOOP_HOME環境變數

-
配置Path環境變數
-
創建一個Maven工程HdfsClientDemo
-
導入相應的依賴坐標+日誌添加
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <!--下麵這個可以註釋掉,如果找不到jdk.tools再配置上--> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> </dependencies>註意:如果Eclipse/Idea列印不出日誌,在控制臺上只顯示
1.log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). 2.log4j:WARN Please initialize the log4j system properly. 3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.需要在項目的src/main/resources目錄下,新建一個文件,命名為“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
常用API
public class TestHDFS {
private FileSystem fs;
private Configuration conf = new Configuration();
@Before
public void init() throws IOException, URISyntaxException, InterruptedException {
//創建一個客戶端對象
fs=FileSystem.get(new URI("hdfs://hadoop101:9000"),conf,"atguigu");
}
@After
public void close() throws IOException {
if (fs !=null) {
fs.close();
}
}
// hadoop fs(運行一個通用的用戶客戶端) -mkdir /xxx
// 創建一個客戶端對象 ,調用創建目錄的方法,路徑作為方法的參數摻入
@Test
public void testMkdir() throws IOException {
fs.mkdirs(new Path("/eclipse2"));
}
// 上傳文件: hadoop fs -put 本地文件 hdfs
@Test
public void testUpload() throws Exception {
/**
* @param delSrc
* whether to delete the src
* @param overwrite
* whether to overwrite an existing file
* @param src path
* @param dst path
*/
fs.copyFromLocalFile(false, true, new Path("F:/BaiduNetdiskDownload/hadoop-2.7.2.zip"), new Path("/"));
}
// 下載文件: hadoop fs -get hdfs 本地路徑
@Test
public void testDownload() throws Exception {
/**
* @param delSrc
* whether to delete the src
* @param src path
* @param dst path
* @param useRawLocalFileSystem
* whether to use RawLocalFileSystem as local file system or not.
*
*/
fs.copyToLocalFile(false, new Path("/wcinput"), new Path("f:/test"), true);
}
// 刪除文件: hadoop fs -rm -r -f 路徑
@Test
public void testDelete() throws Exception {
fs.delete(new Path("/wcoutpout2"), true);
}
// 重命名: hadoop fs -mv 源文件 目標文件
@Test
public void testRename() throws Exception {
fs.rename(new Path("/eclipse1"), new Path("/eclipsedir"));
}
// 判斷當前路徑是否存在
@Test
public void testIfPathExsits() throws Exception {
System.out.println(fs.exists(new Path("/eclipsedir1")));
}
// 判斷當前路徑是目錄還是文件
@Test
public void testFileIsDir() throws Exception {
//Path path = new Path("/eclipsedir");
Path path = new Path("/wcoutput1");
// 不建議使用此方法,建議好似用Instead reuse the FileStatus returned
//by getFileStatus() or listStatus() methods.
/* System.out.println(fs.isDirectory(path));
System.out.println(fs.isFile(path));*/
//FileStatus fileStatus = fs.getFileStatus(path);
FileStatus[] listStatus = fs.listStatus(path);
for (FileStatus fileStatus : listStatus) {
//獲取文件名 Path是完整的路徑 協議+文件名
Path filePath = fileStatus.getPath();
System.out.println(filePath.getName()+"是否是目錄:"+fileStatus.isDirectory());
System.out.println(filePath.getName()+"是否是文件:"+fileStatus.isFile());
}
}
// 獲取到文件的塊信息
@Test
public void testGetBlockInformation() throws Exception {
Path path = new Path("/hadoop-2.7.2.zip");
RemoteIterator<LocatedFileStatus> status = fs.listLocatedStatus(path);
while(status.hasNext()) {
LocatedFileStatus locatedFileStatus = status.next();
System.out.println("Owner:"+locatedFileStatus.getOwner());
System.out.println("Group:"+locatedFileStatus.getGroup());
//---------------塊的位置信息--------------------
BlockLocation[] blockLocations = locatedFileStatus.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
System.out.println(blockLocation);
System.out.println("------------------------");
}
}
}
}
對常用的API做個說明:
-
FileSystem: 文件系統的抽象基類
-
FileSystem的實現取決於fs.defaultFS的配置!有兩種實現!
-
LocalFileSystem: 本地文件系統 fs.defaultFS=file:///
-
DistributedFileSystem: 分散式文件系統 fs.defaultFS=hdfs://xxx:9000
-
聲明用戶身份:
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop101:9000"), conf, "atguigu"); -
-
Configuration : 功能是讀取配置文件中的參數
-
Configuration在讀取配置文件的參數時,根據文件名,從類路徑按照順序讀取配置文件!先讀取 xxx-default.xml,再讀取xxx-site.xml
-
Configuration類一載入,就會預設讀取8個配置文件!
-
將8個配置文件中所有屬性,讀取到一個Map集合中!
-
也提供了set(name,value),來手動設置用戶自定義的參數!
-
-
FileStatus: 代表一個文件的狀態(文件的屬性信息)
-
offset和length
-
offset是偏移量: 指塊在文件中的起始位置
-
length是長度,指塊大小
-
剛剛上傳的hadoop-2.7.2.zip,210.01MB
hadoop-2.7.2.zip 區間 length offset blk1 0-128MB 128MB 0 blk2 128MB-256MB 82.01MB 128MB -
-
LocatedFileStatus
- LocatedFileStatus是FileStatus的子類,除了文件的屬性,還有塊的位置信息!
-
參數優先順序
參數優先順序排序:(1)客戶端代碼中設置的值 >(2)ClassPath下的用戶自定義配置文件 >(3)然後是伺服器的預設配置
HDFS的I/O流操作
上面我們學的API操作HDFS系統都是框架封裝好的。那麼如果我們想自己實現上述API的操作該怎麼實現呢?
我們可以採用IO流的方式實現數據的上傳和下載。
/*
* 1. 上傳文件時,只上傳這個文件的一部分
*
* 2. 下載文件時,如何只下載這個文件的某一個塊?
* 或只下載文件的某一部分?
*/
public class TestCustomUploadAndDownload {
private FileSystem fs;
private FileSystem localFs;
private Configuration conf = new Configuration();
@Before
public void init() throws IOException, URISyntaxException, InterruptedException {
//創建一個客戶端對象
fs=FileSystem.get(new URI("hdfs://hadoop101:9000"),conf,"atguigu");
localFs=FileSystem.get(new Configuration());
}
@After
public void close() throws IOException {
if (fs !=null) {
fs.close();
}
}
// 只上傳文件的前10M
/*
* 官方的實現
* InputStream in=null;
OutputStream out = null;
try {
in = srcFS.open(src);
out = dstFS.create(dst, overwrite);
IOUtils.copyBytes(in, out, conf, true);
} catch (IOException e) {
IOUtils.closeStream(out);
IOUtils.closeStream(in);
throw e;
}
*/
@Test
public void testCustomUpload() throws Exception {
//提供兩個Path,和兩個FileSystem
Path src=new Path("F:/BaiduNetdiskDownload/hadoop-2.7.2.zip");
Path dest=new Path("/hadoop10M.zip");
// 使用本地文件系統中獲取的輸入流讀取本地文件
FSDataInputStream is = localFs.open(src);
// 使用HDFS的分散式文件系統中獲取的輸出流,向dest路徑寫入數據
FSDataOutputStream os = fs.create(dest, true);
// 1k
byte [] buffer=new byte[1024];
// 流中數據的拷貝
for (int i = 0; i < 1024 * 10; i++) {
is.read(buffer);
os.write(buffer);
}
//關流
IOUtils.closeStream(is);
IOUtils.closeStream(os);
}
/**
* 下載第一塊
*/
@Test
public void testFirstBlock() throws Exception {
//提供兩個Path,和兩個FileSystem
Path src=new Path("/hadoop-2.7.2.zip");
Path dest=new Path("f:/test/firstBlock");
// 使用HDFS的分散式文件系統中獲取的輸入流,讀取HDFS上指定路徑的數據
FSDataInputStream is = fs.open(src);
// 使用本地文件系統中獲取的輸出流寫入本地文件
FSDataOutputStream os = localFs.create(dest, true);
// 1k
byte [] buffer=new byte[1024];
// 流中數據的拷貝
for (int i = 0; i < 1024 * 128; i++) {
is.read(buffer);
os.write(buffer);
}
//關流
IOUtils.closeStream(is);
IOUtils.closeStream(os);
}
/**
* 下載第二塊,這裡也就是最後一塊
*/
@Test
public void testFinalBlock() throws Exception {
//提供兩個Path,和兩個FileSystem
Path src=new Path("/hadoop-2.7.2.zip");
Path dest=new Path("f:/test/finalBlock");
// 使用HDFS的分散式文件系統中獲取的輸入流,讀取HDFS上指定路徑的數據
FSDataInputStream is = fs.open(src);
// 使用本地文件系統中獲取的輸出流寫入本地文件
FSDataOutputStream os = localFs.create(dest, true);
//定位到流的指定位置
is.seek(1024*1024*128);
IOUtils.copyBytes(is, os, conf);
}
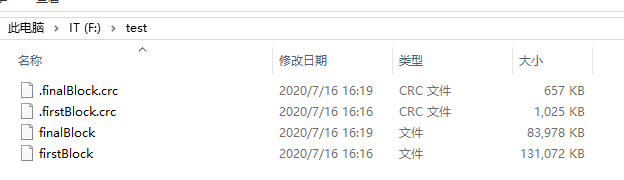
- windows下的合併命令: type finalBlock >> firstBlock
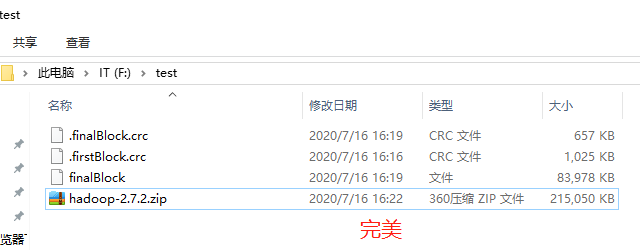
HDFS的數據流(重點)
HDFS寫數據流程
剖析文件寫入
- HDFS寫數據流程,如圖所示
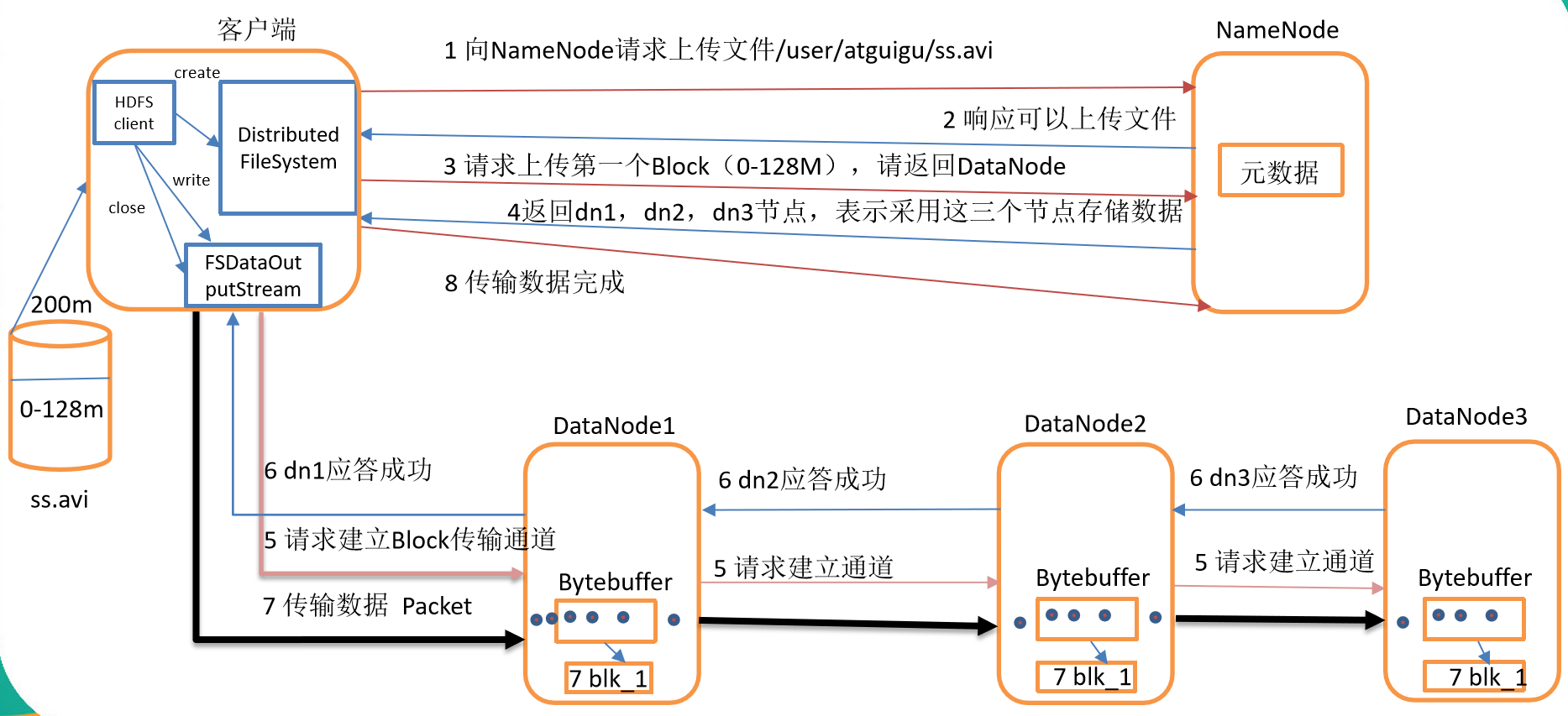
- 客戶端通過Distributed FileSystem模塊向NameNode請求上傳文件,NameNode檢查目標文件是否已存在,父目錄是否存在。
- NameNode返回是否可以上傳。
- 客戶端請求第一個 Block上傳到哪幾個DataNode伺服器上。
- NameNode返回3個DataNode節點,分別為dn1、dn2、dn3。
- 客戶端通過FSDataOutputStream模塊請求dn1上傳數據,dn1收到請求會繼續調用dn2,然後dn2調用dn3,將這個通信管道建立完成。
- dn1、dn2、dn3逐級應答客戶端。
- 客戶端開始往dn1上傳第一個Block(先從磁碟讀取數據放到一個本地記憶體緩存),以Packet(64k)為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答隊列等待應答。
- 當一個Block傳輸完成之後,客戶端再次請求NameNode上傳第二個Block的伺服器。(重覆執行3-7步)。
異常寫流程
1-6步同上
-
- 客戶端每讀取64K的數據,封裝為一個packet,封裝成功的packet,放入到一個隊列中,這個隊列稱為dataQuene(待發送數據包)
- 在發送時,先將dataQuene中的packet按順序發送,發送後再放入到ackquene(正在發送的隊列)。
- 每個節點在收到packet後,向客戶端發送ack確認消息!
- 如果一個packet在發送後,已經收到了所有DN返回的ack確認消息,這個packet會在ackquene中刪除!
- 假如一個packet在發送後,在收到DN返回的ack確認消息時超時,傳輸中止,ackquene中的packet會回滾到dataQuene。
- 重新建立通道,剔除壞的DN節點。建立完成之後,繼續傳輸!
- 只要有一個DN節點收到了數據,DN上報NN已經收完此塊,NN就認為當前塊已經傳輸成功!
- NN會自動維護副本數!
網路拓撲-節點距離計算
在HDFS寫數據的過程中,NameNode會選擇距離待上傳數據最近距離的DataNode接收數據。那麼這個最近距離怎麼計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和。
例如,假設有數據中心d1機架r1中的節點n1。該節點可以表示為/d1/r1/n1。利用這種標記,這裡給出四種距離描述,如圖所示
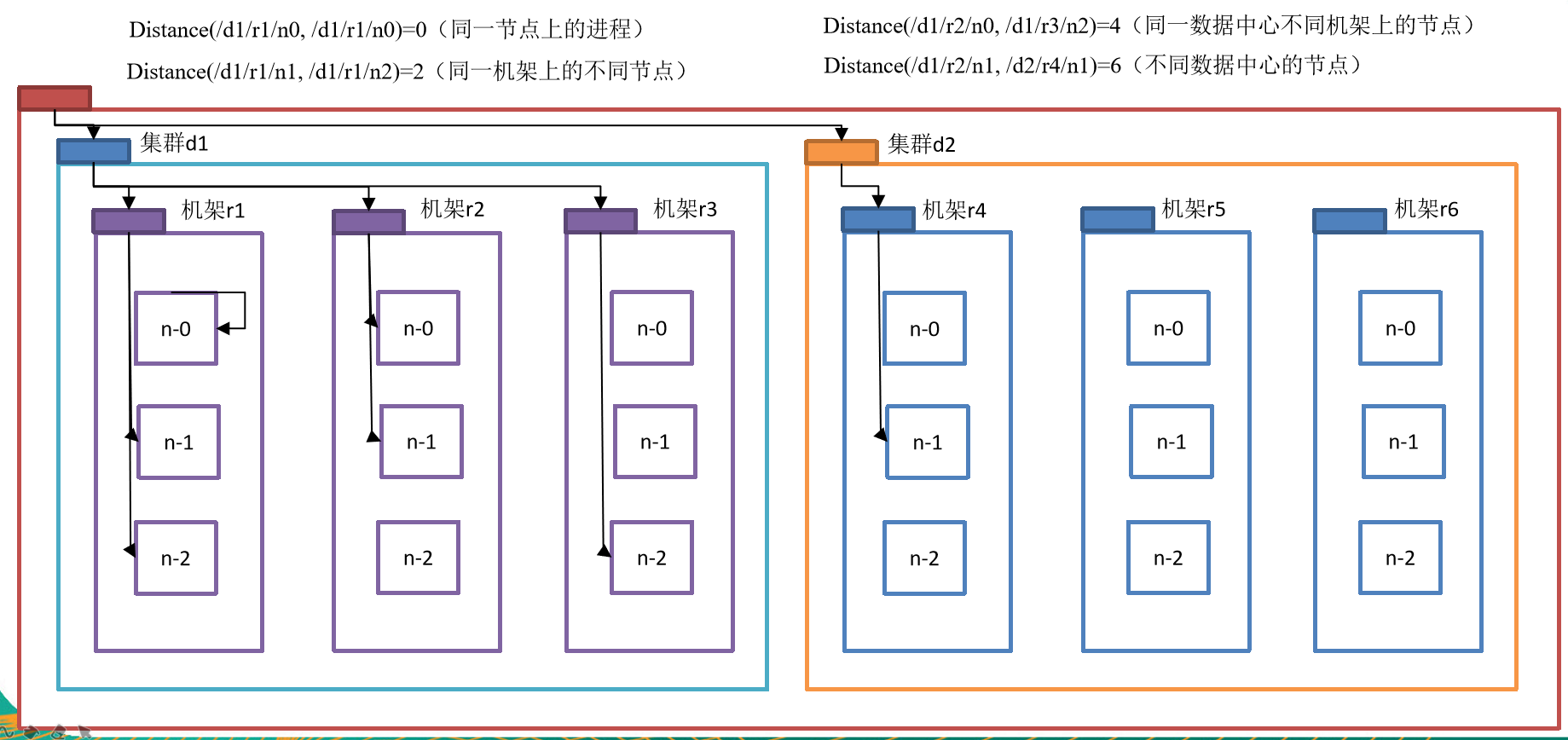
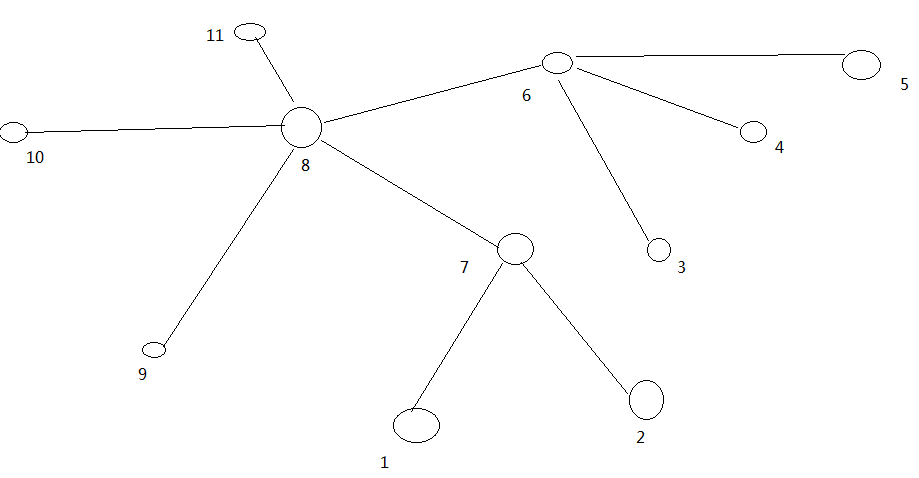
大家算一算每兩個節點之間的距離,如圖所示。
機架感知(副本存儲節點選擇)
-
官方ip地址
機架感知說明
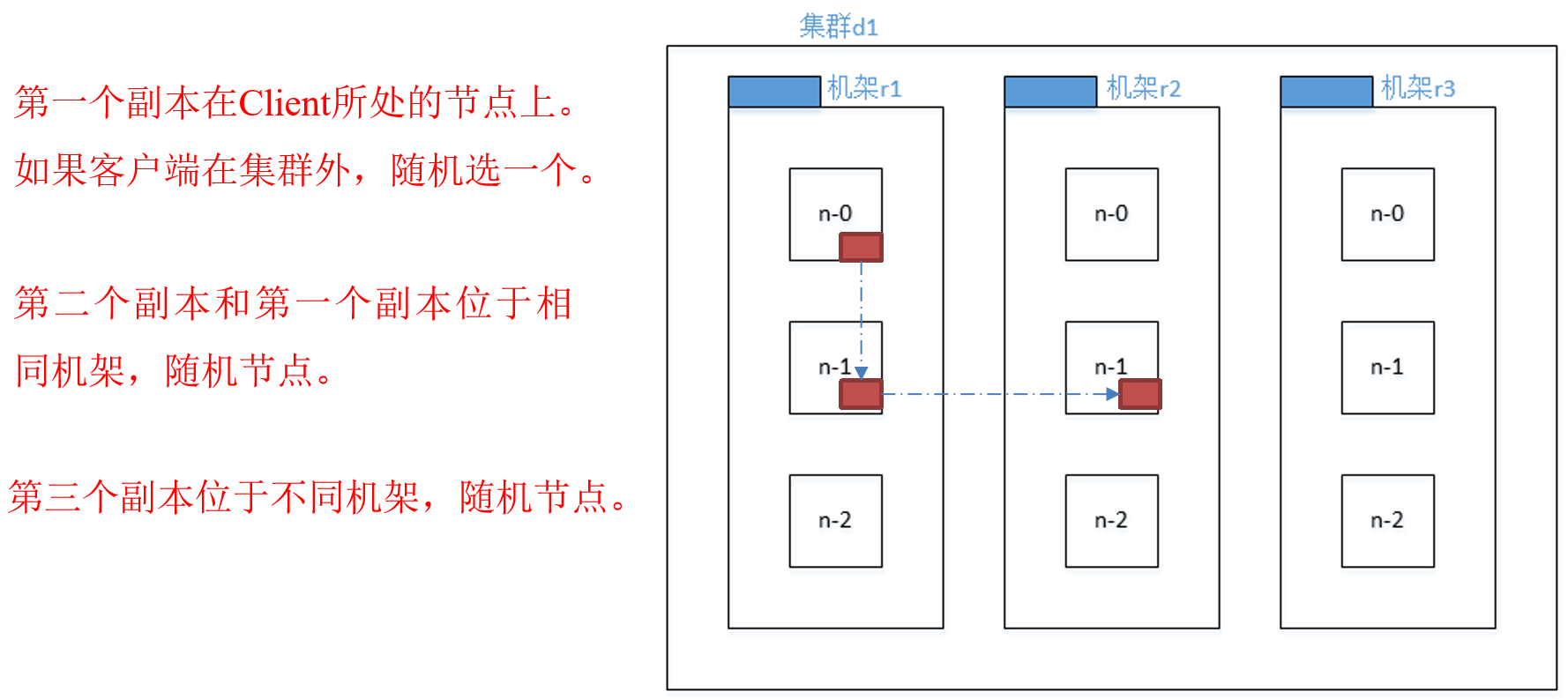
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on one node in the local rack, another on a different node in the local rack, and the last on a different node in a different rack.
-
Hadoop2.7.2副本節點選擇
HDFS讀數據流程
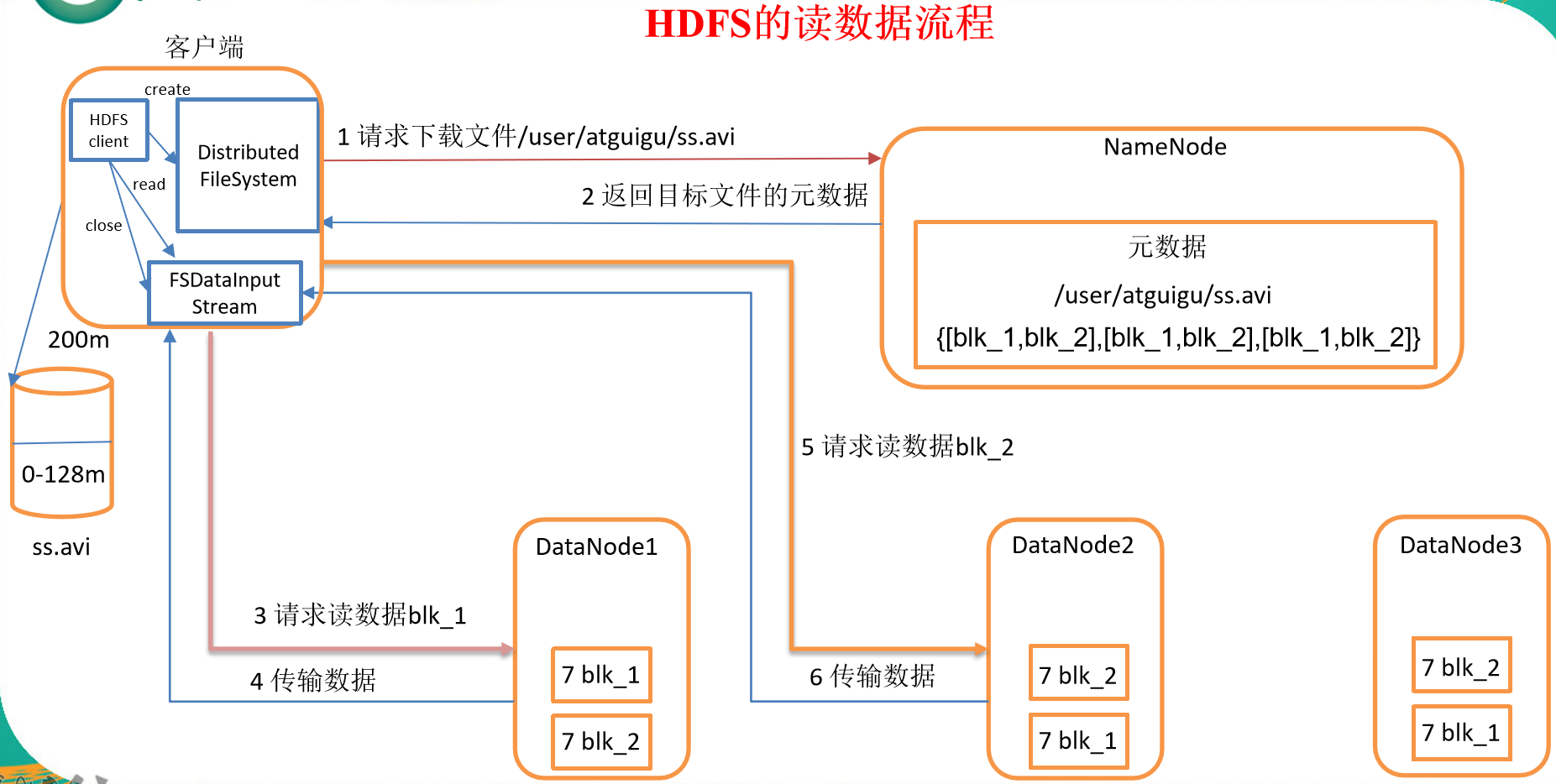
- 客戶端通過Distributed FileSystem向NameNode請求下載文件,NameNode通過查詢元數據,找到文件塊所在的DataNode地址。
- 挑選一臺DataNode(就近原則,然後隨機)伺服器,請求讀取數據。
- DataNode開始傳輸數據給客戶端(從磁碟裡面讀取數據輸入流,以Packet為單位來做校驗)。
- 客戶端以Packet為單位接收,先在本地緩存,然後寫入目標文件。
其他註意事項
- HDFS副本數的概念指的是最大副本數!具體存放幾個副本需要參考DN節點的數量!每個DN節點最多只能存儲一個副本!
- HDFS預設塊大小為128M,128M指的是塊的最大大小!每個塊最多存儲128M的數據,如果當前塊存儲的數據不滿128M存了多少數據,就占用多少的磁碟空間!一個塊只屬於一個文件!
- shell操作命令
- hadoop fs : 既可以對本地文件系統進行操作還可以操作分散式文件系統
- hdfs dfs : 只能操作分散式文件系統


