
根據磁碟IO告警,找到占用磁碟IO (util)讀寫很高的進程。 ...
背景-線上告警
線上一臺伺服器告警,磁碟利用率 disk.util > 90,並持續告警。
登錄該伺服器後通過 iostat -x 1 10 查看了相關磁碟使用信息。相關截圖如下:
1 # 如果沒有 iostat 命令,那麼使用 yum install sysstat 進行安裝 2 # iostat -x 1 10
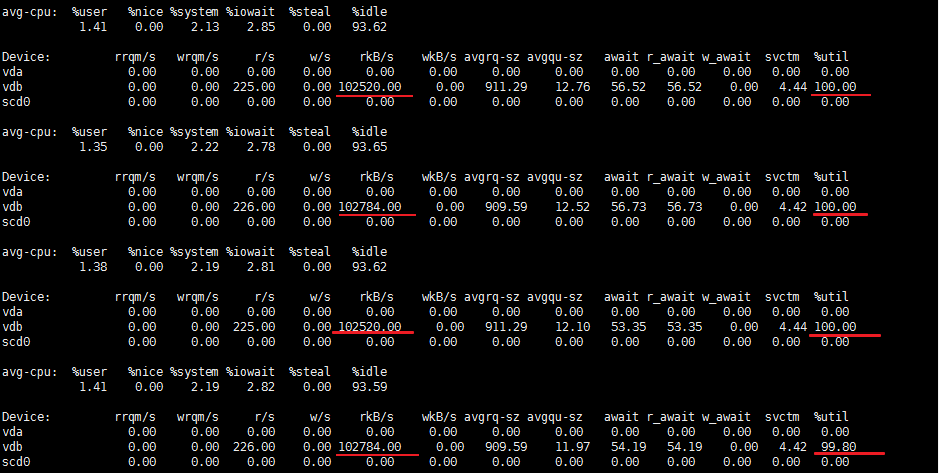
由上圖可知,vdb磁碟的 %util【IO】幾乎都在100%,原因是頻繁的讀取數據造成的。
其他欄位說明
Device:設備名稱
tps:每秒的IO讀、寫請求數量,多個邏輯請求可以組合成對設備的單個I/O請求。
Blk_read/s (kB_read/s, MB_read/s):從設備讀取的數據量,以每秒若幹塊(千位元組、兆位元組)表示。塊相當於扇區,因此塊大小為512位元組。
Blk_wrtn/s (kB_wrtn/s, MB_wrtn/s):寫入設備的數據量,以每秒若幹塊(千位元組、兆位元組)表示。塊相當於扇區,因此塊大小為512位元組。
Blk_read (kB_read, MB_read):讀取塊的總數(千位元組、兆位元組)。
Blk_wrtn (kB_wrtn, MB_wrtn):寫入塊的總數(千位元組,兆位元組)。
rrqm/s:每秒合併到設備的讀請求數。即delta(rmerge)/s
wrqm/s:每秒合併到設備的寫入請求數。即delta(wmerge)/s
r/s:每秒完成的讀I/O設備次數。即delta(rio)/s
w/s:每秒完成的寫I/0設備次數。即delta(wio)/s
rsec/s (rkB/s, rMB/s):每秒讀取設備的扇區數(千位元組、兆位元組)。每扇區大小為512位元組
wsec/s (wkB/s, wMB/s):每秒寫入設備的扇區數(千位元組、兆位元組)。每扇區大小為512位元組
avgrq-sz:平均每次設備I/O操作的數據量(扇區為單位)。即delta(rsec+wsec)/delta(rio+wio)
avgqu-sz:平均每次發送給設備的I/O隊列長度。
await:平均每次IO請求等待時間。(包括等待隊列時間和處理時間,毫秒為單位)
r_await:平均每次IO讀請求等待時間。(包括等待隊列時間和處理時間,毫秒為單位)
w_await:平均每次IO寫請求等待時間。(包括等待隊列時間和處理時間,毫秒為單位)
svctm:平均每次設備I/O操作的處理時間(毫秒)。警告!不要再相信這個欄位值,這個欄位將在將來的sysstat版本中刪除。
%util:一秒中有百分之多少的時間用於I/O操作,或者說一秒中有多少時間I/O隊列是非空的。當該值接近100%時,設備飽和發生。
找到 IO 占用高的進程
通過 iotop 命令
如果沒有該命令,請通過 yum install iotop 進行安裝。
# iotop -oP

通過這個命令可以看見比較詳細信息,如:進程號,磁碟讀取量,磁碟寫入量,IO百分比,涉及到的命令是什麼「兩個都是 grep 命令造成的IO讀取量大」。
通過 pidstat 命令
1 # 命令的含義:展示I/O統計,每秒更新一次 2 # pidstat -d 1
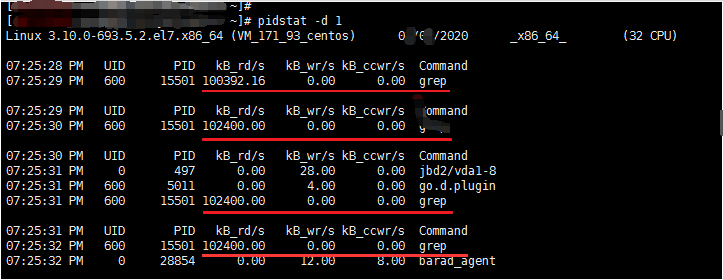
可見其中 grep 命令占用了大量的讀IO,之後可根據 PID 查看相關進程信息。
說明:本圖與上圖的PID不同,原因是上圖涉及的進程執行完了,本圖是之後執行產生的進程【都執行的同一個腳本】。
———END———
如果覺得不錯就關註下唄 (-^O^-) !


