軟工作業2 ——實現一個能夠對文本文件中的單詞的詞頻進行統計的控制台程式 1.Github地址: https://github.com/wangshiyaoyao/WordCont 2.PSP表格 PSP2.1 Personal Software Process Stages 預估耗時(分鐘) 實際 ...
軟工作業2
——實現一個能夠對文本文件中的單詞的詞頻進行統計的控制台程式
1.Github地址:
https://github.com/wangshiyaoyao/WordCont
2.PSP表格
|
PSP2.1 |
Personal Software Process Stages |
預估耗時(分鐘) |
實際耗時(分鐘) |
|
Planning |
計劃 |
||
|
· Estimate |
· 估計這個任務需要多少時間 |
||
|
Development |
開發 |
||
|
· Analysis |
· 需求分析 (包括學習新技術) |
120 |
360 |
|
· Design Spec |
· 生成設計文檔 |
30 |
30 |
|
· Design Review |
· 設計覆審 |
10 |
10 |
|
· Coding Standard |
· 代碼規範 (為目前的開發制定合適的規範) |
20 |
20 |
|
· Design |
· 具體設計 |
30 |
30 |
|
· Coding |
· 具體編碼 |
120 |
120 |
|
· Code Review |
· 代碼覆審 |
20 |
40 |
|
· Test |
· 測試(自我測試,修改代碼,提交修改) |
120 |
300 |
|
Reporting |
報告 |
||
|
· Test Repor |
· 測試報告 |
60 |
60 |
|
· Size Measurement |
· 計算工作量 |
30 |
30 |
|
· Postmortem & Process Improvement Plan |
· 事後總結, 並提出過程改進計劃 |
30 |
30 |
|
|
合計 |
590 |
1030 |
3.需求分析
實現一個能夠對文本文件中的單詞的詞頻進行統計的控制台程式
功能實現:
讀取文件
獲取文件名
判斷獲取參數是否正確
判斷文件是否可讀取,否則報錯處理
根據文件內容進行分析處理
統計字元個數
統計有效行數
統計詞頻
詞頻排序,獲取前十
統計單詞數
輸出結果
測試用例:
創建臨時文件
根據一定規則隨機生成內容
記錄生成內容的有效單詞等各種你參數
功能測試
測試統計字元個數
測試統計有效行數
測試統計詞頻
測試統計單詞數
難點:
單詞匹配,使用正則表達式,學習其語法
測試套件的使用
隨機生成文件內容
代碼規範:
使用python3.7+ pycharm
單函數單功能
添加註釋,提高代碼可讀性
代碼符合pep8規範,使用pylint進行檢查
使用Profile進行性能檢測
4.代碼設計
Get_argv函數:獲取並返回程式執行第一個參數,進行參數個數校驗,有誤返回空字元串,
Main函數:接受一個文件名字元串,輸出分析結果,無返回
創建文件分析實例,進行分析,獲取輸出結果,進行輸出
_file_check函數:文件名檢查,若不能打開並讀取,進行報錯,程式異常退出
FileHandler類:
__init__:初始化用於保存結果的各類變數,接受文件名,調用函數進行檢查,調用分析函數進行分析
_analysis:打開文件,讀取內容,對讀取內容調用歐冠具體函數進行分析,最後對詞頻排序
_chars_analysis:字元統計,使用len函數
_line_analysis:有效行統計,使用strip函數判斷有效行
_word_analysis:詞頻統計,調用單詞檢查函數獲取合法單詞,使用lower函數統一為小寫
_word_sum:單詞數統計,調用單詞檢查函數獲取合法單詞
_sort_conatiner:詞頻結果排序,取前十結果
介面函數:
chars:獲取字元統計結果
cotainer:獲取詞頻前10統計結果
lines:獲取有效行統計結果
words:獲取單詞數目統計結果
_word_check_in_line:函數:獲取字元串中合法單詞,使用正則表達式匹配
單元測試:
創建臨時文件
根據一定規則隨機生成內容
記錄生成內容的有效單詞等各種你參數
通過正則表達式反向匹配生成任意符合測試要求的內容,文件大小可控,覆蓋較全面。
功能測試
測試統計字元個數
測試統計有效行數
測試統計詞頻
測試統計單詞數
5.關鍵功能實現
文件檢查:
1 def _file_check(filename): 2 """判斷參數是一個可讀文件,否則報錯""" 3 try: 4 fd = open(filename) 5 fd.close() 6 except IOError: 7 logging.error("Invalid argument.\nNeed a readable file.") 8 sys.exit(1)
對文件進行嘗試可讀打開,失敗進行報錯,並異常退出
類初始化:
def __init__(self, filename, encoding='utf-8'): self._chars = 0 # 統計ascii self._container = {} # 統計詞頻 self._lines = 0 # 統計行數 self._words = 0 # 統計單詞數 self._sorted_container = [] # 輸出詞頻 _file_check(filename) self._analysis(filename, encoding)
使用字典進行詞頻統計,避免重覆
文件預設使用utf-8打開
詞頻統計:
1 def _word_analysis(self, line): 2 """統計詞頻""" 3 for word_match in _word_check_in_line(line): 4 word = word_match.lower() 5 self._container[word] = self._container.get(word, 0) + 1
使用字典的get函數對初次添加做特殊初始化
合法單詞檢查:
1 def _word_check_in_line(line): 2 """單詞匹配""" 3 pattern = r'(?<![a-zA-Z0-9])([a-zA-Z][0-9a-zA-Z]*)' 4 result = re.findall(pattern, line) 5 # logging.debug('word check in line result:%s', result) 6 return result
使用正則進行檢查
匹配字元開頭後跟任意長度字元或數字,單詞前一字元不為字母數字
使用findall函數獲取所有合法單詞,以列表存儲
詞頻結果處理:
1 def _sort_container(self): 2 """詞頻結果排序,獲取前10結果""" 3 self._sorted_container = sorted(self._container.items(), key=lambda x: (-x[1], x[0]))[:10]
使用sorted函數對字典進行排序
參數:key=lambda x: (-x[1], x[0])
表示排序依據,先根據字典值大->小排序,後根據字典鍵按字典序排序
[:10]:表示取前十個結果
生成用於測試的臨時文件:
1 def touch_test_file(line_num, word_num): 2 """創建測試文件,隨機生成字元,用於測試""" 3 4 _x = Xeger() 5 words = lambda: _x.xeger(r'[a-zA-Z][a-zA-Z0-9]*') # 隨機生成有效單詞 6 non_word = lambda: _x.xeger(r'\d[a-zA-Z0-9]*') # 隨機生成開頭為數字的單詞 7 separator = lambda: _x.xeger(r'[^a-zA-Z0-9\n\r]') # 隨機生成非字母數字回車換行符的字元 8 space = lambda: _x.xeger(r'\n[\s]*\n') # 隨機生成回車空白字元回車 9 10 # 統計生成的文件中字元、單詞、有效行、詞頻 11 result = {'chars': 0, 'words': word_num * line_num, 'lines': line_num, 'container': {}} 12 13 # 創建文件,隨機生成字元 14 fd = open(temp_file, 'w') 15 for line in range(line_num): 16 for i in range(word_num): 17 word = words() 18 chars = word + separator() + non_word() + separator() 19 result['chars'] += len(chars) 20 result['container'][word.lower()] = result['container'].get(word.lower(), 0) + 1 21 fd.write(chars) 22 chars = space() 23 result['chars'] += len(chars) 24 fd.write(chars) 25 fd.close() 26 27 # 獲取排序後的詞頻結果 28 sort_result = sorted(result['container'].items(), key=lambda x: (-x[1], x[0]))[:10] 29 result['container'] = sort_result 30 return result
使用第三方庫xeger,反向生成符合正則的任意字元串
創建好要生成的合法非法單詞,字元,空白字元等
創建臨時文件,隨機生成字元串寫入
將結果返回
6.代碼風格說明
Unused variable 'line' (unused-variable):未使用的參數:for迴圈中,使用_代替
Trailing newlines (trailing-newlines):文件末尾多餘空行,刪除
7.運行結果
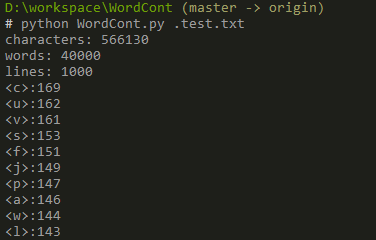
測試運行:

8.性能分析結果及改進
使用cProfile
182480 function calls (182313 primitive calls) in 0.207 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
7382 0.057 0.000 0.057 0.000 {method 'findall' of 're.Pattern' objects}
1 0.049 0.049 0.057 0.057 {built-in method builtins.sorted}
3691 0.025 0.000 0.074 0.000 WordCont.py:64(_word_analysis)
1 0.010 0.010 0.190 0.190 WordCont.py:74(_analysis)
40049 0.008 0.000 0.008 0.000 {method 'get' of 'dict' objects}
33382 0.008 0.000 0.008 0.000 WordCont.py:87(<lambda>)
40006 0.006 0.000 0.006 0.000 {method 'lower' of 'str' objects}
7385 0.005 0.000 0.010 0.000 re.py:271(_compile)
13 0.004 0.000 0.004 0.000 {built-in method builtins.print}
7382 0.004 0.000 0.068 0.000 re.py:215(findall)
3691 0.004 0.000 0.040 0.000 WordCont.py:70(_word_sum)
7382 0.004 0.000 0.072 0.000 WordCont.py:25(_word_check_in_line)
1 0.003 0.003 0.060 0.060 WordCont.py:85(_sort_container)
7681 0.002 0.000 0.002 0.000 {built-in method builtins.isinstance}
3691 0.002 0.000 0.003 0.000 WordCont.py:59(_line_analysis)
57 0.002 0.000 0.002 0.000 {built-in method nt.stat}
3691 0.002 0.000 0.002 0.000 WordCont.py:55(_chars_analysis)
10 0.002 0.000 0.002 0.000 {built-in method marshal.loads}
3691 0.001 0.000 0.001 0.000 {method 'strip' of 'str' objects}
10 0.001 0.000 0.001 0.000 {method 'read' of '_io.FileIO' objects}
7762/7732 0.001 0.000 0.001 0.000 {built-in method builtins.len}
45 0.001 0.000 0.002 0.000 {built-in method builtins.__build_class__}
1 0.001 0.001 0.207 0.207 WordCont.py:8(<module>)
19/4 0.001 0.000 0.002 0.000 sre_parse.py:475(_parse)
…… …… ……
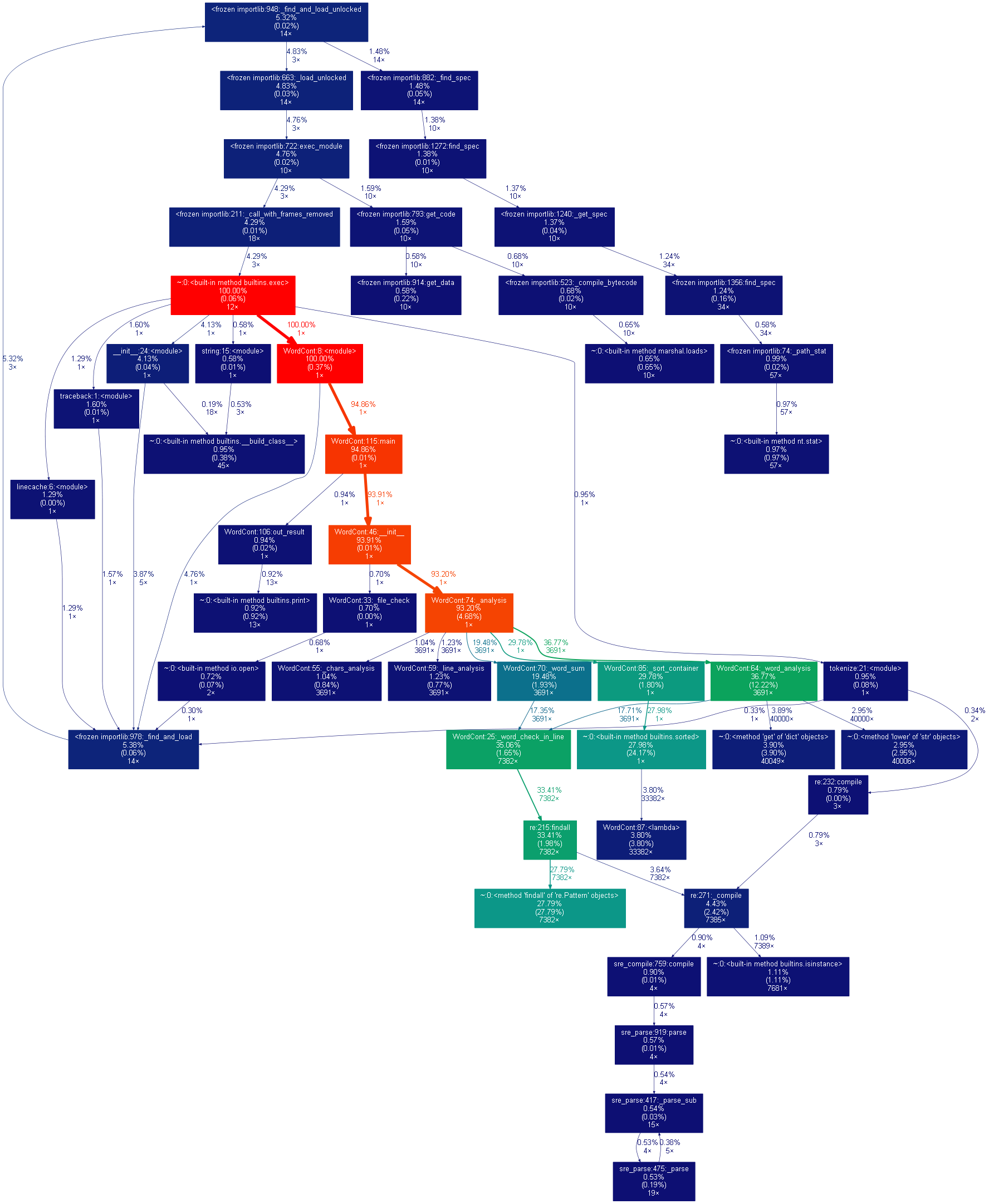
Findall函數耗時最多,sorted其次,內建函數暫無法優化。
按執行次數分析:
182480 function calls (182313 primitive calls) in 0.216 seconds
Ordered by: call count
ncalls tottime percall cumtime percall filename:lineno(function)
40049 0.009 0.000 0.009 0.000 {method 'get' of 'dict' objects}
40006 0.006 0.000 0.006 0.000 {method 'lower' of 'str' objects}
33382 0.008 0.000 0.008 0.000 WordCont.py:87(<lambda>)
7762/7732 0.001 0.000 0.001 0.000 {built-in method builtins.len}
7681 0.003 0.000 0.003 0.000 {built-in method builtins.isinstance}
7385 0.006 0.000 0.011 0.000 re.py:271(_compile)
7382 0.004 0.000 0.076 0.000 WordCont.py:25(_word_check_in_line)
7382 0.004 0.000 0.072 0.000 re.py:215(findall)
7382 0.058 0.000 0.058 0.000 {method 'findall' of 're.Pattern' objects}
3691 0.002 0.000 0.003 0.000 WordCont.py:55(_chars_analysis)
3691 0.002 0.000 0.003 0.000 WordCont.py:59(_line_analysis)
3691 0.025 0.000 0.078 0.000 WordCont.py:64(_word_analysis)
3691 0.004 0.000 0.042 0.000 WordCont.py:70(_word_sum)
3691 0.001 0.000 0.001 0.000 {method 'strip' of 'str' objects}
411 0.000 0.000 0.000 0.000 sre_parse.py:233(__next)
執行次數最多代碼:get函數,lower函數
按函數運行時間分析:
182480 function calls (182313 primitive calls) in 0.201 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
12/1 0.000 0.000 0.201 0.201 {built-in method builtins.exec}
1 0.001 0.001 0.201 0.201 WordCont.py:8(<module>)
1 0.000 0.000 0.190 0.190 WordCont.py:115(main)
1 0.000 0.000 0.188 0.188 WordCont.py:46(__init__)
1 0.010 0.010 0.187 0.187 WordCont.py:74(_analysis)
3691 0.023 0.000 0.073 0.000 WordCont.py:64(_word_analysis)
7382 0.004 0.000 0.070 0.000 WordCont.py:25(_word_check_in_line)
7382 0.004 0.000 0.066 0.000 re.py:215(findall)
1 0.003 0.003 0.060 0.060 WordCont.py:85(_sort_container)
1 0.050 0.050 0.057 0.057 {built-in method builtins.sorted}
7382 0.055 0.000 0.055 0.000 {method 'findall' of 're.Pattern' objects}
3691 0.004 0.000 0.039 0.000 WordCont.py:70(_word_sum)
14/3 0.000 0.000 0.012 0.004 <frozen importlib._bootstrap>:978(_find_and_load)
14/3 0.000 0.000 0.011 0.004 <frozen importlib._bootstrap>:948(_find_and_load_unlocked)
14/3 0.000 0.000 0.011 0.004 <frozen importlib._bootstrap>:663(_load_unlocked)
10/3 0.000 0.000 0.010 0.003 <frozen importlib._bootstrap_external>:722(exec_module)
18/3 0.000 0.000 0.010 0.003 <frozen importlib._bootstrap>:211(_call_with_frames_removed)
7385 0.005 0.000 0.009 0.000 re.py:271(_compile)
運行時間最多函數main函數,__init__初始化函數。
附:
ncalls:表示函數調用的次數;
tottime:表示指定函數的總的運行時間,除掉函數中調用子函數的運行時間;
percall:(第一個percall)等於
tottime/ncalls;
cumtime:表示該函數及其所有子函數的調用運行的時間,即函數開始調用到返回的時間;
percall:(第二個percall)即函數運行一次的平均時間,等於 cumtime/ncalls;
filename:lineno(function):每個函數調用的具體信息;
性能分析圖: