
一、監督學習基礎知識 利用一組帶有標簽的數據,學習從輸入到輸出的映射,然後將這種映射關係應用到未知數據上,達到分類或回歸的目的 分類:當輸出是離散的,學習任務為分類任務 回歸:當輸出是連續的,學習任務為回歸任務 二、分類學習 1、輸入與輸出 輸入:一組有標簽的訓練數據(也稱觀察和評估),標簽表明瞭這 ...
一、監督學習基礎知識
利用一組帶有標簽的數據,學習從輸入到輸出的映射,然後將這種映射關係應用到未知數據上,達到分類或回歸的目的
分類:當輸出是離散的,學習任務為分類任務
回歸:當輸出是連續的,學習任務為回歸任務
二、分類學習
1、輸入與輸出
輸入:一組有標簽的訓練數據(也稱觀察和評估),標簽表明瞭這些數據(觀察)的所署類別 輸出:分類模型根據這些訓練數據,訓練自己的模型參數,學習出一個適合這組數據的分類器,當有新數據(非訓練數據)需要進行類別判斷,就可以將這組新數據作為輸入送給學好的分類器進行判斷
2、分類任務
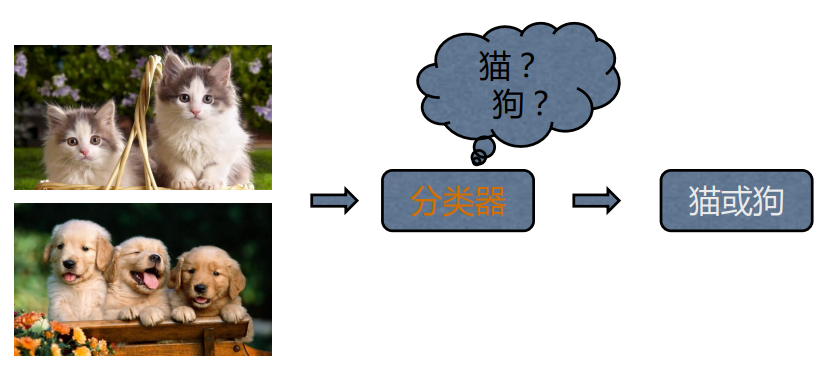
3、評價
訓練集(training set):顧名思義用來訓練模型的已標註數據,用來建立模型,發現規律
測試集(testing set):也是已標註數據,通常做法是將標註隱藏,輸送給訓練好的模型,通過結果與真實標註進行對比,評估模型的學習能力
訓練集/測試集的劃分方法:根據已有標註數據,隨機選出一部分數據(70%)數據作為訓練數據,餘下的作為測試數據,此外還有交叉驗證法,自助法用來評估分類模型
精確率:精確率是針對我們預測結果而言的,(以二分類為例)它表示的是預測為正的樣本中有多少是真正的正樣本。那麼預測為正就有兩種可能了,一種就是把正類預測為正類(TP),一種就是把負類預測為正類(FP), 也就是
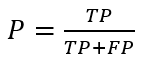
召回率:是針對我們原來的樣本而言的,它表示的是樣本中的正例有多少被預測正確了。那也有兩種可能,一種是把原來的正類預測成正類(TP),另一種就是把原來的正類預測為負類(FN),也就是
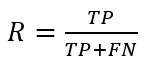
假設我們手上有60個正樣本,40個負樣本,我們要找出所有的正樣本,分類演算法查找出50個,其中只有40個是真正的正樣本
TP: 將正類預測為正類數40
FN: 將正類預測為負類數20
FP: 將負類預測為正類數10
TN: 將負類預測為負類數30
準確率(accuracy)= (TP+TN)/(TP+FN+FP+TN) = 70%
精確率(precision)= TP/(TP+FP)=80%
召回率(recall)=TP/(TP+FN)=66.7%
4、sklearn庫
與聚類演算法被統一封裝在sklearn.cluster模塊不同,sklearn庫中的分類演算法並未被統一封裝在一個子模塊中,因此對分類演算法的import方式各有不同
Sklearn提供的分類函數包括:
k近鄰(knn)、朴素貝葉斯(naivebayes)、 支持向量機(svm)、 決策樹 (decision tree)、神經網路模型(Neural networks)等,這其中有線性分類器,也有非線性分類器
5、應用
金融:貸款是否批准進行評估
醫療診斷:判斷一個腫瘤是惡性還是良性
欺詐檢測:判斷一筆銀行的交易是否涉嫌欺詐
網頁分類:判斷網頁的所屬類別,財經或者是娛樂?
三、回歸分析
1、基礎知識
統計學分析數據的方法,目的在於瞭解兩個或多個變數間是否相關、研究其相關方向與強度,並建立數學模型以便觀察特定變數來預測研究者感興趣的變數。回歸分析可以幫助人們瞭解在自變數變化時因變數的變化量。一般來說,通過回歸分析我們可以由給出的自變數估計因變數的條件期望
2、回歸任務

3、sklearn庫
Sklearn提供的回歸函數主要被封裝在兩個子模塊中,分別是sklearn.linear_model和sklearn.preprocessing
sklearn.linear_modlel封裝的是一些線性函數,線性回歸函數包括有:
普通線性回歸函數( LinearRegression )
嶺回歸(Ridge)
Lasso(Lasso)
非線性回歸函數,如多項式回歸(PolynomialFeatures)則通過 sklearn.preprocessing子模塊進行調用
4、應用
回歸方法適合對一些帶有時序信息的數據進行預測或者趨勢擬合,常用在 金融及其他涉及時間序列分析的領域:
股票趨勢預測
交通流量預測
資料來源:《Python機器學習應用》——禮欣,嵩天,北京理工大學,MOOC

