
DataStream API(一) 在瞭解DataStream API之前我們先來瞭解一下Flink API的構成。Flink API是分層的。由最底層的Stateful Stream Process到最頂層的SQL分為四層。如下圖: DataStream API 顧名思義,就是DataStream ...
DataStream API(一)
在瞭解DataStream API之前我們先來瞭解一下Flink API的構成。Flink API是分層的。由最底層的Stateful Stream Process到最頂層的SQL分為四層。如下圖:
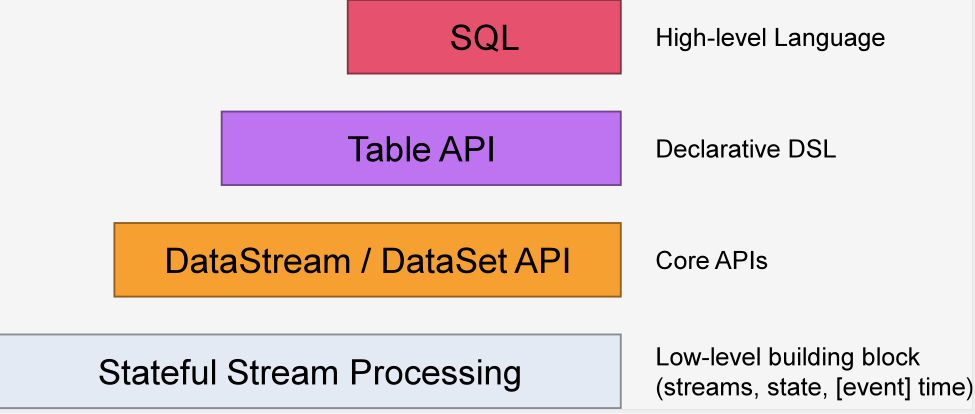
DataStream API 顧名思義,就是DataStream類的API,DataStream表示Flink程式中的流式數據集合。它是一個包含重覆項的不可變數據集合,這些數據可以是有界的也可以是無界的,處理他們的API是相同的。
DataStream是不可變的,這意味著一旦它們被創建,就不能添加或刪除元素。也不能簡單地檢查內部的元素,而只能使用DataStream API(Transform)來處理它們。
Flink程式基本部分組成:
- 獲得執行環境(Environment),
- 載入/創建初始數據(Source),
- 指定此數據的轉換(Transform),
- 指定計算結果的存放位置(Sink),
- 觸發程式執行(Execut)
下麵我們一起來瞭解一下Flink DataStream的執行環境。
Environment
Flink的執行環境包括兩種,分別是StreamExecutionEnvironment和ExecutionEnvironment,他們分別對應StreamData和DataSet。StreamData是流式數據集,DataSet是批量數據集。
StreamExecutionEnvironment是所有Flink流式處理程式的基礎。它為我們提供了三種實例化的方法,分別是:
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String... jarFiles)
createLocalEnvironment()
這個方法是獲取本地的執行環境。它有兩個重載,分別是:
//parallelism表示並行度
createLocalEnvironment(int parallelism)
createLocalEnvironment(int parallelism, Configuration configuration)
createRemoteEnvironment(String host, int port, String... jarFiles)
這個方法是獲取集群的執行環境。與createLocalEnvironment()類似,它也有兩個重載,分別是:
createRemoteEnvironment(String host, int port, int parallelism, String... jarFiles)
createRemoteEnvironment(String host, int port, Configuration clientConfig, String... jarFiles)
getExecutionEnvironment()
getExecutionEnvironment()可以自行判斷我們當前程式的執行環境併為我們返回與之相對應的實例。換句話說,通常情況下我們不需要自己判斷到底是使用createLocalEnvironment還是使用createRemoteEnvironment,一律用getExecutionEnvironment就OK了。
Environment實例
通過Environment實例我們可以做很多事情,比如:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//設置並行度
env.setParallelism(1);
//獲取數據源
//當然獲取數據源的方式有很多種,下麵會一一介紹
env.readTextFile("FilePath");
//執行程式
env.Execute();
//...
Data Sources
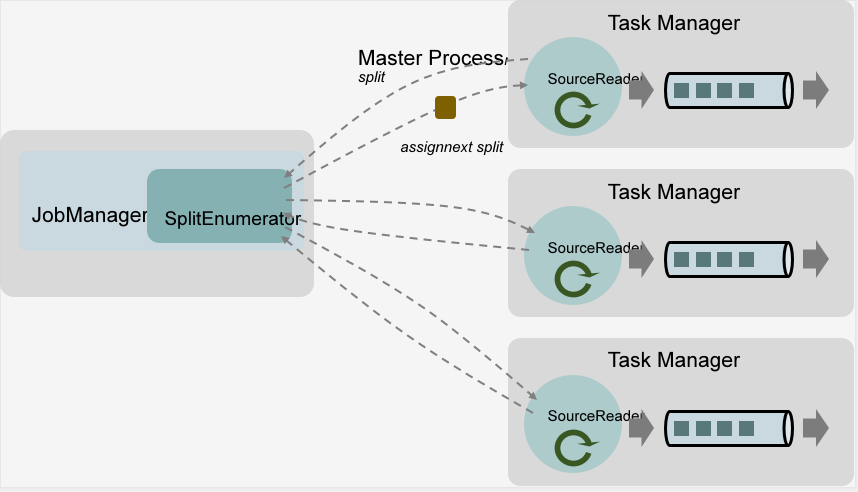
Data Source的核心組件包括三個,分別是Split、SourceReader、SplitEnumerator。
- Split:Split是數據源的一部分,例如:文件的一部分或者一條日誌。Splits是Source並行讀取數據和分發作業的基礎。
- SourceReader:SourceReader向SplitEnumerator請求Splits並處理請求到的Splits。SourceReader位於TaskManager中,這意味著它是並行運行的,同時,它可以產生並行的事件流/記錄流。
- SplitEnumerator:SplitEnumerator負責管理Splits並且將他們發送給SourceReader。它是運行在JobManager上的單個實例。負責維護正在進行的分片的備份日誌並將這些分片均衡的分發到SourceReader中。
具體的過程可以參考以下圖片:
下麵我們來介紹一下幾個常用的獲取數據源的方式。
從集合中讀取
ArrayList<String> strList = new ArrayList<String>();
strList.add("are");
strList.add("you");
strList.add("ok");
env.fromCollection(strList);
從文件中讀取
DataStreamSource<String> inputData = env.readTextFile("FilePath");
消費kafka中的數據
引入kafka依賴
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.0</version>
</dependency>
代碼示例
//kafka配置
Properties pro = new Properties();
pro.setProperty("bootstrap.servers", "localhost:9092");
pro.setProperty("group.id", "consumer-group");
pro.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
pro.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
pro.setProperty("auto.offset.reset", "latest");
//消費kafka數據
DataStreamSource inputStream = env.addSource(new FlinkKafkaConsumer("topic", new SimpleStringSchema(), pro));
當然,出了kafka之外Flink還為我們提供了ElasticSearch、HDFS、RabbitMQ、JDBC等作為數據源的介面。此處就不一一介紹了。
自定義數據源
其實深入研究之後我們會發現,FlinkKafkaConsumer其實是實現了一個SourceFunction介面。so,我們可以通過實現SourceFunction的方式來自定義我們自己的數據源。
有了這個功能我們可以很輕鬆的模擬真實的業務場景。畢竟,絕大多數的項目在開發階段並不會有真實的業務場景來提供數據源。
DataStreamSource inputStream = env.addSource(new MyDataSource());
private static class MyDataSource implements SourceFunction<Sensor> {
private boolean running = true;
public void run(SourceContext sourceContext) throws Exception {
while(running){
//讀取數據,可以從cvs文件...自定義數據源讀取數據
Thread.sleep(100);
}
}
public void cancel() {
running = false;
}
}


