
對於varnish來講,對後端主機做健康狀態監測的原理是請求後端主機特定的資源,如果能夠在指定的超時時長內正確響應我們就認為後端主機上健康狀態的,如果不能正確的響應我們就認為該後端主機上不健康的;在varnish中對後端主機做健康狀態監測需要用.probe 來引入一段上下文配置,明確的說明怎麼對後... ...
前文我們聊了下varnish的緩存項修剪配置,回顧請參考https://www.cnblogs.com/qiuhom-1874/p/12666406.html;今天我來說一下varnish作為代理伺服器反向代理多主機的配置;前邊的所有操作都是針對後端主機只有一臺的情況來說varnish的配置;在生產環境中,我們的web站點伺服器不應該只有一臺;預設情況下才安裝好varnish的主機,在default.vcl中只可以指定一臺後端主機的地址和埠;如果我們後端主機是多台的情況下,我們需要載入varnish的模塊directors;然後用backend+後端主機名稱(這個名稱是我們自定義的,只要是一合法名稱即可),來分別把每個主機的地址和埠配置好即可;
示例:

提示:以上每個紅框中的內容表示一臺後端server;以上配置表示定義兩台後端主機,其名稱分別為webserver1和webserver2;
把主機定義好後,這裡還需要用在vcl_init狀態引擎中配置初始化一個組,然後把這兩台主機加到對應的組中;
示例:

提示:以上配置表示用directors模塊中的round_robin()方法初始化一個組對象,取名叫webserver;然後把對應兩台主機加入到這個初始化組對象中;這意味著這個組裡有兩個成員,一個是webserver1,一個是webserver2;directors.round_robin()用這個方法初始化組對象表示往後端調度的演算法是輪詢,即沒有權重;要想有權重,需要用directors.random()方法;如果需要做會話保持,需要用到directors.hash()方法;
示例:初始化組對象用randomf方法

提示:用random方法就在後面加權重;
示例:初始化組對象用hash方法來保持會話

提示:hash方法也是支持權重的;
到此我們就把兩台後端主機加入到webserver組中了;現在我們可以編譯載入我們的配置文件,然後用varnishadm工具連接到控制管理shell中查看後端主機列表;
[root@test_node1-centos7 ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082 200 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.10.0-693.el7.x86_64,x86_64,-sfile,-smalloc,-hcritbit varnish-4.0.5 revision 07eff4c29 Type 'help' for command list. Type 'quit' to close CLI session. varnish> vcl.list 200 active 0 boot varnish> vcl.load test default.vcl 200 VCL compiled. varnish> vcl.list 200 active 0 boot available 0 test varnish> vcl.use test 200 VCL 'test' now active varnish> backend.list 200 Backend name Refs Admin Probe webserver1(192.168.0.10,,80) 2 probe Healthy (no probe) webserver2(192.168.0.99,,80) 2 probe Healthy (no probe) varnish> quit 500 Closing CLI connection [root@test_node1-centos7 ~]#
提示:可以看到我們編寫的vcl把多台主機加入到webserver組的配置生效了;從上面的配置看,後端主機有兩台,一臺是webserver1,一臺是webserver2;
測試:用curl命令訪問192.168.0.99:8000 看看是否把用戶請求分別調度到後端個server上去了?
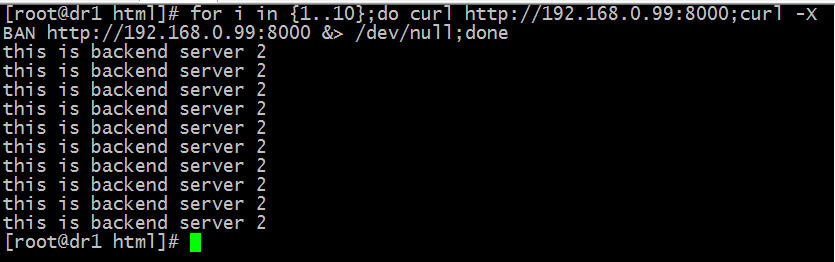
提示:從上面的結果看,好像沒有把用戶的請求調度到server1上去;原因是我們沒有配置說明把所有未命中緩存的請求發送到後端主機上去,它預設是把第一次匹配backend 關鍵字+名稱的配置當作預設主機;所以這裡我們怎麼訪問都調度到192.168.0.10這台主機上去;
示例:在vcl_recv中調用我們之前定義的組,明確說明把未命中緩存的請求發送到該組上;
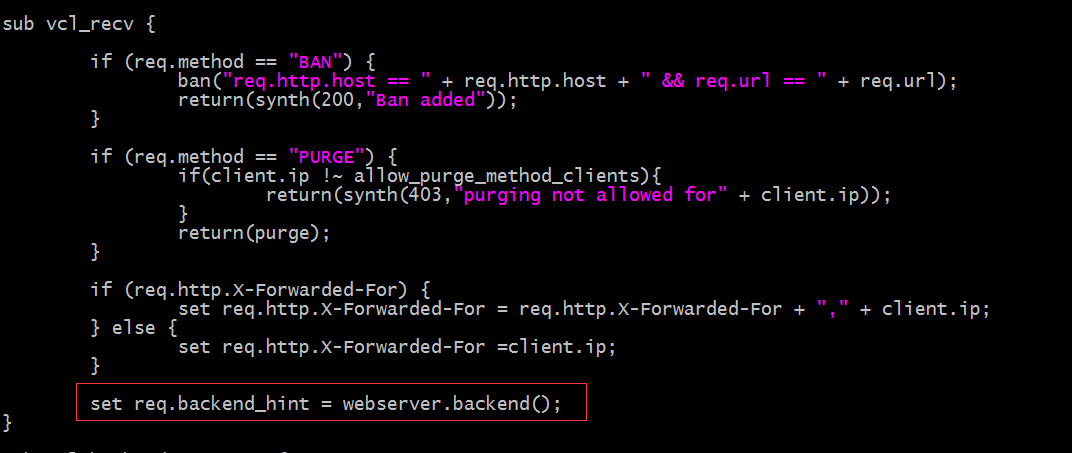
提示:以上紅框中的內容表示把用戶請求發送到我們定義好的組上的主機;
測試:
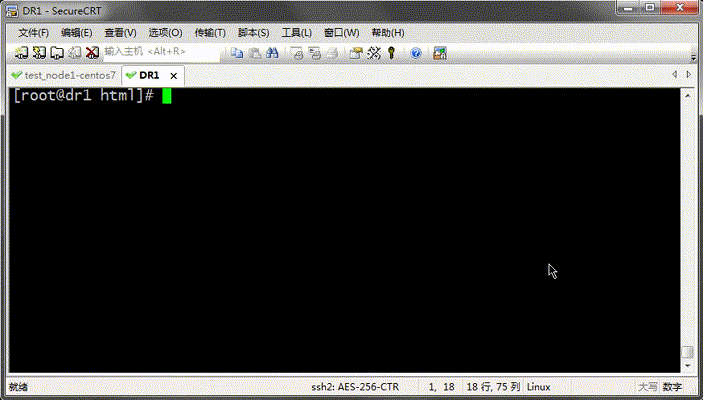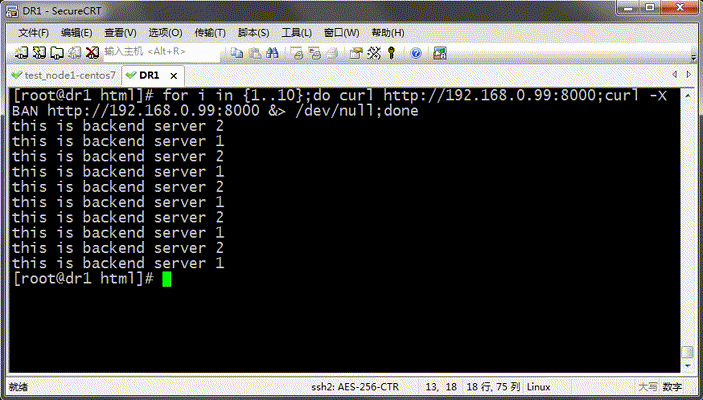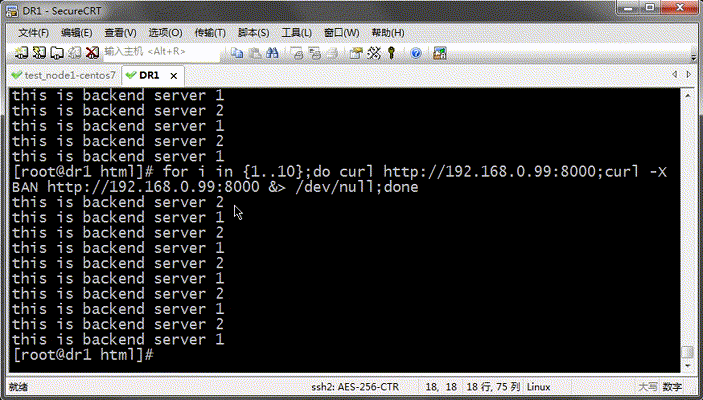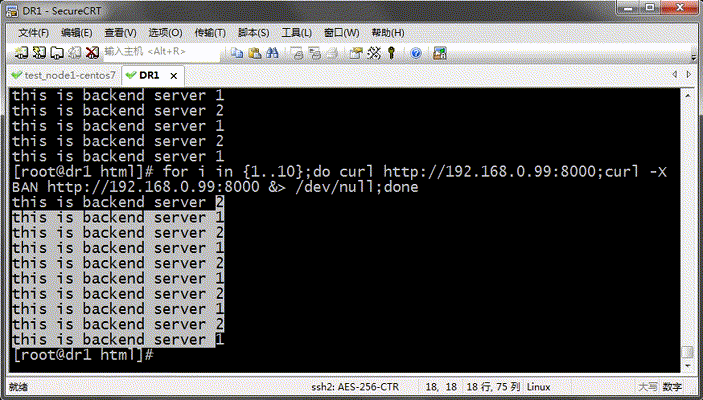
提示:從上面的結果看,我們定義的主機上基於輪詢的方式在往後端調度;這裡測試需要把varnish上的緩存項給修剪掉,然後再次請求才可以看到把請求調度到不同主機上;
以上就是varnish代理多主機的配置方法,總結如下:
1)首先我們要導入directors模塊;
2)用backend關鍵字來定義後端主機,起一名稱,用花括弧引入一段上下文,裡面用.host指定後端主機的IP地址,用.port指定後端主機埠;
3)在vcl_init狀態引擎中初始化一個組對象,然後用組對象的add_backend(server)把對應主機加入到該組;
4)在vcl_recv狀態引擎中使用我們初始化好的組對象;用set req.backend_hint = 組對象中的backend();表示把為能命中的用戶請求發送到該組上,至於用輪詢還是加權輪詢還是hash,取決於我們初始化組對象用到的方法;
瞭解了varnish代理多台主機的配置後,接下來我們再來說說varnish對後端主機做健康狀態監測的配置;對於varnish來講,對後端主機做健康狀態監測的原理是請求後端主機特定的資源,如果能夠在指定的超時時長內正確響應我們就認為後端主機上健康狀態的,如果不能正確的響應我們就認為該後端主機上不健康的;在varnish中對後端主機做健康狀態監測需要用.probe 來引入一段上下文配置,明確的說明怎麼對後端做健康狀態監測(或者用probe關鍵字+名稱來引入一段公有的健康狀態監測機制,後端多台主機可以用.probe +名稱引用);比如請求後端主機的那個url或者用.request來指定向後端主機發送的請求的報文;對後端主機的響應多少次我們認為是健康的,監測頻度,超時時長等等信息;
示例:
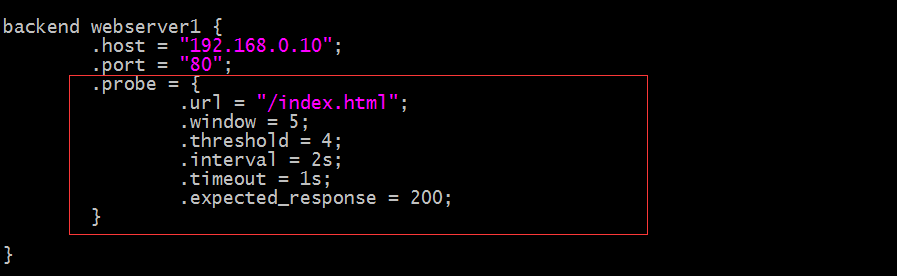
提示:以上紅框中的配置就表示對webserver1這台主機做健康狀態監測;其中.window表示基於最近的多少次檢查來判讀其健康狀態;.threshold表示最近.window中定義的檢查次數至少有多少次是成功的,我們就認為後端主機上健康的;.interval表示檢查的頻度,多久檢查一次;.timeout表示超長時長;綜上所述,該配置就表示對webserver1這台主機做健康狀態監測,如果每隔2秒,超時時長為1秒,請求該主機上的/index.html資源,在最近5次中有4次是成功的,我們就認為後端主機上健康的;
當然以上是對一臺主機做健康狀態檢查的配置。如果是多台主機,監測的方式都是一樣的,我們可以把對健康狀態監測的配置單獨用probe + 名稱來定義監測機制;然後在個server中用.probe +名稱來應用我們定義的健康狀態監測的配置;
示例:
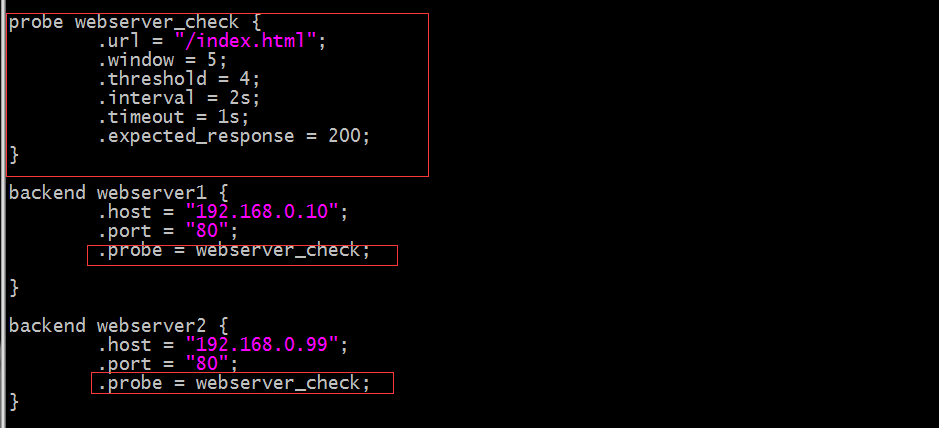
提示:以上配置就表示定義了一個健康狀態監測的配置其名稱為webserver_check,然後在個後端server的配置中用.probe來對webserver_check調用;意思就表示兩台主機都用同樣的監測配置;
當然除了以上對rul請求外,我們也可使用向後端主機發送指定一的請求報文的形式來定義健康狀態監測機制;
示例:

提示:以上配置表示對於server1的健康狀態監測是向server1發送特定的請求首部,如果每隔2秒超時時長為1秒,在5次請求中有4次是200的響應碼,我們就認為該主機上健康的,否則不健康;對於server2主機的健康狀態監測是通過項該主機上的特定資源/index.html發起請求,如果每個2秒超時1秒的情況下,5次請求中有4次都是200的響應碼,我們就認為該主機上健康的,否則不健康;如果不指定.expected_response預設值就是200;
測試:編譯載入default.vcl 看看我們配置的健康狀態監測是否正確
[root@test_node1-centos7 ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082 200 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.10.0-693.el7.x86_64,x86_64,-sfile,-smalloc,-hcritbit varnish-4.0.5 revision 07eff4c29 Type 'help' for command list. Type 'quit' to close CLI session. varnish> vcl.load check_cfg default.vcl 200 VCL compiled. varnish> vcl.use check_cfg 200 VCL 'check_cfg' now active varnish>
提示:上面load過程沒有保存,說明我們配置後端伺服器健康狀體檢查的配置沒有問題;接下來測試把後端主機服務宕機,在管理shell中使用backend.list查看對應主機是否會變為sick?

提示:通過上面的測試結果看,我們把後端主機192.168.0.10這台主機的httpd服務給停了,然後在看後端主機情況,立刻webserver1的狀態就變為了sick,我們接著又把服務給啟動起來,再看後端伺服器狀態,可看到當檢查到第四次是正常的響應後,狀態就變成health;說明我們配置後端主機健康狀態監測是沒有問題的;


