一、分散式資料庫存儲 在前面的章節;GreenPlum資料庫是分散式架構資料庫;表的數據分佈在segment節點。那麼表的數據根據什麼策略來分佈的? GreenPlum資料庫性能依賴於跨數據節點均勻分佈 二、分佈策略 在GreenPlum資料庫在創建表時可以指定分佈策略:哈希分佈(DISTRIBUT ...
一、分散式資料庫存儲
在前面的章節;GreenPlum資料庫是分散式架構資料庫;表的數據分佈在segment節點。那麼表的數據根據什麼策略來分佈的?
GreenPlum資料庫性能依賴於跨數據節點均勻分佈
- GreenPlum資料庫查詢響應時間由所有數據節點完成時間來度量。系統只能跟最慢數據節點完成時間來決定。如果數據存儲傾斜。一個數據節點比其他節點需要花更多的時間來處理數據,數據存儲傾斜只會存在哈希分佈的情況。
- 在GreenPlum資料庫中;表關聯查詢最常見。若兩個或者多個表關聯的欄位非分佈鍵或者採用隨機分佈。在其他分散式架構這表之間的關係不是親和表。要執行連接,匹配的行必須位於同一節點上。 如果數據未在同一連接列上分發,則其中一個表所需的行將動態重新分發到其他節點。 有些情況下,執行廣播動作,每個節點將其各個行發送到所有其他節點上,而不是每個節點重新哈希數據並根據哈希值將行發送到適當的節點的重新分配。
- 是不是還有一種複製表?在GreenPlum6.0以上的版本支持複製表。正好避免2中的廣播或者重分佈動作。
二、分佈策略
在GreenPlum資料庫在創建表時可以指定分佈策略:哈希分佈(DISTRIBUTED BY)、隨機分佈(DISTRIBUTED RANDOMLY)、複製分佈(DISTRIBUTED REPLICATED)。
- 哈希分佈:需要指定分佈鍵。會根據分佈鍵的哈希值分配到對應的segment數據節點。相近的值會分配到同一個數據節點。
- 隨機分佈:隨機分佈無需指定分佈鍵。這樣無法保證表中欄位的唯一性。因為同個值可能會分佈在不同的數據節點。
- 複製分佈:在GreenPlum6.0以上的版本支持複製表;Greenplum資料庫會將每個表行分發到每個節點實例。 複製表的數據均勻分佈,因為每個節點具有相同的行。
如何選擇分佈策略呢?我們現在來分析
2.1、單表查詢情況
結果驗證:好像沒區別

2.2、表關聯查詢
現在我們創建一個表t_lottu;也插入10000條記錄
lottu=# truncate table t_lottu;
TRUNCATE TABLE
lottu=# insert into t_lottu select generate_series(1,10000),'lottu';
INSERT 0 10000
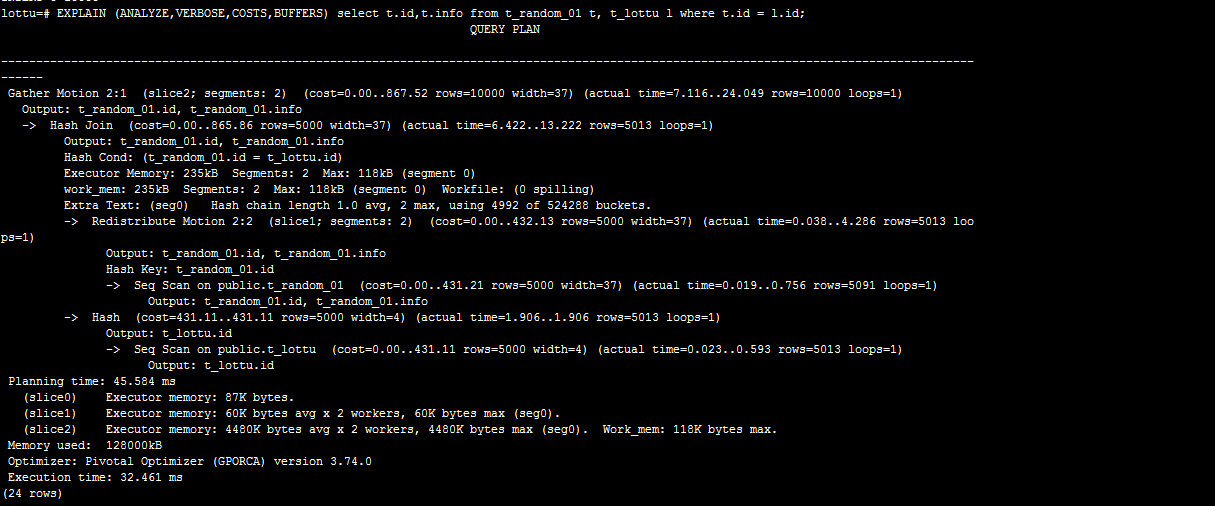
隨機策略:通過t_random_01與表t_lottu關聯
哈希策略:
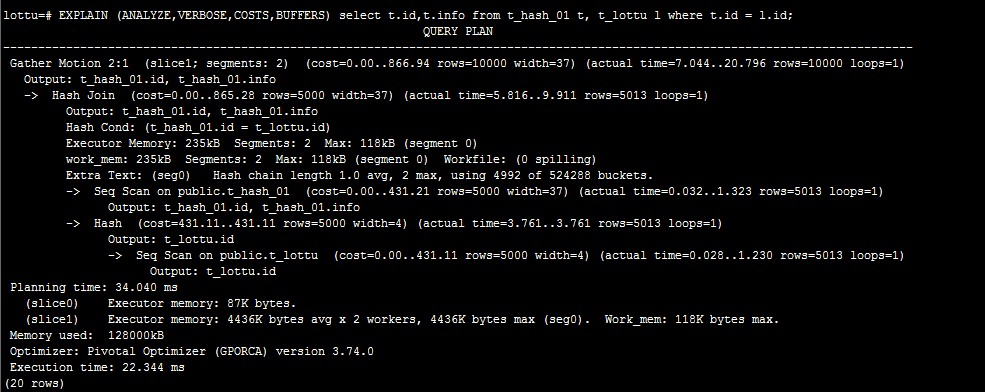
通過上兩圖比較:可以判斷哈希策略略好;我這環境只有2個segment節點。效果不明顯。我們可以明顯可以看到在隨機策略查詢計劃裡面那有Redistribute Motion。 這個在後面講解查詢計劃。這個叫數據重分佈。後須講解。
為什麼隨機策略會Redistribute Motion?
在哈希策略中;同樣的分佈鍵的值肯定會分佈到同一個segment節點。所以上面表t_hash_01和表t_lottu的分佈鍵都是id欄位。所就可以在每個Segment節點關聯後,Segment節點把結果發送到Master節點,再由Master節點彙總,將最終的結果返還客戶端。而隨機分佈則不能保證同樣分佈鍵的數據分佈在同一個Segment節點上,這樣在表關聯的時候,就需要將數據發送到所有Segment節點去做運算,這樣網路傳輸和大量數據運算都需要較長的時間,性能非常低下。所以在關聯的時候不建議使用隨機策略。
這裡有一個問題了;是不是哈希策略查詢計劃就不會出現Redistribute Motion/Broadcast Motion(廣播)。答案是錯誤的。若分佈鍵跟關聯的欄位不一致的情況。就會出現。分布鍵跟關聯的欄位是否一致?在其它分散式架構叫表的親和度。
2.3、數據分佈傾斜的問題
既然不建議使用隨機策略;那我們都是用哈希策略不就好了嗎?
哈希策略是同樣的分佈鍵的值肯定會分佈到同一個segment節點。有可能造成數據分佈傾斜的問題。在隨機策略不會出現這種情況。
數據分佈傾斜的問題;待定。
-- 重新分佈表數據
2.4、數據複製分佈
在GreenPlum6.0版本中支持複製表。作用消除多表關聯中Redistribute Motion/Broadcast Motion帶來的性能消耗。也可用於單表的負載均衡。
在用於單表查詢;可以看出只需查詢一個節點即可。
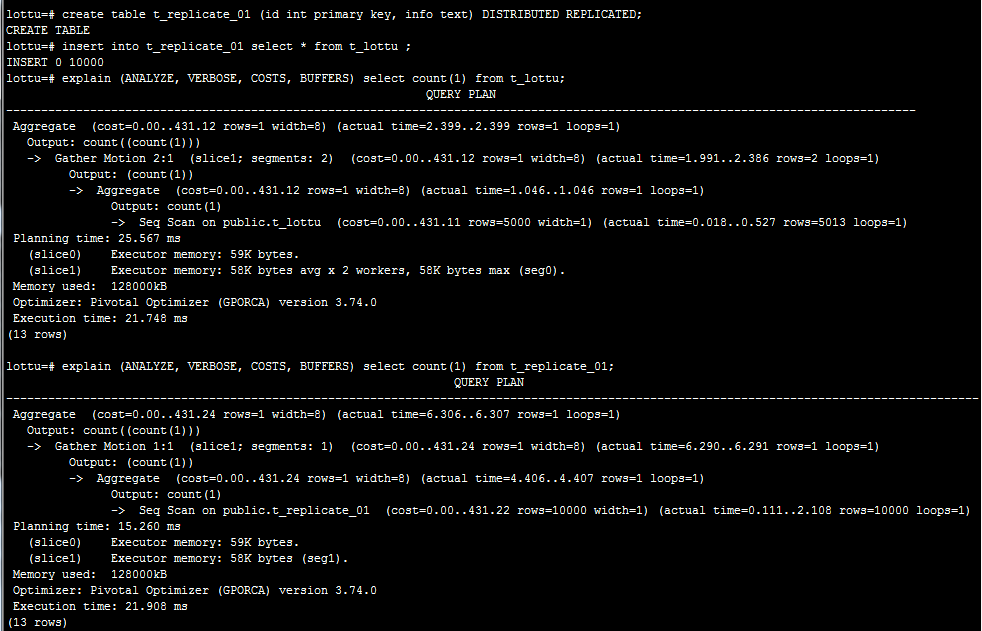
用於多表關聯消除多表關聯中Redistribute Motion/Broadcast Motion帶來的性能消耗

三、數據是如何存儲
創建表的DDL語句還可以通過with子句來定義表的存儲類型
where storage_parameter is:
APPENDONLY={TRUE|FALSE}
BLOCKSIZE={8192-2097152}
ORIENTATION={COLUMN|ROW}
COMPRESSTYPE={ZLIB|QUICKLZ|RLE_TYPE|NONE}
COMPRESSLEVEL={0-9}
CHECKSUM={TRUE|FALSE}
FILLFACTOR={10-100}
OIDS[=TRUE|FALSE]
where column_constraint is:
在前面有說到
參考:https://github.com/digoal/blog/blob/master/201708/20170818_02.md
Greenplum資料庫可以使用追加優化(append-optimized,AO)的存儲個事來批量裝載和讀取數據,並且能提供HEAP表上的性能優勢。 追加優化的存儲為數據保護、壓縮和行/列方向提供了校驗和。行式或者列式追加優化的表都可以被壓縮。
在創建表指定 APPENDONLY = TRUE為AO表。若不指定或者APPENDONLY = FALSE為堆表。
3.1、堆表
堆表是PostgreSQL資料庫原生存儲格式,GreenPlum預設的存儲格式。堆表存儲在OLTP類型負載下表現最好,這種環境中數據會在初始載入後被頻繁地修改。 UPDATE和DELETE操作要求存儲行級版本信息來確保可靠的資料庫事務處理。 堆表最適合於較小的表,例如維度表,它們在初始載入數據後會經常被更新。
多適合用於OLTP系統。但GreenPlum常定位是用於OLAP系統。為了更適合OLAP系統。GreenPlum提供來AO表
應用場景:
堆表是萬油金;只是有些場景其他存儲方式更加適合。更能提升性能。
3.2、AO表
AO表在4.3版本之前取意為(APPEND-ONLY,AO)。根據其意義只能追加,在4.3版本之後取意為(append-optimized,AO)追加優化。支持update/delete。跟堆表一樣。但實現原理不一樣。刪除更新數據時,通過另一個BITMAP文件來標記被刪除的行,通過bit以及偏移對齊來判定AO表上的某一行是否被刪除。
追加優化表存儲在數據倉庫環境中的非規範表表現最好。 非規範表通常是系統中最大的表。 事實表通常成批地被載入並且被只讀查詢訪問。 將大型的事實表改為追加優化存儲模型可以消除每行中的更新可見性信息負擔,這可以為每一行節約大概20位元組。 這可以得到一種更加簡潔並且更容易優化的頁面結構。 追加優化表的存儲模型是為批量數據裝載優化的,因此不推薦單行的INSERT語句
AO支持壓縮以及列存
應用場景:
- 使用列存、壓縮數據使用AO表。
- 數據批量寫入使用AO表
3.3、行存和列存
ORIENTATION=COLUMN可以指定創建列存的AO表。列存的表只能是AO表。
- 行存:以行形式存儲表中。一行數據存在一個數據文件中。適用於具有許多迭代事務的OLTP類型的工作負載以及一次需要多列的單行,因此檢索是高效的
- 列存:以列為形式組織存儲,每列對應一個或一批文件。而且壓縮比例比較高。適合於在少量列上計算數據聚集的數據倉庫負載,或者是用於需要對單列定期更新但不修改其他列數據的情況
若一個寬表。在讀取某一個列數據;行存需要把匹配的列的所在的行數據塊都要掃描一遍。整好列存可以避免。但是帶來的問題是一個表對應多個數據文件。
行存與列存的選擇以及轉換方法
|
類型
|
創建選項
|
適用場景
|
|
堆表
|
預設/APPENDONLY = FALSE
|
適合OLTP系統,適合單條記錄插入,適合小表
|
|
AO表
|
APPENDONLY = TRUE
|
適合OLAP系統,同時支持壓縮。適合批量記錄插入
|
|
行存
|
ORIENTATION=ROW
|
適合小量數據、多列查詢
|
|
列存
|
ORIENTATION=COLUMN
|
適合OLAP系統、寬表
|
備註:以上為本人理解;若有不對的地方;煩請指出。謝謝!



