
1. 內核空間和用戶空間 過去,CPU的地址匯流排只有32位, 32的地址匯流排無論是從邏輯上還是從物理上都只能描述4G的地址空間(232=4Gbit),在物理上理論上最多擁有4G記憶體(除了IO地址空間,實際記憶體容量小於4G),邏輯空間也只能描述4G的線性地址空間。 為了合理的利用邏輯4G空間,Linu ...
1. 內核空間和用戶空間
過去,CPU的地址匯流排只有32位, 32的地址匯流排無論是從邏輯上還是從物理上都只能描述4G的地址空間(232=4Gbit),在物理上理論上最多擁有4G記憶體(除了IO地址空間,實際記憶體容量小於4G),邏輯空間也只能描述4G的線性地址空間。
為了合理的利用邏輯4G空間,Linux採用了3:1的策略,即內核占用1G的線性地址空間,用戶占用3G的線性地址空間。所以用戶進程的地址範圍從0~3G,內核地址範圍從3G~4G,也就是說,內核空間只有1G的邏輯線性地址空間。
把內核空間和用戶空間分開是方便為了MMU映射
如果內核空間和用戶空間都是0~4G範圍的話, 那麼當從用戶態切入到內核態時(系統調用或者中斷),就必須要切換MMU映射 (程式里一個邏輯地址在用戶態和內核態肯定被映射到不同的物理地址上)
這種切換代價是很大,但是用戶態/內核態的切換卻是非常頻繁的。
而且從技術上你根本沒法切換,因為這個時候程式內的任何地址都被映射給用戶進程,你根本沒法取到內核數據。
就算進入內核態時你切換MMU映射,如果這個時候你要讀寫用戶進程的數據怎麼辦呢? 難道又去映射MMU?
把0~3G分給用戶進程、3~4G就能很好的解決這個問題.這樣一來就是你用戶程式里的所有變數和函數的 邏輯地址都是介於0~3G的,內核代碼里所有變數和函數的邏輯地址都是介於3~4G的
所謂用戶空間和內核空間,從cpu角度來說,只是運行的級別不一樣,是否處於特權級別而已
邏輯地址到物理地址的MMU映射是不變的。
不管是用戶態還是內核態,最終都是通過MMU映射到你的物理上的896M記憶體
mmap就可以映射物理記憶體到用戶空間,你可以清楚的看到同一塊物理內在用戶態和內核態的不同邏輯地址
兩個不同的邏輯地址(一個介於0~3G,一個介於3-4G) 通過MMU映射到同一塊物理記憶體
1.2 linux為什麼把內核映射到3G-4G這個地址呢
假如linux把內核映射到0-1G的空間,其他進程共用1-4G的空間不可以嗎?
這個技術上也是可以的,而且不難實現。為什麼不採用估計有歷史原因吧
畢竟cpu和程式出來的年代比MMU早多了
沒有MMU的年代里,對於x86,邏輯地址就是物理地址。物理地址從0開始,那麼程式的邏輯地址從一開始也是從0開始的
對於任何用戶進程,0~3G的映射都是不同的,但是所有用戶進程3~4G的映射都是相同的
一個進程從用戶態切入到內核態,MMU映射不需要變。你能很方便取得內核數據和用戶進程的數據
1.3 應用程式線性地址和動態記憶體分配
應用程式能使用的最大線性地址就是3G, 根據linux應用的分區方法:
---------------------------- 4G
內核空間
---------------------------- 3G
棧 - 向下增長
map - 固定映射
堆 - 向上增長
數據段
代碼段
---------------------------- 0G應用層的動態記憶體分配, 比如malloc, 一般使用的是dlmalloc庫, 具體見:http://opendevkit.com/?e=56
所以, 低端內核和高端記憶體是內核的概念, 跟應用程式沒有直接關係.
如果Linux物理記憶體小於1G的空間,通常內核把物理記憶體與其地址空間做了線性映射,也就是一一映射,這樣可以提高訪問速度。但是,當Linux物理記憶體超過1G時,線性訪問機制就不夠用了,因為只能有1G的記憶體可以被映射,剩餘的物理記憶體無法被內核管理,所以,為瞭解決這一問題,Linux把內核地址分為線性區和非線性區兩部分,線性區規定最大為896M,剩下的128M為非線性區。從而,線性區映射的物理記憶體成為低端記憶體,剩下的物理記憶體被成為高端記憶體。與線性區不同,非線性區不會提前進行記憶體映射,而是在使用時動態映射。
1.4 高端記憶體和低端記憶體的劃分
那麼既然內核態的地址範圍只有1G的,如果你有4G物理上的記憶體,顯然你沒法一次性全部映射所有的物理記憶體到內核態地址。
所有才有了高端記憶體。低896M的記憶體做直接映射,剩下的128M 根據需要動態的映射到剩下的物理記憶體。
64位的內核就可以很好的解決這個問題,但是64位系統不是意味著就有64根地址線。因為沒必要,實際不需要那麼大記憶體。
假設你有38位地址線,可以定址到2048G的記憶體,也按照3:1劃分,那麼內核態就有512G範圍,你的512G物理記憶體可以一次性的全部映射到內核空間,根本不需要高端記憶體
Linux物理記憶體空間分為DMA記憶體區(DMA Zone)、低端記憶體區(Normal Zone)與高端記憶體區(Highmem Zone)三部分。DMA Zone通常很小,只有幾十M,低端記憶體區與高端記憶體區的劃分來源於Linux內核空間大小的限制。
當物理記憶體大於1G的時候, 內核是不能完全用低端記憶體管理全部物理記憶體的, 所以低端記憶體剩下的部分就是高端記憶體了, 高端記憶體沒有直接映射的, 是動態映射到內核空間的.
一般 128M給高端記憶體分配用, 因為很少, 所以不用要趕緊釋放掉
64bit的時候, 就不存在低端記憶體和高端記憶體的概念了, 因為空間很大都可以直接管理了.
1.5 例子
| 區域 | 大小 |
|---|---|
| MemTotal | 1547MB |
| HighTotal | 825MB |
| LowTotal | 721MB |
申請高端記憶體時,如果高端記憶體不夠了,linux也會去低端記憶體區申請,反之則不行。
2. Linux內核高端記憶體的由來
2.1 為什麼需要高端記憶體?
高端記憶體是指物理地址大於 896M 的記憶體。對於這樣的記憶體,無法在“內核直接映射空間”進行映射。
內核空間只有1GB線性地址,如果使用大於1GB的物理記憶體就沒法直接映射到內核線性空間了。
當系統中的記憶體大於896MB時,把內核線性空間分為兩部分,內核中低於896MB線性地址空間直接映射到低896MB的物理地址空間;高於896MB的128MB內核線性空間用於動態映射ZONE_HIGHMEM記憶體區域(即物理地址高於896MB的物理空間)。
實際上,“內核直接映射空間”也達不到 1G, 還得留點線性空間給“內核動態映射空間” 呢。
因此,Linux 規定“內核直接映射空間” 最多映射 896M 物理記憶體。
對於高端記憶體,可以通過 alloc_page() 或者其它函數獲得對應的 page,但是要想訪問實際物理記憶體,還得把 page 轉為線性地址才行(為什麼?想想 MMU 是如何訪問物理記憶體的),也就是說,我們需要為高端記憶體對應的 page 找一個線性空間,這個過程稱為高端記憶體映射。
2.2 高端記憶體
在傳統的x86_32系統中, 當內核模塊代碼或線程訪問記憶體時,代碼中的記憶體地址都為邏輯地址,而對應到真正的物理記憶體地址,需要地址一對一的映射,如邏輯地址0xc0000003對應的物理地址為0×3,0xc0000004對應的物理地址為0×4,… …,
邏輯地址與物理地址對應的關係為
物理地址 = 邏輯地址 – 0xC0000000
這是內核地址空間的地址轉換關係,註意內核的虛擬地址在“高端”,但是ta映射的物理記憶體地址在低端。
邏輯地址 物理記憶體地址
0xc0000000 0×0
0xc0000001 0×1
0xc0000002 0×2
0xc0000003 0×3
… …
0xe0000000 0×20000000
… …
0xffffffff 0×40000000 ??假設按照上述簡單的地址映射關係,那麼內核邏輯地址空間訪問為0xc0000000 ~ 0xffffffff,那麼對應的物理記憶體範圍就為0×0 ~ 0×40000000,即只能訪問1G物理記憶體。若機器中安裝8G物理記憶體,那麼內核就只能訪問前1G物理記憶體,後面7G物理記憶體將會無法訪問,因為內核 的地址空間已經全部映射到物理記憶體地址範圍0×0 ~ 0×40000000。即使安裝了8G物理記憶體,那麼物理地址為0×40000001的記憶體,內核該怎麼去訪問呢?代碼中必須要有記憶體邏輯地址 的,0xc0000000 ~ 0xffffffff的地址空間已經被用完了,所以無法訪問物理地址0×40000000以後的記憶體。
顯 然不能將內核地址空間0xc0000000 ~ 0xfffffff全部用來簡單的地址映射。因此x86架構中將內核地址空間劃分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即為高端記憶體,這就是記憶體高端記憶體概念的由來。
在x86結構中,三種類型的區域(從3G開始計算)如下:
| 區域 | 位置 |
|---|---|
| ZONE_DMA | 記憶體開始的16MB |
| ZONE_NORMAL | 16MB~896MB |
ZONE_HIGHMEM 896MB ~ 結束(1G)
2.3 Linux內核高端記憶體的理解
前 面我們解釋了高端記憶體的由來。 Linux將內核地址空間劃分為三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端記憶體HIGH_MEM地址空間範圍為 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那麼如內核是如何藉助128MB高端記憶體地址空間是如何實現訪問可以所有物理記憶體?
當內核想訪問高於896MB物理地址記憶體時,從0xF8000000 ~ 0xFFFFFFFF地址空間範圍內找一段相應大小空閑的邏輯地址空間,借用一會。借用這段邏輯地址空間,建立映射到想訪問的那段物理記憶體(即填充內核PTE頁面表),臨時用一會,用完後歸還。這樣別人也可以借用這段地址空間訪問其他物理記憶體,實現了使用有限的地址空間,訪問所有所有物理記憶體。如下圖。
例 如內核想訪問2G開始的一段大小為1MB的物理記憶體,即物理地址範圍為0×80000000 ~ 0x800FFFFF。訪問之前先找到一段1MB大小的空閑地址空間,假設找到的空閑地址空間為0xF8700000 ~ 0xF87FFFFF,用這1MB的邏輯地址空間映射到物理地址空間0×80000000 ~ 0x800FFFFF的記憶體。映射關係如下:
邏輯地址 物理記憶體地址
0xF8700000 0×80000000
0xF8700001 0×80000001
0xF8700002 0×80000002
… …
0xF87FFFFF 0x800FFFFF當內核訪問完0×80000000 ~ 0x800FFFFF物理記憶體後,就將0xF8700000 ~ 0xF87FFFFF內核線性空間釋放。這樣其他進程或代碼也可以使用0xF8700000 ~ 0xF87FFFFF這段地址訪問其他物理記憶體。
從上面的描述,我們可以知道高端記憶體的最基本思想, 借一段地址空間,建立臨時地址映射,用完後釋放,達到這段地址空間可以迴圈使用,訪問所有物理記憶體。
看到這裡,不禁有人會問:萬一有內核進程或模塊一直占用某段邏輯地址空間不釋放,怎麼辦?若真的出現的這種情況,則內核的高端記憶體地址空間越來越緊張,若都被占用不釋放,則沒有建立映射到物理記憶體都無法訪問了。
3 Linux內核高端記憶體的劃分與映射
在32位的系統上, 內核占有從第3GB~第4GB的線性地址空間, 共1GB大小
內核將其中的前896MB與物理記憶體的0~896MB進行直接映射, 即線性映射, 將剩餘的128M線性地址空間作為訪問高於896M的記憶體的一個視窗. 引入高端記憶體映射這樣一個概念的主要原因就是我們所安裝的記憶體大於1G時,內核的1G線性地址空間無法建立一個完全的直接映射來觸及整個物理記憶體空間,而對於80x86開啟PAE的情況下,允許的最大物理記憶體可達到64G,因此內核將自己的最後128M的線性地址空間騰出來,用以完成對高端記憶體的暫時性映射。而在64位的系統上就不存在這樣的問題了,因為可用的線性地址空間遠大於可安裝的記憶體。
下圖描述了內核1GB線性地址空間是如何劃分的
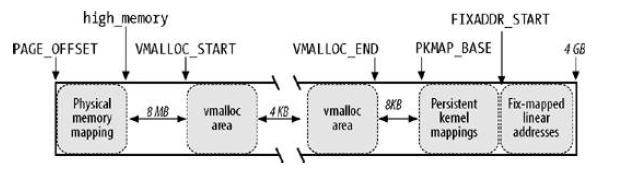
其中可以用來完成上述映射目的的區域為vmalloc area,Persistent kernel mappings區域和固定映射線性地址空間中的FIX_KMAP區域,這三個區域對應的映射機制分別為非連續記憶體分配,永久內核映射和臨時內核映射。
內核將高端記憶體劃分為3部分:
- VMALLOC_START~VMALLOC_END
- KMAP_BASE~FIXADDR_START
- FIXADDR_START~4G
對 於高端記憶體,可以通過 alloc_page() 或者其它函數獲得對應的 page,但是要想訪問實際物理記憶體,還得把 page 轉為線性地址才行(為什麼?想想 MMU 是如何訪問物理記憶體的),也就是說,我們需要為高端記憶體對應的 page 找一個線性空間,這個過程稱為高端記憶體映射。
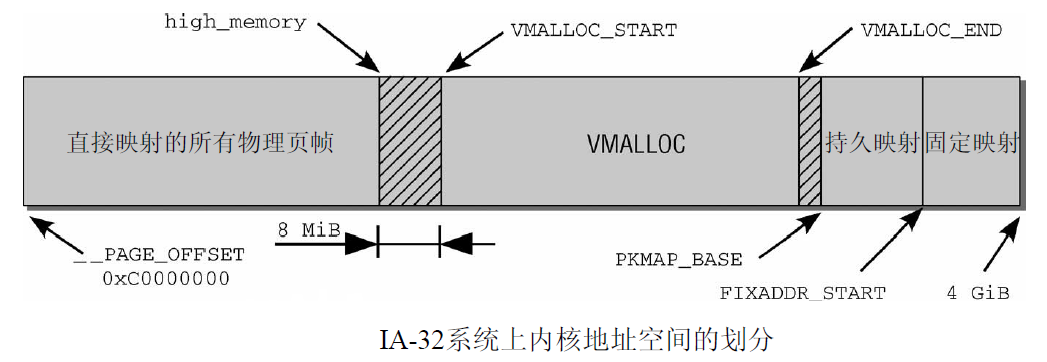
對應高端記憶體的3部分,高端記憶體映射有三種方式:
3.1 映射到”內核動態映射空間”(noncontiguous memory allocation)
這種方式很簡單,因為通過vmalloc() ,在”內核動態映射空間”申請記憶體的時候,就可能從高端記憶體獲得頁面(參看 vmalloc 的實現),因此說高端記憶體有可能映射到”內核動態映射空間”中
3.2 持久內核映射(permanent kernel mapping)
如果是通過alloc_page獲得了高端記憶體對應的 page, 如何給它找個線性空間?
內核專門為此留出一塊線性空間,從PKMAP_BASE 到 FIXADDR_START, 用於映射高端記憶體
在2.6內核上, 這個地址範圍是4G-8M到4G-4M之間. 這個空間起叫”內核永久映射空間”或者”永久內核映射空間”, 這個空間和其它空間使用同樣的頁目錄表,對於內核來說,就是 swapper_pg_dir,對普通進程來說,通過 CR3 寄存器指向。通常情況下,這個空間是 4M 大小,因此僅僅需要一個頁表即可,內核通過來 pkmap_page_table 尋找這個頁表。通過 kmap(),可以把一個 page 映射到這個空間來。由於這個空間是 4M 大小,最多能同時映射 1024 個 page。因此,對於不使用的的 page,及應該時從這個空間釋放掉(也就是解除映射關係),通過 kunmap() ,可以把一個 page 對應的線性地址從這個空間釋放出來。
3.3 臨時映射(temporary kernel mapping)
內核在 FIXADDR_START 到 FIXADDR_TOP 之間保留了一些線性空間用於特殊需求。這個空間稱為”固定映射空間”在這個空間中,有一部分用於高端記憶體的臨時映射。
這塊空間具有如下特點:
- 每個 CPU 占用一塊空間
- 在每個 CPU 占用的那塊空間中,又分為多個小空間,每個小空間大小是 1 個 page,每個小空間用於一個目的,這些目的定義在 kmap_types.h 中的 km_type 中。
當要進行一次臨時映射的時候,需要指定映射的目的,根據映射目的,可以找到對應的小空間,然後把這個空間的地址作為映射地址。這意味著一次臨時映射會導致以前的映射被覆蓋。通過 kmap_atomic() 可實現臨時映射。
4 頁框管理
4.1 頁框管理
Linux採用4KB頁框大小作為標準的記憶體分配單元。內核必須記錄每個頁框的狀態,這種狀態信息保存在一個類型為page的頁描述符中,所有的頁描述存放在mem_map中
virt_to_page(addr)產生線性地址對應的頁描述符地址。pfn_to_page(pfn)產生對應頁框號的頁描述符地址。
在頁框描述符中,幾個關鍵的欄位我認為:flags、_count、_mapcount。
由於CPU對記憶體的非一致性訪問,系統的物理記憶體被劃分為幾個節點(每個節點的描述符為pg_data_t),每個節點的物理記憶體又可以分為3個管理區:ZONE_DMA(低於16M的頁框地址),ZONE_NORMAL(16MB-896MB的頁框地址)和ZONE_HIGHMEM(高於896MB的頁框地址)。
每個管理區又有自己的描述符,描述了該管理區空閑的頁框,保留頁數目等。每個頁描述符都有到記憶體節點和到節點管理區的連接(被放在flag的高位欄位)。
內核調用一個記憶體分配函數時,必須指明請求頁框所在的管理區,內核通常指明它願意使用哪個管理區。
4.2 保留的頁框池
如果有足夠的空閑記憶體可用、請求就會被立刻滿足。否則,必須回收一些記憶體,並且將發出請求的內核控制路徑阻塞,直到有記憶體被釋放。但是有些控制路徑不能被阻塞,例如一些內核路徑產生一些原子記憶體分配請求。儘管無法保證一個原子記憶體分配請求不失敗,但是內核會減少這中概率。為了做到如此,內核採取的方案為原子記憶體分配請求保留一個頁框池,只有在記憶體不足時才使用。頁框池有ZONE_DMA和ZONE_NORMAL兩個區貢獻出一些頁框。
常用的請求頁框和釋放頁框函數:
alloc_pages(gfp_mask, order): 獲得連續的頁框,返回頁描述符地址,是其他類型記憶體分配的基礎。
__get_free_pages(gfp_mask, order): 獲得連續的頁框,返回頁框對應的線性地址。線性地址與物理地址是內核直接映射方式。不能用於大於896M的高端記憶體。
__free_pages(page,order);
__free_pages(addr,order);5 常見問題
5.1 用戶空間(進程)是否有高端記憶體概念?
用戶進程沒有高端記憶體概念。只有在內核空間才存在高端記憶體。用戶進程最多只可以訪問3G物理記憶體,而內核進程可以訪問所有物理記憶體。
5.2 64位內核中有高端記憶體嗎?
目前現實中,64位Linux內核不存在高端記憶體,因為64位內核可以支持超過512GB記憶體。若機器安裝的物理記憶體超過內核地址空間範圍,就會存在高端記憶體。
5.3 用戶進程能訪問多少物理記憶體?內核代碼能訪問多少物理記憶體?
32位系統用戶進程最大可以訪問3GB,內核代碼可以訪問所有物理記憶體。
64位系統用戶進程最大可以訪問超過512GB,內核代碼可以訪問所有物理記憶體。
5.4 高端記憶體和物理地址、邏輯地址、線性地址的關係?
高端記憶體只和邏輯地址有關係,和邏輯地址、物理地址沒有直接關係。
5.5 為什麼不把所有的地址空間都分配給內核?
若把所有地址空間都給記憶體,那麼用戶進程怎麼使用記憶體?怎麼保證內核使用記憶體和用戶進程不起衝突?
- 讓我們忽略Linux對段式記憶體映射的支持。 在保護模式下,我們知道無論CPU運行於用戶態還是核心態,CPU執行程式所訪問的地址都是虛擬地址,MMU 必須通過讀取控制寄存器CR3中的值作為當前頁面目錄的指針,進而根據分頁記憶體映射機制(參看相關文檔)將該虛擬地址轉換為真正的物理地址才能讓CPU真 正的訪問到物理地址。
- 對於32位的Linux,其每一個進程都有4G的定址空間,但當一個進程訪問其虛擬記憶體空間中的某個地址時又是怎樣實現不與其它進程的虛擬空間混淆 的呢?每個進程都有其自身的頁面目錄PGD,Linux將該目錄的指針存放在與進程對應的記憶體結構task_struct.(struct mm_struct)mm->pgd中。每當一個進程被調度(schedule())即將進入運行態時,Linux內核都要用該進程的PGD指針設 置CR3(switch_mm())。
- 當創建一個新的進程時,都要為新進程創建一個新的頁面目錄PGD,並從內核的頁面目錄swapper_pg_dir中複製內核區間頁面目錄項至新建進程頁面目錄PGD的相應位置,具體過程如下:
do_fork() –> copy_mm() –> mm_init() –> pgd_alloc() –> set_pgd_fast() –> get_pgd_slow() –> memcpy(&PGD + USER_PTRS_PER_PGD, swapper_pg_dir + USER_PTRS_PER_PGD, (PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t))
這樣一來,每個進程的頁面目錄就分成了兩部分,第一部分為“用戶空間”,用來映射其整個進程空間(0x0000 0000-0xBFFF FFFF)即3G位元組的虛擬地址;第二部分為“系統空間”,用來映射(0xC000 0000-0xFFFF FFFF)1G位元組的虛擬地址。可以看出Linux系統中每個進程的頁面目錄的第二部分是相同的,所以從進程的角度來看,每個進程有4G位元組的虛擬空間, 較低的3G位元組是自己的用戶空間,最高的1G位元組則為與所有進程以及內核共用的系統空間。
- 現在假設我們有如下一個情景:
在進程A中通過系統調用sethostname(const char *name,seze_t len)設置電腦在網路中的“主機名”.
在該情景中我們勢必涉及到從用戶空間向內核空間傳遞數據的問題,name是用戶空間中的地址,它要通過系統調用設置到內核中的某個地址中。讓我們看看這個 過程中的一些細節問題:系統調用的具體實現是將系統調用的參數依次存入寄存器ebx,ecx,edx,esi,edi(最多5個參數,該情景有兩個 name和len),接著將系統調用號存入寄存器eax,然後通過中斷指令“int 80”使進程A進入系統空間。由於進程的CPU運行級別小於等於為系統調用設置的陷阱門的準入級別3,所以可以暢通無阻的進入系統空間去執行為int 80設置的函數指針system_call()。由於system_call()屬於內核空間,其運行級別DPL為0,CPU要將堆棧切換到內核堆棧,即 進程A的系統空間堆棧。我們知道內核為新建進程創建task_struct結構時,共分配了兩個連續的頁面,即8K的大小,並將底部約1k的大小用於 task_struct(如#define alloc_task_struct() ((struct task_struct ) __get_free_pages(GFP_KERNEL,1))),而其餘部分記憶體用於系統空間的堆棧空間,即當從用戶空間轉入系統空間時,堆棧指針 esp變成了(alloc_task_struct()+8192),這也是為什麼系統空間通常用巨集定義current(參看其實現)獲取當前進程的 task_struct地址的原因。每次在進程從用戶空間進入系統空間之初,系統堆棧就已經被依次壓入用戶堆棧SS、用戶堆棧指針ESP、EFLAGS、 用戶空間CS、EIP,接著system_call()將eax壓入,再接著調用SAVE_ALL依次壓入ES、DS、EAX、EBP、EDI、ESI、 EDX、ECX、EBX,然後調用sys_call_table+4%EAX,本情景為sys_sethostname()。
在sys_sethostname()中,經過一些保護考慮後,調用copy_from_user(to,from,n),其中to指向內核空間 system_utsname.nodename,譬如0xE625A000,from指向用戶空間譬如0x8010FE00。現在進程A進入了內核,在 系統空間中運行,MMU根據其PGD將虛擬地址完成到物理地址的映射,最終完成從用戶空間到系統空間數據的複製。準備複製之前內核先要確定用戶空間地址和 長度的合法性,至於從該用戶空間地址開始的某個長度的整個區間是否已經映射並不去檢查,如果區間內某個地址未映射或讀寫許可權等問題出現時,則視為壞地址, 就產生一個頁面異常,讓頁面異常服務程式處理。過程如 下:copy_from_user()->generic_copy_from_user()->access_ok()+__copy_user_zeroing().
6 小結
- 進程定址空間0~4G
- 進程在用戶態只能訪問0~3G,只有進入內核態才能訪問3G~4G
- 進程通過系統調用進入內核態
- 每個進程虛擬空間的3G~4G部分是相同的
- 進程從用戶態進入內核態不會引起CR3的改變但會引起堆棧的改變
Linux 簡化了分段機制,使得虛擬地址與線性地址總是一致,因此,Linux的虛擬地址空間也為0~4G。Linux內核將這4G位元組的空間分為兩部分。將最高的 1G位元組(從虛擬地址0xC0000000到0xFFFFFFFF),供內核使用,稱為“內核空間”。而將較低的3G位元組(從虛擬地址 0x00000000到0xBFFFFFFF),供各個進程使用,稱為“用戶空間)。因為每個進程可以通過系統調用進入內核,因此,Linux內核由系統 內的所有進程共用。於是,從具體進程的角度來看,每個進程可以擁有4G位元組的虛擬空間。
Linux使用兩級保護機制:0級供內核使用,3級供用戶程式使用。從圖中可以看出(這裡無法表示圖),每個進程有各自的私有用戶空間(0~3G),這個空間對系統中的其他進程是不可見的。最高的1GB位元組虛擬內核空間則為所有進程以及內核所共用。
6.1 虛擬內核空間到物理空間的映射
內核空間中存放的是內核代碼和數據,而進程的用戶空間中存放的是用戶程式的代碼和數據。不管是內核空間還是用戶空間,它們都處於虛擬空間中。讀者會問,系 統啟動時,內核的代碼和數據不是被裝入到物理記憶體嗎?它們為什麼也處於虛擬記憶體中呢?這和編譯程式有關,後面我們通過具體討論就會明白這一點。
雖 然內核空間占據了每個虛擬空間中的最高1GB位元組,但映射到物理記憶體卻總是從最低地址(0x00000000)開始。對內核空間來說,其地址映射是很簡單 的線性映射,0xC0000000就是物理地址與線性地址之間的位移量,在Linux代碼中就叫做PAGE_OFFSET。
我們來看一下在include/asm/i386/page.h中對內核空間中地址映射的說明及定義:
/*
* This handles the memory map.. We could make this a config
* option, but too many people screw it up, and too few need
* it.
*
* A __PAGE_OFFSET of 0xC0000000 means that the kernel has
* a virtual address space of one gigabyte, which limits the
* amount of physical memory you can use to about 950MB.
*
* If you want more physical memory than this then see the CONFIG_HIGHMEM4G
* and CONFIG_HIGHMEM64G options in the kernel configuration.
*/
#define __PAGE_OFFSET (0xC0000000)
……
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))如果你的物理記憶體大於950MB,那麼在編譯內核時就需要加CONFIG_HIGHMEM4G和CONFIG_HIGHMEM64G選 項,這種情況我們暫不考慮。如果物理記憶體小於950MB,則對於內核空間而言,給定一個虛地址x,其物理地址為“x- PAGE_OFFSET”,給定一個物理地址x,其虛地址為“x+ PAGE_OFFSET”。
這裡再次說明,巨集__pa()僅僅把一個內核空間的虛地址映射到物理地址,而決不適用於用戶空間,用戶空間的地址映射要複雜得多。
6.2 內核映像
在下麵的描述中,我們把內核的代碼和數據就叫內核映像(kernel image)。當系統啟動時,Linux內核映像被安裝在物理地址0x00100000開始的地方,即1MB開始的區間(第1M留作它用)。然而,在正常 運行時, 整個內核映像應該在虛擬內核空間中,因此,連接程式在連接內核映像時,在所有的符號地址上加一個偏移量PAGE_OFFSET,這樣,內核映像在內核空間 的起始地址就為0xC0100000。
例如,進程的頁目錄PGD(屬於內核數據結構)就處於內核空間中。在進程切換時,要將寄存器CR3設置成指 向新進程的頁目錄PGD,而該目錄的起始地址在內核空間中是虛地址,但CR3所需要的是物理地址,這時候就要用__pa()進行地址轉換。在 mm_context.h中就有這麼一行語句:
asm volatile(“movl %0,%%cr3”: :”r” (__pa(next->pgd)); 這是一行嵌入式彙編代碼,其含義是將下一個進程的頁目錄起始地址next_pgd,通過__pa()轉換成物理地址,存放在某個寄存器中,然後用mov指令將其寫入CR3寄存器中。經過這行語句的處理,CR3就指向新進程next的頁目錄表PGD了。
6.3 高端記憶體映射方式:
高端記憶體映射有三種方式:
映射到“內核動態映射空間”
這種方式很簡單,因為通過 vmalloc() ,在“內核動態映射空間”申請記憶體的時候,就可能從高端記憶體獲得頁面(參看 vmalloc 的實現),因此說高端記憶體有可能映射到“內核動態映射空間” 中。
永久內核映射
如果是通過 alloc_page() 獲得了高端記憶體對應的 page,如何給它找個線性空間?
內核專門為此留出一塊線性空間,從 PKMAP_BASE 到 FIXADDR_START ,用於映射高端記憶體。在 2.4 內核上,這個地址範圍是 4G-8M 到 4G-4M 之間。這個空間起叫“內核永久映射空間”或者“永久內核映射空間”
這個空間和其它空間使用同樣的頁目錄表,對於內核來說,就是 swapper_pg_dir,對普通進程來說,通過 CR3 寄存器指向。
通常情況下,這個空間是 4M 大小,因此僅僅需要一個頁表即可,內核通過來 pkmap_page_table 尋找這個頁表。
通過 kmap(), 可以把一個 page 映射到這個空間來
由於這個空間是 4M 大小,最多能同時映射 1024 個 page。因此,對於不使用的的 page,應該及時從這個空間釋放掉(也除映射關就是解系),通過 kunmap() ,可以把一個 page 對應的線性地址從這個空間釋放出來。
臨時映射
內核在 FIXADDR_START 到 FIXADDR_TOP 之間保留了一些線性空間用於特殊需求。這個空間稱為“固定映射空間”
這個空間中,有一部分用於高端記憶體的臨時映射。
這塊空間具有如下特點:
- 每個 CPU 占用一塊空間
- 在每個 CPU 占用的那塊空間中,又分為多個小空間,每個小空間大小是 1 個 page,每個小空間用於一個目的,這些目的定義在 kmap_types.h 中的 km_type 中。
當要進行一次臨時映射的時候,需要指定映射的目的,根據映射目的,可以找到對應的小空間,然後把這個空間的地址作為映射地址。這意味著一次臨時映射會導致以前的映射被覆蓋。
通過 kmap_atomic() 可實現臨時映射。
下圖簡單簡單表達如何對高端記憶體進行映射
!對高端記憶體進行映射
Linux記憶體線性地址空間大小為4GB,分為2個部分:用戶空間部分(通常是3G)和內核空間部分(通常是1G)。在此我們主要關註內核地址空間部分。
內核通過內核頁全局目錄來管理所有的物理記憶體,由於線性地址前3G空間為用戶使用,內核頁全局目錄前768項(剛好3G)除0、1兩項外全部為0,後256項(1G)用來管理所有的物理記憶體。內核頁全局目錄在編譯時靜態地定義為swapper_pg_dir數組,該數組從物理記憶體地址0x101000處開始存放。
由圖可見,內核線性地址空間部分從PAGE_OFFSET(通常定義為3G)開始,為了將內核裝入記憶體,從PAGE_OFFSET開始8M線性地址用來映射內核所在的物理記憶體地址(也可以說是內核所在虛擬地址是從PAGE_OFFSET開始的);接下來是mem_map數組,mem_map的起始線性地址與體繫結構相關,比如對於UMA結構,由於從PAGE_OFFSET開始16M線性地址空間對應的16M物理地址空間是DMA區,mem_map數組通常開始於PAGE_OFFSET+16M的線性地址;從PAGE_OFFSET開始到VMALLOC_START – VMALLOC_OFFSET的線性地址空間直接映射到物理記憶體空間(一一對應影射,物理地址<==>線性地址-PAGE_OFFSET),這段區域的大小和機器實際擁有的物理記憶體大小有關,這兒VMALLOC_OFFSET在X86上為8M,主要用來防止越界錯誤;在記憶體比較小的系統上,餘下的線性地址空間(還要再減去空白區即VMALLOC_OFFSET)被vmalloc()函數用來把不連續的物理地址空間映射到連續的線性地址空間上,在記憶體比較大的系統上,vmalloc()使用從VMALLOC_START到VMALLOC_END(也即PKMAP_BASE減去2頁的空白頁大小PAGE_SIZE(解釋VMALLOC_END))的線性地址空間,此時餘下的線性地址空間(還要再減去2頁的空白區即VMALLOC_OFFSET)又可以分成2部分:第一部分從PKMAP_BASE到FIXADDR_START用來由kmap()函數來建立永久映射高端記憶體;第二部分,從FIXADDR_START到FIXADDR_TOP,這是一個固定大小的臨時映射線性地址空間,(引用:Fixed virtual addresses are needed for subsystems that need to know the virtual address at compile time such as the APIC),在X86體繫結構上,FIXADDR_TOP被靜態定義為0xFFFFE000,此時這個固定大小空間結束於整個線性地址空間最後4K前面,該固定大小空間大小是在編譯時計算出來並存儲在__FIXADDR_SIZE變數中。
正是由於vmalloc()使用區、kmap()使用區及固定大小區(kmap_atomic()使用區)的存在才使ZONE_NORMAL區大小受到限制,由於內核在運行時需要這些函數,因此線上性地址空間中至少要VMALLOC_RESERVE大小的空間。VMALLOC_RESERVE的大小與體繫結構相關,在X86上,VMALLOC_RESERVE定義為128M,這就是為什麼ZONE_NORMAL大小通常是16M到896M的原因。

