
1、什麼是分散式事務? 答:指一次大的操作由不同的小操作組成的,這些小的操作分佈在不同的伺服器上,分散式事務需要保證這些小操作要麼全部成功,要麼全部失敗。從本質上來說,分散式事務就是為了保證不同資料庫的數據一致性。 2、分散式事務產生的原因? 2.1 資料庫分庫分表 &ems ...
1、什麼是分散式事務?
答:指一次大的操作由不同的小操作組成的,這些小的操作分佈在不同的伺服器上,分散式事務需要保證這些小操作要麼全部成功,要麼全部失敗。從本質上來說,分散式事務就是為了保證不同資料庫的數據一致性。
2、分散式事務產生的原因?
2.1 資料庫分庫分表
當資料庫單表數據達到千萬級別,就要考慮分庫分表,那麼就會從原來的一個資料庫變成多個資料庫。例如如果一個操作即操作了01庫,又操作了02庫,而且又要保證數據的一致性,那麼就要用到分散式事務。
2.2 應用SOA化
所謂的SOA化,就是業務的服務化。例如電商平臺下單操作就會產生調用庫存服務扣減庫存和訂單服務更新訂單數據,那麼就會設計到訂單資料庫和庫存資料庫,為了保證數據的一致性,就需要用到分散式事務。
總結:其實上面兩種場景,歸根到底是要操作多資料庫,並且要保證數據的一致性,而產生的分散式事務的。
3、分散式事務解決方案
3.1 兩階段提交(2PC)
XA是一個分散式事務協議,由Tuxedo提出。XA中大致分為兩部分:事務管理器和本地資源管理器。其中本地資源管理器往往由資料庫實現,比如Oracle、Mysql等資料庫都實現了XA介面,而事務管理器作為全局的調度者,負責各個本地資源的提交回滾。
XA實現分散式事務的原理如下:
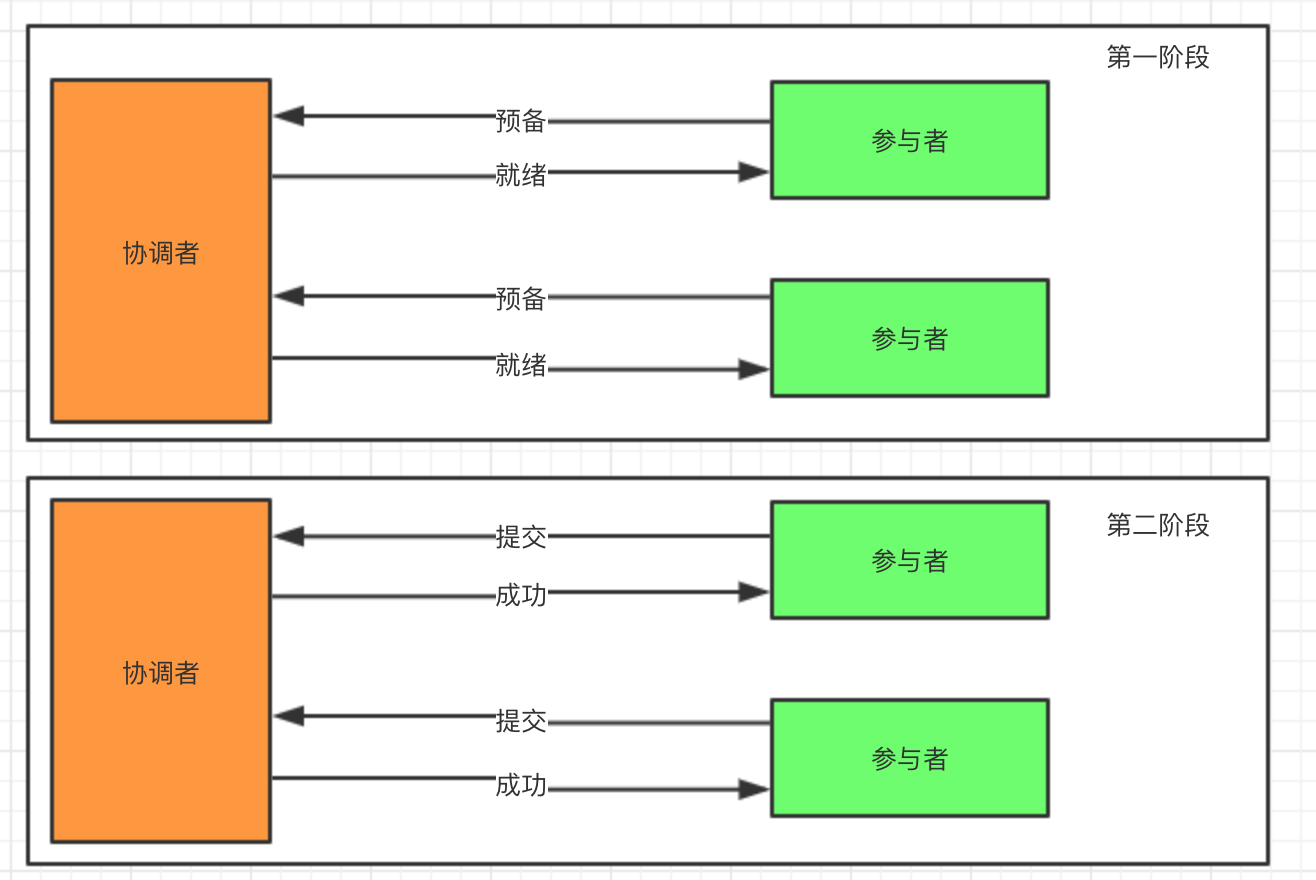
總結
二階段提交看起來確實能夠提供原子性的操作,但是它存在幾個缺點:
1、同步阻塞問題:執行過程中,所有參與節點都是事務阻塞型的。當參與者占有公共資源時,其他第三方節點訪問公共資源不得不處於阻塞狀態。
2、單點故障:由於(事務管理器)協調者的重要性,一旦協調者發生故障。(本地資源管理器)參與者會一直阻塞下去。尤其在第二階段,協調者發生故障,那麼所有的參與者還都處於鎖定事務資源的狀態中,而無法繼續完成事務操作。(如果是協調者掛掉,可以重新選舉一個協調者,但是無法解決因為協調者宕機導致的參與者處於阻塞狀態的問題)
3、數據不一致:在二階段提交的階段二中,當協調者向參與者發送commit請求之後,發生了局部網路異常或者在發送commit請求過程中協調者發生了故障,這會導致只有一部分參與者接收到了commit請求。而在這部分參與者接到commit請求之後就會執行commit操作。但是其他部分未接到commit請求的機器無法執行事務提交。於是整個分散式系統便出現了數據不一致的現象。
4、二階段無法解決的問題:參與者在發出commit消息之後宕機,而唯一接收到這條消息的協調者同時也宕機了。那麼即使協調者通過選舉協議產生了新的協調者,這條事務的狀態也是不確定的,沒人知道事務是否被已經提交了。
3.2 三階段提交(3PC)
3PC其實在2PC的基礎上增加了CanCommit階段,是2PC的變種,並引入了超時機制。一旦事務參與者遲遲沒有收到協調者的Commit請求,就會自動進行本地commit,這樣相對有效的解決了協調者單點故障的問題。但是,性能和數據一致性問題沒有根本解決。
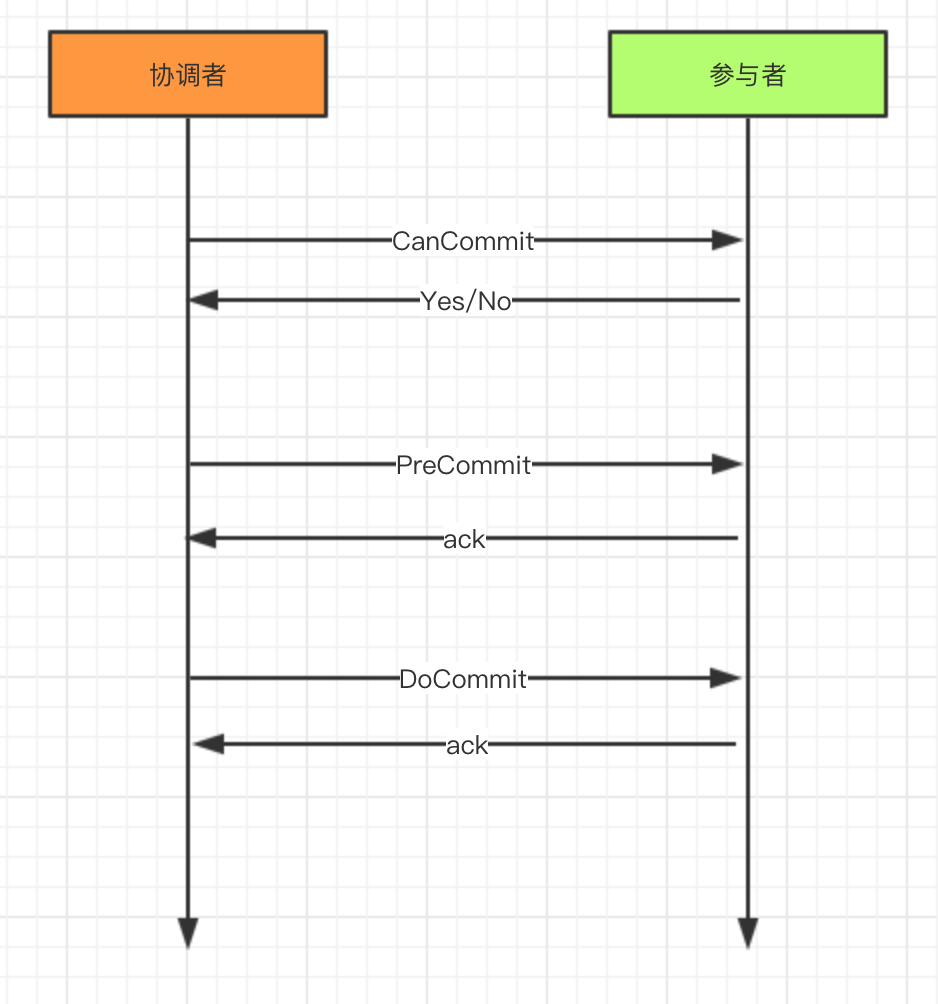
3PC分為三個階段:CanCommit、PreCommit、DoCommit
3.2.1 CanCommit階段
它跟2PC的 準備階段很像,協調者向參與者發送commit請求,參與者如果可以提交就返回Yes響應,否則返回No響應。
- 事務詢問:協調者向參與者發送CanCommit請求。詢問是否可以執行事務提交操作。然後開始等待參與者的響應
- 響應反饋:參與者接到CanCommit請求之後,正常情況下,如果其自身認為可以順利執行事務,則返回Yes響應,併進入預備狀態。否則返回No
3.2.2 PreCommit階段
協調者根據參與者的響應情況來決定是否可以進行事務的PreCommit操作。根據響應情況,有以下兩種可能:
- 假如協調者從所有的參與者獲得的反饋都是Yes,那麼就會執行事務的與執行。
- 發送預提交請求:協調者向參與者發送PreCommit請求,併進入Prepared階段。
- 事務預提交:參與者接收到PreCommit請求後,會執行事務操作,並將undo和redo信息記錄到事務日誌中。
- 響應反饋:如果參與者成功的執行了事務操作,則返回ACK響應,同時開始等待最終指令。
- 假如有任何一個參與者向協調者發送了No響應,或者等待超時,或者協調者都沒有接到參與者的響應,那麼就執行事務的中斷。
- 發送中斷請求:協調者向所有參與者發送abort請求。
- 中斷事務:參與者收到來自協調者的abort請求之後(或超時之後,仍未收到協調者的請求),執行事務的中斷。
3.2.3 doCommit階段
該階段進行真正的事務提交,也可以分為以下兩種情況:
- 執行提交
- 發送提交請求:協調接收到參與者發送的ACK響應,那麼將從預提交狀態進入到提交狀態。並向所有參與者發送doCommit請求。
- 事務提交:參與者接收到doCommit請求之後,執行正式的事務提交,併在完成事務提交之後釋放所有事務資源。
- 響應反饋:事務提交完之後,向協調者發送ACK響應。
- 完成事務:協調者接收到所有參與者的ACK響應之後,完成事務。
- 中斷事務
- 協調者沒有接收到參與者發送的ACK響應(可能是接受者發送的不是ACK響應,也可能響應超時),那麼就會執行中斷事務。
- 發送中斷請求:協調者向所有參與者發送abort請求
- 事務回滾:參與者接收到abort請求之後,利用其在階段二記錄的undo信息來執行事務的回滾操作,併在完成回滾之後釋放所有的事務資源。
- 反饋結果:參與者完成事務回滾之後,像協調者發送ACK消息。
- 中斷事務:協調者接收到參與者反饋的ACK消息之後,執行事務的中斷。
- 協調者沒有接收到參與者發送的ACK響應(可能是接受者發送的不是ACK響應,也可能響應超時),那麼就會執行中斷事務。
原理圖如下:
總結
相對於2PC而言,3PC對於協調者和參與者都設置了超時時間,而2PC只有協調者才擁有超時時間機制。這個優化解決了,參與者在長時間無法與協調者節點通訊的情況下,無法釋放資源的問題,因為參與者自身擁有超時機制會在超時後,自動進行本地commit從而進行釋放資源。而這種機制也側面降低了整個事務的阻塞時間和範圍。但是仍然沒有解決數據一致性問題,即在參與者收到PreCommit請求後等待最終指令,如果此時協調者無法與參與者正常通信,會導致參與者繼續提交事務,造成數據不一致。
3.3 補償事務(TCC)
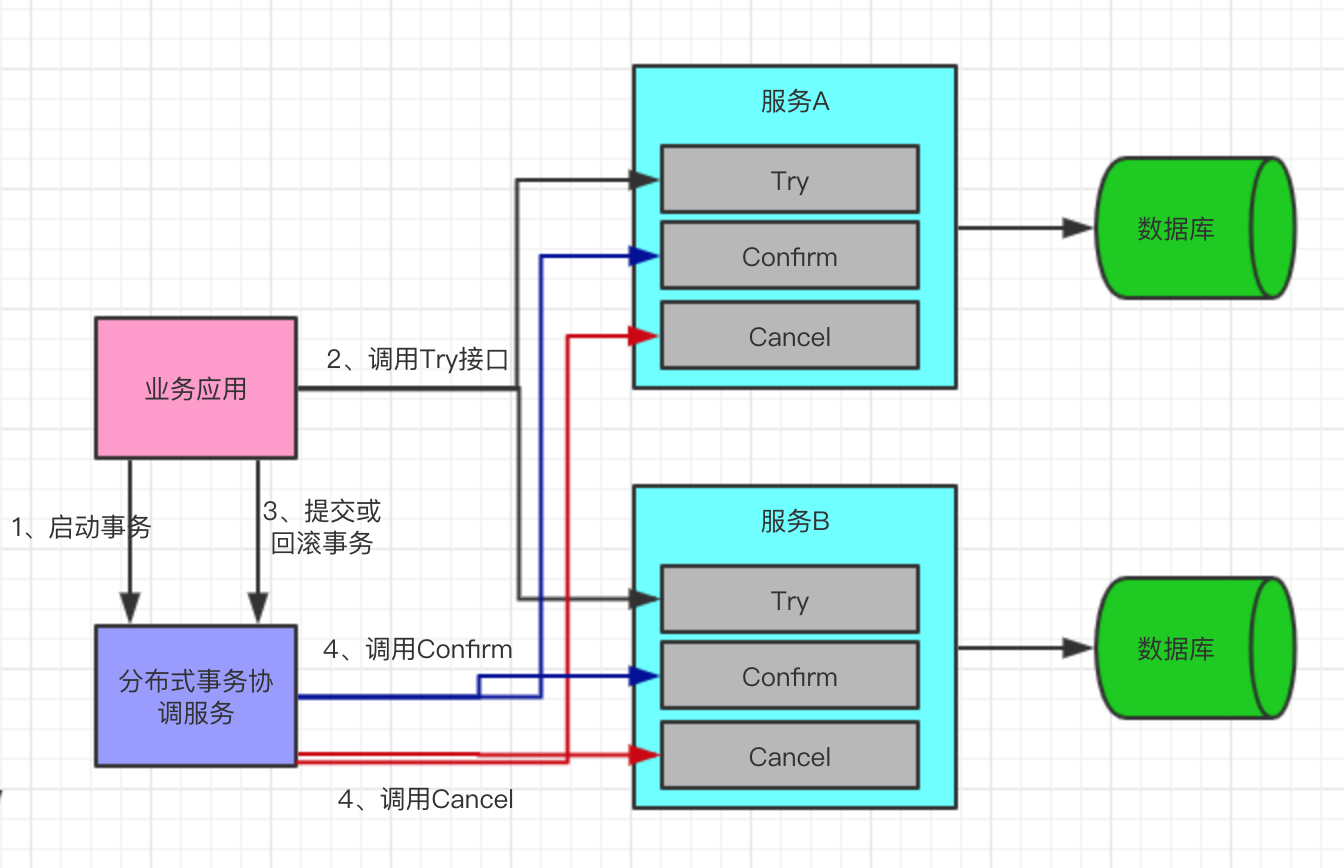
TCC(Try-Confirm-Cancel)又稱補償事務。它實際上與2PC、3PC一樣,都是分散式事務的一種實現方案而已。它分為三個操作:
- Try階段:主要是對業務系統做檢測及資源預留。
- Confirm階段:確認執行業務操作。
- Cancel階段:取消執行業務操作。
TCC事務的處理流程與2PC兩階段提交類似,不過2PC通常都是在DB層面,而TCC本質上就是應用層面的2PC,需要通過業務邏輯來實現。它的優勢在於,可以讓應用自己定義資料庫操作的粒度,使得降低鎖衝突、提交吞吐量。
不過對應用的侵入性非常強,業務邏輯的每個分支都需要實現try、confirm、cancel三個操作。
TCC原理圖如下:
3.4 消息事務+最終一致性
所謂的消息事務就是基於消息中間件的兩階段提交,本質上是中間件的一種特殊利用,他是將本地事務和發消息放在一個分散式事務里,保證要麼本地操作成功並且對外發消息成功,要麼兩者都失敗,開源的RocketMQ就支持這一特性,具體原理如下:
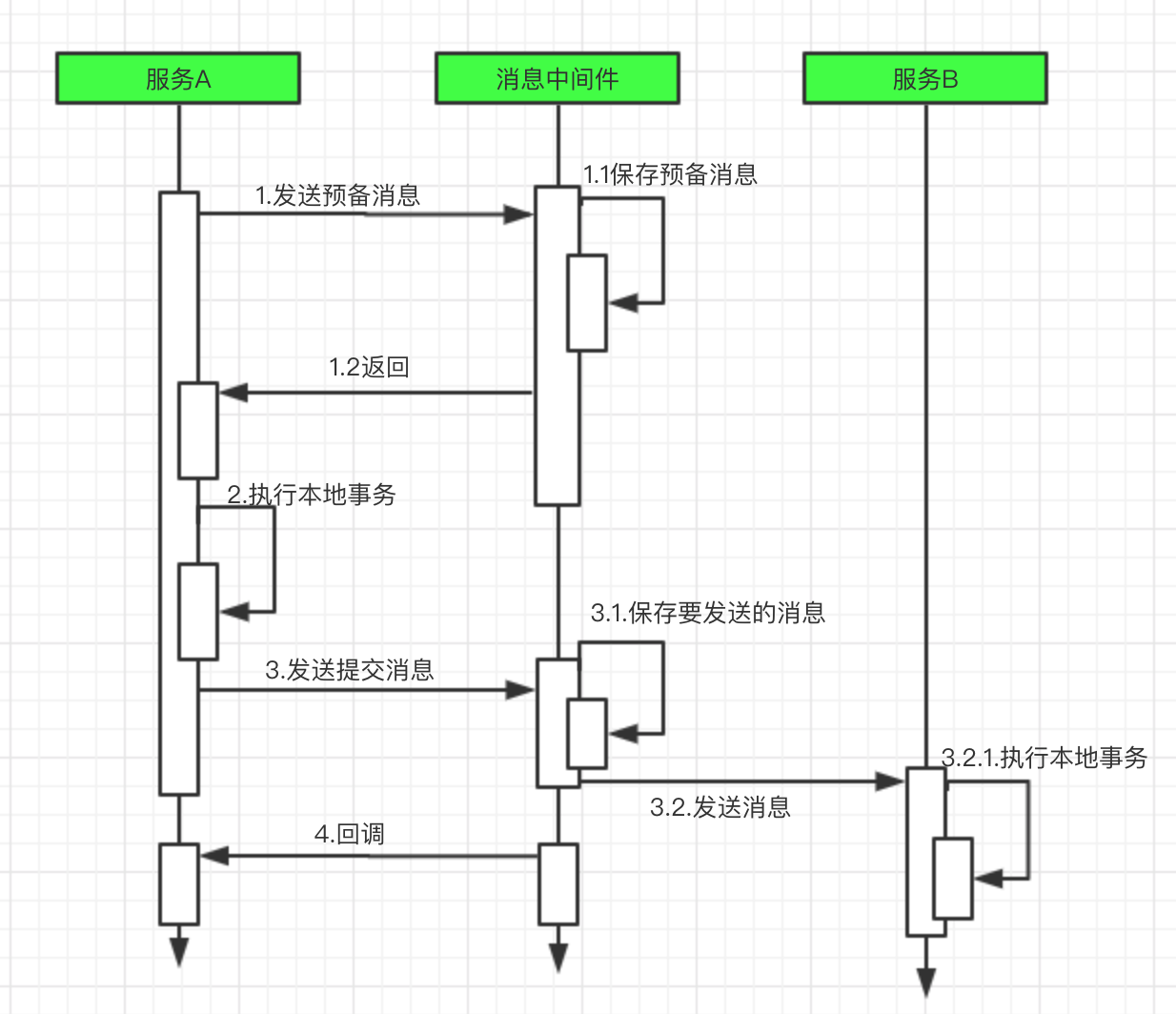
步驟如下:
1、:服務A向消息中間件發送一條預備消息。
2、消息中間件保存預備消息並返回成功。
3、服務A執行本地事務。
4、服務A發送提交消息給消息中間件,服務B接收到消息之後執行本地事務。
基於消息中間件的兩階段提交往往用在高併發場景下,將一個分散式事務拆成一個消息事務(服務A的本地操作+發消息)+服務B的本地操作,其中服務B的操作由消息驅動,只要消息事務成功,那麼服務A一定成功,消息也一定發出來了,這時候服務B會收到消息去執行本地操作,如果本地操作失敗,消息會重投,直到服務B操作成功,這樣就變相地實現了A與B的分散式事務。
以上幾個步驟可能存在異常情況,現在對其進行分析:
步驟一齣錯:則整個事務失敗,不會執行服務A的本地操作。
步驟二出錯:則整個事務失敗,不會執行服務A的本地操作。
步驟三出錯:需要做回滾預備消息,由服務A實現一個消息中間件的回調介面,消息中間件會不斷執行回調介面,檢查服務A事務執行是否執行成功,如果失敗則回滾預備消息。
步驟四齣錯:這個時候服務A的本地事務是成功的,但是消息中間件不需要回滾,其實通過回調介面,消息中間件能夠檢查到服務A執行成功了,這個時候其實不需要服務發提交消息了,消息中間件可以自己對消息進行提交,從而完成整個消息事務。
參考文章:
1、https://www.cnblogs.com/xifenglou/p/8440836.html
2、https://blog.csdn.net/skyie53101517/article/details/80741868
3、https://www.cnblogs.com/zcjcsl/p/7989792.html

