
垃圾回收演算法和垃圾收集器 1.什麼是垃圾回收 對於記憶體當中無用的對象進行回收,如何去判斷一個對象是不是無用的對象。 引用計數法: 每個對象中都會存儲一個引用計數,每增加一個引用就+1,消失一個引用就 1。當引用計數器為0時就會判斷該對象是垃圾,進行回收。 但是這樣會有一個弊端。就是當有兩個對象互相引 ...
垃圾回收演算法和垃圾收集器
1.什麼是垃圾回收
對於記憶體當中無用的對象進行回收,如何去判斷一個對象是不是無用的對象。
引用計數法:
每個對象中都會存儲一個引用計數,每增加一個引用就+1,消失一個引用就-1。當引用計數器為0時就會判斷該對象是垃圾,進行回收。
但是這樣會有一個弊端。就是當有兩個對象互相引用時,那麼這兩個對象的引用計數器都不為0,那麼就不會對其進行回收。
可達性分析:
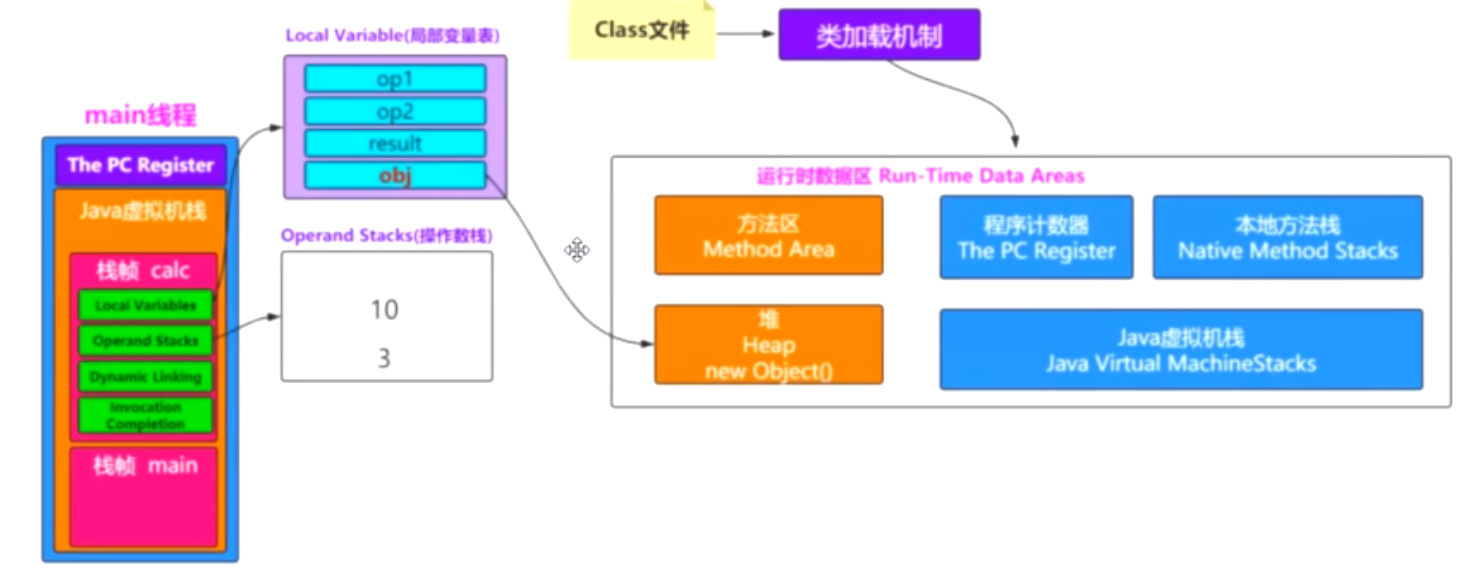
判斷某個對象是否可到達。有兩種方式判斷是否可到達:
-
直接引用(上帝視角GC Roots):就是虛擬機棧幀中的局部或本地變數表、類載入器、static成員、常量引用、Thread等等中的引用直接到達。
為什麼本地或局部變數表裡面的變數有它出發就可以用來判斷GC Roots的判斷標準呢?
因為只用它表示這個棧幀正在被壓棧,正在被使用,這個時候再去回收這個對象不是瘋了嘛!!!同理static、常量也是一樣的道理。
-
間接引用:通過別人的引用來達到。
併發的可達性分析(併發標記、浮動垃圾):https://mp.weixin.qq.com/s/EgVPlOLArsWb86Kujykn3A
2.垃圾回收的策略
垃圾收集演算法
-
標記-清除
先標記

後清除
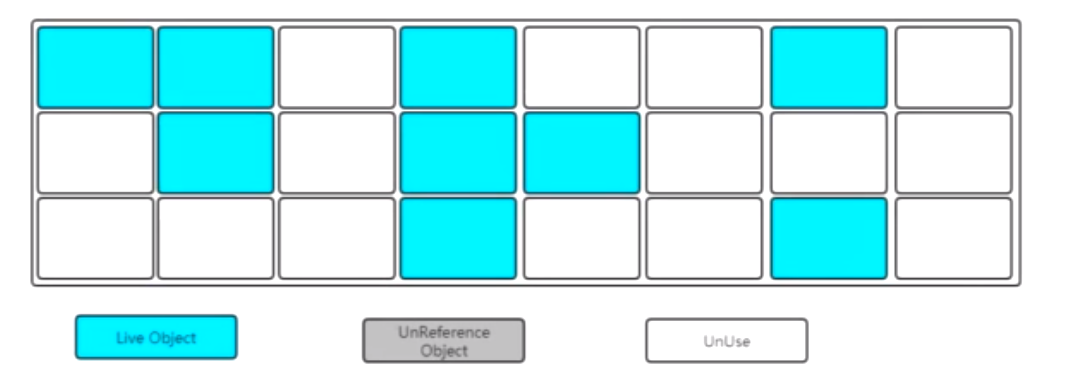
弊端一:會有空間碎片問題,空間不連續;這時如果有大一點的對象進來,發現沒有連續的空間記憶體去進行分配,就會再一次的觸發垃圾回收機制。
弊端二:在標記和清除的過程中、會掃描整個堆記憶體;會比較耗時。
有點:簡單、明瞭、好操作。
-
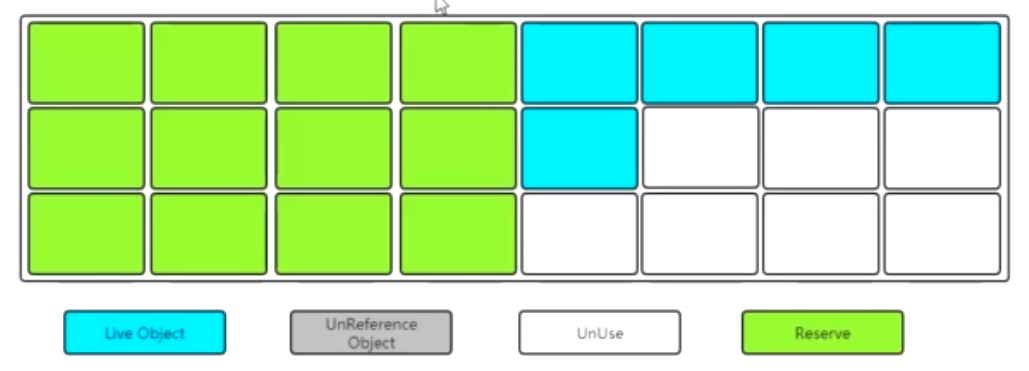
標記-複製
一開始將這個記憶體空間一分為二,兩邊大小相等,一邊使用中的,一邊是保留區未使用的。劃分為這樣示例圖:

在標記和清除之後,將存活的對象複製到另外一邊,在將先前的一邊數據全部清除掉。
之後以此反覆、兩個迴圈往返。
類似於堆記憶體中的新生代(Young)區中的Survivor區中的S0、S1,所以堆記憶體中的新生代(Young)區一定用的就是複製演算法。
-
標記-整理
先標記
後整理。
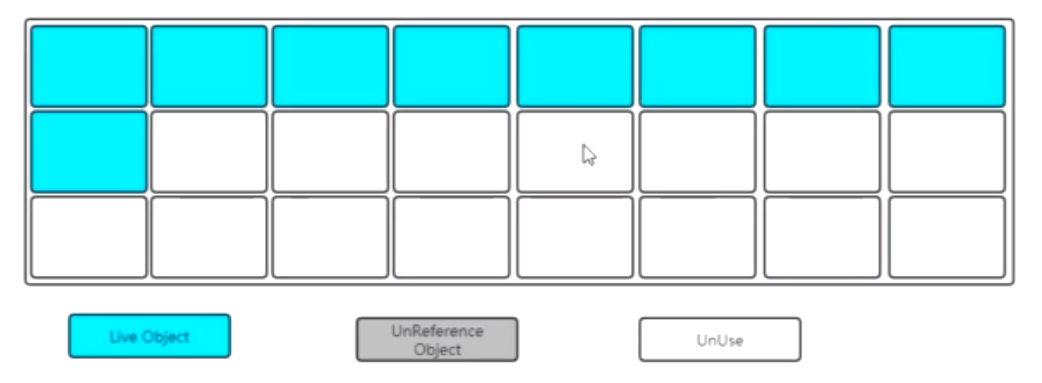
整理移動之後會得到一片連續的可分配記憶體空間。解決了空間碎片的問題,但是這種方式在標記和整理移動的過程中也是耗時的。
垃圾收集器:評判一個垃圾收集好壞和調優關註的是【高吞吐量、少停頓時間、少垃圾回收次數】
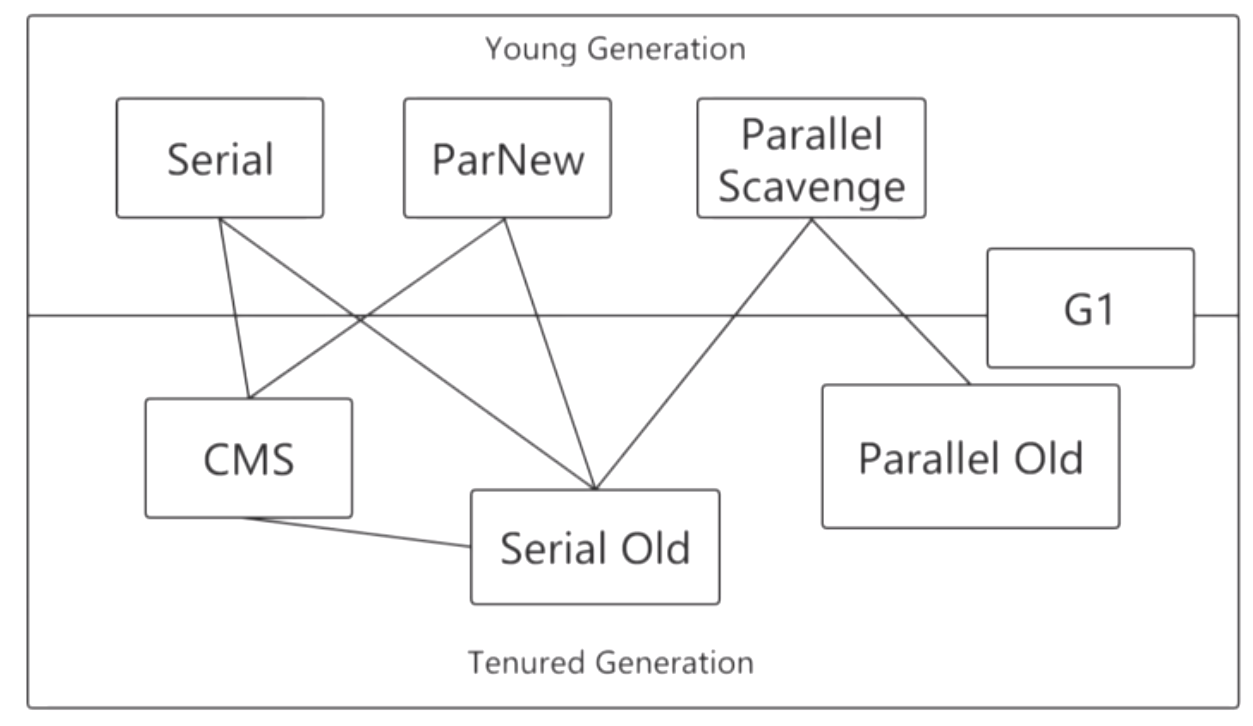
串列:Serial系列;
並行【吞吐量優先】:Paraller系列;
吞吐量:用戶代碼執行的時間 / (用戶代碼執行的時間+垃圾收集時間)99/(99+1)=99%。
適用於後臺運算,不需要太多的交互場景。
併發【停頓時間優先】:CMS、G1;
適用於用戶交互較多的場景,給用戶更好的體驗感;如Web應用。
JVM垃圾收集器調優的原則:儘可能在停頓時間較低的情況下,追求高的吞吐量和少的垃圾回收次數。
官方JVM垃圾收集器建議:
- 使用預設垃圾收集器
- 調整JVM堆的大小
-
- 如果應用程式記憶體空間比較小(比如100MB),直接選擇SerialGC串列收集器。-XX:+UseSerialGC
- 如果應用程式運行在一個單核的CPU,和沒有停頓時間要求的情況下;可以讓JVM自己去選擇或者選擇SerialGC串列收集器。-XX:+UseSerialGC
- 如果應用程式更加關註的吞吐量也沒有停頓時間要求的情況下,可以讓JVM自己去選擇或者選擇並行的ParallelGC。-XX+UseParallelGC
- 如果應用程式對停頓時間要求比較高(比如小於1秒鐘的時間),那麼就選擇CMS或者G1的收集器。-XX:+UseConcMarkSweepGC 或 -XX:+UseG1GC
G1(Garbage-First):JDK7出現,JDK8推薦使用,JDK9預設垃圾收集器。
G1的整個垃圾收集並清理的過程階段大體上和CMS收集器是不變的。在最後一個階段進行刪選回收(選擇性的回收,進行優先順序的回收:優先回收區域(Region)記憶體活對象較少的)。
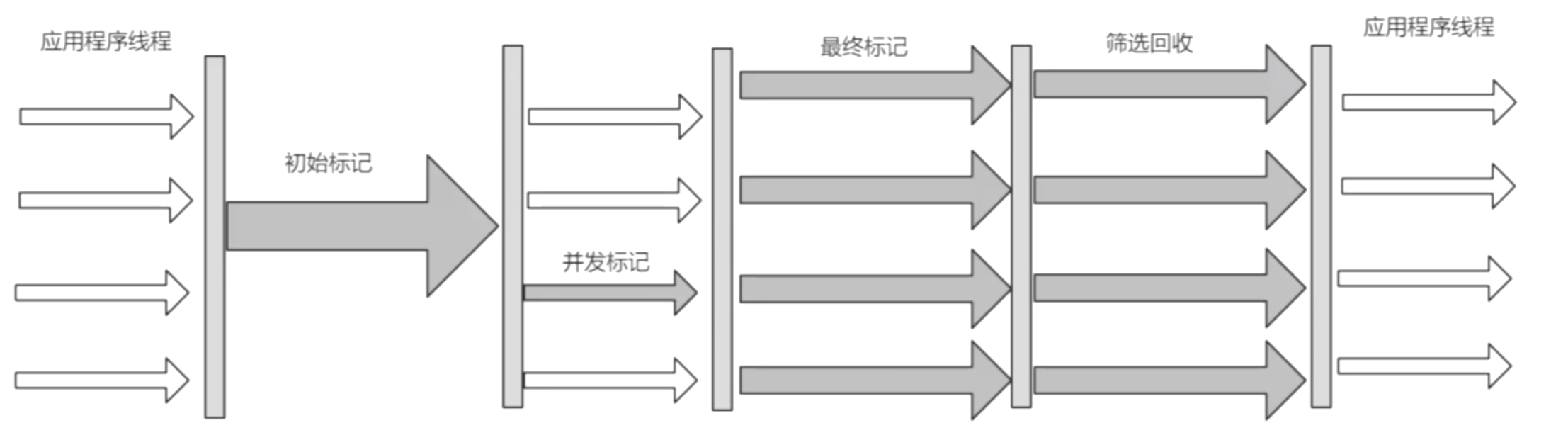
重新設計記憶體空間如圖所示:

整個記憶體劃分為一個個大小相等的區域(Region)。邏輯上對這些區域(Region)進行標記,這些標記有Eden區,Survivor區和Old區。這時的物理空間上就不在是連續空間了;之前的空間劃分都是連續的空間。假如回收掉某個Old區的數據,這時這個區域也可能會標位Survivor區或者Eden區。
區域(Region)內還有一個記錄rememberd Set。以前會全盤掃描堆記憶體,是比較耗時的。這時會記錄一個對象存活的地方,對象的引用指向;這樣就不用在全盤掃描了耗時比較低。
官方文檔(G1垃圾收集器的前世今生):https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
Young Generation(新生代)- 垃圾收集演算法一定是標記-複製演算法的實現
Serial:JDK1.3出現的,單線程收集,STW。那時候的CPU還是單核CPU。單線程處理效率比較高,在進行垃圾回收的時候,會暫停業務線程,等待垃圾回收完成之後,在讓業務線程再繼續執行。會搭配老年代的SerialOld配合使用。
這時會出現Stop The World(STW)

ParNew:並行垃圾收集器多個垃圾線程一起跑,STW ,停頓時間較多,更加關註吞吐量
複製演算法、並行多線程垃圾收集器,解決了單線程的局限性,但是還是Stop The World(STW)。
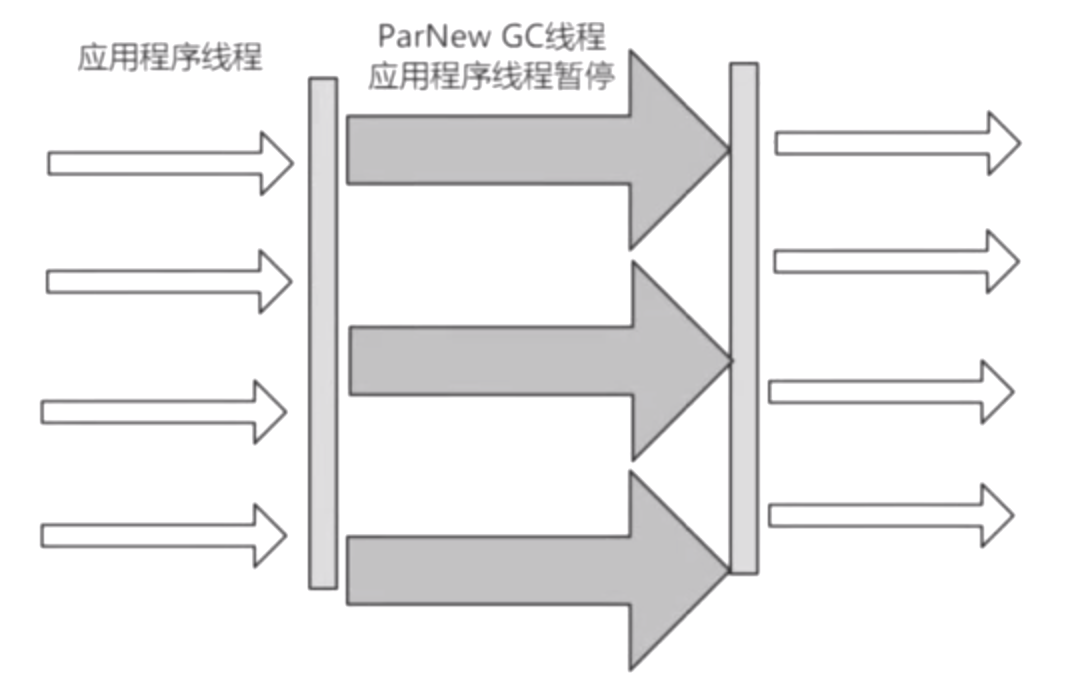
ParallelScavenge
同上
Tenured Generation(老年代)- 這裡是標記-清除、或標記-整理的演算法實現
CMS:JDK5出現的,併發收集,兩個階段會STW(初始標記、重新標記),更加關註停頓時間。在JDK8中已經不推薦使用,JDK8推薦使用G1收集器。
併發:垃圾收集線程和業務代碼線程一起跑。但是並不能做到全程一起執行。
因為垃圾收集線程在執行的時候對垃圾進行標記,這時業務代碼線程也在執行,也會產生新的垃圾。至少在垃圾收集線程在進行標記的階段,業務代碼暫定的是不執行的。
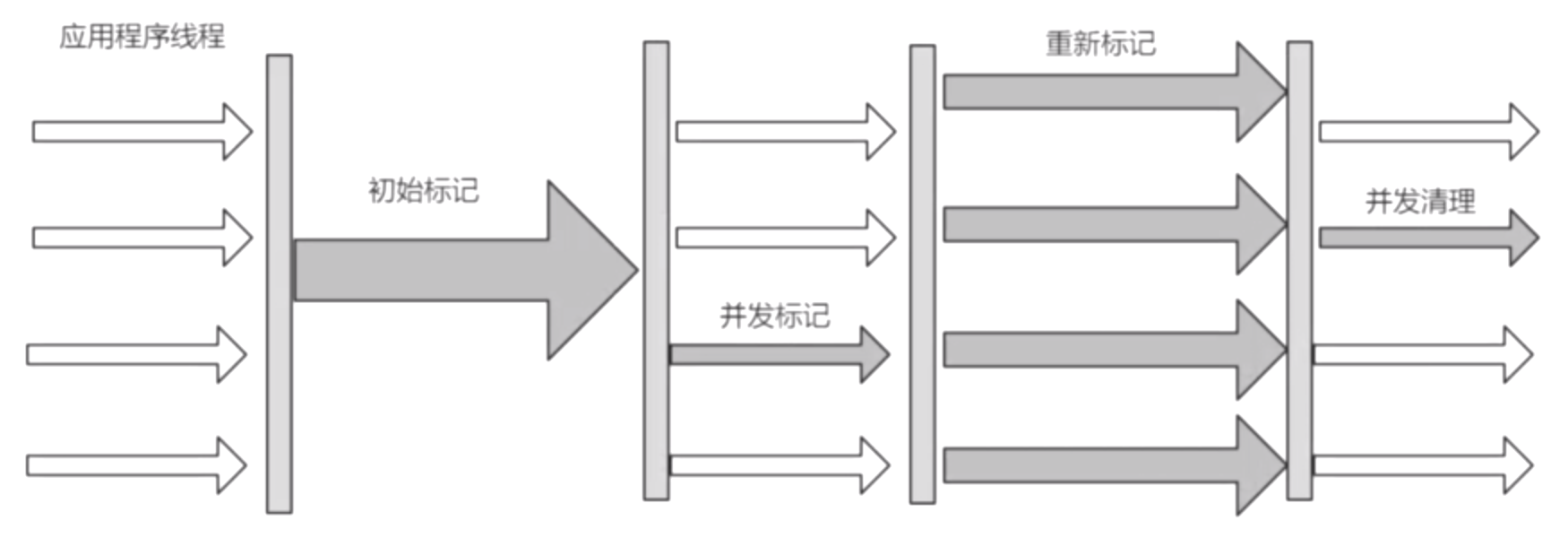
劃分為四個階段:初始標記、併發標記、重新標記、併發清理。
初始標記:第一階段會Stop The World(STW)。這個階段執行的時間是非常快的,如果開啟多個線程,會消耗線程之前的切換反而會增加時間成本。
併發標記:第二階段就是可達性分析,對第一階段的垃圾進行跟蹤。在這個階段垃圾線程和業務線程是一起執行的;為啥可以一起執行呢?因為在第一階段初始標記完成後大局已定,第二階段的併發標記只是做增量的更新。如果此時又產生了垃圾那麼就是浮動垃圾(把原本消亡的對象錯誤的標記為存活狀態),只能等待下次清理。
重新標記:第三階段這時會停止業務代碼的線程Stop The World(STW),會多線程垃圾收集器並行一起跑,一起執行。
併發清理:第四階段垃圾收集線程和業務代碼線程再次一起執行,一起跑。
特點:併發收集,停頓時間較少。
缺點:會產生浮動垃圾。其次由於採用的是標記-清除這樣的演算法會產生大量的空間碎片。
Serial Old:串列的

Paraller Old:並行的
如何查看當前JAVA程式應用使用的是什麼垃圾收集器:
# 查看進程ID
jps -l
8720 org.jetbrains.jps.cmdline.Launcher
10212 org.jetbrains.idea.maven.server.RemoteMavenServer36
3764
15480 sun.tools.jps.Jps
4216 com.hopefun.scm.WebApplication
# 查看當前進程下是否使用UseParallelGC
jinfo -flag UseParallelGC 4216
-XX:+UseParallelGC

