
大概的簡述一下,及cpu讀取記憶體里的東西時,並不會直接去記憶體去讀取,這樣會導致讀取的數據很慢。cpu會到一級緩存讀取所需要的數據,而一級緩存則會去記憶體裡面讀取數據,讀取的方式是通過緩存行(cache line)的形式來進行讀取。當一級緩存內的數據需要置換時,則會將緩存內的數據置換到二級緩存內,然後依 ...
大概的簡述一下,及cpu讀取記憶體里的東西時,並不會直接去記憶體去讀取,這樣會導致讀取的數據很慢。cpu會到一級緩存讀取所需要的數據,而一級緩存則會去記憶體裡面讀取數據,讀取的方式是通過緩存行(cache line)的形式來進行讀取。當一級緩存內的數據需要置換時,則會將緩存內的數據置換到二級緩存內,然後依次類推到記憶體中。
假設我們的緩存行為64位元組,512行(一共32K)。那麼32K的大小怎麼進行對幾百M或者幾G的記憶體進行映射呢?
高速緩存讀物理記憶體的位置不是任意的,而是固定的。那麼就根據高速緩存的大小進行映射,這裡是32K一組大小進行映射:
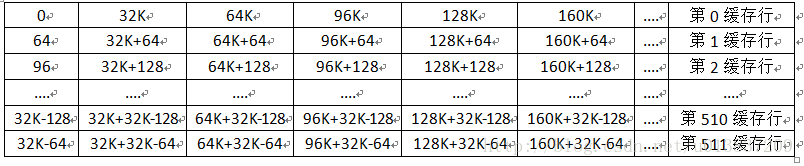
再假設: 我們讀取數據的記憶體物理地址是0x1000000,
則第0緩存行就會固定的讀取0x10000000x1000040這64個位元組大小(即緩存行大小),並且第0緩存行並不能讀取0x10000400x1000080的數據,這個地址只能是第1緩存行進行讀取的。第0緩存行讀取的下一個地址只能是0x1008000~0x1008040的數據,然後以此類推。
那麼現在已經可以解釋slab為啥要進行著色了:
比如cpu正在對0x10000008地址進行讀寫操作,突然有一個地址指針指向了0x10008008,並且需要讀取0x10008008記憶體處的地址,cpu檢測到衝突,因為此時位於第0根緩存行上的64個位元組數據有效地址空間是0x100000000x10000040,而另一個地址段下的物理記憶體也需要使用第0根緩存行,cpu執行寫回操作,將現在第0根緩存行上的64位元組數據塊傳輸到物理記憶體0x100000000x10000040上,之後將0x10008000~0x10008040物理記憶體段上的64位元組數據,塊傳輸到第0緩存行,這樣就完成了衝突之後的一次切換。
如果我們需要進行對這兩塊上面的數據分別交叉的讀取1000次,那麼我們需要進行對高速緩存的不斷移除更新,而且讀取記憶體的速度遠遠的大於讀取緩存的速度,那麼將會造成大量的時間消耗。
解決辦法就是將第二塊讀取的數據前加一個偏移,讓它移到第1塊緩存行上面,兩塊數據分別可以在緩存行的0和1行上面進行讀取,那麼我們讀取數據的時候就不會造成不必要的數據交換。
著色即為添加偏移。

