
1.正則表達式到底是什麼東西? 在編寫處理字元串的程式或網頁時,經常會有查找符合某些複雜規則的字元串的需要。正則表達式就是用於描述這些規則的工具。換句話說,正則表達式就是記錄文本規則的代碼。 很可能你使用過Windows/Dos下用於文件查找的通配符(wildcard),也就是*和?。如果你想查找某 ...
1.正則表達式到底是什麼東西?
在編寫處理字元串的程式或網頁時,經常會有查找符合某些複雜規則的字元串的需要。正則表達式就是用於描述這些規則的工具。換句話說,正則表達式就是記錄文本規則的代碼。
很可能你使用過Windows/Dos下用於文件查找的通配符(wildcard),也就是*和?。如果你想查找某個目錄下的所有的Word文檔的話,你會搜索*.doc。在這裡,*會被解釋成任意的字元串。和通配符類似,正則表達式也是用來進行文本匹配的工具,只不過比起通配符,它能更精確地描述你的需求——當然,代價就是更複雜——比如你可以編寫一個正則表達式,用來查找所有以0開頭,後面跟著2-3個數字,然後是一個連字型大小“-”,最後是7或8位數字的字元串(像010-12345678或0376-7654321)。
2.入門
學習正則表達式的最好方法是從例子開始,理解例子之後再自己對例子進行修改,實驗。下麵給出了不少簡單的例子,並對它們作了詳細的說明。
假設你在一篇英文小說里查找hi,你可以使用正則表達式hi。
這幾乎是最簡單的正則表達式了,它可以精確匹配這樣的字元串:由兩個字元組成,前一個字元是h,後一個是i。通常,處理正則表達式的工具會提供一個忽略大小寫的選項,如果選中了這個選項,它可以匹配hi,HI,Hi,hI這四種情況中的任意一種。
不幸的是,很多單詞里包含hi這兩個連續的字元,比如him,history,high等等。用hi來查找的話,這裡邊的hi也會被找出來。如果要精確地查找hi這個單詞的話,我們應該使用\bhi\b。
\b是正則表達式規定的一個特殊代碼(好吧,某些人叫它元字元,metacharacter),代表著單詞的開頭或結尾,也就是單詞的分界處。雖然通常英文的單詞是由空格,標點符號或者換行來分隔的,但是\b並不匹配這些單詞分隔字元中的任何一個,它只匹配一個位置。
如果需要更精確的說法,\b匹配這樣的位置:它的前一個字元和後一個字元不全是(一個是,一個不是或不存在)\w。
假如你要找的是hi後面不遠處跟著一個Lucy,你應該用\bhi\b.*\bLucy\b。
這裡,.是另一個元字元,匹配除了換行符以外的任意字元。*同樣是元字元,不過它代表的不是字元,也不是位置,而是數量——它指定*前邊的內容可以連續重覆使用任意次以使整個表達式得到匹配。因此,.*連在一起就意味著任意數量的不包含換行的字元。現在\bhi\b.*\bLucy\b的意思就很明顯了:先是一個單詞hi,然後是任意個任意字元(但不能是換行),最後是Lucy這個單詞。
換行符就是'\n',ASCII編碼為10(十六進位0x0A)的字元。
如果同時使用其它元字元,我們就能構造出功能更強大的正則表達式。比如下麵這個例子:
0\d\d-\d\d\d\d\d\d\d\d匹配這樣的字元串:以0開頭,然後是兩個數字,然後是一個連字型大小“-”,最後是8個數字(也就是中國的電話號碼。當然,這個例子只能匹配區號為3位的情形)。
這裡的\d是個新的元字元,匹配一位數字(0,或1,或2,或……)。-不是元字元,只匹配它本身——連字元(或者減號,或者中橫線,或者隨你怎麼稱呼它)。
為了避免那麼多煩人的重覆,我們也可以這樣寫這個表達式:0\d{2}-\d{8}。 這裡\d後面的{2}({8})的意思是前面\d必須連續重覆匹配2次(8次)。
3.元字元
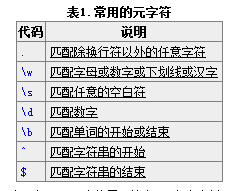
現在你已經知道幾個很有用的元字元了,如\b,.,*,還有\d.正則表達式里還有更多的元字元,比如\s匹配任意的空白符,包括空格,製表符(Tab),換行符,中文全形空格等。\w匹配字母或數字或下劃線或漢字等。
對中文/漢字的特殊處理是由.Net提供的正則表達式引擎支持的,其它環境下的具體情況請查看相關文檔。
下麵來看看更多的例子:
\ba\w*\b匹配以字母a開頭的單詞——先是某個單詞開始處(\b),然後是字母a,然後是任意數量的字母或數字(\w*),最後是單詞結束處(\b)。
好吧,現在我們說說正則表達式里的單詞是什麼意思吧:就是不少於一個的連續的\w。不錯,這與學習英文時要背的成千上萬個同名的東西的確關係不大 :)
\d+匹配1個或更多連續的數字。這裡的+是和*類似的元字元,不同的是*匹配重覆任意次(可能是0次),而+則匹配重覆1次或更多次。
\b\w{6}\b 匹配剛好6個字元的單詞
字元轉義
如果你想查找元字元本身的話,比如你查找.,或者*,就出現了問題:你沒辦法指定它們,因為它們會被解釋成別的意思。這時你就得使用\來取消這些字元的特殊意義。因此,你應該使用\.和\*。當然,要查找\本身,你也得用\\.
例如:deerchao\.net匹配deerchao.net,C:\\Windows匹配C:\Windows。
重覆
你已經看過了前面的*,+,{2},{5,12}這幾個匹配重覆的方式了。下麵是正則表達式中所有的限定符(指定數量的代碼,例如*,{5,12}等):

下麵是一些使用重覆的例子:
Windows\d+匹配Windows後面跟1個或更多數字
^\w+匹配一行的第一個單詞(或整個字元串的第一個單詞,具體匹配哪個意思得看選項設置)
字元類
要想查找數字,字母或數字,空白是很簡單的,因為已經有了對應這些字元集合的元字元,但是如果你想匹配沒有預定義元字元的字元集合(比如母音字母a,e,i,o,u),應該怎麼辦?
很簡單,你只需要在方括弧里列出它們就行了,像[aeiou]就匹配任何一個英文母音字母,[.?!]匹配標點符號(.或?或!)。
我們也可以輕鬆地指定一個字元範圍,像[0-9]代表的含意與\d就是完全一致的:一位數字;同理[a-z0-9A-Z_]也完全等同於\w(如果只考慮英文的話)。
下麵是一個更複雜的表達式:\(?0\d{2}[) -]?\d{8}。
“(”和“)”也是元字元,後面的分組節里會提到,所以在這裡需要使用轉義。
這個表達式可以匹配幾種格式的電話號碼,像(010)88886666,或022-22334455,或02912345678等。我們對它進行一些分析吧:首先是一個轉義字元\(,它能出現0次或1次(?),然後是一個0,後面跟著2個數字(\d{2}),然後是)或-或空格中的一個,它出現1次或不出現(?),最後是8個數字(\d{8})。
分支條件
不幸的是,剛纔那個表達式也能匹配010)12345678或(022-87654321這樣的“不正確”的格式。要解決這個問題,我們需要用到分支條件。正則表達式里的分支條件指的是有幾種規則,如果滿足其中任意一種規則都應該當成匹配,具體方法是用|把不同的規則分隔開。聽不明白?沒關係,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}這個表達式能匹配兩種以連字型大小分隔的電話號碼:一種是三位區號,8位本地號(如010-12345678),一種是4位區號,7位本地號(0376-2233445)。
\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}這個表達式匹配3位區號的電話號碼,其中區號可以用小括弧括起來,也可以不用,區號與本地號間可以用連字型大小或空格間隔,也可以沒有間隔。你可以試試用分支條件把這個表達式擴展成也支持4位區號的。
\d{5}-\d{4}|\d{5}這個表達式用於匹配美國的郵政編碼。美國郵編的規則是5位數字,或者用連字型大小間隔的9位數字。之所以要給出這個例子是因為它能說明一個問題:使用分支條件時,要註意各個條件的順序。如果你把它改成\d{5}|\d{5}-\d{4}的話,那麼就只會匹配5位的郵編(以及9位郵編的前5位)。原因是匹配分支條件時,將會從左到右地測試每個條件,如果滿足了某個分支的話,就不會去再管其它的條件了。
分組
我們已經提到了怎麼重覆單個字元(直接在字元後面加上限定符就行了);但如果想要重覆多個字元又該怎麼辦?你可以用小括弧來指定子表達式(也叫做分組),然後你就可以指定這個子表達式的重覆次數了,你也可以對子表達式進行其它一些操作(後面會有介紹)。
(\d{1,3}\.){3}\d{1,3}是一個簡單的IP地址匹配表達式。要理解這個表達式,請按下列順序分析它:\d{1,3}匹配1到3位的數字,(\d{1,3}\.){3}匹配三位數字加上一個英文句號(這個整體也就是這個分組)重覆3次,最後再加上一個一到三位的數字(\d{1,3})。
IP地址中每個數字都不能大於255,大家千萬不要被《24》第三季的編劇給忽悠了……
不幸的是,它也將匹配256.300.888.999這種不可能存在的IP地址。如果能使用算術比較的話,或許能簡單地解決這個問題,但是正則表達式中並不提供關於數學的任何功能,所以只能使用冗長的分組,選擇,字元類來描述一個正確的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解這個表達式的關鍵是理解2[0-4]\d|25[0-5]|[01]?\d\d?,這裡我就不細說了,你自己應該能分析得出來它的意義。
反義
有時需要查找不屬於某個能簡單定義的字元類的字元。比如想查找除了數字以外,其它任意字元都行的情況,這時需要用到反義:

例子:\S+匹配不包含空白符的字元串。
<a[^>]+>匹配用尖括弧括起來的以a開頭的字元串。
後向引用
後向引用用於重覆搜索前面某個分組匹配的文本。例如,\1代表分組1匹配的文本。難以理解?請看示例:
\b(\w+)\b\s+\1\b可以用來匹配重覆的單詞,像go go, 或者kitty kitty。這個表達式首先是一個單詞,也就是單詞開始處和結束處之間的多於一個的字母或數字(\b(\w+)\b),這個單詞會被捕獲到編號為1的分組中,然後是1個或幾個空白符(\s+),最後是分組1中捕獲的內容(也就是前面匹配的那個單詞)(\1)。
你也可以自己指定子表達式的組名。要指定一個子表達式的組名,請使用這樣的語法:(?<Word>\w+)(或者把尖括弧換成'也行:(?'Word'\w+)),這樣就把\w+的組名指定為Word了。要反向引用這個分組捕獲的內容,你可以使用\k<Word>,所以上一個例子也可以寫成這樣:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括弧的時候,還有很多特定用途的語法。下麵列出了最常用的一些:

註釋
小括弧的另一種用途是通過語法(?#comment)來包含註釋。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含註釋的話,最好是啟用“忽略模式里的空白符”選項,這樣在編寫表達式時能任意的添加空格,Tab,換行,而實際使用時這些都將被忽略。啟用這個選項後,在#後面到這一行結束的所有文本都將被當成註釋忽略掉。例如,我們可以前面的一個表達式寫成這樣:
(?<= # 斷言要匹配的文本的首碼
<(\w+)> # 查找尖括弧括起來的字母或數字(即HTML/XML標簽)
) # 首碼結束
.* # 匹配任意文本
(?= # 斷言要匹配的文本的尾碼
<\/\1> # 查找尖括弧括起來的內容:前面是一個"/",後面是先前捕獲的標簽
) # 尾碼結束


