
從輸入URL到頁面載入發生了什麼? 最近在進行前端性能優化方面的一些工作,發現前端性能方面太廣,不知道如何下手。參考了許多文章,發現最終都會歸咎於一個非常經典的問題: 從輸入URL到頁面載入發生了什麼? 通過連接這個過程,然後針對性地對每個過程進行優化,最終實現的就是我們的前端性能優化。本篇文章主要 ...
從輸入URL到頁面載入發生了什麼?
最近在進行前端性能優化方面的一些工作,發現前端性能方面太廣,不知道如何下手。參考了許多文章,發現最終都會歸咎於一個非常經典的問題:從輸入URL到頁面載入發生了什麼?通過連接這個過程,然後針對性地對每個過程進行優化,最終實現的就是我們的前端性能優化。本篇文章主要介紹一些基礎性的概念,很少涉及真正的性能優化。
具體過程?
打開瀏覽器,輸入URL,到頁面展示出來,這個中間大致經歷了這些過程:
- 輸入URL
- DNS解析
- TCP握手
- HTTP請求
- HTTP響應返回數據
- 瀏覽器解析並渲染頁面

上面粗劣的介紹了輸入URL到頁面載入的大致過程,但是缺少更加詳細的過程,事實上w3c給我們提供了一個介面performance.timing更加詳細地介紹了每個過程,並且可以通過這個過程獲取頁面性能數據。如下圖所示:
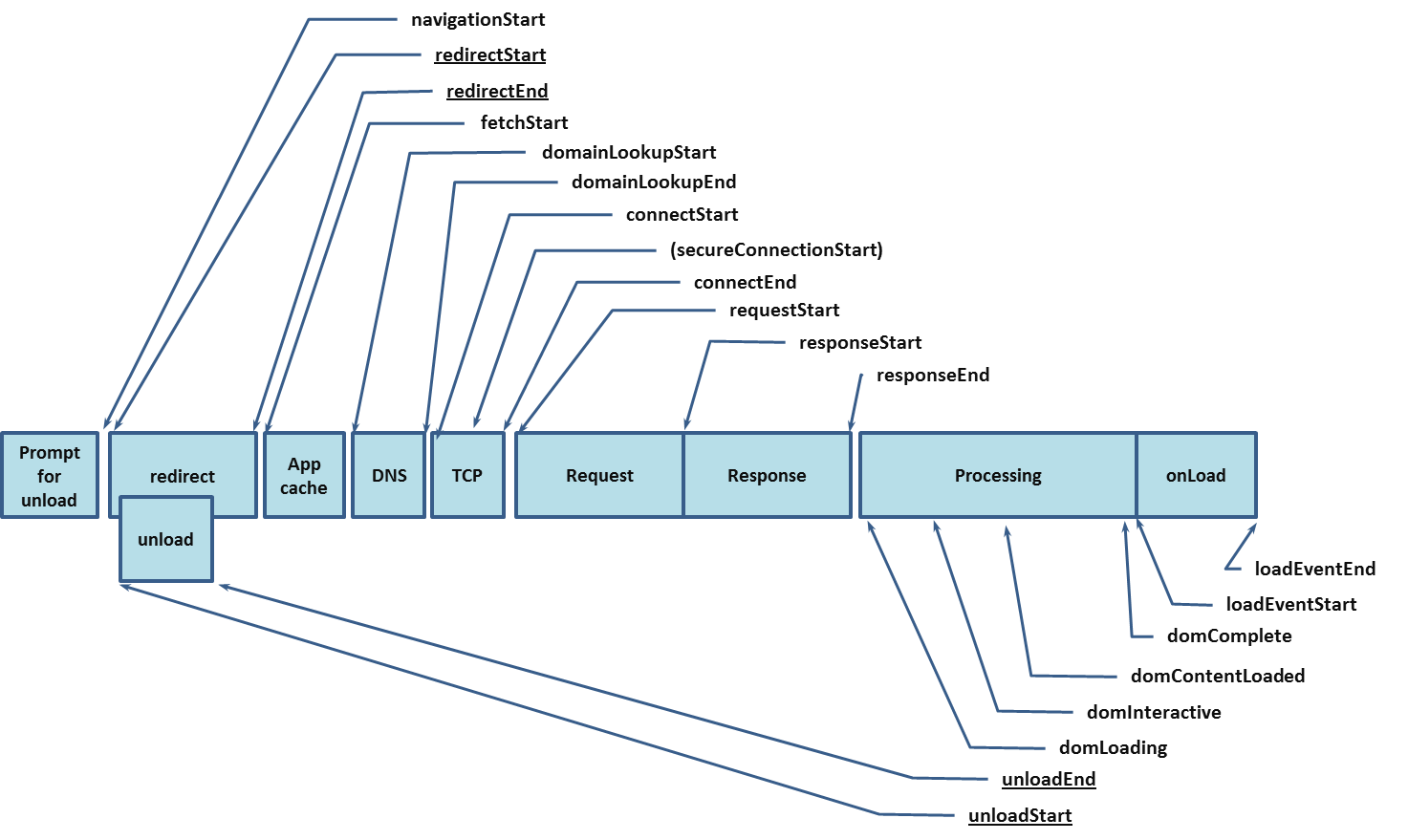
上圖的過程大致可以分為三個大的階段:
- 緩存相關:主要包括Prompt for unload,redirect和App cache3個過程
- 網路相關:主要包括DNS,TCP和HTTP(Request,Response)3個過程
- 瀏覽器相關:主要包括Processing和onload兩個過程
通過將整個過程細分為3個大的階段,然後再每個階段每個階段介紹,這樣方便我們記憶和理解。
緩存相關
1、卸載已有的頁面(Prompt for unload)
我們在頁面中輸入URL時,首先會卸載掉原來的頁面。這是為了釋放頁面占據的記憶體,否則沒請求一次URL都占據一份記憶體,會導致瀏覽器占據記憶體越來越大。
2、重定向(redirect)
所謂的重定向實際上就是先從本地緩存中去查找請求的內容,如果本地緩存中有則直接使用,如果沒有則向伺服器進行請求(這隻是簡單的理解,實際上如何獲取數據是存在緩存策略的)。事實上,每次從伺服器獲取到文件,文件會被暫時存放到一個指定區域,當我們下次再次請求這個文件時,瀏覽器會首先從這個區域查看是否已經存在過這個文件,如果已經存在,則不需要再次進行請求數據。
3、App cache
網路相關
4、DNS
DNS(Domain Name System)功能變數名稱系統,顧名思義是用來解析功能變數名稱系統的。在網路中,我們人適合於記憶文本,因此我們輸入的都是www.baidu.com這種字元串,但是電腦適合於處理數字,每一臺電腦對應的是一個IP地址。因此,如果我們要訪問一個指定的資源,必須先找到對應的伺服器,而找到伺服器需要先將功能變數名稱轉換為對應的IP地址。而DNS就是幫助我們實現這個過程。
功能變數名稱級別
功能變數名稱的級別是指一個功能變數名稱由多少級組成,功能變數名稱的各個級別被"."分開,總而言之,有多少個點就是幾級功能變數名稱。
頂級功能變數名稱在開頭有一個點(.com .cn .net)
一級功能變數名稱就是在"com cn net"前加一級 (baidu.com)
二級功能變數名稱就是在一級功能變數名稱前再加一級(www.baidu.com)
二級功能變數名稱及以上級別的功能變數名稱,統稱為子功能變數名稱,不在註冊功能變數名稱的範疇中
功能變數名稱資源記錄
| 記錄類型 | 含義 |
|---|---|
| SOA(StartOf Authority,起始授權記錄) | 一個區域解析庫中有且只能有一個SOA記錄,而且必須放在第一條 |
| A記錄(主機記錄,針對IPV4的記錄) | 用於名稱解析的重要記錄,將特定的主機名映射到對應主機的IP地址上 |
| CNAME記錄(別名記錄) | 用於返回另外一個功能變數名稱,即當前查詢的功能變數名稱是另一個功能變數名稱的跳轉,主要用於功能變數名稱的內部跳轉,為伺服器配置提供靈活性 |
| NS記錄(功能變數名稱伺服器記錄) | 用於返回保存下一級功能變數名稱信息的伺服器地址。該記錄只能設置為功能變數名稱,不能設置為IP地址 |
| MX(郵件記錄) | 用戶返回接收電子郵件的伺服器地址 |
| C記錄(IPV6記錄) | 用於將特定的主機名映射到一個主機的IPV6地址 |
功能變數名稱伺服器
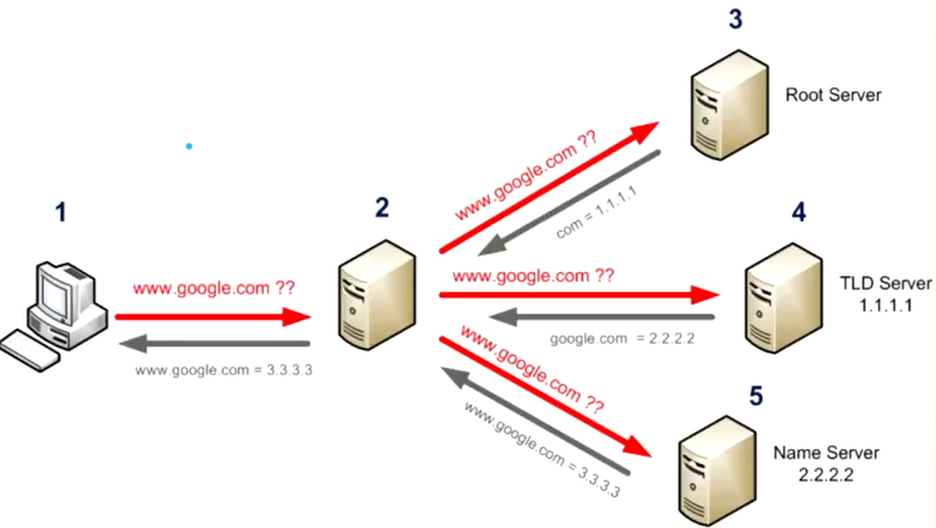
功能變數名稱的解析需要用到一系列的伺服器,而不是簡單的一個伺服器。比如:用戶想要解析www.google.com:
- 在本機上輸入www.google.com
- 2號伺服器是用戶在自己電腦上填寫的DNS地址,由於功能變數名稱和ip地址的對照表非常龐大,因此2號伺服器會進行分層管理。2號伺服器進行功能變數名稱解析是會先從緩存中進行查找,如果一個功能變數名稱被頻繁訪問,通常會被保存到緩存中。如果DNS這沒有對應的功能變數名稱-IP緩存,那麼就需要向根伺服器(Root Server)發起請求。
- 根伺服器負責維護全球的功能變數名稱-IP地址解析。根伺服器會檢查功能變數名稱尾碼(比如.com),根據不同的尾碼,交給不同的TLD伺服器處理。獲取到尾碼後,返回對應的TLD伺服器的ip地址(com = 1.1.1.1)。
- DNS拿到TLD伺服器的IP地址後,繼續向TLD伺服器進行詢問。TLD伺服器只返回頂級功能變數名稱對應的IP(google.com = 2222),交給頂級功能變數名稱對應的Name Server處理。
- DNS伺服器獲取到頂級功能變數名稱的IP後,繼續向Name Server進行詢問。Name Server返回具體的功能變數名稱對應的IP地址。
- DNS伺服器獲取到具體的功能變數名稱對應的IP後,會先進行緩存,避免下次請求時繼續多次詢問。
5、TCP
TCP是HTTP的下層協議,我們想要通過HTTP進行請求,必須先通過TCP進行連接,也就是說HTTP是依賴於TCP的。TCP的作用就是連接指定IP地址的伺服器(通過DNS已經獲取到對應的伺服器IP地址)。
每次連接的時候,TCP都會經歷三次握手,每次斷開連接時TCP都會經歷四次揮手。這些過程就是可以優化的地方,這裡不做闡釋。
6、HTTP請求(Request)和響應(Response)
在 HTTP/1.x 中,如果客戶端要想發起多個並行請求以提升性能,則必須使用多個 TCP 連接。 這是 HTTP/1.x 交付模型的直接結果,該模型可以保證每個連接每次只交付一個響應(響應排隊)。 更糟糕的是,這種模型也會導致隊首阻塞,從而造成底層 TCP 連接的效率低下。 也就是說在目前的HTTP1.X的協議下,瀏覽器對資源的併發請求個數是有限制的。 等到HTTP2到來的時候,通過二進位分幀層進行優化。 HTTP/2 中新的二進位分幀層突破了這些限制,實現了完整的請求和響應復用:客戶端和伺服器可以將 HTTP 消息分解為互不依賴的幀,然後交錯發送,最後再在另一端把它們重新組裝起來。
瀏覽器相關
7、文檔解析和DOM的載入(Processing)
HTTP請求後返回的是一個文本,我們需要將文本轉換成DOM樹,然後載入DOM
8、觸發Onload事件(onload)
DOM載入完成之後,觸發onload事件。


