
NN與2NN工作機制 思考:NameNode中的元數據是存儲在哪裡的? 假設存儲在NameNode節點的硬碟中,因為經常需要隨機訪問和響應客戶請求,必然效率太低,所以是存儲在記憶體中的 但是,如果存儲在記憶體中,一旦斷電,元數據丟失,整個集群便無法工作,因此會在硬碟中產生備份元數據的Fsimage 但是 ...
NN與2NN工作機制
思考:NameNode中的元數據是存儲在哪裡的?
- 假設存儲在NameNode節點的硬碟中,因為經常需要隨機訪問和響應客戶請求,必然效率太低,所以是存儲在記憶體中的
- 但是,如果存儲在記憶體中,一旦斷電,元數據丟失,整個集群便無法工作,因此會在硬碟中產生備份元數據的Fsimage
- 但是這樣又會有新的問題出現,當記憶體中的元數據更新時,需要同時更新Fsimage,否則會發生一致性的問題;
- 但要更新的話,又會導致效率過低
- 因此,又引入了Edits文件,用來記錄客戶端更新元數據的每一步操作(只進行追加操作,效率很高),每當元數據有更新時,就把更新的操作記錄到Edits中,Edits也存放在硬碟中
- 這樣,一旦NameNode節點斷電,可以通過Fsimage和Edits合併,生成最新的元數據
- 如果長時間一直添加操作數據到Edits,會導致文件數據過大,效率降低,而一旦斷電會造成恢復時間過長,因此需要對Fsimage與Edits定期合併
- 而如果這些操作都交給NameNode節點完成,則又會造成效率降低
- 因此引入了一個輔助NameNode的新的節點SecondaryNameNode,專門用於Fsimage和Edits的合併
NN與2NN工作機制
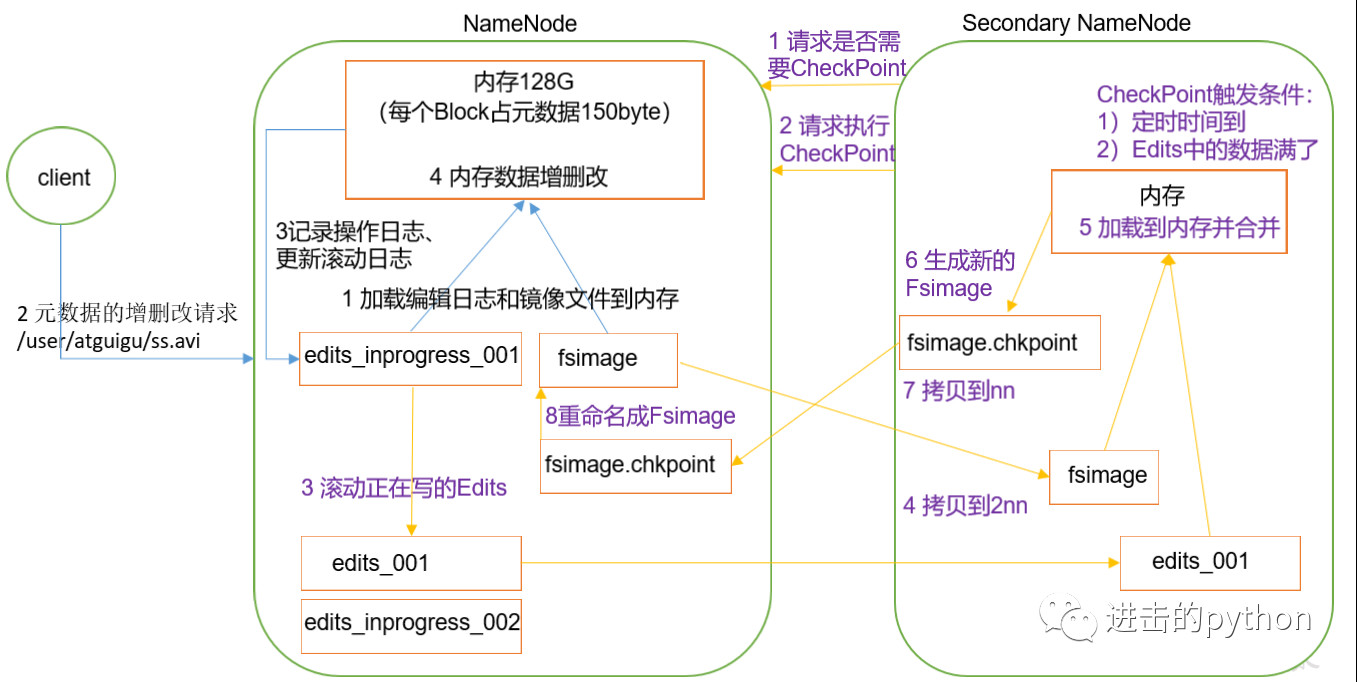
- 第一階段:NameNode啟動
- 第一次啟動NameNode格式化之後,創建Fsimage,Edits文件實在啟動NameNode時生成的;如果不是第一次創建,會直接載入Edits和Fsimage到記憶體,在HDFS啟動時會有一次Edits和Fsimage的合併操作,此時NameNode記憶體就持有最新的元數據信息
- 客戶端對元數據發送增刪改(不記錄查詢操作,因為查詢不改變元數據)的請求
- NameNode會首先記錄操作日誌,,更新滾動日誌
- NameNode在記憶體中對元數據進行增刪改操作
- 第二階段:SecondaryNameNode工作
- SecondaryNameNode定期詢問NameNode是否需要CheckPoint,直接帶回NameNode是否檢查的結果
- 當CheckPoint定時時間到了或者Edits中的數據滿了,SecondaryNameNode請求執行CheckPoint
- NameNode滾動正在寫的Edits,並生成新的空的edits.inprogress_002,滾動的目的是給Edits打個標記,以後所有更新操作都寫入edits.inprogress_002中
- 原來的Fsimage和Edits文件會拷貝到SecondaryNameNode節點,SecondaryNameNode會將它們載入到記憶體合併,生成新的鏡像文件fsimage.chkpoint
- 然後將新的鏡像文件fsimage.chkpoint拷貝給NameNode,重命名為Fsimage,替換原來的鏡像文件
- 因此,最後當NameNode啟動時,只需要載入之前未合併的Edits和Fsimage即可更新到最新的元數據信息
Fsimage與Edits解析
- NameNode在格式化之後,將在
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current/目錄下產生如下文件:
-rw-rw-r--. 1 kocdaniel kocdaniel 945 9月 25 20:27 fsimage_0000000000000000000
-rw-rw-r--. 1 kocdaniel kocdaniel 62 9月 25 20:27 fsimage_0000000000000000000.md5
-rw-rw-r--. 1 kocdaniel kocdaniel 4 9月 25 20:27 seen_txid
-rw-rw-r--. 1 kocdaniel kocdaniel 205 9月 25 10:25 VERSION- fsimage:HDFS文件系統元數據的一個永久性的檢查點,其中包含HDFS文件系統的所有目錄和文件inode的序列化信息
- Edits(啟動NameNode時生成):存放HDFS文件系統所有更新操作,文件系統客戶端執行的寫操作首先會被記錄到Edits文件中
- seen_txis:保存的時一個數字,是最新的edits_後的數字
- 每次NameNode啟動的時候都會將Fsimage文件讀入記憶體,載入Edits文件里的更新操作,保證記憶體中元數據的內容是最新的,同步的
- oiv查看Fsimage文件
- 基本語法:
hdfs oiv -p 文件類型 -i 鏡像文件 -o 轉換後文件輸出路徑
- oev查看Edits文件
- 基本語法:
hdfs oev -p 文件類型 -i 編輯日誌 -o 轉換後文件輸出路徑
Checkpoint時間設置
預設情況下,SecondaryNameNode每隔一個小時或者當操作次數超過100萬次時執行一次,但是操作次數的統計SecondaryNameNode自己做不到,需要藉助NameNode,所以還有一個參數設置是namenode每隔一分鐘檢查一次操作次數,當操作次數達到100萬時SecondaryNameNode開始執行Checkpoint,三個參數的設置都在hdfs_site.xml配置文件中,配置如下:
# SecondaryNameNode每隔一個小時執行一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
# SecondaryNameNode當操作次數超過100萬次時執行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作動作次數</description>
</property>
# NameNode一分鐘檢查一次操作次數
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分鐘檢查一次操作次數</description>
</property >
NameNode故障處理
NameNode故障後有兩種處理方式:
NameNode故障處理方式一:直接將SecondaryNameNode目錄下的數據直接拷貝到NameNode目錄下,然後重新啟動NameNode
NameNode故障處理方式二:使用-importCheckpoint選項啟動NameNode守護進程,從而將SecondaryNameNode目錄下的數據直接拷貝到NameNode目錄下
- 首先需要在hdfs_site.xml文件中添加如下配置
# SecondaryNameNode每隔兩分鐘執行一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
# 指定namenode生成的文件目錄
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
- 然後,如果SecondaryNameNode和NameNode不在一個主機節點上,需要將SecondaryNameNode存儲數據的目錄拷貝到NameNode存儲數據的平級目錄,並刪除in_use.lock文件
- 最後導入檢查點數據(等待一會兒ctrl + c結束掉)
[kocdaniel@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint註意:執行完該命令後,觀察namenode已經啟動(臨時啟動),而且每2分鐘檢查一次,如果確定已經恢復了數據,我們ctrl+c停止,然後自己手動起namenode
ctrl+c之後,重啟namenode即可恢複數據,但是並不能完全恢復,可能會將最新的Edits文件中的操作丟失
集群安全模式
什麼是安全模式
- NameNode啟動時,首先將Fsimage載入記憶體,再執行Edits中的各項操作,一旦在記憶體中成功建立文件系統元數據的映像,則創建一個新的Fsimage文件和一個空的編輯日誌,然後開始監聽DataNode請求,在這個過程期間,NameNode一直運行在安全模式下,也就是NameNode對於客戶端是只讀的
- DataNode啟動時,系統中的數據塊的位置並不是由NameNode維護的,而是由塊列表的形式存儲在DataNode中,在系統的正常操作期間,NameNode會在記憶體中保留所有塊的映射信息。在安全模式下,各個DataNode會向NameNode發送最新的塊列表信息,NameNode瞭解足夠多的塊列表信息後,即可高效運行文件系統
- 安全模式退出判斷:如果滿足最小副本條件,NameNode會在30秒之後退出安全模式。最小副本條件是指在整個文件系統中99.9%的塊滿足最小副本級別(預設為1),即99.9%的塊至少有一個副本存在。
- 在啟動一個剛剛格式化的HDFS集群時,由於系統中還沒有任何塊,所以NameNode不會進入安全模式
基本語法
- 集群處於安全模式時,不能執行任何重要操作(寫操作)。
- 集群啟動完成後,自動退出安全模式
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式狀態)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:進入安全模式狀態)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:離開安全模式狀態)
# wait是指,如果在腳本中寫入此命令,則腳本將等待安全模式退出後自動執行
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式狀態)NameNode多目錄配置
- NameNode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性,提高高可用性
- 具體需要在hdfs_site.xml中加入如下配置:
# 指定目錄的路徑
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>


