
上面這張監控圖,對於服務端的研發同學來說再熟悉不過了。在日常的系統維護中,『服務超時』應該屬於監控報警最多的一類問題。 尤其在微服務架構下,一次請求可能要經過一條很長的鏈路,跨多個服務調用後才能返回結果。當服務超時發生時,研發同學往往要抽絲剝繭般去分析自身系統的性能以及依賴服務的性能,這也是為什麼服 ...

上面這張監控圖,對於服務端的研發同學來說再熟悉不過了。在日常的系統維護中,『服務超時』應該屬於監控報警最多的一類問題。
尤其在微服務架構下,一次請求可能要經過一條很長的鏈路,跨多個服務調用後才能返回結果。當服務超時發生時,研發同學往往要抽絲剝繭般去分析自身系統的性能以及依賴服務的性能,這也是為什麼服務超時相對於服務出錯和服務調用量異常更難調查的原因。
這篇文章將通過一個真實的線上事故,系統性地介紹下:在微服務架構下,該如何正確理解並設置RPC介面的超時時間,讓大家在開發服務端介面時有更全局的視野。內容將分成以下4個部分:
1、從一次RPC介面超時引發的線上事故說起
2、超時的實現原理是什麼?
3、設置超時時間到底是為瞭解決什麼問題?
4、應該如何合理的設置超時時間?
01 從一次線上事故說起
事故發生在電商APP的首頁推薦模塊,某天中午突然收到用戶反饋:APP首頁除了banner圖和導航區域,下方的推薦模塊變成空白頁了(推薦模塊占到首頁2/3的空間,是根據用戶興趣由演算法實時推薦的商品list)。
上面的業務場景可以藉助下麵的調用鏈來理解
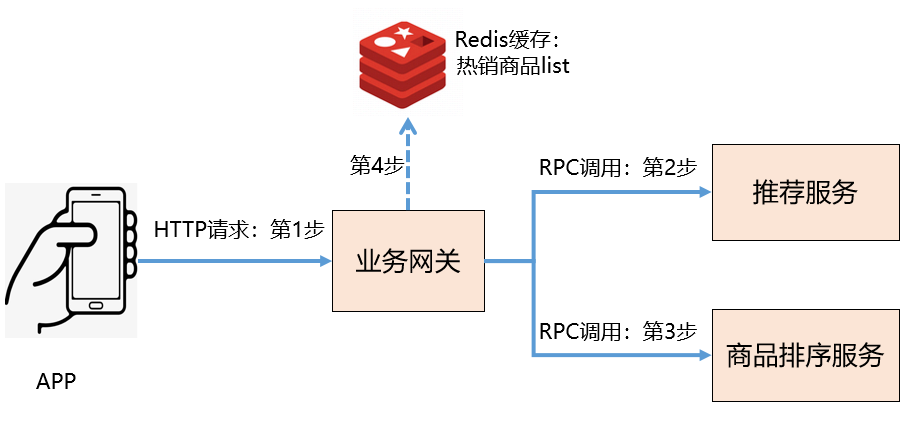
1、APP端發起一個HTTP請求到業務網關
2、業務網關RPC調用推薦服務,獲取推薦商品list
3、如果第2步調用失敗,則服務降級,改成RPC調用商品排序服務,獲取熱銷商品list進行托底
4、如果第3步調用失敗,則再次降級,直接獲取Redis緩存中的熱銷商品list
粗看起來,兩個依賴服務的降級策略都考慮進去了,理論上就算推薦服務或者商品排序服務全部掛掉,服務端都應該可以返回數據給APP端。但是APP端的推薦模塊確實出現空白了,降級策略可能並未生效,下麵詳細說下定位過程。
1、問題定位過程
第1步:APP端通過抓包發現:HTTP請求存在介面超時(超時時間設置的是5秒)。
第2步:業務網關通過日誌發現:調用推薦服務的RPC介面出現了大面積超時(超時時間設置的是3秒),錯誤信息如下:

第3步:推薦服務通過日誌發現:dubbo的線程池耗盡,錯誤信息如下:

通過以上3步,基本就定位到了問題出現在推薦服務,後來進一步調查得出:是因為推薦服務依賴的redis集群不可用導致了超時,進而導致線程池耗盡。詳細原因這裡不作展開,跟本文要討論的主題相關性不大。
2、降級策略未生效的原因分析
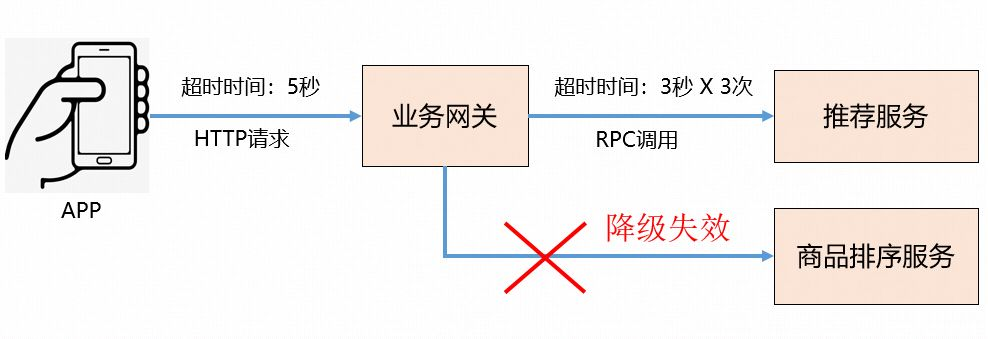
下麵再接著分析下:當推薦服務調用失敗時,為什麼業務網關的降級策略沒有生效呢?理論上來說,不應該降級去調用商品排序服務進行托底嗎?
最終跟蹤分析找到了根本原因:APP端調用業務網關的超時時間是5秒,業務網關調用推薦服務的超時時間是3秒,同時還設置了3次超時重試,這樣當推薦服務調用失敗進行第2次重試時,HTTP請求就已經超時了,因此業務網關的所有降級策略都不會生效。下麵是更加直觀的示意圖:
3、解決方案
1、將業務網關調用推薦服務的超時時間改成了800ms(推薦服務的TP99大約為540ms),超時重試次數改成了2次
2、將業務網關調用商品排序服務的超時時間改成了600ms(商品排序服務的TP99大約為400ms),超時重試次數也改成了2次
關於超時時間和重試次數的設置,需要考慮整個調用鏈中所有依賴服務的耗時、各個服務是否是核心服務等很多因素。這裡先不作展開,後文會詳細介紹具體方法。
02 超時的實現原理是什麼?
只有瞭解了RPC框架的超時實現原理,才能更好地去設置它。不論是dubbo、SpringCloud或者大廠自研的微服務框架(比如京東的JSF),超時的實現原理基本類似。下麵以dubbo 2.8.4版本的源碼為例來看下具體實現。
熟悉dubbo的同學都知道,可在兩個地方配置超時時間:分別是provider(服務端,服務提供方)和consumer(消費端,服務調用方)。服務端的超時配置是消費端的預設配置,也就是說只要服務端設置了超時時間,則所有消費端都無需設置,可通過註冊中心傳遞給消費端,這樣:一方面簡化了配置,另一方面因為服務端更清楚自己的介面性能,所以交給服務端進行設置也算合理。
dubbo支持非常細粒度的超時設置,包括:方法級別、介面級別和全局。如果各個級別同時配置了,優先順序為:消費端方法級 > 服務端方法級 > 消費端介面級 > 服務端介面級 > 消費端全局 > 服務端全局。
通過源碼,我們先看下服務端的超時處理邏輯
1 public class TimeoutFilter implements Filter {
2
3 public TimeoutFilter() {
4 }
5
6 public Result invoke(...) throws RpcException {
7 // 執行真正的邏輯調用,並統計耗時
8 long start = System.currentTimeMillis();
9 Result result = invoker.invoke(invocation);
10 long elapsed = System.currentTimeMillis() - start;
11
12 // 判斷是否超時
13 if (invoker.getUrl() != null && elapsed > timeout) {
14 // 列印warn日誌
15 logger.warn("invoke time out...");
16 }
17
18 return result;
19 }
20 }
可以看到,服務端即使超時,也只是列印了一個warn日誌。因此,服務端的超時設置並不會影響實際的調用過程,就算超時也會執行完整個處理邏輯。
再來看下消費端的超時處理邏輯
1 public class FailoverClusterInvoker {
2
3 public Result doInvoke(...) {
4 ...
5 // 迴圈調用設定的重試次數
6 for (int i = 0; i < retryTimes; ++i) {
7 ...
8 try {
9 Result result = invoker.invoke(invocation);
10 return result;
11 } catch (RpcException e) {
12 // 如果是業務異常,終止重試
13 if (e.isBiz()) {
14 throw e;
15 }
16
17 le = e;
18 } catch (Throwable e) {
19 le = new RpcException(...);
20 } finally {
21 ...
22 }
23 }
24
25 throw new RpcException("...");
26 }
27 }
FailoverCluster是集群容錯的預設模式,當調用失敗後會切換成調用其他伺服器。再看下doInvoke方法,當調用失敗時,會先判斷是否是業務異常,如果是則終止重試,否則會一直重試直到達到重試次數。
繼續跟蹤invoker的invoke方法,可以看到在請求發出後通過Future的get方法獲取結果,源碼如下:
1 public Object get(int timeout) {
2 if (timeout <= 0) {
3 timeout = 1000;
4 }
5
6 if (!isDone()) {
7 long start = System.currentTimeMillis();
8 this.lock.lock();
9
10 try {
11 // 迴圈判斷
12 while(!isDone()) {
13 // 放棄鎖,進入等待狀態
14 done.await((long)timeout, TimeUnit.MILLISECONDS);
15
16 // 判斷是否已經返回結果或者已經超時
17 long elapsed = System.currentTimeMillis() - start;
18 if (isDone() || elapsed > (long)timeout) {
19 break;
20 }
21 }
22 } catch (InterruptedException var8) {
23 throw new RuntimeException(var8);
24 } finally {
25 this.lock.unlock();
26 }
27
28 if (!isDone()) {
29 // 如果未返回結果,則拋出超時異常
30 throw new TimeoutException(...);
31 }
32 }
33
34 return returnFromResponse();
35 }
進入方法後開始計時,如果在設定的超時時間內沒有獲得返回結果,則拋出TimeoutException。因此,消費端的超時邏輯同時受到超時時間和超時次數兩個參數的控制,像網路異常、響應超時等都會一直重試,直到達到重試次數。
03 設置超時時間是為瞭解決什麼問題?
RPC框架的超時重試機制到底是為瞭解決什麼問題呢?從微服務架構這個巨集觀角度來說,它是為了確保服務鏈路的穩定性,提供了一種框架級的容錯能力。微觀上如何理解呢?可以從下麵幾個具體case來看:
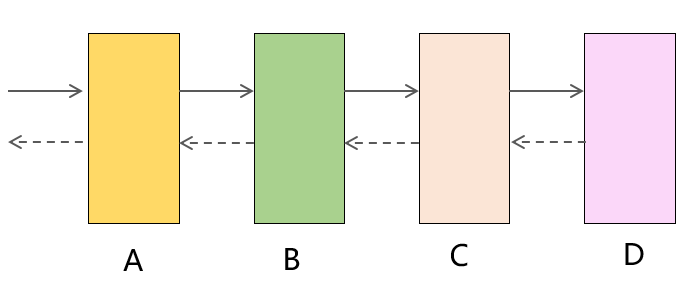
1、consumer調用provider,如果不設置超時時間,則consumer的響應時間肯定會大於provider的響應時間。當provider性能變差時,consumer的性能也會受到影響,因為它必須無限期地等待provider的返回。假如整個調用鏈路經過了A、B、C、D多個服務,只要D的性能變差,就會自下而上影響到A、B、C,最終造成整個鏈路超時甚至癱瘓,因此設置超時時間是非常有必要的。
2、假設consumer是核心的商品服務,provider是非核心的評論服務,當評價服務出現性能問題時,商品服務可以接受不返回評價信息,從而保證能繼續對外提供服務。這樣情況下,就必須設置一個超時時間,當評價服務超過這個閾值時,商品服務不用繼續等待。
3、provider很有可能是因為某個瞬間的網路抖動或者機器高負載引起的超時,如果超時後直接放棄,某些場景會造成業務損失(比如庫存介面超時會導致下單失敗)。因此,對於這種臨時性的服務抖動,如果在超時後重試一下是可以輓救的,所以有必要通過重試機制來解決。
但是引入超時重試機制後,並非一切就完美了。它同樣會帶來副作用,這些是開發RPC介面必須要考慮,同時也是最容易忽視的問題:
1、重覆請求:有可能provider執行完了,但是因為網路抖動consumer認為超時了,這種情況下重試機制就會導致重覆請求,從而帶來臟數據問題,因此服務端必須考慮介面的冪等性。
2、降低consumer的負載能力:如果provider並不是臨時性的抖動,而是確實存在性能問題,這樣重試多次也是沒法成功的,反而會使得consumer的平均響應時間變長。比如正常情況下provider的平均響應時間是1s,consumer將超時時間設置成1.5s,重試次數設置為2次,這樣單次請求將耗時3s,consumer的整體負載就會被拉下來,如果consumer是一個高QPS的服務,還有可能引起連鎖反應造成雪崩。
3、爆炸式的重試風暴:假如一條調用鏈路經過了4個服務,最底層的服務D出現超時,這樣上游服務都將發起重試,假設重試次數都設置的3次,那麼B將面臨正常情況下3倍的負載量,C是9倍,D是27倍,整個服務集群可能因此雪崩。
04 應該如何合理的設置超時時間?
理解了RPC框架的超時實現原理和可能引入的副作用後,可以按照下麵的方法進行超時設置:
1、設置調用方的超時時間之前,先瞭解清楚依賴服務的TP99響應時間是多少(如果依賴服務性能波動大,也可以看TP95),調用方的超時時間可以在此基礎上加50%
2、如果RPC框架支持多粒度的超時設置,則:全局超時時間應該要略大於介面級別最長的耗時時間,每個介面的超時時間應該要略大於方法級別最長的耗時時間,每個方法的超時時間應該要略大於實際的方法執行時間
3、區分是可重試服務還是不可重試服務,如果介面沒實現冪等則不允許設置重試次數。註意:讀介面是天然冪等的,寫介面則可以使用業務單據ID或者在調用方生成唯一ID傳遞給服務端,通過此ID進行防重避免引入臟數據
4、如果RPC框架支持服務端的超時設置,同樣基於前面3條規則依次進行設置,這樣能避免客戶端不設置的情況下配置是合理的,減少隱患
5、如果從業務角度來看,服務可用性要求不用那麼高(比如偏內部的應用系統),則可以不用設置超時重試次數,直接人工重試即可,這樣能減少介面實現的複雜度,反而更利於後期維護
6、重試次數設置越大,服務可用性越高,業務損失也能進一步降低,但是性能隱患也會更大,這個需要綜合考慮設置成幾次(一般是2次,最多3次)
7、如果調用方是高QPS服務,則必須考慮服務方超時情況下的降級和熔斷策略。(比如超過10%的請求出錯,則停止重試機制直接熔斷,改成調用其他服務、非同步MQ機制、或者使用調用方的緩存數據)
最後,再簡單總結下:
RPC介面的超時設置看似簡單,實際上有很大學問。不僅涉及到很多技術層面的問題(比如介面冪等、服務降級和熔斷、性能評估和優化),同時還需要從業務角度評估必要性。知其然知其所以然,希望這些知識能讓你在開發RPC介面時,有更全局的視野。
作者簡介:程式員,985碩士,前亞馬遜Java工程師,現58轉轉技術總監。持續分享技術和管理方向的文章。如果感興趣,可微信掃描下麵的二維碼關註我的公眾號:『IT人的職場進階』



