
ETL概述 ETL(Extraction-Transformation-Loading)是將業務系統的數據經過抽取、清洗轉換之後載入到數據倉庫的過程,目的是將企業中的分散、零亂、標準不統一的數據整合到一起,為企業的決策提供分析依據, ETL是BI(商業智能)項目重要的一個環節。 數據治理流程 數據挖 ...
ETL概述
ETL(Extraction-Transformation-Loading)是將業務系統的數據經過抽取、清洗轉換之後載入到數據倉庫的過程,目的是將企業中的分散、零亂、標準不統一的數據整合到一起,為企業的決策提供分析依據, ETL是BI(商業智能)項目重要的一個環節。
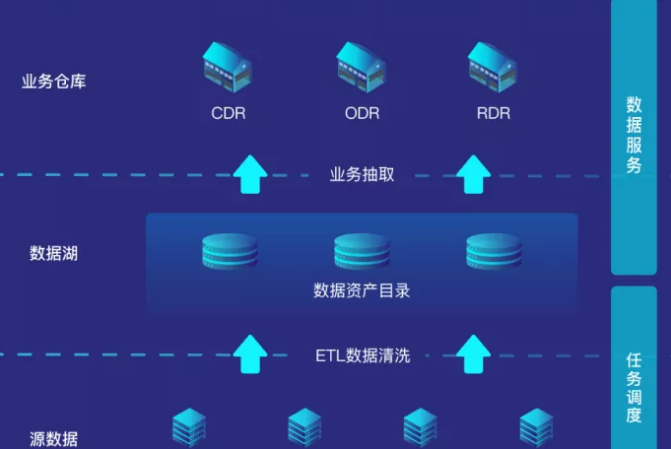
數據治理流程
數據挖掘一般是指從大量的數據中通過演算法搜索隱藏於其中信息的過程。它通常與電腦科學有關,並通過統計、線上分析處理、情報檢索、機器學習、專家系統(依靠過去的經驗法則)和模式識別等諸多方法來實現上述目標。它的分析方法包括:分類、估計、預測、相關性分組或關聯規則、聚類和複雜數據類型挖掘。

1)數據的採集
首先得有數據,數據的收集有兩個方式,第一個方式是拿,專業點的說法叫抓取或者爬取,例如搜索引擎就是這麼做的,它把網上的所有的信息都下載到它的數據中心,然後你一搜才能搜出來。
2)數據的傳輸
一般會通過隊列方式進行,因為數據量實在是太大了,數據必須經過處理才會有用,可是系統處理不過來,只好排好隊,慢慢的處理。
3)數據的存儲
現在數據就是金錢,掌握了數據就相當於掌握了錢。要不然網站怎麼知道你想買什麼呢?就是因為它有你歷史的交易的數據,這個信息可不能給別人,十分寶貴,所以需要存儲下來。
4)數據的清洗和分析
上面存儲的數據是原始數據,原始數據多是雜亂無章的,有很多垃圾數據在裡面,因而需要清洗和過濾,得到一些高質量的數據。對於高質量的數據,就可以進行分析,從而對數據進行分類,或者發現數據之間的相互關係,得到知識。
註:第三與第四個步驟,現存後清洗和先清洗再存,在真是的業務場景中可以適當互換。
5)數據的檢索和挖掘
檢索就是搜索,所謂外事問google,內事問百度。挖掘,僅僅搜索出來已經不能滿足人們的要求了,還需要從信息中挖掘出相互的關係。
6)數據的載入與應用
怎麼友好的展示與傳遞給用戶為數據挖掘工作做好閉環。
數據治理工具類
1)數據採集工具
1、針對日誌文件類
|
工具 |
定義 |
|
Logstash |
Logstash是一個開源數據收集引擎,具有實時管道功能。Logstash可以動態地將來自不同數據源的數據統一起來,並將數據標準化到所選擇的目的地。 |
|
Filebeat |
Filebeat 作為一個輕量級的日誌傳輸工具可以將日誌推送到中心 Logstash。 |
|
Fluentd |
Fluentd 創建的初衷主要是儘可能的使用 JSON 作為日誌輸出,所以傳輸工具及其下游的傳輸線不需要猜測子字元串裡面各個欄位的類型。這樣,它為幾乎所有的語言都提供庫,即可以將它插入到自定義的程式中。 |
|
Logagent |
Logagent 是 Sematext 提供的傳輸工具,它用來將日誌傳輸到 Logsene(一個基於SaaS 平臺的 Elasticsearch API)。 |
|
Rsylog |
絕大多數 Linux 發佈版本預設的守護進程,rsyslog 讀取並寫入 /var/log/messages。它可以提取文件、解析、緩衝(磁碟和記憶體)以及將它們傳輸到多個目的地,包括 Elasticsearch 。可以從此處找到如何處理 Apache 以及系統日誌。 |
|
Logtail |
阿裡雲日誌服務的生產者,目前在阿裡集團內部機器上運行,經過3年多時間的考驗,目前為阿裡公有雲用戶提供日誌收集服務。 |
關於詳解日誌採集工具Logstash、Filebeat、Fluentd、Logagent、Rsylog和Logtail在優勢、劣勢
2、針對爬蟲類
頁面下載 --> 頁面解析 --> 數據存儲
(1)頁面下載器
對於下載器而言,python的庫requests能滿足大部分測試+抓取需求,進階工程化scrapy,動態網頁優先找API介面,如果有簡單加密就破解,實在困難就使用splash渲染。
(2)頁面解析器
①BeautifulSoup(入門級):Python爬蟲入門BeautifulSoup模塊
②pyquery(類似jQuery):Python爬蟲:pyquery模塊解析網頁
③lxml:Python爬蟲:使用lxml解析網頁內容
④parsel:Extract text using CSS or XPath selectors
⑤scrapy的Selector (強烈推薦, 比較高級的封裝,基於parsel)
⑥選擇器(Selectors):python爬蟲:scrapy框架xpath和css選擇器語法
---------------------
總結:
解析器直接使用scrapy的Selector 就行,簡單、直接、高效。
(3)數據存儲
①txt文本:Python全棧之路:文件file常用操作
②csv文件:python讀取寫入csv文件
③sqlite3 (python自帶):Python編程:使用資料庫sqlite3
④MySQL:SQL:pymysql模塊讀寫mysql數據
⑤MongoDB:Python編程:mongodb的基本增刪改查操作
---------------------
總結:
數據存儲沒有什麼可深究的,按照業務需求來就行,一般快速測試使用MongoDB,業務使用MySQL
(4)其他工具
①execjs :執行js
Python爬蟲:execjs在python中運行javascript代碼
②pyv8: 執行js
mac安裝pyv8模塊-JavaScript翻譯成python
③html5lib
Python爬蟲:scrapy利用html5lib解析不規範的html文本
2)數據清洗工具
1、DataWrangler
基於網路的服務是斯坦福大學的可視化組設計來清洗和重排數據的.文本編輯非常簡單。例如,當我選擇大標題為“Reported crime in Alabama”的樣本數據的某行的“Alabama”,然後選擇另一組數據的“Alaska”,它會建議提取每州的名字。把滑鼠停留在建議上,就可以看到用紅色突出顯示的行。
2、Google Refine
它可以導入導出多種格式的數據,如標簽或逗號分隔的文本文件、Excel、XML和JSON文件。Refine設有內置演算法,可以發現一些拼寫不一樣但實際上應分為一組的文本。導入你的數據後,選擇編輯單元格->聚類,編輯,然後選擇要用的演算法。數據選項,提供快速簡單的數據分佈概貌。這個功能可以揭示那些可能由於輸入錯誤導致的異常——例如,工資記錄不是80,000美元而竟然是800,000美元;或指出不一致的地方——例如薪酬數據記錄之間的差異,有的是計時工資,有的是每周支付,有的是年薪。除了數據管家功能,Google Refine還提供了一些有用的分析工具,例如排序和篩選。
3、Logstash
Logstash 是一款強大的數據處理工具,它可以實現數據傳輸,格式處理,格式化輸出,還有強大的插件功能,常用於日誌處理。
3)數據存儲工具
數據存儲主要分為結構化數據的存儲和非結構化數據的存儲。
1、結構化數據
(1)定義
一般指存儲在資料庫中,具有一定邏輯結構和物理結構的數據,最為常見的是存儲在關係資料庫中的數據;非結構化數據:一般指結構化數據以外的數據,這些數據不存儲在資料庫中,而是以各種類型的文本形式存放,其中Web上的一些數據(內嵌於HTML或XML標記中)又具有一定的邏輯結構和物理結構,被稱為半結構數據。
(2)存儲系統
目前比較成熟的結構化存儲系統有Oracle、MySQL、Hadoop等。
2、非結構化數據
(1)定義
非結構化數據是數據結構不規則或不完整,沒有預定義的數據模型,不方便用資料庫二維邏輯表來表現的數據。包括所有格式的辦公文檔、文本、圖片、XML, HTML、各類報表、圖像和音頻/視頻信息等等。
(2)存儲方式
1)使用文件系統存儲文件,而在資料庫中存儲訪問路徑。這種方式的優點是實現簡單,不需要DBMS的高級功能,但是這種方式無法實現文件的事務性訪問,不便於數據備份和恢復,不便於數據遷移等;
2)使用阿裡雲OSS的文件存儲功能。
4)數據計算工具
數據計算分為實時計算、線上計算、離線計算。
1、數據實時計算
Apache Storm
2、數據線上計算
Elasticsearch
MySQL
3、數據離線計算
HaDoop Hive
5)數據分析工具
1、對數據矩陣科學計算:Python的numpy庫
2、對數據切片等常規處理:強大的pandas庫
3、對數據建模處理:sklearn庫
6)數據載入工具
1、數據的可視化處理:Python中的matplotlib和seaborn庫
2、常用的BI可視化工具:Tableu和帆軟
3、ECharts
——————————————
閱讀推薦

