
1. 到底什麼是主鍵,外鍵? 基本概念: MySQL中“鍵”和“索引”的定義相同,所以外鍵和主鍵一樣也是索引的一種。不同的是MySQL會自動為所有表的主鍵進行索引,但是外鍵欄位必須由用戶進行明確的索引。 用於外鍵關係的欄位必須在所有的參照表中進行明確地索引,InnoDB不能自動地創建索引。 外鍵可以 ...
1. 到底什麼是主鍵,外鍵?
基本概念:
MySQL中“鍵”和“索引”的定義相同,所以外鍵和主鍵一樣也是索引的一種。不同的是MySQL會自動為所有表的主鍵進行索引,但是外鍵欄位必須由用戶進行明確的索引。
用於外鍵關係的欄位必須在所有的參照表中進行明確地索引,InnoDB不能自動地創建索引。
外鍵可以是一對一的,一個表的記錄只能與另一個表的一條記錄連接,或者是一對多的,一個表的記錄與另一個表的多條記錄連接
主鍵作用:
- 能夠唯一表示數據表中的每個記錄的欄位或欄位組合;
- 與其他表中的數據進行關聯(不同表中各記錄間的簡單指針);
- 主鍵不能是空值;
- 唯一約束是指用於指定一個或多個列的組合值具有唯一性,防止重覆,所有找主鍵值對用戶而言沒有什麼意義的。
外鍵:
- C是表A的主鍵,B中也有C欄位,則C是表B的外鍵
- 外鍵約束主要用來維護兩個表之間數據的一致性
- A為基本表,B為信息表,兩個表的C欄位列必須是數據類型相似,比如 int和tinyint可以,而int和char則不可以
方法1
建表指明外鍵:
create table 表B(... ,
CONSTRAINT `外鍵名稱` FOREIGNKEY(`外鍵欄位名稱`) REFERENCES 外鍵A表名(`主鍵欄位名稱`) ON DELETE SET NULL ON UPDATE SET NULL
) charset=utf8mb4;
例如:
create table employee( no int comment "員工編號", name varchar(20) comment "姓名", job varchar(40) comment "職位", mgr int comment "上司id", hiredate date comment "雇佣時間", sal double(10, 2) comment "工資", comm double(10, 2) comment "獎金", deptno int comment "部分id", CONSTRAINT `fk` FOREIGNKEY(`deptno`) REFERENCES dept(`deptno`) ONDELETESET NULL ONUPDATESET NULL ) charset=utf8mb4;
方法2
後期為表添加外鍵語法:
alter table 表B add constraint `外鍵名稱` foreign key(`外鍵欄位名稱`) references 外鍵A表名(`主鍵欄位名稱`) on delete set null on update set null;
例如:
alter table employee add CONSTRAINT `fkdd` FOREIGN KEY(`deptno`) REFERENCES dept(`deptno`) ON DELETE SET NULL ON UPDATE SET NULL;
外鍵的幾種模式:
- [ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
- [ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
ON DELETE、ON UPDATE表示事件觸發限制,可設參數:
RESTRICT(限制外表中的外鍵改動,預設值)
CASCADE(跟隨外鍵改動,表A影響到表B)
SET NULL(設空值,B表的外鍵列不能為NOT NULL)
SET DEFAULT(設預設值)
NO ACTION(無動作,預設的)
外鍵優點:數據一致性,減少寫代碼的量,保證數據可靠性。
外鍵缺點:會影響性能,為保證數據完整性會使得併發性降低。
外鍵與id方式優缺點相反
2. 並集(union)
並集(union)也叫聯合查詢
union和union all 區別:
union:可以去重
union all:返回所有記錄,效率高於union
- 在多個select語句中,第一個語句中的欄位將被用於結果的欄位名稱顯示
例如:
SELECT id, name, age FROM student UNION ALL SELECT id, name, age FROM teacher;
SELECT id, name, age FROM student UNION SELECT age, name, id FROM teacher;
- 在聯合查詢中,當使用 ORDER BY 的時候,需要對 SELECT 語句添加括弧,並且與LIMIT結合使用才生效
如:
(SELECT classId, id, name, age FROM student WHERE classId = 1 ORDER BY age DESC LIMIT 2) UNION (SELECT classId, id, name, age FROM student WHERE classId = 2 ORDER BY age);
- 也可對最終結果進行排序:(...) union (...) order by id;
3. 笛卡爾積
先確定數據要用到哪些表,將多個表先通過笛卡爾積變成一個表
然後去除不符合邏輯的數據(根據兩個表的關係去掉)
最後當做一個虛擬表來加上條件即可
A表m條數據,B表n條數據,一共產生m*n條數據
當然也可自交
例如:select * from 表A,表B;
4. 內連接 外連接
內連接:join,inner join
外連接:left join,left outer join,right join,right outer join,union,union al
交叉連接:cross join
on: ...... on A.id=B.id;
用using簡化當兩張表的列相同:.......using (id)
where:也可用where 代替on
先看圖
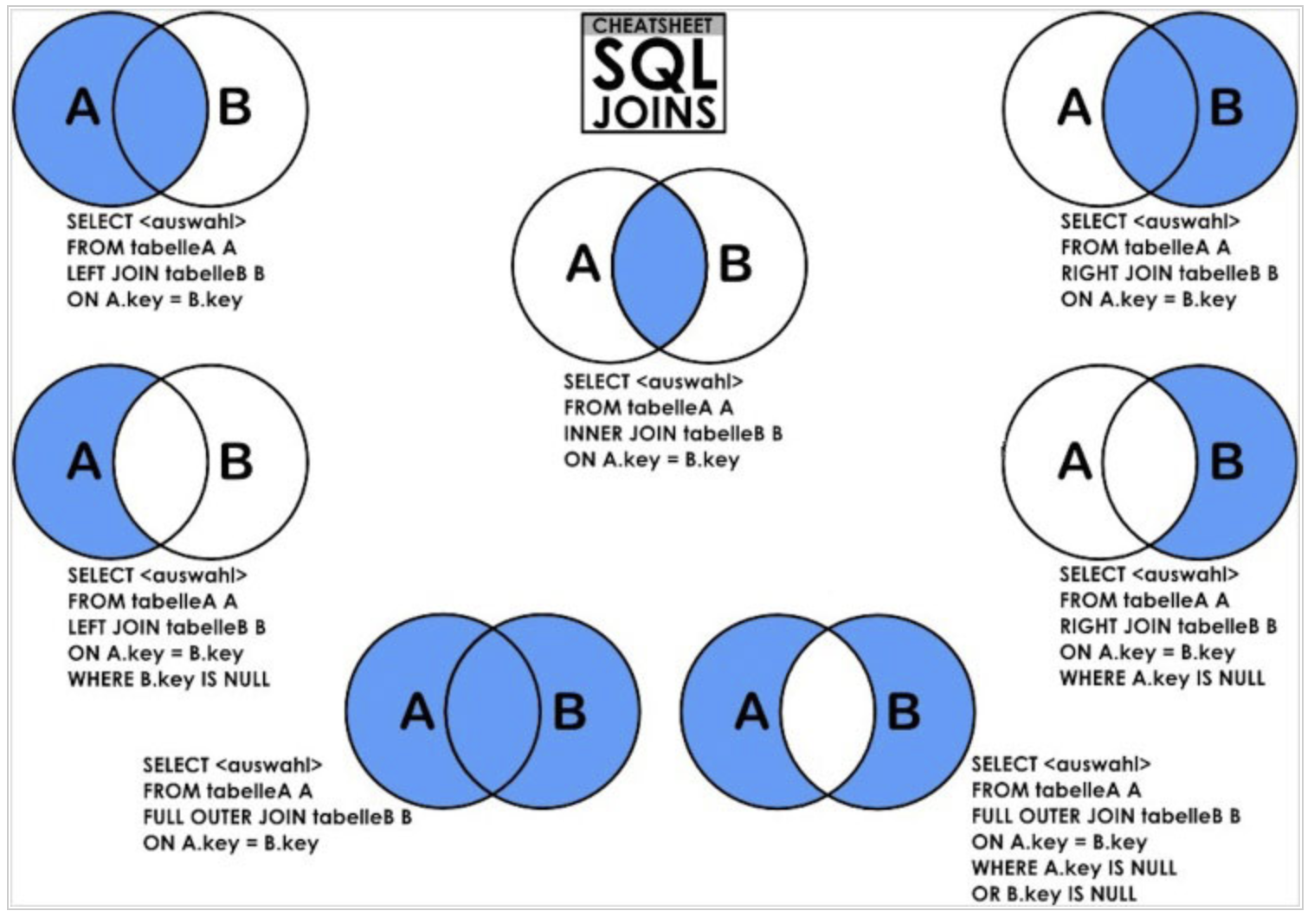
內連接
select * from a inner join b on a.id = b.id;
select * from a join b on a.id = b.id;
select * from a, b where a.id = b.id;
當表A中的一條記錄對應表B中的多條記錄時,會以重覆的方式對應多條表B記錄出現在結果集中。
當表B中的一條記錄對應表A中的多條記錄時,會以重覆的方式對應多條表A記錄出現在結果集中。
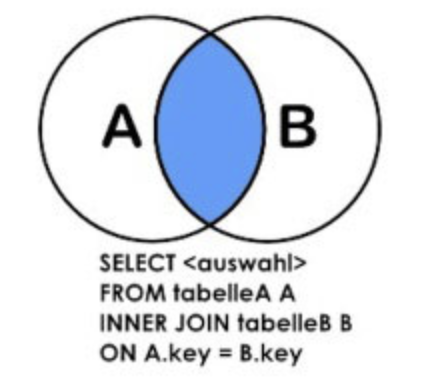
左連接:
也叫左外連接
select * from a left join b on a.id = b.id;
select * from a left outer join b on a.id = b.id;
左外連接,會以左邊的表A為主表,返回所有行,即使右表B中沒有匹配的行。
如果左邊的表A在右表B中找不到一條記錄,則返回表A所有記錄並且表B相應的欄位設為null。
如果左邊的表A在右表B中找到多條記錄,則以相同表A記錄和不同表B記錄多條顯示在結果集中。
這種情況下,其實是把表A中所有記錄都查詢出來了,包括不滿足條件的記錄。
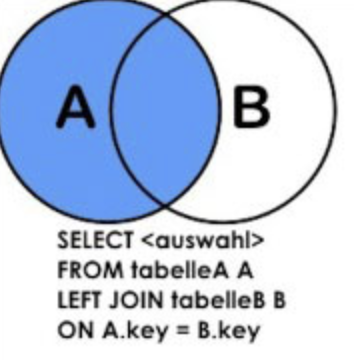
如果我們只想查出表A中滿足條件的:
select * from a left join b on a.id = b.id where b.id is null;
右連接:
也叫右外連接

select * from a right join b on a.id = b.a_id;
select * from a right outer join b on a.id = b.a_id;
如果只想查表B滿足要求的:
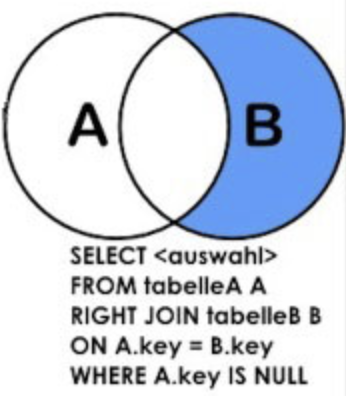
select * from a right join b on a.id = b.id where a.id is null;
全連接:

mysql並不支持全連接,不過有相應的替代方案,就是left join union right join 來代替。
select * from a left join b on a.id = b.id
union
select * from a right join b on a.id = b.id;
如果只想顯示所有不滿足條件的記錄,則通過如下語句:
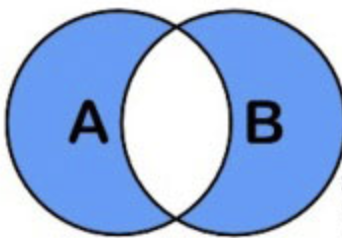
select * from a left join b on a.id = b.a_id where b.a_id is null
union
select * from a right join b on a.id = b.a_id where a.id is null;
交叉連接:
交叉連接實際上就是表A與表B的笛卡爾乘積
select * from a cross join b;
select * from a, b;
5. 子查詢
概念:當一個查詢時另一個查詢的條件時,稱之為子查詢(內層查詢)
使用原因:很多時候兩張表可能非常大,做笛卡爾積之後,更大,會死機
子查詢優點:減少查詢次數!
好習慣:先通過select count(*)的方式查看記錄數。
一般在where或者from子句中出現,外層的select為主查詢。
子查詢出現位置:
- where子句子查詢:返回單行單列,多行單列,單行多列數據.多行單列子查詢通常包含 in ,any,all,exists關鍵字
- from子句子查詢:返回多行多列的數據,可以做一張臨時表,要求必須起別名
- select後面:僅支持標量子查詢
#案例1:誰的工資比 Abel 高?
#①查詢Abel的工資
SELECT salary
FROM employees
WHERE last_name = 'Abel';
#②查詢員工的信息,滿足 salary>①結果
SELECT *
FROM employees
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
#案例2:返回job_id與141號員工相同,salary比143號員工多的員工 姓名,job_id 和工資
#①查詢141號員工的job_id
SELECT job_id FROM employees WHERE employee_id = 141;
#②查詢143號員工的salary
SELECT salary FROM employees WHERE employee_id = 143
#③查詢員工的姓名,job_id 和工資,要求job_id=①並且salary>②
SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary>( SELECT salary FROM employees WHERE employee_id = 143 );
#案例3:返回公司工資最少的員工的last_name,job_id和salary
#①查詢公司的 最低工資
SELECT MIN(salary) FROM employees;
#②查詢last_name,job_id和salary,要求salary=①
SELECT last_name,job_id,salary FROM employees WHERE salary=( SELECT MIN(salary) FROM employees );
#案例4:查詢最低工資大於50號部門最低工資的部門id和其最低工資
#①查詢50號部門的最低工資
SELECT MIN(salary) FROM employees WHERE department_id = 50;
#②查詢每個部門的最低工資
SELECT MIN(salary),department_id FROM employees GROUP BY department_id;
#③ 在②基礎上篩選,滿足min(salary)>①
SELECT MIN(salary),department_id FROM employees GROUP BY department_id HAVING MIN(salary)>( SELECT MIN(salary) FROM employees WHERE department_id = 50;
#案例:查詢員工編號最小並且工資最高的員工信息
SELECT * FROM employees WHERE (employee_id,salary)=( SELECT MIN(employee_id),MAX(salary) FROM employees );
select後面/*僅僅支持標量子查詢
#案例:查詢每個部門的員工個數
SELECT d.*,( SELECT COUNT(*) FROM employees e WHERE e.department_id = d.`department_id` ) 個數 FROM departments d;
any關鍵字:
=any :和in關鍵字一樣
>any (>=any):比最小的大
<any (<=any):比最大的小
案例:查詢工資大於最小的經理的員工姓名和工資
select name,sale from employ where sal>any( select sal from employ where job="manager");
all關鍵字:
>all:大於所有
<all:小於所有
案例:查詢薪資比任意一個經理都要高的員工和薪資
select name,sale from employ where sal>all( select sal from employ where job="manager");
6. 關鍵字:in和exists
exists返回的是一個布爾類型 True False
案列:顯示所有不在部門的員工信息
select * from dept where not exists( select * from employee where deptno=dept.deptno);
in和exists的區別1:執行原理
外表 in 內表
外表 exists 內表
in:先遍歷內表,再索引外表,故外表用大表
exists:先遍歷外表,再索引內表,故內表用大表
那麼外表大的用in,內表大的用exists,增加效率
區別2:欄位限制
in 有欄位限制
exists沒有欄位限制
例如:
select * from tabA where tabA.x in (select x from tabB where y>0 );
參考文獻:
https://blog.csdn.net/haluoluo211/article/details/52638366
https://blog.csdn.net/qq_34306360/article/details/79717682
https://www.jb51.net/article/180763.htm
https://blog.csdn.net/qq_26594041/article/details/89438382


