
先來些簡單的問題 “你用過HashMap嗎?” “什麼是HashMap?你為什麼用到它?” 幾乎每個人都會回答“是的”,然後回答HashMap的一些特性,譬如HashMap可以接受null鍵值和值,而HashTable則不能;HashMap是非synchronized;HashMap很快;以及Has ...
先來些簡單的問題
“你用過HashMap嗎?” “什麼是HashMap?你為什麼用到它?”
幾乎每個人都會回答“是的”,然後回答HashMap的一些特性,譬如HashMap可以接受null鍵值和值,而HashTable則不能;HashMap是非synchronized;HashMap很快;以及HashMap儲存的是鍵值對等等。這顯示出你已經用過HashMap,而且對它相當的熟悉。但是面試官來個急轉直下,從此刻開始問出一些刁鑽的問題,關於HashMap的更多基礎的細節。面試官可能會問出下麵的問題:
“你知道HashMap的工作原理嗎?” “你知道HashMap的get()方法的工作原理嗎?”
你也許會回答“我沒有詳查標準的Java API,你可以看看Java源代碼或者Open JDK。”“我可以用Google找到答案。”
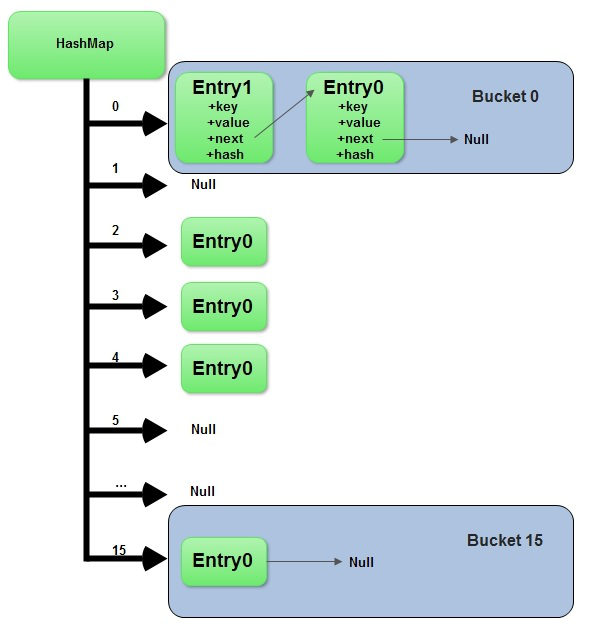
但一些面試者可能可以給出答案,“HashMap是基於hashing的原理,我們使用put(key, value)存儲對象到HashMap中,使用get(key)從HashMap中獲取對象。當我們給put()方法傳遞鍵和值時,我們先對鍵調用hashCode()方法,返回的hashCode用於找到bucket位置來儲存Entry對象。”這裡關鍵點在於指出,HashMap是在bucket中儲存鍵對象和值對象,作為Map.Entry。這一點有助於理解獲取對象的邏輯。如果你沒有意識到這一點,或者錯誤的認為僅僅只在bucket中存儲值的話,你將不會回答如何從HashMap中獲取對象的邏輯。這個答案相當的正確,也顯示出面試者確實知道hashing以及HashMap的工作原理。但是這僅僅是故事的開始,當面試官加入一些Java程式員每天要碰到的實際場景的時候,錯誤的答案頻現。下個問題可能是關於HashMap中的碰撞探測(collision detection)以及碰撞的解決方法:
“當兩個對象的hashcode相同會發生什麼?” 從這裡開始,真正的困惑開始了,一些面試者會回答因為hashcode相同,所以兩個對象是相等的,HashMap將會拋出異常,或者不會存儲它們。然後面試官可能會提醒他們有equals()和hashCode()兩個方法,並告訴他們兩個對象就算hashcode相同,但是它們可能並不相等。一些面試者可能就此放棄,而另外一些還能繼續挺進,他們回答“因為hashcode相同,所以它們的bucket位置相同,‘碰撞’會發生。因為HashMap使用LinkedList存儲對象,這個Entry(包含有鍵值對的Map.Entry對象)會存儲在LinkedList中。”這個答案非常的合理,雖然有很多種處理碰撞的方法,這種方法是最簡單的,也正是HashMap的處理方法。但故事還沒有完結,面試官會繼續問:
“如果兩個鍵的hashcode相同,你如何獲取值對象?” 面試者會回答:當我們調用get()方法,HashMap會使用鍵對象的hashcode找到bucket位置,然後獲取值對象。面試官提醒他如果有兩個值對象儲存在同一個bucket,他給出答案:將會遍歷LinkedList直到找到值對象。面試官會問因為你並沒有值對象去比較,你是如何確定確定找到值對象的?除非面試者直到HashMap在LinkedList中存儲的是鍵值對,否則他們不可能回答出這一題。
其中一些記得這個重要知識點的面試者會說,找到bucket位置之後,會調用keys.equals()方法去找到LinkedList中正確的節點,最終找到要找的值對象。完美的答案!
許多情況下,面試者會在這個環節中出錯,因為他們混淆了hashCode()和equals()方法。因為在此之前hashCode()屢屢出現,而equals()方法僅僅在獲取值對象的時候才出現。一些優秀的開發者會指出使用不可變的、聲明作final的對象,並且採用合適的equals()和hashCode()方法的話,將會減少碰撞的發生,提高效率。不可變性使得能夠緩存不同鍵的hashcode,這將提高整個獲取對象的速度,使用String,Interger這樣的wrapper類作為鍵是非常好的選擇。
如果你認為到這裡已經完結了,那麼聽到下麵這個問題的時候,你會大吃一驚。“如果HashMap的大小超過了負載因數(load factor)定義的容量,怎麼辦?”除非你真正知道HashMap的工作原理,否則你將回答不出這道題。預設的負載因數大小為0.75,也就是說,當一個map填滿了75%的bucket時候,和其它集合類(如ArrayList等)一樣,將會創建原來HashMap大小的兩倍的bucket數組,來重新調整map的大小,並將原來的對象放入新的bucket數組中。這個過程叫作rehashing,因為它調用hash方法找到新的bucket位置。
如果你能夠回答這道問題,下麵的問題來了:“你瞭解重新調整HashMap大小存在什麼問題嗎?”你可能回答不上來,這時面試官會提醒你當多線程的情況下,可能產生條件競爭(race condition)。
當重新調整HashMap大小的時候,確實存在條件競爭,因為如果兩個線程都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,存儲在LinkedList中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap並不會將元素放在LinkedList的尾部,而是放在頭部,這是為了避免尾部遍歷(tail traversing)。如果條件競爭發生了,那麼就死迴圈了。這個時候,你可以質問面試官,為什麼這麼奇怪,要在多線程的環境下使用HashMap呢?:)
熱心的讀者貢獻了更多的關於HashMap的問題:
- 為什麼String, Interger這樣的wrapper類適合作為鍵? String, Interger這樣的wrapper類作為HashMap的鍵是再適合不過了,而且String最為常用。因為String是不可變的,也是final的,而且已經重寫了equals()和hashCode()方法了。其他的wrapper類也有這個特點。不可變性是必要的,因為為了要計算hashCode(),就要防止鍵值改變,如果鍵值在放入時和獲取時返回不同的hashcode的話,那麼就不能從HashMap中找到你想要的對象。不可變性還有其他的優點如線程安全。如果你可以僅僅通過將某個field聲明成final就能保證hashCode是不變的,那麼請這麼做吧。因為獲取對象的時候要用到equals()和hashCode()方法,那麼鍵對象正確的重寫這兩個方法是非常重要的。如果兩個不相等的對象返回不同的hashcode的話,那麼碰撞的幾率就會小些,這樣就能提高HashMap的性能。
- 我們可以使用自定義的對象作為鍵嗎? 這是前一個問題的延伸。當然你可能使用任何對象作為鍵,只要它遵守了equals()和hashCode()方法的定義規則,並且當對象插入到Map中之後將不會再改變了。如果這個自定義對象時不可變的,那麼它已經滿足了作為鍵的條件,因為當它創建之後就已經不能改變了。
- 我們可以使用CocurrentHashMap來代替HashTable嗎?這是另外一個很熱門的面試題,因為ConcurrentHashMap越來越多人用了。我們知道HashTable是synchronized的,但是ConcurrentHashMap同步性能更好,因為它僅僅根據同步級別對map的一部分進行上鎖。ConcurrentHashMap當然可以代替HashTable,但是HashTable提供更強的線程安全性。
我個人很喜歡這個問題,因為這個問題的深度和廣度,也不直接的涉及到不同的概念。讓我們再來看看這些問題設計哪些知識點:
- hashing的概念
- HashMap中解決碰撞的方法
- equals()和hashCode()的應用,以及它們在HashMap中的重要性
- 不可變對象的好處
- HashMap多線程的條件競爭
- 重新調整HashMap的大小
總結
HashMap的工作原理
HashMap基於hashing原理,我們通過put()和get()方法儲存和獲取對象。當我們將鍵值對傳遞給put()方法時,它調用鍵對象的hashCode()方法來計算hashcode,讓後找到bucket位置來儲存值對象。當獲取對象時,通過鍵對象的equals()方法找到正確的鍵值對,然後返回值對象。HashMap使用LinkedList來解決碰撞問題,當發生碰撞了,對象將會儲存在LinkedList的下一個節點中。 HashMap在每個LinkedList節點中儲存鍵值對對象。
當兩個不同的鍵對象的hashcode相同時會發生什麼? 它們會儲存在同一個bucket位置的LinkedList中。鍵對象的equals()方法用來找到鍵值對。
因為HashMap的好處非常多,我曾經在電子商務的應用中使用HashMap作為緩存。因為金融領域非常多的運用Java,也出於性能的考慮,我們會經常用到HashMap和ConcurrentHashMap。你可以查看更多的關於HashMap和HashTable的文章。


