
8. 告別Lock 不是一直說Lock比較麻煩危險嗎,那就不要好了。其實有一個Lock free的方法。 首先引入一個概念——原子變數。在這種變數上的操作是原子操作(atomic operation)。原子操作就是說這個操作要麼都完成,要麼都不完成,部分完成是不行的。就像物理化學中的原子一樣,借用不 ...
8. 告別Lock
不是一直說Lock比較麻煩危險嗎,那就不要好了。其實有一個Lock free的方法。
首先引入一個概念——原子變數。在這種變數上的操作是原子操作(atomic operation)。原子操作就是說這個操作要麼都完成,要麼都不完成,部分完成是不行的。就像物理化學中的原子一樣,借用不可再分的意思。按照這樣理解,對這個原子變數的訪問操作就必定是串列的。一個原子操作完成後才能進行另一個原子操作。這樣子的變數類型多半是基本變數,什麼int啊double啊boolean啊之類。
就可以簡單這樣想,只要調用原子操作,就能保證對象的串列訪問。
常用語言原子操作內部實現基本用到了鎖。原子操作常用的有++,--,compare & swap。特別地,這個CAS(compare and swap)配合迴圈操作就能實現lock free方法。看下麵的stack.push(…)偽代碼。
1 Atomic<Node*> head; 2 Node* new_node= new Node(….); 3 New_node->next=head; (1) 4 While(!head.compare_and_swap(new_node->next, new_node)); (2)
設有一個Stack,需要push一個值進去,head指針申明為原子量。(1)把新值的next設為head。(2)更新head,如果head==new_node->next那麼,head=new_node,返回true,跳出迴圈;否則new_node->next更新為head,並返回false,繼續迴圈。猜想?什麼情況會new_node->next不等於head?如果在(1)執行完畢後head被其它線程修改。此時的old_head(new_node->next)就需要更新為當前最新的head,才能進行接下來的操作。這種方式實現的stack push就是用了lock free思想。是不是比加lock代碼看起來簡潔多了? 代碼中一個lock操作都沒有看到哦。
Lock free需要一個自旋鎖,耗CPU時間,而lock方法是直接block住,釋放占用的CPU時間。發現沒?這個“自旋鎖”思想在前文的try lock中也出現了?甚至可以這樣猜想,如果把所有的鎖都換成自旋鎖,是不是就能防止死鎖了?前面的stack.push操作也可以添加CAS試做次數,操作一定次數或時間限制,表示此次push失敗,也就跳出了此自旋鎖。另外,沒有所謂的lock free就是比lock好,根據不同的業務情況,自行選擇吧。
問:如果我的關鍵實體是一個對象,那麼可以把對象最為一個原子量嗎?這個,恐怕不能,不過可以分解對象中的一些基本類型欄位作為原子量。到底使用哪些基本類型,需要對業務需求有深刻的理解。
9. 輪詢操作
觀察者設計模式這裡不多說了,主要思想是把主動輪詢,轉變為被動通知。不過在某些併發程式集中“輪詢”比“通知”思想還要普遍,或者說“通過輪詢來通知”。甚至這樣說,我感覺在某些場合輪詢比通知更有用,特別是對順序要求敏感的地方。這類程式基於規避亂序風險從而選擇此架構方式,而且輪詢的架構方式能人為製造“程式柵欄”。Thread barrier這個操作聽說過吧,這是一種同步程式的方式。這種方式在某些分散式程式中用到(特別是消息隊列模塊),而且非常利於Debug。
一個完整的系統輪詢和通知都很重要,沒有誰好誰不好一說。寫到這裡想想,在上文輪詢中,提到“順序”兩個字,你懂的,順序執行容易引發性能瓶頸,及其連鎖反應。而且輪詢資料庫什麼的,數據多起來能直接把系統搞得不響應好嗎,考慮下觸發器嘛。所以架構就是一種舍一種得的心態,要根據具體業務需求來定奪。
“通知”的理解以後有機會再說。對了,輪詢時記得yield, 別到時候輪詢線程一跑起來把CPU時間片占光了,其它併發操作受到影響。
10. 線程操作
線程是執行一個函數,很有函數式編程理念的感覺。但是並不是線程開得越多程式處理就越快,這和實際處理器數和線程上下文切換頻率就很大關係,這些情況baidu google一下就知道,不細說,基本上最好的線程數量就大概是空閑處理器的數量。
這裡說的一個思想是線程池Thread pool。就是說線程創建後不會因為執行完畢而被銷毀,它會放入一個池子中等待新任務喚醒它,然後開始執行。線程創建是要耗CPU資源的,重覆利用當然是好的。這個功能在高級語言中有對應的實現,比如說C#的task,它的預設調度類就實現了此思想。所以說高級語言使用起來比較順暢,你不用從頭開始造輪子。C++的boost庫中也有類似方法。編程的時候用上唄,何樂而不為?
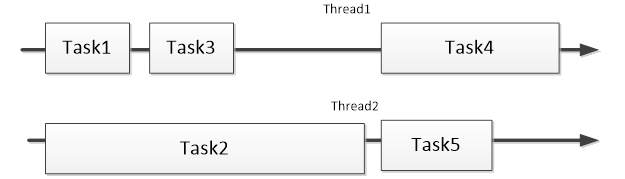
如上圖,2個線程做5個任務,而不是用5個線程。而且在task3之後,線程1就處於空轉或阻塞的等待狀態而不是銷毀自身,直到task4出現又開始執行。但是,如果5個task並行執行,且確實有如此多空閑處理器,開5條線程,處理效率更高。線程池的方式是否適用此場景還需好好考慮下。
我們看得稍微抽象點,前文所說的線程池技術,就是任務調度操作,這個以後有機會在說吧。。。


