
[TOC] 哈嘍,大家好!距離上一篇文章近1個半月了,不是我拖呀~,剛好這個月遇到了工作調整,再加上要照顧10個月的孩子,實屬不易,所以就這麼長時間沒來更新了。這不,我每天碼一點點,'滴水成河',努力完成了這篇文章。 1. 封裝和解構 1.1 封裝 說明: 等號(=)右邊有多個數值僅通過逗號分割,就 ...
[TOC]
哈嘍,大家好!距離上一篇文章近1個半月了,不是我拖呀~,剛好這個月遇到了工作調整,再加上要照顧10個月的孩子,實屬不易,所以就這麼長時間沒來更新了。這不,我每天碼一點點,'滴水成河',努力完成了這篇文章。
1. 封裝和解構
1.1 封裝
說明: 等號(=)右邊有多個數值僅通過逗號分割,就會封裝到一個元組,稱為封裝packing。
# 示例:
x = 1,
y = 1,2
print(type(x), x)
print(type(y), y)
# 輸出結果如下:
<class 'tuple'> (1,)
<class 'tuple'> (1, 2)
備註: 如果右邊只有一個數值且沒有用逗號,其實是一個整數類型,請留意。另外等號右邊一定先運行,再賦值給左邊。
1.2 解構
說明: 等號(=)右邊容器類型的元素與左邊通過逗號分割的變數要一 一對應,稱為解構unpacking。
x,y = (1,2) # [1,2] {1,2} {'a':1,'b':2}
print(x)
print(y)
# 輸出結果如下:
1
2
*備註:*右邊的容器可以是元組、列表、字典、集合等,必須是可迭代對象。
錯誤示範:
x,y = (1,2,3)
print(x)
print(y)
# 輸出結果如下:
ValueError: too many values to unpack (expected 2)
*說明:*左、右兩邊個數一定要一致,不然會拋出'ValueError'錯誤。
剩餘變數解構
*說明:*python3引入了剩餘變數解構(rest),'儘可能'收集剩下的數據組成一個列表。
x, *rest = [1,2,3,4,5,6]
print(type(x), x)
print(type(rest), rest) # 剩餘沒有賦值的就是rest的了
# 輸出結果如下:
<class 'int'> 1
<class 'list'> [2, 3, 4, 5, 6]
*rest, y = [1,2,3,4,5,6]
print(type(rest), rest)
print(type(y), y)
# 輸出結果如下:
<class 'list'> [1, 2, 3, 4, 5]
<class 'int'> 6
錯誤示例:
不能單獨使用
*說明:*等號左邊只有一個標識符,無法解構。
*rest = [1,2,3,4,5,6] print(rest) # 輸出結果如下: #語法錯誤 SyntaxError: starred assignment target must be in a list or tuple不能多次同時使用
x, *rest1, *rest2, y = [1,2,3,4,5,6] print(rest1) print(rest2) # 輸出結果如下: #語法錯誤,其中一個rest就把剩餘元素拿走了,另外一個rest怎麼拿? SyntaxError: two starred expressions in assignment
另外一種丟棄變數下劃線:'_'
說明: '_'是合法的標識符,大多場景表示不關心該值。
x, *_, y = [1,2,3,4,5,6]
print(x)
print(_)
print(y)
# 輸出結果如下:
1
[2, 3, 4, 5]
6
_, *rest, _ = [1,2,3,4,5,6]
print(_) # '_'是上一次輸出值
print(rest)
# 輸出結果如下:
6
[2, 3, 4, 5]
2. 集合Set
*說明:*集合是'可變的、無序的、不重覆'的元素集合。
成為集合元素是有條件的:'元素必須可hash、可迭代'
可哈希對象如下(不可變):
- 數值型:int(整數)、float(浮點)、complex(複數)
- 布爾型:True(是)、False(否)
- 字元串:string(字元串)、bytes(位元組)
- tuple(元組)
- None(空)
可以通過內置hash函數判斷是否可hash:
s1 = [1,2,3]
print(hash(s1))
# 輸出結果如下:
TypeError: unhashable type: 'list' # 列表是不可hash的
2.1 初始化
說明:
- set() → new empty set object,新的空集合
- set(iterable) → new set object,元素必須可迭代
s = {} # 註意這個是空字典,不是空集合
s1 = set() # 空集合
s2 = set([1,2,3]) # 註意列表裡面元素迭代出來的是整數,可hash
s3 = set("abcd")
print(s1)
print(s2)
print(s3)
# 輸出結果如下:
set()
{1, 2, 3}
{'c', 'd', 'a', 'b'}
錯誤示例:
s = set([[1]]) # 列表套列表,迭代出來是列表,不可hash
print(s)
# 輸出結果如下:
TypeError: unhashable type: 'list'
2.2 增加
s.add(element)
*說明:*增加一個元素到集合,如果元素已經存在,則不操作。
s1 = set([1,2,3])
s1.add(4)
print(s1)
# 輸出結果如下:
{1, 2, 3, 4}
s.update(*element))
*說明:*合併一個或多個元素到集合中,元素必須可迭代(把迭代的元素併到集合),和後面講的並集一樣。
s1 = set([1,2,3])
s1.update((4,5,6),[7,8,9])
print(s1)
# 輸出結果如下:
{1, 2, 3, 4, 5, 6, 7, 8, 9}
2.3 刪除
remove(element)
*說明:*從集合中移除一個元素,如果元素不存在拋出'KeyError'錯誤。
s1 = {1,2,3,4,5,6} s1.remove(6) print(s1) # 輸出結果如下: {1, 2, 3, 4, 5}discard(element)
*說明:*也是從集合中移除一個元素,如果元素不存在不會報異常,啥都不做。
s1 = {1,2,3,4,5,6} s1.discard(6) print(s1) # 輸出結果如下: {1, 2, 3, 4, 5}pop()
*說明:*因為集合是無序的,所以是刪除'任意'一個元素,如果是空集則拋出'KeyError'錯誤。
s1 = {1,2,3,4,5,6} print(s1.pop()) # 隨機的(因為無序) print(s1) # 輸出結果如下: 1 {2, 3, 4, 5, 6}clear()
*說明:*刪除所有元素,都不推薦使用的啦。
s1 = {1,2,3,4,5,6} s1.clear() print(s1) # 輸出結果如下: set()
2.4 遍歷
*說明:*集合是個容器,是可以遍歷的,但是效率都是O(n)。
s1 = {1,2,3}
for s in s1:
print(s)
# 輸出結果如下:
1
2
3
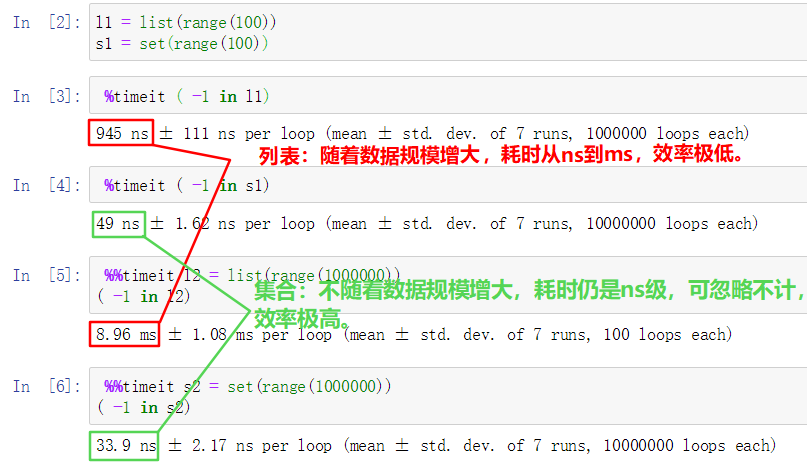
說到這裡,你覺得集合set和列表list哪個遍歷效率更高呢?
答案是set,因為set的元素是hash值作為key(下麵講的字典也是hash值),查詢時間複雜度為O(1),而list是線性數據結構,時間複雜度是O(n)。
大家可以按照如下進行驗證下,隨著數據規模越來越大,很明顯就可以看出哪個效率高。
2.5 並集&交集&差集&對稱差集
並集
說明: 將多個集合的所有元素合併在一起組成新的集合。
s1 = {1,2,3} s2 = {3,4,5} print(s1.union(s2)) # 輸出結果如下: {1, 2, 3, 4, 5}備註:還可以使用運算符 '|'、'update(element)'、'|='。
交集
說明: 取多個集合的共同(相交)元素
s1 = {1,2,3} s2 = {3,4,5} print(s1.intersection(s2)) # 輸出結果如下: {3}備註:還可以使用'&'、's.intersection_update(element)'、'&='。
差集
*說明:*屬於一個集合但不屬於另一個集合的元素組成的集合。
s1 = {1,2,3} s2 = {3,4,5} print(s1.difference(s2)) # 輸出結果如下: {1, 2}備註:還可以使用'-'、's.difference_update(element)'、'-='.
對稱差集
*說明:*多個集合中,不屬於交集元素組成的集合。
s1 = {1,2,3} s2 = {3,4,5} print(s1.symmetric_difference(s2)) # 輸出結果如下: {1, 2, 4, 5}備註:還可以使用''、's1.symmetric_difference_update(s2)'、'='.
3.字典
*說明:*字典是由任意個item(元素)組成的集合,item是由key:value對組成的二元組。
- 字典是'可變的':支持增刪改查;
- 字典是'無序的':key存儲是無序的,非線性數據結構(請不要讓錶面矇蔽了你哈);
- 字典是'key不重覆':key是唯一的,且必須可'hash';
3.1 初始化
# 空字典
d1 = {}
d2 = dict()
# 示例:
d3 = dict(a=1,b=2,c=3)
d4 = dict(d3)
d5 = dict([('a',1),('b',2),('c',3)]) # 元素必須是可迭代的
d6 = {'a':1,'b':2,'c':3}
# 輸出結果都是:
{'a': 1, 'b': 2, 'c': 3}
3.2 增刪改查
增加&修改元素
1)通過'd[key] = value'方式:
備註:如果key不存在,則新增,key存在則直接覆蓋(修改元素)。
# 增加 & 修改 d = {'a':1,'b':2,'c':3} d['d'] = 4 # 增加 d['a'] = 11 # 修改 print(d) # 輸出結果如下: {'a': 11, 'b': 2, 'c': 3, 'd': 4}2)通過d.update([E, ]**F) → None
# 增加 & 修改 d = {'a':1,'b':2,'c':3} d.update(d=4) print(d) # 輸出結果如下: {'a': 1, 'b': 2, 'c': 3, 'd': 4}刪除元素
1)d.pop()
- key存在則移除,並返回對應value值。
- key不存在,返回給定的預設值,否則拋出KeyError。
d = {'a':1,'b':2,'c':3} print(d.pop('c',None)) print(d) # 輸出結果如下: 3 {'a': 1, 'b': 2}2)d.popitem()
- 刪除並返回一個任意的item(key:value)。
- 如果是空字典,拋出KeyError。
d = {'a':1,'b':2,'c':3} print(d.popitem()) print(d) # 輸出結果如下: ('c', 3) {'a': 1, 'b': 2}3)d.clear()
- 刪除所有item,不推薦使用。
d = {'a':1,'b':2,'c':3} d.clear() print(d)查找元素
- 通過key這個鍵就可以快速找到value值。
- 時間複雜度是O(1),不會隨著數據規模大而降低效率。
正常訪問元素:
d = {'a':1,'b':2,'c':3} print(d['a']) print(d.get('b')) # 輸出結果如下: 1 2key不存在的處理方式:
d = {'a':1,'b':2,'c':3} print(d.get('d',None)) # 如果key不存在,預設返回None print(d.setdefault('d',100)) # 如果key不存在,則新增key:value對 print(d) # 輸出結果如下: None 100 {'a': 1, 'b': 2, 'c': 3, 'd': 100}
3.3 遍歷
遍歷鍵:key
d = {'a':1,'b':2,'c':3} # 方法1: for k in d: # 預設是遍歷key print(k) # 方法2: for k in d.keys(): print(k) # 方法3: for k, _ in d.items(): print(k) # 輸出結果如下: a b c遍歷值:value
d = {'a':1,'b':2,'c':3} # 方法1: for v in d.values(): print(v) # 方法2: for k in d: # print(d[k]) # 也可以用 print(d.get(k)) # 方法3: for _, v in d.items(): print(v) # 輸出結果如下: 1 2 3遍歷item:key-value
d = {'a':1,'b':2,'c':3} for item in d.items(): print(item) # 輸出結果如下: ('a', 1) ('b', 2) ('c', 3)其他問題
這種情況在遍歷的時候,不能夠刪除元素,不能改變字典的size。
d = {'a':1,'b':2,'c':3} for k in d: print(d.pop(k)) # 輸出結果如下: RuntimeError: dictionary changed size during iteration優雅的刪除方式:
d = {'a':1,'b':2,'c':3} key_list = [] for k in d: key_list.append(k) for k in key_list: print('已刪除key:', d.pop(k))然並卵,想要清除,直接用clear()啦。
4.解析式和生成器表達式
4.1 列表解析式
語法
- [ 返回值 for 元素 in 可迭代對象 if 條件 ]
- 列表解析式用中括弧''表示
- 返回一個新的列表
優點
- 提高效率
- 代碼輕量
- 可讀性高
示例需求:請從給定區間中提取能夠被2整除的元素。
大眾普遍的寫法:
list = []
for i in range(10):
if i % 2 == 0:
list.append(i)
print(list)
# 輸出結果如下:
[0, 2, 4, 6, 8]
再來感受一下簡單而優雅的寫法:
print([i for i in range(10) if i % 2 == 0])
# 輸出結果如下:
[0, 2, 4, 6, 8]
以上就是列表解析式,也叫列表推倒式。
4.2 生成器表達式
語法
- ( 返回值 for 元素 in 可迭代對象 if 條件 )
- 生成器表達式用中括弧'( )'表示
- 返回一個生成器對象(generator)
特點:
- 按需計算,就是需要取值的時候才去計算(而列表解析式是一次性計算立即返回所有結果)
- 前期並不怎麼占用記憶體,最後取值多了就跟列表解析式一樣;
- 計算耗時極短,本身並不返回結果,返回的是生成器對象;
看下生成器對象是長什麼樣的(不要認為是元組解析式,哈哈):
x = (i for i in range(10) if i % 2 == 0)
print(type(x))
print(x)
# 輸出結果如下:
<class 'generator'> # 生成器
<generator object <genexpr> at 0x000001A143ACBA98> # 生成器對象
那生成器對象是如何計算得到結果:
import time
x = (i for i in range(10) if i % 2 == 0)
for i in range(6): # 僅一次迴圈取值
time.sleep(0.5)
print(next(x))
time.sleep(1)
print(next(x)) # for迴圈已經計算完所有結果了,不能取值,故拋出異常
# 輸出結果如下:
0
2
4
6
8
StopIteration # 已經超出可迭代範圍,拋出異常
備註:生成器表達式只能迭代一次。
4.3 集合解析式
集合解析式和列表解析式語法類似,不做過多解析。
語法:
- { 返回值 for 元素 in 可迭代對象 if 條件 }
- 集合解析式用花括弧''表示
- 返回一個集合
示例:
print({i for i in range(10) if i % 2 == 0})
# 輸出結果如下:
{0, 2, 4, 6, 8}
4.4 字典解析式
字典解析式和集合解析式語法類似,不做過多解析。
語法:
- { key:value for 元素 in 可迭代對象 if 條件 }
- 字典解析式用花括弧''表示
- 返回一個字典
示例:
print({i:(i+1) for i in range(10) if i % 2 == 0})
# 輸出結果如下:
{0: 1, 2: 3, 4: 5, 6: 7, 8: 9}
總體來說,解析式寫起來如果讓人簡單易懂、又高效,是非常推薦大家使用的。
但有的場景寫起來很複雜,那還是得用for...in迴圈拆分來寫。
如果喜歡的我的文章,歡迎關註我的公眾號:點滴技術,掃碼關註,不定期分享



