
1. 索引 1.1 索引原理 1.什麼是索引 ? 目錄 索引就是建立起的一個在存儲表階段就有的一個存儲結構,能在查詢的時候加速。 2.索引的重要性: 讀寫比例 為 10:1,所有讀(查詢)的速度就至關重要了。 3.索引的原理: block 磁碟預讀原理 相當於讀文件操作的 :for line in ...
1. 索引
1.1 索引原理
1.什麼是索引 ?-- 目錄
索引就是建立起的一個在存儲表階段就有的一個存儲結構,能在查詢的時候加速。
2.索引的重要性:
讀寫比例 為 10:1,所有讀(查詢)的速度就至關重要了。
3.索引的原理:
block 磁碟預讀原理
相當於讀文件操作的 :for line in f

每個索引塊可以存4096個位元組
讀硬碟的io操作的時間非常的長,比CPU執行指令的時間長很多,儘量的減少IO次數才是讀寫數據的主要要解決的問題。
1.2 資料庫的存儲方式
1.資料庫的存儲方式:
1.新的數據結構 —— 樹
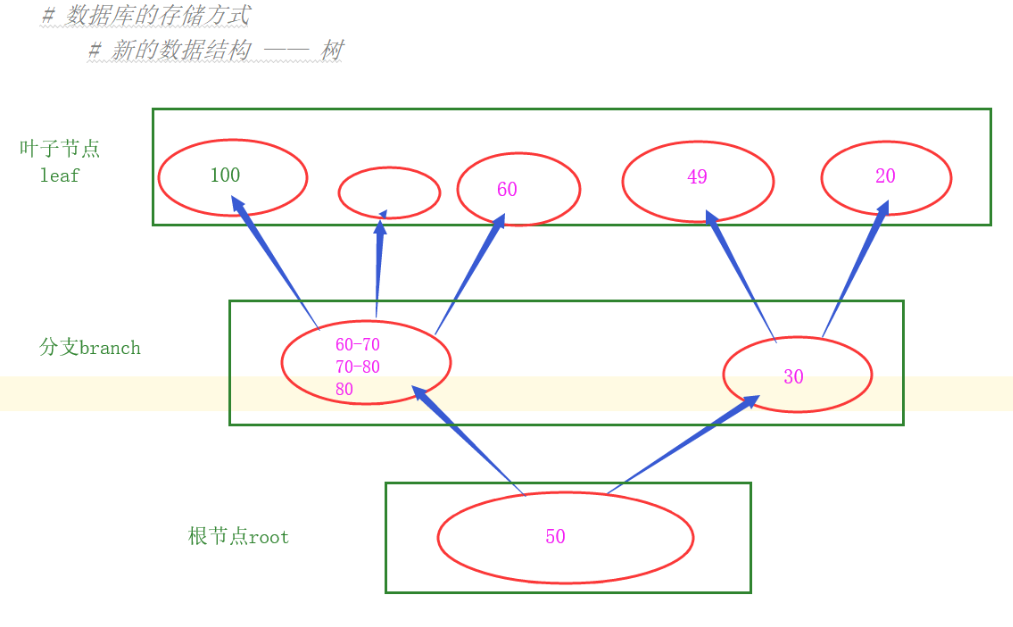
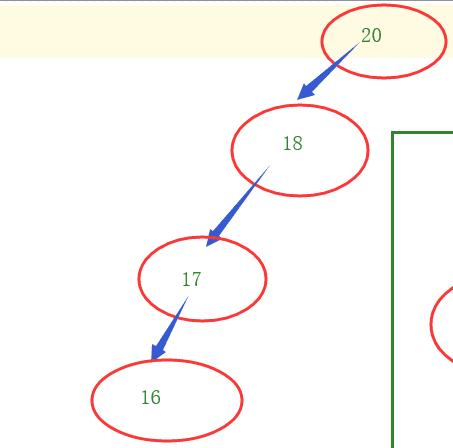
缺點:容易出現數據只在一端,造成讀取慢(io操作次數多)。
2.平衡樹 balance tree - b樹
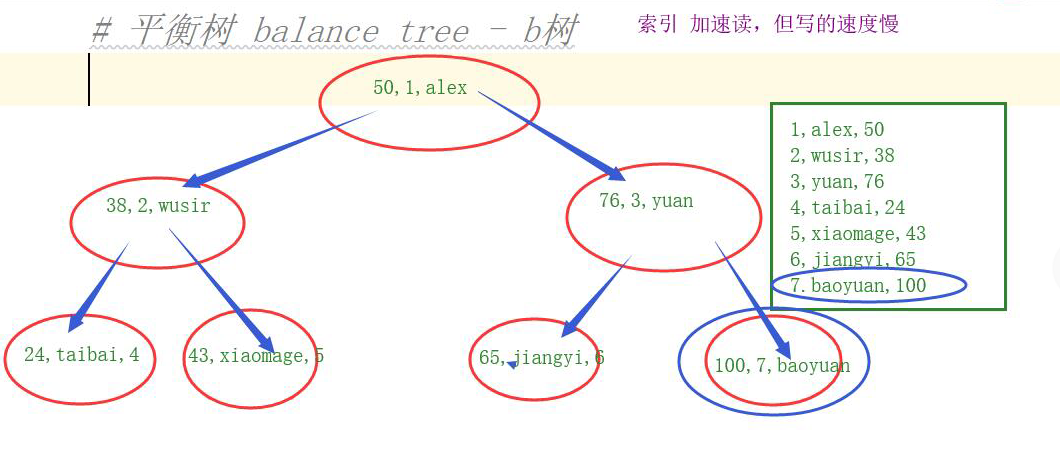
缺點:存儲的數據長度大、能存儲的數據條數有限,造成書的高度比較大,讀取效率很低。
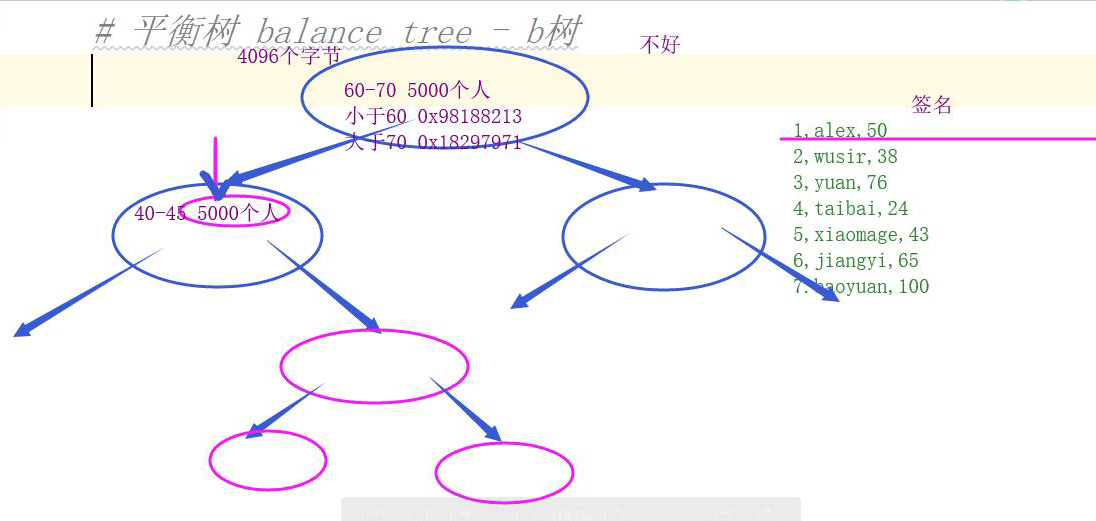
3.在b樹的基礎上進行了改良 - b+樹
- 1.分支節點和根節點都不在存儲實際的數據了,讓分支和根節點能存儲更多的索引的信息,就降低了樹的高度,所有的實際數據都存儲在葉子節點中
- 2.在葉子節點之間加入了雙向的鏈式結構,方便在查詢中的範圍條件。
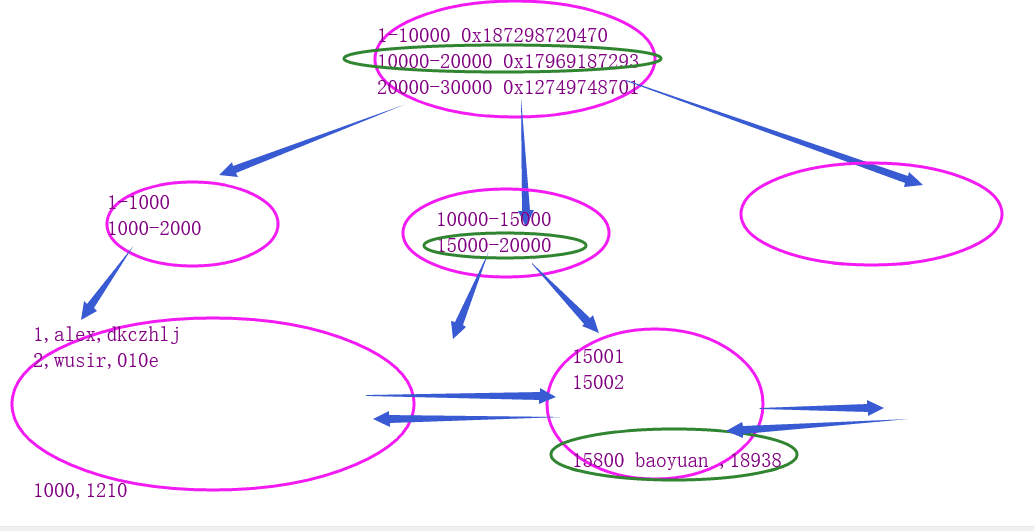
4.mysql當中所有的b+樹索引的高度都基本控制在3層:
- 1.io操作的次數非常穩定
- 2.有利於通過範圍查詢
5.什麼會影響索引的效率? —— 樹的高度
- 1.對哪一列創建索引,選擇儘量短的列做索引
- 2.對區分度高的列建索引,重覆率超過了10%,那麼就不適合創建索引。
1.3 聚集索引和輔助索引
在innodb中 :聚集索引和輔助索引並存的
聚集索引 - 主鍵 、更快
只有主鍵是聚集索引
數據直接存儲在樹結構的葉子節點
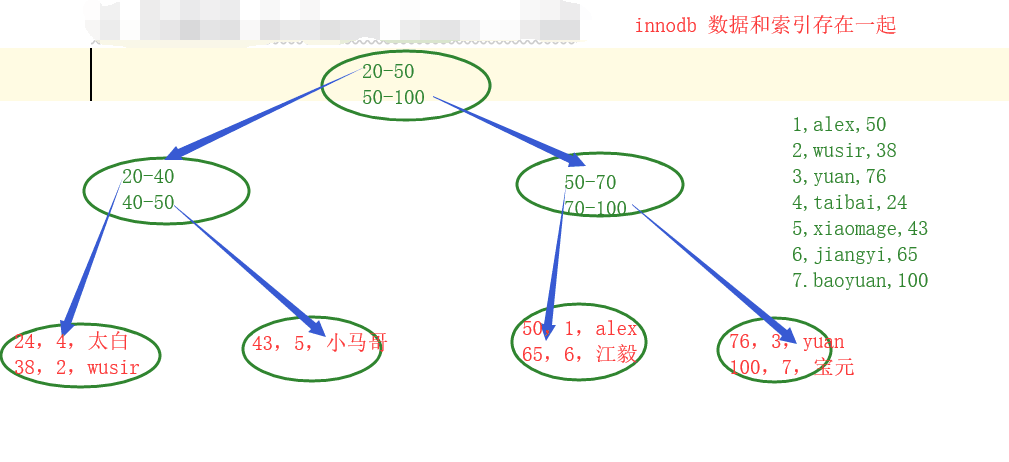
輔助索引 - 除了主鍵之外所有的索引都是輔助索引 、稍慢
數據不直接存儲在樹中

在myisam中 :只有輔助索引,沒有聚集索引
1.4 索引的種類
1.索引的種類:
primary key 主鍵 ,是聚集索引 ,約束的作用:非空 + 唯一
聯合主鍵
unique 自帶索引 ,是輔助索引 ,約束的作用:唯一
聯合唯一
index 是輔助索引,沒有約束作用
聯合索引
註意:按大項分有三個種類:primary key 、unique 、index
細分有6個種類:primary key 、聯合主鍵 、unique 、聯合唯一 、index 、聯合索引
2.看一下如何創建索引、創建索引之後的變化
create index 索引名字 on 表(欄位)
刪除索引 :drop index 索引名 on 表名字;
3.索引是如何發揮作用的?
select * from 表 where id = xxxxx;
- 以email為條件查詢:
- 不添加索引的時候,肯定慢
- 查詢的欄位不是索引欄位,也慢
- id作為條件的時候:
- 在id欄位沒有索引的時候,效率低
- 在id欄位有索引之後,效率高
1.5 索引不生效的原因
1.索引不生效的原因:
<1.>要查詢的數據的範圍大
與範圍相關的:
1.< >= <= !=(!=幾乎命中不了索引)
2.between and
select * from 表 order by age limit 0,5;
select * from 表 where id between 1000000 and 1000005;
3.like
- 結果的範圍大 索引不生效
- 如果 abc% 索引生效,%abc索引就不生效
<2.>如果一列內容的區分度不高,索引也不生效
- 如:name列
<3.>索引列不能在條件中參與計算
- select * from s1 where id*10 = 1000000; 索引不生效
<4.>對兩列內容進行條件查詢
and :and條件兩端的內容,優先選擇一個有索引的,並且樹形結構更好的,來進行查詢(效率也會更高)。兩個條件都成立才能完成where條件,先完成範圍小的,縮小後麵條件的壓力。
- select * from s1 where id =1000000 and email = 'eva1000000@oldboy';
or :帶or條件的,不會進行優化,只是根據條件從左到右依次篩選。
條件中帶有or的要想命中索引,這些條件中所有的列都是索引列。
- select * from s1 where id =1000000 or email = 'eva1000000@oldboy';
<5.>聯合索引
創建聯合索引:create index ind_mix on s1(id,name,email);
select * from s1 where id =1000000 and email = 'eva1000000@oldboy'; 能命中索引1.在聯合索引中如果使用了or條件索引就不能生效:
select * from s1 where id =1000000 or email = 'eva1000000@oldboy'; 不能命中索引
2.最左首碼原則 :在聯合索引中,條件必須含有在創建索引的時候的第一個索引列。
select * from s1 where id =1000000; 能命中索引 select * from s1 where email = 'eva1000000@oldboy'; 不能命中索引 # 聯合索引 (a,b,c,d) a,b 、 a,c 、 a 、 a,d 、 a,b,d 、 a,c,d 、 a,b,c,d # 等含有a索引的都能命中索引 # 不含a索引的其他索引都不能命中。3.在整個條件中,從開始出現模糊匹配的那一刻,索引就失效了
select * from s1 where id >1000000 and email = 'eva1000001@oldboy'; 不能命中索引 select * from s1 where id =1000000 and email like 'eva%'; 能命中引
2.什麼時候用聯合索引?
- 只對a 、對abc 條件進行索引,而不會對b,對c進行單列的索引的時候。
3.對於單列的索引:
- 選擇一個區分度高的列建立索引,條件中的列不要參與計算,條件的範圍儘量小,使用and作為條件的連接符
4.使用or來連接多個條件:
- 在滿足上述條件(單列的索引)的基礎上,對or相關的所有列分別創建索引。
1.6 一些索引名詞
1.覆蓋索引
如果我們使用索引作為條件查詢,查詢完畢之後,不需要回表查,就是覆蓋索引。

explain select id from s1 where id = 1000000;
explain select count(id) from s1 where id > 1000000;
2.合併索引
對兩個欄位分別創建索引,由於sql的條件讓兩個索引同時生效了,那麼這個時候這兩個索引就成為了合併索引
3.執行計劃 explain
如果你想在執行sql語句之前就知道sql語句的執行情況,那麼可以使用執行計劃。
# 情況1:
如果有30000000條數據,使用sql語句查詢需要20s,
explain sql語句 --> 並不會真正的執行sql,而是會給你列出一個執行計劃
# 情況2:
20條數據 --> 30000000
explain sql4.建議
<1>建表、使用sql語句的時候註意的:
- char 代替 varchar
- 連表 代替 子查詢
- 創建表的時候 :固定長度的欄位放在前面
<2> utf8 與 utf8mb4 :
- utf8 不是能全量顯示中文的編碼,如很多不常用的生僻字 和 Emoji 表情(Emoji 是一種特殊的 Unicode 編碼,常見於 ios 和 android 手機上),以及任何新增的 Unicode 字元等等
- utf8mb4 能全量顯示中文的編碼
以後如果遇到使用 utf8 出現亂碼的情況,可以更改為 utf8mb4 進行編碼。
1.7 慢查詢優化的基本步驟
- 先運行看看是否真的很慢,註意設置SQL_NO_CACHE
1.where條件單表查,鎖定最小返回記錄表。這句話的意思是把查詢語句的where都應用到表中返回的記錄數最小的表開始查起,單表每個欄位分別查詢,看哪個欄位的區分度最高
2.explain查看執行計劃,是否與第1步預期一致(從鎖定記錄較少的表開始查詢)
3.order by limit 形式的sql語句讓排序的表優先查
4.瞭解業務方使用場景
5.加索引時參照建索引的幾大原則
6.觀察結果,不符合預期繼續從0分析
1.8 慢日誌管理
1.慢日誌
- 執行時間 > 10
- 未命中索引
- 日誌文件路徑
2.配置:
記憶體
show variables like '%query%';
show variables like '%queries%';
set global 變數名 = 值
配置文件
mysqld --defaults-file='E:\wupeiqi\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini'
my.conf內容:
- slow_query_log = ON
- slow_query_log_file = D:/....
註意:修改配置文件之後,需要重啟服務
3.日誌管理
詳見網址:https://www.cnblogs.com/Eva-J/articles/10126413.html#_label8
2. pymysql模塊
2.1 使用pymysql模塊
python相當於是客戶端
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",database='day40') # python與mysql連接
cur = conn.cursor() # 創建 資料庫操作符:游標
# 增加數據
cur.execute('insert into employee(emp_name,sex,age,hire_date) '
'values ("郭凱豐","male",40,20190808)')
# 刪除數據
cur.execute('delete from employee where id = 18')
conn.commit() # 提交
conn.close()
# 查詢數據
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",database='day40')
cur = conn.cursor(pymysql.cursors.DictCursor) # 想要輸出為字典格式時加上pymysql.cursors.DictCursor
cur.execute('select * from employee where id > 10')
ret = cur.fetchone() # 查詢第一條數據
print(ret['emp_name'])
ret = cur.fetchmany(5) # 查詢5條數據
ret = cur.fetchall() # 查詢所有的數據
print(ret)
conn.close()2.2 數據備份和事務
1.資料庫的邏輯備份
語法:mysqldump -h 伺服器 -u用戶名 -p密碼 資料庫名 > 備份文件.sql
#示例:
#單庫備份
mysqldump -uroot -p123 db1 > db1.sql
mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql
#多庫備份
mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql
#備份所有庫
mysqldump -uroot -p123 --all-databases > all.sql2.數據恢復
#方法一:
[root@egon backup]# mysql -uroot -p123 < /backup/all.sql
#方法二:
mysql> use db1;
mysql> SET SQL_LOG_BIN=0; #關閉二進位日誌,只對當前session生效
mysql> source /root/db1.sql3.事務
begin; # 開啟事務
select * from emp where id = 1 for update; # 查詢id值,for update添加行鎖;
update emp set salary=10000 where id = 1; # 完成更新
commit; # 提交事務(解鎖)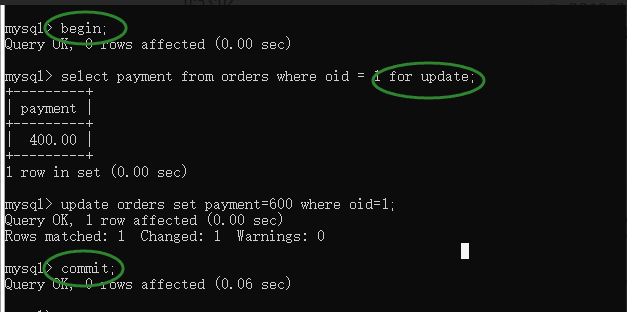
註意3個關鍵點:
- begin
- commit
- for update
2.3 sql註入
create table userinfo(
id int primary key auto_increment,
name char(12) unique not null,
password char(18) not null
)
insert into userinfo(name,password) values('alex','alex3714')
# 用戶名和密碼到資料庫里查詢數據
# 如果能查到數據 說明用戶名和密碼正確
# 如果查不到,說明用戶名和密碼不對
username = input('user >>>')
password = input('passwd >>>')
sql = "select * from userinfo where name = '%s' and password = '%s'"%(username,password)
print(sql)
-- :表示註釋掉--之後的sql語句
select * from userinfo where name = 'alex' ;-- and password = '792164987034';
select * from userinfo where name = 219879 or 1=1 ;-- and password = 792164987034;
select * from userinfo where name = '219879' or 1=1 ;-- and password = '792164987034';上面的輸入情況都能查詢到結果,所以存在安全隱患,這種存在安全隱患的情況就叫 sql註入。
為了避免 sql註入,在用pymysql時,不要再自己去拼接sql語句了,要讓mysql模塊自己去拼接。
import pymysql
conn = pymysql.connect(host = '127.0.0.1',user = 'root',
password = '123',database='day41')
cur = conn.cursor()
username = input('user >>>')
password = input('passwd >>>')
sql = "select * from userinfo where name = %s and password = %s"
cur.execute(sql,(username,password)) # 讓mysql模塊去拼接
print(cur.fetchone())
cur.close()
conn.close()
