
[TOC] 翻譯自《Demo Week: Time Series Machine Learning with h2o and timetk》 原文鏈接:https://www.business science.io/code tools/2017/10/28/demo_week_h2o.html 文 ...
目錄
翻譯自《Demo Week: Time Series Machine Learning with h2o and timetk》
原文鏈接:https://www.business-science.io/code-tools/2017/10/28/demo_week_h2o.html
文字和代碼略有刪改
時間序列分析工具箱—— h2o + timetk

h2o 的用途
h2o 包是 H2O.ai 提供的產品,包含許多先進的機器學習演算法,表現指標和輔助函數,使機器學習功能強大而且容易使用。h2o 的主要優點之一是它可以部署在集群上(今天不會討論),從 R 的角度來看,有四個主要用途:
- 數據操作:拼接、分組、旋轉、傳輸、拆分成訓練 / 測試 / 驗證集,等等。
- 機器學習演算法:包含非常複雜的監督和非監督學習演算法。監督學習演算法包括深度學習(神經網路)、隨機森林、廣義線性模型、梯度增強機、朴素貝葉斯分析、模型堆疊集成和 xgboost;無監督演算法包括廣義低秩模型、k 均值模型和 PCA;還有 Word2vec 用於文本分析。最新的穩定版本還有 AutoML——自動機器學習,我們將在這篇文章中看到這個非常酷的功能!
- 輔助機器學習功能:表現分析和超參數網格搜索。
- 產品、MapReduce 和 雲:Java 環境下進行產品化;使用 Hadoop / Spark(Sparkling Water)進行集群部署;在雲環境(Azure、AWS、Databricks 等)中部署。
我們將討論如何將 h2o 用作時間序列機器學習的一種高級演算法。我們將在本地使用 h2o,在先前關於 timetk 和 sweep 的教程中使用的數據集(beer_sales_tbl)上開發一個高精度的時間序列模型。這是一個監督學習的回歸問題。
載入包
我們需要三個包:
h2o:機器學習演算法包tidyquant:用於獲取數據和載入tidyverse系列工具timetk:R 中的時間序列工具箱
安裝 h2o
推薦在 ubuntu 環境下安裝最新穩定版 h2o。
載入包
# Load libraries
library(h2o) # Awesome ML Library
library(timetk) # Toolkit for working with time series in R
library(tidyquant) # Loads tidyverse, financial pkgs, used to get data數據
我們使用 tidyquant 的函數 tq_get(),獲取 FRED 的數據——啤酒、紅酒和蒸餾酒銷售。
# Beer, Wine, Distilled Alcoholic Beverages, in Millions USD
beer_sales_tbl <- tq_get(
"S4248SM144NCEN",
get = "economic.data",
from = "2010-01-01",
to = "2017-10-27")
beer_sales_tbl## # A tibble: 92 x 2
## date price
## <date> <int>
## 1 2010-01-01 6558
## 2 2010-02-01 7481
## 3 2010-03-01 9475
## 4 2010-04-01 9424
## 5 2010-05-01 9351
## 6 2010-06-01 10552
## 7 2010-07-01 9077
## 8 2010-08-01 9273
## 9 2010-09-01 9420
## 10 2010-10-01 9413
## # ... with 82 more rows可視化是一個好主意,我們要知道我們正在使用的是什麼數據,這對於時間序列分析和預測尤為重要,並且最好將數據分成訓練、測試和驗證集。
# Plot Beer Sales with train, validation, and test sets shown
beer_sales_tbl %>%
ggplot(aes(date, price)) +
# Train Region
annotate(
"text",
x = ymd("2012-01-01"), y = 7000,
color = palette_light()[[1]],
label = "Train Region") +
# Validation Region
geom_rect(
xmin = as.numeric(ymd("2016-01-01")),
xmax = as.numeric(ymd("2016-12-31")),
ymin = 0, ymax = Inf, alpha = 0.02,
fill = palette_light()[[3]]) +
annotate(
"text",
x = ymd("2016-07-01"), y = 7000,
color = palette_light()[[1]],
label = "Validation\nRegion") +
# Test Region
geom_rect(
xmin = as.numeric(ymd("2017-01-01")),
xmax = as.numeric(ymd("2017-08-31")),
ymin = 0, ymax = Inf, alpha = 0.02,
fill = palette_light()[[4]]) +
annotate(
"text",
x = ymd("2017-05-01"), y = 7000,
color = palette_light()[[1]],
label = "Test\nRegion") +
# Data
geom_line(col = palette_light()[1]) +
geom_point(col = palette_light()[1]) +
geom_ma(ma_fun = SMA, n = 12, size = 1) +
# Aesthetics
theme_tq() +
scale_x_date(
date_breaks = "1 year",
date_labels = "%Y") +
labs(title = "Beer Sales: 2007 through 2017",
subtitle = "Train, Validation, and Test Sets Shown") 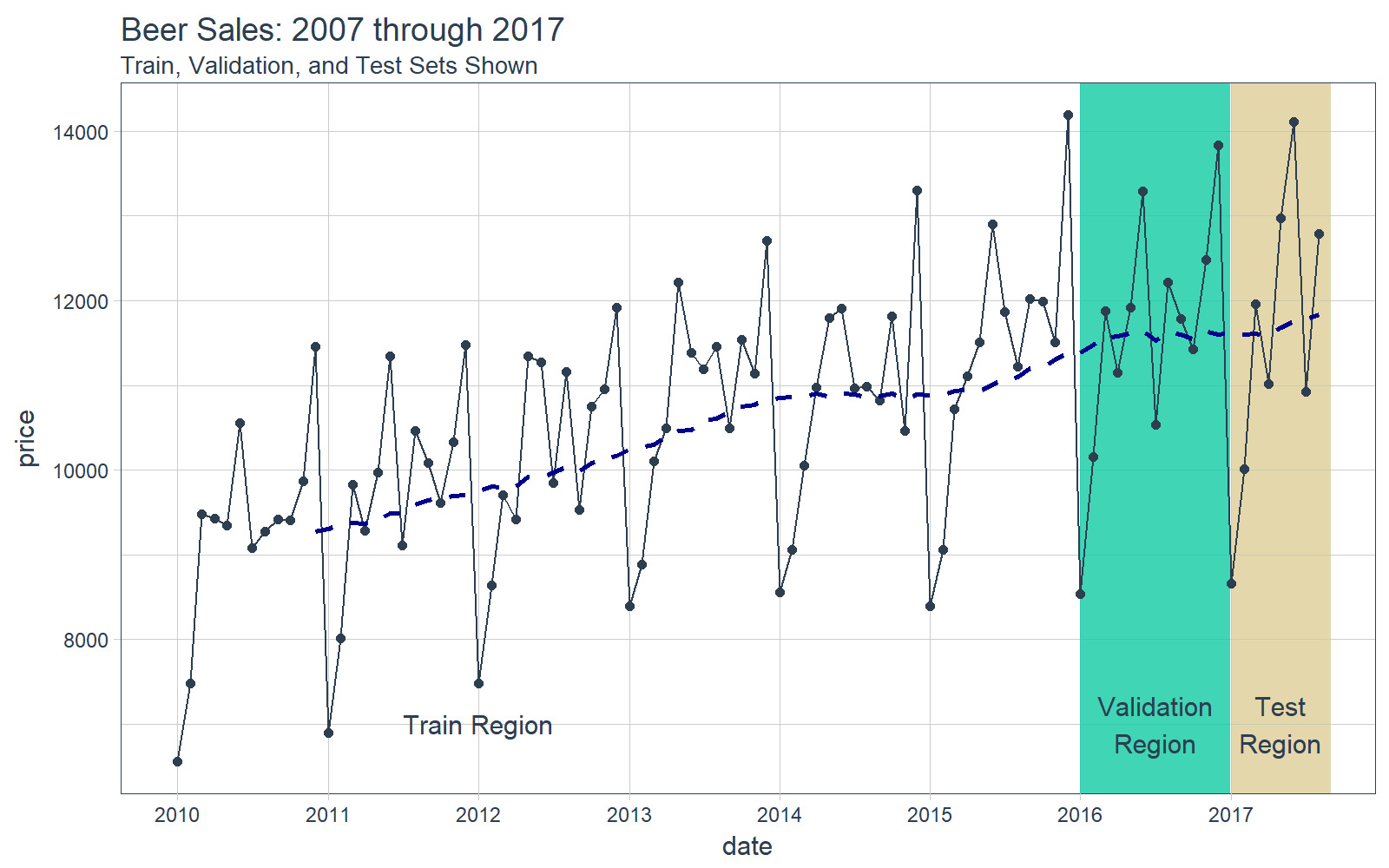
現在我們對數據有了直觀的認識,讓我們繼續吧。
教程:h2o + timetk,時間序列機器學習
我們的時間序列機器學習項目遵循的工作流與之前 timetk + 線性回歸文章中的類似。但是,這次我們將用 h2o.autoML() 替換 lm() 函數以獲得更高的準確性。
時間序列機器學習
時間序列機器學習是預測時間序列數據的好方法,在開始之前,先明確教程的兩個關鍵問題:
- 關鍵洞察:時間序列簽名——將時間戳信息逐列擴展,成為特征集,用於執行機器學習演算法。
- 目標:我們將用時間序列簽名預測未來 8 個月的數據,並和先前教程中出現的兩種方法(即
timetk+lm()和sweep+auto.arima())的預測結果作對比。
下麵,我們將經歷一遍執行時間序列機器學習的工作流。
STEP 0:檢查數據
作為分析的起點,先用 glimpse() 列印出 beer_sales_tbl,獲得數據的第一印象。
# Starting point
beer_sales_tbl %>%
glimpse()## Observations: 92
## Variables: 2
## $ date <date> 2010-01-01, 2010-02-01, 2010-03-01, 2010-04-01, 20...
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273, 94...STEP 1:擴充時間序列簽名
tk_augment_timeseries_signature() 函數將時間戳信息逐列擴展成機器學習所用的特征集,將時間序列信息列添加到原始數據框。再次使用 glimpse() 進行快速檢查。現在有了 30 個特征,有些特征很重要,但並非所有特征都重要。
# Augment (adds data frame columns)
beer_sales_tbl_aug <- beer_sales_tbl %>%
tk_augment_timeseries_signature()
beer_sales_tbl_aug %>% glimpse()## Observations: 92
## Variables: 30
## $ date <date> 2010-01-01, 2010-02-01, 2010-03-01, 2010-04-01...
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273...
## $ index.num <int> 1262304000, 1264982400, 1267401600, 1270080000,...
## $ diff <int> NA, 2678400, 2419200, 2678400, 2592000, 2678400...
## $ year <int> 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ year.iso <int> 2009, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ half <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1,...
## $ quarter <int> 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 1, 1, 1, 2,...
## $ month <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3,...
## $ month.xts <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, ...
## $ month.lbl <ord> January, February, March, April, May, June, Jul...
## $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ minute <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ second <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ hour12 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ am.pm <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ wday <int> 6, 2, 2, 5, 7, 3, 5, 1, 4, 6, 2, 4, 7, 3, 3, 6,...
## $ wday.xts <int> 5, 1, 1, 4, 6, 2, 4, 0, 3, 5, 1, 3, 6, 2, 2, 5,...
## $ wday.lbl <ord> Friday, Monday, Monday, Thursday, Saturday, Tue...
## $ mday <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ qday <int> 1, 32, 60, 1, 31, 62, 1, 32, 63, 1, 32, 62, 1, ...
## $ yday <int> 1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 30...
## $ mweek <int> 5, 6, 5, 5, 5, 6, 5, 5, 5, 5, 6, 5, 5, 6, 5, 5,...
## $ week <int> 1, 5, 9, 13, 18, 22, 26, 31, 35, 40, 44, 48, 1,...
## $ week.iso <int> 53, 5, 9, 13, 17, 22, 26, 30, 35, 39, 44, 48, 5...
## $ week2 <int> 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1,...
## $ week3 <int> 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 2, 0, 1, 2, 0, 1,...
## $ week4 <int> 1, 1, 1, 1, 2, 2, 2, 3, 3, 0, 0, 0, 1, 1, 1, 1,...
## $ mday7 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...STEP 2:為 h2o 準備數據
我們需要以 h2o 的格式準備數據。首先,讓我們刪除任何不必要的列,如日期列或存在缺失值的列,並將有序類型的數據更改為普通因數。我們推薦用 dplyr 操作這些步驟。
beer_sales_tbl_clean <- beer_sales_tbl_aug %>%
select_if(~ !is.Date(.)) %>%
select_if(~ !any(is.na(.))) %>%
mutate_if(is.ordered, ~ as.character(.) %>% as.factor)
beer_sales_tbl_clean %>% glimpse()## Observations: 92
## Variables: 28
## $ price <int> 6558, 7481, 9475, 9424, 9351, 10552, 9077, 9273...
## $ index.num <int> 1262304000, 1264982400, 1267401600, 1270080000,...
## $ year <int> 2010, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ year.iso <int> 2009, 2010, 2010, 2010, 2010, 2010, 2010, 2010,...
## $ half <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1,...
## $ quarter <int> 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 1, 1, 1, 2,...
## $ month <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3,...
## $ month.xts <int> 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 1, 2, ...
## $ month.lbl <fctr> January, February, March, April, May, June, Ju...
## $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ hour <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ minute <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ second <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ hour12 <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ am.pm <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ wday <int> 6, 2, 2, 5, 7, 3, 5, 1, 4, 6, 2, 4, 7, 3, 3, 6,...
## $ wday.xts <int> 5, 1, 1, 4, 6, 2, 4, 0, 3, 5, 1, 3, 6, 2, 2, 5,...
## $ wday.lbl <fctr> Friday, Monday, Monday, Thursday, Saturday, Tu...
## $ mday <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...
## $ qday <int> 1, 32, 60, 1, 31, 62, 1, 32, 63, 1, 32, 62, 1, ...
## $ yday <int> 1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 30...
## $ mweek <int> 5, 6, 5, 5, 5, 6, 5, 5, 5, 5, 6, 5, 5, 6, 5, 5,...
## $ week <int> 1, 5, 9, 13, 18, 22, 26, 31, 35, 40, 44, 48, 1,...
## $ week.iso <int> 53, 5, 9, 13, 17, 22, 26, 30, 35, 39, 44, 48, 5...
## $ week2 <int> 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1,...
## $ week3 <int> 1, 2, 0, 1, 0, 1, 2, 1, 2, 1, 2, 0, 1, 2, 0, 1,...
## $ week4 <int> 1, 1, 1, 1, 2, 2, 2, 3, 3, 0, 0, 0, 1, 1, 1, 1,...
## $ mday7 <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,...讓我們在可視化之前按照時間範圍將數據分成訓練、驗證和測試集。
# Split into training, validation and test sets
train_tbl <- beer_sales_tbl_clean %>% filter(year < 2016)
valid_tbl <- beer_sales_tbl_clean %>% filter(year == 2016)
test_tbl <- beer_sales_tbl_clean %>% filter(year == 2017)STEP 3:h2o 模型
首先,啟動 h2o。這將初始化 h2o 使用的 java 虛擬機。
h2o.init() # Fire up h2o## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 46 minutes 4 seconds
## H2O cluster version: 3.14.0.3
## H2O cluster version age: 1 month and 5 days
## H2O cluster name: H2O_started_from_R_mdancho_pcs046
## H2O cluster total nodes: 1
## H2O cluster total memory: 3.51 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: Algos, AutoML, Core V3, Core V4
## R Version: R version 3.4.1 (2017-06-30)h2o.no_progress() # Turn off progress bars將數據轉成 H2OFrame 對象,使得 h2o 包可以讀取。
# Convert to H2OFrame objects
train_h2o <- as.h2o(train_tbl)
valid_h2o <- as.h2o(valid_tbl)
test_h2o <- as.h2o(test_tbl)為目標和預測變數命名。
# Set names for h2o
y <- "price"
x <- setdiff(names(train_h2o), y)我們將使用 h2o.automl,在數據上嘗試任何回歸模型。
x = x:特征列的名字y = y:目標列的名字training_frame = train_h2o:訓練集,包括 2010 - 2016 年的數據validation_frame = valid_h2o:驗證集,包括 2016 年的數據,用於避免模型的過度擬合leaderboard_frame = test_h2o:模型基於測試集上 MAE 的表現排序max_runtime_secs = 60:設置這個參數用於加速h2o模型計算。演算法背後有大量複雜模型需要計算,所以我們以犧牲精度為代價,保證模型可以正常運轉。stopping_metric = "deviance":把偏離度作為停止指標,這可以改善結果的 MAPE。
# linear regression model used, but can use any model
automl_models_h2o <- h2o.automl(
x = x,
y = y,
training_frame = train_h2o,
validation_frame = valid_h2o,
leaderboard_frame = test_h2o,
max_runtime_secs = 60,
stopping_metric = "deviance")接著,提取主模型。
# Extract leader model
automl_leader <- automl_models_h2o@leaderSTEP 4:預測
使用 h2o.predict() 在測試數據上產生預測。
pred_h2o <- h2o.predict(
automl_leader, newdata = test_h2o)STEP 5:評估表現
有幾種方法可以評估模型表現,這裡,將通過簡單的方法,即 h2o.performance()。這產生了預設值,這些預設值通常用於比較回歸模型,包括均方根誤差(RMSE)和平均絕對誤差(MAE)。
h2o.performance(
automl_leader, newdata = test_h2o)## H2ORegressionMetrics: gbm
##
## MSE: 340918.3
## RMSE: 583.8821
## MAE: 467.8388
## RMSLE: 0.04844583
## Mean Residual Deviance : 340918.3我們偏好的評估指標是平均絕對百分比誤差(MAPE),未包括在上面。但是,我們可以輕易計算出來。我們可以查看測試集上的誤差(實際值 vs 預測值)。
# Investigate test error
error_tbl <- beer_sales_tbl %>%
filter(lubridate::year(date) == 2017) %>%
add_column(
pred = pred_h2o %>% as.tibble() %>% pull(predict)) %>%
rename(actual = price) %>%
mutate(
error = actual - pred,
error_pct = error / actual)
error_tbl## # A tibble: 8 x 5
## date actual pred error error_pct
## <date> <int> <dbl> <dbl> <dbl>
## 1 2017-01-01 8664 8241.261 422.7386 0.048792541
## 2 2017-02-01 10017 9495.047 521.9534 0.052106763
## 3 2017-03-01 11960 11631.327 328.6726 0.027480989
## 4 2017-04-01 11019 10716.038 302.9619 0.027494498
## 5 2017-05-01 12971 13081.857 -110.8568 -0.008546509
## 6 2017-06-01 14113 12796.170 1316.8296 0.093306142
## 7 2017-07-01 10928 10727.804 200.1962 0.018319563
## 8 2017-08-01 12788 12249.498 538.5016 0.042109915為了比較,我們計算了一些殘差度量指標。
error_tbl %>%
summarise(
me = mean(error),
rmse = mean(error^2)^0.5,
mae = mean(abs(error)),
mape = mean(abs(error_pct)),
mpe = mean(error_pct)) %>%
glimpse()## Observations: 1
## Variables: 5
## $ me <dbl> 440.1246
## $ rmse <dbl> 583.8821
## $ mae <dbl> 467.8388
## $ mape <dbl> 0.03976961
## $ mpe <dbl> 0.03763299STEP 6:可視化預測結果
最後,可視化我們得到的預測結果。
beer_sales_tbl %>%
ggplot(aes(x = date, y = price)) +
# Data - Spooky Orange
geom_point(col = palette_light()[1]) +
geom_line(col = palette_light()[1]) +
geom_ma(
n = 12) +
# Predictions - Spooky Purple
geom_point(
aes(y = pred),
col = palette_light()[2],
data = error_tbl) +
geom_line(
aes(y = pred),
col = palette_light()[2],
data = error_tbl) +
# Aesthetics
theme_tq() +
labs(
title = "Beer Sales Forecast: h2o + timetk",
subtitle = "H2O had highest accuracy, MAPE = 3.9%")
最終的勝利者是...
h2o + timetk 的 MAPE 優於先前兩個教程中的方法:
- timetk + h2o:MAPE = 3.9%(本教程)
- timetk + linear regression:MAPE = 4.3%(時間序列分析工具箱——timetk)
- sweep + ARIMA:MAPE = 4.3%(時間序列分析工具箱——sweep)
感興趣的讀者要問一個問題:對所有三種不同方法的預測進行平均時,準確度會發生什麼變化?
請註意,時間序列機器學習的準確性可能並不總是優於 ARIMA 和其他預測技術,包括那些由 prophet(Facebook 開發的預測工具)和 GARCH 方法實現的技術。數據科學家有責任測試不同的方法併為工作選擇合適的工具。


