
點擊關註本 "公眾號" 獲取文檔最新更新,並可以領取配套於本指南的 《前端面試手冊》 以及 最標準的簡歷模板 . 前言 Babel 是現代 JavaScript 語法轉換器,幾乎在任何現代前端項目中都能看到他的身影,其背後的原理對於大部分開發者還屬於黑盒,不過 Babel 作為一個工具真的有瞭解背後 ...
點擊關註本公眾號獲取文檔最新更新,並可以領取配套於本指南的 《前端面試手冊》 以及最標準的簡歷模板.
前言
Babel 是現代 JavaScript 語法轉換器,幾乎在任何現代前端項目中都能看到他的身影,其背後的原理對於大部分開發者還屬於黑盒,不過 Babel 作為一個工具真的有瞭解背後原理的必要嗎?
如果只是 Babel 可能真沒有必要,問題是其背後的原理在我們開發中應用過於廣泛了,包括不限於: eslint jshint stylelint css-in-js prettier jsx vue-template uglify-js postcss less 等等等等,從模板到代碼檢測,從混淆壓縮到代碼轉換,甚至編輯器的代碼高亮都與之息息相關.
如果有興趣就可以搞一些黑魔法: 前端工程師可以用編譯原理做什麼?
前置
Babel 大概分為三大部分:
- 解析: 將代碼(其實就是字元串)轉換成 AST( 抽象語法樹)
- 轉換: 訪問 AST 的節點進行變換操作生成新的 AST
- 生成: 以新的 AST 為基礎生成代碼
我們主要通過打造一個微型 babel 來瞭解 babel 的基本原理,這個微型 babel 的功能很單一也很雞肋,但是依然有400行代碼,其實現細節與 babel 並不相同,因為我們省去了很多額外的驗證和信息解析,因為單單一個相容現代 JavaScript 語法的 parser 就需要5000行代碼,並不利於我們快速瞭解 babel 的基本實現,所以這個微型 babel可以說比較雞肋(因為除了展示之外沒啥用處),但是比較完整展示了 babel 的基本原理,你可以以此作為入門,在入門之後如果仍有興趣,可以閱讀:
代碼解析
parser 概念
代碼解析,也就是我們常說的 Parser, 用於將一段代碼(文本)解析成一個數據結構.
例如這段 es6的代碼
const add = (a, b) => a + b我們用 babel 解析後便是這種形式:
{
"type": "File",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"program": {
"type": "Program",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"sourceType": "module",
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 0
},
"end": {
"line": 1,
"column": 27
}
},
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 6
},
"end": {
"line": 1,
"column": 27
}
},
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"loc": {
"start": {
"line": 1,
"column": 6
},
"end": {
"line": 1,
"column": 9
},
"identifierName": "add"
},
"name": "add"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 12,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 12
},
"end": {
"line": 1,
"column": 27
}
},
"id": null,
"generator": false,
"expression": true,
"async": false,
"params": [
{
"type": "Identifier",
"start": 13,
"end": 14,
"loc": {
"start": {
"line": 1,
"column": 13
},
"end": {
"line": 1,
"column": 14
},
"identifierName": "a"
},
"name": "a"
},
{
"type": "Identifier",
"start": 16,
"end": 17,
"loc": {
"start": {
"line": 1,
"column": 16
},
"end": {
"line": 1,
"column": 17
},
"identifierName": "b"
},
"name": "b"
}
],
"body": {
"type": "BinaryExpression",
"start": 22,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 22
},
"end": {
"line": 1,
"column": 27
}
},
"left": {
"type": "Identifier",
"start": 22,
"end": 23,
"loc": {
"start": {
"line": 1,
"column": 22
},
"end": {
"line": 1,
"column": 23
},
"identifierName": "a"
},
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 26,
"end": 27,
"loc": {
"start": {
"line": 1,
"column": 26
},
"end": {
"line": 1,
"column": 27
},
"identifierName": "b"
},
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"directives": []
}
}我們以解析上面的 es6箭頭函數為目標,來寫一個簡單的 parser.
文本 ---> AST 的過程中有兩個關鍵步驟:
- 詞法分析: 將代碼(字元串)分割為token流,即語法單元成的數組
- 語法分析: 分析token流(上面生成的數組)並生成 AST
詞法分析(Tokenizer -- 詞法分析器)
要做詞法分析,首先我們需要明白在 JavaScript 中哪些屬於語法單元
- 數字:JavaScript 中的科學記數法以及普通數組都屬於語法單元.
- 括弧:『(』『)』只要出現,不管任何意義都算是語法單元
- 標識符:連續字元,常見的有變數,常量(例如: null true),關鍵字(if break)等等
- 運算符:+、-、*、/等等
- 當然還有註釋,中括弧等
在我們 parser 的過程中,應該換一個角度看待代碼,我們平時工作用的代碼.本質是就是字元串或者一段文本,它沒有任何意義,是 JavaScript 引擎賦予了它意義,所以我們在解析過程中代碼只是一段字元串.
仍然以下麵代碼為例
const add = (a, b) => a + b我們期望的結果是類似這樣的
[
{ type: "identifier", value: "const" },
{ type: "whitespace", value: " " },
...
]那麼我們現在開始打造一個Tokenizer(詞法分析器)
// 詞法分析器,接收字元串返回token數組
export const tokenizer = (code) => {
// 儲存 token 的數組
const tokens = [];
// 指針
let current = 0;
while (current < code.length) {
// 獲取指針指向的字元
const char = code[current];
// 我們先處理單字元的語法單元 類似於`;` `(` `)`等等這種
if (char === '(' || char === ')') {
tokens.push({
type: 'parens',
value: char,
});
current ++;
continue;
}
// 我們接著處理標識符,標識符一般為以字母、_、$開頭的連續字元
if (/[a-zA-Z\$\_]/.test(char)) {
let value = '';
value += char;
current ++;
// 如果是連續字那麼將其拼接在一起,隨後指針後移
while (/[a-zA-Z0-9\$\_]/.test(code[current]) && current < code.length) {
value += code[current];
current ++;
}
tokens.push({
type: 'identifier',
value,
});
continue;
}
// 處理空白字元
if (/\s/.test(char)) {
let value = '';
value += char;
current ++;
//道理同上
while (/\s]/.test(code[current]) && current < code.length) {
value += code[current];
current ++;
}
tokens.push({
type: 'whitespace',
value,
});
continue;
}
// 處理逗號分隔符
if (/,/.test(char)) {
tokens.push({
type: ',',
value: ',',
});
current ++;
continue;
}
// 處理運算符
if (/=|\+|>/.test(char)) {
let value = '';
value += char;
current ++;
while (/=|\+|>/.test(code[current])) {
value += code[current];
current ++;
}
// 當 = 後面有 > 時為箭頭函數而非運算符
if (value === '=>') {
tokens.push({
type: 'ArrowFunctionExpression',
value,
});
continue;
}
tokens.push({
type: 'operator',
value,
});
continue;
}
// 如果碰到我們詞法分析器以外的字元,則報錯
throw new TypeError('I dont know what this character is: ' + char);
}
return tokens;
};
那麼我們基本的詞法分析器就打造完成,因為只針對這一個es6函數,所以沒有做額外的工作(額外的工作量會非常龐大).
const result = tokenizer('const add = (a, b) => a + b')
console.log(result);
/**
[ { type: 'identifier', value: 'const' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'add' },
{ type: 'whitespace', value: ' ' },
{ type: 'operator', value: '=' },
{ type: 'whitespace', value: ' ' },
{ type: 'parens', value: '(' },
{ type: 'identifier', value: 'a' },
{ type: ',', value: ',' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'b' },
{ type: 'parens', value: ')' },
{ type: 'whitespace', value: ' ' },
{ type: 'ArrowFunctionExpression', value: '=>' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'a' },
{ type: 'whitespace', value: ' ' },
{ type: 'operator', value: '+' },
{ type: 'whitespace', value: ' ' },
{ type: 'identifier', value: 'b' } ]
**/1.3 語法分析
語法分析要比詞法分析複雜得多,因為我們接下來的是示意代碼,所以做了很多“武斷”的判斷來省略代碼,即使這樣也是整個微型 babel 中代碼量最多的.
語法分析之所以複雜,是因為要分析各種語法的可能性,需要開發者根據token流(上一節我們生成的 token 數組)提供的信息來分析出代碼之間的邏輯關係,只有經過詞法分析 token 流才能成為有結構的抽象語法樹.
做語法分析最好依照標準,大多數 JavaScript Parser 都遵循estree規範
由於標準內容很多,感興趣的可以去閱讀,我們目前只介紹幾個比較重要的標準:
語句(Statements): 語句是 JavaScript 中非常常見的語法,我們常見的迴圈、if 判斷、異常處理語句、with 語句等等都屬於語句
// 典型的for 迴圈語句
for (var i = 0; i < 7; i++) {
console.log(i);
}表達式(Expressions): 表達式是一組代碼的集合,它返回一個值,表達式是另一個十分常見的語法,函數表達式就是一種典型的表達式,如果你不理解什麼是表達式, MDN上有很詳細的解釋.
// 函數表達式
var add = function(a, b) {
return a + b
}聲明(Declarations): 聲明分為變數聲明和函數聲明,表達式(Expressions)中的函數表達式的例子用聲明的寫法就是下麵這樣.
// 函數聲明
function add(a, b) {
return a + b
}你可能有點糊塗,為了理清其中的關係,我們就下麵的代碼為例來解讀
// 函數表達式
var add = function(a, b) {
return a + b
}首先這段代碼的整體本質是是一個變數聲明(VariableDeclarator):
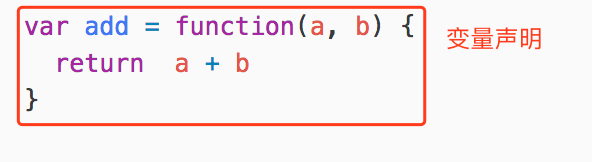
而變數被聲明為一個函數表達式(FunctionExpression):

函數表達式中的大括弧在內的為塊狀語句(BlockStatement):
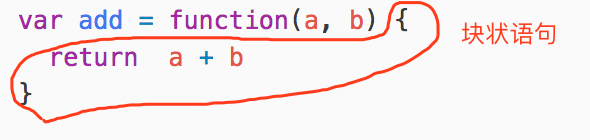
塊狀語句內 return 的部分是返回語句(ReturnStatement):

而 return 的其實是一個二元運算符或者叫二元表達式(BinaryExpression):

上面提到的這些有些屬於表達式,有些屬於聲明也有些屬於語句,當然還有更多我們沒提到的,它們被語法分析之後被叫做AST(抽象語法樹).
我們做語法分析的時候思路也是類似的,要分析哪一層的 token 到底屬於表達式或者說語句,如果是語句那麼是塊狀語句(BlockStatement)還是Loops,如果是 Loops 那麼屬於while 迴圈(WhileStatement)還是for 迴圈(ForStatement)等等,其中甚至難免要考慮作用域的問題,因此語法分析的複雜也體現在此.
const parser = tokens => {
// 聲明一個全時指針,它會一直存在
let current = -1;
// 聲明一個暫存棧,用於存放臨時指針
const tem = [];
// 指針指向的當前token
let token = tokens[current];
const parseDeclarations = () => {
// 暫存當前指針
setTem();
// 指針後移
next();
// 如果字元為'const'可見是一個聲明
if (token.type === 'identifier' && token.value === 'const') {
const declarations = {
type: 'VariableDeclaration',
kind: token.value
};
next();
// const 後面要跟變數的,如果不是則報錯
if (token.type !== 'identifier') {
throw new Error('Expected Variable after const');
}
// 我們獲取到了變數名稱
declarations.identifierName = token.value;
next();
// 如果跟著 '=' 那麼後面應該是個表達式或者常量之類的,額外判斷的代碼就忽略了,直接解析函數表達式
if (token.type === 'operator' && token.value === '=') {
declarations.init = parseFunctionExpression();
}
return declarations;
}
};
const parseFunctionExpression = () => {
next();
let init;
// 如果 '=' 後面跟著括弧或者字元那基本判斷是一個表達式
if (
(token.type === 'parens' && token.value === '(') ||
token.type === 'identifier'
) {
setTem();
next();
while (token.type === 'identifier' || token.type === ',') {
next();
}
// 如果括弧後跟著箭頭,那麼判斷是箭頭函數表達式
if (token.type === 'parens' && token.value === ')') {
next();
if (token.type === 'ArrowFunctionExpression') {
init = {
type: 'ArrowFunctionExpression',
params: [],
body: {}
};
backTem();
// 解析箭頭函數的參數
init.params = parseParams();
// 解析箭頭函數的函數主體
init.body = parseExpression();
} else {
backTem();
}
}
}
return init;
};
const parseParams = () => {
const params = [];
if (token.type === 'parens' && token.value === '(') {
next();
while (token.type !== 'parens' && token.value !== ')') {
if (token.type === 'identifier') {
params.push({
type: token.type,
identifierName: token.value
});
}
next();
}
}
return params;
};
const parseExpression = () => {
next();
let body;
while (token.type === 'ArrowFunctionExpression') {
next();
}
// 如果以(開頭或者變數開頭說明不是 BlockStatement,我們以二元表達式來解析
if (token.type === 'identifier') {
body = {
type: 'BinaryExpression',
left: {
type: 'identifier',
identifierName: token.value
},
operator: '',
right: {
type: '',
identifierName: ''
}
};
next();
if (token.type === 'operator') {
body.operator = token.value;
}
next();
if (token.type === 'identifier') {
body.right = {
type: 'identifier',
identifierName: token.value
};
}
}
return body;
};
// 指針後移的函數
const next = () => {
do {
++current;
token = tokens[current]
? tokens[current]
: { type: 'eof', value: '' };
} while (token.type === 'whitespace');
};
// 指針暫存的函數
const setTem = () => {
tem.push(current);
};
// 指針回退的函數
const backTem = () => {
current = tem.pop();
token = tokens[current];
};
const ast = {
type: 'Program',
body: []
};
while (current < tokens.length) {
const statement = parseDeclarations();
if (!statement) {
break;
}
ast.body.push(statement);
}
return ast;
};
至此我們暴力 parser 了token 流,最終得到了簡陋的抽象語法樹:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"identifierName": "add",
"init": {
"type": "ArrowFunctionExpression",
"params": [
{
"type": "identifier",
"identifierName": "a"
},
{
"type": "identifier",
"identifierName": "b"
}
],
"body": {
"type": "BinaryExpression",
"left": {
"type": "identifier",
"identifierName": "a"
},
"operator": "+",
"right": {
"type": "identifier",
"identifierName": "b"
}
}
}
}
]
}
代碼轉換
如何轉換代碼?
在 Babel 中我們使用者最常使用的地方就是代碼轉換,大家常用的 Babel 插件就是定義代碼轉換規則而生的,而代碼解析和生成這一頭一尾都主要是 Babel 負責。
比如我們要用 babel 做一個React 轉小程式的轉換器,babel工作流程的粗略情況是這樣的:
- babel 將 React 代碼解析為抽象語法樹
- 開發者利用 babel 插件定義轉換規則,根據原本的抽象語法樹生成一個符合小程式規則的新抽象語法樹
- babel 則根據新的抽象語法樹生成代碼,此時的代碼就是符合小程式規則的新代碼
例如 Taro就是用 babel 完成的小程式語法轉換.
到這裡大家就明白了,我們轉換代碼的關鍵就是根據當前的抽象語法樹,以我們定義的規則生成新的抽象語法樹,轉換的過程就是生成新抽象語法樹的過程.
遍歷抽象語法樹(實現遍歷器traverser)
抽象語法樹是一個樹狀數據結構,我們要生成新語法樹,那麼一定需要訪問 AST 上的節點,因此我們需要一個工具來遍歷抽象語法樹的節點.
const traverser = (ast, visitor) => {
// 如果節點是數組那麼遍曆數組
const traverseArray = (array, parent) => {
array.forEach((child) => {
traverseNode(child, parent);
});
};
// 遍歷 ast 節點
const traverseNode = (node, parent) => {
const method = visitor[node.type];
if (method) {
method(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'VariableDeclaration':
traverseArray(node.init.params, node.init);
break;
case 'identifier':
break;
default:
throw new TypeError(node.type);
}
};
traverseNode(ast, null);
};轉換代碼(實現轉換器transformer)
我們要轉換的代碼const add = (a, b) => a + b其實是個變數聲明,按理來講我們要轉換為es5的代碼也應該是個變數聲明,比如這種:
var add = function(a, b) {
return a + b
}當然也可以不按規則,直接生成一個函數聲明,像這樣:
function add(a, b) {
return a + b
}這次我們把代碼轉換為一個es5的函數聲明

我們之前的遍歷器traverser接收兩個參數,一個是 ast 節點對象,一個是 visitor,visitor本質是掛載不同方法的 JavaScript 對象,visitor 也叫做訪問者,顧名思義它會訪問 ast 上每個節點,然後根據針對不同節點用相應的方法做出不同的轉換.
const transformer = (ast) => {
// 新 ast
const newAst = {
type: 'Program',
body: []
};
// 在老 ast 上加一個指針指向新 ast
ast._context = newAst.body;
traverser(ast, {
// 對於變數聲明的處理方法
VariableDeclaration: (node, parent) => {
let functionDeclaration = {
params: []
};
if (node.init.type === 'ArrowFunctionExpression') {
functionDeclaration.type = 'FunctionDeclaration';
functionDeclaration.identifierName = node.identifierName;
}
if (node.init.body.type === 'BinaryExpression') {
functionDeclaration.body = {
type: 'BlockStatement',
body: [{
type: 'ReturnStatement',
argument: node.init.body
}],
};
}
parent._context.push(functionDeclaration);
},
//對於字元的處理方法
identifier: (node, parent) => {
if (parent.type === 'ArrowFunctionExpression') {
// 忽略我這暴力的操作....領略大意即可..
ast._context[0].params.push({
type: 'identifier',
identifierName: node.identifierName
});
}
}
});
return newAst;
};
生成代碼(實現生成器generator)
我們之前提到過,生成代碼這一步實際上是根據我們轉換後的抽象語法樹來生成新的代碼,我們會實現一個函數, 他接受一個對象( ast),通過遞歸生成最終的代碼
const generator = (node) => {
switch (node.type) {
// 如果是 `Program` 結點,那麼我們會遍歷它的 `body` 屬性中的每一個結點,並且遞歸地
// 對這些結點再次調用 codeGenerator,再把結果列印進入新的一行中。
case 'Program':
return node.body.map(generator)
.join('\n');
// 如果是FunctionDeclaration我們分別遍歷調用其參數數組以及調用其 body 的屬性
case 'FunctionDeclaration':
return 'function' + ' ' + node.identifierName + '(' + node.params.map(generator) + ')' + ' ' + generator(node.body);
// 對於 `Identifiers` 我們只是返回 `node` 的 identifierName
case 'identifier':
return node.identifierName;
// 如果是BlockStatement我們遍歷調用其body數組
case 'BlockStatement':
return '{' + node.body.map(generator) + '}';
// 如果是ReturnStatement我們調用其 argument 的屬性
case 'ReturnStatement':
return 'return' + ' ' + generator(node.argument);
// 如果是ReturnStatement我們調用其左右節點並拼接
case 'BinaryExpression':
return generator(node.left) + ' ' + node.operator + ' ' + generator(node.right);
// 沒有符合的則報錯
default:
throw new TypeError(node.type);
}
};
至此我們完成了一個簡陋的微型 babel,我們開始試驗:
const compiler = (input) => {
const tokens = tokenizer(input);
const ast = parser(tokens);
const newAst = transformer(ast);
const output = generator(newAst);
return output;
};
const str = 'const add = (a, b) => a + b';
const result = compiler(str);
console.log(result);
// function add(a,b) {return a + b}
我們成功地將一個es6的箭頭函數轉換為es5的function函數.
最後
我們可以通過這個微型 babel 瞭解 babel 的工作原理,如果讓你對編譯原理產生興趣並去深入那是更好的, babel集合包 是有數十萬行代碼的巨大工程,我們用區區幾百行代碼只能展示其最基本的原理,代碼有很多不合理之處,如果想真正的瞭解 babel 歡迎閱讀器源碼.
前端可以利用編譯原理相關的東西還有很多,除了我們常見的es6轉換工具 babel,代碼檢測的 eslint等等,我們還可以:
- 小程式多端轉義Taro
- 小程式熱更新js 解釋器
- babel與錯誤監控瀏覽器端 JavaScript 異常監控
- 模板引擎
- css 預處理後處理等等
- ...
這篇文章受the-super-tiny-compiler啟發而來.
公眾號
想要實時關註筆者最新的文章和最新的文檔更新請關註公眾號程式員面試官,後續的文章會優先在公眾號更新.
簡歷模板: 關註公眾號回覆「模板」獲取
《前端面試手冊》: 配套於本指南的突擊手冊,關註公眾號回覆「fed」獲取



