
上次使用了BeautifulSoup庫爬取電影排行榜,爬取相對來說有點麻煩,爬取的速度也較慢。本次使用的lxml庫,我個人是最喜歡的,爬取的語法很簡單,爬取速度也快。 本次爬取的豆瓣書籍排行榜的首頁地址是: https://www.douban.com/doulist/1264675/?start= ...
上次使用了BeautifulSoup庫爬取電影排行榜,爬取相對來說有點麻煩,爬取的速度也較慢。本次使用的lxml庫,我個人是最喜歡的,爬取的語法很簡單,爬取速度也快。
本次爬取的豆瓣書籍排行榜的首頁地址是:
https://www.douban.com/doulist/1264675/?start=0&sort=time&playable=0&sub_type=
該排行榜一共有22頁,且發現更改網址的 start=0 的 0 為25、50就可以跳到排行榜的第二、第三頁,所以後面只需更改這個數字然後通過遍歷就可以爬取整個排行榜的書籍信息。
本次爬取的內容有書名、評分、評價數、出版社、出版年份以及書籍封面圖,封面圖保存為圖片,其他數據存為csv文件,方面後面讀取分析。
本次的項目步驟:一、分析網頁,確定爬取數據
二、使用lxml庫爬取內容並保存
三、讀取數據並選擇部分內容進行分析
- 步驟一:

分析網頁源代碼可以看到,書籍信息在屬性為 class="doulist-item"的div標簽中,打開發現,我們需要爬取的信息都在標簽內部,通過xpath語法我們可以很簡便的爬取所需內容。
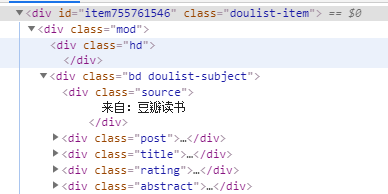 (書籍各類信息所在標簽)
(書籍各類信息所在標簽)
所需爬取的內容在 class為post、title、rating、abstract的div標簽中。
- 步驟二:
- 先定義爬取函數,爬取所需內容
- 執行函數,並存入csv文件
具體代碼如下: 註:轉載代碼請標明出處
1 import requests 2 from lxml import etree 3 import time 4 import csv 5 6 #信息頭 7 headers = { 8 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' 9 } 10 11 #定義爬取函數 12 def douban_booksrank(url): 13 res = requests.get(url, headers=headers) 14 selector = etree.HTML(res.text) 15 contents = selector.xpath('//div[@class="article"]/div[contains(@class,"doulist-item")]') #迴圈點 16 for content in contents: 17 try: 18 title = content.xpath('div/div[2]/div[3]/a/text()')[0] #書名 19 scores = content.xpath('div/div[2]/div[4]/span[2]/text()') #評分 20 scores.append('9.0') #因為有一些書沒有評分,導致列表為空,此處添加一個預設評分,若無評分則預設為9.0 21 score = scores[0] 22 comments = content.xpath('div/div[2]/div[4]/span[3]/text()')[0] #評論數量 23 author = content.xpath('div/div[2]/div[5]/text()[1]')[0] #作者 24 publishment = content.xpath('div/div[2]/div[5]/text()[2]')[0] #出版社 25 pub_year = content.xpath('div/div[2]/div[5]/text()[3]')[0] #出版時間 26 img_url = content.xpath('div/div[2]/div[2]/a/img/@src')[0] #書本圖片的網址 27 img = requests.get(img_url) #解析圖片網址,為下麵下載圖片 28 img_name_file = 'C:/Users/lenovo/Desktop/douban_books/{}.png'.format((title.strip())[:3]) #圖片存儲位置,圖片名只取前3 29 #寫入csv 30 with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as fp: #newline 使不隔行 31 writer = csv.writer(fp) 32 writer.writerow((title, score, comments, author, publishment, pub_year, img_url)) 33 #下載圖片,為防止圖片名導致格式錯誤,加入try...except 34 try: 35 with open(img_name_file, 'wb')as imgf: 36 imgf.write(img.content) 37 except FileNotFoundError or OSError: 38 pass 39 time.sleep(0.5) #睡眠0.5s 40 except IndexError: 41 pass 42 #執行程式 43 if __name__=='__main__': 44 #爬取所有書本,共22頁的內容 45 urls = ['https://www.douban.com/doulist/1264675/?start={}&sort=time&playable=0&sub_type='.format(str(i))for i in range(0,550,25)] 46 #寫csv首行 47 with open('C:\\Users\lenovo\Desktop\\douban_books.csv', 'a+', newline='', encoding='utf-8')as f: 48 writer = csv.writer(f) 49 writer.writerow(('title', 'score', 'comment', 'author', 'publishment', 'pub_year', 'img_url')) 50 #遍歷所有網頁,執行爬取程式 51 for url in urls: 52 douban_booksrank(url)
爬取結果截圖如下:
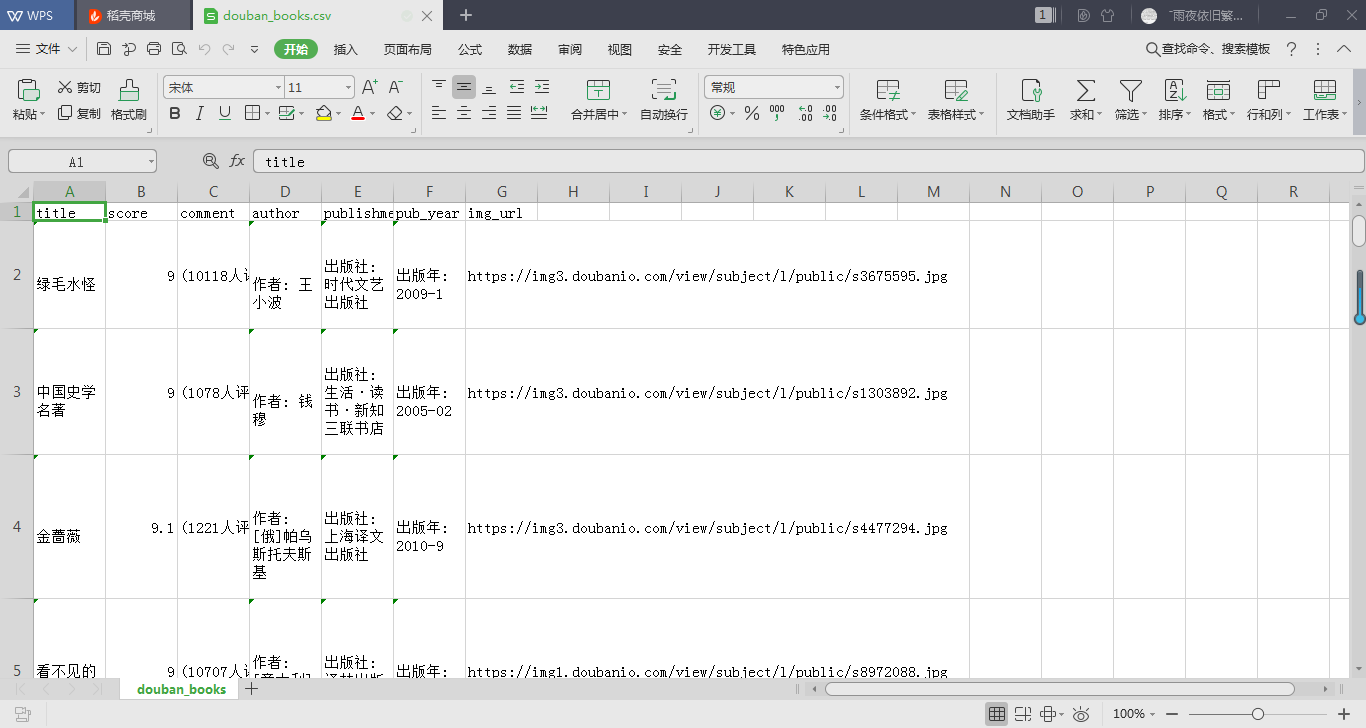
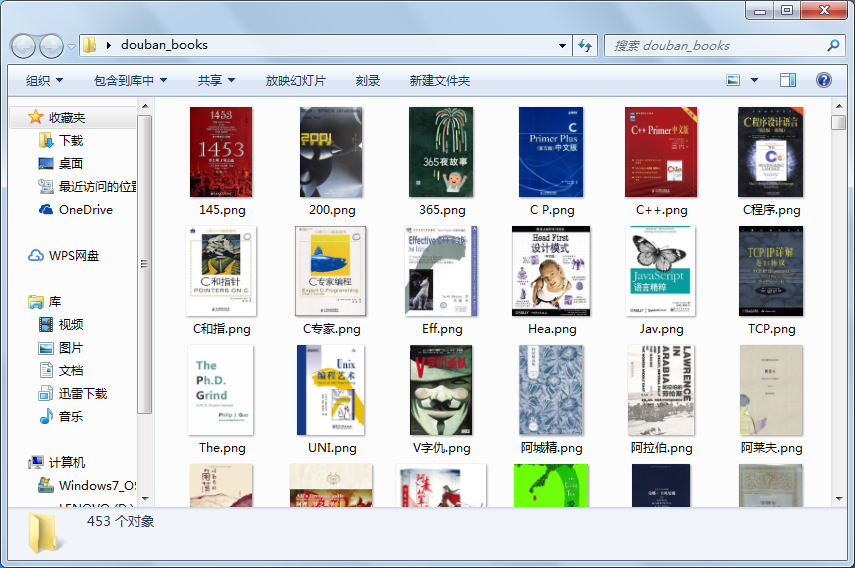
- 步驟三:
本次使用Python常用的數據分析庫pandas來提取所需內容。pandas的read_csv()函數可以讀取csv文件並根據文件格式轉換為Series、DataFrame或面板對象。
此處我們提取的數據轉變為DataFrame(數據幀)對象,然後通過Matplotlib繪圖庫來進行繪圖。
具體代碼如下:
1 from matplotlib import pyplot as plt 2 import pandas as pd 3 import re 4 5 plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽 6 plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號 7 plt.subplots_adjust(wsapce=0.5, hspace=0.5) #調整subplot子圖間的距離 8 9 pd.set_option('display.max_rows', None) #設置使dataframe 所有行都顯示 10 11 df = pd.read_csv('C:\\Users\lenovo\Desktop\\douban_books.csv') #讀取csv文件,並賦為dataframe對象 12 13 comment = re.findall('\((.*?)人評價', str(df.comment), re.S) #使用正則表達式獲取評論人數 14 #將comment的元素化為整型 15 new_comment = [] 16 for i in comment: 17 new_comment.append(int(i)) 18 19 pub_year = re.findall(r'\d{4}', str(df.pub_year),re.S) #獲取書籍出版年份 20 #同上 21 new_pubyear = [] 22 for n in pub_year: 23 new_pubyear.append(int(n)) 24 25 #繪圖 26 #1、繪製書籍評分範圍的直方圖 27 plt.subplot(2,2,1) 28 plt.hist(df.score, bins=16, edgecolor='black') 29 plt.title('豆瓣書籍排行榜評分分佈', fontweight=700) 30 plt.xlabel('scores') 31 plt.ylabel('numbers') 32 33 #繪製書籍評論數量的直方分佈圖 34 plt.subplot(222) 35 plt.hist(new_comment, bins=16, color='green', edgecolor='yellow') 36 plt.title('豆瓣書籍排行榜評價分佈', fontweight=700) 37 plt.xlabel('評價數') 38 plt.ylabel('書籍數量(單位/本)') 39 40 #繪製書籍出版年份分佈圖 41 plt.subplot(2,2,3) 42 plt.hist(new_pubyear, bins=30, color='indigo',edgecolor='blue') 43 plt.title('書籍出版年份分佈', fontweight=700) 44 plt.xlabel('出版年份/year') 45 plt.ylabel('書籍數量/本') 46 47 #尋找關係 48 plt.subplot(224) 49 plt.bar(new_pubyear,new_comment, color='red', edgecolor='white') 50 plt.title('書籍出版年份與評論數量的關係', fontweight=700) 51 plt.xlabel('出版年份/year') 52 plt.ylabel('評論數') 53 54 plt.savefig('C:\\Users\lenovo\Desktop\\douban_books_analysis.png') #保存圖片 55 plt.show()
這裡需要註意的是,使用了正則表達式來提取評論數和出版年份,將其中的符號和文字等剔除。
分析結果如下:

本次分析的內容也較為簡單,從上面的幾個圖形中我們也能得出一些結論。
- 這些高分書籍中絕大多數的評論數量都在50000以下;
- 多數排行榜上的高分書籍都出版在2000年以後;
- 出版年份在2000年後的書籍有更多的評論數量。
以上數據也見解的說明瞭在進入二十世紀後我國的圖書需求量更大了,網路更發達,更多人願意發表自己的看法。
本次的分享到此。若有錯誤,歡迎指正。有建議的話也可以留言。

