
聚合就是歸類的意思,把同類事物統一處理; 聚合根也就是最抽象,最普遍的特性; 背景 領域建模的過程回顧: 那麼問題來了? 為什麼要在限界上下文和實體之間增加聚合和聚合根的概念,即作用是什麼? 如何設計聚合? 按照一般的研究和學習思路,先弄懂概念,然後結合實際例子理解概念,然後再回答提出的問題。 聚合 ...

聚合就是歸類的意思,把同類事物統一處理;
聚合根也就是最抽象,最普遍的特性;
背景
領域建模的過程回顧:
那麼問題來了?
為什麼要在限界上下文和實體之間增加聚合和聚合根的概念,即作用是什麼?
如何設計聚合?
按照一般的研究和學習思路,先弄懂概念,然後結合實際例子理解概念,然後再回答提出的問題。
聚合根
聚合根:如果把聚合比作組織,聚合根則是組織的負責人,聚合根也叫做根實體,它不僅僅是實體,還是實體的管理者;
職責:
1,作為實體,具備自己的業務屬性,業務行為,業務邏輯
2,作為聚合的管理者,
在聚合內部,負責協調實體和值對象按照固定的業務規則協同完成共同的業務邏輯;
在聚合之間:它是聚合對外的介面人,以聚合根ID的方式接受外部請求和任務,實現上下文中的聚合之間的業務協同;
聚合之間通過聚合根關聯引用,如果需要訪問其他聚合的實體,先訪問聚合根,再導航到聚合內部的實體;即外部對象不能直接訪問聚合內的實體;
解決的問題: 複雜數據模型缺少統一的業務規則控制而導致的聚合,實體之間數據不一致的問題;
| 數據處理方式 | 問題 |
|---|---|
| 傳統:實體個數據模型一一對應, | 任由實體無控制的修改數據,容易導致實體之間數據邏輯不一致的問題; |
加鎖增加了軟體複雜度和降低系統性能;
|
聚合
在DDD中,實體和值對象都是很基礎的領域對象。
聚合是什麼呢?類比一下:
| DDD的概念 | 人類 |
|---|---|
| 實體,值對象 | 人 |
| 聚合 | 社團,組織,部門 |
| 聚合的好處: | |
| 讓實體和值對象協同工作的組織就是聚合,用來確保這些領域對象在實現公共的業務邏輯的時候,可以保持數據的一致性 | 個人是組織的一員,協同工作,有共同目標,可以發揮出更大的力量 |
聚合的另一種視圖: 聚合是業務和邏輯緊密關聯的實體和值對象組合而成,聚合是數據修改和持久化的基本單元,一個聚合對應一個數據的持久化;
聚合在DDD分層架構中屬於領域層,領域層包含了多個聚合,共同實現核心業務邏輯,聚合內的實體以充血模型實現個體業務能力,以及業務邏輯的高內聚;
跨多個實體的業務邏輯通過領域服務來實現,跨多個聚合的業務邏輯通過應用服務來實現;
| 跨越場景 | 處理辦法 |
|---|---|
| 業務場景需要一個聚合中的A實體和B實體共同完成 | 業務邏輯用領域服務來實現; |
| 業務邏輯需要聚合C和聚合D共同完成 | 應用服務來組合這兩個服務; |
聚合的組成:
| 組成部分 | 說明 |
|---|---|
| 上下文邊界 | 邊界是根據業務單一職責和高內聚原則,定義了聚合內部應該包含哪些實體和值對象 |
| 聚合之間的邊界是松耦合的; | |
| 聚合根 | 見下麵的介紹 |
如何設計聚合?
例子:保單系統聚合的過程。
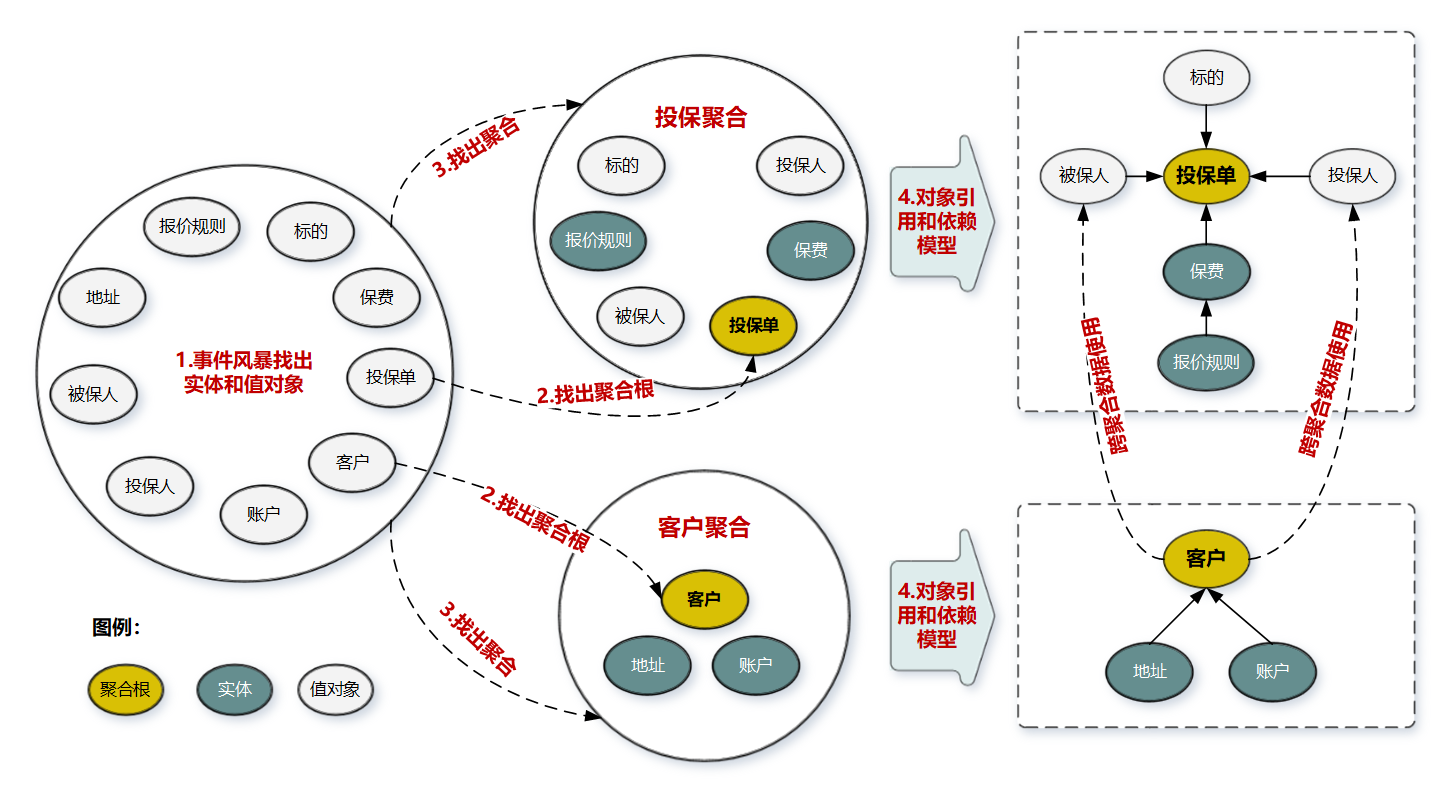
| 步驟 | 說明 |
|---|---|
| 1 | 通過事件風暴的用例分析,場景分析,用戶旅程分析得到領域對象(賬戶,客戶,投保單,報廢,標的,報價規則,地址,投保人,被保人) |
| 2 | 從領域對象中找出適合作為實體管理者的對象(聚合根),[是否具備唯一標識,能管理其他的實體]-》(投保,客戶) |
| 3 | 按照業務的職責單一和高內聚原則,找出聚合根緊密關聯的實體和值對象,構建以聚合根為中心的集合,即得到聚合;-》(投保聚合,客戶聚合) |
| 4 | 在聚合內部畫出聚合根跟實體和值對象的引用和依賴關係圖-》(客戶依賴地址和賬戶) |
| 5 | 多個聚合根據業務語義,和上下文劃在同一個限界上下文中 |
聚合的設計原則:
| 原則 | 說明 |
|---|---|
| 聚合設計的儘量小 | 如果聚合設計的過大,內部還有大量的實體和值對象,管理會比較複雜,高頻操作會有併發和資料庫鎖衝突的問題,導致系統可用性降低; 聚合設計的足夠小,也就降低了複雜度,可復用性也更高,降低了後期重構複雜聚合的成本; |
| 聚合應該高內聚 | 封裝的是真正的不變的領域對象,內部的實體和值對象按照固定的規則運行,實現數據的一致性,邊界外的任何東西都於該聚合無關, |
| 通過唯一標識符引用其它聚合 | 聚合之間通過聚合根的唯一ID來關聯,而不是直接對象引用的方式,外部的聚合對象如果在本聚合範圍內管理,容易導致邊界不清晰,增加聚合之間的耦合度; |
| 邊界之外使用最終一致性 | 聚合內部數據強一致性,聚合之間數據最終一致性,在一次事務中最多只修改一個聚合的數據狀態,如果在一次事務中涉及修改多個聚合的狀態,應該使用領域事件的方式來非同步的實現最終一致性,實現聚合之間的解耦; |
| 在應用層實現跨聚合的調用 | 實現微服務內部聚合之間的解耦,以為為未來以聚合為單位的拆分和組合,應該避免跨聚合的的領域服務調用和數據表關聯; |
小結
聚合的特點:高內聚低耦合,是領域模型中最底層的邊界,可以作為拆分微服務的最小單位,但是不建議單獨對應一個微服務,除非是對性能有極致要求的場景,一個微服務可以包含多個聚合,聚合之間的邊界是邏輯最天然的邊界,有了這個邏輯邊界,就可以在微服務拆分的時候作為拆分和組合依據,微服務架構演進也就不是難事了。
聚合根的特點:聚合根是實體,具備唯一標識,有獨立的生命周期,一個聚合只有一個聚合根,聚合根在聚合之內採用引用依賴的方式對實體和值對象進行組織和協調,聚合根和聚合根之間通過唯一id進行聚合之間的協同;
實體的特點:具備id標識,可以通過id進行相等性比較,實體在聚合內唯一,但是狀態可變,它依附於聚合根,它的生命周期由聚合根管理,實體一般都會持久化,跟數據持久化對象存在多種對應關係(一對一,一對多,多對一,1對0),實體可以引用聚合中的聚合根,實體,值對象;
值對象特點:無id,不可變,無生命周期,用完即失效,值對象之間通過屬性值判斷相等性,他的核心是值,是一組概念完整的屬性集合,用於描述實體的特征和狀態,值對象儘量只引用值對象;
本篇主要介紹了聚合根,聚合的概念,然後介紹了聚合的設計過程和原則,以及對比了聚合,聚合根,實體,值對象的特點。
下麵我們來回答最初的兩個問題?
為什麼要在實體和限界上下文之間增加聚合和聚合根,作用是什麼?
在實體和限界上下文之間增加聚合和聚合根之間的原因是:讓實體和值對象協同工作,在實現公共業務邏輯的時候,可以保證數據的一致性;
如何設計聚合?
過程是:通過事件風暴(用例分析,場景分析,用戶旅程分析)得到實體和值對象,然後找出聚合根,按照高內聚低耦合的設計原則,找出跟聚合根緊密關聯的實體和值對象,即形成聚合,並畫出聚合內的實體和值對象的引用依賴關係,最後把業務把關聯緊密的聚合畫在同一個限界上線文中,即完成了領域建模;
聚合的設計原則: 高內聚,聚合儘量小,聚合之間通過id關聯,邊界之外使用最終一致性,在應用層實現跨聚合的調用。
希望大家可以得到相對完整(高內聚低耦合)的業務領域模型;
原創不易,關註誠可貴,轉發價更高!轉載請註明出處,讓我們互通有無,共同進步,歡迎溝通交流。
我會持續分享Java軟體編程知識和程式員發展職業之路,歡迎關註,我整理了這些年編程學習的各種資源,關註公眾號‘李福春持續輸出’,發送'學習資料'分享給你!



