
目錄: 一.字元編碼 二.字元串格式化 三.進位轉換 四.數據類型及其操作 五.字元串轉換 六.列表 七.元組 八.字典 一.字元編碼: 電腦由美國人發明,最早的字元編碼為ASCII,只規定了英文字母數字和一些特殊字元與數字的對應關係。最多只能用 8 位來表示(一個位元組),即:2**8 = 256 ...
目錄:
一.字元編碼:
電腦由美國人發明,最早的字元編碼為ASCII,只規定了英文字母數字和一些特殊字元與數字的對應關係。最多只能用 8 位來表示(一個位元組),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號
ascii用1個位元組代表一個字元;
unicode常用2個位元組代表一個字元,生僻字需要用4個位元組;
UTF-8英文字母被編碼成1個位元組,漢字通常是3個位元組有很生僻的字元才會被編碼成4-6個位元組。
例:
字母x,用ascii表示是十進位的120,二進位0111 1000
漢字中已經超出了ASCII編碼的範圍,用Unicode編碼是十進位的20013,二進位的01001110 00101101。
字母x,用unicode表示二進位0000 0000 0111 1000,所以unicode相容ascii,也相容萬國,是世界的標準
這時候亂碼問題消失了,所有的文檔我們都使用但是新問題出現了,如果我們的文檔通篇都是英文,你用unicode會比ascii耗費多一倍的空間,在存儲和傳輸上十分的低效
本著節約的精神,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文本包含大量英文字元,用UTF-8編碼就能節省空間:
|
字元 |
Ascll |
Unicode |
Utf-8 |
|
x |
01000001 |
00000000 01000001 |
01000001 |
|
中 |
不能表示 |
01001110 00101101 |
11100100 10111000 10101101 |
從上面的表格還可以發現,UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支持ASCII編碼的歷史遺留軟體可以在UTF-8編碼下繼續工作。
ASCII:只能存英文和拉丁字元,一個字元占一個位元組,8位
gb2312:只能存6700多個中文,1980年
gbk1.0:存2萬多字元,1995年
gb18030:存27000中文,2000年
萬國碼:Unicode:utf-32 一個字元占4個位元組
Utf-16 一個字元占2個位元組,或兩個以上。
Utf-8 一個英文用ASCII碼來存,一個中文占3個位元組
聲明編碼 -*- coding:utf-8 -*-
gbk預設不認識utf-8,utf-8是Unicode的一個子集
Unicode 預設向下相容gbk等
python3內部預設是 unicode,文件預設編碼是utf-8
階段一:現代電腦起源於美國,最早誕生也是基於英文考慮的ASCII
ASCII:一個Bytes代表一個字元(英文字元/鍵盤上的所有其他字元),1Bytes=8bit,8bit可以表示0-2**8-1種變化,即可以表示256個字元
ASCII最初只用了後七位,127個數字,已經完全能夠代表鍵盤上所有的字元了(英文字元/鍵盤的所有其他字元),後來為了將拉丁文也編碼進了ASCII表,將最高位也占用了
階段二:為了滿足中文和英文,中國人定製了GBK
GBK:2Bytes代表一個中文字元,1Bytes表示一個英文字元
為了滿足其他國家,各個國家紛紛定製了自己的編碼
日本把日文編到Shift_JIS里,南韓把韓文編到Euc-kr里
階段三:各國有各國的標準,就會不可避免地出現衝突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。如何解決這個問題呢???
說白了亂碼問題的本質就是不統一,如果我們能統一全世界,規定全世界只能使用一種文字元號,然後統一使用一種編碼,那麼亂碼問題將不復存在,
很多地方或老的系統、應用軟體仍會採用各種各樣的編碼,這是歷史遺留問題。於是我們必須找出一種解決方案或者說編碼方案,需要同時滿足:
1、能夠相容萬國字元
2、與全世界所有的字元編碼都有映射關係,這樣就可以轉換成任意國家的字元編碼
這就是unicode(定長), 統一用2Bytes代表一個字元, 雖然2**16-1=65535,但unicode卻可以存放100w+個字元,因為unicode存放了與其他編碼的映射關係,準確地說unicode並不是一種嚴格意義上的字元編碼表
很明顯對於通篇都是英文的文本來說,unicode的式無疑是多了一倍的存儲空間(二進位最終都是以電或者磁的方式存儲到存儲介質中的)
階段四:於是產生了UTF-8(可變長,全稱Unicode Transformation Format),對英文字元只用1Bytes表示,對中文字元用3Bytes,對其他生僻字用更多的Bytes去存。
二. Python 字元串格式化
Python 支持格式化字元串的輸出 。儘管這樣可能會用到非常複雜的表達式,但最基本的用法是將一個值插入到一個有字元串格式符 %s 的字元串中。
例如:
print("My name is %s and weight is %d kg!" % ('Zrh', 20))
輸出結果:
My name is Zrh and weight is 20 kg!
如果在格式化輸出中想要輸出%號,就要用到%%格式
例如:
print("我是%s,我的進度已經完成80%%" %('zrh'))
輸出結果:
我是zrh,我的進度已經完成80%
三.進位轉換
進位也就是進位位,我們常用的進位包括:二進位、八進位、十進位與十六進位,它們之間區別在於數運算時是逢幾進一位。比如二進位是逢2進一位,十進位也就是我們常用的0-9是逢10進一位,16進位的10-15用A、B、C、D、E、F來表示。
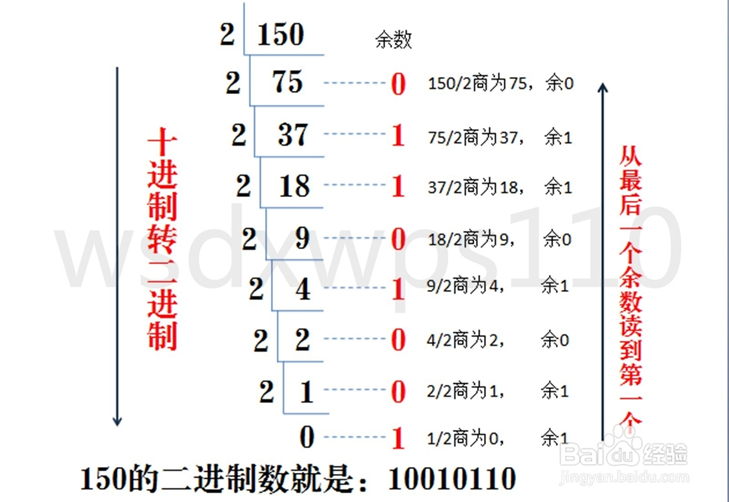
1. 十進位轉二進位
方法為:十進位數除2取餘法,即十進位數除2,餘數為權位上的數,得到的商值繼續除2,依此步驟繼續向下運算直到商為0為止。
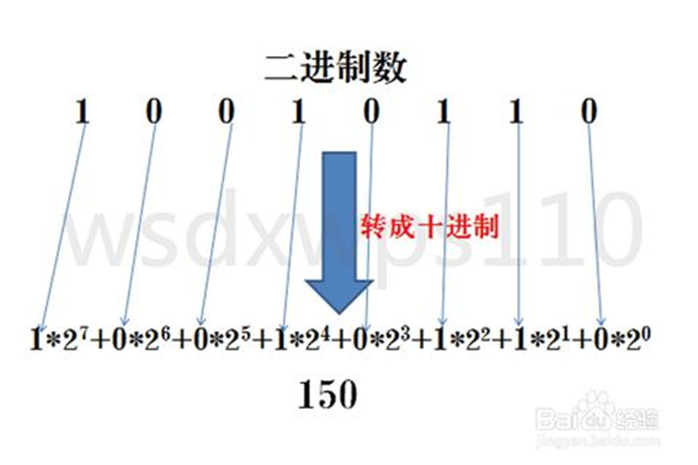
2. 二進位轉十進位
方法為:把二進位數按權展開、相加即得十進位數。
第一個的1*2的7次方,是因為數位就是8位,8-1=7,依此類推。
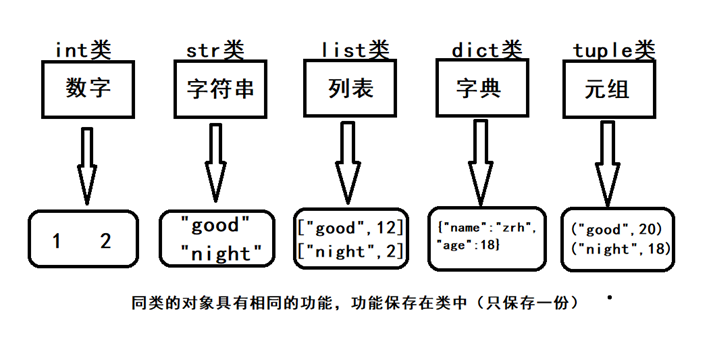
四. 數據類型
Python有五個標準的數據類型:
Numbers(數字) V = 1 int類
Boolean value(布爾值) V = True (bool類)
String(字元串) V = “Good” (str類)
List(列表) V = [“good”,”best”] (list類)
Tuple(元組) V = (“good”,”best”) (tuple類)
Dictionary(字典) V = {“name”:”zrh”,”age”:20} (dict類)
1.int類(記住一個)
bit_length()表示當前十進位數用二進位數表示時,最少使用的位數。
代碼示例:
count = 16
v = count.bit_length()
print(v,"---",count)
輸出結果:
5 --- 16
2.str類
對於字元串,執行內置命令後,原來的值不變。
2.1:upper()轉換字元串中的小寫字母為大寫
代碼示例:
name = "zrh"
v = name.upper()
print(v,"---",name)
輸出結果:
ZRH --- zrh
2.2:lower()轉換字元串中所有大寫字元為小寫
代碼示例:
name = "ZrH"
v = name.lower()
print(v,"---",name)
輸出結果:
zrh --- ZrH
2.3:capitalize()將字元串的第一個字元轉換為大寫
代碼示例:
name = "zrh"
v = name.capitalize()
print(v,"---",name)
輸出結果:
Zrh --- zrh
2.4:strip()去除首尾空格
代碼示例:
name = " zrh "
v = name.strip()
print(v+"---",name)
輸出結果:
zrh--- zrh
2.5:lstrip()截掉字元串左邊的空格或指定字元
2.6:rstrip()刪除字元串字元串末尾的空格
2.7:replace(str1, str2 , max)將字元串中的 str1 替換成 str2,如果max指定,則替換不超過max次
代碼示例:
content = "人生自古誰無死,早死晚死都得死"
v = content.replace("死","*",2)
print(v,"---",content)
輸出結果:
人生自古誰無*,早*晚死都得死 --- 人生自古誰無死,早死晚死都得死
2.8: len(string)返回字元串長度
代碼示例:
content = "人生自古誰無死,早死晚死都得死"
v = len(content)
print(v)
輸出結果:
15
2.9:[]根據索引取值
代碼示例:
#索引值從0開始計算不是從1
content = "人生自古誰無死,早死晚死都得死"
v = content[0] #取字元串的第一個字元
v1 = content[-1] #-代表從後往前找,1代表第一個,所以-1代表正向的最後一個
v2 = content[0:5] #從0開始取到索引值為4的對象,不包括索引值為5的對象,相當於數學中的左閉右開區間
v3 = content[8:] #從索引值為8的對象開始取到最後一個
v4 = content[0:15:2] #從0開始隔一個取一個,一直取到14,2表步長表示各一個取一個,3就表示隔2個
print(v,v1,v2,v3,v4)
輸出結果:
人 死 人生自古誰 早死晚死都得死 人自誰死早晚都死
2.10 :split(“str”,num)
以 str 為分隔符截取字元串,如果 num 有指定值,則僅截取 num+1 個子字元串
代碼示例:
content = "人生自古誰無死,早死晚死都得死"
v = content.split("死",2)
print(v)
輸出結果:
['人生自古誰無', ',早', '晚死都得死']
2.11 :.isdecimal()判斷當前字元串中是否全部都是數字
代碼示例:
v = "a123"
c = v.isdecimal()
print(c)
輸出結果:
False
2.12 :join(seq) 以指定字元串作為分隔符,將 seq 中所有的元素(的字元串表示)合併為一個新的字元串
代碼示例:
list1 = ['alex','zrh','sdv']
a = '_'.join(list1) #這裡的_就表示用_連接
b = "".join(list1) #""里什麼都沒有表示直接連接
print(a)
print(b)
輸出結果:
alex_zrh_sdv
alexzrhsdv
五.字元串轉換
1.數字轉字元串 str(對象)
2.字元串轉數字 int(對象)
對象必須是形為數字,才能轉換
Int(string)就會報錯
3.數字轉布爾值 bool(對象)
bool(0)是False
其他不是0的數都是True
4.字元串轉布爾值 bool(對象)
bool(“”)是False
其他任何字元串都是True
註意:
代碼示例:
a = 9 or 2>3
print(a)
輸出結果:
9
代碼示例:
a = 0 or 2>3
print(a)
輸出結果:
False
代碼示例:
a = 0 or 6
print(a)
輸出結果:
6
代碼示例:
a = 0 or 2<3
print(a)
輸出結果:
True
六.列表
列表是Python中最基本的數據結構。列表中的每個元素都分配一個數字 - 它的位置,或索引,第一個索引是0,第二個索引是1,依此類推。
創建一個列表,只要把逗號分隔的不同的數據項使用方括弧括起來即可。
如下所示:
list = ["one","two",3,4,"five"]
列表可以進行 增、刪、改、查。如果列表只有一個對象,在後面也要加上,
列表中的元素可以是 數字、字元串、布爾值、列表(列表的嵌套)
1.查 切片:
list[1:] #從1開始取到最後
list[1:-1] #從1開始取到倒數第二值
list[1:-1:1] #從左到右一個一個去取,取到倒數第二值
list[1::2] #左到右隔一個去取
list[3::-1] #從3開始從右到左一個一個取,註意索引值不變
2.增 添加:
2.1:append()
append(“str”)將數據插到最後一個位置
代碼示例:
list = ["one","two",3,4,"five"]
list.append("six")
print(list)
輸出結果:
['one', 'two', 3, 4, 'five', 'six']
2.2:insert()
根據索引值位置將數據插入到任意一個位置
代碼示例:
list = ["one","two",3,4,"five"]
list.insert(2,"two2") #想把新對象插在什麼位置就輸入相應的索引值
print(list)
輸出結果:
['one', 'two', 'two2', 3, 4, 'five']
3.改 修改:
想要修改首先得用切片把相應的值取出來,在進行賦值即可。
代碼示例:
list = ["one","two",3,4,"five"]
list[1] = 2 #將索引值為1的對象取出來,再重新賦值
print(list)
輸出結果:
['one', 2, 3, 4, 'five']
需求:將list = ["one","two",3,4,"five"]這個列表裡的two 和 4 修改成 2 和 four
代碼示例:
list = ["one","two",3,4,"five"]
list[1:4:2] = [2,"four"]
print(list)
輸出結果:
['one', 2, 3, 'four', 'five']
註意:在list[1:4:2] = [2,"four"]中,因為list[1:4:2]輸出得是一個列表,所以等號右邊也必須是個列表
4.刪 刪除:
4.1:remove
remove只能刪除一個,並且()里填寫的是對象內容
代碼示例:
list = ["one","two",3,4,"five"]
list.remove("two") #刪除two
print(list)
輸出結果:
['one', 3, 4, 'five']
4.2 :pop
pop刪除的時候()里是填寫索引值,並且還可以將刪除數據返回出來,如果括弧裡面不填索引值,即pop(),則預設刪除最後一個值。
代碼示例:
list = ["one","two",3,4,"five"]
list.pop(1) #刪除 two
print(list)
輸出結果:
['one', 3, 4, 'five']
4.3 :del什麼都可以刪除
代碼示例:
list = ["one","two",3,4,"five"]
del list[0] #刪除 one
print(list)
輸出結果:
['two', 3, 4, 'five']
5.列表的其他操作
5.1 :count:計算某元素出現次數
代碼示例:
list = ["one","two",3,4,"five"]
v = list.count("two") #計算two出現的次數
print(v)
輸出結果:
1
5.2:extend:用於在列表末尾一次性追加另一個序列中的多個值
代碼示例:
a = [1,2,3]
b = [4,5,6]
a.extend(b) #把b加到a裡面
print(a)
print(b)
輸出結果:
[1, 2, 3, 4, 5, 6]
[4, 5, 6]
5.3:index根據內容找位置,輸出得是第一個匹配內容的索引位置
代碼示例:
list = ["one","two",3,4,"five"]
T = list.index("five") #查找five的索引值
print(T)
輸出結果:
4
5.4 合集
1.reverse:用於反向列表中元素
2.sort:對原列表進行排序
reverse -- 排序規則,reverse = True 降序(由大到小), reverse = False 升序(由小到大)(預設)
3.in:查一個數據在不在列表內
4.type:身份判斷:判斷一個對象是不是列表
代碼示例:
list0 = ["one","two",str(3),str(4),"five"]
list0.reverse() #反向列表中元素
print(list0)
list0.sort(reverse=True) #由大到小de對原列表進行排序
print(list0)
a = "six" in list0 #判單six在不在列表裡
print(a)
b = type(list0) is list #判斷list0是不是列表
print(b)
輸出結果:
['five', '4', '3', 'two', 'one']
['two', 'one', 'five', '4', '3']
False
True
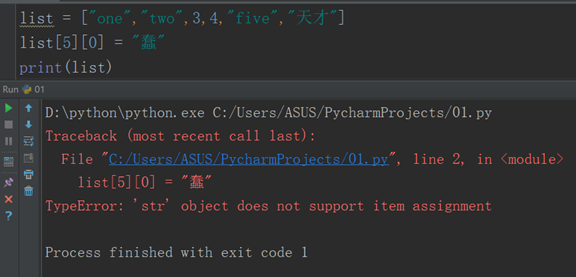
6.列表練習題:
list = ["one","two",3,4,"five","天才"]
把list列表中的天才的 天 改成 蠢
代碼示例:
list = ["one","two",3,4,"five","天才"]
v = list[5].replace("天","蠢")
list[5] = v
print(list)
輸出結果:
['one', 'two', 3, 4, 'five', '蠢才']
註意:字元串不能通過索引值修改,只能通過索引值取出來。(⬇)
七.元組
Python 的元組與列表類似,不同之處在於元組的元素不能修改。
元組使用小括弧,列表使用方括弧。
元組創建很簡單,只需要在括弧中添加元素,並使用逗號隔開即可。
1. 創建空元組
tup1 = ()
2. 元組中只包含一個元素時,需要在元素後面添加逗號,否則括弧會被當作運算符使用:
代碼示例:
tup1 = (50)
print(type(tup1)) # 不加逗號,類型為整型
tup1 = (50,)
print(type(tup1)) # 加上逗號,類型為元組
輸出結果:
<class 'int'>
<class 'tuple'>
3. 元組可以使用下標索引來訪問元組中的值
4. 可以對元組進行連接組合
5.元組可以計算長度len()
6.元組中的元素值是不允許刪除的,但我們可以使用del語句來刪除整個元組
7.重點:
元組的兒子不能修改,但是孫子可以,元組的元素不能修改,但是元組的元素的元素是可以修改的。
代碼示例:
tuple1 = ("one","two","three",[1,2,"zrh"],(1,2,3),"four")
tuple1[3][1] = 3
print(tuple1)
tuple1[3].append("q")
print(tuple1)
輸出結果:
('one', 'two', 'three', [1, 3, 'zrh'], (1, 2, 3), 'four')
('one', 'two', 'three', [1, 3, 'zrh', 'q'], (1, 2, 3), 'four')
八.字典
字典是另一種可變容器模型,且可存儲任意類型對象。
字典的每個鍵值(key=>value)對,用冒號(:)分割,每個對之間用逗號(,)分割,整個字典包括在花括弧({})中
鍵必須是唯一的,但值則不必。
值可以取任何數據類型,但鍵必須是不可變類型。
不可變類型:整型、字元串、元組
可變類型:字典、列表
格式:變數名 = {鍵:值,鍵:值}
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
1.:dict.get
1.1通過鍵取值
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
print(dict1.get("name"))
輸出結果:
zrh
1.2()參數,如果鍵不存在,就用後面的結果當作預設值。
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
print(dict1.get("key",999))
輸出結果:
999
2.:dict.keys() 、 dict.values() and dict.items()
經常和for迴圈一起使用
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
a = dict1.keys() #查看所有鍵
print(type(a)) #查看a的類型
print(a)
print(dict1.values()) #查看所有值
print(dict1.items()) #查看所有鍵值對
輸出結果:
<class 'dict_keys'>
dict_keys(['name', 'age', 'height'])
dict_values(['zrh', 20, 75])
dict_items([('name', 'zrh'), ('age', 20), ('height', 75)])
3.增加鍵值對
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
dict1["hobby"] = "eat"
print(dict1)
輸出結果:
{'name': 'zrh', 'age': 20, 'height': 75, 'hobby': 'eat'}
如果增加的鍵已經存在,那就是改的功能。
4.刪除
代碼示例:
dict1 = {
"name":"zrh",
"age":20,
"height":75
}
del dict1["name"] #刪除指定鍵值對
print(dict1)
dict1.clear()
print(dict1) #清空字典中所有鍵值對,但空字典還存在
dict2 = {
"name":"zrh",
"age":20,
"height":75
}
a = dict2.pop("name") #通過鍵去刪除,並可以返回相應的值
print(a)
print(dict2)
b = dict2.popitem()
print(b)
print(dict2) #隨機刪除一對鍵值對,並且返回相相應鍵值對
輸出結果:
{'age': 20, 'height': 75}
{}
zrh
{'age': 20, 'height': 75}
('height', 75)
{'age': 20}
5.嵌套
字典裡面可嵌套字典或者列表都可以,列表頁都可以嵌套字典。
在修改時,遇到字典用鍵,遇到列表用索引值,然後查找出來之後賦值即可,其他操作一樣,反正一句話:
遇到字典用鍵,遇到列表用索引值。


