String源碼分析 類結構 String類實現了Serializable可以被序列化 String類實現了Comparable可以進行比較 String類實現了CharSequence可以按下標進行相關操作 並且String類使用final進行修飾,不可以被繼承 屬性 構造方法 方法 靜態方法 j ...
String源碼分析
類結構
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence

String類實現了Serializable可以被序列化
String類實現了Comparable可以進行比較
String類實現了CharSequence可以按下標進行相關操作
並且String類使用final進行修飾,不可以被繼承
屬性
//用來存儲字元串的每一個字元
private final char value[];
//hash值
private int hash; // Default to 0
//序列化版本號
private static final long serialVersionUID = -6849794470754667710L;
//從變數名大致可以看出和序列化有關,具體的不明白
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
構造方法
//無參,直接使用空字元串賦值,hash為0
public String() {
this.value = "".value;
}
//使用已有字元串初始化
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//使用char數組初始化,hash為0
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
//使用字元數組,並指定偏移、字元個數初始化
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
//使用unicode編碼數組並指定偏移和數量進行初始化
public String(int[] codePoints, int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= codePoints.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
final int end = offset + count;
// Pass 1: Compute precise size of char[] 計算char數組大小
int n = count;
for (int i = offset; i < end; i++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))//判斷編碼是不是BMP(Basic Mutilingual Plane)
continue;
else if (Character.isValidCodePoint(c))//驗證編碼是否在unicode編碼範圍內
n++;
else throw new IllegalArgumentException(Integer.toString(c));
}
// Pass 2: Allocate and fill in char[] 申明char數組並填入編碼對應char
final char[] v = new char[n];
for (int i = offset, j = 0; i < end; i++, j++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))//如果編碼是BMP直接一個字元就是接受
v[j] = (char)c;
else
Character.toSurrogates(c, v, j++);//轉換成兩個字元存儲
}
this.value = v;
}
//使用ascii碼數組進行初始化
@Deprecated
public String(byte ascii[], int hibyte, int offset, int count) {
checkBounds(ascii, offset, count);
char value[] = new char[count];
if (hibyte == 0) {
for (int i = count; i-- > 0;) {
value[i] = (char)(ascii[i + offset] & 0xff);
}
} else {
hibyte <<= 8;
for (int i = count; i-- > 0;) {
value[i] = (char)(hibyte | (ascii[i + offset] & 0xff));
}
}
this.value = value;
}
@Deprecated
public String(byte ascii[], int hibyte) {
this(ascii, hibyte, 0, ascii.length);
}
//使用位元組數組+字元集名初始化
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
//使用位元組數組+字元集名初始化
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
}
//使用位元組數組+字元集名初始化
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
//使用位元組數組+字元集名初始化
public String(byte bytes[], Charset charset) {
this(bytes, 0, bytes.length, charset);
}
//使用位元組數組初始化
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
public String(byte bytes[]) {
this(bytes, 0, bytes.length);
}
//使用StringBuffer初始化
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
//使用StringBuilder初始化
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
方法
靜態方法
join(CharSequence,CharSequence...)使用分隔符拼接字元串
public static String join(CharSequence delimiter, CharSequence... elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
// Number of elements not likely worth Arrays.stream overhead.
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
join(CharSequence,Iterable<? extends CharSequence>)使用分隔符拼接字元串
public static String join(CharSequence delimiter,
Iterable<? extends CharSequence> elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
format(String,Object...)使用字元串格式指定參數進行格式化生成字元串
public static String format(String format, Object... args) {
return new Formatter().format(format, args).toString();
}
format(Local,String,Object...)根據環境使用字元串格式指定參數進行格式化生成字元串
public static String format(Locale l, String format, Object... args) {
return new Formatter(l).format(format, args).toString();
}
valueOf(Object)對象轉換成字元串,如果對象為null轉為為字元串“null”
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
valueOf(char[])char數組轉換成字元串
public static String valueOf(char data[]) {
return new String(data);
}
valueOf(xxx)xxx數據類型轉換為字元串
public static String valueOf(boolean b) {
return b ? "true" : "false";
}
public static String valueOf(char c) {
char data[] = {c};
return new String(data, true);
}
public static String valueOf(int i) {
return Integer.toString(i);
}
public static String valueOf(long l) {
return Long.toString(l);
}
public static String valueOf(float f) {
return Float.toString(f);
}
public static String valueOf(double d) {
return Double.toString(d);
}
valueOf(char[],int,int)char數組按照偏移個指定字元格式轉換為字元串
public static String valueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
copyValueOf(char,int,int)使用指定字元數組根據偏移和字元個數拷貝一個新字元串,同valueOf
public static String copyValueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
copyValueOf(char[])使用指定字元數組拷貝新字元串
public static String copyValueOf(char data[]) {
return new String(data);
}
成員方法
char charAt(int index)獲取指定下標的字元
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin)把當前字元串的char數組的指定範圍拷貝到目標char數組的指定位置
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
if (srcBegin < 0) {
throw new StringIndexOutOfBoundsException(srcBegin);
}
if (srcEnd > value.length) {
throw new StringIndexOutOfBoundsException(srcEnd);
}
if (srcBegin > srcEnd) {
throw new StringIndexOutOfBoundsException(srcEnd - srcBegin);
}
//System.arraycopy(Object src, int srcPos,Object dest, int destPos,int length)
//src:要拷貝的源數組
//srcPos:源數組拷貝的起始位置
//dest:目標數組
//destPost:拷貝到目標數組的起始位置
//length:要拷貝元素的個數
System.arraycopy(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
byte[] getBytes(String charsetName)根據字元集獲取字元串的編碼後的位元組數組
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
boolean equals(Object anObject)方法比較兩個字元串,重寫的Object方法
public boolean equals(Object anObject) {
if (this == anObject) {//地址相等兩對象equals為true
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {//判斷兩字元串的字元個數
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])//有一個字元不相等最直接為false
return false;
i++;
}
return true;
}
}
return false;
}
contentEquals(CharSequence cs)判斷當前String與其他字元序列是否相等,與equals不同的是,equals只有當兩個對象都是String時equals才為true,contentEquals可以用來同其他StringBuffer、StringBuilder和其他字元序列進行比較
public boolean contentEquals(CharSequence cs) {
// Argument is a StringBuffer, StringBuilder
if (cs instanceof AbstractStringBuilder) {
if (cs instanceof StringBuffer) {
synchronized(cs) {//如果是StringBuffer那麼進行上鎖操作
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
} else {//StringBuilder不上鎖
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
}
// Argument is a String
if (cs instanceof String) {
return equals(cs);
}
// Argument is a generic CharSequence
char v1[] = value;
int n = v1.length;
if (n != cs.length()) {
return false;
}
for (int i = 0; i < n; i++) {//其他字元序列,一個一個字元進行比較
if (v1[i] != cs.charAt(i)) {
return false;
}
}
return true;
}
equalsIgnoreCase(String anotherString)兩個字元串忽略大小寫進行比較是否相等
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)//不為空
&& (anotherString.value.length == value.length)//字元個數相等
&& regionMatches(true, 0, anotherString, 0, value.length);//忽略大小寫比較
}
public boolean regionMatches(boolean ignoreCase, int toffset,
String other, int ooffset, int len) {
char ta[] = value;
int to = toffset;
char pa[] = other.value;
int po = ooffset;
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0)
|| (toffset > (long)value.length - len)
|| (ooffset > (long)other.value.length - len)) {
return false;
}
while (len-- > 0) {
char c1 = ta[to++];
char c2 = pa[po++];
if (c1 == c2) {
continue;
}
if (ignoreCase) {
// If characters don't match but case may be ignored,
// try converting both characters to uppercase.
// If the results match, then the comparison scan should
// continue.
//把兩個字元轉換成大寫的
char u1 = Character.toUpperCase(c1);
char u2 = Character.toUpperCase(c2);
if (u1 == u2) {
continue;
}
// Unfortunately, conversion to uppercase does not work properly
// for the Georgian alphabet, which has strange rules about case
// conversion. So we need to make one last check before
// exiting.
//轉換成大寫的不相等,在轉換成小寫的判斷
if (Character.toLowerCase(u1) == Character.toLowerCase(u2)) {
continue;
}
}
return false;
}
return true;
}
int compareTo(String anotherString)進行字元串的比較
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {//如果當前字元串的字元比參數的大返回正數,否則返回負數
return c1 - c2;
}
k++;
}
//如果兩個字元串,長度小的字元串與長度大的前部分每個字元都相等,如果兩字元串長度相等返回0,當前字元串長度大於參數字元串返回整數,當前字元串長度小於參數字元串返回負數
return len1 - len2;
}
compareToIgnoreCase(String str)字元串忽略大小寫進行比較
public int compareToIgnoreCase(String str) {
return CASE_INSENSITIVE_ORDER.compare(this, str);
}
public int compare(String s1, String s2) {
int n1 = s1.length();
int n2 = s2.length();
int min = Math.min(n1, n2);
for (int i = 0; i < min; i++) {
char c1 = s1.charAt(i);
char c2 = s2.charAt(i);
if (c1 != c2) {
c1 = Character.toUpperCase(c1);
c2 = Character.toUpperCase(c2);
if (c1 != c2) {
c1 = Character.toLowerCase(c1);
c2 = Character.toLowerCase(c2);
if (c1 != c2) {
//如果兩字元不相等,最後是轉換成小寫的進行比較
return c1 - c2;
}
}
}
}
return n1 - n2;
}
startsWith(String prefix)判斷字元串是否以指定字元串開頭
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
while (--pc >= 0) {//迴圈給定首碼字元串長度
if (ta[to++] != pa[po++]) {//首碼字元串字元和當前字元串字元比較
return false;
}
}
return true;
}
boolean endsWith(String suffix)判斷字元串是否以指定字元串結尾
public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
int hashCode()獲取字元串的hashCode
public int hashCode() {
//預設字元串hash為0,如果是用另一個字元串就等於另一個字元串的hash
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {//一個一個字元的變數
//前面字元的hash*31+當前字元的ascii碼
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
int indexOf(int ch)根據unicode編碼獲取下標
public int indexOf(int ch) {
return indexOf(ch, 0);
}
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {//如果查找的起始位置超過了數組下標
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
//編碼是一個基本多語言編碼
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
//獲取需要使用兩個char存儲的編碼的下標
return indexOfSupplementary(ch, fromIndex);
}
}
private int indexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {//是一個合法的unicode編碼
final char[] value = this.value;
final char hi = Character.highSurrogate(ch);
final char lo = Character.lowSurrogate(ch);
final int max = value.length - 1;
for (int i = fromIndex; i < max; i++) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
int lastIndexOf(int ch)獲取指定編碼從後往前搜索的第一個下標
public int lastIndexOf(int ch) {
return lastIndexOf(ch, value.length - 1);
}
public int lastIndexOf(int ch, int fromIndex) {
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {//編碼是一個基本多語言unicode編碼,使用一個char存儲
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
int i = Math.min(fromIndex, value.length - 1);
for (; i >= 0; i--) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
//編碼使用兩個char存儲
return lastIndexOfSupplementary(ch, fromIndex);
}
}
private int lastIndexOfSupplementary(int ch, int fromIndex) {
if (Character.isValidCodePoint(ch)) {
final char[] value = this.value;
char hi = Character.highSurrogate(ch);
char lo = Character.lowSurrogate(ch);
int i = Math.min(fromIndex, value.length - 2);
for (; i >= 0; i--) {
if (value[i] == hi && value[i + 1] == lo) {
return i;
}
}
}
return -1;
}
int indexOf(String str)獲取指定字元串的的第一個字元在當前字元串的下標
public int indexOf(String str) {
return indexOf(str, 0);
}
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
//計算終止下標
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
String substring(int beginIndex)獲取指定下標到最末下標的字元串
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
//計算長度
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
String substring(int beginIndex, int endIndex)根據起始下標和結束下標獲取字元串,包含起始下標字元,不包含結束下標字元
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
//計算字元個數
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
String concat(String str)把參數字元串拼接到當前字元串
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
//獲取拼接字元串的長度
int len = value.length;
//把原字元串的字元拷貝到一個大小為原字元串大小+參數字元串大小的新數組中
char buf[] = Arrays.copyOf(value, len + otherLen);
//把拼接字元串的字元拷貝到數組中
str.getChars(buf, len);
return new String(buf, true);
}
String replace(char oldChar, char newChar)把指定字元替換為新字元
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {//找到需要替換字元的位置
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;//把原字元替換為新字元
i++;
}
return new String(buf, true);
}
}
return this;
}
boolean matches(String regex)判斷正則表達式是否比配當前字元串
public boolean matches(String regex) {
return Pattern.matches(regex, this);
}
boolean contains(CharSequence s)判斷當前字元串是否包含另一個字元序列
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
String trim()去掉字元串前後的空格
public String trim() {
int len = value.length;
int st = 0;
char[] val = value; /* avoid getfield opcode */
//找到字元串由前往後第一個不是空格的位置
while ((st < len) && (val[st] <= ' ')) {
st++;
}
//找到字元串由後往前第一個不是空格的位置
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
char[] toCharArray()把字元串轉換成字元數組
public char[] toCharArray() {
// Cannot use Arrays.copyOf because of class initialization order issues
char result[] = new char[value.length];
//使用System.arraycopy方法拷貝
System.arraycopy(value, 0, result, 0, value.length);
return result;
}
本地方法
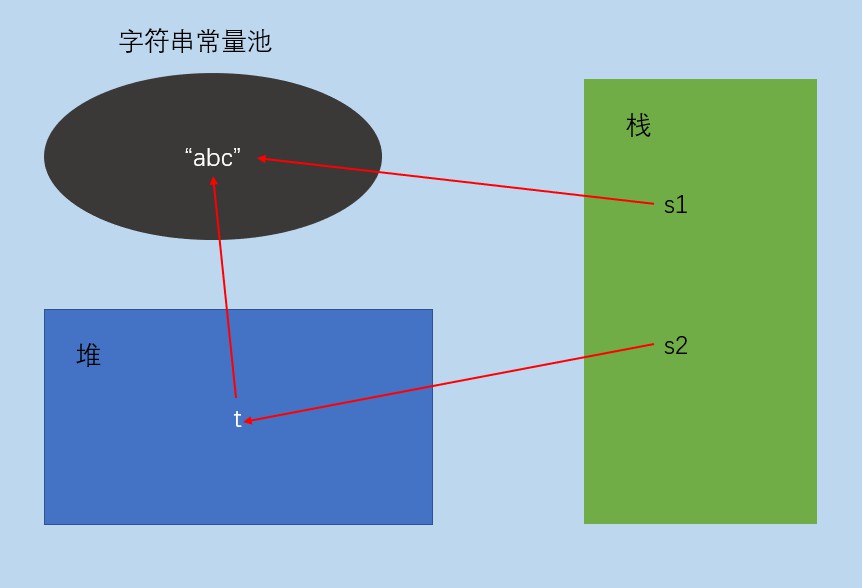
native String intern();獲取字元串所指向的字元串常量池中對象的地址
@Test
public void test8() {
String s1="abc";
String s2=new String("abc");
System.out.println(s1==s2);//false
System.out.println(s1==s2.intern());//true
}
使用s1="abc"這種方式棧中變數s1直接指向字元串常量池中的常量“abc”,而s2=new String("abc")這種方式,棧中變數s2指向的是對中一個變數t,t指向字元串常量池中的“abc”,所以s1和s2指向的地址不相同
s2.intern()獲取的是字元串的常量池中的地址,也就是如果變數直接指向常量池,那麼就是變數的地址,如果變數指向堆,那麼會獲取堆所指向字元串常量池中的地址