
在對文檔(Document)中的內容進行索引前, 需要對域(Field)中的內容使用分析對象(分詞器)進行分詞. IK分詞器是一款功能完備、擴展性較高的中文分詞器, 企業開發中使用較多. ...
1 分詞器簡介及IK分詞器的使用
1.1 分詞器簡介
在對文檔(Document)中的內容進行索引前, 需要對域(Field)中的內容使用分析對象(分詞器)進行分詞.
分詞的目的是為了索引, 索引的目的是為了搜索.
- 分詞的過程是 先分詞, 再過濾:
- 分詞: 將Document中Field域的值切分成一個一個的單詞. 具體的切分方法(演算法)由具體使用的分詞器內部實現.
- 過濾: 去除標點符號,去除停用詞(的、是、is、the、a等), 詞的大寫轉為小寫.
分詞流程圖:

停用詞說明:
停用詞是指為了節省存儲空間和提高搜索效率, 搜索引擎在索引內容或處理搜索請求時會自動忽略的字詞, 這些字或詞被稱為"stop words". 如語氣助詞、副詞、介詞、連接詞等, 通常自身沒有明確的含義, 只有放在一個上下文語句中才有意義(如:的、在、啊, is、a等).
例如:
原始文檔內容: Lucene is a Java full-text search engine
分析以後的詞: lucene java full text search engine
1.2 分詞器的使用
1.2.1 索引流程使用
流程: 把原始數據轉換成文檔對象(Document), 再使用分詞器將文檔域(Field)的內容切分成一個一個的詞語.
目的: 方便後續建立索引.
1.2.2 檢索流程使用
流程: 根據用戶輸入的查詢關鍵詞, 使用分詞器將關鍵詞進行分詞以後, 建立查詢對象(Query), 再執行搜索.
註意: 索引流程和檢索流程使用的分詞器, 必須統一.
1.3 中文分詞器
1.3.1 中文分詞器簡介
英文本身是以單詞為單位, 單詞與單詞之間, 句子之間通常是空格、逗號、句號分隔. 因而對於英文, 可以簡單的以空格來判斷某個字元串是否是一個詞, 比如: I love China, love和China很容易被程式處理.
但是中文是以字為單位的, 字與字再組成詞, 詞再組成句子. 中文: 我愛中國, 電腦不知道“愛中”是一個詞, 還是“中國”是一個詞?所以我們需要一定的規則來告訴電腦應該怎麼切分, 這就是中文分詞器所要解決的問題.
常見的有一元切分法“我愛中國”: 我、愛、中、國. 二元切分法”我愛中國”: 我愛, 愛中、中國.
1.3.2 Lucene提供的中文分詞器
StandardAnalyzer分詞器:
單字分詞器: 一個字切分成一個詞, 一元切分法.
CJKAnalyzer分詞器:
二元切分法: 把相鄰的兩個字, 作為一個詞.
SmartChineseAnalyzer分詞器:
通常一元切分法, 二元切分法都不能滿足我們的業務需求. 而SmartChineseAnalyzer對中文支持較好, 但是擴展性差, 針對擴展詞庫、停用詞均不好處理.
說明: Lucene提供的中文分詞器, 只做瞭解, 企業項目中不推薦使用.
1.3.3 第三方中文分詞器
paoding: 庖丁解牛分詞器, 可在https://code.google.com/p/paoding/下載. 沒有持續更新, 只支持到lucene3.0, 項目中不予以考慮使用.
- mmseg4j: 最新版已從https://code.google.com/p/mmseg4j/移至https://github.com/chenlb/mmseg4j-solr. 支持Lucene4.10, 且在github中有持續更新, 使用的是mmseg演算法.
IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上, 支持Lucene 4.10. 從2006年12月推出1.0版開始, IKAnalyzer已經推出了4個大版本. 最初是以開源項目Luence為應用主體的, 結合詞典分詞和文法分析演算法的中文分片語件. 從3.0版本開始, IK發展為面向Java的公用分片語件, 獨立於Lucene項目, 同時提供了對Lucene的預設優化實現. 適合在項目中應用.
1.4 使用IK分詞器
說明: 由於IK分詞器是對Lucene分詞器的擴展實現, 使用IK分詞器與使用Lucene分詞器是一樣的.
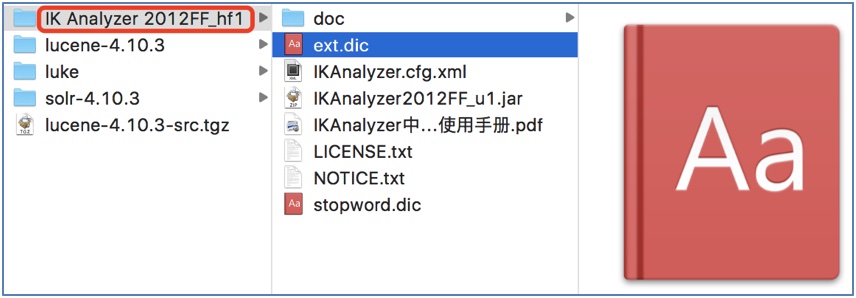
1.4.1 配置pom.xml文件, 加入IK分詞器的依賴
<project>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- mysql版本 -->
<mysql.version>5.1.44</mysql.version>
<!-- lucene版本 -->
<lucene.version>4.10.4</lucene.version>
<!-- ik分詞器版本 -->
<ik.version>2012_u6</ik.version>
</properties>
<dependencies>
<!-- ik分詞器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>${ik.version}</version>
</dependency>
</dependencies>
</project> 1.4.2 修改索引流程的分詞器

1.4.3 修改檢索流程的分詞器

1.4.4 重新創建索引
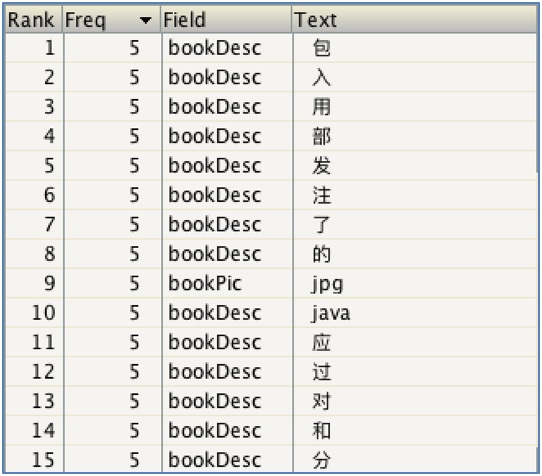
使用Lucene預設的標準分詞器(一元分詞器):
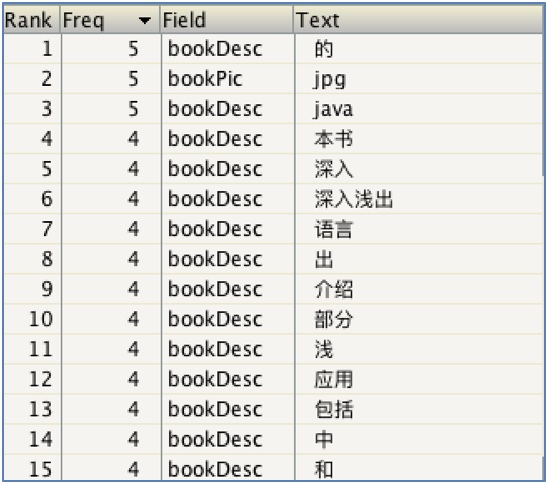
使用ik分詞器之後(對中文分詞支持較好):
1.5 擴展中文詞庫
說明: 企業開發中, 隨著業務的發展, 會產生一些新的詞語不需要分詞, 而需要作為整體匹配, 如: 尬聊, 戲精, 藍瘦香菇; 也可能有一些詞語會過時, 需要停用.
-- 通過配置文件來實現.
1.5.1 加入IK分詞器的配置文件
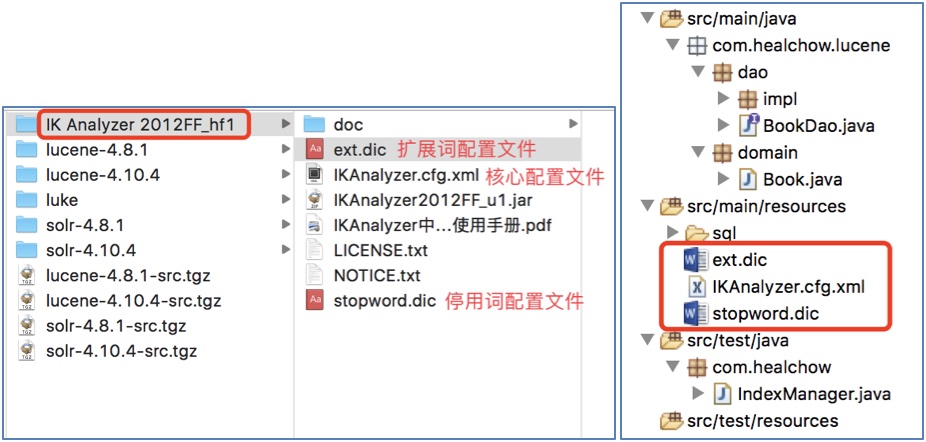
說明: 這些配置文件需要放到類的根路徑下.
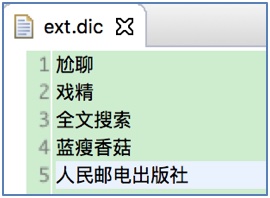
1.5.2 增加擴展詞演示(擴展: 人民郵電出版社)
說明: 在ext.dic文件中增加"人民郵電出版社":
註意: 不要使用Windows自帶的記事本或Word, 因為這些程式會在文件中加入一些標記符號(bom, byte order market), 導致配置文件不能被識別.
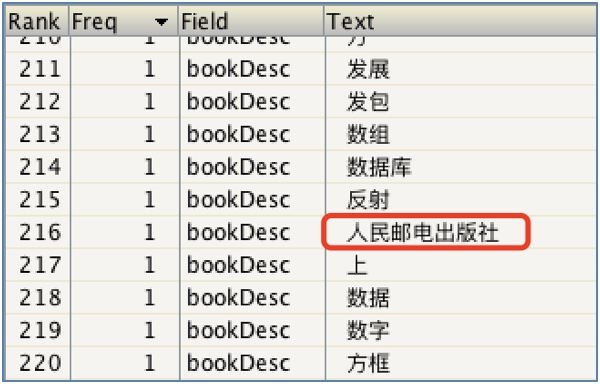
增加擴展詞之後:
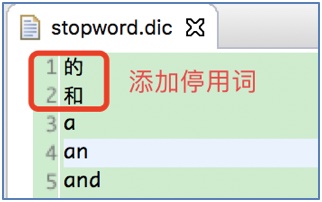
1.5.3 增加停用詞演示(增加: 的、和)
在stopword.dic文件增加停用詞(的、和):
增加停用詞之前:
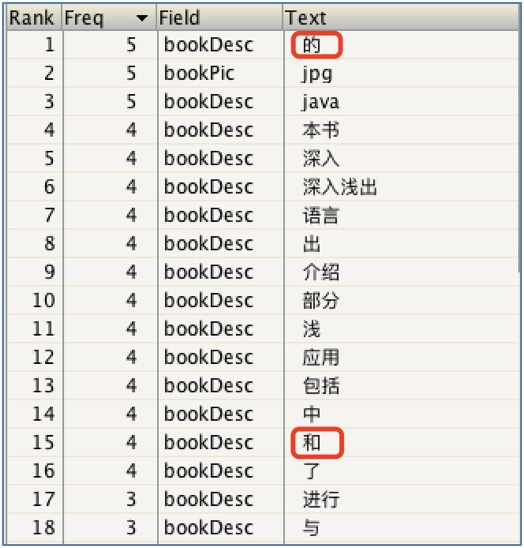
增加停用詞之後:

註意事項: 修改擴展詞配置文件ext.dic和停用詞配置文件stopword.dic, 不能使用windows自帶的記事本程式修改, 否則修改以後不生效: 記事本程式會增加一些bom符號.
推薦使用notepad++, sublime, eclipse自帶的編輯器修改.
版權聲明
作者: ma_shoufeng(馬瘦風)
出處: 博客園 馬瘦風的博客
您的支持是對博主的極大鼓勵, 感謝您的閱讀.
本文版權歸博主所有, 歡迎轉載, 但未經博主同意必須保留此段聲明, 且在文章頁面明顯位置給出原文鏈接, 否則博主保留追究法律責任的權利.


